
Évaluation de la qualité des prédictions d'impact causal
Publié: 2022-02-15CausalImpact est l'un des packages les plus populaires utilisés dans l'expérimentation SEO. Sa popularité est compréhensible.
L'expérimentation SEO fournit des informations intéressantes et des moyens pour les référenceurs de rendre compte de la valeur de leur travail.
Pourtant, la précision de tout modèle d'apprentissage automatique dépend des informations d'entrée qui lui sont fournies.
En termes simples, une mauvaise entrée peut renvoyer une mauvaise estimation.
Dans cet article, nous montrerons à quel point CausalImpact peut être fiable (et peu fiable). Nous apprendrons également comment devenir plus confiant dans les résultats de vos expériences.
Tout d'abord, nous allons donner un bref aperçu du fonctionnement de CausalImpact. Ensuite, nous discuterons de la fiabilité des estimations de CausalImpact. Enfin, nous découvrirons une méthodologie qui peut être utilisée pour estimer vos propres résultats d'expériences SEO.
Qu'est-ce que CausalImpact et comment ça marche ?
CausalImpact est un package qui utilise des statistiques bayésiennes pour estimer l'effet d'un événement en l'absence d'expérience. Cette estimation est appelée inférence causale.
L'inférence causale estime si un changement observé a été causé par un événement spécifique.
Il est souvent utilisé pour évaluer les performances des expériences SEO.
Par exemple, lorsqu'on lui donne la date d'un événement, CausalImpact (CI) utilisera les points de données avant l'intervention pour prédire les points de données après l'intervention. Il comparera ensuite la prédiction aux données observées et estimera la différence avec un certain seuil de confiance.
De plus, des groupes de contrôle peuvent être utilisés pour rendre les prédictions plus précises.
Différents paramètres auront également un impact sur la précision de la prédiction :
- Taille des données de test.
- Durée de la période précédant l'expérience.
- Choix du groupe témoin à comparer.
- Hyperparamètres de saisonnalité.
- Nombre d'itérations.
Tous ces paramètres aident à fournir plus de contexte au modèle et à améliorer sa fiabilité.
Oncrawl BI
 Découvrir
DécouvrirPourquoi l'évaluation de la précision des expériences de référencement est-elle importante ?
Au cours des dernières années, j'ai analysé de nombreuses expériences de référencement et quelque chose m'a frappé.
Plusieurs fois, l'utilisation de différents groupes de contrôle et de délais sur des ensembles de tests et des dates d'intervention identiques a donné des résultats différents.
À titre d'illustration, voici deux résultats du même événement.
Le premier a rapporté une baisse statistiquement significative. 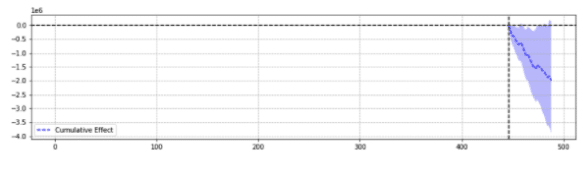
La seconde n'était pas statistiquement significative. 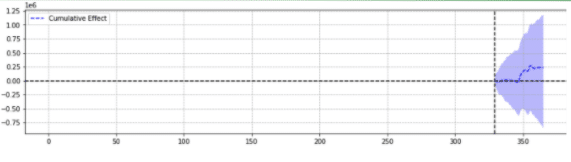
En termes simples, pour le même événement, différents résultats ont été renvoyés en fonction des paramètres choisis.
Il faut se demander quelle prédiction est exacte.
Au final, le « statistiquement significatif » n'est-il pas censé renforcer la confiance dans nos estimations ?
Définitions
Pour mieux comprendre le monde des expérimentations SEO, le lecteur doit connaître les concepts de base des expérimentations SEO :
- Expérimentation : procédure entreprise pour tester une hypothèse. Dans le cas de l'inférence causale, elle a une date de début spécifique.
- Groupe de test : un sous-ensemble de données auquel un changement est appliqué. Il peut s'agir d'un site Web entier ou d'une partie du site.
- Groupe de contrôle : un sous-ensemble de données auquel aucun changement n'a été appliqué. Vous pouvez avoir un ou plusieurs groupes de contrôle. Il peut s'agir d'un site distinct dans le même secteur ou d'une partie différente du même site.
L'exemple ci-dessous aidera à illustrer ces concepts :
La modification du titre (expérience) devrait augmenter le CTR organique de 1 % (hypothèse) des pages produits dans cinq villes (groupe test). Les estimations seront améliorées en utilisant un titre inchangé sur toutes les autres villes (groupe témoin).
Piliers de la prédiction précise des expériences de référencement
- Pour plus de simplicité, j'ai compilé quelques informations intéressantes pour les professionnels du référencement qui apprennent à améliorer la précision des expériences :
- Certaines entrées dans CausalImpact renverront des estimations erronées, même si elles sont statistiquement significatives. C'est ce que nous appelons les "faux positifs" et les "faux négatifs".
- Il n'y a pas de règle générale qui régit le contrôle à utiliser par rapport à un ensemble de tests. Une expérience est nécessaire pour définir les meilleures données de contrôle à utiliser pour un ensemble de test spécifique.
- L'utilisation de CausalImpact avec le bon contrôle et la bonne longueur de données de pré-période peut être très précise, l'erreur moyenne étant aussi faible que 0,1 %.
- Alternativement, l'utilisation de CausalImpact avec le mauvais contrôle peut entraîner un taux d'erreur élevé. Des expériences personnelles ont montré des variations statistiquement significatives allant jusqu'à 20%, alors qu'en fait il n'y avait aucun changement.
- Tout ne peut pas être testé. Certains groupes de test ne renvoient presque jamais d'estimations précises.
- Les expériences avec ou sans groupes de contrôle ont besoin de différentes longueurs de données avant l'intervention.
Tous les groupes de test ne renverront pas des estimations précises
Certains groupes de test renverront toujours des prédictions inexactes. Ils ne doivent pas être utilisés pour l'expérimentation.
Les groupes de test avec de grandes variations anormales de trafic renvoient souvent des résultats peu fiables.
Par exemple, la même année, un site Web a subi une migration de site, a été touché par la pandémie de covid et une partie du site a été « non indexée » pendant 2 semaines en raison d'une erreur technique. Faire des expériences sur ce site fournira des résultats peu fiables.
Les éléments ci-dessus ont été recueillis grâce à une vaste série de tests effectués à l'aide de la méthodologie décrite ci-dessous.
Lorsque vous n'utilisez pas les groupes de contrôle
- L'utilisation d'un contrôle au lieu d'un simple pré-post peut augmenter jusqu'à 18 fois la précision de l'estimation.
- L'utilisation de 16 mois de données antérieures était aussi précise que l'utilisation de 3 ans.
Lors de l'utilisation de groupes de contrôle
- Il est souvent préférable d'utiliser le bon contrôle que d'utiliser plusieurs contrôles. Cependant, un seul contrôle augmente les risques de prédiction erronée dans les cas où le trafic du contrôle varie beaucoup.
- Choisir le bon contrôle peut multiplier par 10 la précision (par exemple, l'un signale +3,1 % et l'autre +4,1 % alors qu'en fait, il était de +3 %).
- La plupart des modèles de trafic corrélés entre les données de test et les données de contrôle ne signifient pas nécessairement de meilleures estimations.
- L'utilisation de 16 mois de données antérieures n'était PAS aussi précise que l'utilisation de 3 ans.
Méfiez-vous de la longueur des données avant les expériences
Fait intéressant, lors de l'expérimentation avec des groupes de contrôle, l'utilisation de 16 mois de données auparavant peut entraîner un taux d'erreur très intense.
En fait, les erreurs peuvent être aussi importantes que l'estimation d'une augmentation de trafic par 3 alors qu'il n'y a eu aucun changement réel.
Cependant, l'utilisation de 3 ans de données a supprimé ce taux d'erreur. Cela contraste avec de simples expériences pré-post où ce taux d'erreur n'a pas augmenté en augmentant la durée de 16 à 36 mois.
Cela ne signifie pas que l'utilisation des contrôles est mauvaise. C'est tout le contraire.
Il montre simplement comment l'ajout de contrôle affecte les prédictions.

C'est le cas lorsqu'il y a de grandes variations dans le groupe de contrôle.
Cette conclusion est particulièrement importante pour les sites Web qui ont connu des variations de trafic anormales au cours de l'année écoulée (erreur technique critique, pandémie de COVID, etc.).
Comment évaluer la prédiction de l'impact causal ?
Maintenant, il n'y a pas de score de précision construit dans la bibliothèque CausalImpact. Donc, il faut en déduire le contraire.
On peut regarder comment d'autres modèles d'apprentissage automatique estiment la précision de leurs prédictions et se rendre compte que la somme des erreurs des carrés (SSE) est une métrique très courante.
La somme des erreurs des carrés, ou somme résiduelle des carrés, calcule la somme de toutes les (n) différences entre les attentes (yi) et les résultats réels (f(xi)), au carré. 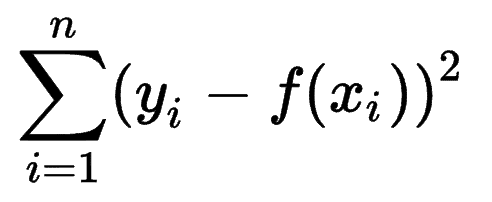
Plus le SSE est faible, meilleur est le résultat.
Le défi est qu'avec les expériences pré-post sur le trafic SEO, il n'y a pas de résultats réels.
Bien qu'aucune modification n'ait été apportée sur place, certaines modifications peuvent s'être produites hors de votre contrôle (par exemple, mise à jour de l'algorithme Google, nouveau concurrent, etc.). Le trafic SEO ne varie pas non plus d'un nombre fixe mais varie progressivement de haut en bas.
Les spécialistes du référencement peuvent se demander comment relever le défi.
Présentation de fausses variations
Pour être certain de l'ampleur de la variation causée par un événement, l'expérimentateur peut introduire des variations fixes à différents moments dans le temps et voir si CausalImpact a réussi à estimer le changement.
Mieux encore, l'expert SEO peut répéter le processus pour différents groupes de test et de contrôle.
En utilisant Python, des variations fixes ont été introduites dans les données à différentes dates d'intervention pour la post-période.
La somme des erreurs au carré a ensuite été estimée entre la variation rapportée par CausalImpact et la variation introduite.
L'idée va comme ceci:
- Choisissez un test et contrôlez les données.
- Introduire de fausses interventions dans les données réelles à différentes dates (par exemple, augmentation de 5 %).
- Comparez les estimations de CausalImpact à chacune des variations introduites.
- Calculez la somme des erreurs des carrés (SSE).
- Répétez l'étape 1 avec plusieurs contrôles.
- Choisissez le contrôle avec le plus petit SSE pour des expériences dans le monde réel
La Méthodologie
Avec la méthodologie ci-dessous, j'ai créé un tableau que je pourrais utiliser pour identifier quel contrôle avait les meilleurs et les pires taux d'erreur à différents moments.
Tout d'abord, choisissez un test et des données de contrôle et introduisez des variations de -50 % à 50 %.
Ensuite, exécutez CausalImpact (CI) et soustrayez les variations signalées par CI à la variation que vous avez réellement introduite.
Ensuite, calculez les carrés de ces différences et additionnez toutes les valeurs ensemble.
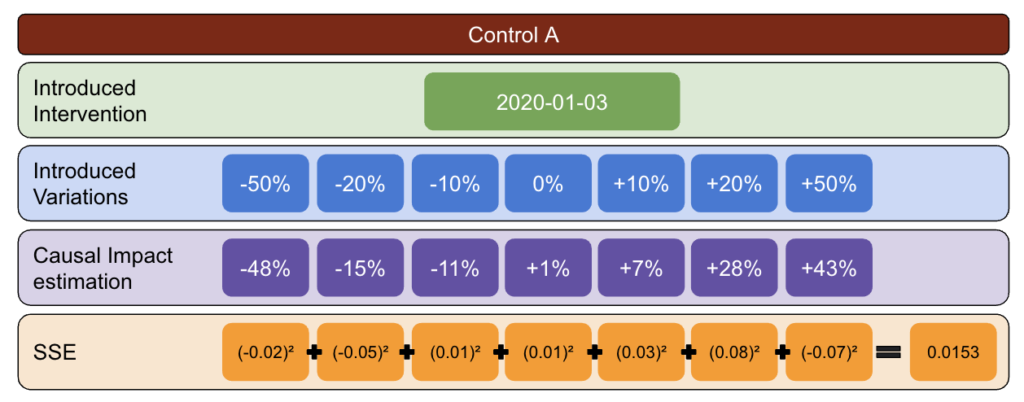
Ensuite, répétez le même processus à des dates différentes pour réduire le risque de biais causé par une variation réelle à une date précise.
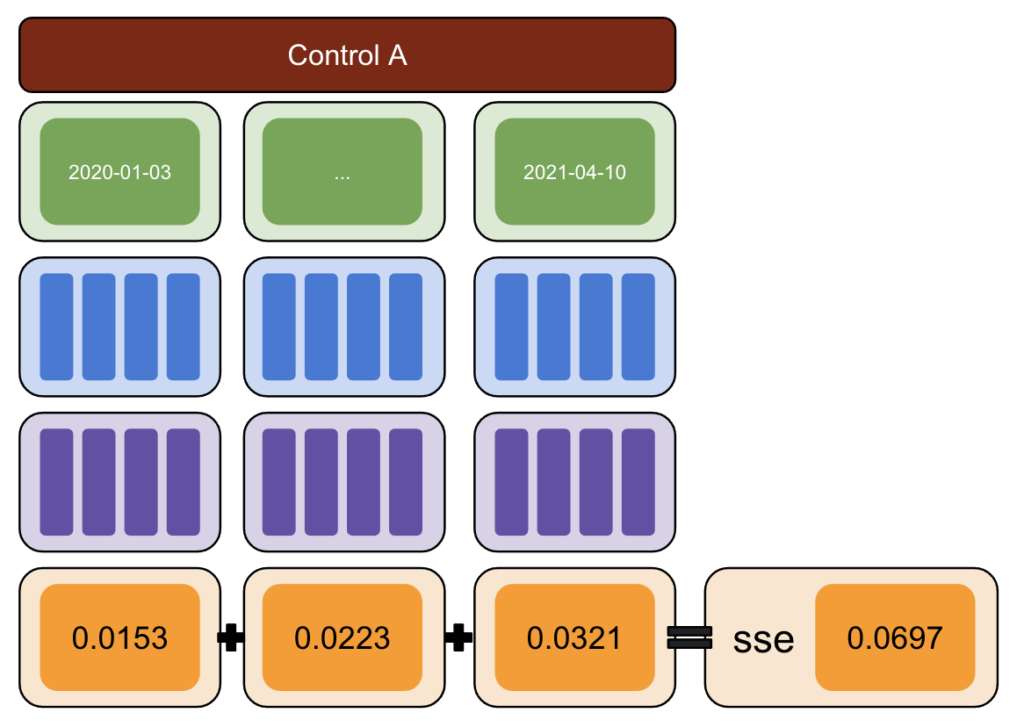
Encore une fois, répétez avec plusieurs groupes de contrôle.
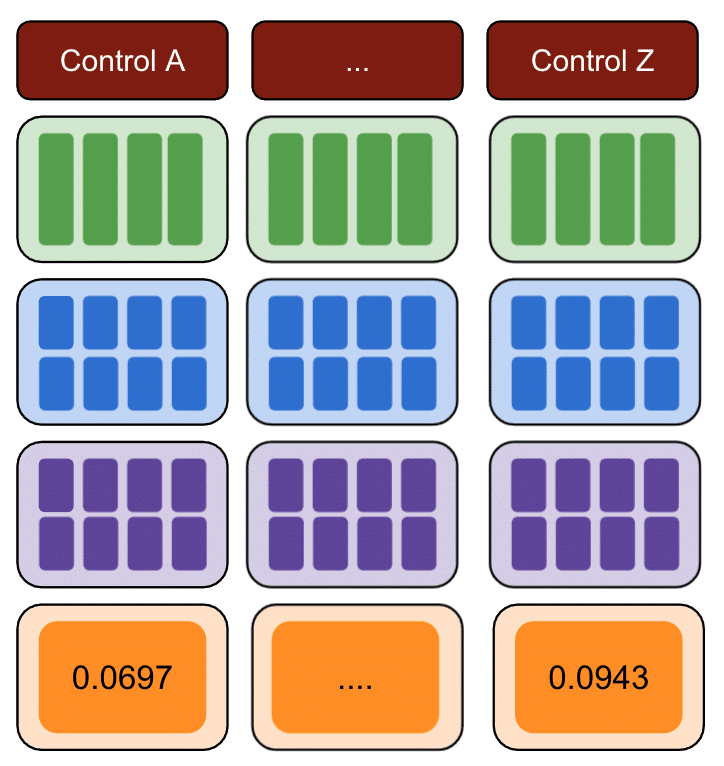
Enfin, le contrôle avec la plus petite somme d'erreurs au carré est le meilleur groupe de contrôle à utiliser pour vos données de test.
Si vous répétez chacune des étapes pour chacune de vos données de test, le résultat variera.
Sur le tableau résultant, chaque ligne représente un groupe de contrôle, chaque colonne représente un groupe de test. Les données à l'intérieur sont le SSE.
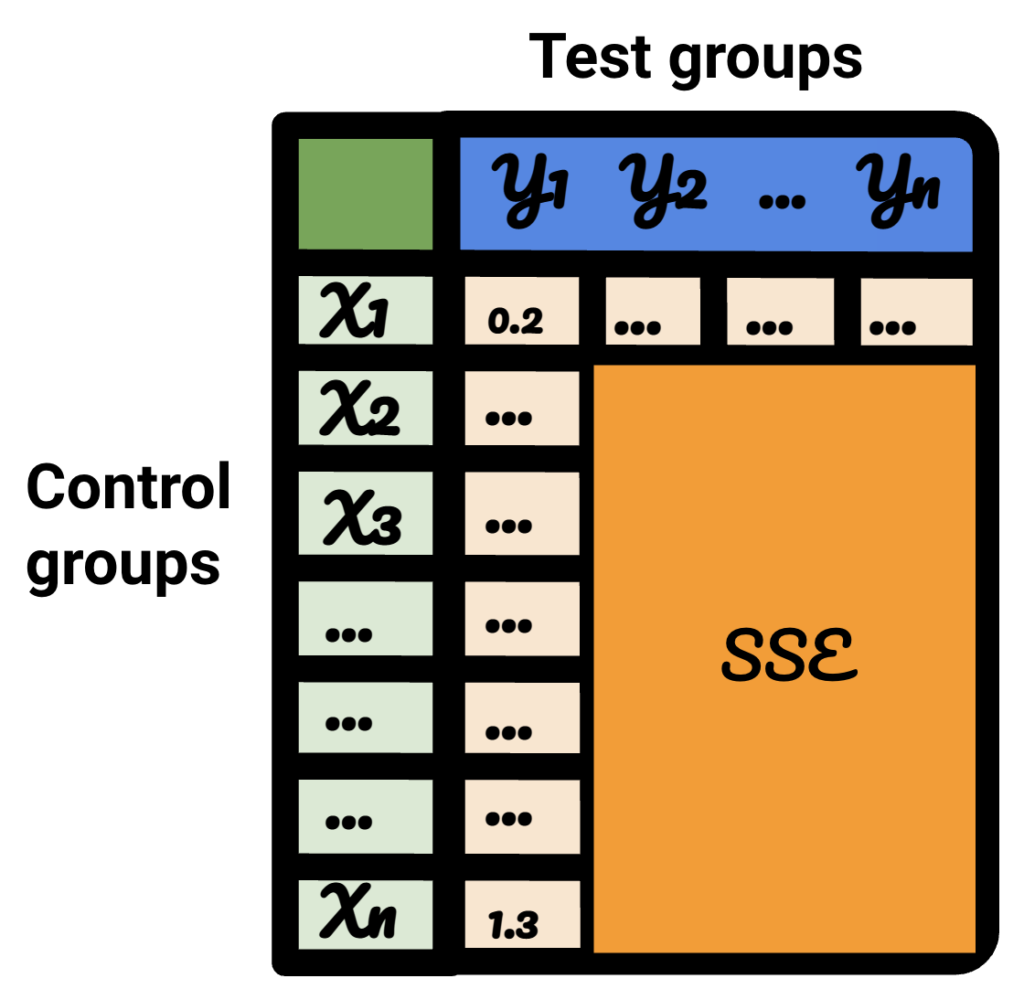
En triant ce tableau, je suis maintenant convaincu que, pour chacun des groupes de test, je peux sélectionner le meilleur groupe de contrôle pour celui-ci.
Devrions-nous utiliser des groupes de contrôle ou non ?
Les preuves montrent que l'utilisation de groupes de contrôle permet d'avoir de meilleures estimations qu'un simple pré-post.
Cependant, cela n'est vrai que si nous choisissons le bon groupe de contrôle.
Quelle devrait être la durée de la période d'estimation ?
La réponse à cette question dépend des contrôles que nous sélectionnons.
Lorsque vous n'utilisez pas de contrôle, une expérience préalable de 16 mois semble suffisante.
Lors de l'utilisation d'un contrôle, l'utilisation de seulement 16 mois peut entraîner des taux d'erreur massifs. L'utilisation de 3 ans permet de réduire le risque d'interprétation erronée.
Devrions-nous utiliser 1 contrôle ou plusieurs contrôles ?
La réponse à cette question dépend des données de test.
Des données de test très stables peuvent donner de bons résultats lorsqu'elles sont comparées à plusieurs contrôles. Dans ce cas, c'est bien car utiliser beaucoup de contrôle rend le modèle moins impacté par des fluctuations insoupçonnées de l'un des contrôles.
Sur d'autres ensembles de données, l'utilisation de plusieurs contrôles peut rendre le modèle 10 à 20 fois moins précis que l'utilisation d'un seul.
Travail intéressant dans la communauté SEO
CausalImpact n'est pas la seule bibliothèque qui peut être utilisée pour les tests SEO, et la méthodologie ci-dessus n'est pas non plus la seule solution pour tester sa précision.
Pour découvrir des solutions alternatives, lisez quelques-uns des articles incroyables partagés par les membres de la communauté SEO.
Tout d'abord, Andrea Volpini a écrit un article intéressant sur la mesure de l'efficacité du référencement à l'aide de CausalImpact Analysis.
Ensuite, Daniel Heredia a couvert le package Prophet de Facebook pour prévoir le trafic SEO avec Prophet et Python.
Bien que la bibliothèque Prophet soit plus appropriée pour les prévisions que pour les expériences, il vaut la peine d'apprendre diverses bibliothèques pour acquérir une solide compréhension du monde des prédictions.
Enfin, j'ai été très heureux de la présentation de Sandy Lee à Brighton SEO où il a partagé des idées sur la science des données pour les tests SEO et a soulevé certains des pièges des tests SEO.
Choses à considérer lors des expériences de référencement
- Les outils tiers de test fractionné SEO sont excellents mais peuvent également être inexacts. Soyez minutieux lors du choix de votre solution.
- Bien que j'aie écrit à ce sujet dans le passé, vous ne pouvez pas faire d'expériences de test fractionné SEO avec Google Tag Manager, sauf côté serveur. Le meilleur moyen est de déployer via des CDN.
- Soyez audacieux lors des tests. Les petits changements ne sont généralement pas captés par CausalImpact.
- Les tests SEO ne devraient pas toujours être votre premier choix.
- Il existe des alternatives pour tester des changements plus petits comme les balises de titre. Tests A/B Google Ads ou tests A/B sur plateforme. Les vrais tests A/B sont plus précis que les tests fractionnés SEO et fournissent généralement plus d'informations sur la qualité de vos titres.
Résultats reproductibles
Dans ce didacticiel, je voulais me concentrer sur la façon dont on pouvait améliorer la précision des expériences de référencement sans avoir à savoir coder. De plus, la source des données peut varier et chaque site est différent.
Par conséquent, le code Python que j'ai utilisé pour produire ce contenu ne faisait pas partie de la portée de cet article.
Cependant, avec la logique, vous pouvez reproduire les expériences ci-dessus.
Conclusion
Si vous n'aviez qu'un seul point à retenir de cet article, ce serait que l'analyse CausalImpact peut être très précise, mais peut toujours être très éloignée.
Il est très important pour les référenceurs souhaitant utiliser ce package de comprendre à quoi ils ont affaire. Le résultat de mon propre voyage est que je ne ferais pas confiance à CausalImpact sans tester d'abord la précision du modèle sur les données d'entrée.