
Crawl over Crawl maintenant disponible
Publié: 2019-11-21Notre fonctionnalité Crawl over Crawl vous permet de comparer deux crawls différents et affiche les évolutions de crawl .
En 2016, il s'appuyait sur notre précédente version sur les "Tendances" qui vous donnait l'opportunité de repérer les tendances mondiales entre différents crawls. Vous pouvez désormais accéder à des vues complètes de vos améliorations SEO et mettre en évidence les différences entre les crawls sur un thème donné . La mise à jour Crawl over Crawl incluait de nouveaux types de graphiques pour lire vos données.
En 2019, la fonctionnalité Crawl over Crawl s'est améliorée. Vous pouvez maintenant examiner :
- Deux versions d'un site Web contenant des pages identiques ou similaires, telles que des sites Web de production et de développement, ou des versions mobiles et de bureau .
- Le même site Web à deux moments différents, par exemple avant et après un changement sur le site.
Comparer deux versions d'un site Web
Pour comparer deux sites Web, OnCrawl regarde l'URL de démarrage que vous fournissez pour deux crawls différents afin de déterminer les différences dans les adresses Web des différents sites. Il suppose que ces deux versions du site Web contiennent le même (ou presque le même) contenu. Cela signifie que la majorité des slugs des URL des deux domaines, dossiers ou sous-domaines que vous comparez doivent être identiques .
Voici quelques exemples de sites qui peuvent être comparés :
| Cas d'utilisation | Explorer 1 – URL de démarrage | Explorer 2 – URL de démarrage |
|---|---|---|
| Sites de production vs sites intermédiaires | https://www.exemple.com | http://staging.example.com/site/ |
| Sites de bureau vs sites mobiles | https://www.exemple.com | https://m.exemple.com |
| Versions régionales | https://www.example.com/en-us/ | https://www.example.com/en-ca/ |
| Versions régionales | https://www.exemple.com | https://www.example.co.uk |
Pour les différences complexes entre les URL de démarrage, la correspondance automatique peut ne pas suffire. Si tel est le cas, vous verrez une erreur lors de la configuration de votre crawl qui vous demandera de contacter OnCrawl via le chat. Nous sommes en mesure de passer outre la mise en correspondance automatique afin de nous adapter à votre cas spécifique.
Comparer un site Web à deux moments différents dans le temps
Pour comparer un site Web à deux moments différents, par exemple avant et après une amélioration ou un changement majeur sur le site Web, vous devrez fournir :
- Les mêmes URL de démarrage
- La même étendue de crawl (les mêmes règles d'exploration de sous-domaine)
Comment mettre en place un Crawl over Crawl
Vous pouvez lancer un Crawl over Crawl entre deux crawls existants, ou demander la comparaison avec un crawl précédent lors de la création d'un nouveau. Vous trouverez plus d'informations sur la création de Crawl over Crawls dans la Base de connaissances d'OnCrawl.
Comment lire un Crawl over Crawl sunburst
Vous lisez un rayon de soleil comme une tarte traditionnelle. Ces graphiques sont très utiles pour suivre l'évolution d'un site web , crawl après crawl ou pour vérifier les différences entre deux versions d'un site web (entre une version live et lors d'une restructuration par exemple).
Ce camembert multi-niveaux permet de comparer deux crawls selon une thématique donnée :
- Le premier niveau et cercle intérieur : affiche les pages appartenant au premier crawl (le plus ancien).
- Le second niveau et cercle extérieur : affiche les pages du second crawl (le plus récent) qui correspondent à chaque segment du cercle intérieur.
Ainsi vous pourrez facilement retrouver, par exemple, des pages indexables dans le premier crawl qui ne le sont plus dans le second et inversement.
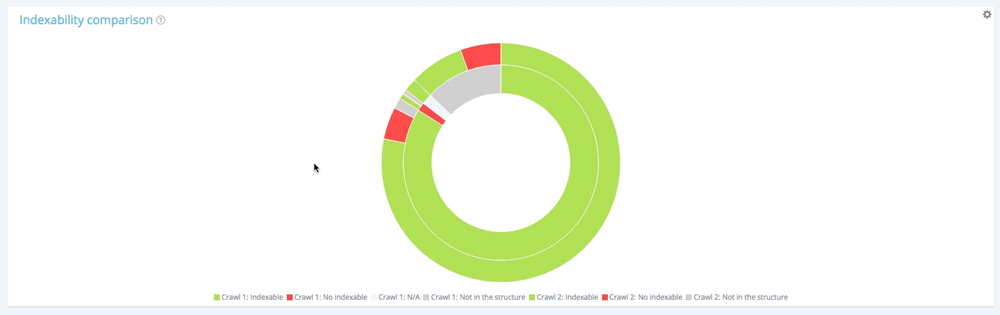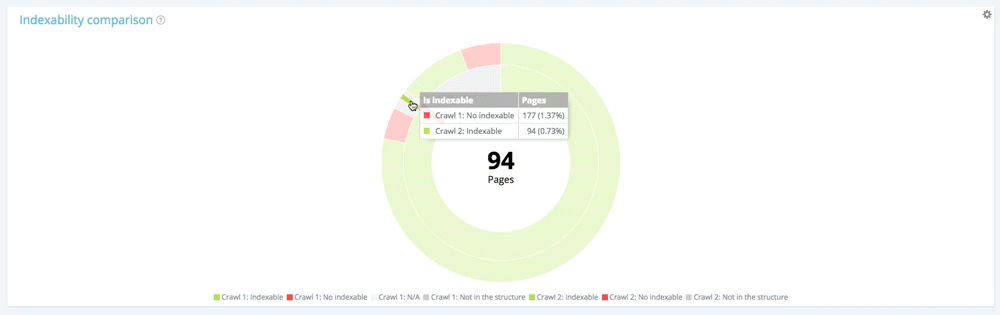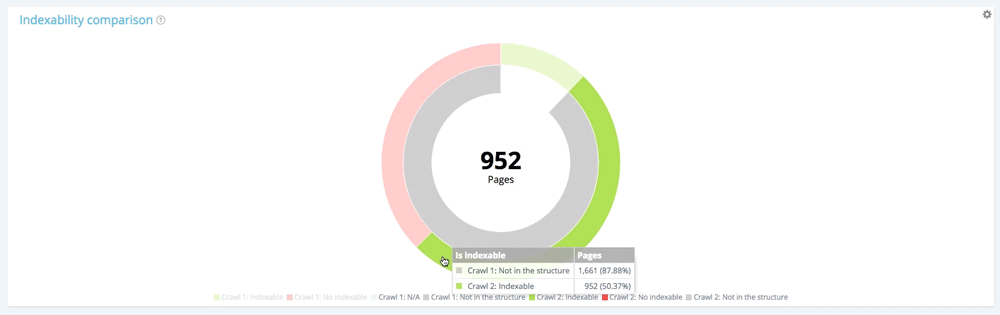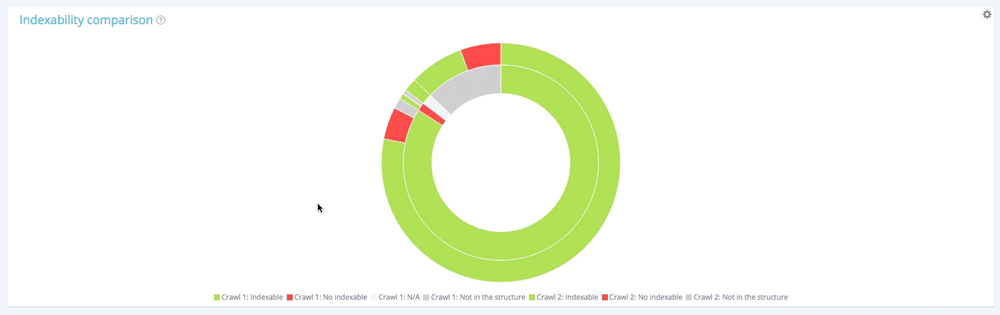
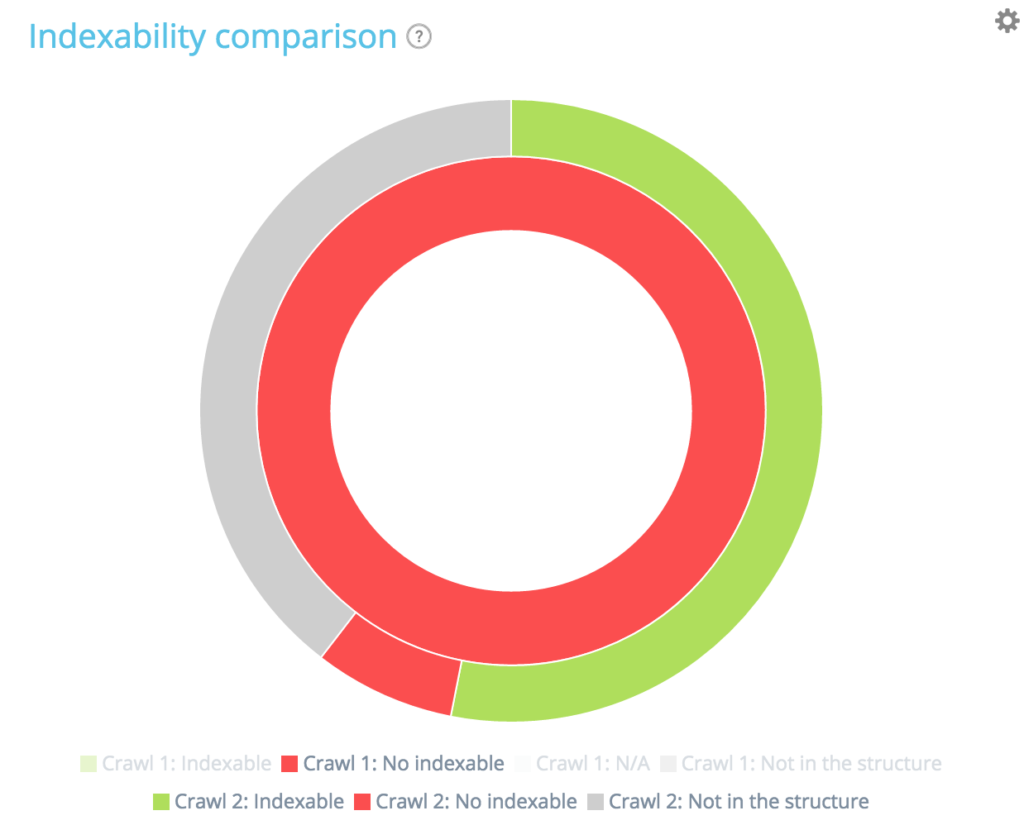
Dans ce graphique, le cercle intérieur montre la répartition des pages du premier point de vue du crawl (le plus ancien). Vous pouvez voir qu'il y a des pages indexables, pas de pages indexables et des pages qui n'étaient pas dans le premier crawl mais qui apparaissent dans le second (la section grise).
Ensuite, pour chaque section du cercle intérieur, vous pouvez voir la répartition des pages d'une section donnée dans le second crawl. La section intérieure grise signifie que ces pages n'existaient pas dans le premier crawl mais apparaissent dans le second (la section extérieure verte et rouge appartenant à la section intérieure grise).

Les sections grises signifient que les pages sont nouvelles ou non existantes dans la structure en fonction du cercle auquel elles appartiennent.
En cliquant sur la légende, vous pouvez décider des données que vous souhaitez afficher ou sur lesquelles vous souhaitez vous concentrer. Crawl 2 offre une vue plus globale.
Jetons un coup d'œil au cercle intérieur.
La répartition des pages dans le premier crawl en fonction de leur indexabilité
 Le premier crawl contient 10 854 pages indexables et 177 pages non indexables. 1 661 pages n'ont été trouvées qu'au second crawl.
Le premier crawl contient 10 854 pages indexables et 177 pages non indexables. 1 661 pages n'ont été trouvées qu'au second crawl.
Jetez maintenant un coup d'œil au cercle extérieur. Pour chaque segment du premier cercle, on retrouve la répartition de ces pages dans le second crawl.
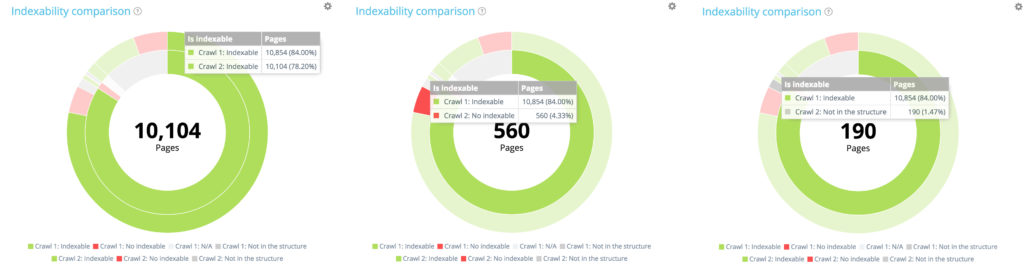
Parmi les 10 854 pages indexables au premier crawl, seules 10 104 sont encore indexables au second. 560 sont désormais non indexables et 190 pages ne faisaient plus partie du site crawlable au moment du second crawl.
Concentrons-nous sur une petite section : les pages non indexables au premier crawl
En utilisant la légende pour masquer les pages indexables et les pages non présentes dans la structure du site au moment du premier crawl, nous pouvons nous concentrer uniquement sur les pages non indexables lors du premier crawl.
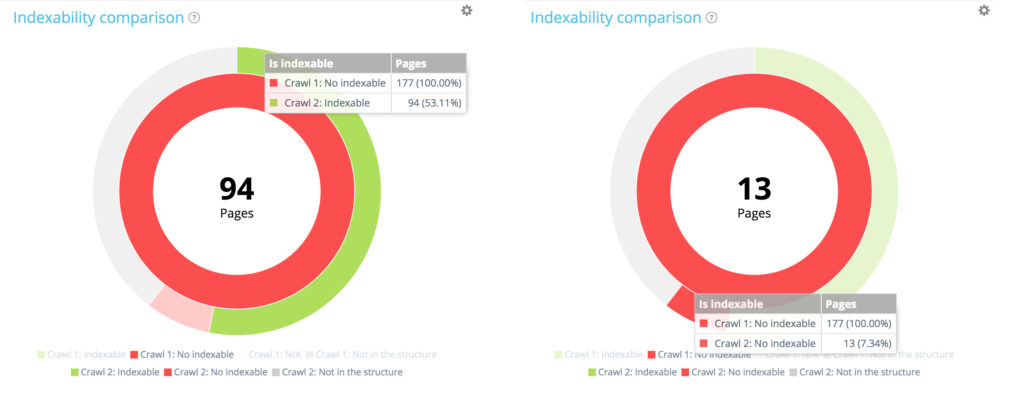 Parmi les 177 pages non indexables du premier crawl, 94 sont désormais indexables au second et 13 restent indexables.
Parmi les 177 pages non indexables du premier crawl, 94 sont désormais indexables au second et 13 restent indexables.
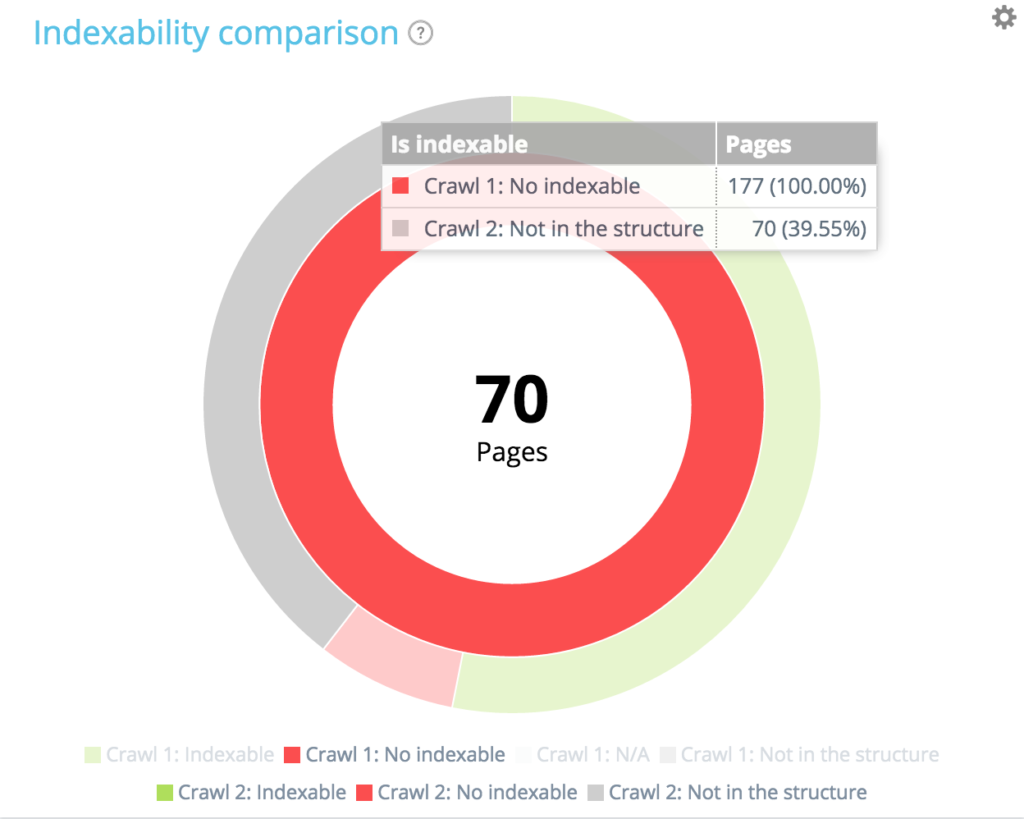
Sur les 177 pages non indexables au premier crawl, 70 ne sont plus présentes au second crawl. 94 + 13 + 70 = 177. On retrouve la répartition attendue des 177 pages non indexables dès le premier crawl.
Focus sur les nouvelles pages : pages trouvées uniquement lors du deuxième crawl
Utilisons maintenant la légende pour masquer les pages indexables et non indexables du premier crawl, et afficher uniquement les pages qui ne faisaient pas partie de la structure du site Web lors de ce crawl. Cela vous permet de voir l'état des nouvelles pages en termes d'indexation.
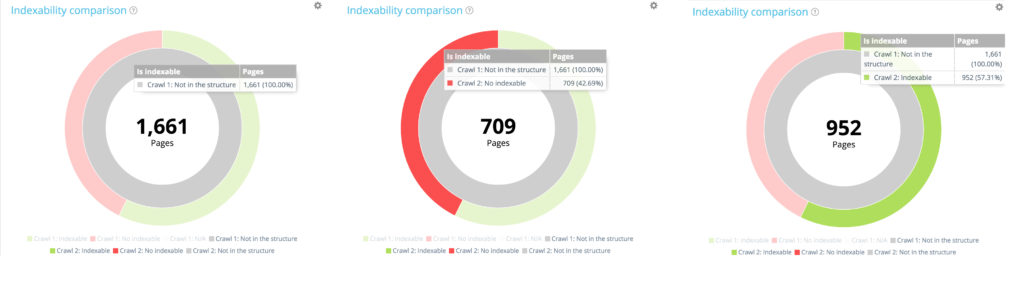
Toutes les nouvelles pages : 1 661 pages.
Sur les 1 661 pages nouvellement créées, 709 ne sont pas indexables.
Sur les 1661 pages nouvellement créées, 952 sont indexables.
Résumé : toutes les pages du deuxième crawl
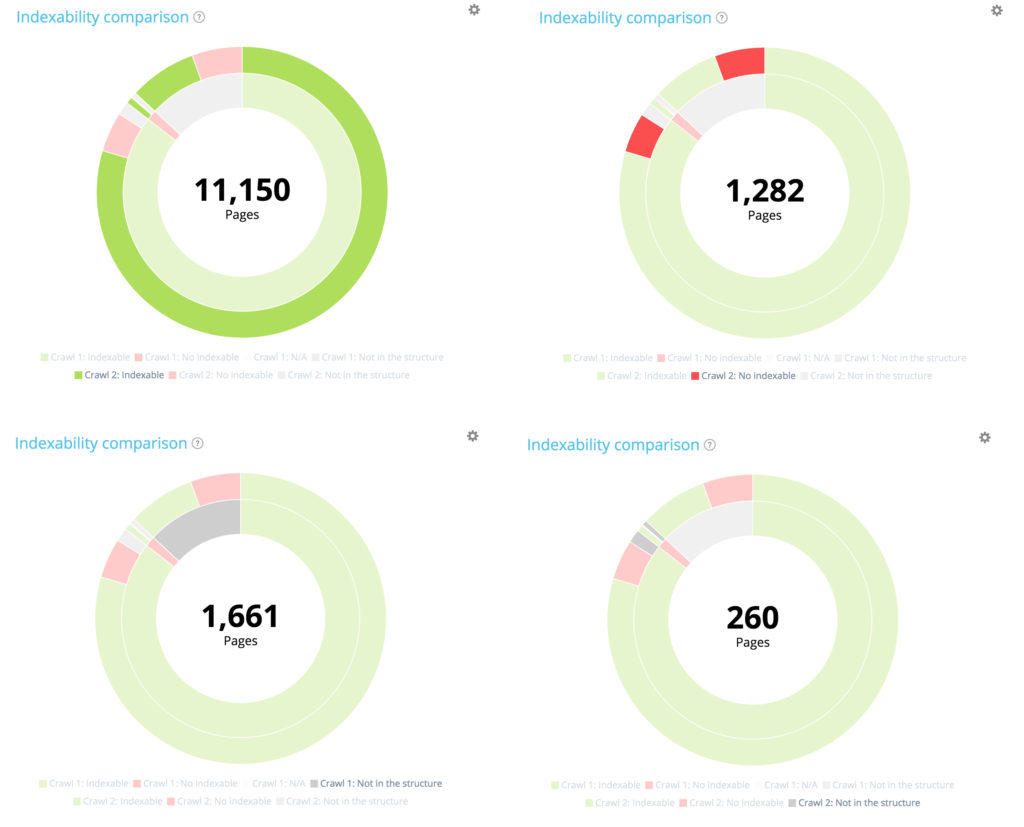 10 104 pages étaient indexables au premier crawl. 11 150 sont désormais indexables dans le second. 177 pages étaient non indexables au premier crawl mais 1 282 sont désormais non indexables au second.
10 104 pages étaient indexables au premier crawl. 11 150 sont désormais indexables dans le second. 177 pages étaient non indexables au premier crawl mais 1 282 sont désormais non indexables au second.
1661 pages ont été créées et 260 pages ont été supprimées de la structure.
Crawl over Crawl : données disponibles
Cette nouvelle fonctionnalité est répartie par expertises métiers et entre les onglets suivants :
- Structure
- Maillage interne
- Teneur
- Codes d'état
- Performance
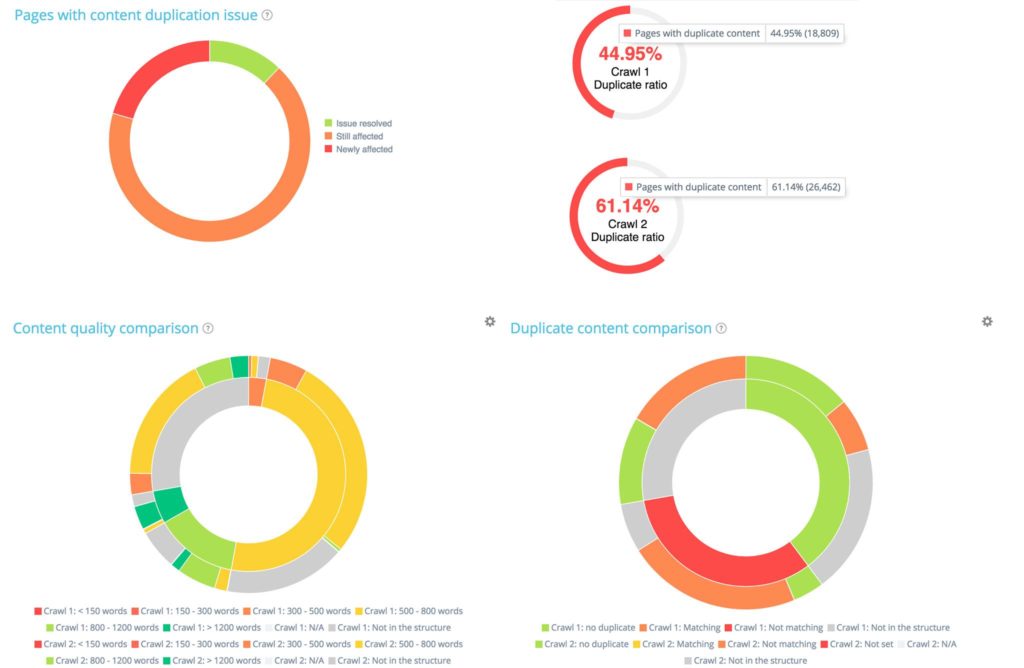
Par exemple, dans la section 'Contenu', vous trouverez un fort accent sur les différences de duplication entre les deux crawls :
De plus, vous pouvez analyser comment la profondeur de votre page diffère entre les deux crawls. Dans le graphique ci-dessous, vous pouvez voir les différences de profondeur :
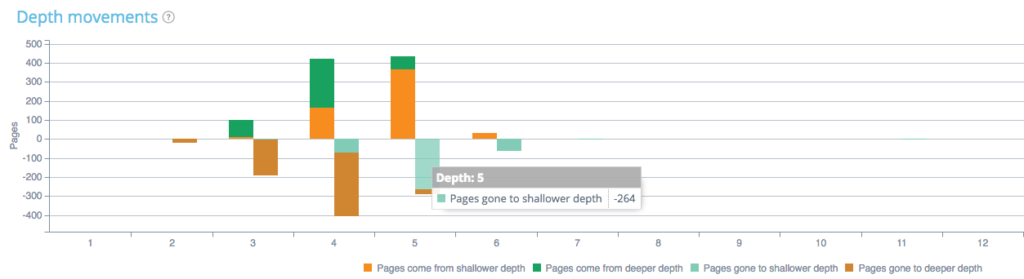
Par exemple, si nous regardons la profondeur 5, nous pouvons voir des pages qui sont allées à une profondeur moins profonde ou plus profonde ou des pages qui proviennent d'une profondeur moins profonde ou plus profonde entre le crawl 1 et 2. Ici, 264 pages qui étaient en crawl 1 et en profondeur 5 sont allés à une profondeur moindre (profondeur 4, 3 ou 2).
Ceci n'est qu'un aperçu de ce qui est disponible. Notre explorateur de données vous permet également d'explorer plus de 700 métriques pour les comparaisons de crawl.