
Comment automatiser la modélisation du marketing mix avec une feuille de calcul de flux de données MMM
Publié: 2022-06-16La modélisation du marketing mix ou MMM connaît une renaissance, plus de 60 ans après sa généralisation. Contrairement à la plupart des méthodes d'attribution marketing, MMM ne nécessite pas de données au niveau de l'utilisateur, au lieu de modéliser les canaux qui méritent un crédit pour les ventes en cartographiant statistiquement les pics et les baisses de dépenses aux actions et événements de vos canaux marketing. Passant de la simple régression linéaire à des techniques telles que la régression ridge ou les méthodes bayésiennes, la modélisation du mix marketing est en train d'être réinventée pour l'ère moderne.

Vous voulez en savoir plus sur MMM ?
Lisez les avantages et les inconvénients de la modélisation du mix marketing par rapport à la modélisation d'attribution
Cependant, il y a des obstacles majeurs à surmonter. La construction d'un modèle peut prendre de 3 à 6 mois, selon Meta/Facebook, qui travaille sur sa bibliothèque MMM open source depuis octobre 2021. Selon ses estimations, environ 50 % du temps est consacré à la collecte et au nettoyage des données avant le début de la modélisation. . Cela correspond à mon expérience chez Recast – et précédemment à celle de Harry – ainsi qu'aux résultats d'une étude CrowdFlower qui a révélé que 60 % du temps consacré à la science des données est consacré au nettoyage et à l'organisation des données.
Avance rapide >>
- Nettoyage des données
- Construire un modèle de mix marketing
- Modélisation automatisée
Le nettoyage des données représente 60 % du travail, et comment le rendre 0 %
Pour construire un modèle précis, vous avez besoin de vos données dans un format spécifique. La préparation des données prend du temps, les projets MMM prennent donc plus de temps que nécessaire. Cela fait du MMM une compétence spécialisée et coûteuse, de sorte que la plupart des entreprises ne peuvent construire qu'un à deux modèles par an. Si vous pouvez automatiser le processus à l'aide d'un outil comme Supermetrics pour créer un flux de données MMM, vous pouvez mettre à jour votre modèle régulièrement, ce qui vous permet de mieux optimiser votre budget marketing.
Format de données tabulaire
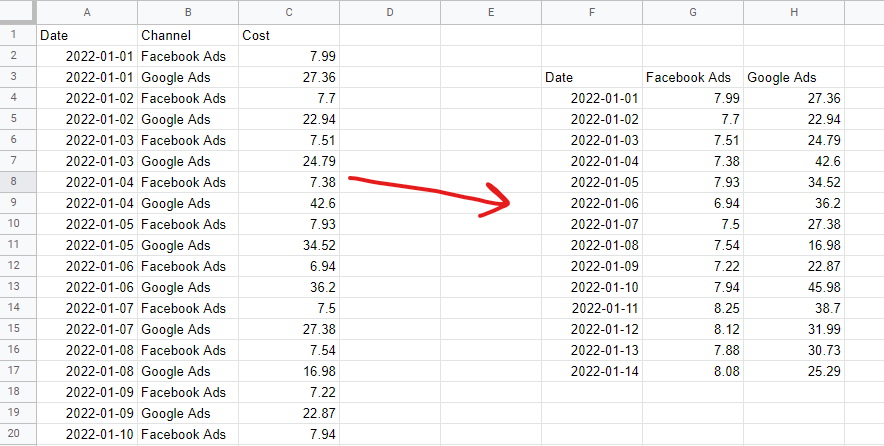
Pour créer un modèle de mix marketing, vos données doivent être présentées dans un format tabulaire non empilé. Cela signifie une ligne par observation (généralement des jours ou des semaines) et une colonne par "fonctionnalité" du modèle (généralement des dépenses médiatiques et des variables organiques ou externes). Les données catégorielles (par exemple, une liste de jours fériés nationaux) doivent être encodées dans des variables factices : 1 lorsqu'il s'agit de ce jour férié, 0 lorsqu'il ne l'est pas.
Sources de données jointes
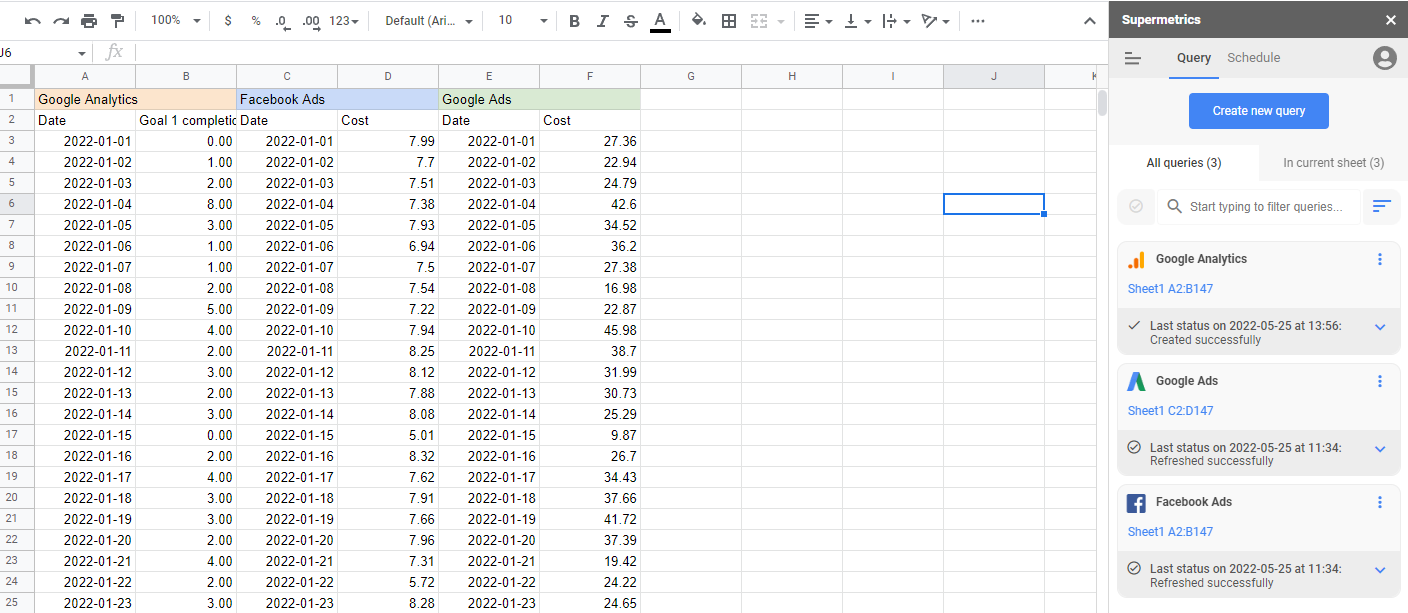
Pour créer un modèle d'attribution marketing, vous devez disposer de toutes vos données marketing au même endroit. C'est ce que Supermetrics gère automatiquement pour vous. Avec plus de 90 connecteurs, toutes vos dépenses, événements et activités marketing peuvent être regroupés en un seul endroit, manipulés selon les besoins, puis exportés au format et à l'emplacement dont vous avez besoin.
Exportation vers Google Sheets
Une fois que vous avez un compte Supermetrics, il vous suffit d'aller dans Extensions > Modules complémentaires > Obtenir des modules complémentaires et de l'installer. Il vous demandera de vous authentifier avec votre compte Google lié à votre compte Supermetrics, puis la barre latérale apparaîtra dans le menu des extensions.
Une fois cela fait, vous pouvez lancer la barre latérale - si ce n'est pas déjà fait - et cliquer pour créer une nouvelle requête. Les requêtes vous permettent de décider quelles données extraire et de quels comptes. Lorsque vous sélectionnez l'une des plateformes publicitaires telles que Facebook Ads et Google Ads, vous êtes invité à vous authentifier et à accorder l'accès à Supermetrics.
Ensuite, vous choisirez le compte dont vous souhaitez extraire les données et la plage de dates. Enfin, choisissez vos statistiques (généralement le coût ou les impressions pour MMM) et les dimensions (sélectionnez uniquement la date pour être cohérent avec le format tabulaire).
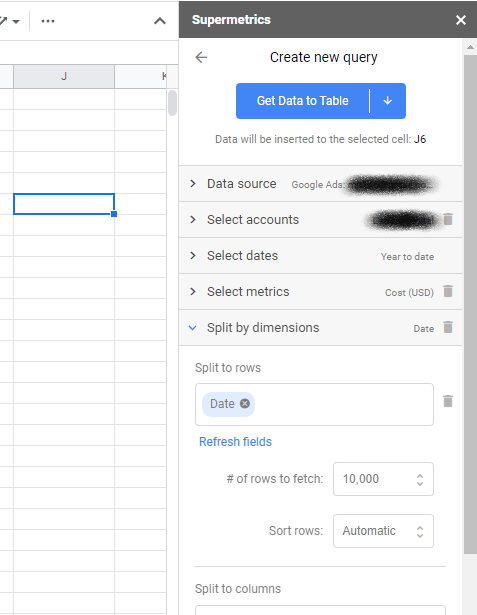
Si vous le souhaitez, vous pouvez ajouter un filtre si vous devez sélectionner un ensemble spécifique de campagnes. Par exemple, si vous aviez " YT : " dans le nom de vos campagnes YouTube, vous souhaiterez peut-être les sélectionner en tant que source distincte, puis dupliquer la requête et le filtre pour chacun de vos autres types de campagne.
Lorsque vous avez terminé votre requête, assurez-vous d'avoir sélectionné la cellule dans laquelle vous souhaitez extraire les données, puis cliquez sur "Get Data to Table". Si vous faites une erreur, dupliquez simplement la requête et placez-la au bon endroit, en supprimant l'autre.
Je trouve utile de mettre le nom de chaque source dans une cellule au-dessus du tableau afin de savoir d'où je tire les données. Le résultat devrait ressembler à ceci :
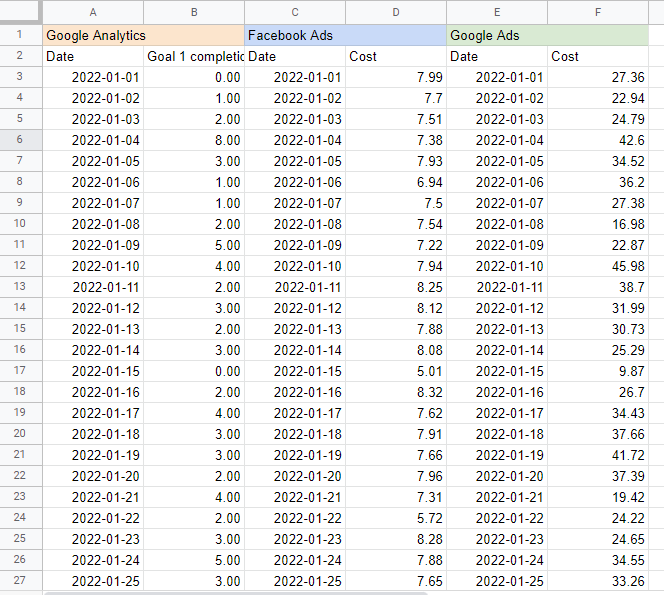
Construire un modèle de marketing mix dans Google Sheets
La modélisation du marketing mix est un puissant outil d'attribution, mais il est en fait plus accessible que vous ne le pensez. La plupart des praticiens utilisent un code personnalisé et des statistiques avancées, mais vous pouvez faire les bases en un après-midi avec rien de plus qu'Excel ou Google Sheets.
Régression linéaire avec la fonction DROITEREG
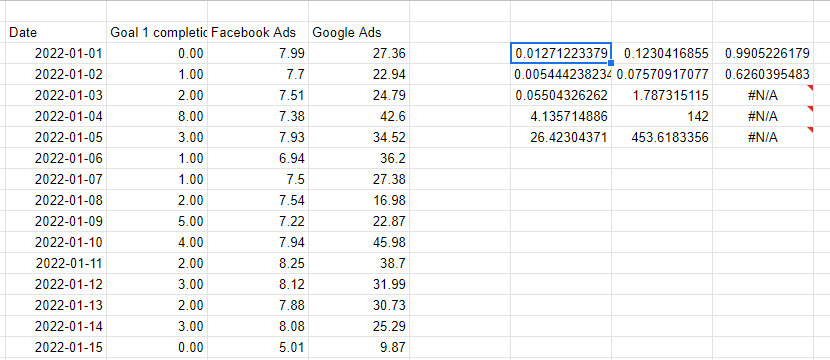
Excel et Google Sheets fournissent tous deux une méthode simple, la fonction DROITEREG, pour effectuer une régression linéaire multivariable. LINEST fonctionne en passant la colonne que nous essayons de prédire, puis plusieurs colonnes représentant les variables que nous utilisons pour faire la prédiction. Les deux derniers paramètres sont si nous voulons une ligne d'interception - généralement 1 pour oui - et si nous voulons que la sortie soit détaillée - contenant toutes les statistiques du modèle, pas seulement les coefficients.
Notez que les variables X que nous utilisons pour faire la prédiction doivent être consécutives, donc j'ai juste référencé les colonnes de gauche pour répéter les valeurs les unes à côté des autres.
Re-prévision avec les coefficients du modèle
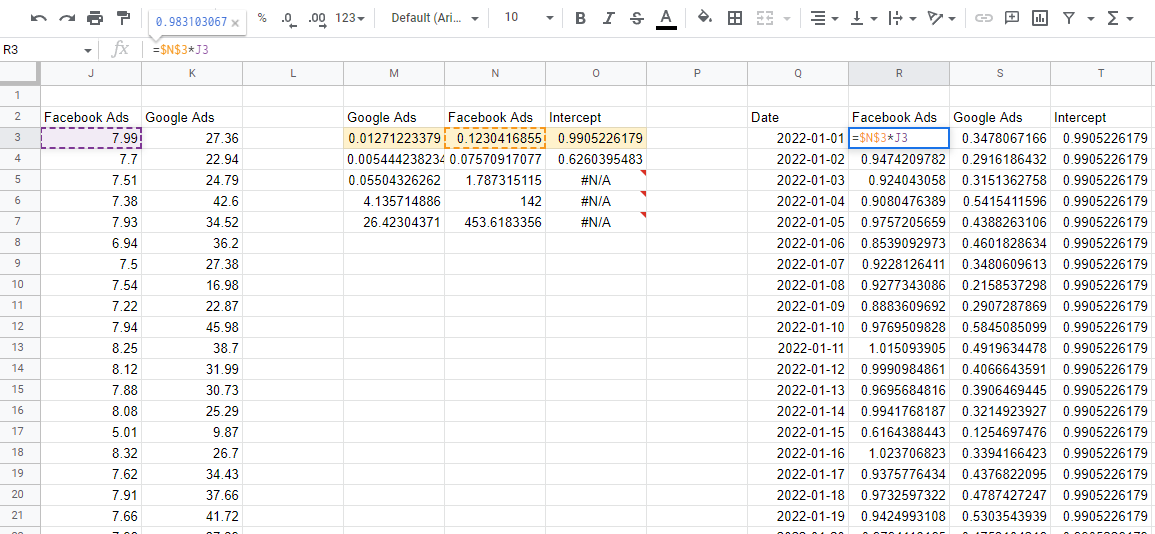
Maintenant que nous avons un modèle, nous devons utiliser les coefficients pour estimer l'impact de chaque canal. Si nous prenons la rangée supérieure de nombres, ce sont les coefficients, et que nous les multiplions par les valeurs d'entrée correspondantes de nos données, nous obtiendrons la contribution de chaque variable aux ventes totales.

Une chose à surveiller est que LINEST génère les coefficients à l'envers. La première valeur en partant de la gauche est toujours la dernière variable saisie, puis elles continuent dans l'ordre inverse jusqu'à ce que vous arriviez à la dernière valeur, qui est l'interception. Si vous additionnez toutes ces valeurs de contribution, cela vous donne les prédictions du modèle, que vous pouvez comparer aux valeurs réelles pour vous assurer que le modèle est précis.
Vérification des mesures de précision du modèle
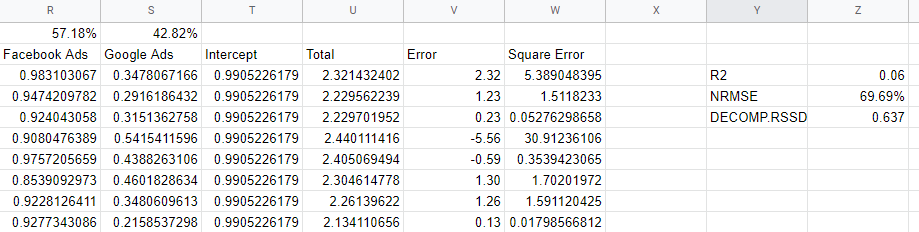
Comment savoir si notre modèle est fiable ? Le modèle doit bien s'adapter aux données, il doit être capable de prédire de nouvelles données qu'il n'a pas vues et il doit avoir des coefficients plausibles. Plusieurs métriques de validation capturent ces exigences.
Vérifiez les fonctions du modèle pour savoir comment calculer ces métriques.
Pour utiliser le modèle, allez dans 'Fichier' > 'Créer une copie' > 'Lancer Supermetrics' dans la liste des modules complémentaires > dupliquez ce fichier pour un autre compte, puis passez à la sélection du compte.
R2 ou R-Squared est une mesure de la part de variance dans les données expliquée par le modèle, et elle est comprise entre 0 et 1 : un bon modèle serait supérieur à 0,7, mais tout ce qui approche 1 est probablement suspect. Près de 0, comme l'est notre modèle, est un signe que nous n'incluons pas suffisamment de variables dans notre modèle et que nous devons intégrer des éléments tels que les canaux organiques, les vacances et les facteurs macro-économiques.
L'« erreur quadratique moyenne normalisée » est la façon dont nous mesurons la précision, et elle est trouvée en prenant la différence entre les prédictions du modèle et les valeurs réelles, puis en trouvant la racine des valeurs au carré en pourcentage de la valeur réelle. Idéalement, cela se fait sur la base de données invisibles - un groupe exclu - mais dans notre modèle simple, nous avons simplement calculé l'erreur par rapport aux données de l'échantillon.
La procédure de racine et d'élévation au carré gère les valeurs négatives pour nous et agit pour pénaliser les très grosses erreurs. Cela peut être interprété comme le pourcentage du modèle est désactivé un jour donné, il s'agit donc d'une mesure utile et intuitive.
La plausibilité est un sujet important, et c'est généralement quelque chose sur lequel un analyste devrait avoir le dernier mot. Cependant, il est utile de disposer d'une métrique que vous pouvez calculer par programmation afin de comprendre dans quelle mesure le modèle s'écarte en termes de résultats par rapport à votre mix de canaux actuel.
Decomp RSSD est une métrique inventée par l'équipe Robyn de Facebook qui mesure la différence entre votre allocation de dépenses actuelle et les canaux qui ont généré les effets les plus importants, comme prévu par le modèle. Si le modèle indiquait que votre plus grand canal n'a pas généré autant de ventes, alors vous auriez un RSSD Decomp élevé.
Dans notre cas, nous avons une valeur élevée de 0,6 car le modèle donne trop de crédit à Facebook, ce qui représente une petite quantité de dépenses.
Délivrer des MMM automatiquement et à grande échelle
La modélisation du marketing mix fait partie de ces activités évolutives à l'infini. Vous pouvez obtenir des résultats décents en un après-midi avec Excel ou Google Sheets et Supermetrics, comme nous l'avons fait ici, mais vous pouvez également passer 3 mois avec une équipe de 6 scientifiques des données écrivant du code personnalisé avec des algorithmes sophistiqués comme Bayesian MCMC pour construire quelque chose de plus robuste et précis.
Il existe une liste de contrôle des fonctionnalités qui entrent dans la construction d'un modèle avancé, dont certaines nécessitent des connaissances statistiques avancées. Ajoutez à cela plusieurs ingénieurs de données coûteux pour la création de pipelines de données si vous n'utilisez pas Supermetrics pour automatiser cette partie pour vous.
Vous voulez en savoir plus sur l'automatisation du mix de modélisation ?
Consultez notre article sur la modélisation automatisée du marketing mix
Soyez averti: MMM est difficile. Vous pourriez dépenser 500 $, 5 000 $ ou 50 000 $ en modélisation et voir des résultats extrêmement différents en termes de précision et de robustesse. Ce qui compte vraiment, c'est le coût d'opportunité d'une mauvaise répartition de vos dépenses marketing.
Si vous dépensez 10 000 $ par mois, un modèle de feuille de calcul une fois par trimestre conviendra. Cependant, si vous dépensez plus de 100 000 $ par mois, même une réduction de 5 % peut vous coûter des dizaines de milliers de dollars sur une année.
Vous ne savez pas de quel modèle d'accès aux données vous avez besoin pour votre flux MMM ?
Consultez notre article pour choisir celui qui convient à votre entreprise
C'est alors qu'il est logique d'investir dans une modélisation plus avancée. Effectuez une analyse de la construction par rapport à l'achat pour décider entre une solution personnalisée basée sur des bibliothèques open source comme Robyn de Facebook ou un logiciel d'attribution avancé comme celui que nous avons construit chez Recast.
A propos de l'auteur
Michael Kaminsky est un économètre de formation avec une formation en économie de la santé et de l'environnement. Il a précédemment construit l'équipe de science marketing de la marque de soins pour hommes Harry's avant de co-fonder Recast.

Améliorez les performances de votre entreprise
en combinant marketing et business intelligence dans votre entrepôt de données