
Renforcer la sécurité bancaire : apprentissage automatique pour la détection des fraudes
Publié: 2023-11-14Chaque opportunité s’accompagne d’une menace. Le passage à la numérisation dans le secteur bancaire a amélioré l’expérience client et élargi la clientèle à des populations auparavant non bancarisées. L’inconvénient était que les transactions en ligne et les solutions de paiement numérique ouvraient de nouvelles voies à exploiter pour les fraudeurs.
Les résultats d'une enquête sur la fraude de KMPG indiquent que les cyberattaques sont de plus en plus fréquentes et graves, entraînant des pertes de plusieurs milliards de dollars.
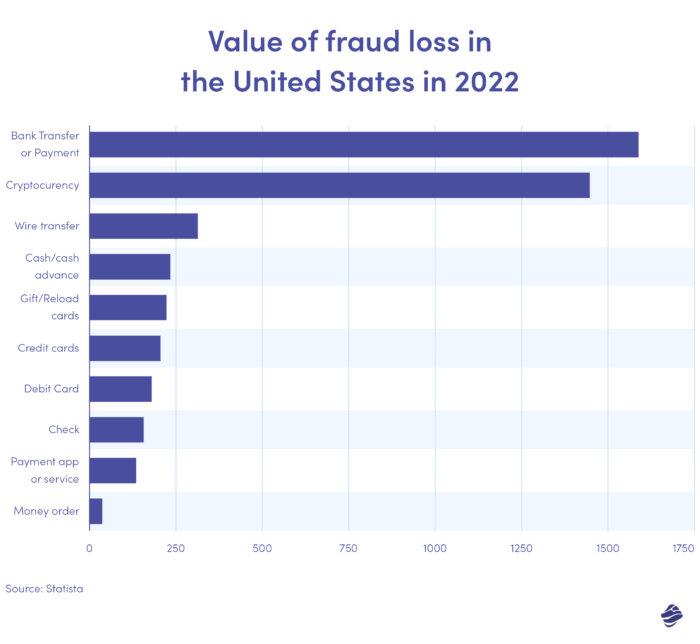
Le graphique ci-dessus illustre la valeur des pertes liées à la fraude par mode de paiement aux États-Unis en 2022. Les virements et paiements bancaires ont été les plus élevés, avec une perte de 1,59 milliard de dollars.
Ces pertes ont contraint les institutions bancaires à adopter de nouvelles solutions pour détecter, atténuer et prévenir la fraude financière. L’une de ces méthodes est l’intelligence artificielle (IA), plus précisément l’apprentissage automatique.
Dans cet article, nous aborderons tout ce que vous devez savoir sur l'apprentissage automatique pour la détection des fraudes , y compris les avantages et les applications réelles.
Evolution de la détection des fraudes
La détection traditionnelle des fraudes suit une approche basée sur des règles. Comme son nom l'indique, il fonctionne selon un ensemble de règles ou de conditions qui déterminent si une transaction est authentique ou frauduleuse. Les conditions courantes incluent le lieu (l'achat est-il en dehors de la zone habituelle de l'utilisateur ?) et la fréquence (le nombre et le type d'achat sont-ils habituels pour l'utilisateur ?).
Une transaction n’est conclue que lorsqu’elle remplit les conditions. Par exemple, un client de l'Ohio doit soudainement payer des frais de point de vente en Nouvelle-Zélande. L'emplacement se trouve en dehors de l'indicatif régional de l'utilisateur, le système signale donc les transactions comme frauduleuses.
Ce type de système de détection de fraude présente plusieurs inconvénients.
- Cela produit un nombre élevé de faux positifs. C'est ici que vous bloquez les paiements des véritables clients.
- C’est inflexible. L’approche basée sur des règles utilise des résultats fixes, ce qui rend difficile l’adaptation aux tendances de la banque numérique. Vous devez changer les règles pour détecter de nouvelles formes de fraude.
- Cela n’évolue pas. Lorsque les données augmentent, les efforts nécessaires pour les empêcher augmentent également. Toute modification apportée au système est effectuée manuellement, ce qui la rend coûteuse et prend du temps.
La détection des fraudes basée sur des règles fonctionne. Cependant, ses inconvénients le rendent inadapté aux environnements numériques modernes. Il ne peut pas reconnaître de modèles et s'appuie sur l'intervention humaine.
De plus, les pirates ne respectent pas un horaire de 9h à 17h et peuvent déployer des méthodes sophistiquées telles que l'usurpation de localisation et l'usurpation d'identité du comportement des clients pour tromper les systèmes de détection de fraude. Par conséquent, vous avez besoin d’un système tout aussi développé qui fonctionne 24h/24 et 7j/7.
Entrez dans l’apprentissage automatique.
L'apprentissage automatique est une intelligence artificielle (IA) qui utilise les données pour entraîner des algorithmes de détection de fraude afin de découvrir des modèles et des relations entre données, d'obtenir des informations et de faire des prédictions.
Vous êtes déjà familier avec le machine learning, même si vous ne le connaissez pas. Par exemple, chaque fois que vous interagissez avec une publication Instagram, vous fournissez à l'algorithme des informations sur le type de contenu que vous aimez. Il parcourt ensuite l'application à la recherche d'un contenu similaire à ajouter à votre flux.
Comment l’apprentissage automatique va transformer la détection des fraudes
La détection de la fraude dans le secteur bancaire à l'aide de l'apprentissage automatique est déjà en train de changer le secteur, avec une identification et une réponse plus rapides, plus flexibles et plus précises à la fraude.
Le système d'IA analyse les modèles de données client et modifie automatiquement les règles en fonction des menaces historiques et émergentes.
Vous vous souvenez des frais de point de vente néo-zélandais que nous avons mentionnés plus tôt ? La détection de fraude par machine learning considérerait que la même carte bancaire a effectué un achat pour un vol vers cet endroit. Le nouveau débit est donc très probablement légitime.
Deux modèles sont utilisés pour entraîner les algorithmes à détecter la fraude : l’apprentissage automatique supervisé et l’apprentissage automatique non supervisé.
Apprentissage automatique supervisé
Le modèle d’apprentissage supervisé alimente les algorithmes en grandes quantités de données étiquetées comme frauduleuses ou non. L'algorithme étudie ces exemples et apprend quels modèles et relations distinguent les transactions légitimes des transactions frauduleuses.
Ce modèle d'apprentissage prend du temps car il nécessite un marquage manuel des données. De plus, vos ensembles de données doivent être correctement étiquetés et bien organisés. Une transaction mal étiquetée affectera la précision de l’algorithme.
De plus, il n’apprend qu’à partir des entrées incluses dans l’ensemble de formation. Ainsi, les transactions via les fonctionnalités de votre application bancaire mobile nouvellement lancée qui ne faisaient pas partie des données historiques ne seraient pas signalées. Il existe désormais une faille que les fraudeurs peuvent exploiter.
Apprentissage automatique non supervisé
Le modèle d'apprentissage non supervisé utilise un minimum d'intervention humaine. L'algorithme apprend des modèles et des relations à partir de grandes quantités de données non balisées, regroupant des ensembles de données en fonction de similitudes et de différences.
L'objectif est de repérer les activités inhabituelles non incluses dans l'ensemble de données d'entraînement. Ainsi, l’apprentissage non supervisé reprend là où l’apprentissage supervisé s’arrête et détecte de nouvelles fraudes.
N'oubliez pas que vous n'avez pas à choisir entre un modèle d'apprentissage automatique supervisé ou non supervisé. Vous pouvez les utiliser ensemble (modèle d’apprentissage semi-supervisé) ou indépendamment.
Avantages de l'utilisation du ML pour la détection des fraudes
Nous avons fait allusion aux avantages de la détection des fraudes grâce à l'apprentissage automatique dans le secteur bancaire, mais discutons-en plus en détail.
- Vitesse
Les calculs d’apprentissage automatique s’effectuent rapidement et donnent des décisions en matière de fraude en temps réel. Même si les algorithmes basés sur des règles décident également en temps réel, ils s’appuient sur des règles écrites pour signaler la fraude.
Que se passe-t-il dans les nouveaux scénarios sans règles prédéfinies ? Cela conduit à des faux positifs ou à des faux négatifs.
L'apprentissage automatique détecte automatiquement les nouveaux modèles, analyse l'activité régulière des clients et calcule les résultats appropriés en quelques millisecondes.
- Précision
Les systèmes de détection basés sur des règles bloquent les transactions authentiques ou autorisent les transactions frauduleuses, car ils ne détectent pas les nuances du comportement des clients.
Les systèmes d'apprentissage automatique prennent en compte des variables au-delà des règles écrites, par exemple un comportement frauduleux connu. Ces variables aident à contextualiser la transaction, réduisant ainsi le taux de faux positifs.
- La flexibilité
L'apprentissage automatique est flexible et réactif. La capacité d'auto-apprentissage permet à ce système de s'adapter à de nouveaux scénarios et de détecter de nouvelles menaces. Les systèmes basés sur des règles sont rigides et n'ont pas de capacités d'apprentissage. Par conséquent, il ne peut répondre aux activités frauduleuses que selon des règles prédéfinies.
- Efficacité
Les algorithmes d’apprentissage automatique peuvent analyser des milliers de données de transaction par seconde. Au lieu de dépenser de la main d’œuvre et des frais généraux pour enquêter sur des cas de fraude faibles à modérés, l’apprentissage automatique peut traiter les fraudes répétitives ou claires. Il permet aux spécialistes de la fraude de se concentrer sur des modèles complexes qui nécessitent une expertise humaine.
- Évolutivité
L’augmentation du volume de données exerce une pression sur les systèmes basés sur des règles. Les nouvelles règles ajoutent à la complexité du système, le rendant difficile à maintenir. Toute erreur ou contradiction peut rendre l’ensemble du modèle inefficace.
Les systèmes d’apprentissage automatique sont à l’opposé. Non seulement ils assimilent de gros volumes de nouvelles données, mais ils s’améliorent également.
Techniques d'apprentissage automatique utilisées dans la détection des fraudes
Avant d'examiner les différents algorithmes utilisés dans la détection des fraudes par l'IA, examinons le fonctionnement du système.
La première étape est la saisie des données. La précision du modèle dépend du volume et de la qualité des données. Plus vous ajoutez de données de haute qualité, plus le modèle devient précis.
Ensuite, le modèle analyse les données et extrait les caractéristiques clés qui décrivent les comportements normaux par rapport aux comportements frauduleux. Ces fonctionnalités incluent l'identité du client (e-mail ou numéro de téléphone), l'emplacement (IP ou adresse de livraison), les méthodes de paiement (nom du titulaire de la carte et pays d'origine), etc.
La troisième étape consiste à entraîner l'algorithme (avec plus de données) à faire la distinction entre les transactions authentiques et frauduleuses. Le modèle reçoit un ensemble de données de formation et prédit la probabilité de fraude dans divers cas. Une fois l’algorithme suffisamment entraîné, vous êtes prêt à le lancer.
Voyons maintenant les différents algorithmes que vous pouvez utiliser.
1. Régression logistique
La régression logistique est un algorithme d'apprentissage supervisé. Il calcule la probabilité de fraude sur une échelle binaire – fraude ou non-fraude – en fonction des paramètres du modèle.
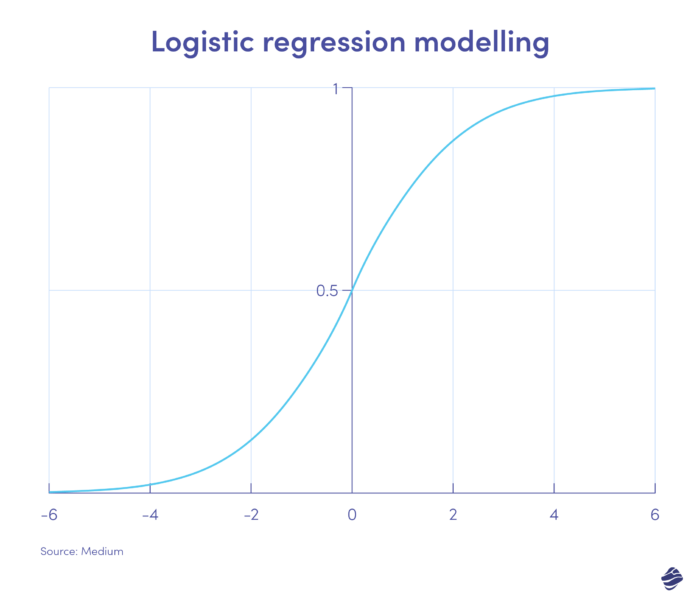
Les transactions qui se situent du côté positif du graphique sont très probablement frauduleuses, tandis que celles du côté négatif sont très probablement légitimes.
2. Arbre de décision
Un arbre de décision est un algorithme d’apprentissage supervisé mais va plus loin que les algorithmes de régression logistique. Il s'agit d'une structure de décision hiérarchique qui analyse les données par niveaux pour déterminer si une transaction est authentique ou frauduleuse.
Vous trouverez ci-dessous une illustration d’un arbre décisionnel pour la détection des fraudes par carte de crédit.
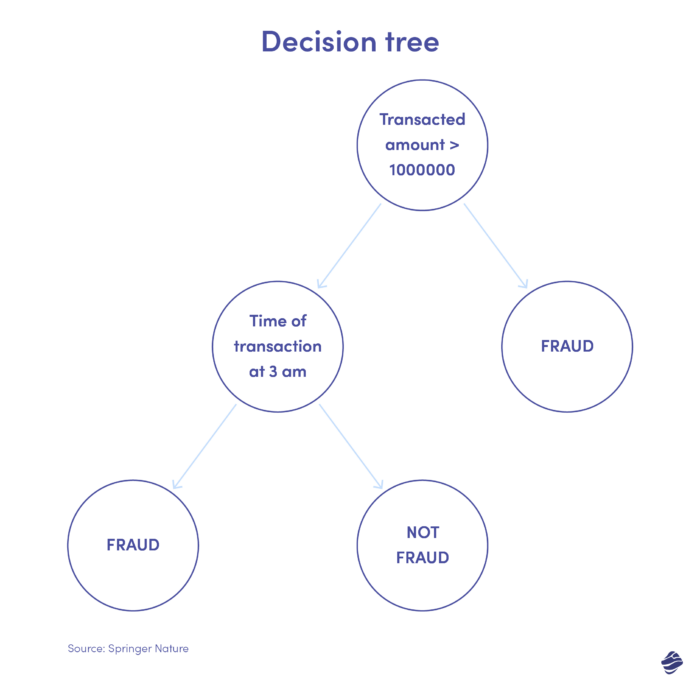
La condition permettant d'identifier si la transaction est frauduleuse est le montant de la transaction. Si la valeur de la transaction dépasse un seuil fixé, l'algorithme la considère comme frauduleuse. Sinon, l’arborescence vérifie une autre condition : l’heure de la transaction. Si le timing est inhabituel (ici, 3 heures du matin), il s'agit probablement d'une fraude. Sinon, il vérifie une autre condition. Cela continue.
3. Forêt aléatoire
La forêt aléatoire est une combinaison de nombreux arbres de décision, où chaque arbre de décision vérifie différentes conditions – identité, emplacement, etc.
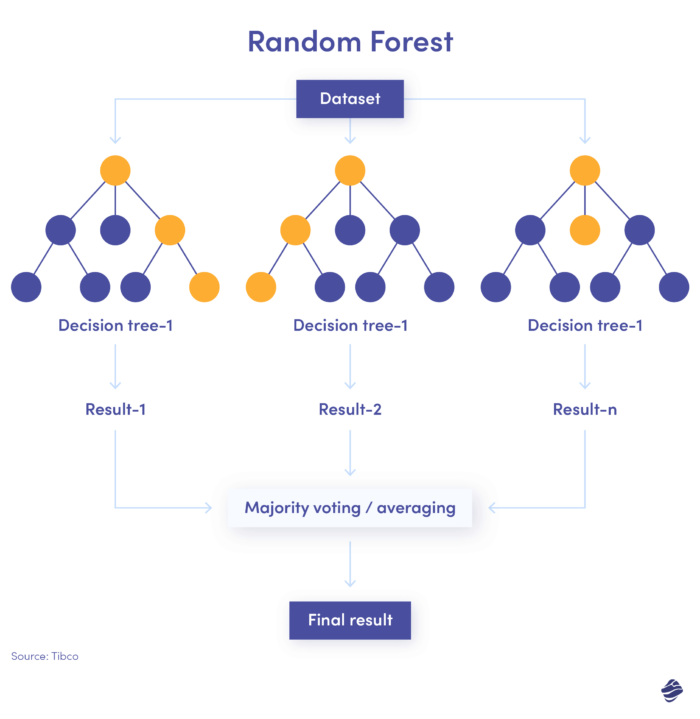
Après avoir vérifié tous les paramètres, chaque sous-arbre propose une décision. Le total combiné détermine si la transaction est authentique ou frauduleuse.
4. Réseaux de neurones
Les réseaux de neurones sont des algorithmes complexes et non supervisés. Inspirés du cerveau humain, les réseaux de neurones traitent les données sur plusieurs couches pour en extraire des fonctionnalités de haut niveau. Cet algorithme va de pair avec l’apprentissage profond, qui peut reconnaître des modèles dans les images, le texte, l’audio et d’autres données.

Voici une version simplifiée d'un réseau de neurones.
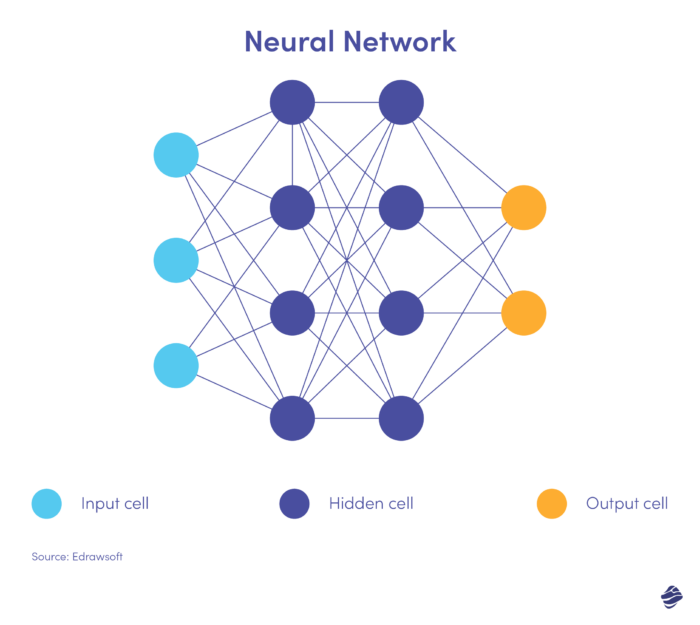
Un réseau de neurones comporte trois couches : entrée, cachée et sortie. La couche d'entrée traite les données, la couche cachée analyse les données de la couche d'entrée pour identifier les modèles cachés et la couche de sortie classe les données.
Les réseaux de neurones profonds comportent plusieurs couches cachées. Ils sont parfaits pour identifier les relations non linéaires et détecter des scénarios de fraude sans précédent.
5. Machine vectorielle de support
Les machines à vecteurs de support (SVM) sont des algorithmes d'apprentissage supervisé qui prédisent, classifient et détectent les valeurs aberrantes.
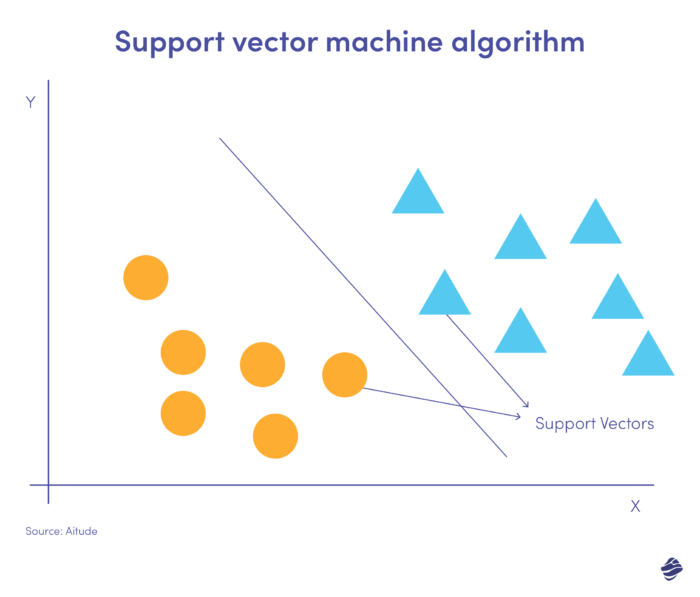
Cette illustration SVM linéaire montre deux ensembles de données séparés par une ligne droite appelée hyperplan. C'est la limite de décision qui classe les données comme étant frauduleuses ou non.
Les points de données plus éloignés de l'hyperplan sont facilement classés. Les vecteurs de support (les plus proches de l'hyperplan) sont difficiles à catégoriser. Ces valeurs aberrantes peuvent affecter la position de l'hyperplan si elles sont supprimées.
6. K-voisin le plus proche
Le K-plus proche voisin (KNN) est un algorithme d'apprentissage supervisé. Il part du principe que des éléments similaires existent à proximité les uns des autres.
Ci-dessous une illustration simple.
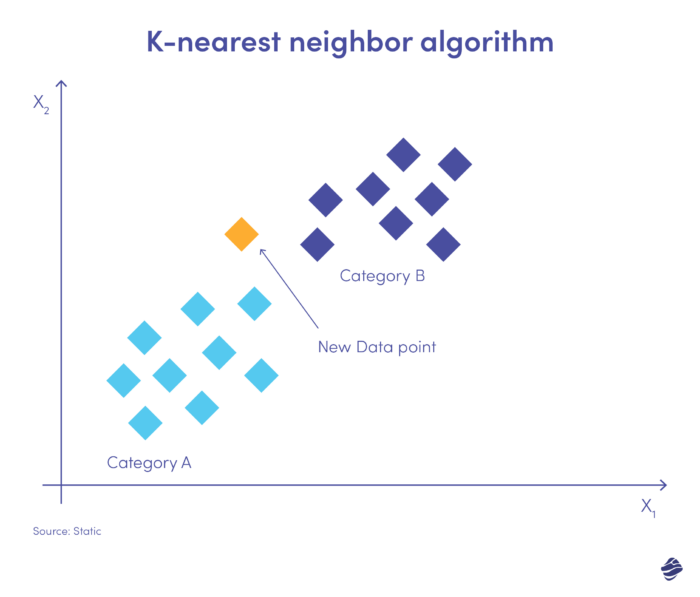
Les nouvelles saisies de données doivent être placées dans la catégorie A ou B. L'algorithme calcule la distance entre les points de données à l'aide d'une équation mathématique appelée distance euclidienne. Le nouveau point de données appartient au groupe comportant le plus de voisins. Si l'ensemble de données le plus proche est étiqueté « fraude », cette transaction est classée comme frauduleuse.
Faire face aux défis et aux considérations stratégiques
Comme toute technologie, l’intégration de l’apprentissage automatique pour la détection des fraudes pose de plus en plus de difficultés. Voici quelques défis courants auxquels vous pourriez être confronté.
Infrastructures inadéquates
De nombreux systèmes bancaires ne peuvent pas analyser de grandes quantités de données complexes. De plus, la plupart des données sont cloisonnées et hébergées dans des installations de stockage distinctes.
Malheureusement, il n’existe pas de solution miracle à ce problème. Vous devez investir dans le matériel et les logiciels appropriés.
Vous devrez vous associer à une agence de développement d'applications Fintech expérimentée et mettre en place une infrastructure pour sélectionner automatiquement les algorithmes appropriés pour des ensembles de données spécifiques, importer des données brutes et les préparer pour l'apprentissage automatique, visualiser les données, tester l'algorithme, etc.
Qualité et sécurité des données
La qualité des données est un problème important pour les institutions financières qui cherchent à mettre en œuvre l’apprentissage automatique pour détecter la fraude. Les modèles d’apprentissage automatique ne font pas la distinction entre les bonnes et les mauvaises données. Ainsi, si l’algorithme est entaché de données non pertinentes ou incomplètes, la précision de votre modèle sera incorrecte.
Les solutions d'ingestion de données comme Amazon Kinesis collectent, nettoient et transforment les données brutes, les rendant ainsi adaptées aux modèles d'apprentissage automatique. Une fois les données nettoyées et organisées, vous devez séparer les données sensibles et insensibles. Cryptez les informations confidentielles et stockez-les dans des installations sécurisées. Vous devez également limiter l'accès à ces données.
Manque de talent
Malgré ce que les gens craignent, l’apprentissage automatique ne vole pas d’emplois. C'est tout le contraire. Nous avons toujours besoin d’analystes de la fraude pour gérer les cas complexes qui nécessitent une vision et une expérience humaines. De plus, l’apprentissage automatique est une nouvelle technologie et il n’y a pas assez d’experts dans ce domaine.
C'est une bonne nouvelle pour les demandeurs d'emploi, mais pas pour les institutions qui ne peuvent pas exploiter tout le potentiel de l'apprentissage automatique. Vous pouvez surmonter ce ralentissement en vous associant à des entreprises possédant les compétences nécessaires pour mettre en œuvre l’apprentissage automatique.
Études de cas de détection de fraude dans le secteur bancaire grâce à l'apprentissage automatique
Examinons maintenant des exemples concrets de détection de fraude dans le secteur bancaire grâce à l'apprentissage automatique.
Détection de fraude
Danske Bank est une société financière multinationale danoise. Il s'agit de la plus grande banque du Danemark et d'une banque de détail leader en Europe du Nord. Grâce au système de détection basé sur des règles, la banque a eu du mal à atténuer la fraude. Il avait un taux de détection de fraude de 40 % et un taux de faux positifs de 99,5 %.
En collaboration avec Teradata, une société de logiciels de données, Danske a intégré un logiciel d'apprentissage profond pour aider à identifier les activités frauduleuses potentielles. Le résultat a été une réduction de 60 % des faux positifs et une augmentation de 50 % des vrais positifs.
Lutte contre le blanchiment d'argent
OakNorth est une banque de prêt commercial du Royaume-Uni qui fournit des services financiers professionnels et personnels aux entreprises en pleine croissance. La banque avait un processus de contrôle fragmenté, avec un fournisseur pour les contrôles anti-blanchiment d'argent et un autre pour les clients. Par ailleurs, les dépistages des personnes politiquement exposées (PEP) ont généré de nombreux faux positifs.
En collaboration avec ComplyAdvantage, une société de détection de fraude et de lutte contre le blanchiment d'argent, la banque a intégré une solution de filtrage et de surveillance continue pour rationaliser la conformité et consolider les données. Cela a facilité un transfert rapide de données entre les opérations de prêt et d'épargne de la banque.
Souscription de crédit
Hawaii USA Credit Union est la plus grande coopérative de crédit d'Hawaï et l'une des meilleures coopératives de crédit du magazine Forbes. Elle souhaitait être compétitive par rapport aux sociétés Fintech et développer son portefeuille de prêts personnels sans augmenter le risque.
En travaillant avec Zest AI, la coopérative de crédit a automatisé ses processus décisionnels à l'aide d'un modèle de prêt personnel basé sur l'IA. Le modèle a utilisé 278 variables pour fournir des informations plus approfondies que le système de notation de crédit VantageScore. Le résultat a été une augmentation de 21 % du taux d’approbation et un taux de fraude par défaut/demande de prêt de 0 %.
Considérations clés lors de l'utilisation du ML pour la détection des fraudes
Si la détection des fraudes bancaires grâce à l’apprentissage automatique est efficace, elle est également intimidante. Ces systèmes exigent beaucoup de données précises, sinon les modèles ne fonctionnent pas aussi bien qu'ils le devraient.
Voici donc quelques conseils pour optimiser le processus d’apprentissage automatique.
1. Limiter le nombre de variables d'entrée
Tout au long de cet article, nous avons dit que plus c'est plus. Cela reste vrai en ce qui concerne le volume de données. Cependant, moins c'est plus avec le nombre de variables de détection de fraude.
Les caractéristiques typiques à prendre en compte lors d’une enquête sur une fraude comprennent :
- adresse IP
- Adresse e-mail
- Adresse de livraison
- Valeur moyenne des commandes/transactions
L'avantage de moins de fonctionnalités est des temps de formation d'algorithmes plus courts. Vous évitez également les problèmes de chevauchement ou d’ensembles de données non pertinents.
2. Assurer la conformité réglementaire
La prévention de la fraude fait partie de la sécurité des données. L'autre est la confidentialité des données. De nombreux pays ont des lois sur la manière dont les institutions peuvent collecter, utiliser et stocker les données des clients. Il existe la loi chinoise sur la protection des informations personnelles (PIPL), la loi californienne sur la protection de la vie privée des consommateurs (CCPA) et le règlement général sur la protection des données (RGPD) de l'Union européenne, pour n'en nommer que quelques-uns.
Ces lois ont des implications sur les données utilisées dans l'apprentissage automatique. Le principe principal de la plupart des réglementations de conformité en matière de confidentialité des données est la notification/le consentement. Vous devez notifier et recevoir l'autorisation d'utiliser les données des clients à des fins autres que les demandes des utilisateurs, y compris les données pour la formation des algorithmes d'apprentissage automatique.
Le moyen le plus simple de garantir le respect des normes de confidentialité consiste à faire appel à des partenaires techniques dotés de fonctionnalités conformes à la réglementation. Par exemple, vous devriez vous associer à une société de développement d’applications bancaires qui sait comment préserver la confidentialité et la sécurité des données.
3. Fixez un seuil raisonnable
Les règles de valeur de transaction ont des exigences minimales pour déclencher une réponse d'acceptation ou de rejet. Vous voulez un seuil qui équilibre la sécurité et l’expérience utilisateur. Si le seuil est trop strict, vous risquez de bloquer les transactions légitimes. Si le seuil est trop laxiste, vous augmenterez le taux de fraude réussie.
Calculez votre appétit pour le risque pour trouver le bon équilibre. Les niveaux de risque diffèrent pour chaque institution financière ou produit. Par exemple, une offre bancaire de microcrédit peut fixer un seuil élevé pour les prêts de faible valeur. Une banque commerciale ne peut pas être aussi généreuse en matière de prêts hypothécaires.
Anticiper l'avenir
L’avenir, c’est maintenant, mais seulement 17 % des organisations utilisent l’apprentissage automatique dans leurs programmes antifraude. Ne soyez pas laissé pour compte.
Voici quelques avancées auxquelles vous pouvez vous attendre en matière de sécurité de votre banque grâce à l'apprentissage automatique.
- Profilage des appareils : identifiez les différents appareils qui se connectent à votre réseau bancaire, en analysant les caractéristiques et les comportements de chaque appareil donné.
- Détection et réponse automatisées des anomalies : identifiez les comportements frauduleux des appareils connus et isolez les systèmes concernés.
- Détection Zero Day : identifiez les vulnérabilités et les logiciels malveillants jusqu'alors inconnus pour protéger les organisations contre les cyberattaques.
- Masquage des données : détecte et anonymise automatiquement les données confidentielles.
- Informations à l'échelle : identifiez les tendances en matière de fraude sur plusieurs appareils et emplacements.
- Politique innovante : utilisez les informations du machine learning pour mettre en œuvre des politiques de sécurité pertinentes.
Que vous soyez une institution de gestion de patrimoine ou une coopérative de crédit, l'IA et l'apprentissage automatique offrent d'énormes opportunités en matière de détection des fraudes.
Il ne faut toutefois pas oublier que les pirates informatiques utilisent également ces technologies pour contourner les mesures de protection. Mettez à jour vos modèles d'apprentissage automatique pour garder une longueur d'avance sur ces attaques. Vous pouvez également renforcer votre sécurité basée sur l’IA grâce à la bonne vieille intelligence humaine.