
Une introduction au robot d'exploration Web
Publié: 2016-03-08Lorsque je parle aux gens de ce que je fais et de ce qu'est le référencement, ils comprennent généralement assez rapidement, ou ils agissent comme ils le font. Une bonne structure de site Web, un bon contenu, de bons backlinks d'approbation. Mais parfois, cela devient un peu plus technique et je finis par parler des moteurs de recherche qui crawlent votre site Web et je les perds généralement…
Pourquoi crawler un site web ?
L'exploration Web a commencé par la cartographie d'Internet et la façon dont chaque site Web était connecté les uns aux autres. Il était également utilisé par les moteurs de recherche pour découvrir et indexer de nouvelles pages en ligne. Les robots d'exploration Web ont également été utilisés pour tester la vulnérabilité du site Web en testant un site Web et en analysant si un problème a été détecté.
Vous pouvez maintenant trouver des outils qui explorent votre site Web afin de vous fournir des informations. Par exemple, OnCrawl fournit des données concernant votre contenu et le référencement sur site ou Majestic qui fournit des informations sur tous les liens pointant vers une page.
Les robots d'exploration sont utilisés pour collecter des informations qui peuvent ensuite être utilisées et traitées pour classer les documents et fournir des informations sur les données collectées.
Construire un crawler est accessible à toute personne connaissant un peu le code. Faire un crawler efficace est cependant plus difficile et prend du temps.
Comment ça marche ?
Pour explorer un site Web ou le Web, vous avez d'abord besoin d'un point d'entrée. Les robots ont besoin de savoir que votre site Web existe pour pouvoir venir le consulter. À l'époque, vous auriez soumis votre site Web aux moteurs de recherche afin de leur dire que votre site Web était en ligne. Maintenant, vous pouvez facilement créer quelques liens vers votre site Web et voilà, vous êtes au courant !
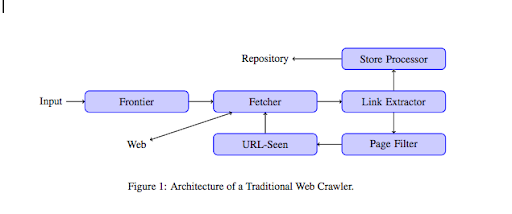
Une fois qu'un crawler atterrit sur votre site Web, il analyse tout votre contenu ligne par ligne et suit chacun des liens que vous avez, qu'ils soient internes ou externes. Et ainsi de suite jusqu'à ce qu'il atterrisse sur une page sans plus de liens ou s'il rencontre des erreurs comme 404, 403, 500, 503.
D'un point de vue plus technique, un robot fonctionne avec une graine (ou une liste) d'URL. Ceci est transmis à un Fetcher qui récupérera le contenu d'une page. Ce contenu est ensuite déplacé vers un extracteur de liens qui analysera le code HTML et extraira tous les liens. Ces liens sont envoyés à la fois à un processeur Store qui va, comme son nom l'indique, les stocker. Ces URL passeront également par un filtre de page qui enverra tous les liens intéressants vers un module URL-vu. Ce module détecte si l'URL a déjà été vue ou non. Sinon, il est envoyé au Fetcher qui récupérera le contenu de la page et ainsi de suite.
Gardez à l'esprit que certains contenus sont impossibles à explorer pour les araignées, comme Flash. Javascript est maintenant correctement exploré par GoogleBot, mais de temps en temps, il n'en explore aucun. Les images ne sont pas du contenu que Google peut techniquement crawler, mais il est devenu assez intelligent pour commencer à les comprendre !
Si on ne dit pas le contraire aux robots, ils ramperont sur tout. C'est là que le fichier robots.txt devient très utile. Il indique aux crawlers (cela peut être spécifique à chaque crawler, c'est-à-dire GoogleBot ou MSN Bot - en savoir plus sur les bots ici) quelles pages ils ne peuvent pas explorer. Disons par exemple que vous avez une navigation à l'aide de facettes, vous ne voudrez peut-être pas que les robots les explorent toutes car elles ont peu de valeur ajoutée et utiliseront le budget de crawl. L'utilisation de cette ligne simple vous aidera à empêcher tout robot de le ramper
Agent utilisateur: *
Interdire : /dossier-a/
Cela indique à tous les robots de ne pas explorer le dossier A.
Agent utilisateur : GoogleBot
Interdire : /répertoire-b/
Cela précise en revanche que seul Google Bot ne peut pas explorer le dossier B.
Vous pouvez également utiliser une indication en HTML qui indique aux robots de ne pas suivre un lien spécifique en utilisant la balise rel="nofollow". Certains tests ont montré que même l'utilisation de la balise rel="nofollow" sur un lien n'empêchera pas Googlebot de le suivre. Ceci est contraire à son objectif, mais sera utile dans d'autres cas.
[Étude de cas] Augmentez la visibilité en améliorant l'exploration du site Web pour Googlebot
 Lire l'étude de cas
Lire l'étude de cas
Vous avez parlé de crawl budget mais qu'est-ce que c'est ?
Disons que vous avez un site Web qui a été découvert par les moteurs de recherche. Ils viennent régulièrement voir si vous avez fait des mises à jour sur votre site web et créé de nouvelles pages.
Chaque site Web a son propre budget de crawl en fonction de plusieurs facteurs tels que le nombre de pages de votre site Web et sa santé (s'il contient beaucoup d'erreurs, par exemple). Vous pouvez facilement avoir une idée rapide de votre budget de crawl en vous connectant à la Search Console.
Votre budget de crawl fixera le nombre de pages qu'un robot parcourra sur votre site Web à chaque visite. Il est proportionnellement lié au nombre de pages que vous avez sur votre site Web et il a déjà exploré. Certaines pages sont explorées plus souvent que d'autres, surtout si elles sont mises à jour régulièrement ou si elles sont liées à des pages importantes.
Par exemple, votre maison est votre point d'entrée principal qui sera très souvent parcouru. Si vous avez un blog ou une page de catégorie, ils seront souvent explorés s'ils sont liés à la navigation principale. Un blog sera également exploré souvent car il est mis à jour régulièrement. Un article de blog peut être exploré souvent lors de sa première publication, mais après quelques mois, il ne sera probablement pas mis à jour.
Plus une page est explorée souvent, plus un robot considère qu'elle est importante par rapport aux autres. C'est à ce moment que vous devez commencer à travailler sur l'optimisation de votre budget de crawl.
Optimiser votre budget de crawl
Afin d'optimiser votre budget et de vous assurer que vos pages les plus importantes reçoivent l'attention qu'elles méritent, vous pouvez analyser les journaux de votre serveur et voir comment votre site Web est exploré :
- À quelle fréquence vos pages les plus consultées sont-elles explorées ?
- Pouvez-vous voir des pages moins importantes être explorées plus que d'autres plus importantes ?
- Les robots obtiennent-ils souvent une erreur 4xx ou 5xx lors de l'exploration de votre site Web ?
- Les robots rencontrent-ils des pièges à araignées ? (Matthew Henry a écrit un excellent article à leur sujet)
En analysant vos logs, vous verrez quelles pages que vous considérez comme moins importantes sont beaucoup crawlées. Vous devez ensuite approfondir votre structure de liens internes. S'il est exploré, il doit y avoir beaucoup de liens pointant vers lui.
Vous pouvez également travailler sur la correction de toutes ces erreurs (4xx et 5xx) avec OnCrawl. Cela améliorera la crawlabilité ainsi que l'expérience utilisateur, c'est un cas gagnant-gagnant.
Crawling VS Scraping ?
L'exploration et le grattage sont deux choses différentes qui sont utilisées à des fins différentes. Explorer un site Web, c'est atterrir sur une page et suivre les liens que vous trouvez lorsque vous analysez le contenu. Un robot se déplacera alors vers une autre page et ainsi de suite.
Le scraping, quant à lui, consiste à numériser une page et à collecter des données spécifiques à partir de la page : balise de titre, méta description, balise h1 ou une zone spécifique de votre site Web telle qu'une liste de prix. Les grattoirs agissent généralement comme des "humains", ils ignoreront toutes les règles du fichier robots.txt, rempliront des formulaires et utiliseront un agent utilisateur de navigateur afin de ne pas être détectés.
Les robots des moteurs de recherche agissent généralement comme des scrappers et doivent collecter des données afin de les traiter pour leur algorithme de classement. Ils ne recherchent pas de données spécifiques par rapport au scrapper, ils utilisent simplement toutes les données disponibles sur la page et même plus (le temps de chargement est quelque chose que vous ne pouvez pas obtenir à partir d'une page). Les robots des moteurs de recherche s'identifieront toujours comme des robots afin que le propriétaire d'un site Web puisse savoir quand il est venu pour la dernière fois sur son site Web. Cela peut être très utile lorsque vous suivez l'activité réelle des utilisateurs.
Alors maintenant que vous en savez un peu plus sur l'exploration, son fonctionnement et son importance, la prochaine étape consiste à commencer à analyser les journaux du serveur. Cela vous fournira des informations approfondies sur la façon dont les robots interagissent avec votre site Web, les pages qu'ils visitent souvent et le nombre d'erreurs qu'ils rencontrent lors de la visite de votre site Web.
Pour plus d'informations techniques et historiques sur les robots d'exploration Web, vous pouvez lire "Une brève histoire des robots d'exploration Web"