
Comment définir son budget de crawl ?
Publié: 2016-09-14Nous en parlons tous en tant que référenceurs, mais comment fonctionne réellement le budget de crawl ? Nous savons que le nombre de pages que les moteurs de recherche explorent et indexent lorsqu'ils visitent les sites Web de nos clients est en corrélation avec leur succès dans la recherche organique, mais est-il toujours préférable d'avoir un budget d'exploration plus important ?
Comme tout avec Google, je ne pense pas que la relation entre le budget d'exploration de vos sites Web et les performances de classement/SERP soit simple à 100 %, elle dépend d'un certain nombre de facteurs.
Pourquoi le budget de crawl est-il important ? En raison de la mise à jour 2010 de la caféine. Avec cette mise à jour, Google a reconstruit la manière dont il indexait le contenu, avec une indexation incrémentale. En introduisant le système de "percolateur", ils ont supprimé le "goulot d'étranglement" des pages indexées.
Comment Google détermine-t-il le budget de crawl ?
Tout dépend de votre PageRank, de votre Citation Flow et de votre Trust Flow.
Pourquoi n'ai-je pas mentionné l'autorité de domaine ? Honnêtement, à mon avis, c'est l'une des mesures les plus mal utilisées et les plus mal comprises disponibles pour les référenceurs et les spécialistes du marketing de contenu qui a sa place, mais beaucoup trop d'agences et de référenceurs lui accordent trop de valeur, en particulier lors de la création de liens.
Le PageRank est maintenant, bien sûr, obsolète, surtout depuis qu'ils ont abandonné la barre d'outils, il s'agit donc du ratio de confiance d'un site (Trust Ratio = Trust Flow/Citation Flow). Essentiellement, les domaines les plus puissants ont des budgets d'exploration plus importants, alors comment identifiez-vous l'activité des bots Google sur votre site Web et, surtout, identifiez les problèmes d'exploration des bots ? Fichiers journaux du serveur.
Maintenant, nous savons tous que pour indiquer les pages au bot Google que nous avons indexées (et classées), nous utilisons une structure de liens interne et les gardons près du domaine racine, et non 5 sous-dossiers le long de l'URL. Mais qu'en est-il des problèmes plus techniques ? Comme le gaspillage du budget de crawl, les bot traps ou si Google essaie de remplir des formulaires sur le site (ça arrive).
Identification de l'activité du robot d'exploration
Pour ce faire, vous devez mettre la main sur certains fichiers journaux du serveur. Vous devrez peut-être les demander à votre client ou vous pouvez les télécharger directement auprès de la société d'hébergement.
L'idée sous-jacente est que vous voulez essayer de trouver un enregistrement du bot Google sur votre site, mais comme il ne s'agit pas d'un événement planifié, vous devrez peut-être obtenir quelques jours de données. Il existe différents logiciels disponibles pour analyser ces fichiers.
Vous trouverez ci-dessous un exemple d'accès à un serveur Apache :
50.56.92.47 – – [31/May/2012:12:21:17 +0100] « GET » – « /wp-content/themes/wp-theme/help.php » – « 404 » « - » « Mozilla/ 5.0 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html) » – www.hit-example.com
À partir de là, vous pouvez utiliser des outils (tels que OnCrawl) pour analyser les fichiers journaux et identifier des problèmes tels que l'exploration de pages PPC par Google ou des requêtes GET infinies vers des scripts JSON - qui peuvent tous deux être corrigés dans le fichier Robots.txt.
Quand le budget de crawl est-il un problème ?
Le budget de crawl n'est pas toujours un problème, si votre site a beaucoup d'URL et a une allocation proportionnelle de "crawls", tout va bien. Mais que se passe-t-il si votre site Web contient 200 000 URL et que Google n'explore que 2 000 pages de votre site chaque jour ? Cela peut prendre jusqu'à 100 jours pour que Google remarque les URL nouvelles ou actualisées - maintenant c'est un problème.
Un test rapide pour voir si votre budget de crawl est un problème consiste à utiliser Google Search Console et le nombre d'URL sur votre site pour calculer votre "numéro de crawl".
- Vous devez d'abord déterminer combien de pages il y a sur votre site, vous pouvez le faire en faisant un site : recherche, par exemple oncrawl.com a environ 512 pages dans l'index :
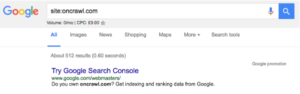

- Deuxièmement, vous devez accéder à votre compte Google Search Console et accéder à Crawl, puis Crawl Stats. Si votre compte GSC n'a pas été configuré correctement, vous ne disposez peut-être pas de ces données.
- La troisième étape consiste à prendre le nombre moyen de "Pages explorées par jour" (celui du milieu) et le nombre total d'URL sur votre site Web et à les diviser :
Nombre total de pages sur le site / Nombre moyen de pages explorées par jour = X
Si X est supérieur à 10, vous devez envisager d'optimiser votre budget de crawl. Si c'est moins de 5, bravo. Vous n'avez pas besoin de lire la suite.
Optimiser votre capacité de 'budget de crawl'
Vous pouvez avoir le plus gros budget de crawl sur internet, mais si vous ne savez pas comment l'utiliser, ça ne vaut rien.
Oui, c'est un cliché, mais c'est vrai. Si Google explore toutes les pages de votre site et constate que la grande majorité d'entre elles sont en double, vides ou se chargent si lentement qu'elles provoquent des erreurs de temporisation, votre budget peut tout aussi bien être nul.
Pour tirer le meilleur parti de votre budget de crawl (même sans accès aux fichiers journaux du serveur), vous devez vous assurer que vous procédez comme suit :
Supprimer les pages en double
Souvent, sur les sites de commerce électronique, des outils tels qu'OpenCart peuvent créer plusieurs URL pour le même produit. J'ai vu des instances du même produit sur 4 URL avec des sous-dossiers différents entre la destination et la racine.
Vous ne voulez pas que Google indexe plus d'une version de chaque page, alors assurez-vous d'avoir mis en place des balises canoniques pointant Google vers la bonne version.
Résoudre les liens brisés
Utilisez Google Search Console, ou un logiciel d'exploration, et trouvez tous les liens internes et externes brisés sur votre site et corrigez-les. L'utilisation de 301 est excellente, mais s'il s'agit de liens de navigation ou de liens de pied de page qui sont rompus, modifiez simplement l'URL vers laquelle ils pointent sans vous fier à un 301.
N'écrivez pas de pages fines
Évitez d'avoir beaucoup de pages sur votre site qui n'offrent que peu ou pas de valeur aux utilisateurs ou aux moteurs de recherche. Sans contexte, Google a du mal à classer les pages, ce qui signifie qu'elles ne contribuent en rien à la pertinence globale du site et qu'elles ne sont que des passagers prenant en charge le budget de crawl.
Supprimer les chaînes de redirection 301
Les redirections en chaîne sont inutiles, désordonnées et mal comprises. Les chaînes de redirection peuvent endommager votre budget de crawl de plusieurs façons. Lorsque Google atteint une URL et voit un 301, il ne la suit pas toujours immédiatement, il ajoute à la place la nouvelle URL à une liste, puis la suit.
Vous devez également vous assurer que votre plan de site XML (et plan de site HTML) est exact, et si votre site Web est multilingue, assurez-vous d'avoir des plans de site pour chaque langue du site Web. Vous devez également mettre en œuvre une architecture de site intelligente, une architecture d'URL et accélérer vos pages. Mettre votre site derrière un CDN comme CloudFlare serait également bénéfique.
TL ; RD :
Le budget de crawl comme tout budget est une opportunité, vous utilisez en théorie votre budget pour gagner du temps que Googlebot, Bingbot et Slurp passent sur votre site, il est important que vous profitiez au maximum de ce temps.
L'optimisation du budget de crawl n'est pas facile, et ce n'est certainement pas une « victoire rapide ». Si vous avez un petit site ou un site de taille moyenne bien entretenu, tout ira probablement bien. Si vous avez un mastodonte de site avec des dizaines de milliers d'URL et que les fichiers journaux du serveur vous dépassent, il est peut-être temps de faire appel à des experts.