
Combien de tests A/B devriez-vous exécuter par mois ?
Publié: 2023-01-19
C'est une question importante à considérer pour le succès de votre programme de test.
Exécutez trop de tests et vous risquez de gaspiller des ressources sans tirer beaucoup de valeur d'une expérience individuelle.
Mais exécutez trop peu de tests et vous risquez de manquer d'importantes opportunités d'optimisation qui pourraient générer davantage de conversions.
Alors, compte tenu de cette énigme, quelle est la cadence de test idéale ?
Pour aider à répondre à cette question, $en$e se penche sur certaines des équipes d'expérimentation les plus performantes et les plus progressistes au monde.
Amazon est un de ces noms qui me vient à l'esprit.
Le géant du commerce électronique est également un géant de l'expérimentation. En fait, on dit qu'Amazon exécute plus de 12 000 expériences par an ! Ce montant se décompose en environ un millier d'expériences par mois.
On dit que des entreprises comme Google et Bing de Microsoft maintiennent un rythme similaire.
Selon Wikipedia, les géants des moteurs de recherche effectuent chacun plus de 10 000 tests A/B par an, soit environ 800 tests par mois.
Et ce ne sont pas seulement les moteurs de recherche qui fonctionnent à ce rythme.
Booking.com est un autre nom notable dans l'expérimentation. Le site de réservation de voyages effectuerait plus de 25 000 tests par an, ce qui représente plus de 2 000 tests par mois ou 70 tests par jour !
Pourtant, des études montrent qu'une entreprise moyenne n'effectue que 2 à 3 tests par mois.
Donc, si la plupart des entreprises n'exécutent que quelques tests par mois, mais que certaines des meilleures au monde exécutent des milliers d'expériences par mois, combien de tests devriez-vous, idéalement, exécuter ?
Dans le vrai style CRO, la réponse est : cela dépend.
De quoi dépend-il ? Un certain nombre de facteurs importants dont vous devez tenir compte.
Le nombre idéal de tests A/B à exécuter est déterminé par la situation spécifique et des facteurs tels que la taille de l'échantillon, la complexité des idées de test et les ressources disponibles.
Les 6 facteurs à prendre en compte lors de l'exécution de tests A/B
Il y a 6 facteurs essentiels à prendre en compte pour décider du nombre de tests à exécuter par mois. Ils comprennent
- Exigences relatives à la taille de l'échantillon
- Maturité organisationnelle
- Ressources disponibles
- Complexité des idées de test
- Délais de test
- Effets d'interaction
Plongeons profondément dans chacun.
Exigences relatives à la taille de l'échantillon
Dans les tests A/B, la taille de l'échantillon décrit la quantité de trafic dont vous avez besoin pour exécuter un test fiable.
Pour exécuter une étude statistiquement valide, vous avez besoin d'un échantillon important et représentatif d'utilisateurs.
Bien que, théoriquement, vous puissiez exécuter une expérience avec seulement quelques utilisateurs, vous n'obtiendrez pas de résultats très significatifs.
Des échantillons de petite taille peuvent encore produire des résultats statistiquement significatifs
Par exemple, imaginez un test A/B où seulement 10 utilisateurs ont vu la version A et 2 converties. Et seulement 8 utilisateurs ont vu la version B avec 6 qui se sont convertis.
Comme le montre ce graphique, les résultats sont statistiquement significatifs :
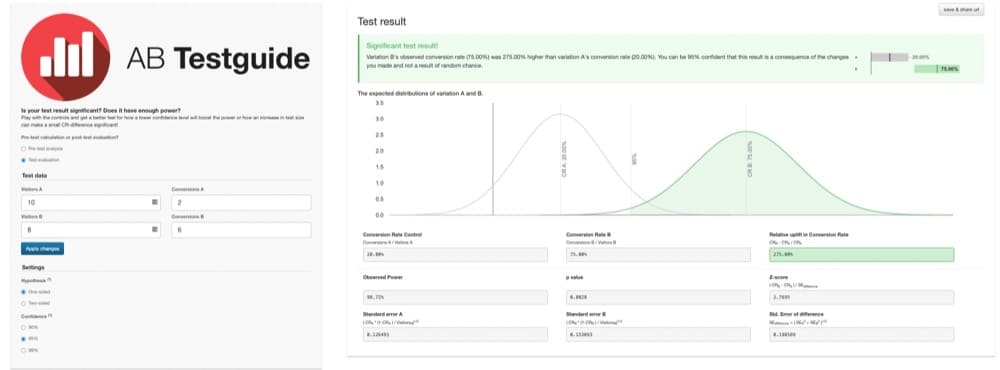
La version B semble surperformer de 275 %. Mais, ces résultats ne sont pas très fiables. La taille de l'échantillon est trop faible pour fournir des résultats significatifs.
L'étude manque de puissance. Il ne contient pas un grand échantillon représentatif d'utilisateurs.
Parce que le test est sous-alimenté, les résultats sont sujets à erreur. Et il n'est pas clair si le résultat s'est produit par hasard ou si une version est vraiment supérieure.
Avec ce petit échantillon, il est facile de tirer des conclusions erronées.
Tests correctement alimentés
Pour surmonter cet écueil, les tests A/B doivent être suffisamment alimentés avec un large échantillon représentatif d'utilisateurs.
Quelle est la taille suffisante ?
On peut répondre à cette question en faisant quelques calculs simples de taille d'échantillon.
Pour calculer plus facilement vos exigences en matière de taille d'échantillon, je vous suggère d'utiliser un calculateur de taille d'échantillon. Il y en a beaucoup là-bas.
Mon préféré est celui d'Evan Miller parce qu'il est flexible et complet. De plus, si vous pouvez comprendre comment l'utiliser, vous pouvez maîtriser presque toutes les calculatrices.
Voici à quoi ressemble la calculatrice d'Evan Miller :
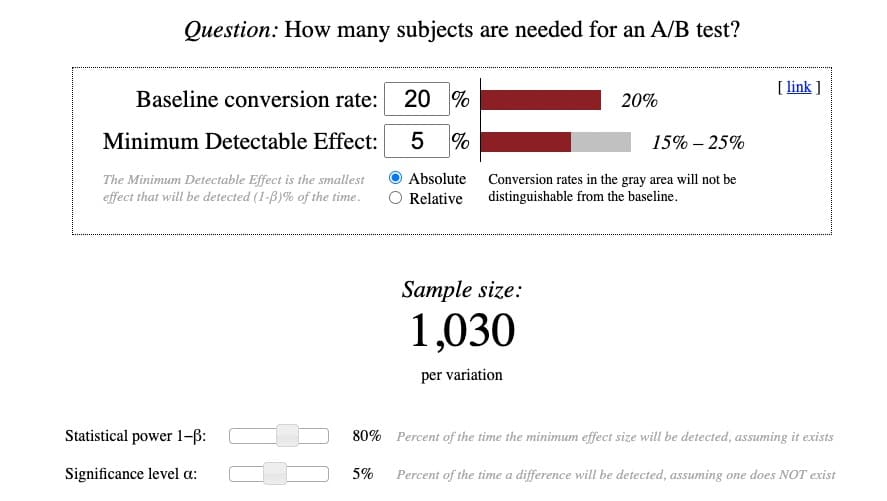
Bien que les calculs eux-mêmes soient assez simples, comprendre la terminologie qui les sous-tend ne l'est pas. J'ai donc tenté de clarifier le complexe:
Taux de conversion de base
Le taux de conversion de base est le taux de conversion existant de la version de contrôle ou d'origine. Il est généralement étiqueté "version A" lors de la configuration d'un test A/B.
Vous devriez pouvoir trouver ce taux de conversion dans votre plateforme d'analyse.
Si vous n'avez jamais effectué de test A/B ou si vous ne connaissez pas le taux de conversion de base, faites votre meilleure estimation.
Le taux de conversion moyen, sur la plupart des sites, des secteurs verticaux de l'industrie et des types d'appareils, se situe entre 2 et 5 %. Donc, si vous n'êtes vraiment pas sûr de votre taux de conversion de base, faites preuve de prudence et commencez avec une base de 2 %.
Plus le taux de conversion de base est faible, plus la taille de l'échantillon dont vous aurez besoin sera grande. Et vice versa.
Effet minimum détectable (MDE)
L'effet minimum détectable (MDE) ressemble à un concept compliqué. Mais cela devient beaucoup plus facile à saisir si vous décomposez le terme en ses trois parties :
- Minimum = plus petit
- Détectable = vous essayez de détecter ou de trouver en exécutant l'expérience
- Effet = différence de conversion entre le contrôle et le traitement
Par conséquent, l'effet minimal détectable est la plus petite augmentation de conversion que vous espérez détecter en exécutant le test.
Certains puristes des données diront que cette définition décrit en fait l'effet d'intérêt minimum (MEI). Quelle que soit la façon dont vous voulez l'appeler, l'objectif est d'anticiper l'ampleur de l'augmentation de la conversion que vous vous attendez à obtenir en exécutant le test.
Bien que cet exercice puisse sembler très spéculatif, vous pouvez utiliser un calculateur de taille d'échantillon comme celui-ci ou le calculateur statistique de test A/B de Convert pour calculer le MDE anticipé.
En règle générale, un MDE de 2 à 5 % est considéré comme raisonnable. Tout ce qui est beaucoup plus élevé est généralement irréaliste lors de l'exécution d'un test vraiment correctement alimenté.
Plus le MDE est petit, plus la taille de l'échantillon nécessaire est grande. Et vice versa.
Une MDE peut être exprimée en montant absolu ou relatif.
Absolu
Un MDE absolu est la différence de nombre brut entre le taux de conversion du contrôle et de la variante.
Par exemple, si le taux de conversion de base est de 2,77 % et que vous vous attendez à ce que la variante atteigne un MDE absolu de +3 %, la différence absolue est de 5,77 %.
Relatif
En revanche, un effet relatif exprime la différence en pourcentage entre les variantes.
Par exemple, si le taux de conversion de base est de 2,77 % et que vous vous attendez à ce que la variante atteigne un MDE relatif de +3 %, la différence relative est de 2,89 %.
En général, la plupart des expérimentateurs utilisent une augmentation relative en pourcentage, donc, généralement, il est préférable de représenter les résultats de cette façon.
Puissance statistique 1−β
La puissance fait référence à la probabilité de trouver un effet, ou une différence de conversion, en supposant qu'il en existe vraiment un.
Lors des tests, votre objectif est de vous assurer que vous disposez de suffisamment de puissance pour détecter de manière significative une différence, s'il en existe une, sans erreur. Par conséquent, une puissance supérieure est toujours meilleure. Mais le compromis est que cela nécessite une taille d'échantillon plus grande.
Une puissance de 0,80 est considérée comme la meilleure pratique standard. Vous pouvez donc la laisser comme plage par défaut sur cette calculatrice.
Ce montant signifie qu'il y a 80 % de chances que, s'il y a un effet, vous le détectiez avec précision et sans erreur. En tant que tel, il n'y a que 20% de chances que vous manquiez de détecter correctement l'effet. Un risque à prendre.
Niveau de signification α
En tant que définition très simple, le niveau de signification alpha est le taux de faux positifs, ou le pourcentage de temps pendant lequel une différence de conversion sera détectée, même si elle n'existe pas réellement.
En tant que meilleure pratique de test A/B, votre niveau de signification doit être de 5 % ou moins. Vous pouvez donc simplement le laisser par défaut sur cette calculatrice.
Un niveau de signification α de 5 % signifie qu'il y a 5 % de chances que vous trouviez une différence entre le contrôle et la variante, alors qu'aucune différence n'existe réellement.
Encore une fois, un risque qui vaut la peine d'être pris.
Évaluation de vos exigences en matière de taille d'échantillon
Avec ces chiffres branchés sur votre calculatrice, vous pouvez désormais vous assurer que votre site a suffisamment de trafic pour exécuter un test correctement alimenté sur une période de test standard de 2 à 6 semaines.
Pour vérifier, accédez à votre plate-forme d'analyse préférée et examinez le taux de trafic moyen historique du site, ou de la page que vous souhaitez tester, sur une période déterminée.
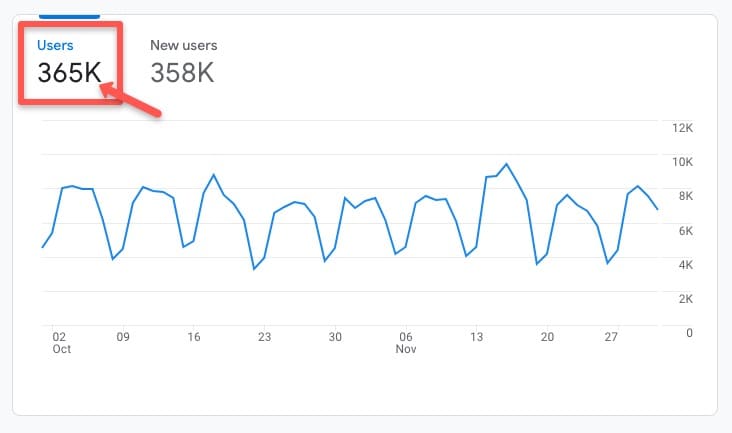
Par exemple, dans ce compte Google Analytics 4 (GA4), en accédant à l'onglet Cycle de vie > Acquisition > Aperçu de l'acquisition, vous pouvez voir qu'il y avait 365 000 utilisateurs au cours de la période historique récente entre octobre et novembre 2022 :
Sur la base d'un taux de conversion de base existant de 3,5 %, avec un MDE relatif de 5 %, à une puissance standard de 80 % et un niveau de signification standard de 5 %, le calculateur indique qu'un échantillon de 174 369 visiteurs par variante est nécessaire pour exécuter correctement un Test A/B alimenté :
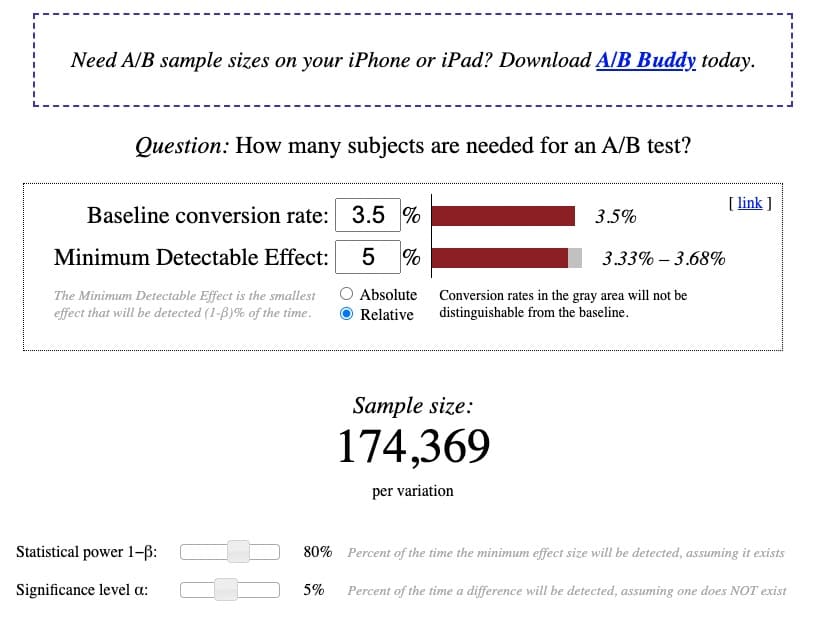
En supposant que les tendances du trafic restent relativement stables pour les mois à venir, il est raisonnable de s'attendre à ce que le site atteigne environ 365 000 utilisateurs ou (365 000/2 variantes) 182 000 visiteurs par variante dans un délai de test raisonnable.
Les exigences de taille d'échantillon sont réalisables, ce qui donne le feu vert pour aller de l'avant et exécuter le test.
Une remarque importante, cet exercice de vérification des exigences de taille d'échantillon doit toujours être effectué AVANT l'exécution de toute étude afin que vous sachiez si vous avez suffisamment de trafic pour exécuter un test correctement alimenté.
De plus, lors de l'exécution du test, vous ne devez JAMAIS arrêter votre test avant d'avoir atteint vos exigences de taille d'échantillon pré-calculées - même si les résultats apparaissent significatifs plus tôt.
Déclarer prématurément un gagnant ou un perdant avant de répondre aux exigences de taille d'échantillon est ce que l'on appelle le « regarder » et est une pratique de test dangereuse qui peut vous amener à faire des appels incorrects avant que les résultats ne soient complètement éliminés.
Combien de tests pouvez-vous exécuter si vous avez suffisamment de trafic ?
En supposant que le site ou la ou les pages que vous souhaitez tester répondent aux exigences de taille d'échantillon, combien de tests pouvez-vous exécuter ?
La réponse est, encore une fois, cela dépend.
Selon une présentation partagée par Ronny Kohavi, l'ancien vice-président de l'expérimentation chez Bing de Microsoft, Microsoft exécute généralement plus de 300 expériences par jour.
Mais ils ont le trafic pour le faire.
Chaque expérience voit plus de 100 000 utilisateurs :
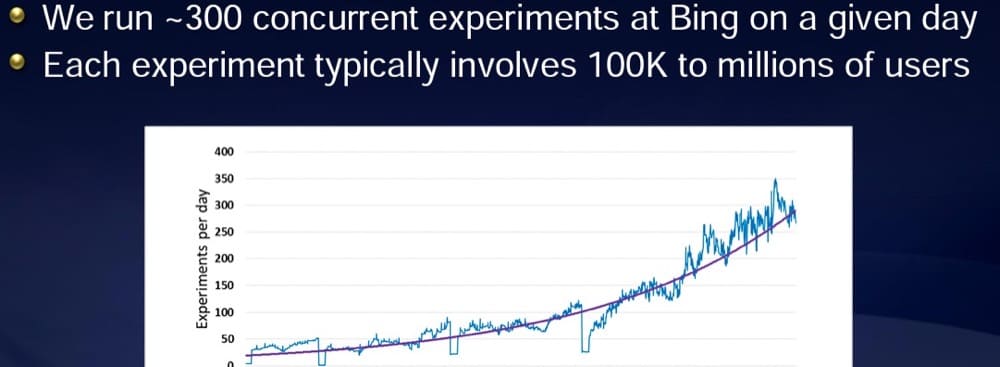
Plus votre trafic disponible est important, plus vous pouvez exécuter de tests.

Pour tout test, vous devez vous assurer que vous disposez d'un échantillon suffisamment grand pour exécuter une expérience correctement alimentée.
Si vous êtes une petite organisation avec un trafic plus limité, envisagez moins de tests de meilleure qualité.
En fin de compte, il ne s'agit pas vraiment du nombre de tests que vous exécutez, mais du résultat de vos expériences.
Options si vous ne pouvez pas répondre aux exigences de taille d'échantillon
Si vous découvrez que vous ne pouvez pas répondre aux exigences de taille d'échantillon, ne vous inquiétez pas. L'expérimentation n'est pas hors de propos pour vous. Vous avez quelques options d'expérimentation potentielles disponibles :
- Focus sur l'acquisition de trafic
Même les grands sites peuvent avoir un faible trafic sur certaines pages.
Si vous trouvez que le trafic du site, ou le trafic sur certaines pages, ne répond pas aux exigences de taille d'échantillon, envisagez de concentrer vos efforts sur l'acquisition de plus de trafic.
Pour ce faire, vous pouvez entreprendre des tactiques agressives d'optimisation des moteurs de recherche (SEO) pour vous classer plus haut dans les moteurs de recherche et obtenir plus de clics.
Vous pouvez également acquérir du trafic payant via des canaux tels que Google Ads, des publicités LinkedIn ou même des bannières publicitaires.
Ces deux activités d'acquisition peuvent aider à augmenter le trafic Web et vous donner une plus grande capacité à tester ce qui se convertit le mieux auprès des utilisateurs.
Toutefois, si vous utilisez du trafic payant pour répondre aux exigences de taille d'échantillon, envisagez de segmenter les résultats des tests par type de trafic, car le comportement des visiteurs peut différer selon la source de trafic.
- Évaluer si les tests A/B sont la meilleure méthode d'expérimentation pour vous
Bien que les tests A/B soient considérés comme l'étalon-or de l'expérimentation, les résultats ne sont aussi bons que les données qui les sous-tendent.
Si vous trouvez que vous n'avez pas assez de trafic pour exécuter un test correctement alimenté, vous voudrez peut-être vous demander si le test A/B est vraiment la meilleure option d'expérimentation pour vous.
Il existe d'autres approches basées sur la recherche qui nécessitent des échantillons beaucoup plus petits et peuvent encore fournir des informations d'optimisation incroyablement précieuses.
Les tests d'expérience utilisateur (UX), les enquêtes auprès des consommateurs, les sondages de sortie ou les entretiens avec les clients sont quelques autres modalités d'expérimentation que vous pouvez essayer comme alternative aux tests A/B.
- Les résultats de réalisation peuvent fournir uniquement des données directionnelles
Mais si vous restez concentré sur les tests A/B, vous pouvez toujours exécuter des tests.
Réalisez simplement que les résultats peuvent ne pas être entièrement précis et ne fourniront que des «données directionnelles» indiquant le résultat probable – plutôt que totalement fiable.
Étant donné que les résultats peuvent ne pas être entièrement vrais, vous souhaiterez surveiller de près l'effet de conversion au fil du temps.
Cela dit, ce qui est souvent plus important que des chiffres de conversion précis, ce sont les chiffres du compte bancaire. S'ils augmentent, vous savez que le travail d'optimisation que vous faites fonctionne.
Tester la maturité
En plus des exigences de taille d'échantillon, un autre facteur qui influence la cadence des tests est le niveau de maturité de l'organisation de test.
Tester la maturité est un terme utilisé pour décrire à quel point l'expérimentation est ancrée dans une culture organisationnelle et à quel point les pratiques d'expérimentation sont avancées.
Des organisations comme Amazon, Google, Bing et Booking – qui exécutent des milliers de tests par mois – ont des équipes de test progressives et matures.
Ce n'est pas une coïncidence.
La cadence des tests tend à être étroitement liée au niveau de maturité d'une organisation.
Si l'expérimentation est enracinée dans l'organisation, la direction s'y engage. De plus, les employés, dans toute l'organisation, sont généralement encouragés à soutenir et à prioriser l'expérimentation, et peuvent même aider à fournir des idées de test.
Lorsque ces facteurs sont réunis, il est beaucoup plus facile d'exécuter un programme de test rapide.
Si vous espérez accélérer les tests, il peut être utile de commencer par examiner le niveau de maturité de votre organisation.
Commencez par évaluer des questions comme
- Quelle est l'importance de l'expérimentation pour la C-Suite ?
- Quels sont les moyens mis à disposition pour favoriser l'expérimentation ?
- Quels canaux de communication sont disponibles pour communiquer les mises à jour des tests ?
Si la réponse est « aucune » ou presque, envisagez de travailler d'abord sur la création d'une culture de test.
Au fur et à mesure que votre organisation adopte une culture d'expérimentation plus progressive, il sera naturellement plus facile d'accélérer la cadence des tests.
Pour des suggestions sur la façon de créer une culture d'expérimentation, consultez des ressources comme cet article et celui-ci.
Contraintes de ressources
En supposant que vous ayez déjà un certain degré d'adhésion organisationnelle, le prochain problème à combattre est le manque de ressources.
Le temps, l'argent et le pouvoir humain sont autant de limites qui peuvent limiter votre capacité à tester. Et testez vite.
Pour surmonter les contraintes de ressources, il peut être utile de commencer par évaluer la complexité des tests.
Équilibrez les tests simples et complexes
En tant qu'expérimentateur, vous pouvez choisir d'exécuter des tests allant du plus simple au plus complexe.
Des tests simples peuvent inclure l'optimisation d'éléments tels que la copie ou la couleur, la mise à jour d'images ou le déplacement d'éléments uniques sur une page.
Les tests complexes peuvent impliquer la modification de plusieurs éléments, la modification de la structure de la page ou la mise à jour de l'entonnoir de conversion. Ces types de tests nécessitent souvent un travail de codage approfondi.
En exécutant des milliers de tests A/B, j'ai trouvé utile d'avoir un mélange d'environ ⅗ tests plus simples et ⅖ plus complexes exécutés simultanément à tout moment.
Des tests plus simples peuvent vous donner des gains rapides et faciles.
Mais des tests plus importants, avec des changements plus importants, produisent souvent des effets plus importants. En fait, selon certaines recherches d'optimisation, plus vous exécutez de tests complexes et nombreux, plus vous avez de chances de réussir. N'ayez donc pas peur de faire souvent de gros tests de swing.
Sachez simplement que le compromis est que vous dépenserez plus de ressources pour concevoir et construire le test. Et rien ne garantit qu'il gagnera.
Test basé sur les ressources humaines disponibles
Si vous êtes un stratège CRO solo ou si vous travaillez avec une petite équipe, votre capacité est limitée. Qu'ils soient simples ou complexes, vous pouvez trouver 2 à 5 tests par mois qui vous taraudent.
En revanche, si vous faites partie d'une organisation qui dispose d'une équipe dédiée de chercheurs, de stratèges, de concepteurs, de développeurs et de spécialistes de l'assurance qualité, vous avez probablement la capacité d'exécuter des dizaines à des centaines de tests par mois.
Pour déterminer le nombre de tests à exécuter, évaluez la disponibilité de vos ressources humaines.
En moyenne, un test simple peut prendre 3 à 6 heures pour imaginer, structurer, concevoir, développer, mettre en œuvre, AQ et surveiller les résultats.
D'un autre côté, un test très complexe peut prendre jusqu'à 15 à 20 heures.
Il y a environ 730 heures par mois, vous voudrez donc être très calculé sur les tests et le nombre de tests que vous exécutez pendant ce temps précieux.
Planifiez et hiérarchisez vos idées de test
Pour vous aider à définir votre structure de test optimale, envisagez d'utiliser un cadre de priorisation des tests, comme PIE, ICE ou PXL.
Ces cadres fournissent une technique quantitative pour classer vos meilleures idées de test, évaluer la facilité de mise en œuvre et déterminer quels tests sont les plus susceptibles d'augmenter les conversions.
Après avoir effectué cette évaluation, votre liste prioritaire d'idées de test ressemblera à ceci :

Avec vos meilleures idées de test classées, il est également recommandé de créer une feuille de route de test pour planifier visuellement votre calendrier de test et les prochaines étapes.
Votre feuille de route peut ressembler à ceci :
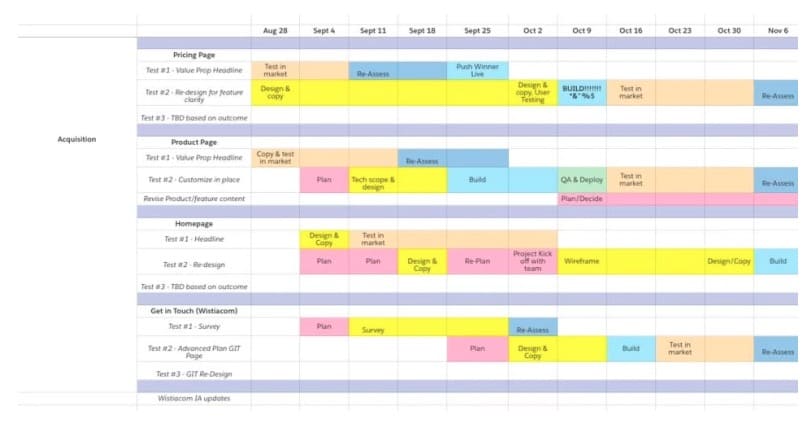
Il devrait inclure :
- La liste des idées que vous envisagez de tester, par page.
- Combien de temps vous prévoyez que chaque étape de test (conception, développement, AQ, etc.) prendra.
- Combien de temps vous prévoyez d'exécuter chaque test, en fonction des exigences de taille d'échantillon pré-calculées. Vous pouvez calculer les exigences de durée de test à l'aide d'un calculateur de durée de test comme celui-ci.
En cartographiant vos idées de test, vous serez en mesure de déterminer plus précisément la cadence et la capacité des tests.
Au fur et à mesure que vous remplissez votre feuille de route de test, il peut devenir très clair que le nombre de tests que vous pouvez exécuter est basé sur les ressources dont vous disposez.
Devriez-vous exécuter plusieurs tests à la fois ?
Mais ce n'est pas parce que vous pouvez faire quelque chose que vous devez toujours le faire.
Lorsqu'il s'agit d'exécuter plusieurs tests à la fois, il y a un grand débat sur la meilleure approche.
Des articles, comme celui-ci, par le leader d'Experiment Nation, Rommil Santiago, soulèvent une question controversée : est-il acceptable d'exécuter plusieurs tests A/B simultanément ?
Certains expérimentateurs diront, absolument pas !
Ils diront que vous ne devriez jamais exécuter qu'un seul test, une page à la fois. Sinon, vous ne pourrez isoler correctement aucun effet.
J'étais dans ce camp parce que c'est comme ça qu'on m'a appris il y a près de dix ans.
Il m'a été strictement indiqué que vous ne devriez jamais exécuter qu'un seul test, avec un seul changement, sur une page, à la fois. J'ai fonctionné avec cet état d'esprit pendant de nombreuses années - au grand désarroi des clients anxieux qui voulaient plus de résultats plus rapidement.
Cependant, cet article de Timothy Chan, un ancien scientifique des données chez Facebook et maintenant le scientifique principal des données chez Statsig, m'a complètement changé d'avis.
Dans son article, soutient Chan, les effets d'interaction sont largement surestimés.
En fait, exécuter plusieurs tests simultanément n'est pas seulement un problème ; c'est vraiment le seul moyen de tester !
Cette position est étayée par des données de son passage chez Facebook où Chan a vu le géant des médias sociaux mener avec succès des centaines d'expériences simultanément, dont beaucoup même sur la même page.
Des experts en données comme Ronny Kohavi et Hazjier Pourkhalkhali sont d'accord : les effets d'interaction sont hautement improbables. Et, en fait, la meilleure façon de tester le succès est d'exécuter plusieurs tests à plusieurs reprises, de manière continue.
Ainsi, lorsque vous envisagez de tester la cadence, ne vous inquiétez pas de l'effet d'interaction des tests qui se chevauchent. Testez généreusement.
Résumé
Dans les tests A/B, il n'y a pas de nombre optimal de tests A/B à exécuter.
Le nombre idéal est ce qui convient à votre situation unique.
Ce nombre est basé sur plusieurs facteurs, notamment les contraintes de taille d'échantillon de votre site, la complexité des idées de test, ainsi que l'assistance et les ressources disponibles.
En fin de compte, il ne s'agit pas tant du nombre de tests que vous exécutez, mais plutôt de la qualité des tests et des résultats que vous obtenez. Un seul test qui apporte une grande portance est bien plus précieux que plusieurs tests non concluants qui ne déplacent pas l'aiguille.
Les tests sont vraiment une question de qualité plutôt que de quantité !
Pour en savoir plus sur la façon de tirer le meilleur parti de votre programme de test A/B, consultez cet article Convert.

