
Comment prévoir les revenus du trafic organique sans marque en fonction de la position de l'URL avec Python
Publié: 2022-05-24Qu'est-ce que la prévision SEO ?
La prévision SEO, ou estimation du trafic organique, est le processus d'utilisation des données de votre propre site ou de données tierces pour estimer le futur trafic organique, les revenus SEO et le ROI SEO de votre site. Cette estimation peut être calculée à l'aide de nombreuses méthodes différentes basées sur nos données.
Dans ce didacticiel, nous voulons prédire nos revenus organiques sans marque et notre trafic organique sans marque en fonction de nos positions d'URL et de leurs revenus actuels. Cela peut nous aider en tant que référenceurs à obtenir plus d'adhésion des autres parties prenantes : de l'augmentation du budget mensuel, trimestriel ou annuel à plus d'heures de travail de la part de l'équipe produit et de développement.
Gardez à l'esprit que ce didacticiel ne s'applique pas uniquement au trafic organique sans marque ; en apportant quelques modifications et en connaissant Python, vous pouvez l'utiliser pour estimer le trafic de vos pages cibles.
En conséquence, nous pouvons produire une feuille Google comme l'image ci-dessous.
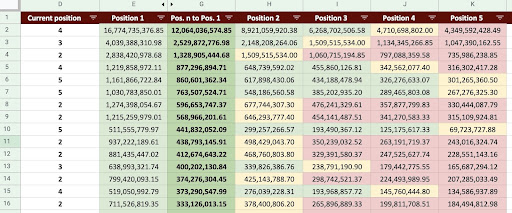
Image Google Sheets
Prévision de trafic SEO sans marque
La première question que vous pouvez vous poser après avoir lu l'introduction est : "Pourquoi calculer le trafic organique sans marque ?".
Considérons une entreprise comme Amazon. Lorsque vous souhaitez acheter un livre ou un masque, vous recherchez simplement "acheter un masque amazon".
Les marques sont souvent une priorité et lorsque vous souhaitez acheter quelque chose, votre préférence est d'acheter les choses dont vous avez besoin auprès de ces entreprises. Dans chaque secteur, il existe des entreprises de marque qui affectent le comportement des utilisateurs dans les recherches Google.
Si nous devions vérifier les données de la console de recherche Google (GSC) d'Amazon, nous constaterions probablement qu'il reçoit beaucoup de trafic provenant de requêtes de marque, et la plupart du temps, le premier résultat des requêtes de marque est le site de cette marque.
En tant que référenceur, comme moi, vous avez probablement entendu dire à plusieurs reprises que « seule notre marque aide notre référencement ! Comment pouvons-nous dire "Non, ce n'est pas le cas" et afficher le trafic et les revenus des requêtes non liées à la marque ?
C'est encore plus compliqué à prouver parce que nous savons que les algorithmes de Google sont si complexes et qu'il est difficile de séparer distinctement les recherches de marque des recherches sans marque. Mais c'est ce qui rend ce que nous faisons en tant que SEO d'autant plus important.
Dans ce didacticiel, je vais vous montrer comment faire la distinction entre les deux - avec et sans marque - et vous montrer à quel point le référencement peut être puissant.
Même si votre entreprise n'a pas de marque, cet article peut vous apporter beaucoup : vous pouvez apprendre à estimer les données organiques de votre site.
ROI SEO basé sur l'estimation du trafic
Peu importe où vous vous trouvez ou ce que vous faites, les ressources sont limitées. que ce soit un budget ou simplement le nombre d'heures dans la journée de travail. Savoir comment allouer au mieux vos ressources joue un rôle majeur dans le retour sur investissement (ROI) global et SEO.
Un CMO, un vice-président marketing ou un spécialiste du marketing à la performance ont tous des KPI différents et nécessitent des ressources différentes pour atteindre leurs objectifs. La meilleure façon de vous assurer d'obtenir ce dont vous avez besoin est de prouver sa nécessité en démontrant les rendements qu'il apportera à l'entreprise. Le ROI SEO n'est pas différent. Lorsque la période d'allocation budgétaire de l'année arrive et que votre équipe souhaite demander un budget plus important, l'estimation de votre retour sur investissement SEO peut vous donner l'avantage dans la négociation. Une fois que vous avez calculé l'estimation du trafic sans marque, vous pouvez mieux évaluer le budget nécessaire pour obtenir les résultats souhaités.
L'effet de la prédiction SEO sur la stratégie SEO
Comme nous le savons, tous les 3 ou 6 mois, nous révisons notre stratégie de référencement et l'ajustons pour obtenir les meilleurs résultats possibles. Mais que se passe-t-il lorsque vous ne savez pas où se trouve le plus de profit pour votre entreprise ? Vous pouvez prendre des décisions, mais elles ne seront pas aussi efficaces que les décisions prises lorsque vous avez une vue plus complète du trafic du site.
L'estimation des revenus du trafic organique sans marque peut être combinée avec vos pages de destination et la segmentation des requêtes pour fournir une vue d'ensemble qui vous aidera à développer de meilleures stratégies en tant que responsable SEO ou stratège SEO.
Les différentes façons de prévoir le trafic organique
Il existe de nombreuses méthodes et scripts publics différents dans la communauté SEO pour prédire le futur trafic organique.
Certaines de ces méthodes incluent :
- Prévision de trafic organique sur l'ensemble du site
- Prévision de trafic organique sur des pages spécifiques (blog, produits, catégories, etc.) ou une seule page
- Prévision de trafic organique sur les requêtes spécifiques (les requêtes contiennent "acheter", "comment faire", etc.) ou une requête
- Prévision de trafic organique pour des périodes spécifiques (en particulier pour les événements saisonniers)
Ma méthode est pour des pages spécifiques et le délai est d'un mois.
[Étude de cas] Stimuler la croissance sur de nouveaux marchés avec le référencement sur la page
 Lire l'étude de cas
Lire l'étude de casComment calculer les revenus du trafic organique
La manière précise est basée sur vos données Google Analytics (GA). Si votre site est tout nouveau, vous devrez utiliser des outils tiers. Je préfère éviter d'utiliser de tels outils lorsque vous avez vos propres données.
N'oubliez pas que vous devrez tester les données tierces que vous utilisez par rapport à certaines de vos données de page réelles pour trouver d'éventuelles erreurs dans leurs données.
Comment calculer les revenus du trafic SEO sans marque avec Python
Jusqu'à présent, nous avons couvert de nombreux concepts théoriques que nous devrions connaître afin de mieux comprendre les différents aspects de notre trafic organique et de nos prévisions de revenus. Passons maintenant à la partie pratique de cet article.
Tout d'abord, nous allons commencer par calculer notre courbe CTR. Dans mon article sur la courbe CTR sur Oncrawl, j'explique deux méthodes différentes ainsi que d'autres méthodes que vous pouvez utiliser en apportant quelques modifications à mon code. Je vous recommande de lire d'abord l'article sur la courbe de clic ; il vous donne un aperçu de cet article.
Dans cet article, je modifie certaines parties de mon code pour obtenir les résultats spécifiques que nous souhaitons dans l'estimation du trafic. Ensuite, nous obtiendrons nos données de GA et utiliserons la dimension des revenus GA pour estimer nos revenus.
Prévoir les revenus du trafic organique hors marque avec Python : pour commencer
Vous pouvez exécuter ce code par vous-même, sans connaître Python. Cependant, je préfère que vous connaissiez un peu la syntaxe Python et les connaissances de base sur les bibliothèques Python que j'utiliserai dans ce code de prévision. Cela vous aidera à mieux comprendre mon code et à le personnaliser d'une manière qui vous sera utile.
Pour exécuter ce code, je vais utiliser Visual Studio Code avec l'extension Python de Microsoft, qui inclut l'extension "Jupyter". Mais, vous pouvez utiliser le bloc-notes Jupyter lui-même.
Pour l'ensemble du processus, nous devons utiliser ces bibliothèques Python :
- Numpy
- Pandas
- comploter
De plus, nous importerons certaines bibliothèques standard Python :
- JSON
- imprimer
# Importation des bibliothèques dont nous avons besoin pour notre processus importer json depuis pprint importer pprint importer numpy en tant que np importer des pandas en tant que pd importer plotly.express en px
Etape 1 : Calcul de la courbe CTR relative (Relative click curve)
Dans la première étape, nous voulons calculer notre courbe CTR relative. Mais qu'est-ce que la courbe CTR relative ?
Qu'est-ce que la courbe CTR relative ?
Commençons d'abord par parler de la "courbe CTR absolue". Lorsque nous calculons la courbe CTR absolue, nous disons que le CTR médian (ou CTR moyen) de la première position est de 36 % et la deuxième position est de 20 %, et ainsi de suite.
Dans la courbe CTR relative, instant de pourcentage, nous divisons la médiane de chaque position par le CTR de la première position. Par exemple, la courbe CTR relative de la première position serait 0,36 / 0,36 = 1, la seconde serait 0,20 / 0,36 = 0,55, et ainsi de suite.
Peut-être vous demandez-vous pourquoi il est utile de calculer cela ? Pensez à une page classée en première position, qui a un CTR de 44 %. Si cette page passe en position deux, la courbe CTR ne diminue pas à 20 %, il est plus probable que son CTR diminue à 44 % * 0,55 = 24,2 %.
1. Obtenir des données de trafic organique de marque et sans marque de GSC
Pour notre processus de calcul, nous devons obtenir nos données auprès de GSC. La première fois, toutes les données seront basées sur des requêtes de marque et la prochaine fois, toutes les données seront basées sur des requêtes sans marque.
Pour obtenir ces données, vous pouvez utiliser différentes méthodes : à partir de scripts Python ou à partir du module complémentaire Google Sheets "Search Analytics for Sheets". J'utiliserai l'explorateur d'API GSC.
La sortie de ces données est constituée de deux fichiers JSON qui affichent les performances de chaque page. Un fichier JSON qui montre les performances des pages de destination en fonction des requêtes de marque et l'autre montre les performances des pages de destination en fonction des requêtes sans marque.
Pour obtenir des données à partir de l'explorateur d'API GSC, procédez comme suit :
- Accédez à https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Maximisez l'explorateur d'API qui se trouve dans le coin supérieur droit de la page.
- Dans le champ «
siteUrl», insérez votre nom de domaine. Par exemple «https://www.example.com» ou «http://your-domain.com». - Dans le corps de la requête, nous devons d'abord définir les paramètres "
startDate" et "endDate". Ma préférence va aux 30 derniers jours. - Ensuite, nous ajoutons «
dimensions» et sélectionnons «page» pour cette liste. - Nous ajoutons maintenant "
dimensionFilterGroups" pour filtrer nos requêtes. Une fois pour les requêtes de marque et une seconde pour les requêtes sans marque. - A la fin, nous fixons notre «
rowLimit» à 25 000. Si les pages de votre site qui génèrent du trafic organique chaque mois sont supérieures à 25 000, vous devez modifier le corps de votre requête. - Après avoir effectué chaque demande, enregistrez la réponse JSON. Pour des performances de marque, enregistrez le fichier JSON sous «
branded_data.json» et pour des performances sans marque, enregistrez le fichier JSON sous «non_branded_data.json».
Une fois que nous avons compris les paramètres de notre corps de requête, la seule chose que vous devez faire est de copier et coller sous les corps de requête. Envisagez de remplacer vos noms de marque par des « brand variation names ».
Vous devez séparer les noms de marque par un pipeline ou « | ”. Par exemple « amazon|amazon.com|amazn ».
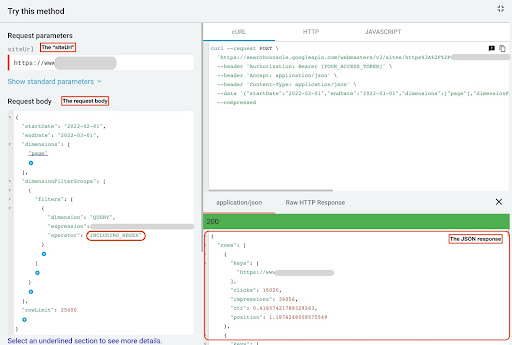
Explorateur d'API GSC
Corps de la demande de marque :
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"dimensions": [
"page"
],
"dimensionFilterGroups": [
{
"filtres": [
{
"dimension": "REQUETE",
"expression": "noms des variantes de la marque",
"opérateur": "INCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
Corps de requête sans marque :
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"dimensions": [
"page"
],
"dimensionFilterGroups": [
{
"filtres": [
{
"dimension": "REQUETE",
"expression": "noms des variantes de la marque",
"opérateur": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
2. Importation des données dans notre notebook Jupyter et extraction des répertoires de sites
Maintenant, nous devons charger nos données dans notre notebook Jupyter pour pouvoir les modifier et en extraire ce que nous voulons. Reprenons là où nous nous sommes arrêtés ci-dessus.
Pour charger des données de marque, vous devez exécuter ce bloc de code :
# Création d'un DataFrame pour les performances des URL du site Web sur la marque et les requêtes de marque
avec open("./branded_data.json") comme json_file :
branded_data = json.loads(json_file.read())["rows"]
branded_df = pd.DataFrame(branded_data)
# Renommer la colonne 'keys' en colonne 'landing page' et convertir la liste 'landing page' en URL
branded_df.rename(columns={"keys": "landing page"}, inplace=True)
branded_df["landing page"] = branded_df["landing page"].apply(lambda x : x[0])
Pour les performances des pages de destination sans marque, vous devrez exécuter ce bloc de code :
# Création d'un DataFrame pour les performances des URL du site Web sur les requêtes sans marque
avec open("./non_branded_data.json") comme json_file :
non_branded_data = json.loads(json_file.read())["rows"]
non_branded_df = pd.DataFrame(non_branded_data)
# Renommer la colonne 'keys' en colonne 'landing page' et convertir la liste 'landing page' en URL
non_branded_df.rename(columns={"keys": "landing page"}, inplace=True)
non_branded_df["landing page"] = non_branded_df["landing page"].apply(lambda x : x[0])
Nous chargeons nos données, puis nous devons définir le nom de notre site pour en extraire ses répertoires.
# Définir le nom de votre site entre guillemets. Par exemple, 'https://www.exemple.com/' ou 'http://mondomaine.com/' SITE_NAME = "https://www.votre_domaine.com/"
Nous avons seulement besoin d'extraire les répertoires de la performance sans marque.
# Obtenir le répertoire de chaque page de destination (URL)
non_branded_df["répertoire"] = non_branded_df["page de destination"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Ensuite, nous imprimons les répertoires afin de sélectionner ceux qui sont importants pour ce processus. Vous pouvez sélectionner tous les répertoires pour obtenir un meilleur aperçu de votre site.

# Pour obtenir tous les répertoires dans la sortie, nous devons manipuler les options de Pandas
pd.set_option("display.max_rows", Aucun)
# Annuaires de sites Web
non_branded_df["répertoire"].value_counts()
Ici, vous pouvez insérer les répertoires qui sont importants pour vous.
""" Choisissez les répertoires importants pour obtenir leur courbe CTR.
Insérez les répertoires dans la variable 'important_directories'.
Par exemple, 'produit,tag,catégorie de produit,mag'. Séparez les valeurs de répertoire par une virgule.
"""
IMPORTANT_DIRECTORIES = "vos_répertoires_importants"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3. Étiquetage des pages en fonction de leur position et calcul de la courbe CTR relative
Nous devons maintenant étiqueter nos pages de destination en fonction de leur position. Nous le faisons, car nous devons calculer la courbe CTR relative pour chaque répertoire en fonction de la position de sa page de destination.
# Étiquetage des postes sans marque
pour je dans la plage (1, 11):
non_branded_df.loc[
(non_branded_df["position"] >= je) & (non_branded_df["position"] < je + 1),
"étiquette de position",
] = je
Ensuite, nous regroupons les pages de destination en fonction de leur répertoire.
# Regroupement des pages de destination en fonction de leur valeur "répertoire" non_brand_grouped_df = non_branded_df.groupby(["répertoire"])
Définissons la fonction pour calculer la courbe CTR relative.
def each_dir_relative_ctr_curve(dir_df, clé):
"""La fonction calcule chaque courbe CTR relative IMPORTANT_DIRECTORIES.
"""
# Regroupement "non_brand_grouped_df" en fonction de leur valeur 'position label'
dir_grouped_df = dir_df.groupby(["position étiquette"])
# Une liste pour enregistrer chaque CTR médian de position
median_ctr_list = []
# Stockage de chaque répertoire sous forme de clé, et c'est "median_ctr_list" comme valeur
répertoires_médian_ctr = {}
# Boucle sur chaque groupe "dir_grouped_df"
pour je dans la plage (1, 11):
# Un try-except pour gérer les situations dans lesquelles un répertoire, par exemple, n'a aucune donnée pour la position 4
essayer:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
à l'exception:
median_ctr_list.append(0)
# Calcul de la courbe CTR relative
directories_median_ctr[clé] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
renvoie répertoires_médian_ctr
Après avoir défini la fonction, nous l'exécutons.
# Boucle sur les répertoires et exécution de la fonction 'each_dir_relative_ctr_curve'
répertoires_median_ctr_dict = dict()
pour la clé, élément dans non_brand_grouped_df :
si clé dans IMPORTANT_DIRECTORIES :
directories_median_ctr_dict.update(each_dir_relative_ctr_curve(item, key))
pprint(directories_median_ctr_dict)
Maintenant, nous allons charger nos pages de destination, avec et sans marque, les performances et calculer la courbe CTR relative pour nos données sans marque. Pourquoi faisons-nous cela uniquement pour les données non liées à la marque ? Parce que nous voulons prédire le trafic et les revenus organiques hors marque.
Étape 2 : Prédire les revenus du trafic organique sans marque
Dans cette deuxième étape, nous verrons comment récupérer nos données de revenus et prévoir nos revenus.
1. Fusionner les données organiques avec et sans marque
Maintenant, nous allons fusionner nos données de marque et sans marque. Cela nous aidera à calculer le pourcentage de trafic organique sans marque sur chaque page de destination par rapport à l'ensemble du trafic.
# 'main_df' est une combinaison de 'données complètes du site' et de 'données non liées à la marque'.
# À l'aide de ce DataFrame, vous pouvez savoir où se trouvent la plupart de nos clics et impressions
# proviennent de requêtes qui ne portent pas de marque.
main_df = non_branded_df.merge(
branded_df, on="landing page", suffixes=("_non_brand", "_branded")
)
Ensuite, nous modifions les colonnes pour supprimer celles qui sont inutiles.
# Modification des colonnes 'main_df' pour celles dont nous avons besoin
main_df = main_df[
[
"page de destination",
"clicks_non_brand",
"ctr_non_brand",
"annuaire",
"étiquette de position",
"clicks_branded",
]
]
Maintenant, calculons le pourcentage de clics sans marque par rapport au nombre total de clics d'une page de destination.
# Calcul du pourcentage de clics sur les requêtes sans marque en fonction des pages de destination par rapport à l'ensemble des clics sur la page de destination
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x : x["clics_sans_marque"] / (x["clics_sans_marque"] + x["clics_sans_marque"]),
axe=1,
)
[Ebook] Automatiser le SEO avec Oncrawl
 Lire l'ebook
Lire l'ebook2. Charger les revenus du trafic organique
Tout comme pour récupérer les données GSC, nous avons plusieurs façons d'obtenir les données GA : nous pourrions utiliser le "module complémentaire Google Analytics Sheets" ou l'API GA. Dans ce tutoriel, je préfère utiliser Google Data Studio (GDS) en raison de sa simplicité.
Afin d'obtenir les données GA de GDS, procédez comme suit :
- Dans GDS, créez un nouveau rapport ou explorateur et une table.
- Pour la dimension ajouter « landing page » et pour la métrique, il faut ajouter « Revenue ».
- Ensuite, vous devrez créer un segment personnalisé dans GA en fonction de la source et du support. Filtrez le trafic "Google/organique". Après la création du segment, ajoutez-le à la section segment dans GDS.
- À l'étape finale, exportez le tableau et enregistrez-le sous «
landing_pages_revenue.csv».
Exportation csv des revenus des pages de destination
Chargeons nos données.
revenu_organique_df = pd.read_csv("./data/landing_pages_revenue.csv")
Maintenant, nous devons ajouter le nom de notre site aux URL des pages de destination GA.
Lorsque nous exportons nos données depuis GA, les pages de destination sont sous une forme relative, mais nos données GSC sont sous une forme absolue.
N'oubliez pas de vérifier les données de vos pages de destination GA. Dans les ensembles de données avec lesquels j'ai travaillé, j'ai constaté que les données GA avaient besoin d'un petit nettoyage à chaque fois.
# Concilier les URL des pages de destination GA avec le SITE_NAME.
# Aussi, renommer les colonnes
organic_revenue_df.loc[:, "Page de destination"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Landing Page": "landing page", "Revenue": "revenu"}, inplace=True)
Maintenant, fusionnons nos données GSC avec les données GA.
# Dans cette étape, je fusionne 'main_df' avec 'dk_organic_revenue_df' DataFrame qui contient le pourcentage de données de requêtes non liées à la marque main_df = main_df.merge(organic_revenue_df, on="landing page", how="left")
À la fin de cette section, nous faisons un petit nettoyage sur nos colonnes DataFrame.
# Un peu de nettoyage du DataFrame 'main_df'
main_df = main_df[
[
"page de destination",
"clicks_non_brand",
"ctr_non_brand",
"annuaire",
"étiquette de position",
"clicks_non_brand_percentage",
"revenu",
]
]
3. Calcul des revenus hors marque
Dans cette section, nous traiterons les données pour extraire les informations que nous recherchons.
Mais avant toute chose, filtrons nos landing pages en fonction de « IMPORTANT_DIRECTORIES » :
# Suppression des pages de destination des autres répertoires, non incluses dans "IMPORTANT_DIRECTORIES"
main_df = (
main_df[main_df["répertoire"].isin(IMPORTANT_DIRECTORIES)]
.dropna(sous-ensemble=["revenu"])
.reset_index(drop=True)
)
Maintenant, calculons le trafic de revenus organiques sans marque.
J'ai défini une métrique qu'on ne peut pas calculer facilement et c'est plus l'intuition qu'autre chose qui nous amène à lui attribuer un numéro.
La métrique " brand_influence " montre la force de votre marque. Si vous pensez que les recherches sans marque génèrent moins de ventes pour votre entreprise, réduisez ce nombre ; quelque chose comme 0,8 par exemple.
# Si votre marque est si forte que l'interrogation sans votre marque peut vendre autant que l'interrogation avec votre marque, alors 1 est bon pour vous.
# Pensez à rechercher un livre sans nom de marque inclus dans votre requête. Lorsque vous voyez Amazon, achetez-vous sur d'autres marketplaces ou magasins ?
marque_influence = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x : x["revenu"] * x["clics_non_brand_percentage"] * brand_influence, axe=1
)
Traçons un graphique à secteurs pour avoir un aperçu des revenus sans marque en fonction des annuaires importants.
# Dans cette cellule, je souhaite obtenir tous les revenus des pages de destination non liées à la marque en fonction de leur répertoire
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
index="répertoire",
valeurs=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "somme"},
)
tarte_fig = px.pie(
non_branded_directory_dist_revenue_df,
valeurs="non_brand_revenue",
names=non_branded_directory_dist_revenue_df.index,
title="Revenus hors marque basés sur les annuaires de sites Web",
)
pie_fig.update_traces(textposition="inside", textinfo="percent+label")
tarte_fig.show()
Ce graphique montre la distribution des requêtes sans marque sur votre IMPORTANT_DIRECTORIES .
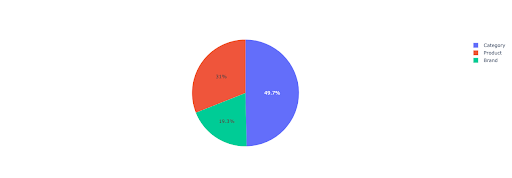
Distribution des requêtes sans marque
Sur la base de mes données de courbe CTR, je vois que je ne peux pas compter sur le CTR pour les positions supérieures à 5. Pour cette raison, je filtre mes données en fonction de la position.
Vous pouvez modifier le bloc de code ci-dessous en fonction de vos données.
# En raison de la précision du CTR dans notre courbe CTR, je pense que nous pouvons ignorer les atterrissages avec une position supérieure à 5. Pour cette raison, j'ai filtré d'autres pages d'atterrissage main_df = main_df[main_df["position label"] < 6].reset_index(drop=True)
4. Calcul du « revenu par clic » (RPC)
Ici, j'ai créé une métrique personnalisée et l'ai appelée "Revenu par clic" ou RPC. Cela nous montre les revenus générés par chaque clic sans marque.
Vous pouvez utiliser cette métrique de différentes manières. J'ai trouvé une page avec un RPC élevé, mais peu de clics. Lorsque j'ai vérifié la page, j'ai découvert qu'elle était indexée il y a moins d'une semaine et nous pouvons utiliser différentes méthodes pour optimiser la page.
# Calcul des revenus générés à chaque clic (RPC : Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x : x["revenu_non_marque"] / x["clics_non_marque"], axe=1
)
5. Prédire les revenus !
Nous arrivons au bout, nous avons attendu jusqu'à maintenant pour prédire nos revenus organiques hors marque.
Exécutons les derniers blocs de code.
# La fonction principale pour calculer les revenus en fonction de différentes positions
pour index, row_values dans main_df.iterrows() :
# Basculer entre les répertoires Liste CTR
ctr_curve = directories_median_ctr_dict[row_values["directory"]]
# Bouclez sur la position 1 à 5 et calculez les revenus en fonction de l'augmentation ou de la diminution du CTR
pour i dans la plage (1, 6):
si je == row_values["position label"] :
main_df.loc[index, i] = row_values["non_brand_revenue"]
autre:
# main_df.loc[index, je + 1] ==
main_df.loc[index, je] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["position label"] - 1)]
)
# Calcul de la métrique "N à 1". Cela montre l'augmentation des revenus lorsque votre classement passe de "N" à "1"
main_df.loc[index, "N à 1"] = main_df.loc[index, 1] - main_df.loc[index, row_values["position label"]]
En regardant la sortie finale, nous avons de nouvelles colonnes. Les noms de ces colonnes sont "1", "2", "3", "4", "5".
Que signifient ces noms ? Par exemple, nous avons une page en position 3 et nous voulons prédire ses revenus si elle améliore sa position, ou nous voulons savoir combien nous perdrons si nous perdons en classement.
Les colonnes « 1 » et « 2 » montrent les revenus de la page quand la position moyenne de cette page s'améliore et les colonnes « 4 » et « 5 » montrent les revenus de cette page quand on baisse dans le classement.
La colonne "3" de cet exemple indique les revenus actuels de la page.
De plus, j'ai créé une métrique appelée "N à 1". Cela vous indique si la position moyenne de cette page passe de "3" (ou N) à "1" et dans quelle mesure ce déplacement peut affecter les revenus.
Emballer
J'ai couvert beaucoup de choses dans cet article et maintenant c'est à vous de vous salir les mains et de prédire vos revenus de trafic organique sans marque.
C'est la manière la plus simple d'utiliser cette prédiction. Nous pourrions rendre cet algorithme plus complexe et le combiner avec certains modèles ML, mais cela rendrait l'article plus compliqué.
Je préfère enregistrer ces données dans un CSV et les télécharger sur une feuille Google. Ou, si je prévois de le partager avec les autres membres de mon équipe ou de l'organisation, je l'ouvrirai avec Excel et formaterai les colonnes en utilisant des couleurs pour qu'il soit plus facile à lire.
Sur la base de ces données, vous pouvez prédire le retour sur investissement de votre trafic organique sans marque et l'utiliser dans votre processus de négociation.