
Rapport Google Crawl Stats vs analyse des fichiers journaux : quel est le gagnant ?
Publié: 2020-12-22Le 24 novembre, Google a publié une nouvelle version de son rapport Search Console Crawl Stats. Cette mise à jour vous fournit des données que vous pouvez utiliser pour déboguer les problèmes d'exploration et vérifier la santé de votre site.
La version précédente indiquait uniquement le nombre de pages crawlées par jour, les kilo-octets téléchargés par jour, le temps passé à télécharger les pages par jour.
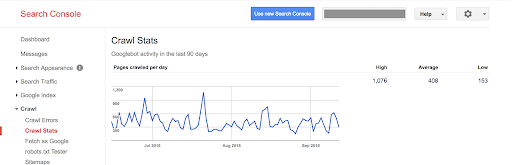
Avec cette nouvelle version, les mêmes informations sont disponibles avec une apparence et une convivialité mises à jour pour correspondre au reste de la Search Console :
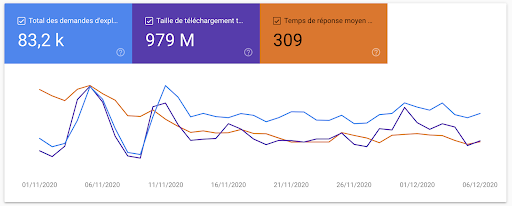
Mais cela ne s'arrête pas là. Google fournit beaucoup plus d'informations sur la façon dont ils explorent votre site. Et avec autant d'informations disponibles directement auprès de Google, la question se pose : avons-nous toujours besoin de fichiers journaux ?
Commençons par examiner le nouveau rapport lui-même.
Tout ce que vous devez savoir sur le rapport Google Search Console Crawl Stats
Où pouvez-vous trouver le nouveau rapport Crawl Stats ?
Le nouveau rapport de statistiques d'exploration est automatiquement disponible pour toute personne disposant d'un compte Google Search Console.
Connectez-vous à la Search Console et accédez à "Paramètres" dans la barre latérale de gauche. Cliquez ensuite sur "Crawl Stats".
Que contient le nouveau rapport Crawl Stats ?
Pour vous aider à trouver votre chemin dans les nouvelles informations détaillées, nous vous recommandons la procédure pas à pas de Tomek Rudzki sur Twitter :
Les nouvelles statistiques de GSC Crawl sont impressionnantes !
La première capture d'écran est similaire à la version précédente du rapport, mais il y a des joyaux cachés dans d'autres rapports
1/n pic.twitter.com/oCNzMhnGsQ– Tomek Rudzki (@TomekRudzki) 24 novembre 2020
Tomek met en évidence de nouveaux cas d'utilisation de données et de référencement pour chacun :
- Hôtes avec le plus de hits Googlebot : trouvez les sous-domaines les plus fréquemment explorés par Google.
- Codes d'état renvoyés à Googlebot : découvrez quel pourcentage de votre budget d'exploration est utilisé par les réponses autres que 200 (c'est-à-dire : les redirections, les pages manquantes et les erreurs).
- Type de fichier : comprenez à quelle fréquence Googlebot demande des fichiers de ressources tels que des fichiers CSS, des fichiers JavaScript et des images.
- Le but de la visite Googlebot : savoir si Google découvre de nouveaux contenus ou actualise des contenus qu'il connaît déjà.
- La répartition entre les requêtes effectuées par le Googlebot pour smartphone et celles effectuées par le Googlebot pour ordinateur : confirmez si votre site est prêt pour le passage complet à l'indexation Mobile-First en mars 2021.
- Un échantillon d'URL explorées : faites-vous une idée de certaines des URL récemment explorées sur votre site.
- Statut de l'hôte : une nouvelle métrique qui indique si votre serveur a récemment rencontré des problèmes. Par exemple, cela prend en compte la disponibilité de robots.txt et la résolution DNS.
Nos trois choses préférées à propos du rapport Crawl Stats
Il y a trop d'avantages offerts par le Crawl Stats Report pour tous les énumérer, en particulier si vous n'avez pas accès aux fichiers journaux. Mais voici nos trois meilleurs :
1. Ce rapport s'adresse à tous.
Il fournit des statistiques d'exploration Googlebot de haut niveau et faciles à lire. Il est clair quand les choses vont bien et quand il y a des problèmes qui pourraient devoir être résolus. Dans certains cas, cela va encore plus loin : par exemple, il fournit des indications telles que les indicateurs d'état vert/jaune/rouge pour l'état de l'hôte.
Même si vous débutez dans le suivi du budget des bots et des crawls, vous ne devriez pas être perdu lorsque vous consultez ces rapports.
2. La documentation est excellente.
La documentation répond non seulement à 99% de vos questions, mais elle donne également les meilleures pratiques et des conseils pour la santé du serveur, les drapeaux rouges, la gestion de la fréquence d'exploration et les querelles de base de googlebot.
3. Données sur le "pourquoi" derrière les requêtes Googlebot
Nous pouvons suivre Googlebot, mais de nombreuses conclusions quant à la raison pour laquelle Google visite une page doivent être tirées sur la base de données limitées. La section Crawl By Purpose et les requêtes de rendu visibles sous « Page Resource Load » apportent une réponse non ambiguë à certaines de nos questions. Nous savons maintenant avec certitude si Google découvre une page, met à jour la page ou télécharge une ressource lors d'une seconde passe distincte afin de rendre la page.
[Étude de cas] Gérer le bot crawling de Google
 Lire l'étude de cas
Lire l'étude de casQuelle est la différence entre les informations disponibles dans les fichiers journaux et le rapport Crawl Stats ?
Les statistiques de crawl sont limitées aux Googlebots
Statistiques d'exploration : 0
Journaux : 1
Les fichiers journaux de votre serveur enregistrent chaque demande pour l'un des fichiers et ressources qui composent votre site Web, peu importe d'où ils proviennent. Cela signifie que les journaux peuvent vous en dire plus que Googlebot.
Cependant, le rapport Crawl Stats de Google est (naturellement !) limité à la propre activité de Google sur votre site.
Voici quelques informations que vous pouvez obtenir à partir des fichiers journaux qui n'apparaissent pas dans les statistiques d'exploration :
- Informations sur d'autres moteurs de recherche, tels que Bing. Vous pouvez voir comment ils explorent votre site, mais aussi voir en quoi leur comportement diffère ou s'aligne sur celui de Googlebot :
Logflare est tellement utile. Intéressant de voir le comportement d'exploration différent des Googlebots par rapport aux Bingbots dans les journaux en direct. Googlebot voit 301, puis la prochaine URL renvoyée est l'URL redirigée vers, mais Bingbot ne semble pas le faire. Voit juste le 301 et puis va ailleurs
– Aube Anderson (@dawnieando) 22 janvier 2020
- Informations sur les outils (et les concurrents) qui tentent d'explorer votre site. Étant donné que les informations disponibles ne se limitent pas à Googlebot, vous pouvez également voir si d'autres robots sont actifs sur votre site.
- Informations sur les pages de référence. Cela peut vous aider à trouver plus d'informations sur vos backlinks les plus actifs. En HTTPS, la dernière page visitée, ou la « page de référence » est également enregistrée avec chaque requête.
- Des informations sur le trafic organique… et pas seulement sur le trafic de Google ! À l'aide des pages de renvoi, vous pouvez identifier le trafic provenant des pages de résultats des moteurs de recherche et mieux voir comment ces visiteurs interagissent avec votre site. Ce type d'informations peut être utilisé pour confirmer ou corriger les chiffres fournis par votre solution Analytics, si vous en utilisez une.
- Identification des pages orphelines. Étant donné que vos journaux contiennent toutes les URL demandées par les visiteurs, toutes les pages "actives" avec un trafic de robots ou humain qui ne sont pas liées à la structure de votre site apparaîtront dans vos journaux. En comparant une liste d'URL dans vos fichiers journaux à une liste d'URL dans la structure de votre site à partir d'un crawl, il sera facile de repérer les pages orphelines.
Complet et à jour ?
Statistiques d'exploration : 0
Bûches : 2
Vos données sont-elles complètes et à jour ? Vos journaux sont. Et vos statistiques de crawl pourraient l'être.

De nombreuses personnes ont rapidement remarqué des différences de 20 à 40 % entre le rapport de la console de recherche Google et leurs fichiers journaux : le rapport Crawl Stats sous-évalue l'activité de Googlebot pour le moment. Il s'agit d'un problème connu dans les statistiques de crawl, mais pas dans vos journaux !
De plus, comme toutes les informations de la Search Console, il peut y avoir un décalage entre la dernière date de données disponible et la date du jour. Jusqu'à présent, nous avons constaté une différence allant jusqu'à huit jours dans le rapport Crawl Stats.
En revanche, vous pouvez utiliser vos fichiers journaux pour une surveillance en temps réel : il n'y a jamais de retard !
Listes agrégées ou complètes d'URL explorées
Statistiques d'exploration : 0
Bûches : 3
Les Crawl Stats fournissent des données agrégées pour toutes vos URL. Le rapport équivaut à un tableau de bord. Lorsque vous allez chercher la liste des URL derrière une métrique donnée, vous verrez une liste d'"exemples". Par exemple, vous pourriez avoir quelques centaines d'exemples de vos requêtes 4.56K pour des fichiers image :
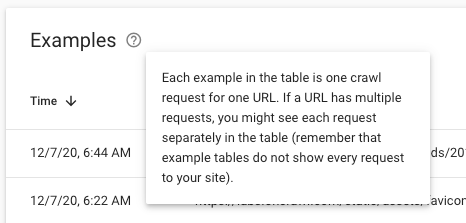
Cependant, dans les fichiers journaux, vous disposez d'une liste complète des URL derrière n'importe quelle métrique. Vous pouvez voir TOUTES les demandes dans vos journaux, pas seulement un échantillon.
Filtrage par régions, dates, URL…
Statistiques d'exploration : 0
Bûches : 4
Pour être vraiment utiles, les Crawl Stats pourraient bénéficier de filtres plus larges qui s'appliquent à toutes les requêtes, pas seulement aux échantillons : 
Ce serait bien d'avoir plus de flexibilité pour :
- Modifier la plage de dates que nous examinons
- Focus sur une zone géographique donnée par recherche IP
- Mieux filtrer par groupes d'URL
- Appliquer les options de filtre aux graphiques
Vous pouvez faire tout cela - et bien plus encore - dans les fichiers journaux.
Informations spécifiques à Googlebot
Statistiques d'exploration : 1
Bûches : 4
Comme nous l'avons vu, Google utilise le Crawl Stats Report pour fournir des informations sur l'objectif de son crawl :
- Actualisation vs découverte
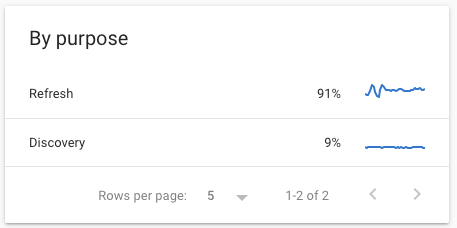
- Ressources de page (récupération secondaire)

Ces informations ne peuvent être trouvées nulle part ailleurs, quelle que soit l'intelligence avec laquelle vous examinez les données de vos fichiers journaux.
Un accès facile
Statistiques d'exploration : 2
Bûches : 4
L'accès au rapport Crawl Stats est simple : les Crawl Stats sont automatiquement disponibles pour toute personne ayant accès à la Search Console.
Techniquement, les fichiers journaux devraient également être disponibles pour tout webmaster. Mais ce n'est souvent pas le cas. Souvent, les équipes de développement, les équipes informatiques ou les entreprises clientes ne comprennent pas l'importance de fournir un accès aux fichiers journaux. Dans des régions comme l'UE, où les lois sur la protection de la vie privée restreignent l'accès aux "données personnellement identifiables", comme les adresses IP, l'accès aux fichiers journaux peut poser un problème juridique. Vous pouvez utiliser certains outils, comme OnCrawl, qui ne stocke pas d'informations sensibles.
Une fois que vous avez accès aux fichiers journaux, il existe des outils gratuits pour analyser les données, et il existe peu de formats propriétaires. En d'autres termes, les fichiers journaux sont une source de données assez démocratique… une fois que vous avez mis la main dessus.
C'est un fait : de nombreux référenceurs ont du mal à accéder aux logs. Ainsi, alors que, théoriquement, les fichiers journaux offrent un accès facile aux données, le point sur celui-ci va au Crawl Stats Report, qui est disponible en deux clics depuis l'outil gratuit de Google.
Analyseur de journaux Oncrawl
 Apprendre encore plus
Apprendre encore plusPas (encore) disponible pour intégration dans d'autres outils et analyses
Statistiques d'exploration : 2
Bûches : 5
Google Search Console permet d'exporter et de télécharger les informations disponibles via l'interface web du Crawl Stats Report. Cela signifie, cependant, que les informations téléchargées ont les mêmes limites que les versions à l'écran.
De plus, les Crawl Stats ne sont pas (encore ?) disponibles via l'API, il peut donc être difficile de connecter ces informations à des processus automatisés de reporting et d'analyse, voire de les sauvegarder pour une vue plus large des données historiques.
Avec les fichiers journaux, le stockage, l'accès et la réutilisation dépendent généralement de vous. Cela rend les fichiers journaux beaucoup plus faciles à utiliser lors de la fusion avec d'autres sources de données telles que le suivi du classement, les données d'exploration ou les données d'analyse. Ils sont également plus faciles à intégrer dans les flux de reporting, de tableau de bord et de visualisation des données.
Le gagnant final : les fichiers journaux !
Avec cinq points à seulement deux points pour le rapport Crawl Stats, les fichiers journaux sont clairement gagnants ici si vous voulez un aperçu complet de la façon dont les moteurs de recherche interagissent avec votre site.
Mais soyons clairs : le rapport Crawl Stats mis à jour fournit de nombreuses nouvelles informations : codes d'état, types de fichiers, sous-domaines (pour les propriétés de domaine), détails sur l'état de l'hôte, etc. Il vous donne des informations plus granulaires et des données exploitables pour comprendre comment votre site Web est exploré et maintenant, vous pouvez suivre les changements dans les modèles d'exploration.
Ce sera un énorme pas en avant pour les personnes qui ne peuvent pas accéder à leurs fichiers journaux ou à ceux de leurs clients.
Cependant, ce ne sont pas tous des pros !
Avantages et inconvénients des nouvelles statistiques d'exploration GSC : https://t.co/bjpG7QjeVt
Avantages:
+Métriques de données améliorées
+Meilleur UX (barre basse TBH)
+Données téléchargeables des URL explorées !
+ Répartition des requêtes de crawl
+ Problèmes d'hôte importants notésLes inconvénients:
-Aucun filtre pour les plages de dates
-Pas d'options de filtre pour changer les graphiques– Micah Fisher-Kirshner (@micahfk) 24 novembre 2020
Les inconvénients du nouveau rapport sont que, bien qu'il s'agisse d'un bon tableau de bord pour la surveillance de Googlebot et d'un excellent ajout pour compléter l'analyse des fichiers journaux, il est limité à bien des égards. N'oubliez pas que seuls vos fichiers journaux vous montreront toutes vos requêtes par URL plutôt qu'une tendance globale.
De plus, il existe un problème connu dans le rapport GSC où certaines demandes ne sont pas comptées pour le moment, et les données peuvent prendre - au moment de la rédaction de cet article - jusqu'à une semaine pour apparaître dans le rapport Crawl Stats. (Cependant, nous sommes convaincus que Google travaille sur ces problèmes et qu'ils disparaîtront bientôt !)
Voici ce que nous recommandons : utilisez ce rapport pour savoir exactement ce qu'il faut rechercher dans vos fichiers journaux. Et puis plongez dans votre analyse de logs !