
Comment extraire le contenu textuel pertinent d'une page HTML ?
Publié: 2021-10-13Le contexte
Au sein du service R&D d'Oncrawl, nous cherchons de plus en plus à valoriser le contenu sémantique de vos pages web. En utilisant des modèles de machine learning pour le traitement du langage naturel (TAL), il est possible de réaliser des tâches à réelle valeur ajoutée pour le SEO.
Ces tâches comprennent des activités telles que :
- Affiner le contenu de vos pages
- Faire des résumés automatiques
- Ajout de nouveaux tags à vos articles ou correction de ceux existants
- Optimiser le contenu en fonction de vos données Google Search Console
- etc.
La première étape de cette aventure consiste à extraire le contenu textuel des pages Web que ces modèles d'apprentissage automatique utiliseront. Lorsque nous parlons de pages Web, cela inclut le HTML, JavaScript, les menus, les médias, l'en-tête, le pied de page, … Extraire automatiquement et correctement du contenu n'est pas facile. A travers cet article, je propose d'explorer le problème et de discuter de quelques outils et recommandations pour accomplir cette tâche.
Problème
Extraire du contenu textuel d'une page Web peut sembler simple. Avec quelques lignes de Python, par exemple, quelques expressions régulières (regexp), une bibliothèque d'analyse comme BeautifulSoup4, et c'est fait.
Si vous ignorez quelques minutes le fait que de plus en plus de sites utilisent des moteurs de rendu JavaScript comme Vue.js ou React, parser du HTML n'est pas bien compliqué. Si vous souhaitez contourner ce problème en profitant de notre crawler JS dans vos crawls, je vous propose de lire « Comment crawler un site en JavaScript ? ».
Cependant, nous voulons extraire un texte qui a du sens, qui est aussi informatif que possible. Lorsque vous lisez un article sur le dernier album posthume de John Coltrane, par exemple, vous ignorez les menus, le pied de page, … et évidemment, vous ne visualisez pas tout le contenu HTML. Ces éléments HTML qui apparaissent sur presque toutes vos pages sont appelés passe-partout. On veut s'en débarrasser et n'en garder qu'une partie : le texte qui porte les informations pertinentes.
C'est donc uniquement ce texte que nous souhaitons transmettre aux modèles d'apprentissage automatique pour traitement. C'est pourquoi il est primordial que l'extraction soit la plus qualitative possible.
Solutions
Globalement, on aimerait se débarrasser de tout ce qui « traîne » dans le texte principal : menus et autres barres latérales, éléments de contact, liens de pied de page, etc. Il existe plusieurs méthodes pour cela. Nous sommes surtout intéressés par les projets Open Source en Python ou JavaScript.
jusText
jusText est une implémentation proposée en Python à partir d'une thèse de doctorat : "Removing Boilerplate and Duplicate Content from Web Corpora". La méthode permet de catégoriser les blocs de texte du HTML comme "bon", "mauvais", "trop court" selon différentes heuristiques. Ces heuristiques sont principalement basées sur le nombre de mots, le rapport texte/code, la présence ou l'absence de liens, etc. Vous pouvez en savoir plus sur l'algorithme dans la documentation.
trafilature
trafilatura, également créé en Python, offre des heuristiques sur le type d'élément HTML et son contenu, par exemple la longueur du texte, la position/profondeur de l'élément dans le HTML ou le nombre de mots. trafilatura utilise également jusText pour effectuer certains traitements.
lisibilité
Avez-vous déjà remarqué le bouton dans la barre d'URL de Firefox ? C'est le Reader View : il permet de supprimer le passe-partout des pages HTML pour ne conserver que le contenu textuel principal. Assez pratique à utiliser pour les sites d'actualités. Le code derrière cette fonctionnalité est écrit en JavaScript et est appelé lisibilité par Mozilla. Il s'appuie sur des travaux initiés par le laboratoire Arc90.
Voici un exemple de rendu de cette fonctionnalité pour un article du site France Musique. 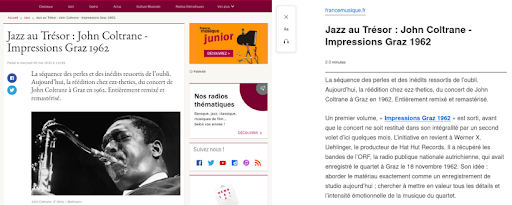
A gauche, c'est un extrait de l'article original. Sur la droite, il s'agit d'un rendu de la fonctionnalité Reader View de Firefox.
Les autres
Nos recherches sur les outils d'extraction de contenu HTML nous ont également amené à envisager d'autres outils :
- journal : une bibliothèque d'extraction de contenu plutôt dédiée aux sites d'actualités (Python). Cette bibliothèque a été utilisée pour extraire le contenu du corpus OpenWebText2.
- boilerpy3 est un port Python de la bibliothèque boilerpipe.
- bibliothèque dragnet Python également inspirée de boilerpipe.
Oncrawl Data³
 Apprendre encore plus
Apprendre encore plusÉvaluation et recommandations
Avant d'évaluer et de comparer les différents outils, nous avons voulu savoir si la communauté du TAL utilise certains de ces outils pour préparer son corpus (grand ensemble de documents). Par exemple, l'ensemble de données appelé The Pile utilisé pour former GPT-Neo contient +800 Go de textes anglais de Wikipedia, Openwebtext2, Github, CommonCrawl, etc. Comme BERT, GPT-Neo est un modèle de langage qui utilise des transformateurs de type. Il offre une implémentation open source similaire à l'architecture GPT-3.

L'article « The Pile : An 800GB Dataset of Diverse Text for Language Modeling » mentionne l'utilisation de jusText pour une grande partie de leur corpus de CommonCrawl. Ce groupe de chercheurs avait également prévu de faire un benchmark des différents outils d'extraction. Malheureusement, ils n'ont pas été en mesure de faire le travail prévu en raison du manque de ressources. Dans leurs conclusions, il convient de noter que :
- jusText supprimait parfois trop de contenu mais fournissait toujours une bonne qualité. Compte tenu de la quantité de données dont ils disposaient, cela ne leur posait aucun problème.
- trafilatura préservait mieux la structure de la page HTML mais gardait trop de passe-partout.
Pour notre méthode d'évaluation, nous avons pris une trentaine de pages web. Nous avons extrait le contenu principal "manuellement". Nous avons ensuite comparé l'extraction de texte des différents outils avec ce contenu dit « de référence ». Nous avons utilisé le score ROUGE, qui est principalement utilisé pour évaluer les résumés de texte automatiques, comme métrique.
Nous avons également comparé ces outils avec un outil « maison » basé sur des règles d'analyse HTML. Il s'avère que trafilatura, jusText et notre outil maison s'en sortent mieux que la plupart des autres outils pour cette métrique.
Voici un tableau des moyennes et écarts-types du score ROUGE :
| Outils | Moyenne | Std |
|---|---|---|
| trafilature | 0,783 | 0,28 |
| Exploration | 0,779 | 0,28 |
| jusText | 0,735 | 0,33 |
| chaudièrepy3 | 0,698 | 0,36 |
| lisibilité | 0,681 | 0,34 |
| drague | 0,672 | 0,37 |
Au vu des valeurs des écarts-types, notez que la qualité de l'extraction peut fortement varier. La façon dont le HTML est implémenté, la cohérence des balises et l'utilisation appropriée du langage peuvent entraîner de nombreuses variations dans les résultats de l'extraction.
Les trois outils les plus performants sont trafilatura, notre outil maison nommé « oncrawl » pour l'occasion et jusText. Comme jusText est utilisé comme alternative par trafilatura, nous avons décidé d'utiliser trafilatura comme premier choix. Cependant, lorsque ce dernier échoue et extrait zéro mot, nous utilisons nos propres règles.
A noter que le code trafilatura propose également un benchmark sur plusieurs centaines de pages. Il calcule les scores de précision, le score f1 et la précision en fonction de la présence ou de l'absence de certains éléments dans le contenu extrait. Deux outils se distinguent : trafilatura et goose3. Vous pouvez également lire :
- Choisir le bon outil pour extraire du contenu du Web (2020)
- le référentiel Github : benchmark d'extraction d'articles : bibliothèques open-source et services commerciaux
conclusion
La qualité du code HTML et l'hétérogénéité du type de page rendent difficile l'extraction d'un contenu de qualité. Comme l'ont découvert les chercheurs d'EleutherAI, à l'origine de The Pile et GPT-Neo, il n'existe pas d'outils parfaits. Il existe un compromis entre le contenu parfois tronqué et le bruit résiduel dans le texte lorsque tout le passe-partout n'a pas été supprimé.
L'avantage de ces outils est qu'ils sont sans contexte. Cela signifie qu'ils n'ont besoin d'aucune donnée autre que le code HTML d'une page pour en extraire le contenu. A partir des résultats d'Oncrawl, on pourrait imaginer une méthode hybride utilisant les fréquences d'occurrence de certains blocs HTML dans toutes les pages du site pour les classer en passe-partout.
Quant aux jeux de données utilisés dans les benchmarks que nous avons rencontrés sur le Web, il s'agit souvent du même type de page : articles d'actualité ou billets de blog. Ils n'incluent pas forcément les sites d'assurance, d'agence de voyage, de e-commerce etc. dont le contenu textuel est parfois plus compliqué à extraire.
Au regard de notre benchmark et faute de moyens, nous sommes conscients qu'une trentaine de pages ne suffisent pas pour avoir une vision plus détaillée des scores. Idéalement, nous aimerions avoir un plus grand nombre de pages Web différentes pour affiner nos valeurs de référence. Et nous aimerions également inclure d'autres outils tels que goose3, html_text ou inscriptis.