
Signification statistique des tests A/B : comment et quand terminer un test
Publié: 2020-05-22
Dans notre analyse récente de 28 304 expériences menées par des clients de Convert, nous avons constaté que seulement 20 % des expériences atteignaient le niveau de signification statistique de 95 %. Econsultancy a découvert une tendance similaire dans son rapport d'optimisation 2018. Les deux tiers de ses répondants voient un «gagnant clair et statistiquement significatif» dans seulement 30% ou moins de leurs expériences.
Ainsi, la plupart des expériences (70 à 80 %) sont soit non concluantes, soit arrêtées prématurément.
Parmi ceux-ci, ceux arrêtés tôt constituent un cas curieux, car les optimiseurs prennent l'appel pour mettre fin aux expériences quand ils le jugent bon. Ils le font lorsqu'ils peuvent soit "voir" un gagnant (ou un perdant) clair, soit un test clairement insignifiant. Habituellement, ils ont aussi des données pour le justifier.
Cela n'est peut-être pas si surprenant, étant donné que 50 % des optimiseurs n'ont pas de "point d'arrêt" standard pour leurs expériences. Pour la plupart, cela est une nécessité, en raison de la pression de devoir maintenir une certaine vitesse de test (XXX tests/mois) et de la course à la domination de leurs concurrents.
Ensuite, il y a aussi la possibilité qu'une expérience négative nuise aux revenus. Nos propres recherches ont montré que les expériences non gagnantes, en moyenne, peuvent entraîner une baisse de 26 % du taux de conversion !
Tout compte fait, mettre fin aux expériences tôt est toujours risqué…
… parce qu'il laisse la probabilité que l'expérience ait couru sa durée prévue, alimentée par la bonne taille d'échantillon, son résultat aurait pu être différent.
Alors, comment les équipes qui mettent fin tôt aux expériences savent-elles quand il est temps de les terminer ? Pour la plupart, la réponse réside dans l'élaboration de règles d'arrêt qui accélèrent la prise de décision, sans compromettre sa qualité.
S'éloigner des règles d'arrêt traditionnelles
Pour les expériences Web, une valeur de p de 0,05 sert de norme. Cette tolérance d'erreur de 5 % ou le niveau de signification statistique de 95 % aide les optimiseurs à maintenir l'intégrité de leurs tests. Ils peuvent s'assurer que les résultats sont des résultats réels et non des coups de chance.
Dans les modèles statistiques traditionnels pour les tests à horizon fixe - où les données de test sont évaluées une seule fois à une heure fixe ou à un nombre spécifique d'utilisateurs engagés - vous accepterez un résultat comme significatif lorsque vous avez une valeur de p inférieure à 0,05. À ce stade, vous pouvez rejeter l'hypothèse nulle selon laquelle votre contrôle et votre traitement sont identiques et que les résultats observés ne sont pas le fruit du hasard.
Contrairement aux modèles statistiques qui vous permettent d'évaluer vos données au fur et à mesure de leur collecte, ces modèles de test vous interdisent de consulter les données de votre expérience pendant son exécution. Cette pratique - également connue sous le nom de peeking - est déconseillée dans de tels modèles car la valeur de p fluctue presque quotidiennement. Vous verrez qu'une expérience sera significative un jour et le lendemain, sa valeur de p augmentera jusqu'à un point où elle ne sera plus significative.
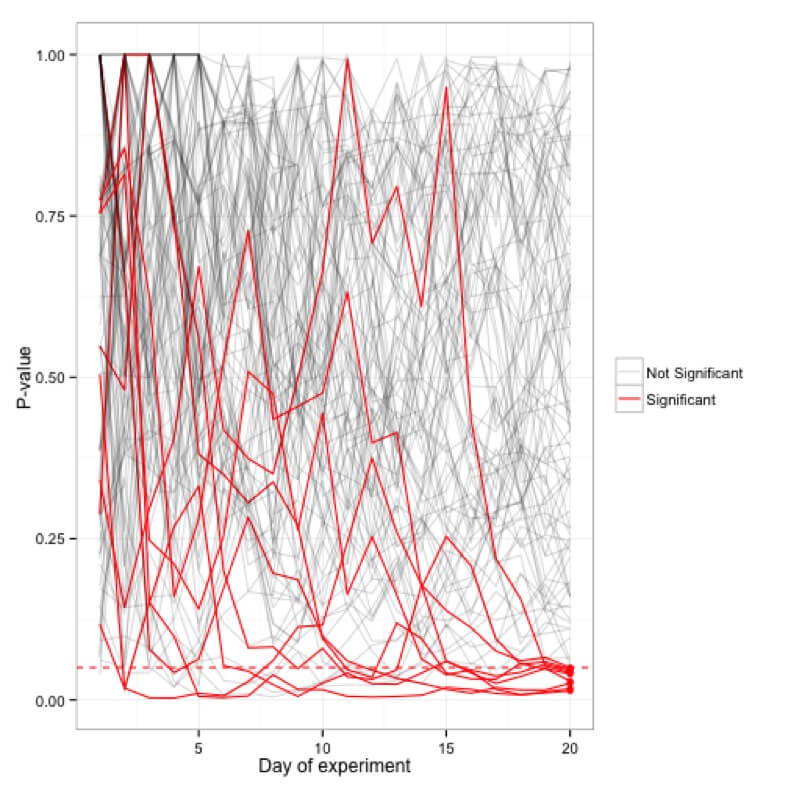
Simulations des valeurs p tracées pour une centaine d'expériences (20 jours) ; seules 5 expériences finissent par être significatives au bout de 20 jours, tandis que beaucoup atteignent parfois le seuil <0,05 dans l'intervalle.
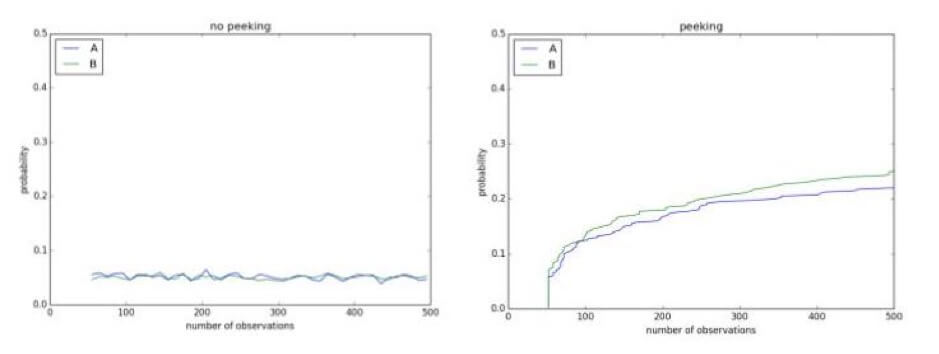
Jeter un coup d'œil à vos expériences dans l'intervalle peut montrer des résultats qui n'existent pas. Par exemple, ci-dessous, vous avez un test A/A utilisant un niveau de signification de 0,1. Puisqu'il s'agit d'un test A/A, il n'y a pas de différence entre le contrôle et le traitement. Cependant, après 500 observations au cours de l'expérience en cours, il y a plus de 50 % de chances de conclure qu'ils sont différents et que l'hypothèse nulle peut être rejetée :
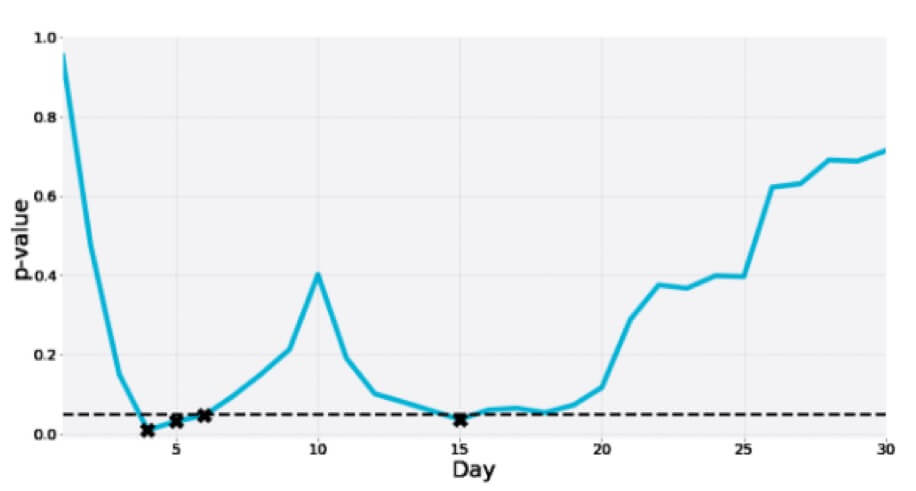
Voici un autre test A/A de 30 jours où la valeur de p chute plusieurs fois dans la zone de signification entre-temps pour finalement être bien supérieure au seuil :
Pour signaler correctement une valeur p à partir d'une expérience à horizon fixe, vous devez vous engager à l'avance sur une taille d'échantillon ou une durée de test fixe. Certaines équipes ajoutent également un certain nombre de conversions à ce critère d'arrêt du test et à une durée prévue.
Cependant, le problème ici est qu'il est difficile pour la plupart des sites Web d'avoir suffisamment de trafic de test pour alimenter chaque expérience pour un arrêt optimal en utilisant cette pratique standard.
C'est ici qu'il est utile d'utiliser des méthodes de test séquentiel prenant en charge les règles d'arrêt facultatives.
Vers des règles d'arrêt flexibles qui permettent des décisions plus rapides
Les méthodes de test séquentiel vous permettent d'exploiter les données de vos expériences telles qu'elles apparaissent et d'utiliser vos propres modèles de signification statistique pour repérer les gagnants plus tôt, avec des règles d'arrêt flexibles.
Les équipes d'optimisation aux plus hauts niveaux de maturité CRO conçoivent souvent leurs propres méthodologies statistiques pour prendre en charge ces tests. Certains outils de test A/B intègrent également cela et pourraient suggérer si une version semble être gagnante. Et certains vous donnent un contrôle total sur la façon dont vous souhaitez que votre signification statistique soit calculée, avec vos valeurs personnalisées et plus encore. Ainsi, vous pouvez jeter un coup d'œil et repérer un gagnant même dans une expérience en cours.

Statisticien, auteur et instructeur du cours populaire CXL sur les statistiques de test A/B, Georgi Georgiev est partisan de ces méthodes de test séquentielles qui permettent une flexibilité dans le nombre et le calendrier des analyses intermédiaires :
“ Les tests séquentiels vous permettent de maximiser les profits en déployant tôt une variante gagnante, ainsi que d'arrêter les tests qui ont peu de probabilité de produire un gagnant le plus tôt possible. Ce dernier minimise les pertes dues aux variantes inférieures et accélère les tests lorsque les variantes sont tout simplement peu susceptibles de surpasser le contrôle. La rigueur statistique est maintenue dans tous les cas. ”
Georgiev a même travaillé sur une calculatrice qui aide les équipes à abandonner les modèles de test d'échantillons fixes pour un qui peut détecter un gagnant pendant qu'une expérience est toujours en cours. Son modèle prend en compte de nombreuses statistiques et vous aide à effectuer des tests environ 20 à 80 % plus rapidement que les calculs de signification statistique standard, sans sacrifier la qualité.
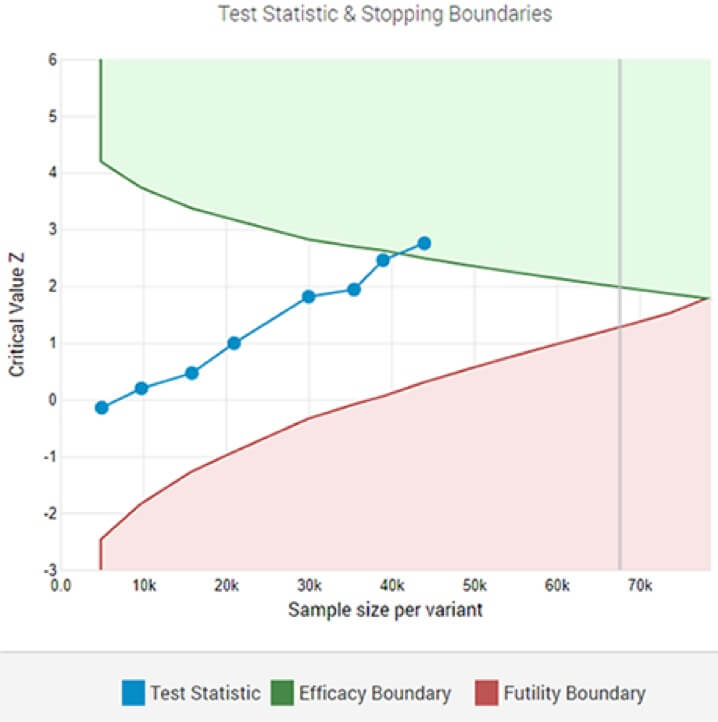
Un test A/B adaptatif montrant un gagnant statistiquement significatif au seuil de signification désigné après la 8ème analyse intermédiaire.
Bien que de tels tests puissent accélérer votre processus de prise de décision, un aspect important doit être pris en compte : l'impact réel de l'expérience . Mettre fin à une expérience entre-temps peut vous amener à la surestimer.
L'examen d'estimations non ajustées de la taille de l'effet peut être dangereux, prévient Georgiev. Pour éviter cela, son modèle utilise des méthodes pour appliquer des ajustements qui tiennent compte du biais encouru en raison du suivi intermédiaire. Il explique comment leur analyse agile ajuste les estimations "en fonction de l'étape d'arrêt et de la valeur observée de la statistique (dépassement, le cas échéant)". Ci-dessous, vous pouvez voir l'analyse du test ci-dessus : (notez que la portance estimée est inférieure à celle observée et que l'intervalle n'est pas centré autour de celle-ci.)
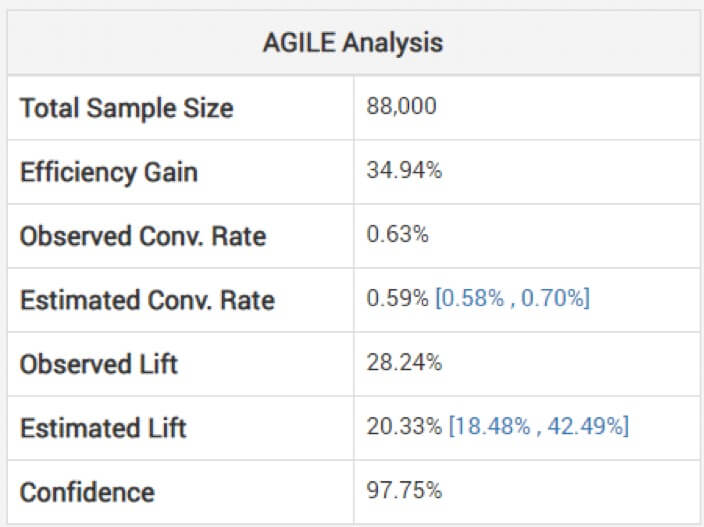
Ainsi, une victoire peut ne pas être aussi importante qu'il n'y paraît en fonction de votre expérience plus courte que prévu.
La perte doit également être prise en compte, car vous avez peut-être encore fini par appeler un gagnant par erreur trop tôt. Mais ce risque existe même dans les tests à horizon fixe. La validité externe, cependant, peut être une préoccupation plus importante lors de l'appel précoce d'expériences par rapport à un test à horizon fixe de plus longue durée. Mais il s'agit, comme l'explique Georgiev, « d'une simple conséquence de la taille réduite de l'échantillon et donc de la durée du test. "
En fin de compte… Il ne s'agit pas de gagnants ou de perdants…
… mais de meilleures décisions commerciales, comme le dit Chris Stucchio.
Ou comme l'affirme Tom Redman (auteur de Data Driven : Profiting from Your Most Important Business Asset) : « il y a souvent des critères plus importants que la signification statistique. La question importante est : « Est-ce que le résultat tient debout sur le marché, ne serait-ce que pour une courte période de temps ? ”'
Et ce sera très probablement le cas, et pas seulement pour une brève période, note Georgiev, " si elle est statistiquement significative et que les considérations de validité externe ont été traitées de manière satisfaisante au stade de la conception".
L'essence même de l'expérimentation est de donner aux équipes les moyens de prendre des décisions plus éclairées. Donc, si vous pouvez transmettre les résultats - vers lesquels les données de vos expériences pointent - plus tôt, alors pourquoi pas ?
Il peut s'agir d'une petite expérience d'interface utilisateur pour laquelle vous ne pouvez pratiquement pas obtenir une taille d'échantillon "suffisante". Cela pourrait aussi être une expérience où votre challenger écrase l'original et vous pourriez simplement prendre ce pari !
Comme Jeff Bezos l'écrit dans sa lettre aux actionnaires d'Amazon, les grandes expériences rapportent gros :
« Étant donné une probabilité de dix pour cent d'un gain de 100 fois, vous devriez prendre ce pari à chaque fois. Mais vous allez toujours vous tromper neuf fois sur dix. Nous savons tous que si vous vous balancez vers les clôtures, vous allez frapper beaucoup, mais vous allez aussi frapper quelques coups de circuit. La différence entre le baseball et les affaires, cependant, est que le baseball a une distribution de résultats tronquée. Lorsque vous vous balancez, quelle que soit la qualité de votre connexion avec le ballon, le maximum de points que vous pouvez obtenir est de quatre. En affaires, de temps en temps, lorsque vous montez au créneau, vous pouvez marquer 1 000 courses. Cette distribution à longue queue des rendements est la raison pour laquelle il est important d'être audacieux. Les grands gagnants paient pour tant d'expériences. "
Appeler des expériences tôt, dans une large mesure, revient à jeter un coup d'œil chaque jour aux résultats et à s'arrêter à un point qui garantit un bon pari.

