
Qu'est-ce qu'une courbe CTR et comment la calculer avec Python ?
Publié: 2022-03-22La courbe CTR, ou en d'autres termes le taux de clics organique basé sur la position, est une donnée qui vous montre combien de liens bleus sur une page de résultats de moteur de recherche (SERP) obtiennent un CTR en fonction de leur position. Par exemple, la plupart du temps, le premier lien bleu dans SERP obtient le plus de CTR.
A la fin de ce tutoriel, vous pourrez calculer la courbe CTR de votre site en fonction de ses annuaires ou calculer le CTR organique en fonction des requêtes CTR. La sortie de mon code Python est une boîte et un diagramme à barres perspicaces qui décrit la courbe CTR du site.
Si vous êtes débutant et que vous ne connaissez pas la définition du CTR, je l'expliquerai plus en détail dans la section suivante.
Qu'est-ce que le CTR organique ou le taux de clics organique ?
Le CTR provient de la division des clics organiques en impressions. Par exemple, si 100 personnes recherchent « pomme » et que 30 personnes cliquent sur le premier résultat, le CTR du premier résultat est de 30/100 * 100 = 30 %.
Cela signifie que sur 100 recherches, vous en obtenez 30 %. Il est important de se rappeler que les impressions dans Google Search Console (GSC) ne sont pas basées sur l'apparence du lien de votre site Web dans la fenêtre de recherche. Si le résultat apparaît sur le SERP du chercheur, vous obtenez une impression pour chacune des recherches.
A quoi sert la courbe CTR ?
L'un des sujets importants du référencement est la prédiction de trafic organique. Pour améliorer le classement dans certains ensembles de mots-clés, nous devons allouer des milliers et des milliers de dollars pour obtenir plus de partages. Mais la question au niveau marketing d'une entreprise est souvent : « Est-il rentable pour nous d'allouer ce budget ? ».
De plus, outre le sujet des allocations budgétaires pour les projets de référencement, nous devons obtenir une estimation de l'augmentation ou de la diminution de notre trafic organique à l'avenir. Par exemple, si nous voyons l'un de nos concurrents s'efforcer de nous remplacer dans notre classement SERP, combien cela nous coûtera-t-il ?
Dans cette situation ou dans de nombreux autres scénarios, nous avons besoin de la courbe CTR de notre site.
Pourquoi n'utilisons-nous pas des études de courbe CTR et n'utilisons-nous pas nos données ?
Pour répondre simplement, il n'y a aucun autre site Web qui possède les caractéristiques de votre site dans SERP.
Il existe de nombreuses recherches sur les courbes CTR dans différentes industries et différentes fonctionnalités SERP, mais lorsque vous avez vos données, pourquoi vos sites ne calculent-ils pas le CTR au lieu de s'appuyer sur des sources tierces ?
Commençons à faire ça.
Calculer la courbe CTR avec Python : Prise en main
Avant de plonger dans le processus de calcul du taux de clics de Google en fonction de la position, vous devez connaître la syntaxe Python de base et avoir une compréhension de base des bibliothèques Python courantes, telles que Pandas. Cela vous aidera à mieux comprendre le code et à le personnaliser à votre guise.
De plus, pour ce processus, je préfère utiliser un notebook Jupyter .
Pour calculer le CTR organique en fonction de la position, nous devons utiliser ces bibliothèques Python :
- Pandas
- comploter
- Kaléido
Nous utiliserons également ces bibliothèques Python standard :
- os
- json
Comme je l'ai dit, nous allons explorer deux manières différentes de calculer la courbe CTR. Certaines étapes sont identiques dans les deux méthodes : importation des packages Python, création d'un dossier de sortie d'images de tracé et définition des tailles de tracé de sortie.
# Importation des bibliothèques nécessaires pour notre processus importer le système d'exploitation importer json importer des pandas en tant que pd importer plotly.express en px importer plotly.io en tant que pio importer kaléïdo
Ici, nous créons un dossier de sortie pour enregistrer nos images de tracé.
# Création du dossier de sortie des images de tracé
sinon os.path.exists('./output plot images'):
os.mkdir('./output plot images')
Vous pouvez modifier la hauteur et la largeur des images de tracé de sortie ci-dessous.
# Réglage de la largeur et de la hauteur des images de tracé de sortie pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Commençons par la première méthode basée sur les requêtes CTR.
Première méthode : Calculer la courbe CTR pour un site Web entier ou une propriété d'URL spécifique en fonction du CTR des requêtes
Tout d'abord, nous devons obtenir toutes nos requêtes avec leur CTR, leur position moyenne et leur impression. Je préfère utiliser un mois complet de données du mois précédent.
Pour ce faire, j'obtiens des données de requêtes à partir de la source de données d'impression du site GSC dans Google Data Studio. Alternativement, vous pouvez acquérir ces données de la manière que vous préférez, comme l'API GSC ou le module complémentaire Google Sheets "Search Analytics for Sheets" par exemple. De cette façon, si votre blog ou vos pages de produits ont une propriété d'URL dédiée, vous pouvez les utiliser comme source de données dans GDS.
1. Obtenir des données de requêtes de Google Data Studio (GDS)
Pour faire ça:
- Créer un rapport et y ajouter un tableau graphique
- Ajoutez la source de données "Impression du site" de votre site au rapport
- Choisissez "requête" pour la dimension ainsi que "ctr", "position moyenne" et "'impression" pour la métrique
- Filtrez les requêtes contenant le nom de la marque en créant un filtre (les requêtes contenant des marques auront un taux de clics plus élevé, ce qui diminuera la précision de nos données)
- Faites un clic droit sur le tableau et cliquez sur Exporter
- Enregistrer la sortie au format CSV
2. Charger nos données et étiqueter les requêtes en fonction de leur position
Pour manipuler le CSV téléchargé, nous utiliserons Pandas.
La meilleure pratique pour la structure de dossiers de notre projet est d'avoir un dossier « données » dans lequel nous enregistrons toutes nos données.
Ici, par souci de fluidité dans le tutoriel, je ne l'ai pas fait.
query_df = pd.read_csv('./downloaded_data.csv')
Ensuite, nous étiquetons nos requêtes en fonction de leur position. J'ai créé une boucle 'for' pour étiqueter les positions 1 à 10.
Par exemple, si la position moyenne d'une requête est 2,2 ou 2,9, elle sera étiquetée "2". En manipulant la plage de position moyenne, vous pouvez obtenir la précision souhaitée.
pour je dans la plage (1, 11):
query_df.loc[(query_df['Position moyenne'] >= i) & (
query_df['Position moyenne'] < i + 1), 'étiquette de position'] = i
Maintenant, nous allons regrouper les requêtes en fonction de leur position. Cela nous aide à mieux manipuler les données des requêtes de position dans les prochaines étapes.
query_grouped_df = query_df.groupby(['étiquette de position'])
3. Filtrage des requêtes en fonction de leurs données pour le calcul de la courbe CTR
Le moyen le plus simple de calculer la courbe CTR consiste à utiliser toutes les données des requêtes et à effectuer le calcul. Cependant; n'oubliez pas de penser à ces requêtes avec une impression en position deux dans vos données.
Ces requêtes, basées sur mon expérience, font une grande différence dans le résultat final. Mais la meilleure façon est d'essayer vous-même. En fonction de l'ensemble de données, cela peut changer.
Avant de commencer cette étape, nous devons créer une liste pour notre sortie de graphique à barres et un DataFrame pour stocker nos requêtes manipulées.
# Création d'un DataFrame pour stocker les données manipulées 'query_df' modified_df = pd.DataFrame() # Une liste pour enregistrer chaque position signifie pour notre graphique à barres moyenne_ctr_list = []
Ensuite, nous parcourons les groupes query_grouped_df et ajoutons les 20 % de requêtes les plus importantes en fonction des impressions au DataFrame modified_df .
Si le calcul du CTR basé uniquement sur les 20 % de requêtes ayant le plus d'impressions n'est pas ce qu'il y a de mieux pour vous, vous pouvez le modifier.
Pour ce faire, vous pouvez l'augmenter ou le diminuer en manipulant .quantile(q=your_optimal_number, interpolation='lower')] et your_optimal_number doit être compris entre 0 et 1.
Par exemple, si vous souhaitez obtenir les 30 % supérieurs de vos requêtes, your_optimal_num est la différence entre 1 et 0,3 (0,7).
pour je dans la plage (1, 11):
# Un essai sauf pour gérer les situations où un répertoire n'a pas de données pour certaines positions
essayer:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions'] >= query_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, interpolation='inférieur')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append(tmp_df, ignore_index=True)
sauf KeyError :
mean_ctr_list.append(0)
# Suppression de DataFrame 'tmp_df' pour réduire l'utilisation de la mémoire
del [tmp_df]
4. Dessiner une boîte à moustaches
Cette étape est ce que nous attendions. Pour dessiner des tracés, nous pouvons utiliser Matplotlib, seaborn comme wrapper pour Matplotlib, ou Plotly.
Personnellement, je pense que l'utilisation de Plotly est l'une des meilleures solutions pour les spécialistes du marketing qui aiment explorer les données.
Par rapport à Mathplotlib, Plotly est si facile à utiliser et avec seulement quelques lignes de code, vous pouvez dessiner un beau tracé.
# 1. La boîte à moustaches
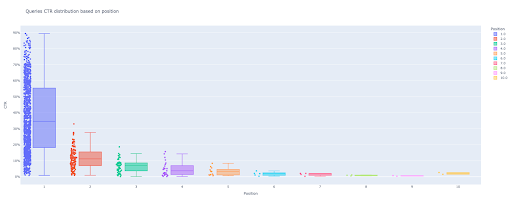
box_fig = px.box(modified_df, x='position label', y='Site CTR', title='Demande la distribution du CTR en fonction de la position',
points='all', color='position label', labels={'position label' : 'Position', 'Site CTR' : 'CTR'})
# Affichage des dix graduations de l'axe des x
box_fig.update_xaxes(tickvals=[je pour je dans la plage(1, 11)])
# Changer le format de graduation des axes y en pourcentage
box_fig.update_yaxes(tickformat=".0%")
# Enregistrement du tracé dans le répertoire 'output plot images'
box_fig.write_image('./output plot images/Queries box plot CTR curve.png')
Avec seulement ces quatre lignes, vous pouvez obtenir une belle boîte à moustaches et commencer à explorer vos données.
Si vous souhaitez interagir avec cette colonne, dans une nouvelle cellule, exécutez :
box_fig.show()
Maintenant, vous avez une boîte à moustaches attrayante en sortie qui est interactive.
Lorsque vous survolez un tracé interactif dans la cellule de sortie, le nombre important qui vous intéresse est le « homme » de chaque position.
Cela montre le CTR moyen pour chaque position. En raison de l'importance moyenne, comme vous vous en souvenez, nous créons une liste qui contient la moyenne de chaque position. Ensuite, nous passerons à l'étape suivante pour dessiner un graphique à barres basé sur la moyenne de chaque position.
5. Dessiner un graphique à barres
Comme une boîte à moustaches, dessiner le graphique à barres est si facile. Vous pouvez changer le title des graphiques en modifiant l'argument title du px.bar() .
# 2. Le graphique à barres
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='Les requêtes signifient la distribution CTR basée sur la position',
labels={'x' : 'Position', 'y' : 'CTR'}, text_auto=True)
# Affichage des dix graduations de l'axe des x
bar_fig.update_xaxes(tickvals=[je pour je dans la plage(1, 11)])
# Changer le format de graduation des axes y en pourcentage
bar_fig.update_yaxes(tickformat='.0%')
# Enregistrement du tracé dans le répertoire 'output plot images'
bar_fig.write_image('./output plot images/Queries bar plot CTR curve.png')
En sortie, on obtient ce tracé :
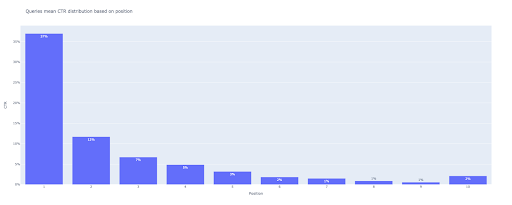
Comme avec le box plot, vous pouvez interagir avec ce graphique en exécutant bar_fig.show() .
C'est ça! Avec quelques lignes de code, nous obtenons le taux de clics organique basé sur la position avec nos données de requêtes.
Si vous avez une propriété d'URL pour chacun de vos sous-domaines ou répertoires, vous pouvez obtenir ces requêtes de propriétés d'URL et calculer la courbe CTR pour celles-ci.
[Étude de cas] Améliorer les classements, les visites organiques et les ventes grâce à l'analyse des fichiers journaux
 Lire l'étude de cas
Lire l'étude de casDeuxième méthode : calcul de la courbe CTR en fonction des URL des pages de destination pour chaque répertoire
Dans la première méthode, nous avons calculé notre CTR organique en fonction du CTR des requêtes, mais avec cette approche, nous obtenons toutes les données de nos pages de destination, puis calculons la courbe CTR pour nos annuaires sélectionnés.

J'aime cette façon. Comme vous le savez, le CTR de nos pages de produits est si différent de celui de nos articles de blog ou d'autres pages. Chaque répertoire a son propre CTR basé sur la position.
De manière plus avancée, vous pouvez catégoriser chaque page d'annuaire et obtenir le taux de clics organique de Google en fonction de la position d'un ensemble de pages.
1. Obtenir les données des pages de destination
Tout comme la première méthode, il existe plusieurs façons d'obtenir les données de Google Search Console (GSC). Dans cette méthode, j'ai préféré obtenir les données des pages de destination de l'explorateur d'API GSC à l'adresse : https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Pour ce qui est nécessaire dans cette approche, GDS ne fournit pas de données solides sur les pages de destination. Vous pouvez également utiliser le module complémentaire Google Sheets "Search Analytics for Sheets".
Notez que Google API Explorer convient parfaitement aux sites contenant moins de 25 000 pages de données. Pour les sites plus volumineux, vous pouvez obtenir partiellement les données des pages de destination et les concaténer, écrire un script Python avec une boucle "for" pour extraire toutes vos données de GSC ou utiliser des outils tiers.
Pour obtenir des données à partir de Google API Explorer :
- Accédez à la page de documentation de l'API GSC "Search Analytics : requête" : https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Utilisez l'explorateur d'API qui se trouve sur le côté droit de la page
- Dans le champ "siteUrl", insérez l'adresse de votre propriété URL, comme
https://www.example.com. Vous pouvez également insérer votre propriété de domaine comme suitsc-domain:example.com - Dans le champ "corps de la requête", ajoutez
startDateetendDate. Je préfère obtenir les données du mois dernier. Le format de ces valeurs estYYYY-MM-DD - Ajouter
dimensionet définir ses valeurs sur lapage - Créez un "dimensionFilterGroups" et filtrez les requêtes avec des noms de variantes de marque (en remplaçant
brand_variation_namespar vos noms de marque RegExp) - Ajoutez
rawLimitet réglez-le sur 25000 - À la fin, appuyez sur le bouton 'EXECUTE'
Vous pouvez également copier et coller le corps de la requête ci-dessous :
{
"startDate": "2022-01-01",
"endDate": "2022-02-01",
"dimensions": [
"page"
],
"dimensionFilterGroups": [
{
"filtres": [
{
"dimension": "REQUETE",
"expression": "brand_variation_names",
"opérateur": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
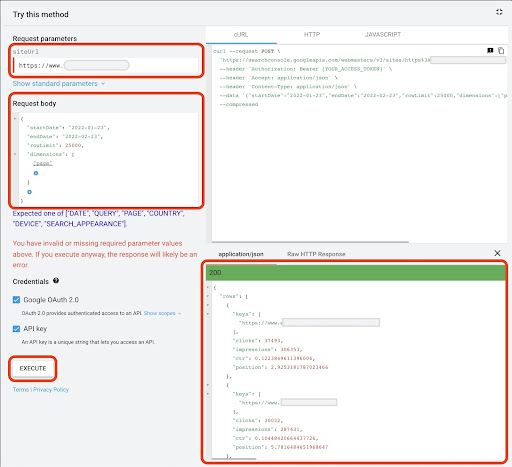
Une fois la requête exécutée, nous devons la sauvegarder. En raison du format de réponse, nous devons créer un fichier JSON, copier toutes les réponses JSON et l'enregistrer avec le nom de fichier downloaded_data.json .
Si votre site est petit, comme un site d'entreprise SASS, et que les données de votre page de destination comptent moins de 1000 pages, vous pouvez facilement définir votre date dans GSC et exporter les données des pages de destination pour l'onglet "PAGES" sous forme de fichier CSV.
2. Chargement des données des pages de destination
Pour les besoins de ce didacticiel, je suppose que vous obtenez des données de Google API Explorer et que vous les enregistrez dans un fichier JSON. Pour charger ces données, nous devons exécuter le code ci-dessous :
# Création d'un DataFrame pour les données téléchargées
avec open('./downloaded_data.json') comme json_file :
landings_data = json.loads(json_file.read())['rows']
landings_df = pd.DataFrame(landings_data)
De plus, nous devons modifier un nom de colonne pour lui donner plus de sens et appliquer une fonction pour obtenir les URL des pages de destination directement dans la colonne "page de destination".
# Renommer la colonne 'keys' en colonne 'landing page' et convertir la liste 'landing page' en URL
landings_df.rename(columns={'keys' : 'landing page'}, inplace=True)
landings_df['landing page'] = landings_df['landing page'].apply(lambda x : x[0])
3. Obtenir tous les répertoires racine des pages de destination
Tout d'abord, nous devons définir le nom de notre site.
# Définir le nom de votre site entre guillemets. Par exemple, 'https://www.exemple.com/' ou 'http://mondomaine.com/' nom_site = ''
Ensuite, nous exécutons une fonction sur les URL des pages de destination pour obtenir leurs répertoires racine et les voir en sortie pour les choisir.
# Obtenir le répertoire de chaque page de destination (URL)
landings_df['directory'] = landings_df['landing page'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Pour obtenir tous les répertoires dans la sortie, nous devons manipuler les options de Pandas
pd.set_option("display.max_rows", Aucun)
# Annuaires de sites Web
landings_df['répertoire'].value_counts()
Ensuite, nous choisissons pour quels répertoires nous devons obtenir leur courbe CTR.
Insérez les répertoires dans la variable important_directories .
Par exemple, product,tag,product-category,mag . Séparez les valeurs de répertoire par une virgule.
répertoires_importants = ''
répertoires_importants = répertoires_importants.split(',')
4. Étiqueter et regrouper les pages de destination
Comme pour les requêtes, nous étiquetons également les pages de destination en fonction de leur position moyenne.
# Étiquetage de la position des pages de destination
pour je dans la plage (1, 11):
landings_df.loc[(landings_df['position'] >= i) & (
landings_df['position'] < i + 1), 'étiquette de position'] = i
Ensuite, nous regroupons les pages de destination en fonction de leur "répertoire".
# Regroupement des pages de destination en fonction de leur valeur "répertoire" landings_grouped_df = landings_df.groupby(['répertoire'])
5. Génération de box et de bar plots pour nos répertoires
Dans la méthode précédente, nous n'utilisions pas de fonction pour générer les tracés. Cependant; pour calculer automatiquement la courbe CTR pour différentes pages de destination, nous devons définir une fonction.
# La fonction de création et de sauvegarde de chaque répertoire graphique
def each_dir_plot(dir_df, clé):
# Regroupement des pages de destination du répertoire en fonction de leur valeur "étiquette de position"
dir_grouped_df = dir_df.groupby(['étiquette de position'])
# Création d'un DataFrame pour stocker les données manipulées 'dir_grouped_df'
modified_df = pd.DataFrame()
# Une liste pour enregistrer chaque position signifie pour notre graphique à barres
moyenne_ctr_list = []
'''
Boucle sur les groupes 'query_grouped_df' et ajout des 20 % de requêtes les plus importantes en fonction des impressions au DataFrame 'modified_df'.
Si le calcul du CTR basé uniquement sur les 20 % de requêtes ayant le plus d'impressions n'est pas ce qu'il y a de mieux pour vous, vous pouvez le modifier.
Pour le changer, vous pouvez l'augmenter ou le diminuer en manipulant '.quantile(q=your_optimal_number, interpolation='lower')]'.
'you_optimal_number' doit être compris entre 0 et 1.
Par exemple, si vous souhaitez obtenir les 30 % supérieurs de vos requêtes, "your_optimal_num" correspond à la différence entre 1 et 0,3 (0,7).
'''
pour je dans la plage (1, 11):
# Un essai sauf pour gérer les situations où un répertoire n'a pas de données pour certaines positions
essayer:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions'] >= dir_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, interpolation='inférieur')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append(tmp_df, ignore_index=True)
sauf KeyError :
mean_ctr_list.append(0)
# 1. La boîte à moustaches
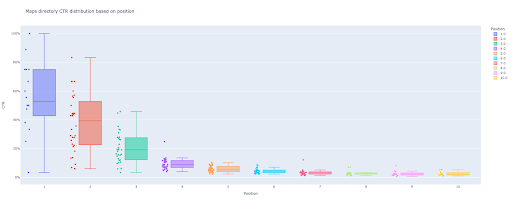
box_fig = px.box(modified_df, x='position label', y='ctr', title=f'{key} répertoire CTR distribution en fonction de la position',
points='all', color='position label', labels={'position label' : 'Position', 'ctr' : 'CTR'})
# Affichage des dix graduations de l'axe des x
box_fig.update_xaxes(tickvals=[je pour je dans la plage(1, 11)])
# Changer le format de graduation des axes y en pourcentage
box_fig.update_yaxes(tickformat=".0%")
# Enregistrement du tracé dans le répertoire 'output plot images'
box_fig.write_image(f'./output plot images/{key} répertoire-Box plot CTR curve.png')
# 2. Le graphique à barres
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} répertoire signifie la distribution CTR basée sur la position',
labels={'x' : 'Position', 'y' : 'CTR'}, text_auto=True)
# Affichage des dix graduations de l'axe des x
bar_fig.update_xaxes(tickvals=[je pour je dans la plage(1, 11)])
# Changer le format de graduation des axes y en pourcentage
bar_fig.update_yaxes(tickformat='.0%')
# Enregistrement du tracé dans le répertoire 'output plot images'
bar_fig.write_image(f'./output plot images/{key} directory-Bar plot CTR curve.png')
Après avoir défini la fonction ci-dessus, nous avons besoin d'une boucle 'for' pour parcourir les données des répertoires pour lesquels nous voulons obtenir leur courbe CTR.
# Boucle sur les répertoires et exécution de la fonction 'each_dir_plot'
pour la clé, élément dans landings_grouped_df :
si clé dans important_directories :
each_dir_plot(élément, clé)
Dans la sortie, nous obtenons nos tracés dans le dossier output plot images .
Astuce avancée !
Vous pouvez également calculer les courbes CTR des différents annuaires en utilisant la landing page des requêtes. Avec quelques changements dans les fonctions, vous pouvez regrouper les requêtes en fonction de leurs répertoires de pages de destination.
Vous pouvez utiliser le corps de la requête ci-dessous pour effectuer une requête API dans l'explorateur d'API (n'oubliez pas la limite de 25 000 lignes) :
{
"startDate": "2022-01-01",
"endDate": "2022-02-01",
"dimensions": [
"requête",
"page"
],
"dimensionFilterGroups": [
{
"filtres": [
{
"dimension": "REQUETE",
"expression": "brand_variation_names",
"opérateur": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
Conseils pour personnaliser le calcul de la courbe CTR avec Python
Pour obtenir des données plus précises pour calculer la courbe CTR, nous devons utiliser des outils tiers.
Par exemple, en plus de savoir quelles requêtes ont un extrait de code, vous pouvez explorer plus de fonctionnalités SERP. De plus, si vous utilisez des outils tiers, vous pouvez obtenir la paire de requêtes avec le classement de la page de destination pour cette requête, en fonction des fonctionnalités SERP.
Ensuite, étiqueter les pages de destination avec leur répertoire racine (parent), regrouper les requêtes en fonction des valeurs du répertoire, prendre en compte les fonctionnalités SERP et enfin regrouper les requêtes en fonction de la position. Pour les données CTR, vous pouvez fusionner les valeurs CTR de GSC avec leurs requêtes homologues.