
Contrôler l'exploration et l'indexation : un guide SEO pour Robots.txt et les balises
Publié: 2019-02-19Optimiser le budget de crawl et empêcher les bots d'indexer les pages sont des concepts que de nombreux référenceurs connaissent bien. Mais le diable est dans les détails. D'autant que les bonnes pratiques ont beaucoup évolué ces dernières années.
Une petite modification apportée à un fichier robots.txt ou à des balises robots peut avoir un impact considérable sur votre site Web. Pour vous assurer que l'impact est toujours positif pour votre site, nous allons aujourd'hui nous pencher sur :
Optimiser le budget de crawl
Qu'est-ce qu'un fichier Robots.txt
Que sont les balises Meta Robots
Que sont les X-Robots-Tags
Directives Robots & SEO
Liste de vérification des meilleures pratiques pour les robots
Optimiser le budget de crawl
Une araignée de moteur de recherche a une "allocation" pour le nombre de pages qu'elle peut et veut explorer sur votre site. C'est ce qu'on appelle le "budget de crawl".
Trouvez le budget de crawl de votre site dans le rapport "Crawl Stats" de la Google Search Console (GSC). A noter que le GSC est un agrégat de 12 bots qui ne sont pas tous dédiés au SEO. Il regroupe également les bots AdWords ou AdSense qui sont des bots SEA. Ainsi, cet outil vous donne une idée de votre budget de crawl global mais pas sa répartition exacte.
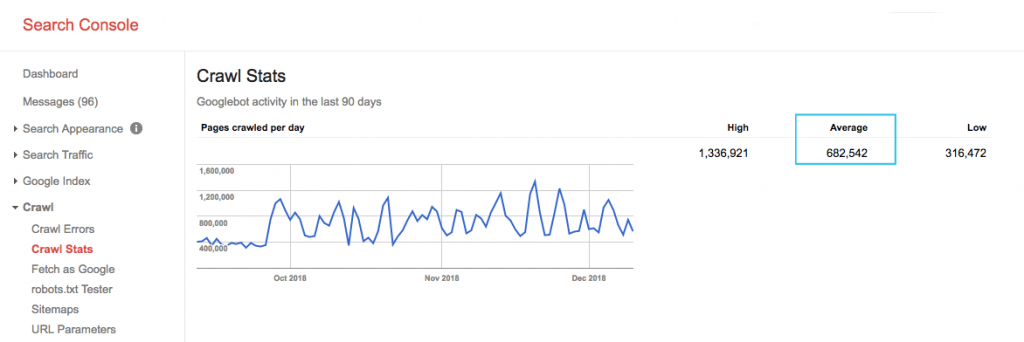
Pour rendre le nombre plus exploitable, divisez le nombre moyen de pages explorées par jour par le nombre total de pages explorables sur votre site. Vous pouvez demander le nombre à votre développeur ou exécuter un robot d'exploration de site illimité. Cela vous donnera un ratio de crawl attendu pour commencer à optimiser.
Vous voulez aller plus loin ? Obtenez une ventilation plus détaillée de l'activité de Googlebot, comme les pages visitées, ainsi que les statistiques des autres robots d'exploration, en analysant les fichiers journaux du serveur de votre site.
Il existe de nombreuses façons d'optimiser le budget d'exploration, mais un point de départ facile consiste à consulter le rapport "Couverture" de GSC pour comprendre le comportement actuel d'exploration et d'indexation de Google.
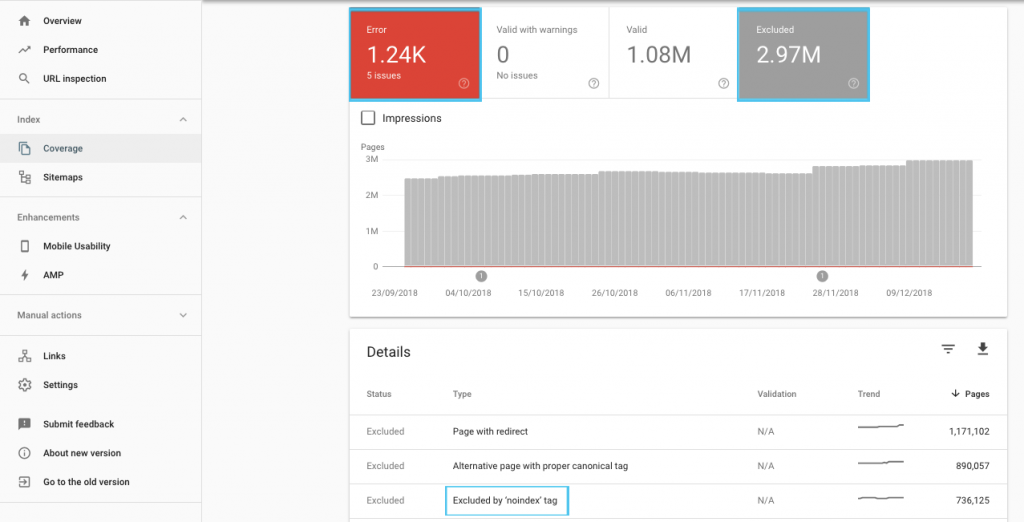
Si vous voyez des erreurs telles que "URL soumise marquée 'noindex'" ou "URL soumise bloquée par robots.txt", contactez votre développeur pour les corriger. Pour toutes les exclusions de robots, étudiez-les pour comprendre s'ils sont stratégiques du point de vue du référencement.
En général, les SEO doivent viser à minimiser les restrictions d'exploration sur les robots. Améliorer l'architecture de votre site Web pour rendre les URL utiles et accessibles pour les moteurs de recherche est la meilleure stratégie.
Google lui-même note qu'"une architecture d'information solide est susceptible d'être une utilisation beaucoup plus productive des ressources que de se concentrer sur la priorisation du crawl".
Cela étant dit, il est utile de comprendre ce qui peut être fait avec les fichiers robots.txt et les balises robots pour guider l'exploration, l'indexation et la transmission de l'équité des liens. Et plus important encore, quand et comment en tirer le meilleur parti pour le référencement moderne.
[Étude de cas] Gérer le bot crawling de Google
 Lire l'étude de cas
Lire l'étude de casQu'est-ce qu'un fichier Robots.txt
Avant qu'un moteur de recherche ne balaye une page, il vérifiera le fichier robots.txt. Ce fichier indique aux bots les chemins d'URL qu'ils sont autorisés à visiter. Mais ces entrées ne sont que des directives, pas des mandats.
Robots.txt ne peut pas empêcher de manière fiable l'exploration comme un pare-feu ou une protection par mot de passe. C'est l'équivalent numérique d'un panneau « s'il vous plaît, n'entrez pas » sur une porte non verrouillée.
Les robots polis, tels que les principaux moteurs de recherche, obéissent généralement aux instructions. Les robots d'exploration hostiles, tels que les grattoirs d'e-mails, les spambots, les logiciels malveillants et les araignées qui recherchent les vulnérabilités du site, n'y prêtent souvent aucune attention.
De plus, il s'agit d'un fichier accessible au public . Tout le monde peut voir vos directives.
N'utilisez pas votre fichier robots.txt pour :
- Pour masquer des informations sensibles. Utilisez la protection par mot de passe.
- Pour bloquer l'accès à votre site de staging et/ou de développement. Utilisez l'authentification côté serveur.
- Pour bloquer explicitement les robots d'exploration hostiles. Utilisez le blocage IP ou le blocage de l'agent utilisateur (c'est-à-dire interdire l'accès d'un robot spécifique avec une règle dans votre fichier .htaccess ou un outil tel que CloudFlare).
Chaque site Web doit avoir un fichier robots.txt valide avec au moins un groupement de directives. Sans un, tous les bots bénéficient d'un accès complet par défaut - de sorte que chaque page est traitée comme explorable. Même si c'est ce que vous avez l'intention, il est préférable de le préciser à toutes les parties prenantes avec un fichier robots.txt. De plus, sans celui-ci, les journaux de votre serveur seront truffés de requêtes infructueuses pour robots.txt.
Structure d'un fichier robots.txt
Pour être reconnu par les crawlers, votre fichier robots.txt doit :
- Soit un fichier texte nommé "robots.txt". Le nom du fichier est sensible à la casse. "Robots.TXT" ou d'autres variantes ne fonctionneront pas.
- Être situé dans le répertoire de niveau supérieur de votre domaine canonique et, le cas échéant, des sous-domaines. Par exemple, pour contrôler l'exploration sur toutes les URL sous https://www.example.com, le fichier robots.txt doit être situé à https://www.example.com/robots.txt et pour subdomain.example.com à sous-domaine.exemple.com/robots.txt.
- Renvoie un statut HTTP de 200 OK.
- Utilisez une syntaxe robots.txt valide - Vérifiez à l'aide de l'outil de test robots.txt de Google Search Console.
Un fichier robots.txt est composé de regroupements de directives. Les entrées consistent principalement en :
- 1. User-agent : adresse les différents crawlers. Vous pouvez avoir un groupe pour tous les robots ou utiliser des groupes pour nommer des moteurs de recherche spécifiques.
- 2. Interdire : spécifie les fichiers ou répertoires à exclure de l'exploration par l'agent utilisateur ci-dessus. Vous pouvez avoir une ou plusieurs de ces lignes par bloc.
Pour une liste complète des noms d'agents utilisateurs et d'autres exemples de directives, consultez le guide robots.txt sur Yoast.
En plus des directives « User-agent » et « Disallow », il existe des directives non standard :
- Autoriser : spécifiez des exceptions à une directive d'interdiction pour un répertoire parent.
- Retard d'exploration : Limitez les robots d'exploration lourds en indiquant aux bots combien de secondes attendre avant de visiter une page. Si vous obtenez peu de sessions organiques, le délai d'exploration peut économiser la bande passante du serveur. Mais je n'investirais l'effort que si les crawlers causaient activement des problèmes de charge du serveur. Google ne reconnaît pas cette commande, offre la possibilité de limiter le taux d'exploration dans Google Search Console.
- Clean-param : évite de réexplorer le contenu en double généré par les paramètres dynamiques.
- Pas d'index : conçu pour contrôler l'indexation sans utiliser de budget de crawl. Il n'est plus officiellement pris en charge par Google. Bien qu'il existe des preuves qu'il peut encore avoir un impact, il n'est pas fiable et n'est pas recommandé par des experts tels que John Mueller.
@maxxeight @google @DeepCrawl J'éviterais vraiment d'utiliser le noindex ici.
— ???? John ???? (@JohnMu) 1er septembre 2015
- Plan du site : la meilleure façon de soumettre votre plan du site XML est via la console de recherche Google et les outils pour les webmasters d'autres moteurs de recherche. Cependant, l'ajout d'une directive sitemap à la base de votre fichier robots.txt aide les autres robots qui n'offrent peut-être pas d'option de soumission.
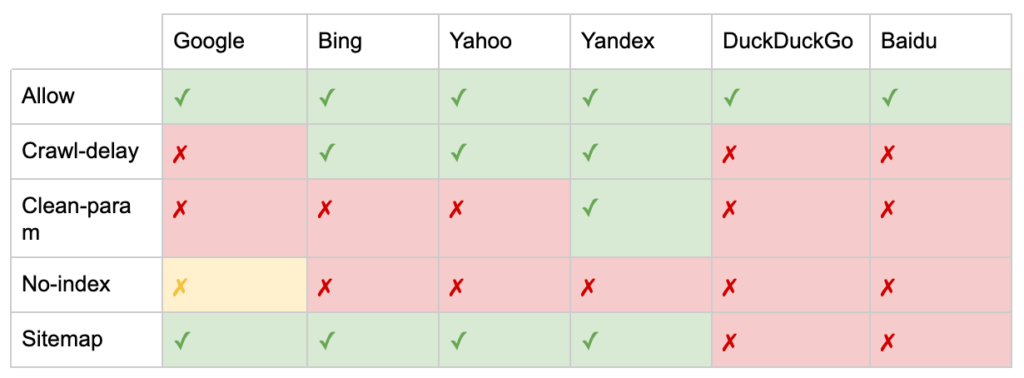
Limitations de robots.txt pour le référencement
Nous savons déjà que robots.txt ne peut pas empêcher l'exploration pour tous les bots. De même, interdire les robots d'exploration d'une page n'empêche pas son inclusion dans les pages de résultats des moteurs de recherche (SERP).
Si une page bloquée a d'autres signaux de classement forts, Google peut juger pertinent de l'afficher dans les résultats de recherche. Bien qu'il n'ait pas exploré la page.
Étant donné que le contenu de cette URL est inconnu de Google, le résultat de la recherche ressemble à ceci :

Pour empêcher définitivement une page d'apparaître dans les SERP, vous devez utiliser une balise méta robots "noindex" ou un en-tête HTTP X-Robots-Tag.
Dans ce cas, n'interdisez pas la page dans robots.txt , car la page doit être explorée pour que la balise "noindex" soit vue et respectée. Si l'URL est bloquée, toutes les balises robots sont inefficaces.
De plus, si une page a accumulé beaucoup de liens entrants, mais que Google est empêché d'explorer ces pages par robots.txt, alors que les liens sont connus de Google, l' équité du lien est perdue.
Que sont les balises Meta Robots
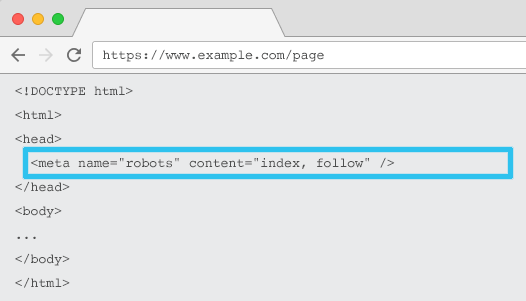
Placé dans le code HTML de chaque URL, meta name="robots" indique aux crawlers si et comment "indexer" le contenu et s'il faut "suivre" (c'est-à-dire explorer) tous les liens sur la page, en transmettant l'équité des liens.
En utilisant le meta name="robots" général, la directive s'applique à tous les crawlers. Vous pouvez également spécifier un agent utilisateur spécifique. Par exemple, meta name="googlebot". Mais il est rare d'avoir besoin d'utiliser plusieurs balises méta-robots pour définir des instructions pour des araignées spécifiques.
Il y a deux considérations importantes lors de l'utilisation des balises meta robots :
- Semblables à robots.txt, les balises méta sont des directives, pas des mandats, elles peuvent donc être ignorées par certains bots.
- La directive robots nofollow ne s'applique qu'aux liens de cette page. Il est possible qu'un robot d'exploration suive le lien depuis une autre page ou un autre site Web sans aucun suivi. Ainsi, le bot peut toujours arriver et indexer votre page indésirable.
Voici la liste de toutes les directives des balises meta robots :
- index : ordonne aux moteurs de recherche d'afficher cette page dans les résultats de recherche. Il s'agit de l'état par défaut si aucune directive n'est spécifiée.
- noindex : indique aux moteurs de recherche de ne pas afficher cette page dans les résultats de recherche.
- suivre : indique aux moteurs de recherche de suivre tous les liens de cette page et de transmettre l'équité, même si la page n'est pas indexée. Il s'agit de l'état par défaut si aucune directive n'est spécifiée.
- nofollow : indique aux moteurs de recherche de ne suivre aucun lien sur cette page ou de ne pas passer l'équité.
- tous : équivalent à « indexer, suivre ».
- aucun : équivalent à "noindex, nofollow".
- noimageindex : indique aux moteurs de recherche de ne pas indexer d'images sur cette page.
- noarchive : indique aux moteurs de recherche de ne pas afficher de lien en cache vers cette page dans les résultats de recherche.
- nocache : identique à noarchive, mais uniquement utilisé par Internet Explorer et Firefox.
- nosnippet : indique aux moteurs de recherche de ne pas afficher de méta-description ou d'aperçu vidéo pour cette page dans les résultats de recherche.
- notranslate : indique au moteur de recherche de ne pas proposer la traduction de cette page dans les résultats de recherche.
- unavailable_after : indique aux moteurs de recherche de ne plus indexer cette page après une date spécifiée.
- noodp : désormais obsolète, il empêchait autrefois les moteurs de recherche d'utiliser la description de la page de DMOZ dans les résultats de recherche.
- noydir : désormais obsolète, il empêchait autrefois Yahoo d'utiliser la description de la page de l'annuaire Yahoo dans les résultats de recherche.
- noyaca : empêche Yandex d'utiliser la description de la page du répertoire Yandex dans les résultats de recherche.
Comme documenté par Yoast, tous les moteurs de recherche ne prennent pas en charge toutes les balises méta des robots, ou ne savent même pas clairement ce qu'ils font et ne prennent pas en charge.
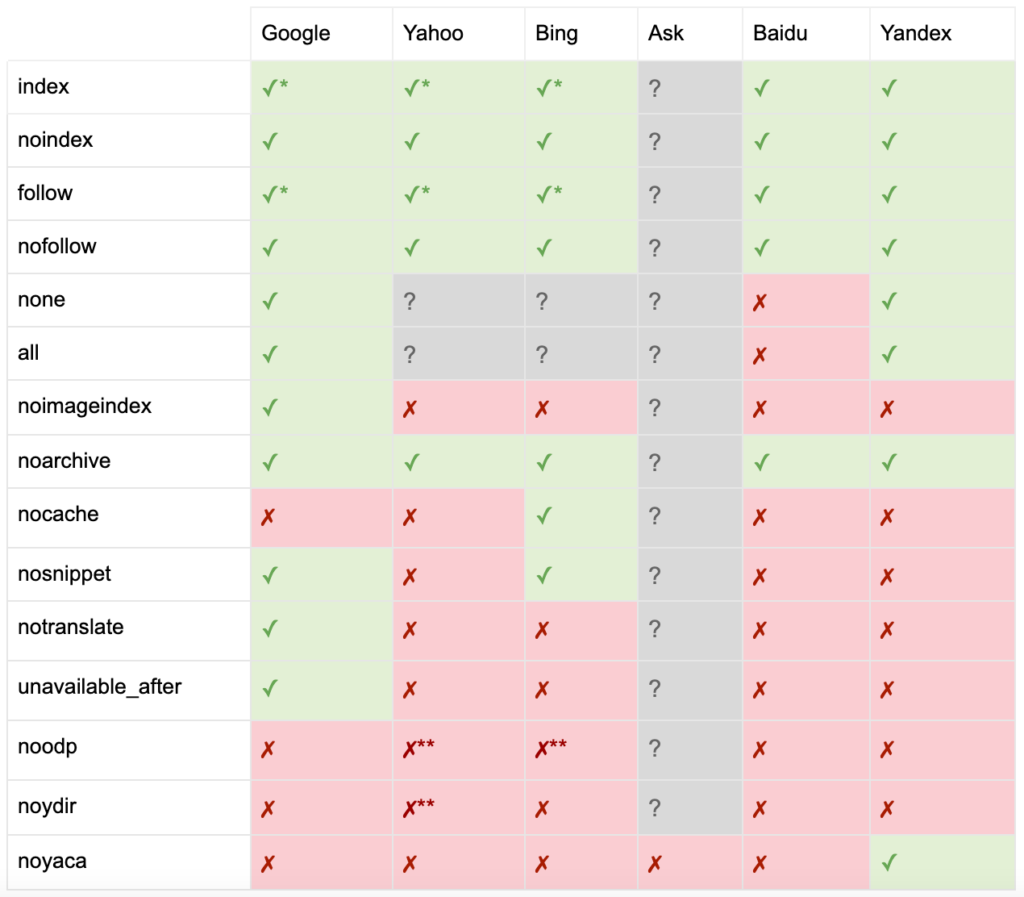
* La plupart des moteurs de recherche n'ont pas de documentation spécifique pour cela, mais il est supposé que la prise en charge des paramètres d'exclusion (par exemple, nofollow) implique la prise en charge de l'équivalent positif (par exemple, suivre).
** Alors que les attributs noodp et noydir peuvent toujours être "supportés", les répertoires n'existent plus, et il est probable que ces valeurs ne fassent rien.
Généralement, les balises des robots seront définies sur "indexer, suivre". Certains référenceurs considèrent l'ajout de cette balise dans le HTML comme redondant car c'est la valeur par défaut. Le contre-argument est qu'une spécification claire des directives peut aider à éviter toute confusion humaine.

Remarque : les URL avec une balise « noindex » seront explorées moins fréquemment et, si elle est présente pendant une longue période, cela conduira finalement Google à ne pas suivre les liens de la page.
Il est rare de trouver un cas d'utilisation pour "ne pas suivre" tous les liens d'une page avec une balise meta robots. Il est plus courant de voir "nofollow" ajouté sur des liens individuels en utilisant un attribut de lien rel = "nofollow". Par exemple, vous pouvez envisager d'ajouter un attribut rel = "nofollow" aux commentaires générés par les utilisateurs ou aux liens payants.
Il est encore plus rare d'avoir un cas d'utilisation SEO pour les directives de balises de robots qui n'abordent pas l'indexation de base et suivent le comportement, comme la mise en cache, l'indexation d'images et la gestion des extraits, etc.
Le défi avec les balises meta robots est qu'elles ne peuvent pas être utilisées pour des fichiers non HTML tels que des images, des vidéos ou des documents PDF. C'est là que vous pouvez vous tourner vers X-Robots-Tags.
Que sont les X-Robots-Tags
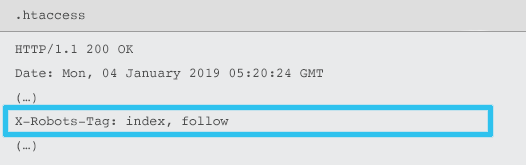
Les X-Robots-Tag sont envoyés par le serveur en tant qu'élément de l'en-tête de réponse HTTP pour une URL donnée à l'aide des fichiers .htaccess et httpd.conf.
Toute directive de balise méta robots peut également être spécifiée en tant que X-Robots-Tag. Cependant, un X-Robots-Tag offre une flexibilité et des fonctionnalités supplémentaires en plus.
Vous utiliserez X-Robots-Tag sur les balises meta robots si vous souhaitez :
- Contrôlez le comportement des robots pour les fichiers non HTML, plutôt que pour les fichiers HTML seuls.
- Contrôlez l'indexation d'un élément spécifique d'une page, plutôt que la page dans son ensemble.
- Ajoutez des règles pour savoir si une page doit être indexée ou non. Par exemple, si un auteur a plus de 5 articles publiés, indexez sa page de profil.
- Appliquez les directives d'indexation et de suivi au niveau de l'ensemble du site, plutôt qu'au niveau de la page.
- Utilisez des expressions régulières.
Évitez d'utiliser à la fois les méta-robots et la balise x-robots sur la même page - cela serait redondant.
Pour afficher les X-Robots-Tags, vous pouvez utiliser la fonction "Explorer comme Google" dans Google Search Console.
Directives Robots & SEO
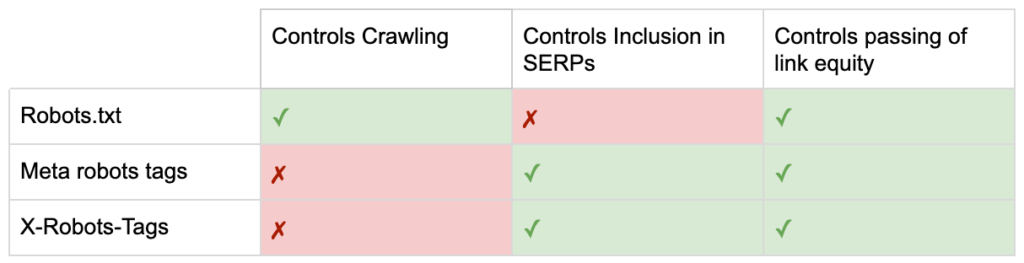
Alors maintenant, vous connaissez les différences entre les trois directives sur les robots.
robots.txt se concentre sur l'économie du budget de crawl, mais n'empêchera pas une page d'être affichée dans les résultats de recherche. Il agit comme le premier gardien de votre site Web, ordonnant aux robots de ne pas y accéder avant que la page ne soit demandée.
Les deux types de balises robots se concentrent sur le contrôle de l'indexation et la transmission de l'équité des liens. Les balises meta robots ne sont effectives qu'après le chargement de la page . Alors que les en-têtes X-Robots-Tag offrent un contrôle plus granulaire et sont efficaces après que le serveur a répondu à une demande de page.
Grâce à cette compréhension, les référenceurs peuvent faire évoluer la manière dont nous utilisons les directives des robots pour résoudre les problèmes d'exploration et d'indexation.
Bloquer les robots pour économiser la bande passante du serveur
Problème : en analysant vos fichiers journaux, vous verrez de nombreux agents utilisateurs prendre de la bande passante mais en redonner peu de valeur.
- Les crawlers SEO, tels que MJ12bot (de Majestic) ou Ahrefsbot (de Ahrefs).
- Outils qui enregistrent le contenu numérique hors ligne, tels que Webcopier ou Teleport.
- Les moteurs de recherche qui ne sont pas pertinents sur votre marché, tels que Baiduspider ou Yandex.
Solution sous-optimale : bloquer ces araignées avec robots.txt car il n'est pas garanti d'être honoré et est une déclaration plutôt publique, ce qui pourrait donner aux parties intéressées des informations compétitives.
Approche des meilleures pratiques : la directive plus subtile du blocage de l'agent utilisateur. Cela peut être accompli de différentes manières, mais cela se fait généralement en éditant votre fichier .htaccess pour rediriger toute demande d'araignée indésirable vers une page 403 - Interdit.
Pages de recherche de site interne utilisant le budget de crawl
Problème : sur de nombreux sites Web, les pages de résultats de recherche de site interne sont générées dynamiquement sur des URL statiques, qui consomment ensuite le budget d'analyse et peuvent entraîner des problèmes de contenu léger ou de contenu dupliqué en cas d'indexation.
Solution sous-optimale : interdire le répertoire avec robots.txt. Bien que cela puisse empêcher les crawler traps, cela limite votre capacité à vous classer pour les recherches de clients clés et pour que ces pages transmettent l'équité des liens.
Approche des meilleures pratiques : mapper les requêtes pertinentes et volumineuses sur des URL existantes conviviales pour les moteurs de recherche. Par exemple, si je recherche "samsung phone", plutôt que de créer une nouvelle page pour /search/samsung-phone, redirigez vers /phones/samsung.
Lorsque cela n'est pas possible, créez une URL basée sur des paramètres. Vous pouvez ensuite facilement spécifier si vous souhaitez que le paramètre soit exploré ou non dans Google Search Console.
Si vous autorisez l'exploration, analysez si ces pages sont de qualité suffisante pour être classées. Si ce n'est pas le cas, ajoutez une directive "noindex, follow" comme solution à court terme pendant que vous élaborez une stratégie pour améliorer la qualité des résultats afin d'aider à la fois le référencement et l'expérience utilisateur.
Paramètres de blocage avec des robots
Problème : les paramètres de chaîne de requête, tels que ceux générés par la navigation ou le suivi à facettes, sont connus pour consommer le budget d'exploration, créer des URL de contenu en double et diviser les signaux de classement.
Solution sous-optimale : interdire l'exploration des paramètres avec robots.txt ou avec une balise méta robots "noindex", car les deux (le premier immédiatement, le plus tard sur une période plus longue) empêcheront le flux d'équité de lien.
Approche des meilleures pratiques : assurez-vous que chaque paramètre a une raison d'être claire et mettez en œuvre des règles de tri, qui n'utilisent les clés qu'une seule fois et empêchent les valeurs vides. Ajoutez un attribut de lien rel=canonical aux pages de paramètres appropriées pour combiner la capacité de classement. Configurez ensuite tous les paramètres dans Google Search Console, où il existe une option plus granulaire pour communiquer les préférences d'exploration. Pour plus de détails, consultez le guide de gestion des paramètres du Search Engine Journal.
Blocage des zones d'administration ou de compte
Problème : empêcher le moteur de recherche d'explorer et d'indexer tout contenu privé.
Solution sous-optimale : utiliser robots.txt pour bloquer le répertoire, car il n'est pas garanti que les pages privées restent hors des SERP.
Approche des meilleures pratiques : utilisez une protection par mot de passe pour empêcher les robots d'exploration d'accéder aux pages et une directive de secours "noindex" dans l'en-tête HTTP.
Blocage des pages de destination marketing et des pages de remerciement
Problème : Vous devez souvent exclure des URL qui ne sont pas destinées à la recherche naturelle, telles que des e-mails dédiés ou des pages de destination de campagne CPC. De même, vous ne voulez pas que les personnes qui n'ont pas converti visitent vos pages de remerciement via les SERP.
Solution sous-optimale : interdire les fichiers avec robots.txt car cela n'empêchera pas le lien d'être inclus dans les résultats de la recherche.
Approche des meilleures pratiques : utilisez une balise méta "noindex".
Gérer le contenu dupliqué sur le site
Problème : certains sites Web ont besoin d'une copie d'un contenu spécifique pour des raisons d'expérience utilisateur, comme une version imprimable d'une page, mais veulent s'assurer que la page canonique, et non la page en double, est reconnue par les moteurs de recherche. Sur d'autres sites Web, le contenu dupliqué est dû à de mauvaises pratiques de développement, telles que la mise en vente du même article sur plusieurs URL de catégorie.
Solution sous-optimale : interdire les URL avec robots.txt empêchera la page en double de transmettre des signaux de classement. L'absence d'indexation pour les robots conduira éventuellement Google à traiter les liens comme "nofollow" également, empêchera la page en double de transmettre toute équité de lien.
Approche des meilleures pratiques : si le contenu dupliqué n'a aucune raison d'exister, supprimez la source et la redirection 301 vers l'URL conviviale du moteur de recherche. S'il y a une raison d'exister, ajoutez un attribut de lien rel=canonical pour consolider les signaux de classement.
Contenu léger des pages liées aux comptes accessibles
Problème : les pages liées au compte, telles que la connexion, l'inscription, le panier d'achat, le paiement ou les formulaires de contact, ont souvent un contenu léger et offrent peu de valeur aux moteurs de recherche, mais sont nécessaires pour les utilisateurs.
Solution sous-optimale : interdire les fichiers avec robots.txt car cela n'empêchera pas le lien d'être inclus dans les résultats de la recherche.
Approche des meilleures pratiques : pour la plupart des sites Web, ces pages devraient être très peu nombreuses et vous ne constaterez peut-être aucun impact sur les KPI de la mise en œuvre de la gestion des robots. Si vous en ressentez le besoin, il est préférable d'utiliser une directive "noindex", à moins qu'il n'y ait des requêtes de recherche pour de telles pages.
Baliser les pages en utilisant le budget de crawl
Problème : le balisage incontrôlé ronge le budget d'exploration et entraîne souvent des problèmes de contenu léger.
Solutions sous-optimales : interdire avec robots.txt ou ajouter une balise "noindex", car les deux empêcheront le classement des balises pertinentes pour le référencement et empêcheront (immédiatement ou éventuellement) le passage de l'équité des liens.
Approche des meilleures pratiques : évaluez la valeur de chacune de vos balises actuelles. Si les données montrent que la page ajoute peu de valeur aux moteurs de recherche ou aux utilisateurs, 301 les redirige. Pour les pages qui survivent à l'élimination, travaillez à améliorer les éléments de la page afin qu'ils deviennent utiles à la fois aux utilisateurs et aux bots.
Exploration de JavaScript et CSS
Problème : Auparavant, les bots ne pouvaient pas explorer JavaScript et d'autres contenus rich media. Cela a changé et il est maintenant fortement recommandé d'autoriser les moteurs de recherche à accéder aux fichiers JS et CSS afin de rendre éventuellement les pages.
Solution sous-optimale : interdire les fichiers JavaScript et CSS avec robots.txt pour économiser le budget d'exploration peut entraîner une mauvaise indexation et avoir un impact négatif sur les classements. Par exemple, le blocage de l'accès des moteurs de recherche à JavaScript qui diffuse une annonce interstitielle ou redirige les utilisateurs peut être considéré comme une dissimulation.
Approche des meilleures pratiques : vérifiez les problèmes de rendu avec l'outil "Explorer comme Google" ou obtenez un aperçu rapide des ressources bloquées avec le rapport "Ressources bloquées", tous deux disponibles dans la console de recherche Google. Si des ressources sont bloquées, ce qui pourrait empêcher les moteurs de recherche d'afficher correctement la page, supprimez l'interdiction de robots.txt.
Robot d'exploration SEO Oncrawl
 Apprendre encore plus
Apprendre encore plusListe de vérification des meilleures pratiques pour les robots
Il est effroyablement courant qu'un site Web ait été accidentellement supprimé de Google par une erreur de contrôle des robots.
Néanmoins, la manipulation des robots peut être un ajout puissant à votre arsenal SEO lorsque vous savez comment l'utiliser. Assurez-vous simplement de procéder avec sagesse et prudence.
Pour vous aider, voici une liste de contrôle rapide :
- Sécurisez les informations privées en utilisant la protection par mot de passe
- Bloquer l'accès aux sites de développement en utilisant l'authentification côté serveur
- Restreindre les crawlers qui consomment de la bande passante mais offrent peu de valeur en retour avec le blocage des agents utilisateurs
- Assurez-vous que le domaine principal et tous les sous-domaines ont un fichier texte nommé "robots.txt" dans le répertoire de niveau supérieur qui renvoie un code 200
- Assurez-vous que le fichier robots.txt contient au moins un bloc avec une ligne d'agent utilisateur et une ligne d'interdiction
- Assurez-vous que le fichier robots.txt comporte au moins une ligne de plan de site, entrée comme dernière ligne
- Validez le fichier robots.txt dans le testeur GSC robots.txt
- Assurez-vous que chaque page indexable spécifie ses directives de balise de robots
- Assurez-vous qu'il n'y a pas de directives contradictoires ou redondantes entre robots.txt, robots meta tags, X-Robots-Tags, fichier .htaccess et gestion des paramètres GSC
- Corrigez les erreurs "URL soumise marquée 'noindex'" ou "URL soumise bloquée par robots.txt" dans le rapport de couverture GSC
- Comprendre la raison de toute exclusion liée aux robots dans le rapport de couverture GSC
- Assurez-vous que seules les pages pertinentes sont affichées dans le rapport GSC « Ressources bloquées »
Allez vérifier la manipulation de vos robots et assurez-vous que vous le faites correctement.