
Ce que tout rédacteur de contenu devrait savoir sur le référencement technique
Publié: 2020-12-10Votre équipe de marketing de contenu a une responsabilité principale : créer du contenu qui génère des résultats. Leur travail nécessite un mélange de créativité et de logique, trouver les bons mots pour éduquer et persuader votre public, et utiliser les bonnes données pour optimiser le contenu pour la performance.
En tant que responsable marketing, il serait difficile de demander à vos créateurs de contenu d'être également responsables de votre référencement technique. Le référencement technique nécessite une compréhension approfondie du développement Web, une compétence complexe à maîtriser par elle-même.
Bien que vous ne puissiez pas demander à vos créateurs de contenu d'optimiser votre référencement technique, ils doivent en comprendre les bases. Cela permet à votre équipe de contenu de communiquer beaucoup plus facilement avec vos développeurs Web et d'augmenter les performances du contenu qu'ils produisent.
Jetons un coup d'œil aux bases du référencement technique que votre équipe de contenu doit maîtriser afin de comprendre comment leur contenu parfaitement écrit peut gagner encore plus de lecteurs organiques.
Qu'est-ce que le référencement technique ?
En termes simples, le référencement technique est le côté technique du référencement. Il englobe toutes les tâches qui nécessitent une connaissance du développement Web, du fonctionnement des sites Web et de la manière dont Google les explore et les indexe.
Pour être plus précis, le référencement technique inclut toute optimisation que vous effectuez pour aider Google à explorer et à indexer correctement vos pages Web.
Exploration et indexation
Toutes les pages Web qui apparaissent dans les résultats de Google (également appelées SERP ou pages de résultats des moteurs de recherche) doivent d'abord exister dans l'index de Google. Cet index est le "répertoire" où Google répertorie toutes les pages qu'ils analysent lors du classement d'une liste de pages pour une requête qui est tapée dans le champ de recherche.
Avant de pouvoir ajouter une page dans leur index, les bots de Google (les algorithmes qu'ils utilisent pour analyser une page Web) doivent pouvoir y accéder. Comme l'explique le support de Google :
« Il n'existe pas de registre central de toutes les pages Web, donc Google doit constamment rechercher de nouvelles pages et les ajouter à sa liste de pages connues. Une fois que Google a découvert l'URL d'une page, il visite ou explore la page pour découvrir ce qu'elle contient.“
En d'autres termes, l'exploration se produit lorsque les robots de Google analysent une page. N'oubliez pas que j'ai dit « scanner » et non « indexer » car le crawling ne fait référence qu'à la capacité des bots de Google à scanner une page ; l'indexation vient plus tard.
La première étape d'une mise en œuvre technique correcte du référencement consiste à s'assurer que votre site Web est "crawlable" ; c'est-à-dire que Google devrait pouvoir explorer toutes les pages de votre site.
Il existe de nombreuses raisons pour lesquelles un site Web ou une page ne serait pas explorable, notamment :
- Le serveur est en panne
- L'URL est cassée
- Il y a un problème lors du chargement du site/de la page
- Aucune autre page n'y renvoie
Certains types de problèmes d'exploration ont tendance à être rares car ils sont relativement faciles à repérer. Néanmoins, vous ne devez jamais négliger l'exploration dans votre analyse : d'autres problèmes peuvent être difficiles à trouver, tels que les pages orphelines que vous avez créées mais que Google ne peut pas trouver, les pages qui sont redirigées dans des cercles ou des parties d'un site qui peuvent potentiellement créer un nombre infini de pages à explorer par Google, telles que des archives pendant des années sans contenu.
Pour trouver des problèmes d'exploration, vous pouvez utiliser Google Search Console, qui fonctionne comme le représentant de Google pour votre site Web : pour tout problème technique que vous pourriez rencontrer, GSC (comme on l'appelle) vous aidera.
Dans GSC, accédez à "Rapport de couverture" et vérifiez la colonne Erreurs.
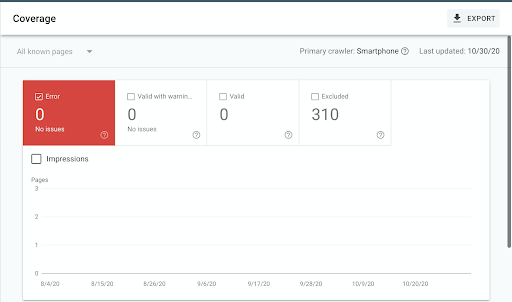
Vous pouvez revérifier tout problème d'exploration en utilisant un outil de référencement qui inclut un robot d'exploration SEO, comme Oncrawl. Les robots d'exploration SEO vous diront quand ils trouvent des problèmes 5xx ou 4xx (ces chiffres étranges font référence à leur code d'état, par exemple, une erreur 404 se produit lorsqu'une page ne peut pas être atteinte ou trouvée).
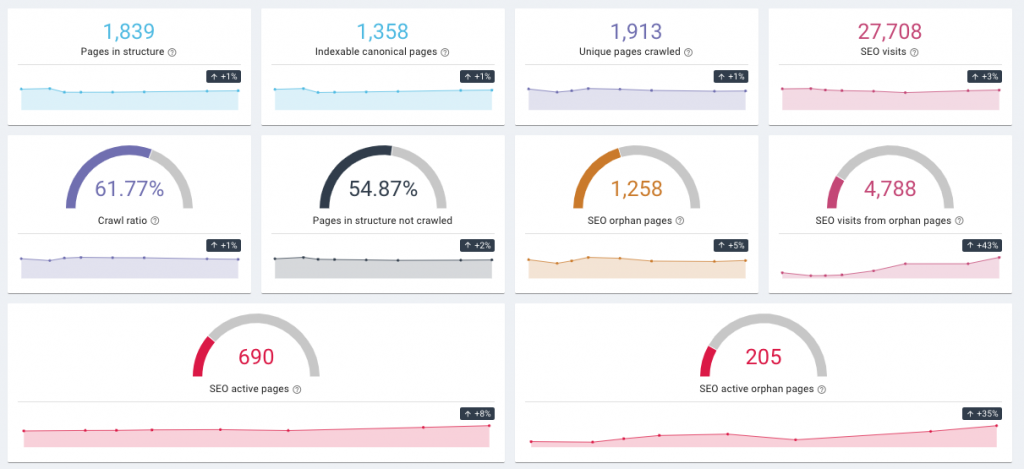 Rapport d'impact SEO Oncrawl
Rapport d'impact SEO Oncrawl 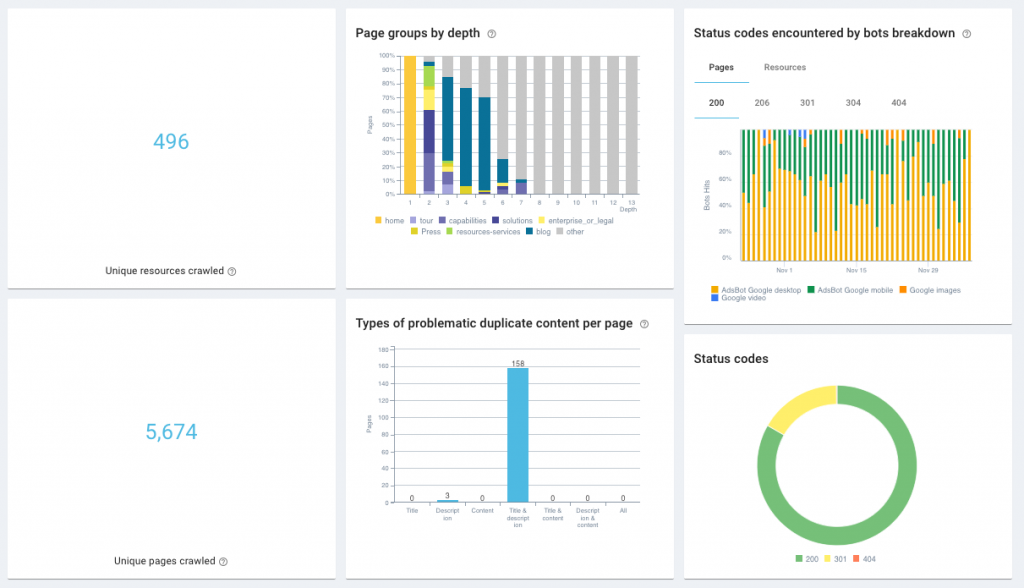 Tableau de bord de santé Oncrawl
Tableau de bord de santé Oncrawl
Une fois que Google explore une page, il ne l'indexe pas immédiatement. L'indexation se produit lorsque Google décide d'ajouter une page à son index, le même index qu'il consulte lorsqu'il classe une page pour les SERP. Comme ils le disent :
"Google analyse le contenu de la page, catalogue les images et les fichiers vidéo intégrés à la page, et essaie autrement de comprendre la page. Ces informations sont stockées dans l'index Google, une énorme base de données stockée dans de très nombreux (beaucoup !) ordinateurs.“
Pour être clair : toute page que les robots de Google peuvent explorer sera explorée, alors que nous ne pouvons pas en dire autant de l'indexation. Pour indexer une page, vous devez indiquer clairement que Google doit le faire. Voici comment:
- Évitez les erreurs de serveur . La meilleure façon d'indexer une page est de s'assurer qu'elle est explorée en premier lieu. Éviter les erreurs de serveur est la meilleure façon de le faire. Vérifiez le rapport de couverture de GSC, comme indiqué précédemment.
- Ajoutez des liens internes . Toutes vos pages doivent être liées les unes aux autres au moins une fois. Utilisez un texte d'ancrage pertinent qui décrit correctement le contenu de la page (par exemple, si je devais créer un lien vers cet article, j'utiliserais le référencement technique du texte d'ancrage).
- Créez et chargez un sitemap XML . Ce sont comme des brochures que vous utilisez pour présenter les pages de votre site aux robots de Google. Selon un ingénieur de Google, les sitemaps XML sont la "deuxième source la plus importante" pour trouver des URL - les liens internes semblent être la première.
- Évitez les indications selon lesquelles Google devrait rester à l'écart de la page . Ceux-ci peuvent inclure des instructions pour ne pas explorer la page dans le guide du site pour les bots, le fichier robots.txt ou des attributs « nofollow » sur les liens pointant vers la page.
- Assurez-vous de ne pas demander à Google d'indexer une autre page . Les pages peuvent suggérer à Google qu'une autre page serait un meilleur choix pour indexer le même contenu, comme nous le verrons plus tard. Il peut envoyer Google vers une autre page avec une redirection, ou il peut également dire directement à Google de ne pas l'indexer avec une balise "noindex". Les pages qui font cela ne sont pas considérées comme indexables.
Pour garantir l'indexabilité de votre page, utilisez l'outil d'inspection d'URL de GSC :
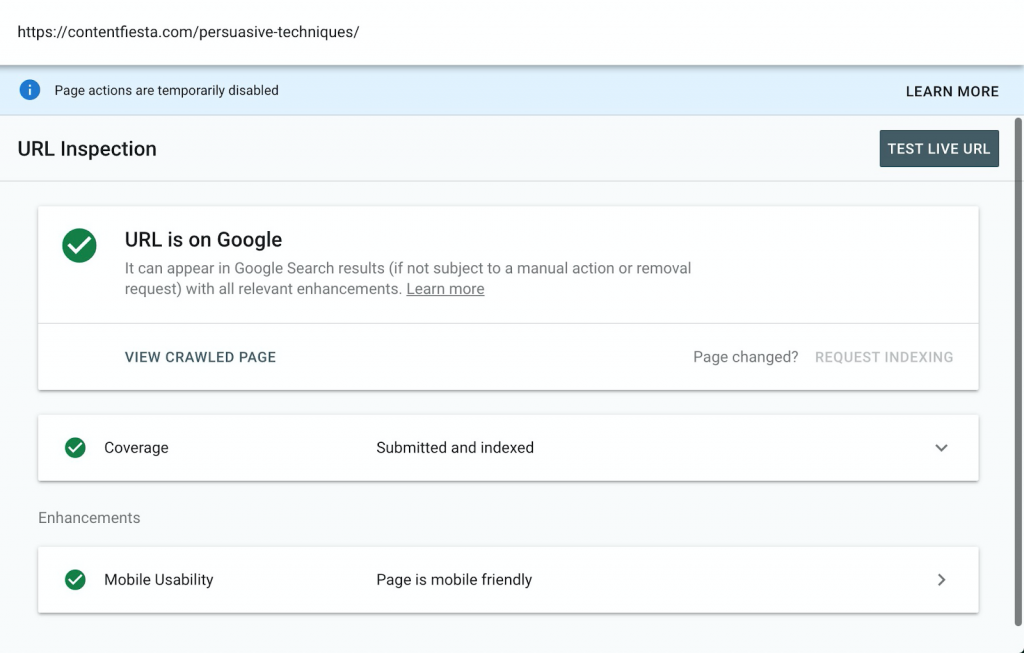
Une fois que Google a indexé une page que vous souhaitez activement classer, vous êtes prêt à partir. Mais il existe de nombreux cas dans lesquels vous ne voudriez pas que Google indexe vos pages.
- Vous avez des informations sensibles que personne en dehors de votre entreprise ne devrait voir
- Vous avez plusieurs versions d'une page que vous souhaitez que Google ignore (plus tard, vous verrez à quoi cela ressemble lorsque nous parlerons des "URL canoniques")
- Vous ne voulez pas diluer votre autorité de domaine en indexant des pages non pertinentes, par exemple, vos conditions de confidentialité
Lorsque vous désindexez une page à dessein, vous utilisez le puissant pouvoir de Google pour le bien. Faites-le inconsciemment et vous nuirez considérablement aux performances de votre site.
Le reste de ce guide couvrira trois sujets qui affectent directement ou indirectement l'exploration et l'indexation de votre site.
Structure du site
La structure de votre site fait référence à la façon dont vous planifiez et organisez vos pages. Cependant, nous ne parlons pas de vos menus, mais plutôt de la structure créée par les liens d'une page à l'autre. Les référenceurs appellent souvent la structure du site "architecture du site" parce que vous définissez la disposition des différentes parties de votre site, comment elles sont liées les unes aux autres et comment elles soutiennent toutes votre site.
De nombreux problèmes d'exploration et d'indexation surviennent lorsque Google ne peut pas accéder à une page ou l'indexer en raison d'une structure de site inefficace ; des sites où différentes parties s'emmêlent de manière incohérente et compliquée. Pour résoudre ce problème, une théorie de l'architecture de site SEO utilise la règle empirique suivante : un site ne doit pas avoir plus de trois à quatre couches.

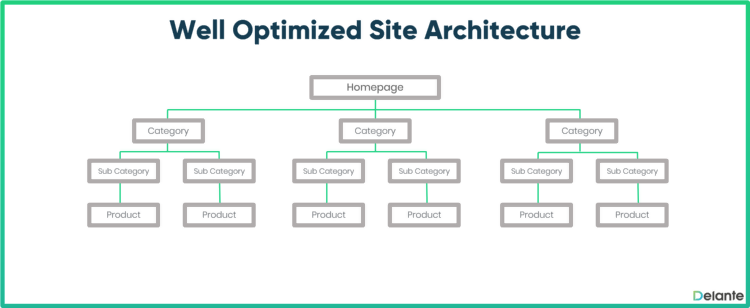
La source
Une structure de site aussi simple signifierait qu'à partir de votre page d'accueil, vous pourriez cliquer sur une page de blog à partir de votre page d'accueil, puis sur un article de blog rédigé par votre équipe de contenu. Vous pouvez cliquer sur d'autres articles ou pages (par exemple, votre page de contact), mais tous peuvent également être accessibles en moins de trois ou quatre clics en partant de la page d'accueil. Alternativement, un site de commerce électronique peut avoir une page d'accueil, une page de catégorie et une page de produit (les paniers de paiement ne sont pas indexés, ils ne comptent donc pas).
Ces structures de site simples sont appelées "plates" en raison de leur apparence, comme vous l'avez vu dans l'image ci-dessus. Que votre site comporte deux, trois ou quatre couches, vous souhaitez disposer d'un site Web facile à naviguer, à la fois pour vos visiteurs et pour le bot de Google.
Selon Google, « La navigation d'un site Web est importante pour aider les visiteurs à trouver rapidement le contenu qu'ils recherchent. Cela peut également aider les moteurs de recherche à comprendre quel contenu le webmaster juge important.“
 La source
La source
Pour avoir une idée de la structure de votre site, réalisez un audit de site avec Screaming Frog ou Oncrawl.
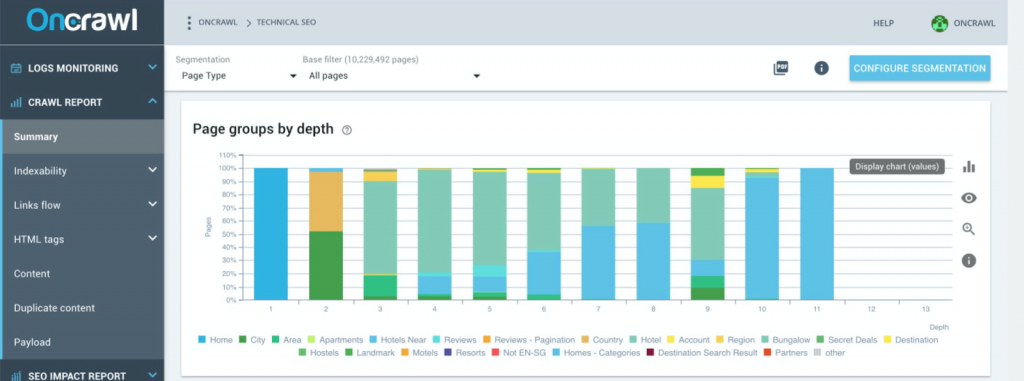
La source
Si vous trouvez que la structure de votre site comporte trop de couches et de sections déroutantes, vous devez repenser votre structure avec l'aide de votre équipe de développement et d'experts SEO professionnels. Vos créateurs de contenu n'ont peut-être pas besoin de participer à la discussion, mais il est important qu'ils sachent pourquoi ce sujet est important : si le contenu qu'ils créent est trop bas dans l'architecture, ou n'en fait pas du tout partie, il ne sera pas indexé.
[Ebook] SEO technique pour les penseurs non techniques
 Lire l'ebook
Lire l'ebookOptimisation de la vitesse
La vitesse est l'un des facteurs les plus critiques qui affectent l'expérience utilisateur (UX) et les classements. Par « vitesse », j'entends le temps qu'il faut à un navigateur pour récupérer les données d'un site Web à partir d'un serveur, créer la page et l'afficher.
Chaque page contient des dizaines, voire des centaines d'éléments qu'un navigateur doit récupérer pour charger une page. La façon dont un navigateur charge ces éléments définira la vitesse de votre site ; plus le temps de chargement des éléments de votre site est long, plus la vitesse de votre page est lente.
L'optimisation de la vitesse de votre site est l'un des changements techniques SEO les plus importants que vous puissiez apporter. Les modifications d'optimisation de vitesse les plus courantes et, le plus souvent, les plus efficaces que vous pouvez apporter sont les suivantes :
- Compresser et réduire vos fichiers HTML, CSS et JS
- Optimiser la taille et la qualité de compression de vos images
- Configuration de la mise en cache du navigateur
- Mise en place d'un CDN
Selon une étude de Backlinko, la taille totale d'une page a la plus forte corrélation avec les temps de chargement, au-dessus de tous les autres facteurs.
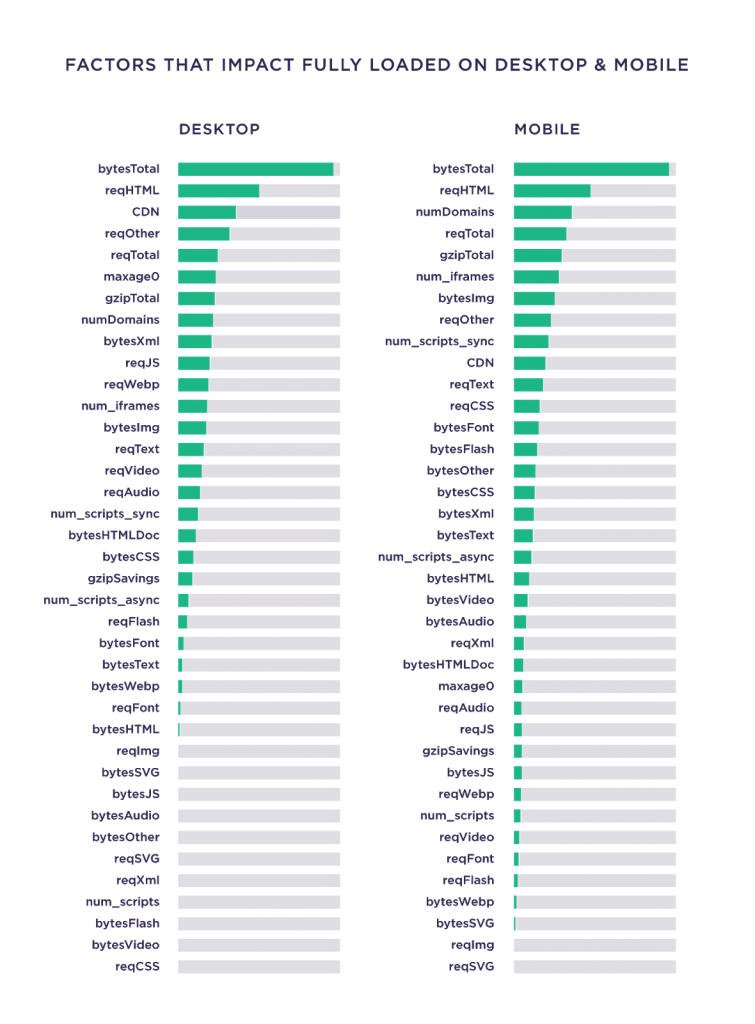
Pour un créateur de contenu, l'optimisation de la vitesse sort souvent de son champ d'action, car elle nécessite des compétences côté serveur et hautement techniques, par exemple, l'utilisation de RegEx, Apache HTTP Server, etc. Néanmoins, tout spécialiste du marketing de contenu peut être responsable de deux aspects :
- Utilisation des plugins : L'installation de plugins WordPress est non seulement facile mais utile. Le problème est qu'ils peuvent réduire la vitesse d'un site, donc chaque fois qu'un spécialiste du marketing de contenu décide d'installer un plugin, il doit discuter correctement de l'implication de la vitesse avec un SEO et un développeur Web.
- Optimisation des images : les images ont tendance à être les éléments les plus lourds d'une page. Pour surmonter ce problème, utilisez le format JPG, compressez vos images et, dans la mesure du possible, réduisez leurs dimensions.
Si vous optimisez une page, qui est déjà bien classée mais pas dans les mêmes premières positions, et vous avez vu qu'elle est déjà correctement optimisée pour le référencement sur la page, vérifiez sa vitesse. Ajoutez votre page dans l'outil PageSpeed Insights de Google - ou alternativement, sur le rapport Payload d'Oncrawl - et optimisez-la en fonction de ses suggestions. Si ces suggestions sortent de votre champ d'application, discutez-en avec votre équipe SEO et les développeurs responsables de la gestion de votre site.
Optimisation du contenu
Lorsqu'un rédacteur de contenu crée un nouveau contenu, son objectif principal est d'éduquer le lecteur. Peu de temps après la publication du contenu, un problème technique peut survenir, ce qui peut ruiner le fonctionnement du contenu.
Je parle de contenu dupliqué , un problème qui survient lorsque Google indexe plusieurs versions d'une page. Les sites de commerce électronique ont tendance à avoir du contenu en double, ce qui entraîne l'indexation de pages variantes telles que :
- http://www.domain.com/product-list.html
- http://www.domain.com/product-list.html?sort=color
- http://www.domain.com/product-list.html?sort=price
Ces erreurs se produisent involontairement et discrètement. Votre but est d'éviter l'indexation de vos pages en double. Pour commencer, auditez votre site avec l'aide du détecteur de quasi-doublons d'Oncrawl.
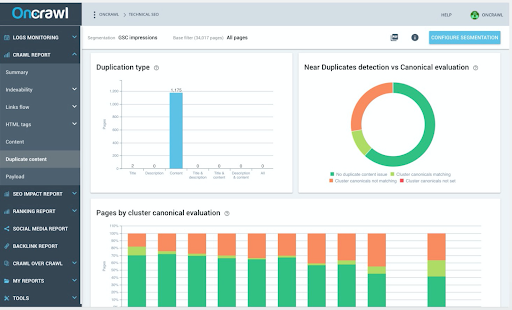
Il existe plusieurs solutions pour corriger le contenu dupliqué :
- Désindexez-le : ajoutez la balise "noindex" à votre page en double, afin que Google la supprime de son index.
- Ajoutez la balise canonique : Ajoutez la balise rel="canonical" à la page dupliquée et indiquez la version réelle (ou "canonique") de la page. Cela ne le désindexera pas, mais indiquera à Google quelle page ils doivent utiliser dans les SERP.
- Redirigez-le : utilisez une redirection 301 ou HTTP pour diriger les visiteurs et les bots de la page en double (http://www.domain.com/product-list.html?sort=color de l'exemple ci-dessus) vers la bonne .
- Supprimer : Dans certains cas, la page en double a un fichier séparé sur votre serveur ou votre CMS. Dans ce cas, supprimez la page en double et redirigez son URL.
- Réécrivez-le : S'il vous arrive d'avoir plusieurs pages similaires les unes aux autres, vous pouvez modifier leur contenu pour vous assurer qu'elles sont reconnues comme des pages distinctes.
Le contenu en double n'est pas un petit problème à ignorer, alors assurez-vous d'auditer correctement votre site et de résoudre tous les cas de ce problème.
En résumé
Les conseils présentés ici ne sont que la pointe de l'iceberg. Le référencement technique peut être une tâche écrasante pour tout rédacteur de contenu non technique, c'est pourquoi un développeur doit apporter les modifications les plus complexes.
Néanmoins, aucun créateur de contenu ne devrait ignorer les bases du référencement technique, car elles sont essentielles pour s'assurer que le contenu fonctionne comme prévu. Tout problème pouvant entraîner une exploration et une indexation incorrectes de Google peut finir par causer de graves problèmes à l'ensemble de l'opération de marketing de contenu.
Selon vous, qu'est-ce qu'un spécialiste du marketing de contenu devrait savoir d'autre sur le référencement technique ?