
10 problèmes SEO techniques courants – et comment les repérer
Publié: 2019-06-04Après avoir effectué des services de référencement dans divers secteurs, vous êtes parfois en mesure de relever des problèmes courants, en particulier lorsque vous travaillez sur un CMS commun comme WordPress, Shopify ou SquareSpace.
Ici, j'ai décrit 10 problèmes techniques de référencement assez courants que vous pourriez rencontrer lors de l'optimisation d'un site Web.
Je ne dis pas que ces questions seront définitivement problématiques pour vous ou votre client – très souvent, le contexte est toujours très important. Il n'y a pas toujours de solution unique, mais il est probablement toujours bon de se méfier des scénarios décrits ci-dessous.
1 – Fichier robots.txt bloquant l'accès à Googlebot
Ce n'est pas nouveau pour la plupart des SEO techniques, mais il est toujours très facile de négliger de vérifier le fichier des robots - et pas seulement au moment d'exécuter un audit technique, mais en tant que vérification récurrente.
Vous pouvez utiliser un outil comme Search Console (l'ancienne version) pour voir si Google a des problèmes d'accès, ou vous pouvez simplement essayer de crawler votre site en tant que Googlebot avec un outil comme OnCrawl (sélectionnez simplement leur User Agent). OnCrawl obéira au robots.txt sauf indication contraire de votre part.
Exportez les résultats du crawl et comparez-les à une liste connue de pages sur votre site et vérifiez qu'il n'y a pas d'angles morts du crawler.
Pour montrer que cela se produit encore assez souvent, et sur certains sites assez importants, j'ai remarqué il y a quelques semaines que l'outil de test de vitesse de Pingdom était bloqué au sein de Google.
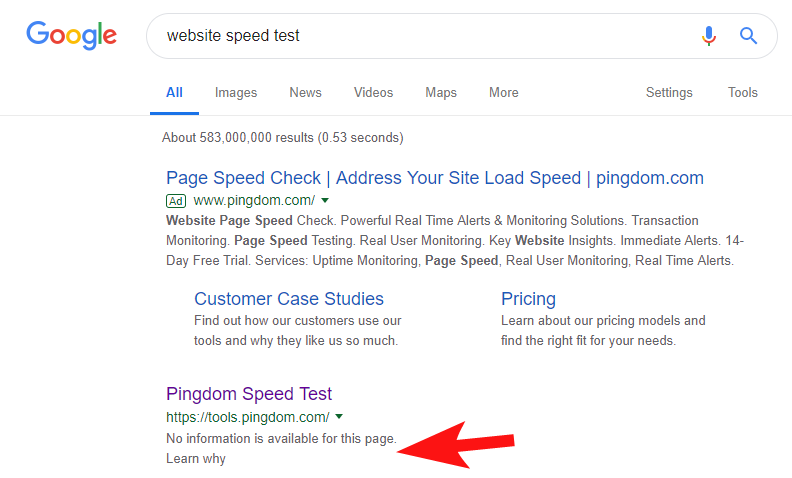
En regardant leur fichier de robots (et en essayant par la suite d'explorer leur page depuis OnCrawl en tant que Googlebot), j'ai confirmé mes soupçons qu'ils bloquaient l'accès à leur site.
Le fichier robots.txt coupable est illustré ci-dessous :

Je les ai contactés avec un "FYI" mais je n'ai eu aucune réponse, mais quelques jours plus tard, j'ai vu que tout était revenu à la normale. Ouf – je pouvais à nouveau dormir facilement !
Dans leur cas, il semblait que chaque fois que vous analysiez votre site dans le cadre de leur audit de vitesse, il créait une URL comprenant ce caractère haché mis en évidence dans le fichier robots ci-dessus.
Peut-être que ceux-ci étaient explorés et même indexés d'une manière ou d'une autre, et ils voulaient contrôler cela (ce qui serait très compréhensible). Dans ce cas, ils n'ont probablement pas pleinement testé l'impact potentiel - qui était probablement minime en fin de compte.
Voici leurs robots actuels pour toute personne intéressée.

Il convient de noter que dans certains cas, vous pouvez accéder aux modifications historiques du fichier robots.txt à l'aide d'Internet Wayback Machine. D'après mon expérience, cela fonctionne mieux sur les sites plus grands, comme vous pouvez l'imaginer - ils sont beaucoup plus souvent explorés par l'archiveur de la Wayback Machine.
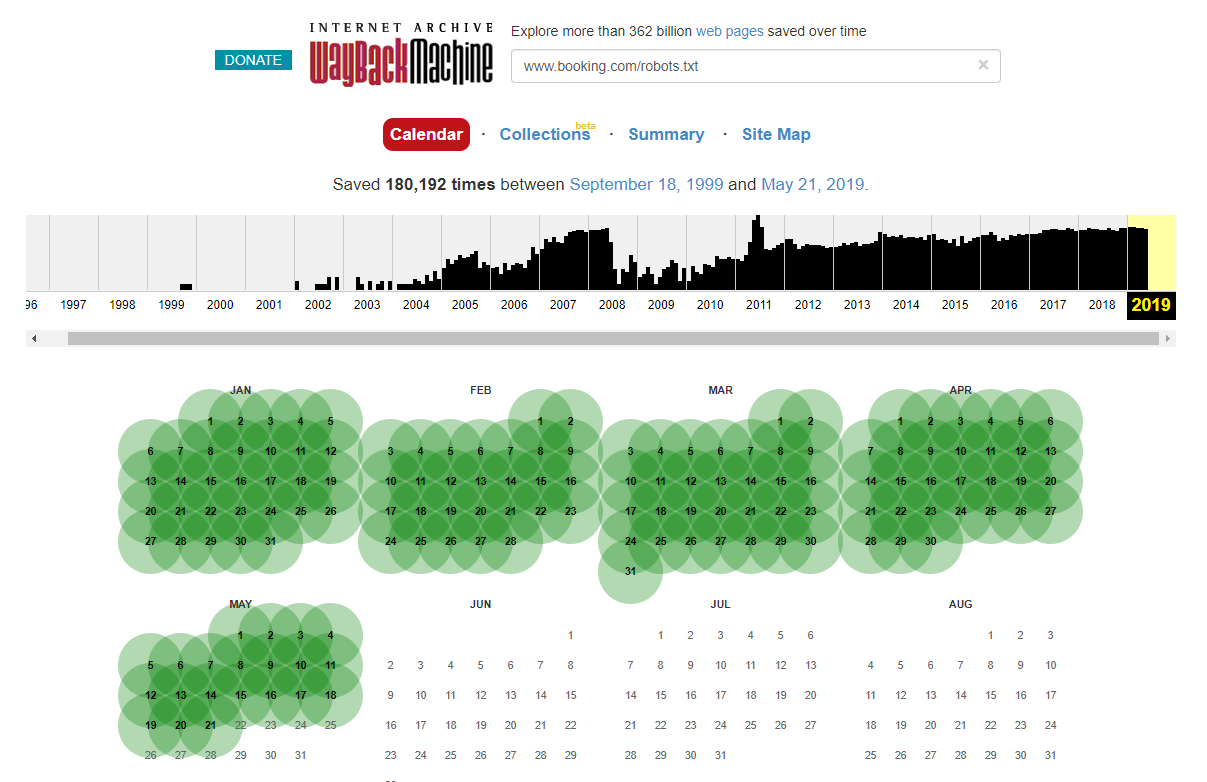
Ce n'est pas la première fois que je vois un robots.txt en direct dans la nature causant un peu de ravage dans le SERPS. Et ce ne sera certainement pas le dernier - c'est une chose si simple à négliger (c'est littéralement un fichier après tout), mais sa vérification devrait faire partie du calendrier de travail continu de chaque SEO.
D'après ce qui précède, vous pouvez voir que même Google gâche parfois son fichier de robots, s'empêchant d'accéder à son contenu. Cela aurait pu être intentionnel, mais en regardant le langage de leur fichier de robots ci-dessous, j'en doute d'une manière ou d'une autre.
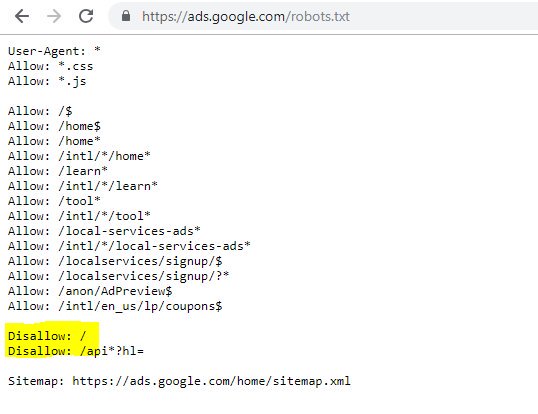
L'option Disallow : / en surbrillance dans ce cas empêchait l'accès à tous les chemins d'URL ; il aurait été plus sûr de lister les sections spécifiques du site qui ne devraient pas être explorées à la place.
2 – Problèmes de configuration de domaine au niveau DNS
C'est étonnamment commun, mais c'est généralement une solution rapide. C'est l'un de ces changements SEO à faible coût et *potentiellement* à fort impact que le référencement technique adore.
Souvent, avec les implémentations SSL, je ne vois pas la version de domaine non-WWW configurée correctement, comme la redirection 302 vers l'URL suivante et la formation d'une chaîne, ou le pire scénario ne se charge pas du tout.
Un bon exemple ici est celui du site Web Hotel Football.
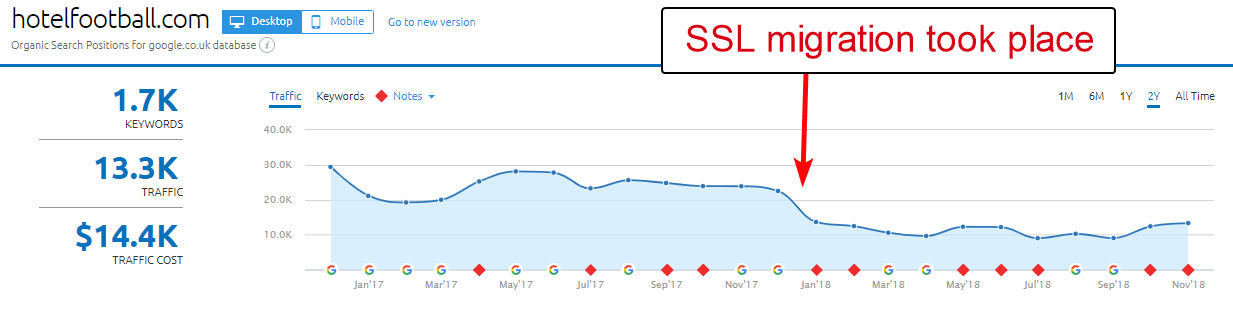
Ils ont subi une migration SSL au début de l'année dernière, ce qui ne s'est pas très bien passé pour eux à en juger par le rapport de présentation du domaine de SEMRush ci-dessus.
J'avais remarqué celui-ci il y a quelque temps car j'ai beaucoup travaillé dans l'industrie du voyage et de l'hôtellerie - et avec un grand amour du football, j'étais intéressé de voir à quoi ressemblait leur site Web (et comment il fonctionnait de manière organique bien sûr ! ).
C'était en fait très facile à diagnostiquer - le site avait une tonne de très bons backlinks, tous pointant vers le domaine WWW non SSL à l'adresse http://www.hotelfootball.com/
Si vous essayez d'accéder à cette URL ci-dessus, elle ne se charge pas. Oups. Et c'est comme ça depuis environ 18 mois maintenant, au moins. J'ai contacté l'agence qui gère le site via Twitter pour l'en informer, mais je n'ai pas eu de réponse.
Avec celui-ci, tout ce qu'ils doivent faire est de s'assurer que les paramètres de la zone DNS sont corrects, avec un enregistrement "A" en place pour la version "WWW" du domaine, qui pointe vers la bonne adresse IP (un CNAME fonctionnerait également). Cela empêchera le domaine de ne pas être résolu.
Le seul inconvénient, ou la raison pour laquelle celui-ci prend tant de temps à résoudre, est qu'il peut être difficile d'accéder au panneau de gestion de domaine d'un site, ou même que les mots de passe ont été perdus, ou qu'il n'est pas considéré comme une priorité élevée.
Envoyer des instructions pour réparer à une personne non technique qui détient les clés du nom de domaine n'est pas toujours une bonne idée non plus.
Je serais très désireux de voir l'impact organique si / quand ils sont en mesure de faire l'ajustement ci-dessus - surtout compte tenu de tous les backlinks que le domaine non WWW a créés depuis que l'hôtel a été lancé par les anciens footballeurs de Manchester United Gary Neville, Ryan Giggs et compagnie.
Bien qu'ils se classent n ° 1 dans Google pour le nom de leur hôtel (comme vous l'imaginez), ils ne semblent pas du tout avoir un classement solide pour aucun de leurs termes de recherche sans marque les plus compétitifs (ils sont actuellement en position 10 sur Google pour "hôtel près d'Old Trafford").
Ils ont marqué un peu leur propre but avec ce qui précède – mais résoudre ce problème pourrait au moins contribuer à résoudre ce problème.
Robot d'exploration SEO Oncrawl
 Apprendre encore plus
Apprendre encore plus3 – Pages escrocs dans le plan du site XML
Encore une fois, c'est assez basique mais c'est étrangement courant - lors de l'examen d'un plan de site XML de sites (qui est presque toujours à domain.com/sitemap.xml ou domain.com/sitemap_index.xml, il peut y avoir des pages répertoriées ici qui ne vraiment pas n'ont pas besoin d'être indexés.
Les coupables typiques incluent les pages de remerciement masquées (merci d'avoir soumis un formulaire de contact), les pages de destination PPC qui peuvent causer des problèmes de contenu en double, ou d'autres formes de pages/publications/taxonomies que vous n'avez déjà pas indexées ailleurs.
Les inclure à nouveau dans le plan du site XML peut envoyer des signaux contradictoires aux moteurs de recherche - vous ne devriez vraiment répertorier que les pages que vous voulez qu'ils trouvent et indexent, ce qui est principalement le but du plan du site.
Vous pouvez désormais utiliser le rapport pratique de la Search Console pour savoir si des pages ont ou non été incluses dans un plan de site XML d'un site via l'option Inspecter l'URL.
Si vous avez un site assez petit, vous pouvez probablement simplement revoir manuellement votre sitemap XML dans votre navigateur - sinon téléchargez-le et comparez-le à une analyse complète de vos URL indexables.
Souvent, vous pouvez détecter ce type de contenu inestimable et de mauvaise qualité en effectuant une recherche site:domain.com dans Google pour renvoyer tout ce qui a été indexé.
Il convient de noter ici que cela peut contenir du contenu ancien et qu'il ne faut pas s'y fier pour être à 100% à jour, mais c'est une vérification facile pour s'assurer qu'il n'y a pas de tonnes de contenu qui gonflent vos efforts de référencement et qui grugent les budgets de crawl.
4 – Problèmes avec Googlebot rendant votre contenu
Celui-ci mérite un article entier qui lui est consacré, et j'ai personnellement l'impression d'avoir passé toute une vie à jouer avec l'outil de recherche et de rendu de Google.
Beaucoup de choses ont déjà été dites à ce sujet (et à propos de JavaScript) par certains SEO très compétents, donc je ne vais pas approfondir cela, mais vérifier comment Googlebot rend votre site sera toujours digne de votre temps.
L'exécution de quelques vérifications via des outils en ligne peut aider à découvrir les angles morts de Googlebot (zones du site auxquelles ils ne peuvent pas accéder), les problèmes avec votre environnement d'hébergement, les problèmes de consommation de ressources JavaScript et même les problèmes de mise à l'échelle de l'écran.
Normalement, ces outils tiers sont très utiles pour diagnostiquer le problème (Google vous indique même quand une ressource est bloquée à cause de votre fichier robots par exemple) mais parfois vous pouvez vous retrouver à tourner en rond.
Pour montrer un exemple vivant d'un site problématique, je vais me tirer une balle dans le pied et référencer mon propre site Web personnel - et un thème WordPress particulièrement frustrant que j'utilise.
Parfois, lors de l'exécution d'une inspection d'URL à partir de la Search Console, je reçois l'avertissement "La page n'est pas adaptée aux mobiles" (voir ci-dessous).
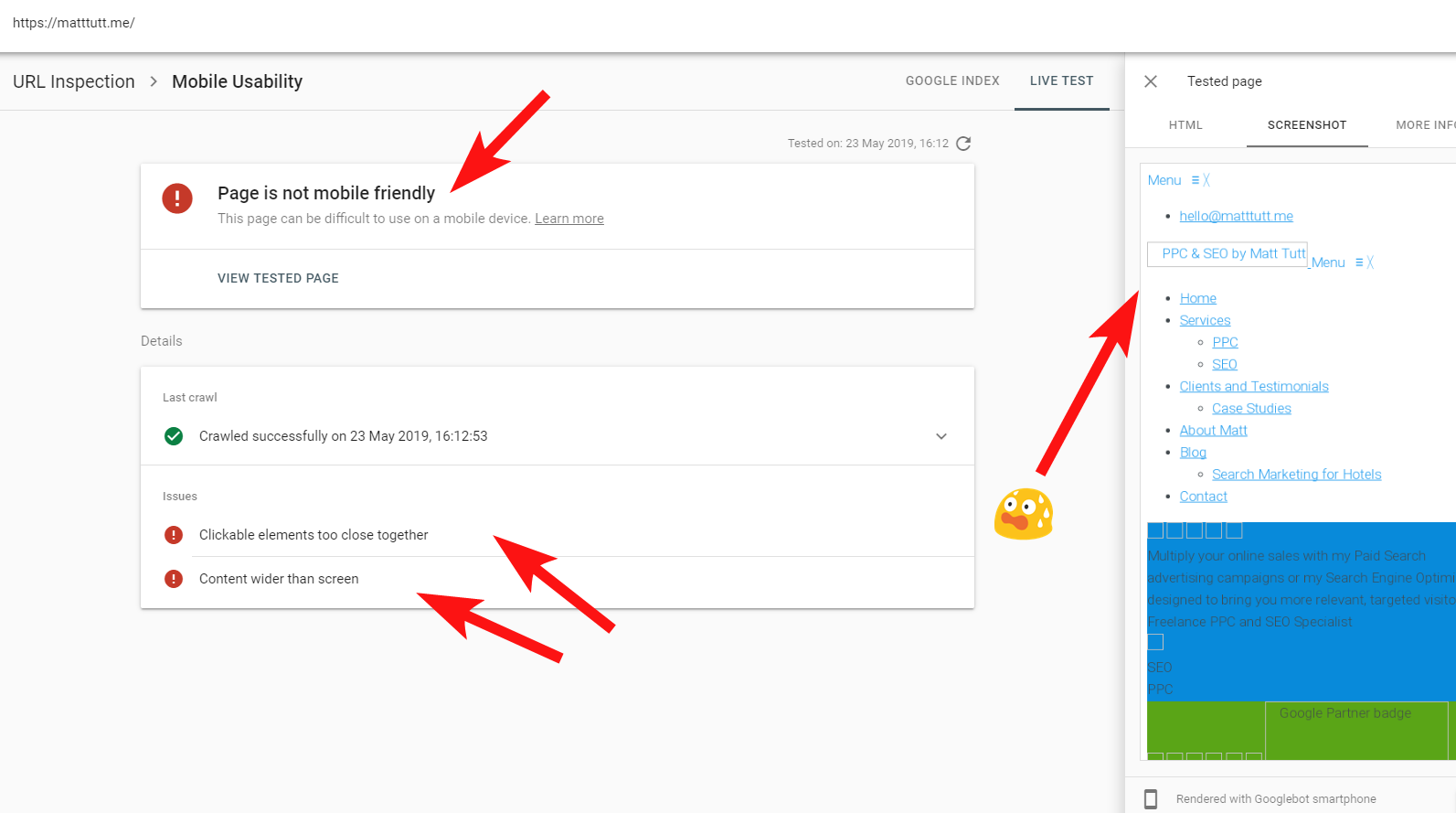
En cliquant sur l'onglet Plus d'informations (en haut à droite), il donne une liste de ressources auxquelles Googlebot n'a pas pu accéder, principalement des fichiers CSS et image.
C'est probablement parce que Googlebot ne peut pas toujours consacrer toute son "énergie" au rendu de la page - parfois c'est parce que Google se méfie de planter mon site (ce qui est gentil de leur part), et d'autres fois je pourrais être limité car ils ont utilisé beaucoup de ressources pour aller chercher et rendre mon site déjà.
Parfois, à cause de ce qui précède, il vaut la peine d'exécuter ces tests plusieurs fois à intervalles étalés pour obtenir une histoire plus vraie. Je vous recommande également de vérifier les journaux du serveur si vous le pouvez, pour vérifier comment Googlebot a accédé (ou n'a pas accédé) au contenu de votre site.
Les statuts 404 ou autres pour ces ressources seraient clairement un mauvais signe, surtout s'ils sont cohérents.
Dans mon cas, Google appelle le site pour ne pas être adapté aux mobiles, ce qui est principalement dû à l'échec de certains fichiers de style CSS lors du rendu, ce qui peut à juste titre sonner l'alarme.
Pour rendre les choses plus confuses, lors de l'exécution du Mobile Friendly Test de Google, ou lors de l'utilisation de tout autre outil tiers, aucun problème n'est détecté : le site est adapté aux mobiles.
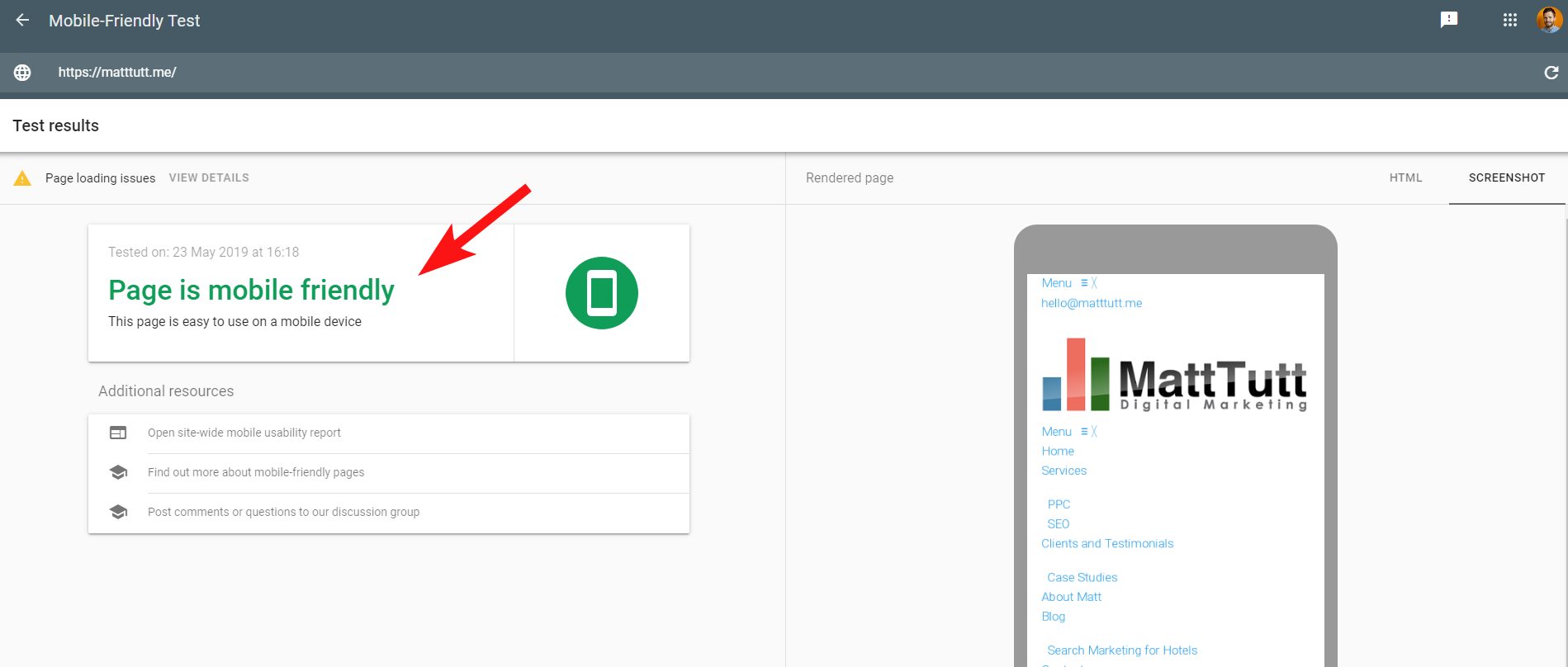
Ces messages contradictoires de Google peuvent être difficiles à décoder pour les SEO et les développeurs Web. Pour mieux comprendre, j'ai contacté John Mueller qui m'a suggéré de vérifier mon hébergeur (aucun problème) et que le fichier CSS peut en effet être mis en cache par Google.
La console de recherche utilise un ancien service de rendu Web (WRS) par rapport à l'outil adapté aux mobiles, donc de nos jours, j'ai tendance à donner plus de poids à ce dernier.
Avec Google annonçant un nouveau Googlebot avec les dernières capacités de rendu, tout cela pourrait être configuré pour changer, il vaut donc la peine de se tenir au courant des meilleurs outils à utiliser pour les vérifications de rendu.
Une autre astuce ici - si vous voulez voir un rendu défilable complet d'une page, vous pouvez passer à l'onglet HTML de l'outil de test mobile de Google, appuyez sur CTRL + A pour mettre en surbrillance tout le code HTML rendu, puis copiez et collez dans un éditeur de texte et enregistrer en tant que fichier HTML.
L'ouvrir dans votre navigateur (les doigts croisés, parfois cela dépend du CMS utilisé !) vous donnera un rendu déroulant. Et l'avantage de cela est que vous pouvez vérifier le rendu de n'importe quel site - vous n'avez pas besoin d'accéder à la Search Console.
5 – Sites piratés et backlinks spammés
C'est assez amusant à attraper et peut souvent se faufiler sur des sites qui fonctionnent sur des versions plus anciennes de WordPress ou d'autres plates-formes CMS qui nécessitent des mises à jour de sécurité régulières.
Avec ce client (un spa de beauté), j'ai remarqué des termes de recherche étranges apparaissant dans la Search Console.
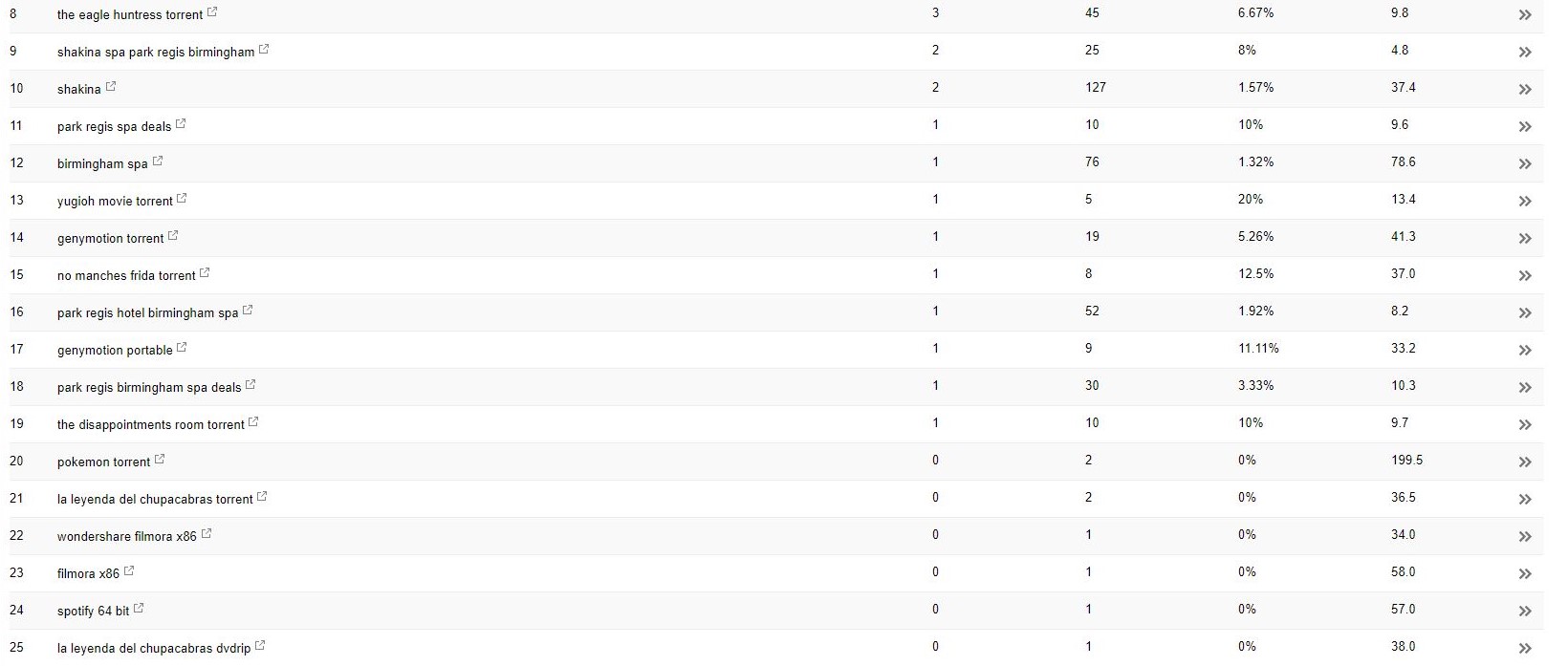
Étonnamment, non seulement ils ont eu des impressions dans la Search Console, mais aussi des clics, ce qui signifie que quelque chose doit avoir été indexé sur le domaine.
À en juger par les requêtes, il s'agissait clairement de spam, et ce n'est pas quelque chose auquel le client voudrait que son entreprise soit associée.
Une simple recherche "site:domain.com" dans Google a mis au jour des centaines de pages de torrents supposés que le client était censé héberger sur son site.
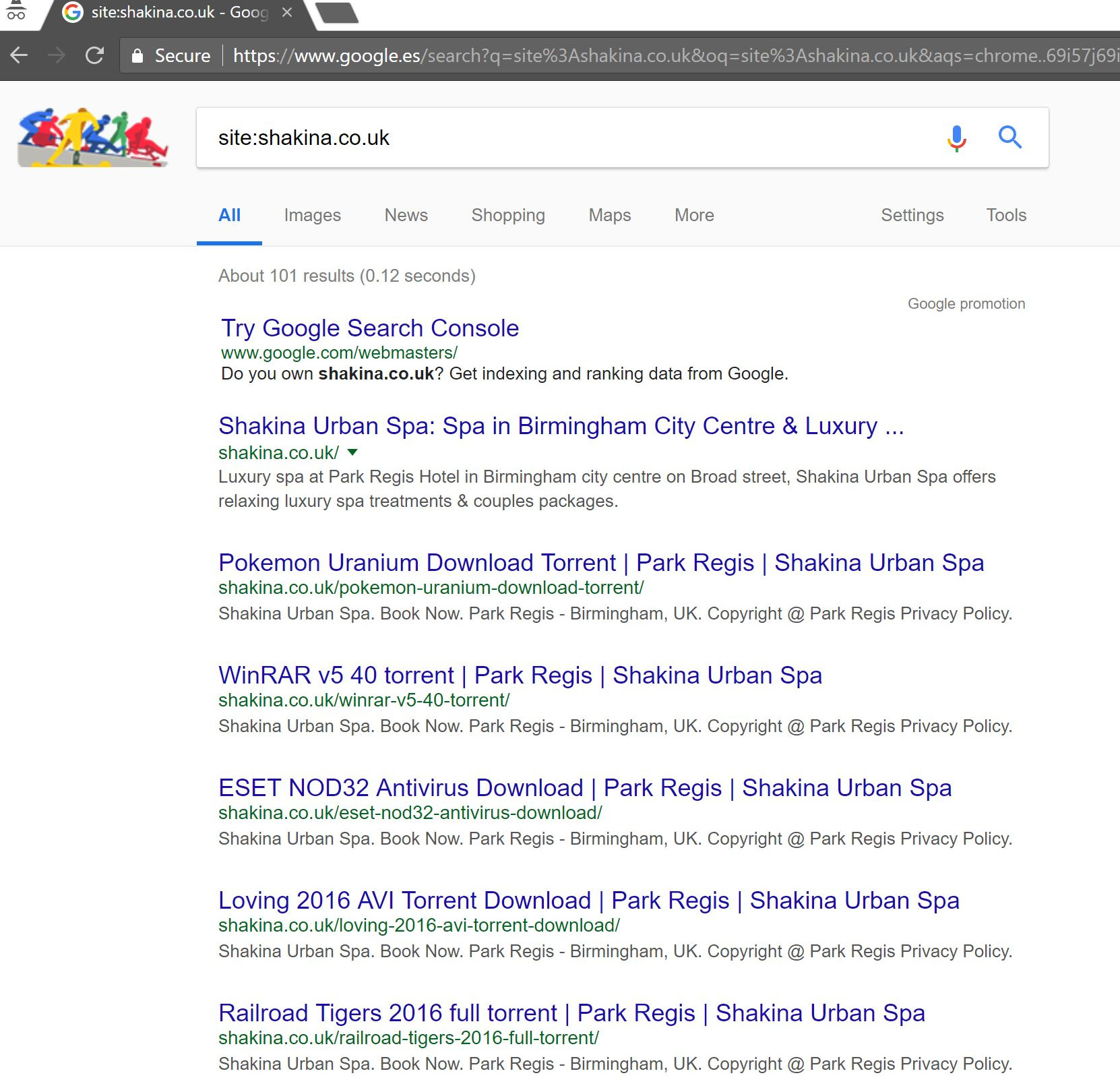
La visite de l'une de ces URL a en fait entraîné une erreur 404 - mais elles étaient toujours indexées (j'ai également vérifié divers agents utilisateurs et ils ont tous obtenu la même erreur 404).
Ensuite, j'ai fait passer le domaine par le vérificateur de backlinks de Majestic et il a donné une longue liste de backlinks de très mauvaise qualité pointant vers ces pages sur les sites clients - ce qui a probablement aidé à les indexer.

Regarder le nuage d'ancrage de Majestic des backlinks a vraiment montré l'étendue du problème.

La seule solution ici était de désavouer tous ces backlinks par domaine, puis de faire table rase de l'installation de WordPress dans l'espoir d'éliminer toute injection de code, ou d'installer une nouvelle copie de WordPress.
Si vous êtes vraiment préoccupé par le contenu indexé dans des cas comme celui ci-dessus, vous pouvez également servir un code de statut 410 pour vraiment clarifier les choses avec les robots de recherche.
Ce qui précède conviendrait aux sites qui ont reçu des avertissements juridiques en raison de revendications de droits d'auteur de la part de producteurs de films - ce qui peut parfois se produire dans des situations comme celle-ci si le problème n'est pas résolu rapidement.
6 – Mauvaises configurations de référencement international
Étant basé en Espagne mais naviguant sur Internet dans mon anglais natal, je me retrouve souvent automatiquement redirigé vers une version espagnole d'un site Web.
Bien que je comprenne la logique (je suis basé en Espagne donc je veux naviguer sur le site en espagnol), c'est assez ennuyeux du point de vue de l'expérience utilisateur, et si ce n'est pas fait correctement, cela peut aussi causer des ravages avec votre référencement international.
Des sites comme Google Ads amènent cela à un autre niveau - en utilisant Angular JavaScript pour générer dynamiquement du contenu en fonction de ma position, sans même passer par une redirection de page de quelque nature que ce soit et en chargeant le contenu directement dans le DOM.
Ma méthode de choix préférée lorsque plusieurs langues sont disponibles consiste à rediriger 302 un utilisateur vers une langue en fonction des paramètres de son navigateur Internet.
Par conséquent, si quelqu'un a l'allemand comme langue par défaut dans Google Chrome, il est probablement à l'aise pour lire le site en allemand, quel que soit son emplacement physique.
Cela aide également à surmonter les difficultés lorsque quelqu'un est basé dans une région où plusieurs langues sont parlées, comme en Suisse où le français, l'italien, l'allemand et le romanche sont tous utilisés.
Il est également essentiel, à des fins de convivialité, de s'assurer qu'il existe une option pour changer de langue en fonction de vos préférences, juste au cas où ils voudraient changer.
Dans un cas, j'ai travaillé avec un hôtel basé à Barcelone, où un script de redirection de langage JavaScript a été ajouté à un site sans tenir compte de l'impact sur le référencement.
Ce script a redirigé les utilisateurs en fonction du paramètre de langue de leur navigateur (ce qui n'est pas trop mal en soi) via une redirection JavaScript côté client.
Malheureusement, dans ce cas, le script n'a pas été configuré correctement en raison d'une configuration étrange des permaliens des sites, et lorsqu'il est combiné avec le fait que la balise HTML lang manquait sur toutes les pages du site, Googlebot est devenu un peu fou…
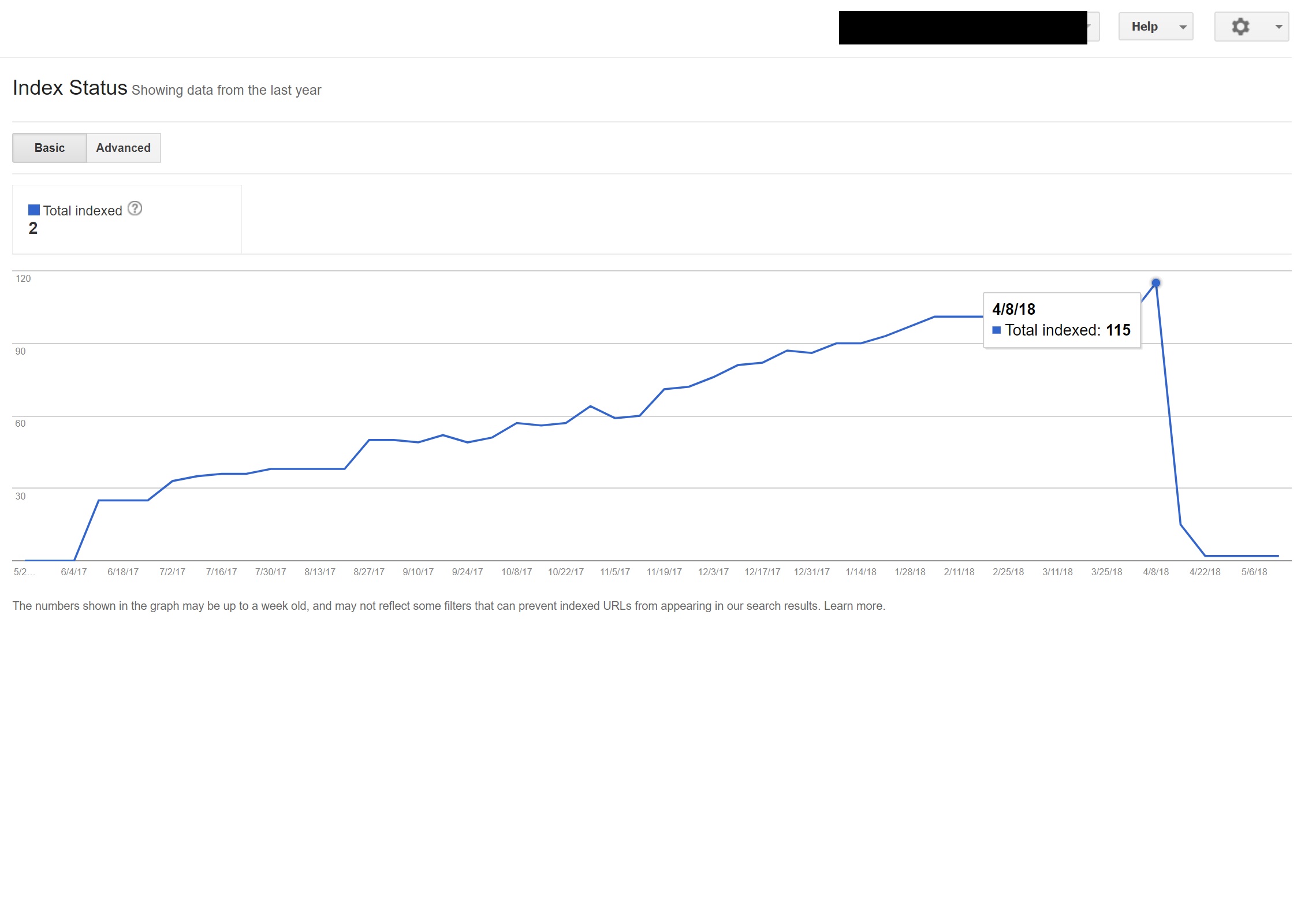
Dans cet exemple, presque tout le contenu non anglais du site a été désindexé par Google, car il était redirigé vers des pages qui n'existaient pas, provoquant ainsi plusieurs erreurs 404.
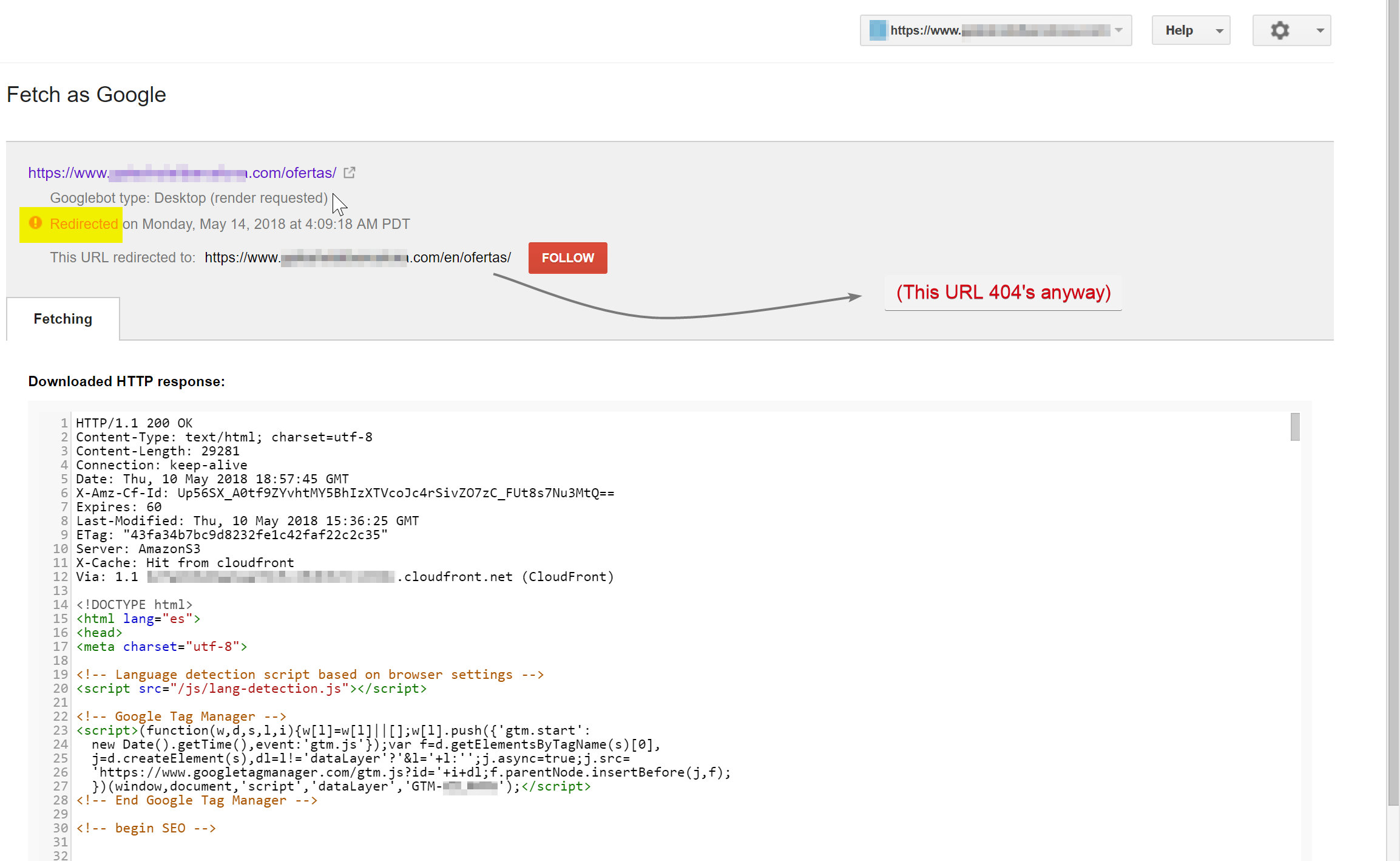
Googlebot essayait d'explorer le contenu espagnol (qui existait sur hotelname.com/ofertas) et était redirigé vers hotelname.com/en/ofertas - une URL inexistante.
Étonnamment, dans ce cas, Googlebot suivait toutes ces redirections JavaScript, et comme il ne pouvait pas trouver ces URL, il a été obligé de les supprimer de son index.
Dans le cas ci-dessus, j'ai pu le confirmer en accédant aux journaux du serveur du site, en filtrant jusqu'à Googlebot et en vérifiant où il recevait les 404.
La suppression du script de redirection JavaScript défectueux a résolu le problème et, heureusement, les pages traduites n'ont pas été désindexées pendant longtemps.
C'est toujours une bonne idée de tester complètement les choses - investir dans un VPN peut aider à diagnostiquer ces types de scénarios, ou même changer votre emplacement et/ou votre langue dans le navigateur Chrome.
[Étude de cas] Gérer plusieurs audits de sites
 Lire l'étude de cas
Lire l'étude de cas7 – Contenu dupliqué
Le contenu en double est un problème assez courant et bien discuté, et il existe de nombreuses façons de vérifier le contenu en double sur votre site - Richard Baxter a récemment écrit un excellent article sur le sujet.
Dans mon cas, le problème est probablement un peu plus simple. J'ai régulièrement vu des sites publier du contenu de qualité, souvent sous la forme d'un article de blog, mais partager ensuite presque instantanément ce contenu sur un site Web tiers comme Medium.com.
Medium est un excellent site pour réutiliser le contenu existant afin d'atteindre un public plus large, mais il faut faire attention à la façon dont cela est abordé.
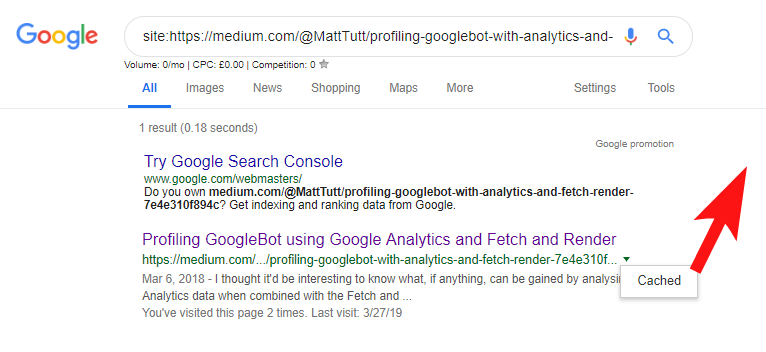
Lors de l'importation de contenu de WordPress vers Medium, pendant ce processus, Medium utilisera l'URL de votre site Web comme balise canonique. Donc, en théorie, cela devrait aider à donner à votre site Web le mérite du contenu, en tant que source originale.
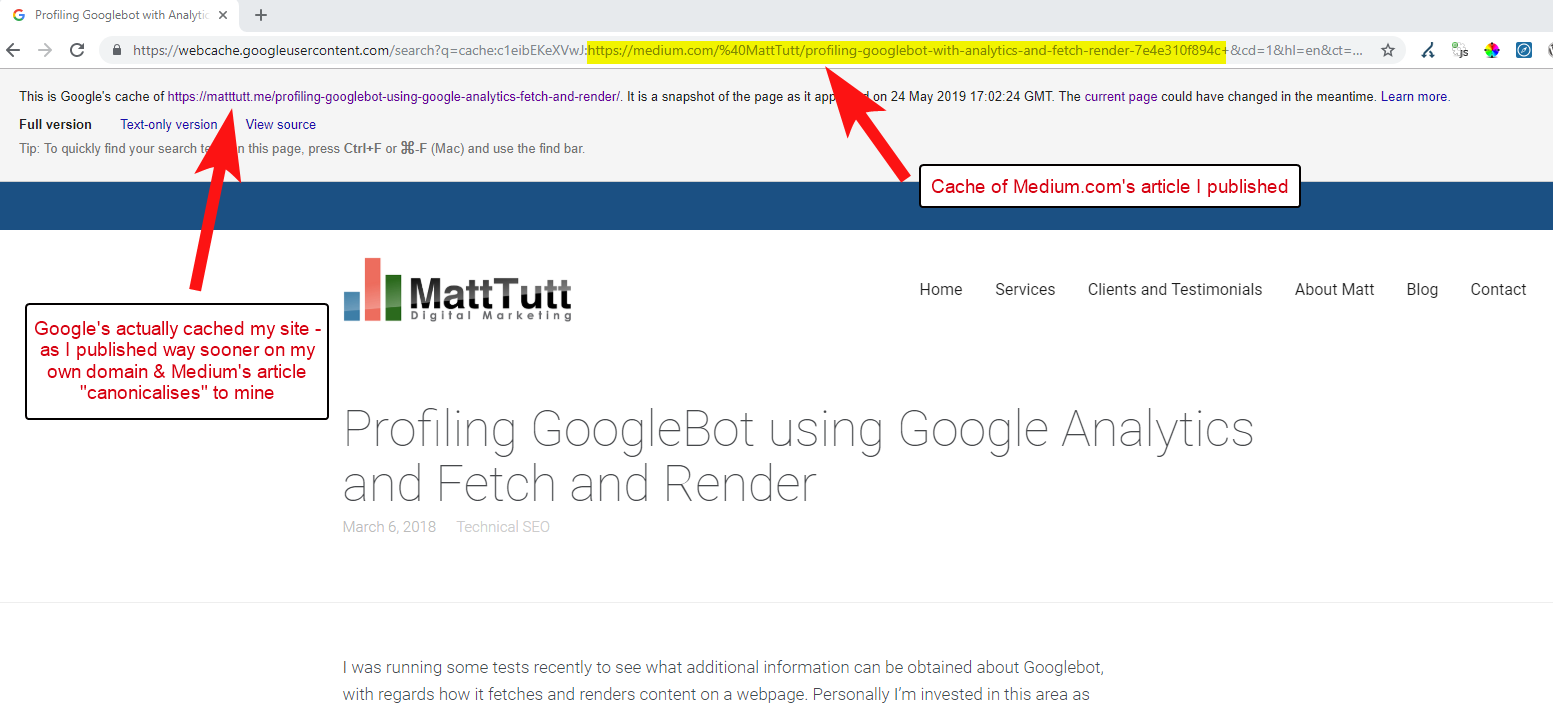
D'après certaines de mes analyses, cela ne fonctionne pas toujours comme ça.
Je pense que c'est le cas car lorsqu'un article est publié sur Medium sans laisser au préalable le temps à Google d'explorer et d'indexer l'article sur votre domaine, si l'article passe bien sur Medium (ce qui est un peu aléatoire), votre contenu devient indexés et associés au site de Medium malgré leur pointage canonique vers le vôtre.
Une fois que le contenu est ajouté à Medium (et en particulier s'il est populaire), vous pouvez à peu près garantir que l'article sera récupéré et republié sur le Web ailleurs presque instantanément - donc encore une fois, votre contenu est dupliqué ailleurs.
Pendant que tout cela se passe, il est probable que si votre domaine est assez petit en termes d'autorité, Google n'a peut-être même pas eu la chance d'explorer et d'indexer le contenu que vous avez publié - et il se peut même que l'élément de rendu du crawl/index n'est pas encore terminé, ou il y a du JavaScript lourd causant un grand décalage entre le crawl, le rendu et l'indexation de ce contenu.
J'ai vu des situations où une grande entreprise publie un excellent article, mais le lendemain, elle le publie sous la forme d'un article de réflexion sur un énorme blog d'actualités de l'industrie. En plus de cela, leur site avait un problème où le contenu était dupliqué (et indexé) sur https://domain.com et https://www.domain.com.
Quelques jours après la publication, lors de la recherche d'une phrase exacte de l'article entre guillemets dans Google, le site Web de l'entreprise était introuvable. Au lieu de cela, le blog de l'industrie faisant autorité était en première place, et d'autres rééditeurs prenaient les positions suivantes.
Dans ce cas, le contenu a été associé au blog de l'industrie et donc tous les liens que l'article gagne bénéficieront à ce site Web - et non à l'éditeur d'origine.
Si vous allez réutiliser du contenu n'importe où sur le Web, il est probable qu'il soit indexé, vous devez vraiment attendre d'être complètement sûr qu'il a été indexé par Google sur votre propre domaine.
Vous travaillez probablement dur pour créer et élaborer votre contenu - ne jetez pas tout cela en étant trop désireux de republier ailleurs !
8 – Mauvaise configuration AMP (déclaration d'URL AMP manquante)
Seule une poignée de clients que j'ai aidés ont choisi d'essayer AMP, peut-être sur la base de certaines des nombreuses études de cas financées par Google concernant son utilisation.
Parfois, je ne savais même pas qu'un client avait une version AMP de son site - il y avait un trafic étrange apparaissant dans les rapports de référence Analytics - où la version AMP du site renvoyait à la version du site non AMP.
Dans ce cas, les versions de page AMP n'étaient pas configurées correctement car il n'y avait aucune référence d'URL provenant de l'en-tête des pages non AMP.

Sans dire aux moteurs de recherche qu'une page AMP existe à une URL particulière, il n'y a pas grand intérêt à configurer AMP - le fait est qu'elle est indexée et renvoyée dans le SERPS pour les utilisateurs mobiles.
L'ajout de la référence à votre page non-AMP est un moyen important d'informer Google de la page AMP, et il est important de se rappeler que les balises canoniques sur les pages AMP ne doivent pas se référencer elles-mêmes : elles renvoient à la page non-AMP.
Et bien qu'il ne s'agisse pas vraiment d'une considération technique pour le référencement, il convient de noter que vous devez toujours inclure le code de suivi sur les pages AMP si vous souhaitez pouvoir signaler des informations sur le trafic et le comportement des utilisateurs.
Généralement, dans le cadre de mes audits SEO, j'aime également effectuer quelques vérifications de base de la mise en œuvre de l'analyse - sinon les données qui vous ont été fournies peuvent ne pas être très utiles, surtout s'il y a eu une configuration d'analyse bloquée.
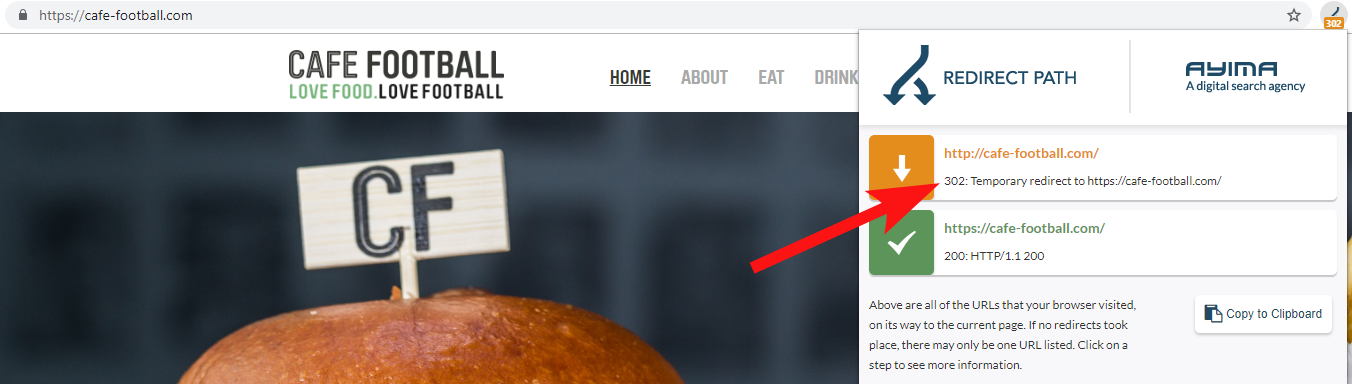
9 – Domaines hérités qui redirigent 302 ou forment une chaîne de redirections
Lorsque vous travaillez avec une grande marque hôtelière indépendante aux États-Unis, qui a subi plusieurs changements de marque au cours des dernières années (ce qui est assez courant dans l'industrie hôtelière), il est important de surveiller le comportement des demandes de nom de domaine précédentes.
C'est facile à oublier, mais il peut s'agir d'une simple vérification semi-régulière consistant à essayer d'explorer leur ancien site à l'aide d'un outil comme OnCrawl, ou même d'un site tiers qui vérifie les codes de statut et les redirections.
Le plus souvent, vous trouverez les redirections 302 du domaine vers la destination finale (301 est toujours un meilleur pari ici) ou 302 vers une version non WWW de l'URL avant de passer par plusieurs autres redirections avant d'atteindre l'URL finale.
John Mueller de Google avait déclaré auparavant qu'ils ne suivaient que 5 redirections avant d'abandonner, alors qu'il est également connu que pour chaque redirection passée, une partie de la valeur du lien est perdue. Pour ces raisons, je préfère m'en tenir à des redirections 301 aussi propres que possible.
Redirect Path by Ayima est une excellente extension de navigateur Chrome qui vous montrera les statuts de redirection lorsque vous naviguez sur le Web.
J'ai également détecté d'anciens noms de domaine appartenant à un client en recherchant sur Google son numéro de téléphone, en utilisant des guillemets exacts ou des parties de son adresse.
Une entreprise comme un hôtel ne change pas souvent d'adresse (au moins une partie de toute façon) et vous pouvez trouver d'anciens annuaires/profils d'entreprise liés à un ancien domaine.
L'utilisation d'un outil de backlink comme Majestic ou Ahrefs peut également afficher d'anciens liens de domaines précédents, c'est donc aussi une bonne escale, surtout si vous n'êtes pas en contact direct avec le client.
10 – Mal gérer le contenu de la recherche interne
C'est en fait un sujet sur lequel j'ai déjà écrit ici chez OnCrawl - mais je l'inclus à nouveau parce que je vois encore très souvent du contenu interne problématique se produire "dans la nature".
J'ai commencé cet article en parlant du problème de la directive robots.txt de Pingdom qui, de mon extérieur, semblait être un correctif pour empêcher le contenu qu'ils produisaient d'être exploré et indexé.
Tout site qui fournit des résultats de recherche internes à Google en tant que contenu, ou qui produit beaucoup de contenu généré par les utilisateurs, doit faire très attention à la manière dont il le fait.
Si un site fournit des résultats de recherche internes à Google de manière très directe, cela peut entraîner une pénalité manuelle quelconque. Google verrait probablement cela comme une mauvaise expérience utilisateur - ils recherchent X, puis atterrissent sur un site où ils doivent ensuite filtrer manuellement ce qu'ils veulent.
Dans certains cas, je pense qu'il peut être bon de diffuser du contenu interne, cela dépend simplement du contexte et des circonstances. Un site d'emploi, par exemple, peut vouloir fournir les derniers résultats d'emploi qui sont mis à jour presque quotidiennement - ils doivent donc presque faire face à cela.
Indeed est un exemple célèbre de site d'emploi qui va peut-être trop loin, générant toutes sortes de contenus basés sur des requêtes de recherche populaires (voir ci-dessous ce qui peut arriver si vous utilisez cette tactique).
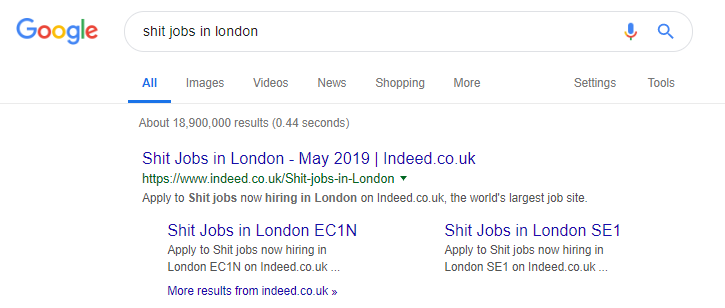
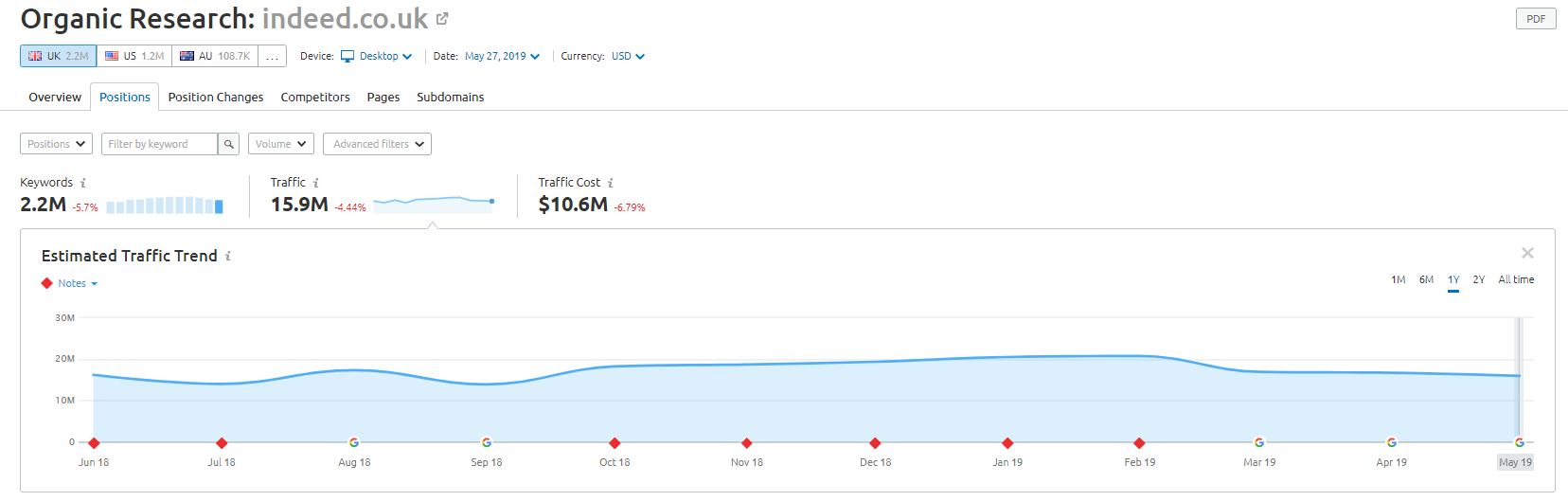
Malgré cela, selon les données de SEMRush, leur trafic organique se porte bien - mais ce sont des lignes fines, et se comporter de la sorte vous expose à un risque élevé de pénalité Google.
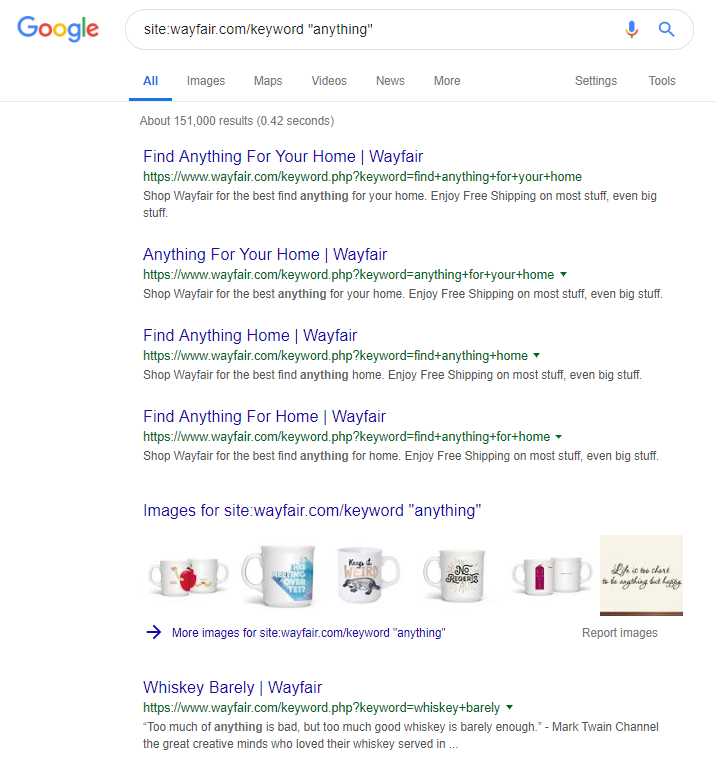
Le détaillant en ligne Wayfair.com est une autre marque qui aime naviguer près du vent. Avec des millions d'URL indexées (et de nombreuses URL de mots clés générés automatiquement), ils s'en sortent très bien en termes de trafic organique, mais ils risquent fort d'être pénalisés pour avoir diffusé du contenu de cette manière aux moteurs de recherche.
En mettant en œuvre une structure de site appropriée qui implique de catégoriser tout le contenu, de créer les différentes hiérarchies parent/enfant, voire d'utiliser des balises ou d'autres taxonomies personnalisées, vous pouvez aider à faciliter la navigation des clients et des robots de recherche.
L'utilisation d'astuces comme celles ci-dessus peut gagner à court terme, mais il est peu probable qu'elle fasse beaucoup pour vous à long terme. Il est donc essentiel d'obtenir une structure de site dès le début, ou au moins de la planifier correctement à l'avance.
Emballer
Les 10 erreurs abordées dans cet article font partie des problèmes techniques les plus courants que je rencontre lors des audits de site.
La correction de ces erreurs sur votre site est une première étape pour vous assurer que votre site est techniquement sain. Une fois ces problèmes corrigés, les audits techniques peuvent se concentrer sur les problèmes spécifiques à votre site.