
Science des données orientée métier
Publié: 2018-12-13Ils disent que Data Scientist est le travail le plus sexy du 21e siècle (et tous les Data Scientists que j'ai rencontrés lors de diverses conférences le savent). Mais quand ils ne parlent que de la partie théorique du machine learning, je me demande parfois s'ils savent pourquoi leur travail est brûlant. La raison en est qu'un Data Scientist sait comment combiner les données, les compétences techniques et les connaissances en statistiques pour atteindre les objectifs commerciaux. Donc, pour bien faire de la science des données, vous devez d'abord penser à l'entreprise.
Je connais des cas dans lesquels des entreprises ont ajouté des outils analytiques pour suivre le toucher de chaque utilisateur sans aucune considération sur ce qu'ils veulent réellement accomplir. Ils ont rassemblé beaucoup de données qu'ils ne comprenaient pas et ne pouvaient pas utiliser pour faire progresser leur entreprise.
Ne faites pas de telles erreurs ! Réfléchissez à vos objectifs et à la spécificité du secteur à chaque étape du processus Data Science. Plus vous êtes créatif, meilleures sont vos chances de succès. Pour le prouver, je vais vous montrer quelques exemples inspirants de Data Science dans les applications des géants…
Comment démarrer votre aventure en science des données
Vous avez entendu dire que de nombreuses entreprises utilisent le ML pour augmenter leurs revenus, mais vous ne savez pas par où commencer ? Pour ne pas vous retrouver avec une infrastructure coûteuse et des données inutiles (pour répondre aux besoins de votre entreprise), vous devriez commencer par fournir des réponses aux questions suivantes :
Quels sont les objectifs commerciaux du client ? Comment pouvons-nous utiliser les données pour les atteindre ?
Ensuite, vous pouvez commencer à planifier quelles données peuvent être suivies et utilisées.
Collecte de données
Quelles données devons-nous collecter ? La réponse à cette question pourrait en fait vous surprendre. Selon Todd Yellin (VP Product Innovation de Netflix), deux types de données peuvent être utilisées : explicites et implicites [1]. Dans le cas de Netflix, l'explicite est lorsque l'utilisateur évalue littéralement un film. Les données comportementales sont implicites, en revanche, basées sur les clics des utilisateurs et l'utilisation de l'application. Quel type est le plus précieux ?
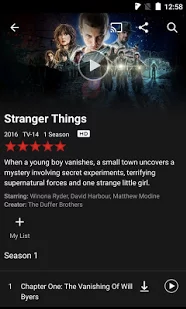
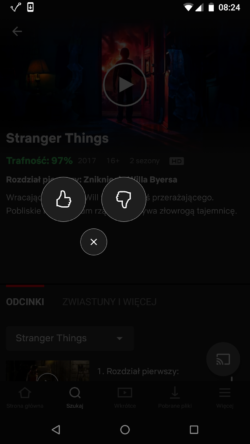
Il n'y a pas de réponse universelle à cette question, mais dans la plupart des cas, les données implicites seraient plus utiles . Et c'est parce que… les gens mentent.
Prenons l'exemple de l'homme qui dit aimer les documentaires et qui les note 5/5. Mais, comme le montrent les données, il regarde ce genre une fois par an. Parallèlement, il regarde chaque vendredi soir des séries populaires. Et c'est parce qu'il est fatigué après le travail et veut juste se détendre sur le canapé. Alors quelles données faut-il utiliser pour élaborer un tel système de recommandation : note ou comportement de l'utilisateur ?
Pour répondre à cette question, nous devons réfléchir à l'objectif commercial de son développement. L'objectif de Netflix est d'encourager un utilisateur à regarder plus de films. Ils ont commencé avec le populaire système de notation cinq étoiles. Lorsqu'ils ont réalisé qu'il était plus probable que les utilisateurs mentionnés verraient Friends au lieu d'un film sur la Seconde Guerre mondiale, ils ont développé le système de recommandation basé sur le comportement des utilisateurs. Ils ont également abandonné la note de cinq étoiles et l'ont remplacée par un système binaire plus simple, pouce vers le haut et pouce vers le bas.
Comme le montre cet exemple, les données recueillies doivent être sélectionnées en tenant compte de la spécificité de l'industrie et doivent apporter suffisamment d'informations pour comprendre les décisions et les besoins des utilisateurs. Mais ici, nous rencontrons un autre problème : les données comportementales, les textes et autres données non structurées sont plus difficiles à analyser et à utiliser dans les modèles d'apprentissage automatique que les modèles structurés. Il est donc temps de parler d'ingénierie des fonctionnalités.
Ingénierie des fonctionnalités
Pour montrer à quel point l'ingénierie des fonctionnalités est importante dans la science des données, je voudrais citer Andrew Ng - co-fondateur de Google Brain et fondateur de deeplearning.ai :
Créer des fonctionnalités est difficile, prend du temps et nécessite des connaissances d'expert. L'apprentissage automatique appliqué est essentiellement de l'ingénierie des fonctionnalités. [2].
https://forum.stanford.edu/events/2011/2011slides/plenary/2011plenaryNg.pdf
Un exemple intéressant d'une approche ciblée du traitement des données est Booking.com, où les utilisateurs peuvent noter les hôtels de 0 à 10. Mais si un fêtard donne une note élevée à l'hôtel, est-ce un bon choix pour les familles avec enfants ? Pas nécessairement.

Heureusement, il existe également des commentaires d'utilisateurs qui contiennent plus d'informations dont nous avons besoin. Booking.com utilise l'analyse des sentiments et la modélisation des sujets pour extraire les forces et les faiblesses de l'hôtel commenté, ainsi que les préférences des utilisateurs concernant l'hébergement.
Considérons cet exemple :
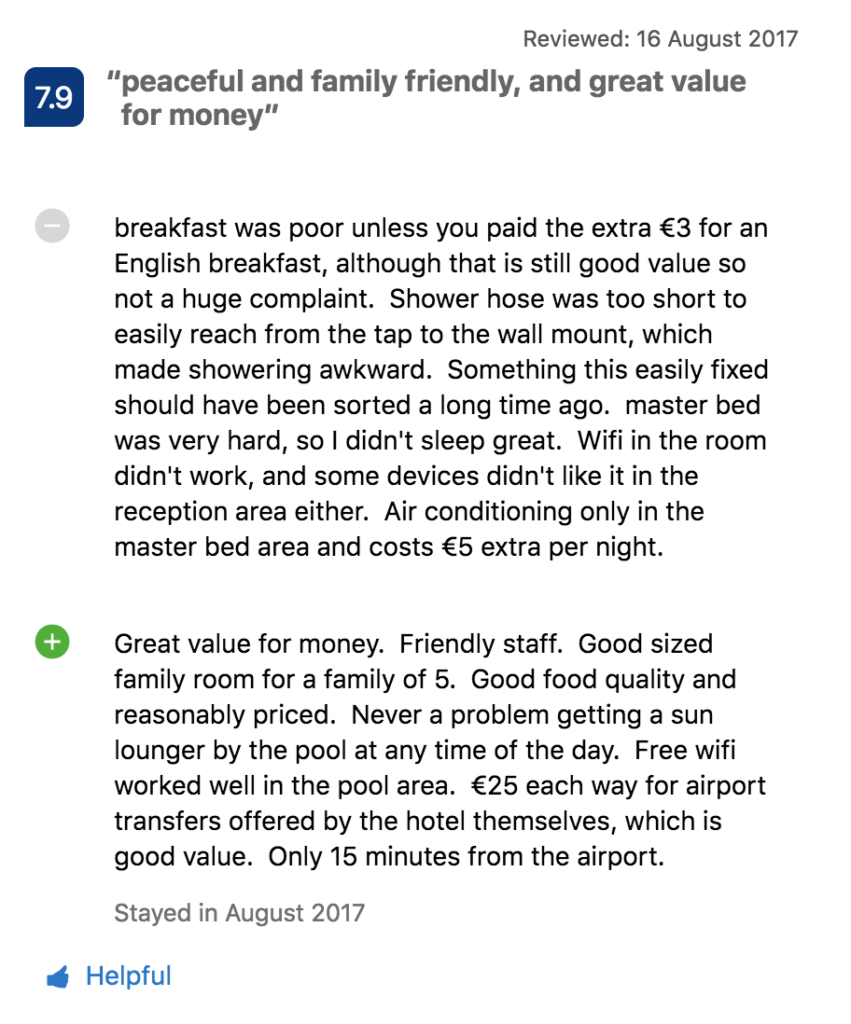
Un sujet sur les équipements de la chambre a un sentiment négatif (l'utilisateur se plaint de la douche, du lit, du wifi et de la climatisation). En même temps, cet utilisateur fait l'éloge de la valeur pour le prix de l'hôtel, du personnel et de la nourriture. Le système analyse également ce qui n'a pas été mentionné dans le commentaire et n'est donc probablement pas important pour l'utilisateur - dans notre exemple, cela peut être la vie nocturne.
Grâce à ces informations, la plateforme peut proposer des hôtels plus adaptés aux utilisateurs ayant un profil similaire, en l'occurrence une famille avec enfants à la recherche d'un endroit pour passer des vacances dans un hôtel paisible à un prix raisonnable. De plus, Booking.com trie les commentaires pour afficher en haut les informations les plus intéressantes pour le spectateur.
Cela conduit à une situation gagnant-gagnant : les utilisateurs peuvent trouver plus rapidement et plus facilement des offres adaptées à leurs besoins spécifiques, et la plate-forme réalise des bénéfices car ces offres sont celles que les utilisateurs sont le plus susceptibles d'acheter.

Curieux de la science des données ?
Apprendre encore plusProduit de données
Vous avez déployé un produit de données avec des résultats satisfaisants ? Ce n'est pas le moment d'être complaisant. Comme le montre l'exemple de Netflix [3] , un travail continu sur l'amélioration du système peut apporter des gains significatifs. Une bonne recommandation de film suffit-elle ? Que pourrions-nous faire de plus ?
L'une des approches prêtes à l'emploi de Netflix consiste non seulement à recommander des films, mais également à les illustrer avec une image qui serait la plus attrayante pour un utilisateur donné. Disons qu'ils vous recommandent Good Will Hunting . Si vous avez regardé beaucoup de comédies romantiques dans le passé, vous verrez peut-être une image d'un couple qui s'embrasse, alors que si vous êtes un fan de comédie, vous obtiendrez très probablement une photo d'un comédien américain populaire :

Avec cette approche, un utilisateur parcourant une myriade de choix est beaucoup plus susceptible de repérer un film qui attire son attention.
Cette stratégie de recommandation et d'autres ont des résultats étonnants - plus de 80% du contenu de la plateforme est basé sur des recommandations algorithmiques . Cela signifie qu'il est difficile pour un utilisateur de manquer de choses à regarder. Lorsqu'une émission est terminée, Netflix est là pour proposer la suivante.
Dans leur entreprise, cela donne un avantage concurrentiel car les utilisateurs sont beaucoup moins susceptibles d'annuler leurs abonnements. Cette application extrêmement réussie de la science des données a été accomplie principalement grâce à la bonne compréhension de leur entreprise et des utilisateurs de l'application.
Le résumé
Lors de l'une des conférences sur la science des données de cette année, un conférencier engagé dans les prévisions du risque de crédit a déclaré :
Quand on me demande en quoi consiste mon métier, je réponds : j'apporte des valeurs business basées sur des données.
Pour moi, c'est l'une des meilleures définitions de la Data Science. Il ne faut pas l'orienter uniquement sur ses fondements théoriques, mais surtout sur le métier. Si vous souhaitez créer une bonne application d'apprentissage automatique, vous devez réfléchir au comportement des utilisateurs dans votre système et à leurs besoins. Dans cet esprit, vous atteindrez vos objectifs commerciaux avec succès.