
Breadcrumb SEO, Python 3 et Oncrawl : en route vers l'automatisation !
Publié: 2021-04-14Apprenons à créer automatiquement une segmentation basée sur le fil d'Ariane avec OnCrawl et Python 3.
Qu'est-ce que la segmentation dans Oncrawl ?
Oncrawl utilise des segmentations pour diviser un ensemble de pages en groupes. Cela facilite l'analyse des données des rapports de crawl, des analyses de logs et d'autres rapports d'analyse croisée qui mélangent les données de crawl avec Google Analytics, Google Search Console, AT Internet, Adobe Analytics ou Majestic pour les backlinks.
Pourquoi est-il important de créer des segmentations ?
Une fois votre crawl terminé, créer une segmentation personnalisée est la chose la plus importante à faire. Cela vous permet de lire les analyses du point de vue qui correspond le mieux à votre site et à sa structure.
Il existe de nombreuses façons de segmenter les pages de votre site, et il n'y a pas de bonne ou de mauvaise façon de le faire. Par exemple, il est possible de suivre la structure de votre site en fonction de la structure des URL.
Par exemple, ce genre d'URL « https://www.mydomain.com/news/canada/politics », pourrait facilement être segmenté comme ceci :
- Un groupe pour isoler la page d'accueil
- Un groupe pour toute l'actualité
- Un sous-groupe pour le répertoire Canada
- Un sous-sous-groupe pour le répertoire Politique
Comme vous pouvez le voir, il est possible de créer jusqu'à 3 niveaux de profondeur pour vos segmentations. Cela vous permet de vous concentrer sur certains groupes ou sous-groupes dans votre analyse SEO, sans avoir à changer de segmentation.
Comment créer une segmentation de base ?
Il faut savoir qu'Oncrawl se charge de créer la première segmentation, tout seul. Celui-ci est basé sur le « Premier chemin » ou le premier répertoire rencontré dans les URL.
Cela vous permet d'avoir une analyse disponible dès que votre crawl est terminé.
Il se peut que cette segmentation ne reflète pas la structure de votre site, ou que vous souhaitiez analyser les choses sous un angle différent.
Vous allez donc créer une nouvelle segmentation en utilisant ce que nous appelons OQL, qui signifie Oncrawl Query Language. C'est un peu comme SQL, mais en beaucoup plus simple et intuitif : 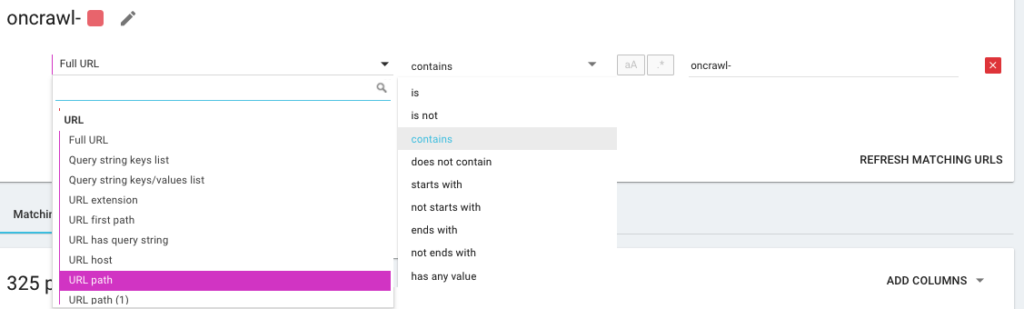
Il est également possible d'utiliser des opérateurs de condition AND/OR pour être le plus précis possible : 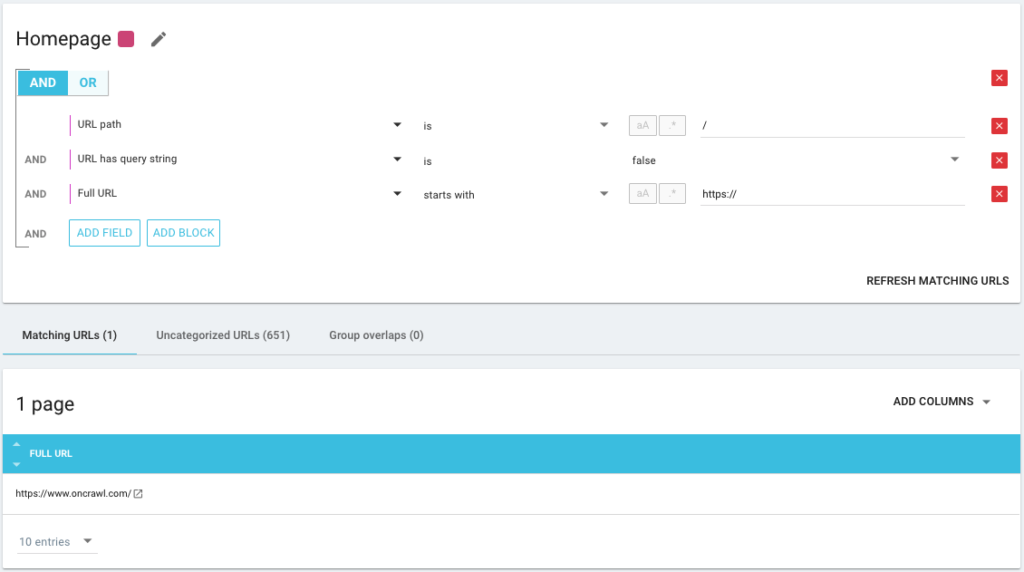
Segmenter mes pages en utilisant différentes méthodes
Utilisation d'autres KPI
Les segmentations basées sur les URL c'est bien, mais ce serait parfait si on pouvait aussi combiner d'autres KPI, comme par exemple regrouper des URL commençant par /car-rental/ et dont le H1 a l'expression « Agences de location de voitures » et un autre groupe où serait le H1 « Les agences de location d'utilitaires », c'est possible ?
Oui c'est possible! Lors de la création de vos segmentations, vous avez à votre disposition tous les KPI que nous utilisons, et pas seulement ceux du crawler, mais aussi ceux des connecteurs. Cela rend la création de segmentations très puissante et permet d'avoir des angles d'analyse totalement différents !
Par exemple, j'adore créer une segmentation en utilisant la position moyenne des URL grâce au connecteur Google Search Console.
De cette façon, je peux facilement identifier les URL profondes de ma structure qui fonctionnent toujours, ou les URL proches de ma page d'accueil qui se trouvent sur la page 2 de Google.
Je peux voir si ces pages ont du contenu dupliqué, une balise de titre vide, si elles reçoivent suffisamment de liens… Je peux aussi voir comment le Googlebot se comporte sur ces pages. La fréquence de crawl est-elle bonne ou mauvaise ? Bref, cela m'aide à prioriser et à prendre des décisions qui auront un réel impact sur mon SEO et mon ROI.
Oncrawl Data³
 Apprendre encore plus
Apprendre encore plusUtilisation de l'ingestion de données
Si vous n'êtes pas familier avec notre fonctionnalité Data Ingest, je vous invite à lire cet article sur le sujet en premier. Il s'agit d'un autre outil très puissant qui vous permet d'ajouter des sources de données externes à Oncrawl.
Par exemple, vous pouvez ajouter des données de SEMrush, Ahrefs, Babbar.tech… L'avantage est que vous pouvez regrouper vos pages selon des métriques tirées de ces outils et effectuer votre analyse en fonction des données qui vous intéressent, même si ce n'est pas le cas. nativement dans Oncrawl.
Récemment, j'ai travaillé avec un groupe hôtelier mondial. Ils utilisent une méthode de scoring interne pour savoir si les fiches hôtel sont correctement remplies, s'ils ont des images, des vidéos, du contenu, etc… Ils déterminent un pourcentage d'achèvement, que nous utilisons pour croiser les données du crawl et du fichier log.
Le résultat nous permet de savoir si Googlebot passe plus de temps sur des pages correctement remplies, de savoir si certaines pages avec un score supérieur à 90% sont trop profondes, ne reçoivent pas assez de liens… Il nous permet de montrer que plus le score, plus les pages reçoivent de visites, plus elles sont explorées par Google et meilleure est leur position dans le SERP de Google. Un argument imparable pour inciter les hôteliers à remplir leur fiche hôtel !
Créer une segmentation basée sur le fil d'Ariane SEO
C'est l'objet de cet article alors rentrons dans le vif du sujet. Il est parfois difficile de segmenter les pages de votre site, si la structure des URL ne rattache pas les pages à un certain répertoire. C'est souvent le cas des sites e-commerce, où les pages produits sont toutes à la racine. Il est donc impossible de savoir à partir de l'URL à quel groupe appartient une page.
Afin de regrouper les pages, nous devons trouver un moyen d'identifier le groupe auquel elles appartiennent. Nous avons donc eu l'idée de récupérer le breadcrumb seo trail de chaque URL et de les catégoriser en fonction des valeurs du breadcrumb seo, grâce à la fonction Scraper proposée par Oncrawl.
Scraper le fil d'Ariane SEO avec Oncrawl
Comme nous l'avons vu plus haut, nous allons mettre en place une règle de scraping pour récupérer le fil d'Ariane. La plupart du temps c'est assez simple car on peut aller récupérer l'information dans une div , puis les champs de chaque niveau sont dans
listes ul et li : 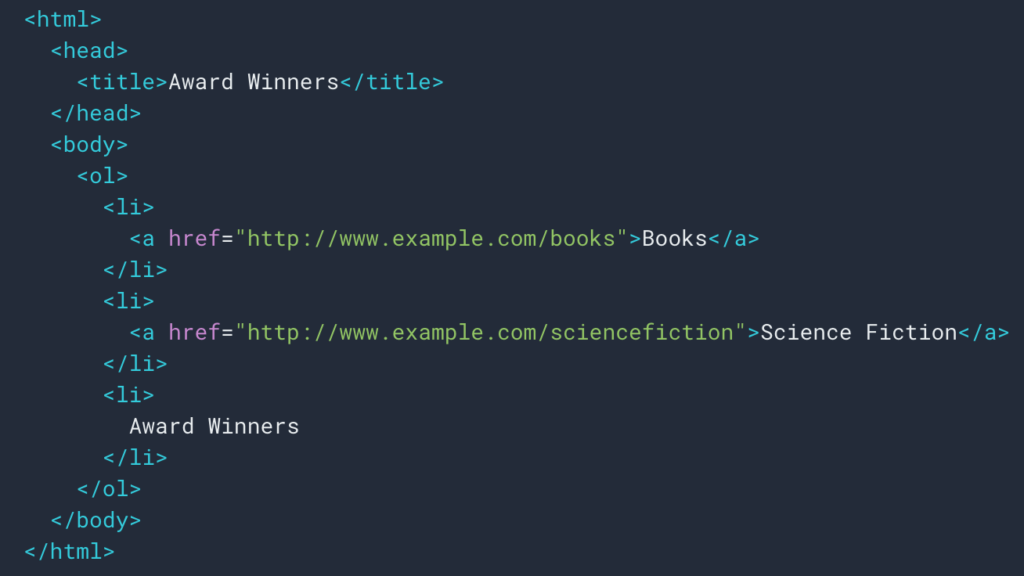
Parfois aussi, nous pouvons facilement récupérer les informations grâce à des données structurées de type Breadcrumb. Ainsi, il sera facile de récupérer la valeur du champ « nom » pour chaque poste. 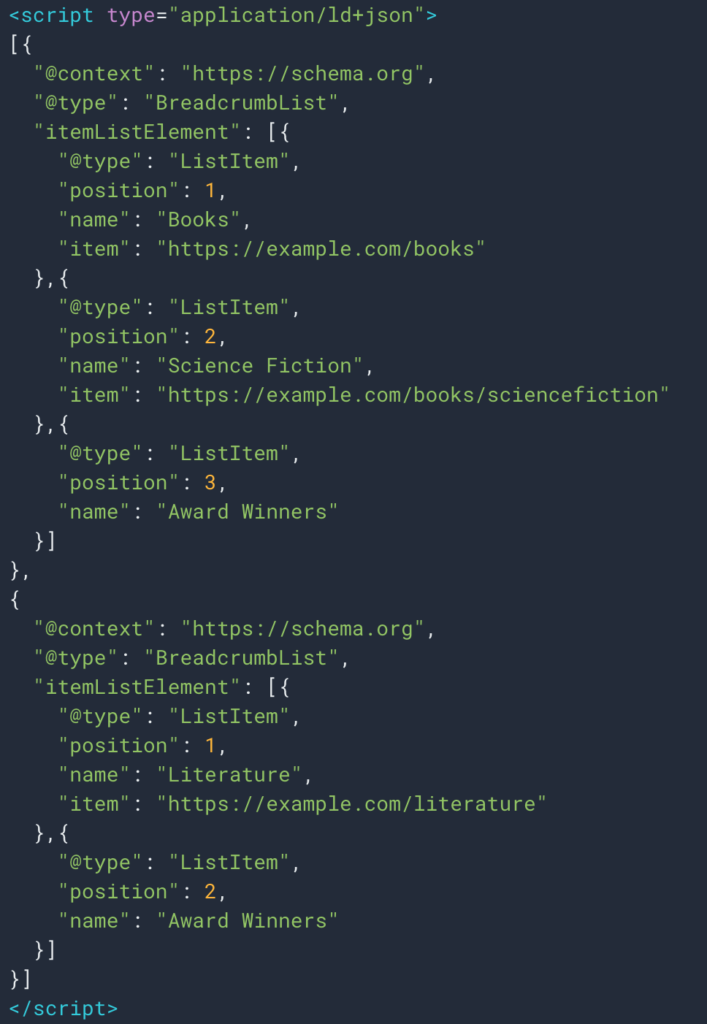
Voici un exemple de règle de grattage que j'utilise : 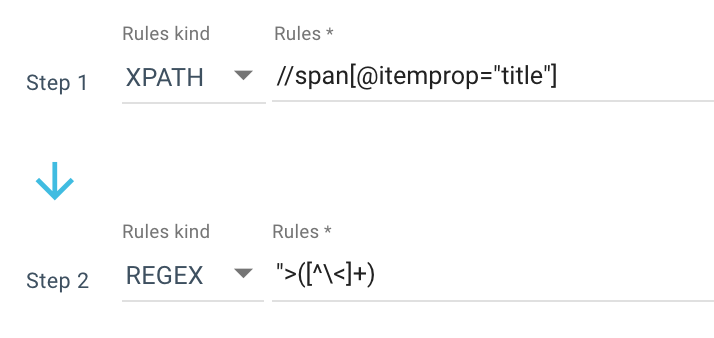
Ou cette règle : //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()

Donc, j'obtiens tout le span itemprop=”title” avec le Xpath, puis j'utilise une expression régulière pour extraire tout après “> qui n'est pas un caractère > . Si vous voulez en savoir plus sur Regex, je vous propose de lire cet article sur le sujet et notre Cheat sheet sur Regex.
J'obtiens plusieurs valeurs comme celle-ci en sortie: 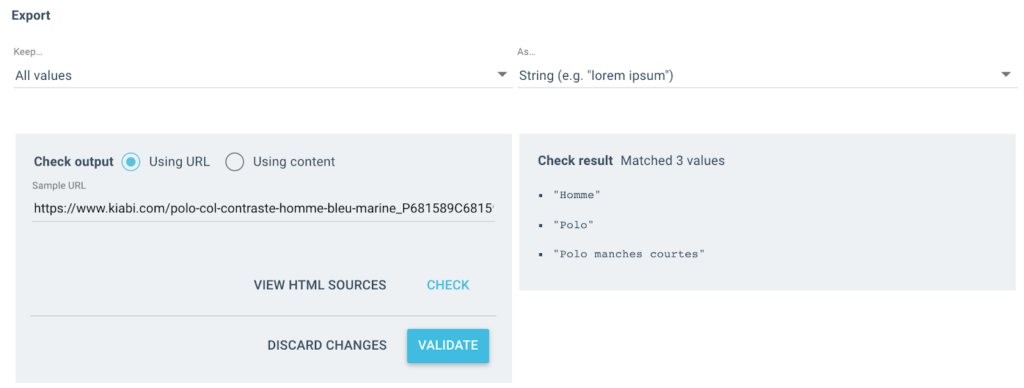
Pour l'URL testée, j'aurai un champ "Breadcrumb" avec 3 valeurs :
- Homme
- chemise polo
- Polo manches courtes
importer json
importer au hasard
demandes d'importation
# Authentification
# Deux façons, avec x-oncrawl-token que vous pouvez obtenir dans les en-têtes de requête du navigateur
# ou avec un jeton api ici : https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# Définissez l'identifiant de crawl où se trouve un champ personnalisé de fil d'Ariane
CRAWL_
# Mettez à jour les éléments de fil d'Ariane interdits que vous ne souhaitez pas obtenir dans la segmentation
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
pour v dans FORBIDDEN_BREADCRUMB_ITEMS.split(',')
]
def random_color() :
nombre_aléatoire = random.randint(0, 16777215)
nombre_hexadécimal = str(hex(nombre_aléatoire))
nombre_hexadécimal = nombre_hexadécimal[2 :].ljust(6, '0')
renvoie f'#{hex_number}'
def value_to_group(value):
revenir {
'couleur' : couleur_aléatoire(),
'nom' : valeur,
'oql' : {'or' : [{'field' : ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(dictionary, level=0):
ret = {
"icon": "tableau de bord",
"transposable": Faux,
"name": "fil d'Ariane"
}Maintenant que la règle est définie, je peux lancer mon crawl et Oncrawl va automatiquement récupérer les valeurs du fil d'Ariane et les associer à chaque URL crawlée.
Automatisez la création de la segmentation multi-niveaux avec Python
Maintenant que j'ai toutes les valeurs du fil d'Ariane SEO pour chaque URL, nous allons utiliser un script python d'automatisation du référencement dans un Google Colab pour créer automatiquement une segmentation compatible avec Oncrawl.
Pour le script lui-même, nous utilisons 3 librairies qui sont :
- json (Pour générer notre segmentation écrite en Json)
- CSV
- aléatoire (pour générer des codes de couleur hexadécimaux pour chaque groupe)
Une fois le script lancé, il se charge automatiquement de créer la segmentation dans votre projet ! 
Prévisualisation des données dans les analyses
Maintenant que notre segmentation est créée, il est possible d'avoir accès aux différentes analyses avec une vue segmentée basée sur mon fil d'Ariane. 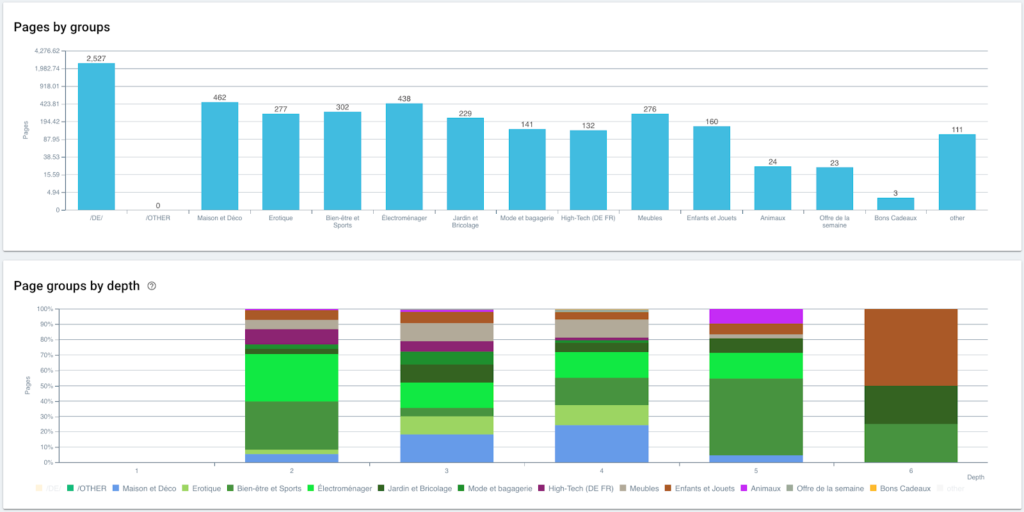
Répartition des pages par groupe et par profondeur
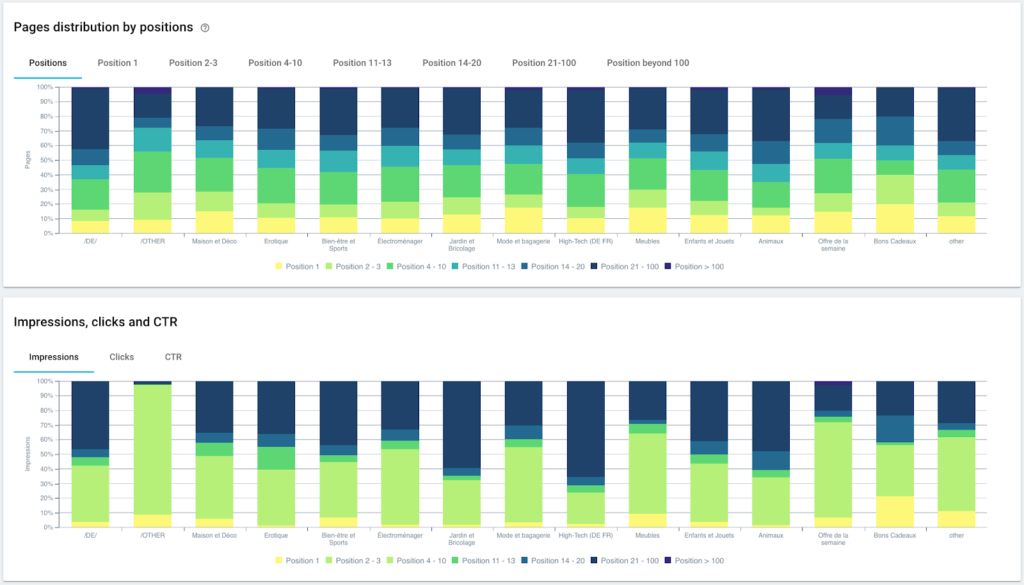
Classement des performances (GSC)
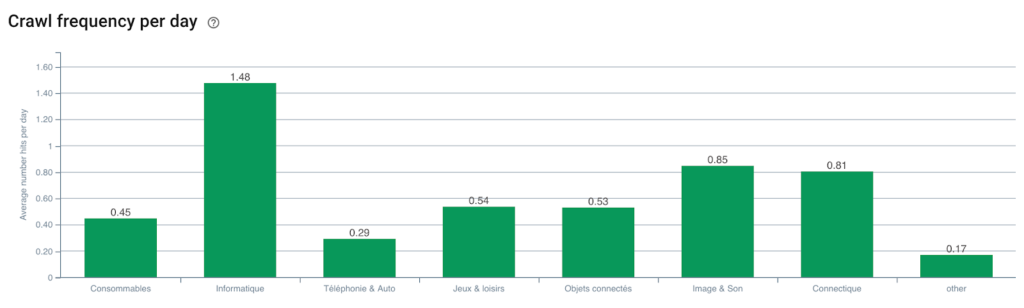
Fréquence d'exploration de Googlebot
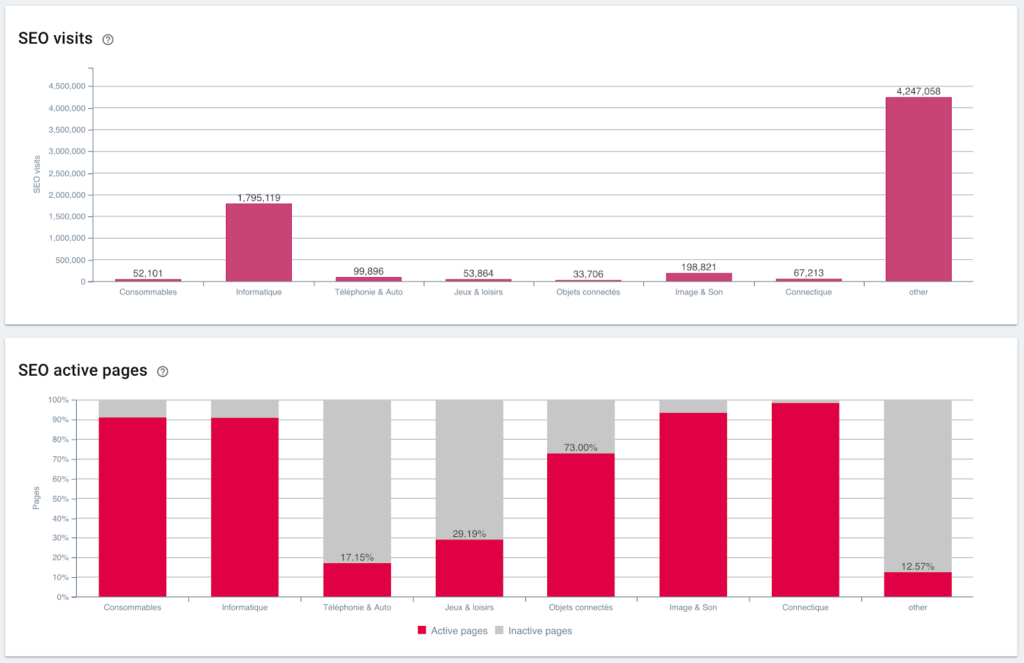
Visites SEO et ratio de pages actives
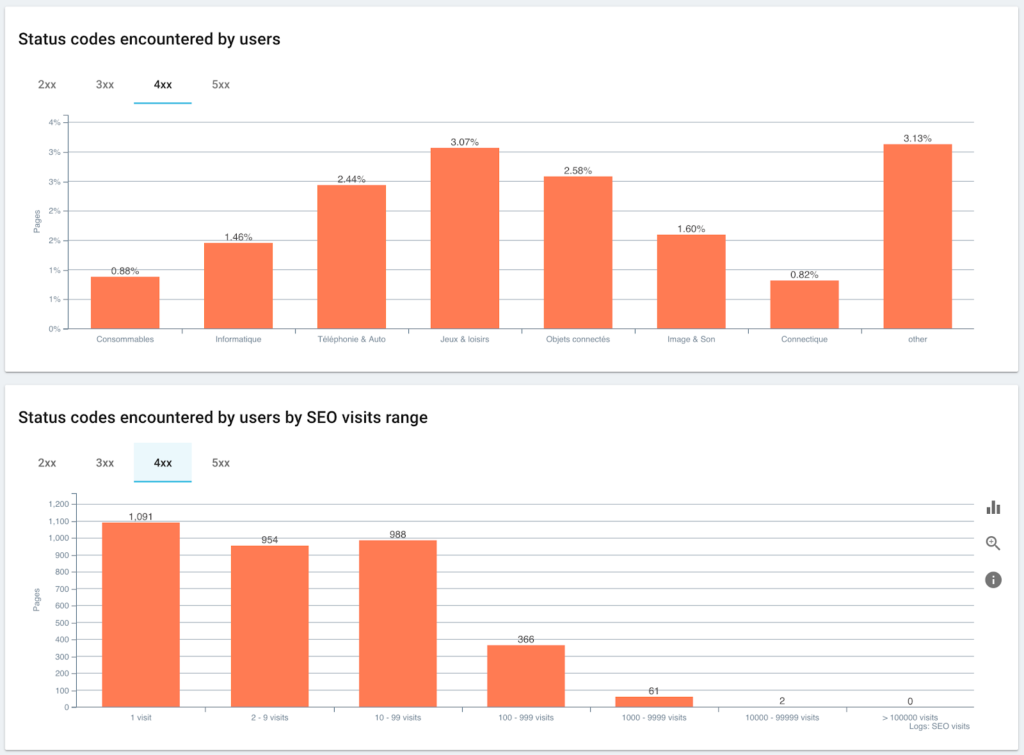
Codes de statut rencontrés par les utilisateurs par rapport aux sessions SEO
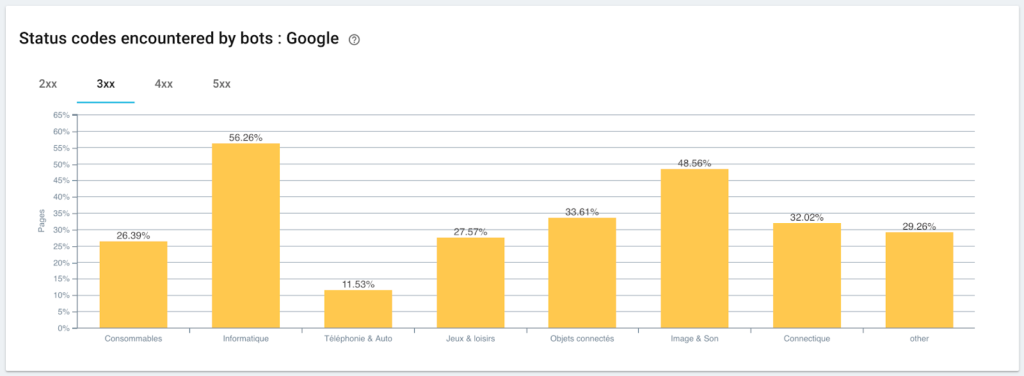
Surveillance des codes d'état rencontrés par Googlebot
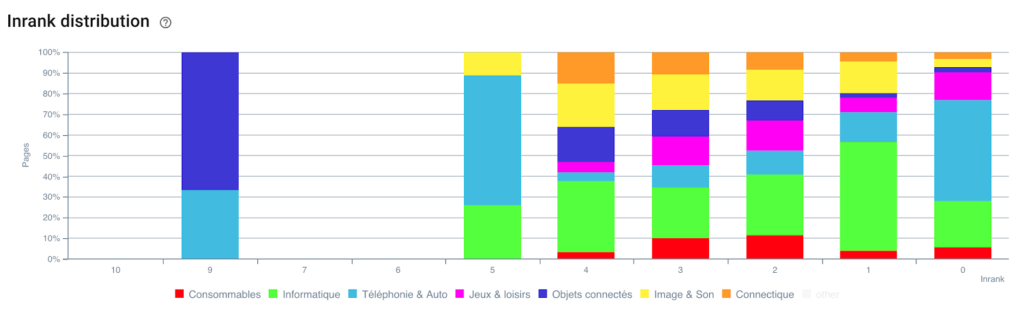
Répartition de l'Inrank
Et voilà, nous venons de créer une segmentation automatiquement grâce à un script utilisant Python et OnCrawl. Toutes les pages sont désormais regroupées selon le fil d'Ariane et ceci sur 3 niveaux de profondeur : 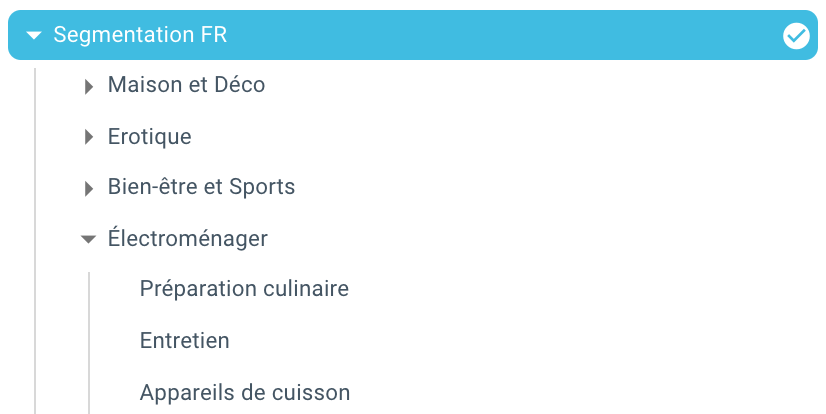
L'avantage est que l'on peut désormais suivre les différents KPI (Crawl, profondeur, liens internes, Crawl budget, sessions SEO, visites SEO, performances Ranking, Load Time) pour chaque groupe et sous-groupe de pages.
L'avenir du SEO avec Oncrawl
Vous pensez probablement que c'est formidable d'avoir cette capacité "prête à l'emploi", mais vous n'avez pas nécessairement le temps de tout faire. La bonne nouvelle est que nous travaillons pour que cette fonctionnalité soit directement intégrée dans un avenir proche.
Cela signifie que vous pourrez bientôt créer automatiquement une segmentation sur n'importe quel champ supprimé ou champ de Data Ingest d'un simple clic. Et cela vous fera gagner beaucoup de temps, tout en vous permettant d'effectuer une incroyable analyse SEO transversale.
Imaginez pouvoir extraire n'importe quelle donnée du code source de vos pages ou intégrer n'importe quel KPI pour chaque URL. La seule limite est votre imagination!
Par exemple, vous pouvez récupérer le prix de vente des produits et voir la profondeur, l'Inrank, les backlinks, le budget de crawl en fonction du prix.
Mais nous pouvons également récupérer les noms des auteurs de vos articles médias et voir qui est le plus performant et appliquer les méthodes d'écriture qui fonctionnent le mieux.
Nous pouvons récupérer les avis et notes de vos produits et voir si les meilleurs produits sont accessibles en un minimum de clics, reçoivent suffisamment de liens, ont des backlinks, sont bien crawlés par Googlebot, etc…
Nous pouvons intégrer vos données commerciales telles que le chiffre d'affaires, la marge, le taux de conversion, vos dépenses Google Ads.
A vous maintenant d'imaginer comment croiser les données pour étoffer votre analyse et prendre les bonnes décisions SEO.
Vous souhaitez tester la segmentation automatique sur le fil d'Ariane ? Contactez-nous via la chatbox directement depuis Oncrawl.
Profitez de votre exploration !