
Extraire automatiquement des concepts et des mots-clés d'un texte (Partie I : Les méthodes traditionnelles)
Publié: 2022-02-22Au sein du service R&D d'Oncrawl, nous cherchons de plus en plus à enrichir le contenu sémantique de vos pages Web. Grâce aux modèles de Machine Learning pour le traitement du langage naturel (NLP), nous pouvons comparer en détail le contenu de vos pages, créer des résumés automatiques, compléter ou corriger les balises de vos articles, optimiser le contenu en fonction de vos données Google Search Console , etc.
Dans un article précédent, nous avons parlé de l'extraction de contenu textuel à partir de pages HTML. Cette fois, nous voudrions parler de l'extraction automatique de mots-clés d'un texte. Ce sujet sera divisé en deux articles :
- le premier abordera le contexte et les méthodes dites "traditionnelles" avec quelques exemples concrets
- le second à venir traitera d'approches plus sémantiques basées sur les transformateurs et les méthodes d'évaluation afin de benchmarker ces différentes méthodes
Le contexte
Au-delà d'un titre ou d'un résumé, quoi de mieux pour identifier le contenu d'un texte, d'un article scientifique ou d'une page web qu'avec quelques mots clés. C'est un moyen simple et très efficace d'identifier le sujet et les concepts d'un texte beaucoup plus long. Cela peut aussi être un bon moyen de catégoriser une série de textes : identifiez-les et regroupez-les par mots-clés. Les sites qui proposent des articles scientifiques tels que PubMed ou arxiv.org peuvent proposer des catégories et des recommandations basées sur ces mots-clés.
Les mots-clés sont également très utiles pour l'indexation de très gros documents et pour la recherche d'informations, un domaine d'expertise bien connu des moteurs de recherche.
Le manque de mots-clés est un problème récurrent dans la catégorisation automatique des articles scientifiques [1] : de nombreux articles n'ont pas de mots-clés assignés. Il faut donc trouver des méthodes pour extraire automatiquement des concepts et des mots clés d'un texte. Afin d'évaluer la pertinence d'un ensemble de mots-clés extraits automatiquement, les jeux de données comparent souvent les mots-clés extraits par un algorithme avec des mots-clés extraits par plusieurs humains.
Comme vous pouvez l'imaginer, il s'agit d'un problème partagé par les moteurs de recherche lors de la catégorisation des pages Web. Une meilleure compréhension des processus automatisés d'extraction de mots-clés permet de mieux comprendre pourquoi une page web se positionne pour tel ou tel mot-clé. Il peut également révéler des lacunes sémantiques qui l'empêchent de bien se classer pour le mot-clé que vous avez ciblé.
Il existe évidemment plusieurs manières d'extraire des mots clés d'un texte ou d'un paragraphe. Dans ce premier post, nous décrirons les approches dites « classiques ».
[Ebook] Data SEO : la prochaine grande aventure
 Lire l'ebook
Lire l'ebookContraintes
Néanmoins, nous avons quelques limitations et prérequis dans le choix d'un algorithme :
- La méthode doit pouvoir extraire des mots clés d'un seul document. Certaines méthodes nécessitent un corpus complet, c'est-à-dire plusieurs centaines voire milliers de documents. Bien que ces méthodes puissent être utilisées par les moteurs de recherche, elles ne seront pas utiles pour un seul document.
- Nous sommes dans un cas de Machine Learning non supervisé. Nous n'avons pas à portée de main un jeu de données en français, anglais ou autres langues avec des données annotées. En d'autres termes, nous n'avons pas des milliers de documents avec des mots-clés déjà extraits.
- La méthode doit être indépendante du domaine/champ lexical du document. Nous voulons pouvoir extraire des mots-clés de tout type de document : articles de presse, pages Web, etc. Notez que certains ensembles de données qui ont déjà des mots-clés extraits pour chaque document sont souvent des domaines spécifiques à la médecine, à l'informatique, etc.
- Certaines méthodes sont basées sur des modèles de POS-tagging, c'est-à-dire la capacité d'un modèle NLP à identifier les mots d'une phrase par leur type grammatical : un verbe, un nom, un déterminant. Déterminer l'importance d'un mot-clé qui est un nom plutôt qu'un déterminant est clairement pertinent. Cependant, selon les langues, les modèles de POS-tagging sont parfois de qualité très inégale.
À propos des méthodes traditionnelles
Nous distinguons les méthodes dites « traditionnelles » des plus récentes qui utilisent des techniques de NLP – Natural Language Processing – telles que les word embeddings et les contextual embeddings. Ce sujet sera traité dans un prochain billet. Mais avant, revenons aux approches classiques, nous en distinguons deux :
- l'approche statistique
- l'approche graphique
L'approche statistique s'appuiera principalement sur les fréquences des mots et leur cooccurrence. On part d'hypothèses simples pour construire des heuristiques et extraire des mots importants : un mot très fréquent, une suite de mots consécutifs qui apparaissent plusieurs fois, etc. Les méthodes basées sur les graphes vont construire un graphe où chaque nœud peut correspondre à un mot, groupe de mots ou phrase. Ensuite, chaque arc peut représenter la probabilité (ou la fréquence) d'observer ces mots ensemble.
Voici quelques méthodes :
- Basé sur les statistiques
- TF-IDF
- RÂTEAU
- YAKE
- Basé sur des graphiques
- TextRank
- TopicRank
- SingleRank
Tous les exemples donnés utilisent le texte tiré de cette page Web : Jazz au Trésor : John Coltrane – Impressions Graz 1962.
Approche statistique
Nous allons vous présenter les deux méthodes Rake et Yake. Dans un contexte SEO, vous avez peut-être entendu parler de la méthode TF-IDF. Mais comme elle nécessite un corpus de documents, nous ne la traiterons pas ici.
RÂTEAU
RAKE signifie Rapid Automatic Keyword Extraction. Il existe plusieurs implémentations de cette méthode en Python, notamment rake-nltk. Le score de chaque mot clé, qui est aussi appelé phrase clé car il contient plusieurs mots, est basé sur deux éléments : la fréquence des mots et la somme de leurs cooccurrences. La constitution de chaque phrase clé est très simple, elle se compose de :
- couper le texte en phrases
- découper chaque phrase en phrases clés
Dans la phrase suivante, nous prendrons tous les groupes de mots séparés par des éléments de ponctuation ou mots vides :
Juste avant, Coltrane dirigeait un quintet, avec Eric Dolphy à ses côtés et Reggie Workman à la contrebasse.
Cela pourrait se traduire par les phrases clés suivantes :
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
A noter que les mots vides sont une suite de mots très fréquents tels que « the », « in », « et » or « it ». Les méthodes classiques étant souvent basées sur le calcul de la fréquence d'occurrence des mots, il est important de bien choisir ses mots vides. La plupart du temps, nous ne voulons pas avoir des mots comme >"to" , "the" or "of" dans nos propositions de phrases clés. En effet, ces mots vides ne sont pas associés à un champ lexical spécifique et sont donc beaucoup moins pertinents que les mots « jazz » ou « saxophone » par exemple.

Une fois que nous avons isolé plusieurs phrases clés candidates, nous leur attribuons une note en fonction de la fréquence des mots et des cooccurrences. Plus le score est élevé, plus les phrases clés sont censées être pertinentes.
Essayons rapidement avec le texte de l'article sur John Coltrane.
# extrait de python pour le râteau de rake_nltk importer Rake # supposons que vous avez déjà l'article dans la variable 'text' râteau = Râteau(stopwords=FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(text) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Voici les 5 premières phrases clés :
"radio publique nationale autrichienne", "pics lyriques plus paradisiaques", "graz a deux particularités", "saxophone ténor john coltrane", "seule version enregistrée"
Il y a quelques inconvénients à cette méthode. Le premier est l'importance du choix des mots vides car ils sont utilisés pour découper une phrase en phrases clés candidates. La seconde est que lorsque les phrases clés sont trop longues, elles auront souvent un score plus élevé en raison de la cooccurrence des mots présents. Pour limiter la longueur des phrases clés, nous avons défini la méthode avec un max_length=4 .
YAKE
YAKE signifie Yet Another Keyword Extractor. Cette méthode est basée sur l'article suivant YAKE! Extraction de mots-clés à partir de documents uniques utilisant plusieurs fonctionnalités locales qui datent de 2020. Il s'agit d'une méthode plus récente que RAKE dont les auteurs ont proposé une implémentation Python disponible sur Github.
Nous nous appuierons, comme pour RAKE, sur la fréquence et la cooccurrence des mots. Les auteurs ajouteront également quelques heuristiques intéressantes :
- on distinguera les mots en minuscules des mots en majuscules (soit la première lettre soit le mot entier). On supposera ici que les mots qui commencent par une majuscule (sauf en début de phrase) sont plus pertinents que les autres : noms de personnes, de villes, de pays, de marques. C'est le même principe pour tous les mots en majuscules.
- le score de chaque phrase clé candidate dépendra de sa position dans le texte. Si les phrases clés candidates apparaissent au début du texte, elles auront un score plus élevé que si elles apparaissent à la fin. Par exemple, les articles de presse mentionnent souvent des concepts importants au début de l'article.
# extrait de python pour yake de yake importer KeywordExtractor en tant que Yake yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(texte)
Comme RAKE, voici les 5 meilleurs résultats :
« Treasure Jazz », « John Coltrane », « Impressions Graz », « Graz », « Coltrane »
Malgré quelques doublons de certains mots dans certaines phrases clés, cette méthode semble assez intéressante.
Approche graphique
Ce type d'approche n'est pas trop éloigné de l'approche statistique dans le sens où l'on va également calculer les cooccurrences de mots. Le suffixe Rank associé à certains noms de méthodes comme TextRank se base sur le principe de l'algo PageRank pour calculer la popularité de chaque page en fonction de ses liens entrants et sortants.
[Ebook] Automatiser le SEO avec Oncrawl
 Lire l'ebook
Lire l'ebookTextRank
Cet algorithme est issu de l'article TextRank : Bringing Order into Texts de 2004 et est basé sur les mêmes principes que l'algorithme PageRank . Cependant, au lieu de construire un graphique avec des pages et des liens, nous allons construire un graphique avec des mots. Chaque mot sera lié à d'autres mots en fonction de leur cooccurrence.
Il existe plusieurs implémentations en Python. Dans cet article, je vais vous présenter pytextrank. Nous allons briser l'une de nos contraintes concernant le POS-tagging. En effet, lors de la construction du graphe, nous n'inclurons pas tous les mots comme nœuds. Seuls les verbes et les noms seront pris en compte. Comme les méthodes précédentes qui utilisent des mots vides pour filtrer les candidats non pertinents, l'algo TextRank utilise le type grammatical des mots.
Voici un exemple d'une partie du graphe qui sera construit par l'algo : 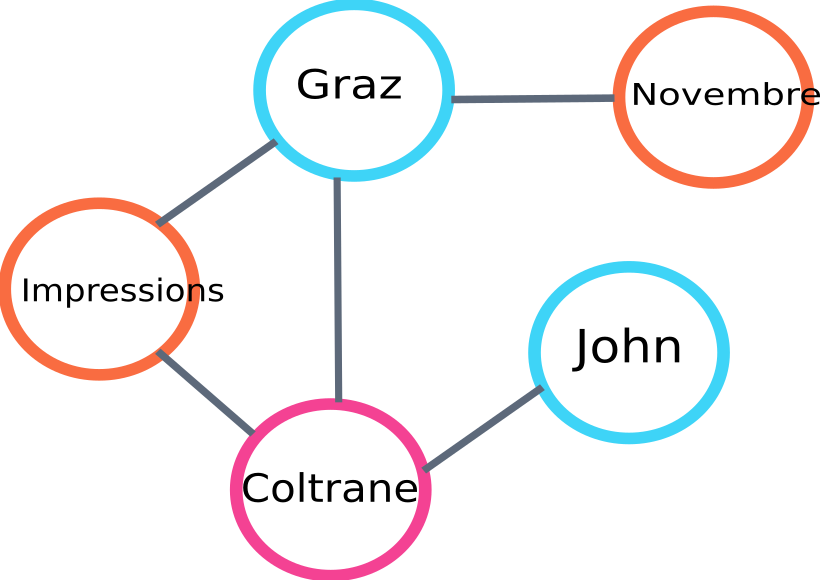
exemple de graphique de classement de texte
Voici un exemple d'utilisation en Python. Notez que cette implémentation utilise le mécanisme de pipeline de la bibliothèque spaCy. C'est cette librairie qui est capable de faire du POS-tagging.
# extrait de code python pour pytextrank
importer de l'espace
importer pytextrank
# charger un modèle français
pnl = spacy.load("fr_core_news_sm")
# ajouter pytextrank au tuyau
nlp.add_pipe("textrank")
doc = pnl(texte)
textrank_keyphrases = doc._.phrases
Voici les 5 meilleurs résultats :
« Copenhague », « novembre », « Impressions Graz », « Graz », « John Coltrane »
En plus d'extraire des phrases clés, TextRank extrait également des phrases. Cela peut être très utile pour faire des « résumés extractifs » – cet aspect ne sera pas abordé dans cet article.
conclusion
Parmi les trois méthodes testées ici, les deux dernières nous semblent tout à fait pertinentes par rapport au sujet du texte. Afin de mieux comparer ces approches, il faudrait évidemment évaluer ces différents modèles sur un plus grand nombre d'exemples. Il existe en effet des métriques pour mesurer la pertinence de ces modèles d'extraction de mots clés.
Les listes de mots-clés produites par ces modèles dits traditionnels constituent une excellente base pour vérifier que vos pages sont bien ciblées. De plus, ils donnent une première approximation de la façon dont un moteur de recherche pourrait comprendre et classer le contenu.
D'autre part, d'autres méthodes utilisant des modèles NLP pré-formés comme BERT peuvent également être utilisées pour extraire des concepts d'un document. Contrairement à l'approche dite classique, ces méthodes permettent généralement une meilleure capture de la sémantique.
Les différentes méthodes d'évaluation, plongements contextuels et transformateurs seront présentés dans un second article à venir sur le sujet !
Voici la liste des mots clés extraits de cet article avec l'une des trois méthodes évoquées :
"méthodes", "mots clés", "phrases clés", "texte", "mots clés extraits", "Traitement du langage naturel"
Références bibliographiques
- [1] Amélioration de l'extraction automatique de mots clés grâce à davantage de connaissances linguistiques, Anette Hulth, 2003
- [2] Extraction automatique de mots-clés à partir de documents individuels, Stuart Rose et. Al, 2010
- [3] YAKE ! Extraction de mots-clés à partir de documents uniques à l'aide de plusieurs fonctionnalités locales, Ricardo Campos et. al, 2020
- [4] TextRank : Mettre de l'ordre dans les textes, Rada Mihalcea et. Al, 2004
Commencez votre essai gratuit de 14 jours
 Commencez votre essai
Commencez votre essai