
Authenticité, Dalle-2 & Midjourney et notre fascination pour les images et l'art générés par l'IA
Publié: 2022-08-04Cet article porte sur la technologie derrière des plates-formes comme Dalle-2 et Midjourney, et pourquoi les créateurs Open AI devraient potentiellement vous payer de l'argent - pas vous facturer…
De plus en plus de personnes sur Internet qualifient Dalle-2 et Open AI d'arnaque. La raison en est que Dalle-2 se transforme soudainement en un service monétisé, où vous devez acheter des crédits, si vous utilisez la plate-forme au-delà de la limite bêta.
DALLE 2 n'est qu'une des nombreuses nouvelles plateformes vous offrant un accès au contenu généré par l'IA et affirmant que vous pouvez l'utiliser à des fins commerciales. Les autres plates-formes incluent Midjourney, Jasper Art, Nightcafe, Starry AI et Craiyon. Nous nous concentrerons sur Dalle 2 dans ce billet de blog, mais ils sont presque identiques, en ce qui concerne les défis et problèmes juridiques.
L'escroquerie est une déclaration assez dure à notre avis, mais il y a un problème évident à utiliser des données que d'autres personnes ont créées (photos, vidéos, annotations, personnes sur les images, etc.) et à commencer ensuite à les revendre aux mêmes personnes.
Ce problème peut être négligé par beaucoup d'entre nous, parce que nous sommes tout simplement fascinés par la nouvelle technologie. Quelque chose qui est tout à fait compréhensible.
Cependant, même si DALL-E 2 n'est en fin de compte qu'une machine de reconnaissance de formes avancée, sa sortie n'est pas neutre et les motifs ne proviennent pas de l'air frais.
Ils sont basés sur des tonnes de données, où il y a de multiples questions juridiques à poser. Des questions importantes pour vous en tant qu'utilisateur potentiel des images que vous générez.
 Image créée par DALLE-2
Image créée par DALLE-2
Les modèles d'IA ne peuvent pas être comparés aux êtres humains
Vous devriez commencer par lire cet article brillant dans Engadget, avant de commencer à envisager d'utiliser les images DALL-E 2 à des fins commerciales.
Dans l'article d'Engadget, ils soulignent une autre chose très importante. À savoir le fait que DALL-E 2 et OpenAI ne renoncent PAS à leur propre droit de commercialiser les images que les utilisateurs créent à l'aide de DALL-E. Cela signifie essentiellement que vous pouvez générer des images qu'ils vendront ensuite commercialement à d'autres.
Cela montre que les intentions sont très différentes de l'analogie parfois utilisée, où les promoteurs de DALLE-2 vont le comparer à un étudiant lisant l'œuvre d'un auteur confirmé. Dans cet exemple, l'étudiant peut apprendre les styles et les modèles de l'auteur et plus tard les trouver applicables dans d'autres contextes et les réutiliser là-bas.
Cependant, il ne s'agit pas d'un cerveau humain utilisant la mémoire créative pour créer de nouvelles œuvres créatives. Il s'agit d'une machine de reconnaissance de formes réutilisant et dans certains cas reproduisant des données d'apprentissage dans des images qui sont ensuite utilisées ou même vendues dans le commerce. C'est simplement deux mondes différents - à la fois métaphoriquement et littéralement parlant.
 Vraie photo du monde réel
Vraie photo du monde réel
La promesse d'authenticité de JumpStory
Cet article est destiné aux personnes qui souhaitent comprendre plus en profondeur le fonctionnement de cette nouvelle technologie de génération d'images AI. Mais avant de commencer, quelques mots sur les raisons pour lesquelles JumpStory ne construit pas actuellement une machine similaire.
Bien sûr, cette question nous a été posée à plusieurs reprises. D'autant plus que nous utilisons déjà l'IA dans notre entreprise et que nous avons accès à des millions d'images authentiques.
Cependant, ce n'est pas une discussion technologique pour nous, mais une discussion éthique. Une discussion qui a abouti à notre Promesse d'Authenticité.
Nous sommes fondamentalement contre un avenir, où les images générées par l'IA deviennent la norme plutôt que l'exception. Appelez-nous démodés, mais nous pensons que le VRAI monde est beau.
Nous sommes fiers que nos photos et vidéos représentent de vrais êtres humains sous différentes formes et tailles. Nous ne sommes pas contre l'utilisation de l'IA, mais nous ne pensons pas qu'elle devrait être utilisée pour générer de fausses personnes ou de fausses réalités.
Des technologies telles que les médias synthétiques et DALL-E 2 peuvent être fascinantes en surface, mais elles présentent également un risque réel. Ils risquent de brouiller les frontières entre le vrai et le faux, ce qui constituera une menace fondamentale pour la confiance entre les êtres humains.

C'est pourquoi JumpStory n'utilise pas l'intelligence artificielle pour générer de fausses images, mais utilise plutôt l'IA pour identifier quelles images sont originales, authentiques et - bien sûr - légales à utiliser à des fins commerciales.
Ce sont les images que vous trouvez en utilisant notre service, et nous avons nommé notre approche "Authentic Intelligence".
Comprendre comment les images IA sont générées
Assez parlé de JumpStory et des problèmes juridiques avec DALL-E 2 pour le moment. Regardons comment les images AI sont générées sur des plateformes comme DALLE-2, Imagen, Crayion (anciennement Dall-E Mini), Midjourney etc. … En utilisant DALLE-2 comme exemple le plus médiatisé actuellement.
Pour commencer, DALLE-2 peut effectuer différents types de tâches, mais nous nous concentrerons sur la tâche de génération d'images dans ce blog.
Comment cela fonctionne est qu'une invite de texte est entrée dans un encodeur de texte. Cet encodeur est formé pour mapper l'invite à un espace de représentation. Ensuite, un soi-disant modèle antérieur mappe le texte codé à un codage d'image correspondant qui capture les informations sémantiques de l'invite de codage de texte.
(Si cela devient déjà un peu geek, je suis vraiment désolé, mais ça va encore empirer )
La dernière étape pour l'encodeur d'image consiste à générer une image qui visualise les informations sémantiques que l'encodeur a reçues. C'est la base des machines comme Open AI.
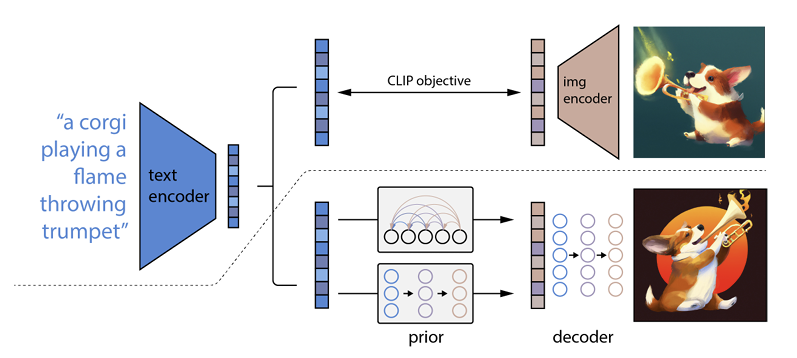
La relation entre le texte et les visuels
DALL-E 2 et les technologies similaires sont souvent appelées générateurs de texte en image. La raison en est leur capacité à recevoir une entrée de texte et à fournir une sortie d'image.
Pour vous donner un exemple, c'est "Un astronaute à cheval dans le style d'Andy Warhol :

source: DALLE-2
Ce qui se passe ici est basé sur le modèle d'Open AI nommé CLIP. CLIP est l'abréviation de "Contrastive Language-Image Pre-training" et est un modèle très complexe formé sur des millions d'images et de légendes.
CLIP est particulièrement doué pour comprendre à quel point un texte particulier se rapporte à une image particulière. La clé ici n'est pas la légende, mais la relation entre une certaine légende et une certaine image.
Ce type de technologie est nommé «contrastif», et ce que CLIP est capable de faire, c'est d'apprendre la sémantique à partir du langage naturel. La façon dont CLIP a appris cela est à travers un processus, où l'objectif est de (citant maintenant la documentation technologique) : "maximiser simultanément la similarité cosinus entre N paires image/légende encodées correctes et minimiser la similarité cosinus entre N 2 - N image encodée incorrecte /paires de sous-titres. »
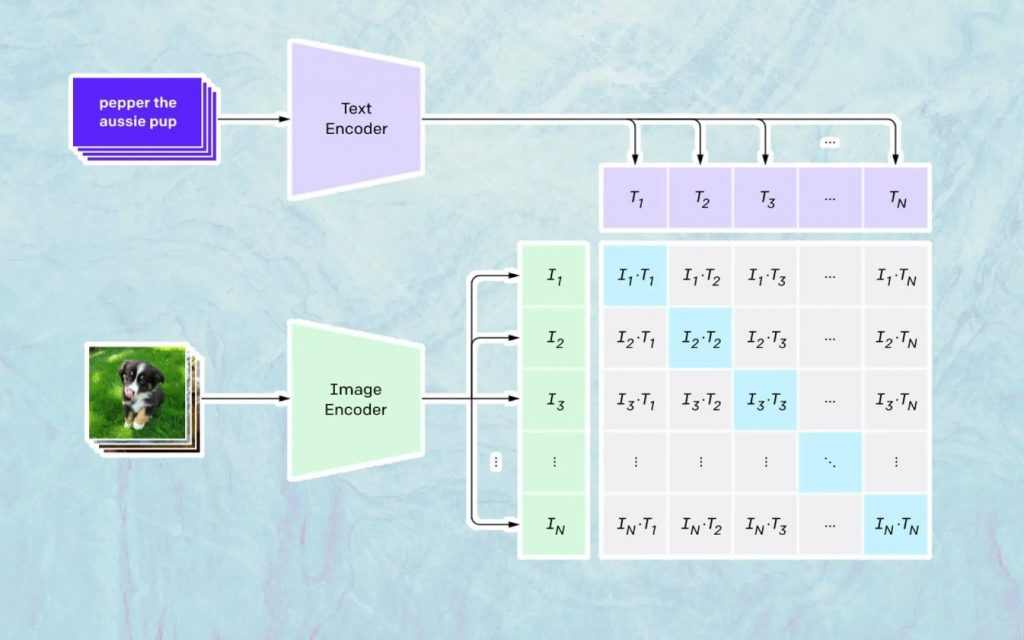
Génération des images
Comme décrit ci-dessus, le modèle CLIP apprend un espace de représentation dans lequel il peut déterminer comment les encodages des images et des textes sont liés.
La tâche suivante consiste à utiliser cet espace pour générer des images. À cette fin, Open AI a développé un autre modèle nommé GLIDE, qui est capable d'utiliser l'entrée de CLIP et - en utilisant un modèle de diffusion - d'effectuer la génération d'image.
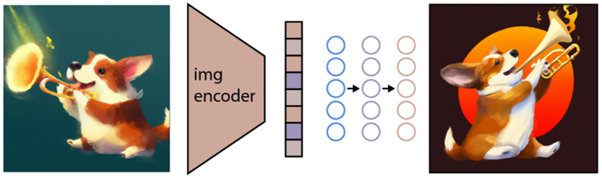
Pour expliquer brièvement ce qu'est un modèle de diffusion, il s'agit essentiellement d'un modèle qui apprend à générer des données en inversant un processus de bruit graduel. Désolé pour cela qui devient maintenant très technique, alors pour citer une description trouvée dans la documentation d'Open AI :
"Le processus de bruit est considéré comme une chaîne de Markov paramétrée qui ajoute progressivement du bruit à une image pour la corrompre, aboutissant finalement (asymptotiquement) à un bruit gaussien pur. Le modèle de diffusion apprend à naviguer en arrière le long de cette chaîne, supprimant progressivement le bruit sur une série de pas de temps pour inverser ce processus.

Si vous voulez aller encore plus loin dans la technologie, nous vous recommandons de lire cet excellent article de Ryan O'Connor.