
Comment répondre à des questions de données complexes avec les données d'Oncrawl, en dehors d'Oncrawl
Publié: 2022-01-04L'un des avantages d'Oncrawl pour le référencement d'entreprise est d'avoir un accès complet à vos données brutes. Que vous connectiez vos données de référencement à un flux de travail de BI ou de science des données, que vous effectuiez vos propres analyses ou que vous travailliez dans le respect des directives de sécurité des données de votre organisation, les données brutes de référencement et d'audit de site Web peuvent servir à de nombreuses fins.
Aujourd'hui, nous allons voir comment utiliser les données d'Oncrawl pour répondre à des questions complexes sur les données.
Qu'est-ce qu'une question complexe sur les données ?
Les questions complexes sur les données sont des questions auxquelles il est impossible de répondre par une simple recherche dans la base de données, mais qui nécessitent un traitement des données afin d'obtenir la réponse.
Voici quelques exemples courants de questions de données « complexes » que les référenceurs se posent souvent :
- Créer une liste de tous les liens pointant vers des pages qui redirigent vers d'autres pages avec un statut 404
- Création d'une liste de tous les liens et de leur texte d'ancrage pointant vers des pages dans une segmentation basée sur des métriques non URL
Comment répondre à des questions complexes sur les données dans Oncrawl
La structure de données d'Oncrawl est conçue pour permettre à presque tous les sites de rechercher des données en temps quasi réel. Cela implique de stocker différents types de données dans différents ensembles de données afin de garantir que les temps de recherche sont réduits au minimum dans l'interface. Par exemple, nous stockons toutes les données associées aux URL dans un jeu de données : code de réponse, nombre de liens sortants, type de données structurées présentes, nombre de mots, nombre de visites organiques… Et nous stockons toutes les données liées aux liens dans un jeu de données séparé : cible du lien, origine du lien, texte d'ancrage…
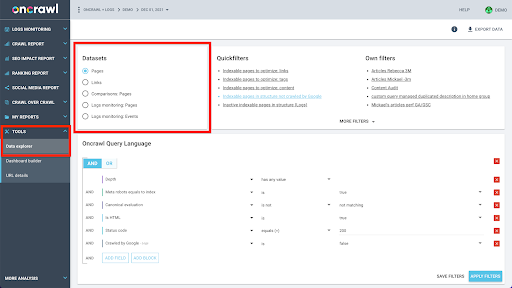
Rejoindre ces ensembles de données est complexe en termes de calcul et n'est pas toujours pris en charge dans l'interface de l'application Oncrawl. Lorsque vous souhaitez rechercher quelque chose qui nécessite de filtrer un ensemble de données afin de rechercher quelque chose dans un autre, nous vous recommandons de manipuler vous-même les données brutes.
Étant donné que toutes les données d'Oncrawl sont à votre disposition, il existe de nombreuses façons de joindre des ensembles de données et d'exprimer des requêtes complexes.
Dans cet article, nous examinerons l'un d'entre eux, à l'aide de Google Cloud et de BigQuery, qui convient aux très grands ensembles de données comme beaucoup de nos clients rencontrent lors de l'examen des données pour les sites avec de gros volumes de pages.
Ce dont vous aurez besoin
Pour suivre la méthode dont nous parlerons dans cet article, vous aurez besoin d'accéder aux outils suivants :
- Exploration
- L'API d'Oncrawl avec le Big Data Export
- Stockage en nuage Google
- BigQuery
- Un script Python pour transférer des données d'Oncrawl vers BigQuery (nous le développerons au cours de l'article.)
Avant de commencer, vous devez avoir accès à un rapport de crawl complet dans Oncrawl.
Comment exploiter les données Oncrawl dans Google BigQuery
Le plan de l'article d'aujourd'hui est le suivant :
- Tout d'abord, nous nous assurerons que Google Cloud Storage est configuré pour recevoir des données d'Oncrawl.
- Ensuite, nous allons utiliser un script Python pour exécuter les exports Big Data d'Oncrawl afin d'exporter les données d'un crawl donné vers un bucket Google Cloud Storage. Nous allons exporter deux ensembles de données : les pages et les liens.
- Lorsque cela sera fait, nous créerons un ensemble de données dans Google BigQuery. Nous allons ensuite créer une table à partir de chacune des deux exportations dans l'ensemble de données BigQuery.
- Enfin, nous expérimenterons l'interrogation des ensembles de données individuels, puis les deux ensembles de données ensemble pour trouver la réponse à une question complexe.
Configuration dans Google Cloud pour recevoir les données d'Oncrawl
Pour exécuter ce guide dans un environnement sandbox dédié, nous vous recommandons de créer un nouveau projet Google Cloud pour l'isoler de vos projets en cours existants.
Commençons par la maison de Google Cloud.
Depuis votre page d'accueil Google Cloud, vous avez accès à de nombreuses choses en plus du Cloud Storage. Nous sommes intéressés par les buckets Cloud Storage, qui sont disponibles dans le niveau de stockage cloud de Google Cloud Platform : 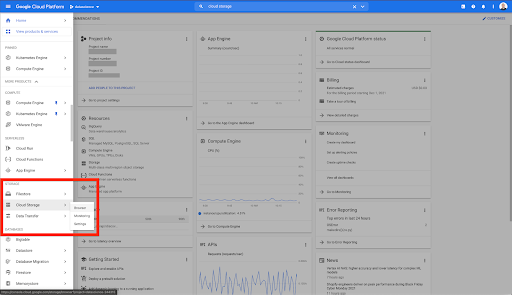
Vous pouvez également accéder directement au navigateur Cloud Storage à l'adresse https://console.cloud.google.com/storage/browser.
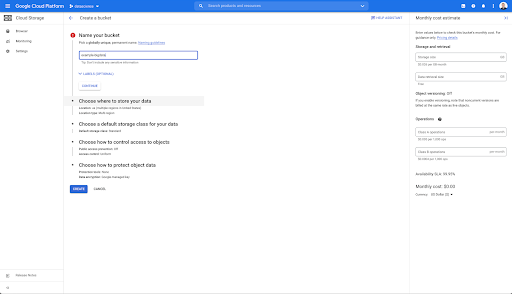
Vous devez ensuite créer un bucket Cloud Storage et accorder les autorisations appropriées afin que le compte de service d'Oncrawl soit autorisé à y écrire, sous le préfixe de votre choix.
Le bucket Google Cloud Storage servira de stockage temporaire pour stocker les exportations Big Data d'Oncrawl avant de les charger dans Google BigQuery.
Dans ce bucket, j'ai également créé deux dossiers : "links" et "pages" : 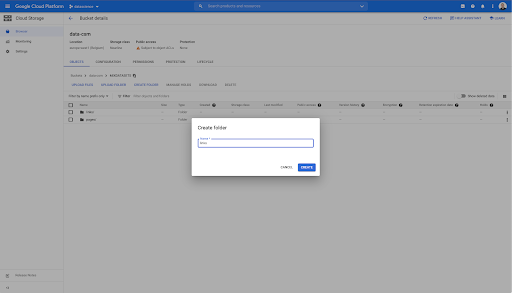
Exporter des ensembles de données depuis Oncrawl
Maintenant que nous avons configuré l'espace où nous voulons enregistrer les données, nous devons les exporter depuis Oncrawl. Exporter vers un bucket Google Cloud Storage avec Oncrawl est particulièrement simple, puisque nous pouvons exporter les données au bon format, et les enregistrer directement dans le bucket. Cela élimine toute étape supplémentaire.
Création d'une clé API
L'exportation de données depuis Oncrawl au format Parquet pour BigQuery nécessitera l'utilisation d'une clé API pour agir sur l'API par programmation, au nom du propriétaire du compte Oncrawl. L'application Oncrawl permet aux utilisateurs de créer des clés API nommées afin que votre compte soit toujours bien organisé et propre. Les clés API sont également associées à différentes autorisations (étendues) afin que vous puissiez gérer les clés et leurs objectifs.
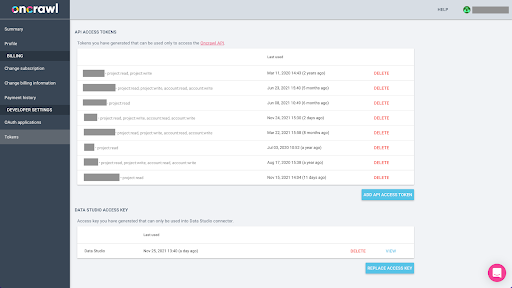
Nommons notre nouvelle clé 'Knowledge session key'. La fonctionnalité d'exportation Big Data nécessite des autorisations d'écriture dans le compte, car nous créons les exportations de données. Pour ce faire, nous devons avoir un accès en lecture sur le projet et un accès en lecture et en écriture sur le compte.
Nous avons maintenant une nouvelle clé API, que je vais copier dans mon presse-papiers.
Notez que, pour des raisons de sécurité, vous n'avez la possibilité de copier la clé qu'une seule fois . Si vous oubliez de copier la clé, vous devrez supprimer la clé et en créer une nouvelle.
Création de votre script Python
J'ai construit un bloc-notes Google Colab pour cela, mais je partagerai le code ci-dessous afin que vous puissiez créer vos propres outils ou votre propre bloc-notes.
1. Stockez votre clé API dans une variable globale
Tout d'abord, nous amorçons l'environnement et nous déclarons la clé API dans une variable globale nommée "Oncrawl Token". Ensuite, nous nous préparons pour le reste de l'expérience :
#@title Accéder à l'API Oncrawl
#@markdown Fournissez votre jeton API ci-dessous pour permettre à ce notebook d'accéder à vos données Oncrawl :
# VOTRE JETON POUR L'API ONCRAWL
ONCRAWL_TOKEN = "" #@param {type :"chaîne"}
!pip installer la prison
depuis IPython.display importer clear_output
clear_output()
print('Tous chargés.') 
2. Créez une liste déroulante pour choisir le projet Oncrawl avec lequel vous souhaitez travailler
Ensuite, en utilisant cette clé, nous voulons pouvoir choisir le projet avec lequel nous voulons jouer en obtenant la liste des projets et en créant un widget déroulant à partir de cette liste. En exécutant le deuxième bloc de code, effectuez les étapes suivantes :
- Nous appellerons l'API Oncrawl pour obtenir la liste des projets sur le compte en utilisant la clé API qui vient d'être soumise.
- Une fois que nous avons la liste du projet à partir de la réponse de l'API, nous la formatons comme une liste en utilisant le nom du projet ainsi que l'URL de démarrage du projet.
- Nous stockons l'ID du projet qui a été fourni dans la réponse.
- Nous construisons un menu déroulant et l'affichons sous le bloc de code.
#@title Sélectionnez le site web à analyser en choisissant le projet Oncrawl correspondant
demandes d'importation
prison d'importation
importer des ipywidgets en tant que widgets
importer json
# Obtenir la liste des projets
réponse = demandes.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
limite=1000,
sort='nom:asc'
),
headers={ 'Autorisation' : 'Porteur '+ONCRAWL_TOKEN }
)
json_res = réponse.json()
Liste déroulante #prepare pour permettre à l'utilisateur de sélectionner un projet
projets = []
pour l'élément dans json_res['projects'] :
projets.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
sortie = widgets. Sortie ()
dropdown_purpose = widgets.Dropdown(options = projets, description="Projet :")
def dropdown_project_eventhandler(change):
sortie.clear_output()
avec sortie :
afficher (projets)
dropdown_purpose.observe(dropdown_project_eventhandler, names='value')
afficher (dropdown_purpose) Dans le menu déroulant créé, vous pouvez voir la liste complète des projets auxquels la clé API a accès. 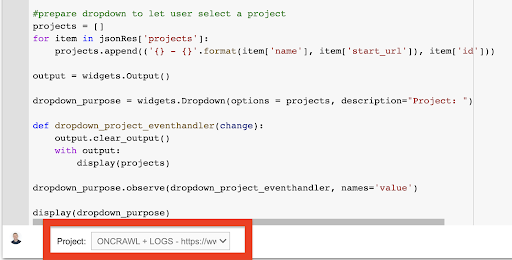
Pour les besoins de la démonstration d'aujourd'hui, nous utilisons un projet de démonstration basé sur le site Web Oncrawl.
3. Créez une liste déroulante pour choisir le profil d'analyse dans le projet avec lequel vous souhaitez travailler
Ensuite, nous déciderons quel profil de crawl utiliser. Nous voulons choisir un profil de crawl dans ce projet. Le projet de démonstration comporte de nombreuses configurations de crawl différentes : 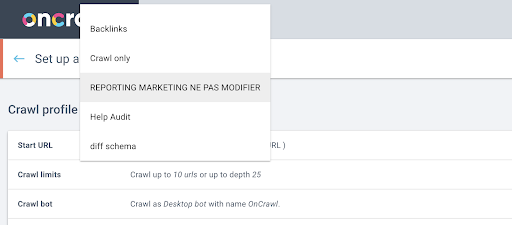
Dans ce cas, on regarde un projet que les équipes Oncrawl utilisent souvent pour des expérimentations, je vais donc choisir le profil de crawl utilisé par l'équipe marketing pour suivre les performances du site Oncrawl. Comme il s'agit du profil d'exploration le plus stable, c'est un bon choix pour l'expérience d'aujourd'hui.
Pour obtenir le profil de crawl, nous allons utiliser l'API Oncrawl, pour demander le dernier crawl dans chaque profil de crawl du projet :
- Nous nous préparons à interroger l'API Oncrawl pour le projet donné.
- Nous demanderons tous les crawls renvoyés par ordre décroissant selon leur date de « création à ».
demandes d'importation
importer json
importer des ipywidgets en tant que widgets
project_id = dropdown_purpose.value
# Obtenir les détails des projets (inclure tous les crawls dans le projet)
projet = demandes.get("https://app.oncrawl.com/api/v2/projects/{}".format(id_projet),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Autorisation' : 'Porteur '+ONCRAWL_TOKEN }).json()
# Regrouper les crawls par profil de crawl (nom du crawl)
crawls_by_config = {}
essayer:
pour explorer dans le projet['crawls'] :
si crawl['status'] dans ["done"] :
si crawl['crawl_config']['name'] pas dans crawls_by_config.keys() :
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
si len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0 :
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
if crawl['status'] == "archivé":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = Vrai
sauf exception comme e :
lever Exception("erreur {} , {}".format(e, projet))
# Construire la liste pour la sélection déroulante
liste = [("{} ({})".format(k, len(v['crawl_ids'])), k) pour k, v dans crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="Crawl configs : ")
def dropdown_cc_eventhandler(change):
sortie.clear_output()
avec sortie :
afficher (crawls_by_config)
si len(crawls_by_config.values()) == 0 :
print('Aucun live crawl trouvé dans ce projet')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='value')
afficher (dropdown_crawl_configs)Lorsque ce code sera exécuté, l'API Oncrawl nous répondra avec la liste des crawls en décroissant la propriété "created at".
Ensuite, puisque nous ne voulons nous concentrer que sur les crawls qui sont terminés, nous allons parcourir la liste des crawls. Pour chaque crawl avec un statut "terminé", nous enregistrerons le nom du profil de crawl et nous stockerons l'ID de crawl.
Nous conserverons au maximum un profil de crawl par crawl afin de ne pas exposer trop de crawls.
Le résultat est ce nouveau menu déroulant créé à partir de la liste des profils de crawl du projet. Nous choisirons celui que nous voulons. Cela prendra la dernière analyse effectuée par l'équipe marketing : 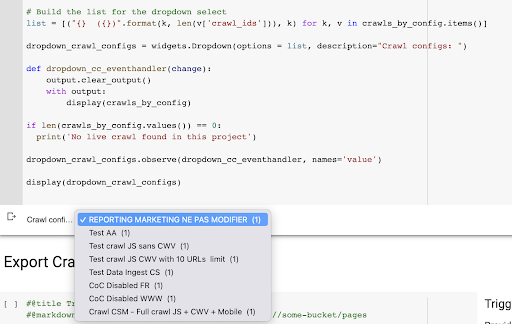
4. Identifiez le dernier crawl avec le profil que nous voulons utiliser
Nous avons déjà l'ID de crawl associé au dernier crawl dans le profil choisi. Il est caché dans le dictionnaire d'objets "crawl_by_config". 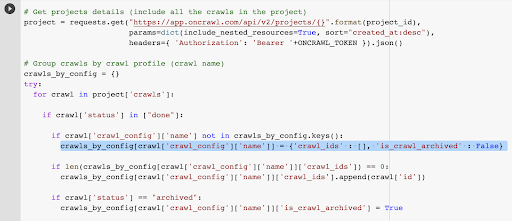
Vous pouvez le vérifier facilement dans l'interface : Trouvez le dernier crawl terminé dans cette analyse de profil. 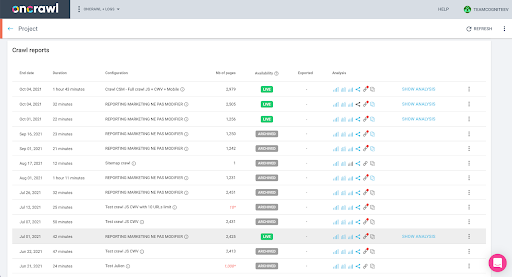
Si nous cliquons pour voir l'analyse, nous verrons que l'ID de crawl se termine par E617. 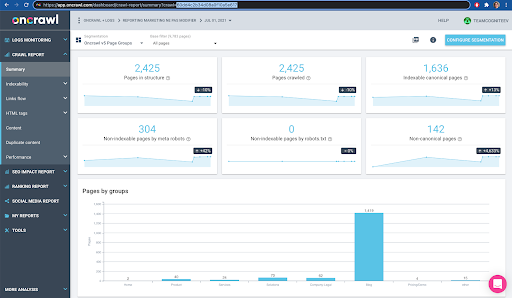
Prenons simplement note de l'ID de crawl pour les besoins de la démonstration d'aujourd'hui.
Bien sûr, si vous savez déjà ce que vous faites, vous pouvez sauter les étapes que nous venons de parcourir pour appeler l'API Oncrawl afin d'obtenir la liste des projets et la liste des crawls par profil de crawl : vous avez déjà le crawl ID du interface, et cet ID est tout ce dont vous avez besoin pour exécuter l'exportation.
Les étapes que nous avons parcourues jusqu'à présent visent simplement à faciliter le processus d'obtention du dernier crawl du profil de crawl donné du projet donné, compte tenu de ce à quoi la clé API a accès. Cela peut être utile si vous fournissez cette solution à d'autres utilisateurs ou si vous cherchez à l'automatiser.
5. Exporter les résultats du crawl
Maintenant, nous allons regarder la commande export :
#@title Déclencher l'exportation de données volumineuses
#@markdown Indiquez votre compartiment GCS et le préfixe gs://some-bucket/pages
# VOTRE GODET GCS
gcs_bucket = #@param {type :"chaîne"}
gcs_prefix = #@param {type :"chaîne"}
# Obtenir le dernier ID de crawl du projet / profil de crawl donné
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Modèle de charge utile pour la requête d'exportation de données
charge utile = {
"data_export": {
"type_données": 'page',
"id_ressource": last_crawl_id,
"output_format": 'parquet',
"cible": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"préfixe_gcs": préfixe_gcs
}
}
}
# Déclencher l'exportation
export = requests.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization' : 'Bearer '+ONCRAWL_TOKEN }).json()
# Afficher la réponse de l'API
afficher (exporter)
# Enregistrer l'ID d'exportation pour une utilisation future
export_id = exporter['data_export']['id']Nous souhaitons exporter vers le bucket Cloud Storage que nous avons configuré précédemment.
Dans ce cadre, nous allons exporter les pages pour le dernier ID de crawl :
- Le dernier ID de crawl est obtenu à partir de la liste des ID de crawl, qui est stockée quelque part dans le dictionnaire "crawls_by_config", qui a été créé à l'étape 3.
- Nous voulons choisir celui correspondant au menu déroulant de l'étape 4, nous utilisons donc l'attribut value du menu déroulant.
- Ensuite, nous extrayons l'attribut crawl_ID. Ceci est une liste. Nous conserverons les 50 premiers éléments de la liste. Nous devons le faire car à l'étape 2, comme vous vous en souviendrez, lorsque nous avons créé le dictionnaire crawls_by_config, nous n'avons stocké qu'un seul ID de crawl par nom de configuration.
J'ai configuré des champs de saisie pour faciliter la fourniture du compartiment et du préfixe ou du dossier Google Cloud Storage, où nous voulons envoyer l'exportation. 
Pour les besoins de la démonstration, aujourd'hui, nous allons écrire dans le dossier "mixed dataset", dans l'un des dossiers que j'ai déjà configurés. Lorsque nous avons configuré notre bucket dans Google Cloud Storage, vous vous souviendrez que j'ai préparé des dossiers pour l'export "liens" et pour l'export "pages".
Pour le premier export, nous voudrons exporter les pages dans le dossier « pages » pour le dernier crawl ID en utilisant le format de fichier Parquet. 
Dans les résultats ci-dessous, vous verrez la charge utile qui doit être envoyée au point de terminaison d'exportation de données, qui est le point de terminaison pour demander une exportation Big Data à l'aide d'une clé API :
# Modèle de charge utile pour la requête d'exportation de données
charge utile = {
"data_export": {
"type_données": 'page',
"id_ressource": last_crawl_id,
"output_format": 'parquet',
"cible": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"préfixe_gcs": préfixe_gcs
}
}
}
Celui-ci contient plusieurs éléments, notamment le type d'ensemble de données que vous souhaitez exporter. Vous pouvez exporter le jeu de données de page, le jeu de données de lien, le jeu de données de clusters ou le jeu de données de données structurées. Si vous ne savez pas ce qui peut être fait, vous pouvez entrer une erreur ici, et lorsque vous appelez l'API, vous obtenez un message indiquant que le choix du type de données doit être soit une page, soit un lien, soit un cluster, soit des données structurées. Le message ressemble à ceci :

{'fields' : [{'message' : 'Le choix n'est pas valide. Doit être l'un des "page", "link", "cluster", "structured_data".',
'nom' : 'type_données',
'type' : 'choix_invalide'}],
'type' : 'invalid_request_parameters'}
Dans le cadre de l'expérience d'aujourd'hui, nous allons exporter l'ensemble de données de page et l'ensemble de données de lien dans des exportations séparées.
Commençons par l'ensemble de données de page. Lorsque j'exécute ce bloc de code, j'ai imprimé la sortie de l'appel API, qui ressemble à ceci :
{'data_export' : {'data_type' : 'page',
'export_failure_reason' : aucun,
'identifiant' : 'XXXXXXXXXXXXXXX',
'format_sortie' : 'parquet',
'output_format_parameters' : aucun,
'output_row_count' : aucun,
'output_size_in_bytes : 1634460016000,
'ID_ressource' : '60dd4c2b34d08a0f10a5e617',
'statut' : 'DEMANDÉ',
'cible': 'gcs',
'target_parameters' : {'gcs_bucket' : 'data-cms',
'gcs_prefix' : 'MIXDATASETS/pages/'}}}
Cela me permet de voir que l'export a été demandé.
Si nous voulons vérifier l'état de l'exportation, c'est très simple. À l'aide de l'ID d'exportation que nous avons enregistré à la fin de ce bloc de code, nous pouvons demander le statut de l'exportation à tout moment avec l'appel d'API suivant :
# STATUT DE L'EXPORTATION
export_status = requests.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Authorization' : 'Bearer '+ONCRAWL_TOKEN }).json ()
afficher (état_exportation)
Cela indiquera un statut dans le cadre de l'objet JSON renvoyé :
{'data_export' : {'data_type' : 'page',
'export_failure_reason' : aucun,
'identifiant' : 'XXXXXXXXXXXXXXX',
'format_sortie' : 'parquet',
'output_format_parameters' : aucun,
'output_row_count' : aucun,
'output_size_in_bytes' : aucun,
'requested_at' : 1638350549000,
'ID_ressource' : '60dd4c2b34d08a0f10a5e617',
'statut' : 'EXPORTATION',
'cible': 'gcs',
'target_parameters' : {'gcs_bucket' : 'data-csm',
'gcs_prefix' : 'MIXDATASETS/pages/'}}} Lorsque l'exportation est terminée ( 'status': 'DONE' ), nous pouvons revenir à Google Cloud Storage.
Si nous regardons dans notre bucket et que nous allons dans le dossier "Liens", il n'y a encore rien ici car nous avons exporté les pages. 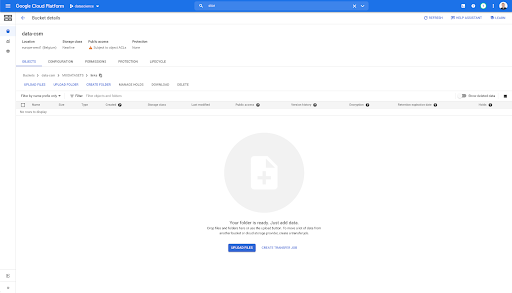
Cependant, lorsque nous regardons dans le dossier "pages", nous pouvons voir que l'exportation a réussi. Nous avons un dossier Parquet : 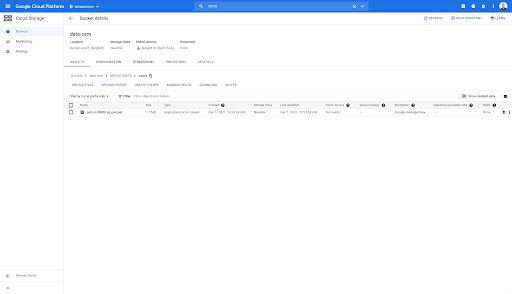
À ce stade, l'ensemble de données des pages est prêt à être importé dans BigQuery, mais nous allons d'abord répéter les étapes ci-dessus pour obtenir le fichier Parquet pour les liens :
- Assurez-vous de définir le préfixe des liens.
- Choisissez le type de données "lien".
- Exécutez à nouveau ce bloc de code pour demander la deuxième exportation.

Cela produira un fichier Parquet dans le dossier "Liens".
Créer des ensembles de données BigQuery
Pendant que l'exportation est en cours, nous pouvons avancer et commencer à créer des ensembles de données dans BigQuery et importer les fichiers Parquet dans des tables distinctes. Ensuite, nous réunirons les tables ensemble.
Ce que nous voulons faire maintenant, c'est jouer avec Google Big Query, qui est disponible dans le cadre de Google Cloud Platform. Vous pouvez utiliser la barre de recherche en haut de l'écran ou accéder directement à https://console.cloud.google.com/bigquery.
Créer un ensemble de données pour votre travail
Nous devrons créer un ensemble de données dans Google BigQuery : 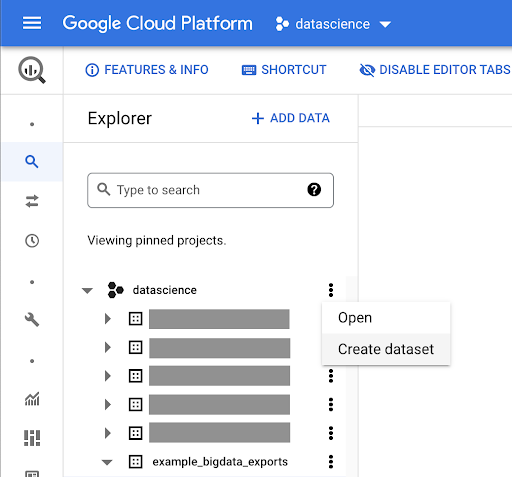
Vous devrez fournir un nom à l'ensemble de données et choisir l'emplacement où les données seront stockées. Ceci est important car cela conditionnera l'endroit où les données sont traitées et ne peut pas être modifié. Cela peut avoir un impact si vos données incluent des informations couvertes par le RGPD ou d'autres lois sur la confidentialité. 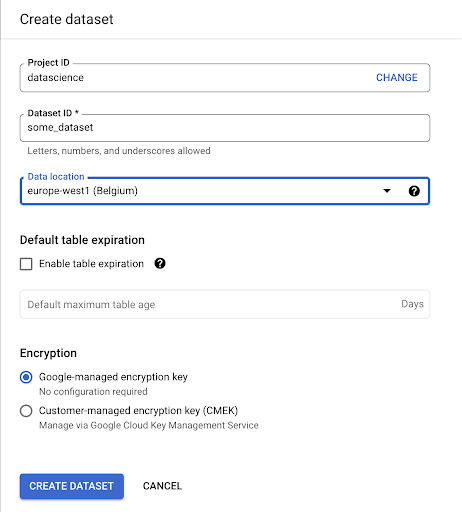
Ce jeu de données est initialement vide. Lorsque vous l'ouvrirez, vous pourrez créer une table, partager l'ensemble de données, copier, supprimer, etc.
Créer des tableaux pour vos données
Nous allons créer une table dans cet ensemble de données. 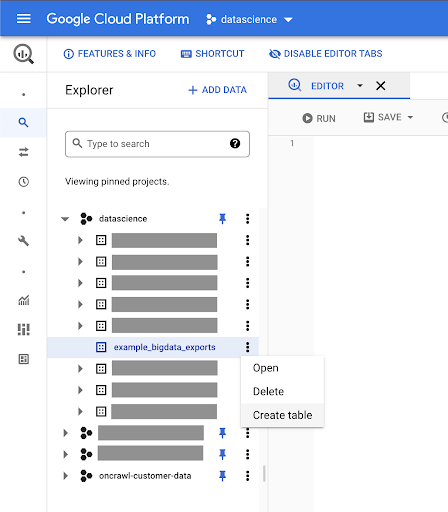
Vous pouvez soit créer une table vide, puis fournir le schéma. Le schéma est la définition des colonnes de la table. Vous pouvez soit définir le vôtre, soit parcourir Google Cloud Storage pour choisir un schéma dans un fichier.
Nous utiliserons cette dernière option. Nous allons accéder à notre bucket, puis au dossier "pages". Choisissons le fichier pages. Il n'y a qu'un seul fichier, donc on ne peut en sélectionner qu'un seul, mais si l'export avait généré plusieurs fichiers, on aurait pu tous les choisir. 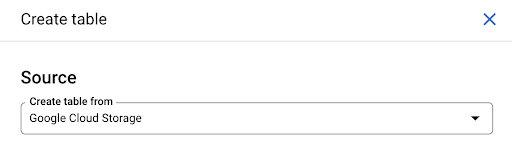
Lorsque nous sélectionnons le fichier, il détecte automatiquement qu'il est au format de fichier Parquet. Nous voulons créer une table nommée "pages", et le schéma sera défini par le fichier source. 
Lorsque nous chargeons un fichier Parquet, il intègre un schéma. En d'autres termes, la définition des colonnes de la table que nous créons sera déduite du schéma qui existe déjà dans le fichier Parquet. C'est là qu'une partie de la magie se produit.
Avançons simplement et créons simplement la table à partir du fichier Parquet. 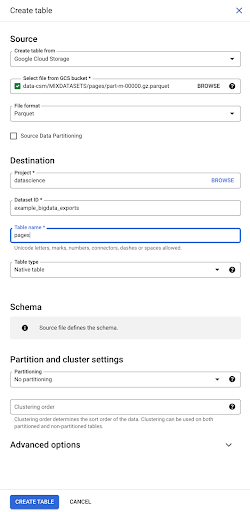
Dans la barre latérale de gauche, nous pouvons maintenant voir qu'un tableau est apparu dans notre ensemble de données, ce qui correspond exactement à ce que nous voulons :
Nous avons donc maintenant le schéma de la table des pages avec tous les champs qui ont été automatiquement déduits du fichier Parquet. On a l'Inrank, la profondeur de la page, si la page est une redirection et ainsi de suite : 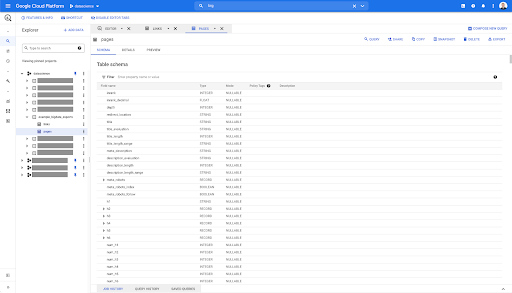
La plupart de ces champs sont les mêmes que ceux mis à disposition dans Data Studio via le connecteur Oncrawl Data Studio, et les mêmes que ceux que vous voyez dans l'explorateur de données de l'interface Oncrawl. 
Cependant, il existe quelques différences. Lorsque nous jouons avec l'exportation de données volumineuses brutes, vous disposez de toutes les données brutes.
- Dans Data Studio, certains champs sont renommés, certains champs sont masqués et certains champs sont ajoutés, comme l'état.
- Dans l'explorateur de données, certains champs sont ce que nous appelons des « champs virtuels », ce qui signifie qu'ils peuvent être une sorte de raccourci vers un champ sous-jacent. Ces champs virtuels disponibles dans l'explorateur de données ne seront pas répertoriés dans le schéma, mais ils peuvent être recréés en fonction de ce qui est disponible dans le fichier Parquet.
Fermons maintenant ce tableau et recommençons pour les liens.
Pour la table des liens, le schéma est un peu plus petit. 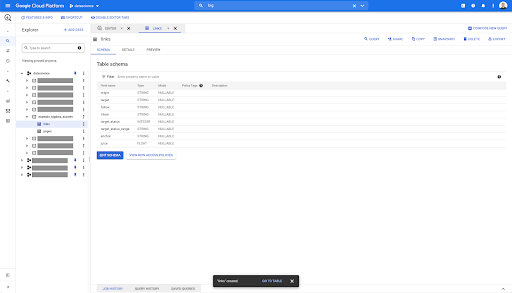
Il ne contient que les champs suivants :
- L'origine du lien,
- La cible du lien,
- La propriété suivante,
- La propriété intérieure,
- Le statut cible,
- La plage du statut cible,
- Le texte d'ancrage, et
- Le jus ou l'équité acheté par le lien.
Sur n'importe quelle table de BigQuery, lorsque vous cliquez sur l'onglet d'aperçu, vous obtenez un aperçu de la table sans interroger la base de données : 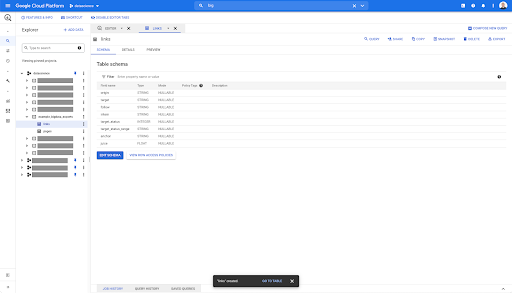
Cela vous donne un aperçu rapide de ce qui y est disponible. Dans l'aperçu du tableau des liens ci-dessus, vous avez un aperçu de chaque ligne et de toutes les colonnes.
Dans certains ensembles de données Oncrawl, vous pouvez voir des lignes qui s'étendent sur plusieurs lignes. Je n'ai pas d'exemple pour vous, mais si c'est le cas, c'est que certains champs contiennent une liste de valeurs. Par exemple, dans la liste des titres h2 d'une page, une seule ligne s'étendra sur plusieurs lignes dans Big Query. Nous verrons cela plus tard si nous voyons un exemple.
Création de votre requête
Si vous n'avez jamais créé de requête dans BigQuery, il est maintenant temps de jouer avec pour vous familiariser avec son fonctionnement. BigQuery utilise SQL pour rechercher des données.
Fonctionnement des requêtes
A titre d'exemple, regardons toutes les URLs et leur inrank…
SELECT URL, inrank ...
à partir du jeu de données des pages…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
où le code d'état de la page est 200…
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
et ne conserver que les 10 premiers résultats :
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
Lorsque nous exécutons cette requête, nous obtiendrons les 10 premières lignes de la liste des pages où le code de statut est 200.
Chacune de ces propriétés peut être modifiée. f Je veux 1000 lignes au lieu de 10, je peux définir 1000 lignes :
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
Si je veux trier, je peux le faire avec "order-by": cela me donnera toutes les lignes classées par ordre décroissant Inrank.
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
Ceci est ma première requête. Je peux l'enregistrer si je veux, ce qui me donnera la possibilité de réutiliser cette requête plus tard si je veux : 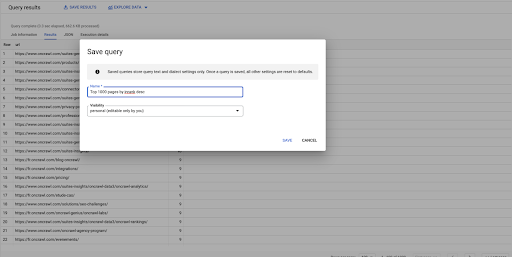
Utiliser des requêtes pour répondre à des questions simples : Lister tous les liens internes vers des pages avec un statut 301
Maintenant que nous savons comment composer une requête, revenons à notre problème initial.
Nous voulions répondre à des questions de données, qu'elles soient simples ou complexes. Commençons par une question simple, telle que "quels sont tous les liens internes qui pointent vers des pages avec un statut 301 (redirigé) et où puis-je les trouver ?"
Création d'une nouvelle requête
Nous allons commencer par explorer comment cela fonctionne.
Je vais vouloir des colonnes pour les éléments suivants de la base de données "links":
- Origine
- Cible
- Code d'état cible
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links`
Je veux limiter ceux-ci aux liens internes uniquement, mais imaginons que je ne me souvienne pas du nom de la colonne ou de la valeur qui indique si le lien est interne ou externe. Je peux accéder au schéma pour le rechercher et utiliser l'aperçu pour afficher la valeur : 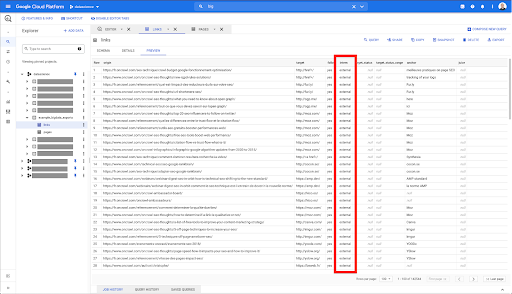
Cela me dit que la colonne est nommée "interne" et que la plage de valeurs possible est "externe" ou "interne".
Dans ma requête, je veux spécifier "où interne est interne", et limiter les résultats aux 100 premiers pour l'instant :
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE interne LIKE 'interne' LIMIT 100
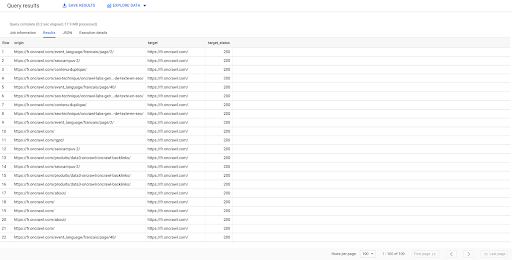
Le résultat ci-dessus montre la liste des liens avec leur statut cible. Nous n'avons que des liens internes, et nous en avons 100, comme spécifié dans la requête.
Si nous voulons n'avoir que des liens internes vers ce point vers des pages redirigées, nous pourrions dire "où le statut interne comme interne et cible est égal à 301":
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE interne LIKE 'interne' AND target_status = 301
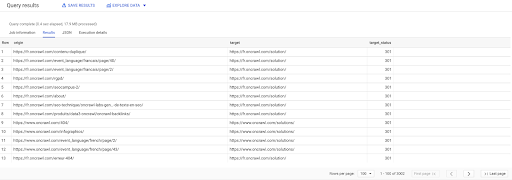
Si nous ne savons pas combien d'entre eux existent, nous pouvons exécuter cette nouvelle requête et nous verrons qu'il y a 3002 liens internes avec un statut cible de 301.
Rejoindre les tables : trouver les codes d'état finaux des liens pointant vers des pages redirigées
Sur un site Web, vous avez souvent des liens vers des pages qui sont redirigées. Nous voulons connaître le code d'état de la page vers laquelle ils sont redirigés (ou l'URL cible finale).
Dans un jeu de données, vous avez les informations sur les liens : la page d'origine, la page cible et son code d'état (comme 301), mais pas l'URL vers laquelle pointe une page redirigée. Et dans l'autre, vous avez les informations sur les redirections et leurs cibles finales, mais pas la page d'origine où le lien vers celles-ci a été trouvé.
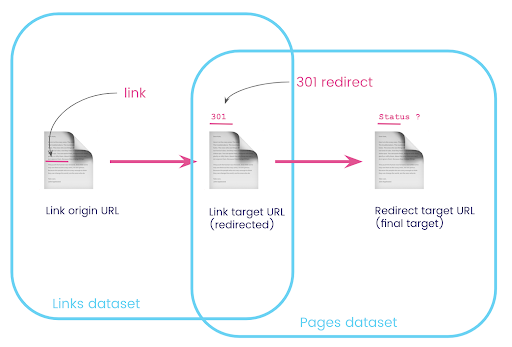
Décomposons cela :
Tout d'abord, nous voulons des liens vers des redirections. Écrivons ceci. Nous voulons:
- L'origine.
- La cible. La cible doit avoir un code d'état 301.
- La cible finale de la redirection.
En d'autres termes, dans le jeu de données des liens, nous voulons :
- L'origine du lien
- La cible du lien
Dans l'ensemble de données de pages, nous voulons :
- Toutes les cibles redirigées
- La cible finale de la redirection
Cela nous donnera une requête du type :
SELECT url, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS pages WHERE status_code = 301 OR status_code = 302
Cela devrait me donner la première partie de l'équation.
Maintenant, j'ai besoin de tous les liens menant à la page qui sont les résultats de la requête que je viens de créer, en utilisant des alias pour mes ensembles de données et en les joignant à l'URL cible du lien et à l'URL de la page. Cela correspond à la zone de chevauchement des deux ensembles de données dans le diagramme au début de cette section.
SÉLECTIONNER liens.origine, pages.url, pages.final_redirect_location, pages.final_redirect_status DE Pages AS de `datascience-oncrawl.example_bigdata_exports.pages` REJOINDRE `datascience-oncrawl.example_bigdata_exports.links` Liens AS SUR liens.cible = pages.url OÙ pages.status_code = 301 OU pages.status_code = 302 COMMANDÉ PAR ASC d'origine
Dans les résultats de la requête, je peux renommer les colonnes pour rendre les choses plus claires, mais je vois déjà que j'ai un lien d'une page de la première colonne, qui va vers la page de la deuxième colonne, qui est à son tour redirigée vers la page dans la troisième colonne. Dans la quatrième colonne, j'ai le code de statut de la cible finale : 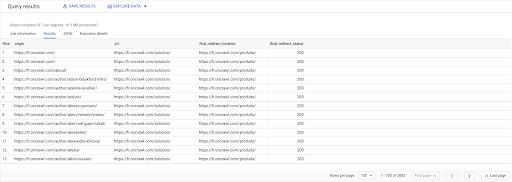
Maintenant, je peux dire quels liens pointent vers des pages redirigées qui ne se résolvent pas en 200 pages. Ce sont peut-être des 404, par exemple, ce qui me donne une liste prioritaire de liens à corriger.
Nous avons vu précédemment comment enregistrer une requête. Nous pouvons également enregistrer les résultats, jusqu'à 16000 lignes de résultats : 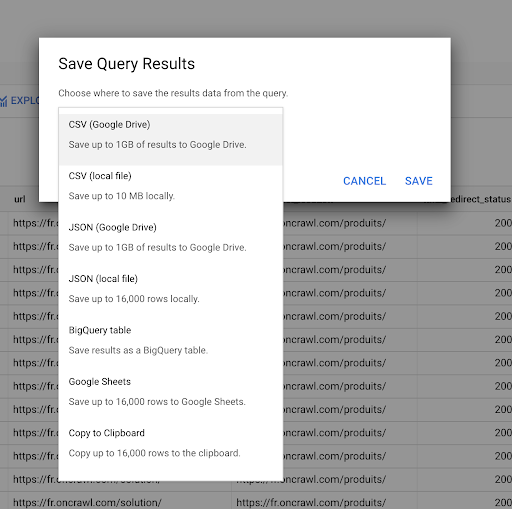
Nous pouvons ensuite utiliser ces résultats de différentes manières. Voici quelques exemples:
- Nous pouvons enregistrer cela en tant que fichier CSV ou JSON localement.
- Nous pouvons l'enregistrer en tant que feuille de calcul Google Sheets et la partager avec le reste de l'équipe.
- Nous pouvons également l'exporter directement vers Data Studio.
Les données comme avantage stratégique
Avec toutes ces possibilités, il est facile d'utiliser stratégiquement les réponses à vos questions complexes. Vous avez peut-être déjà de l'expérience dans la connexion des résultats BigQuery à Data Studio ou à d'autres plates-formes de visualisation de données, ou vous avez peut-être déjà mis en place un processus qui transmet les informations à une équipe d'ingénieurs ou même dans un flux de travail d'informatique décisionnelle ou d'analyse de données.
Si vous avez inclus les étapes décrites dans cet article dans le cadre d'un processus, n'oubliez pas que vous pouvez automatiser toutes les étapes dans BigQuery : toutes les actions que nous avons effectuées dans cet article sont également accessibles via l'API BigQuery. Cela signifie qu'ils peuvent être exécutés par programme dans le cadre d'un script ou d'un outil personnalisé.
Quelles que soient vos prochaines étapes, la première étape est toujours l'accès aux données brutes de référencement et de site Web. Nous pensons que cet accès aux données est l'une des parties les plus importantes de l'analyse technique : avec Oncrawl, vous aurez toujours un accès complet à vos données brutes.
L'accès aux données signifie également que vous pouvez aller au-delà de ce qui est possible dans l'interface d'Oncrawl et explorer toutes les relations entre vos données, quelle que soit la complexité des questions que vous vous posez.