
5 astuces pour gagner du temps avec OnCrawl
Publié: 2017-06-21Comment profiter des fonctionnalités avancées d'OnCrawl pour améliorer votre efficacité lors du suivi SEO quotidien.
OnCrawl est un puissant outil de référencement qui vous aide à surveiller et à optimiser la visibilité des moteurs de recherche des sites Web de commerce électronique, des éditeurs en ligne ou des applications. L'outil a été construit autour d'un principe simple : faire gagner du temps aux gestionnaires de trafic dans leur processus d'analyse et dans leur gestion de projet SEO au quotidien.
En plus d'être un outil d'audit sur site, basé sur une plate-forme SaaS supportée par une API combinant toutes les données des sites Web, c'est aussi un analyseur de journaux qui simplifie l'extraction et l'analyse des données à partir des fichiers du serveur de journaux.
Les possibilités d'OnCrawl sont assez larges mais demandent à être maîtrisées. Dans cet article, nous allons partager 5 astuces pour gagner du temps lors de votre utilisation quotidienne de notre crawler SEO et analyseur de logs.
1# Comment catégoriser les URL HTTP et HTTPS
La migration HTTPS est un sujet brûlant dans la sphère SEO. Pour gérer parfaitement cette étape clé, il est important de suivre précisément le comportement des bots sur les deux protocoles.
L'expérience a montré que les robots mettent plus ou moins de temps à passer complètement de HTTP à HTTPS. En moyenne, cette transition prend quelques semaines ou quelques mois, en fonction de facteurs externes et internes liés à la qualité et à la migration du site.
Pour comprendre précisément cette phase de transition, où votre budget de crawl est fortement impacté, il est astucieux de surveiller les hits des bots. Il est donc nécessaire d'analyser les logs du serveur. Le bot, en tant qu'utilisateur régulier, laisse des marques sur chaque page, ressource et demande qu'il fait. Vos journaux possèdent les ports qui ont délivré ces appels. Vous pouvez ainsi valider la qualité de migration de votre site HTTPS.
Méthodes pour configurer un ensemble http vs https dédié de groupe de pages
Sur votre accueil de projet avancé, vous pouvez trouver dans le coin supérieur droit un bouton "paramètres". Ensuite, sélectionnez le menu "Configurer le groupe de pages". Une fois ici, créez un nouveau "Créer un ensemble de groupes" et nommez-le "HTTP vs HTTPS".
Afin d'accéder à vos logs, il est important de sélectionner l'option « Je souhaite utiliser cet ensemble sur les tableaux de bord de suivi des logs et d'analyses croisées » .
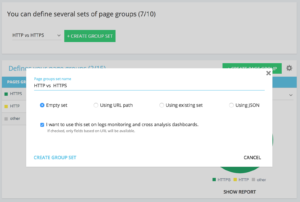
- HTTPS : « URL complète » / « commencer par » / https
- HTTP : "URL complète" / "ne commence pas par" / https
Une fois enregistré, vous accéderez à une vue de votre migration HTTPS (si vous avez ajouté le port de requête dans vos lignes de journal. Vous pouvez consulter notre guide.)
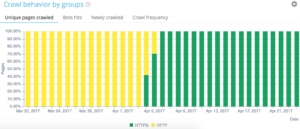
Nos filtres rapides se trouvent dans l'explorateur de données. Ils ont été conçus pour faciliter l'accès à certaines métriques SEO importantes telles que les liens pointant vers 404, 500 ou 301/302, des pages trop lentes ou trop pauvres, etc.
Voici la liste complète:
- 404 erreurs
- erreurs 5xx
- Pages actives
- Pages actives non explorées par Google
- Pages actives avec un code de statut rencontré par Google différent de 200
- Canonique ne correspondant pas
- Canonique non défini
- Pages indexables
- Pas de pages indexables
- Pages actives orphelines
- Pages orphelines
- Pages explorées par Google
- Pages crawlées par Google et OnCrawl
- Pages de la structure non explorées par Google
- Pages pointant vers des erreurs 3xx
- Pages pointant vers des erreurs 4xx
- Pages pointant vers des erreurs 5xx
- Pages avec un mauvais h1
- Pages avec mauvais h2
- Pages avec une mauvaise méta description
- Pages avec un mauvais titre
- Pages avec des problèmes de duplication HTML
- Pages avec moins de 10 liens entrants
- Rediriger 3xx
- Pages trop lourdes
- Pages trop lentes
Mais parfois, ces QuickFilters ne répondent pas à toutes vos préoccupations commerciales. Dans ce cas, vous pouvez partir de l'un d'entre eux et créer votre "filtre personnel" en ajoutant des éléments dans le filtre et en les enregistrant pour retrouver rapidement vos filtres à chaque fois que vous vous connectez à l'outil.
Par exemple, à partir des liens pointant vers 4xx, vous pouvez choisir de filtrer les liens qui ont une ancre vide : "Ancre" / "est" / "" et enregistrer ce filtre. Une fois enregistré, il peut être modifié autant de fois que nécessaire.
Vous avez maintenant directement accès à ce "Quickfilter" particulier dans la liste "Select a Quickfilter" au bas de la partie "Own" comme on le voit sur la capture d'écran ci-dessous.
3# Comment configurer les champs personnalisés liés à DataLayer ?
Vous pouvez utiliser une segmentation de vos types de pages associés lorsque vous définissez vos balises d'outils d'analyse par exemple. Ce code particulier est très intéressant pour segmenter ou croiser les données d'OnCrawl avec vos données externes.
Pour vous permettre de créer une « colonne pivot » pour votre analyse, nous pouvons extraire ces morceaux de codes lors des crawls et les ramener comme type de données de votre projet.
L'option "Champs personnalisés" permet de récupérer n'importe quel élément des pages de code source grâce à une regex ou un XPath. Ces langues ont leur propre définition et leurs propres règles. Vous pouvez trouver des informations sur XPath ici et sur les regex ici.

Use case 1 : extraire les données de la couche de données à partir du code source des pages
Code à analyser :

Solution : Utiliser une « regex » : s.prop2= »([^ »]+) » / Extract : Mono-value / Field Format : Value

- Trouvez la chaîne de caractères s.prop2="
- Scrape tous les caractères qui ne sont pas " (le premier caractère suivant les données à extraire)
- La chaîne à extraire peut être trouvée avant la fermeture "
Suite au crawl, dans l'explorateur de données, vous trouverez dans la colonne sProp2, sProp3 ou dans votre champ Name, les données extraites :

Utiliser un XPATH
Code à analyser :
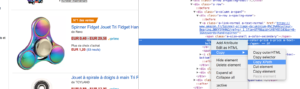
Il vous suffit de copier/coller l'élément Xpath que vous souhaitez récupérer directement depuis l'analyseur de code Chrome. Attention, si le code est rendu en JavaScript, vous devrez mettre en place un projet scrape personnalisé. Le langage Xpath est très puissant et peut être difficile à manipuler. Si vous avez besoin d'aide, veuillez appeler nos experts.
Use case 3 : tester la présence d'un tag analytics lors d'une phase de réception
Utiliser une expression régulière
Code à analyser :

Solution : Utiliser une « regex » : '_setAccount', 'UA-364863-11' / Extraire : Vérifier s'il existe
Vous obtiendrez dans le Data Explorer un "true" si la chaîne est trouvée, "false" au contraire.
4# Comment visualiser la fréquence de crawl Google sur chaque partie de votre site web
Le budget de crawl est au cœur de toute préoccupation SEO. Elle est profondément liée au concept « Page Importance » et à la planification du crawl de Google. On sait que ces principes, introduits dans le brevet Google depuis 2012, permettent à la société Mountain View d'optimiser les ressources dédiées au crawl du web.
Google ne dépense pas la même énergie sur chaque partie de votre site Web. Sa fréquence de crawl sur chaque partie de votre site vous donne un aperçu précis de l'importance de vos pages aux yeux de Google.
Les pages importantes sont davantage crawlées par les bots Google car le budget de crawl est profondément lié aux compétences de classement d'une page.
Les projets OnCrawl Advanced vous permettent nativement de voir le budget de crawl dans la partie « Log monitoring » / « Crawl Behavior » / « Crawl Behavior By Group ».
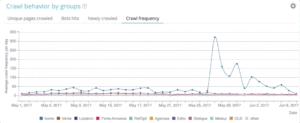
Vous pouvez voir que le groupe "Page d'accueil" a la fréquence de crawl la plus élevée. C'est normal car Google est constamment à la recherche de nouveaux articles et ils sont généralement listés sur la page d'accueil. L'idée de l'importance de la page est profondément liée au concept Google Freshness. Votre page d'accueil est la page la plus importante pour prioriser votre budget de crawl Google. Ensuite, l'optimisation est étendue à d'autres pages en termes de profondeur et de popularité.
Il est cependant difficile de voir les différences de fréquence. Vous devez donc cliquer sur les groupes que vous souhaitez supprimer (en cliquant sur la légende) et voir apparaître les données.
5# Comment tester les codes de statut d'une liste d'URL après une migration
Lorsque l'on souhaite tester rapidement les status codes d'un ensemble d'URL, il est possible de modifier les paramètres d'un nouveau crawl :
- Ajouter toutes les URL de démarrage (bouton "ajouter une URL de démarrage")
- Définir la profondeur maximale à 1
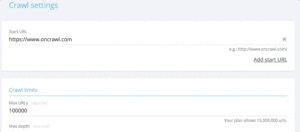
Cette analyse personnalisée renverra des données qualitatives concernant cet ensemble d'URL.
Vous pourrez vérifier si les redirections sont bien configurées ou suivre l'évolution des codes d'état dans le temps. Pensez à l'avantage de crawler régulièrement, vous pourrez suivre automatiquement les anciennes urls.
Pourquoi ne pas créer un tableau de bord automatisé via notre API et créer un suivi de test automatisé sur ces aspects.
Nous espérons que ces hacks vous aideront à améliorer votre efficacité en utilisant OnCrawl. Nous avons encore de nombreuses astuces avancées à vous montrer. S'il vous plaît partagez avec nous sur Twitter vos #oncrawlhacks par exemple, nous sommes heureux que nos utilisateurs puissent s'amuser autant que nous avec notre outil.