
5 bonnes raisons de combiner vos données de crawl et de logs
Publié: 2018-03-27La compréhension des données des fichiers journaux dans le référencement a de plus en plus augmenté dans la communauté SEO. Les fichiers journaux sont en fait la seule représentation qualitative de ce qui se passe sur un site Web. Encore faut-il pouvoir les faire parler efficacement.
Les visites SEO exactes et le comportement des bots sont présents dans vos fichiers journaux. D'autre part, les données de votre rapport de crawl peuvent fournir une bonne connaissance de vos performances sur site. Vous devez combiner vos fichiers journaux et vos données d'exploration pour mettre en évidence de nouvelles dimensions lors de l'analyse de votre site Web.
Cet article vous montrera cinq excellentes façons de combiner les données d'exploration et de fichiers journaux. Évidemment, il y en a beaucoup d'autres que vous pouvez utiliser.
1# Détection des pages orphelines et optimisation du budget de crawl
Qu'est-ce qu'une page orpheline ? Si une URL apparaît dans les logs sans être dans l'architecture du site, cette URL est dite orpheline.
Google a un index colossal ! Dans la durée, il conservera toutes les URL qu'il a déjà découvertes sur votre site, même si elles ne sont plus présentes dans l'architecture (changement de slug, pages supprimées, migration complète du site, liens externes en erreur ou transformés). Évidemment, laisser Google crawler ces pages dites orphelines peut avoir un impact sur l'optimisation de votre budget de crawl. Si des URL obsolètes consomment votre budget de crawl, cela empêche d'autres URL d'être crawlées plus régulièrement et aura forcément un impact sur votre référencement.
Lors du crawl de votre site web, OnCrawl parcourt tous les liens pour découvrir, profondeur par profondeur, l'architecture complète de votre site. D'autre part, lors de la surveillance des fichiers journaux, OnCrawl compile les données des hits des bots Google et des visites SEO.
La différence entre les URL connues de Google et celles qui sont liées dans l'architecture peut être très importante. Les optimisations SEO qui visent à corriger les liens oubliés ou brisés et à réduire les pages orphelines sont essentielles.
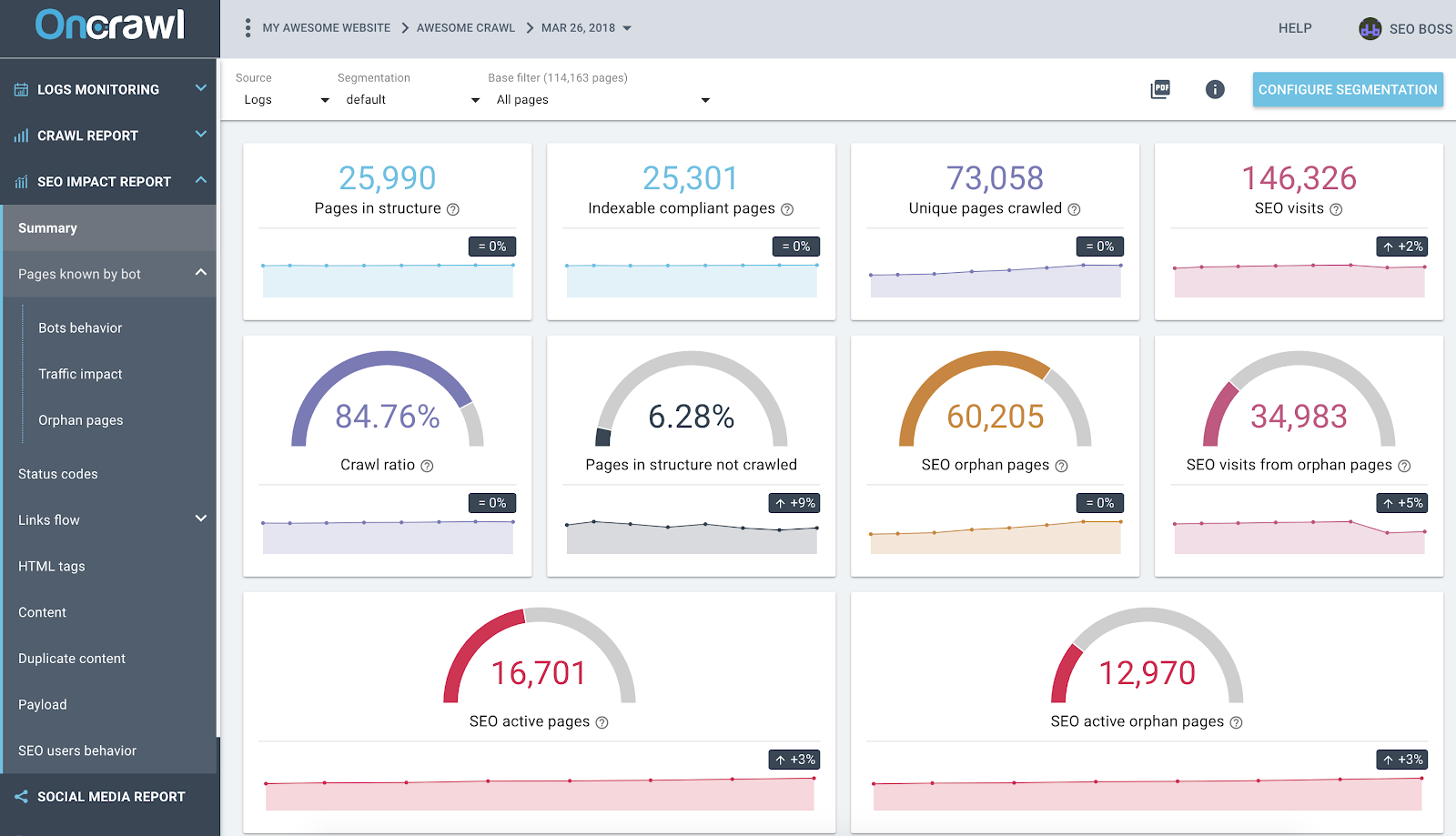
Rapport d'impact SEO d'OnCrawl basé sur l'analyse des données croisées des logs et du crawl
La capture d'écran ci-dessus donne un état de l'art de vos logs et données de crawl. Vous remarquerez rapidement que :
- 25 990 pages sont dans la structure - trouvées par notre crawler et en tenant compte de tous les liens qu'il a suivis sur le site ;
- 73 058 pages sont crawlées par Google – c'est 3x plus que dans la structure ;
- Un ratio de crawl de 84% – (pages crawlées OnCrawl + pages actives issues des logs + pages crawlées Google) / pages crawlées Google ;
- Plus de 6% des pages internes ne sont pas crawlées – il suffit de cliquer sur le seau noir pour avoir la liste de ces pages dans le Data Explorer ;
- 60 000 pages orphelines - le delta entre les pages de la structure et les pages explorées par Google ;
- 34K visites SEO sur ces pages – il semblerait qu'il y ait un problème sur le maillage interne !
Bonne pratique : OnCrawl vous donne l'avantage d'explorer les données derrière chaque graphique ou métrique simplement en cliquant dessus. De cette façon, vous obtiendrez une liste téléchargeable d'URL directement filtrées sur le périmètre que vous avez exploré.
2# Découvrez quelles URL consomment le plus (ou le moins) de budget de crawl
Tous les événements des visites des bots Google sont connus par la plateforme de données OnCrawl. Cela vous permet de connaître – pour chaque URL – toutes les données compilées en fonction du temps.
Dans l'explorateur de données, vous pouvez ajouter pour chaque URL des colonnes de visites de bots (sur une période de 45 jours) et des visites par jour et par bots, ce qui correspond à une valeur moyenne par jour. Ces informations sont précieuses pour évaluer la consommation du budget de crawl de Google. Vous constaterez souvent que ce budget n'est pas uniforme sur tous les sites.
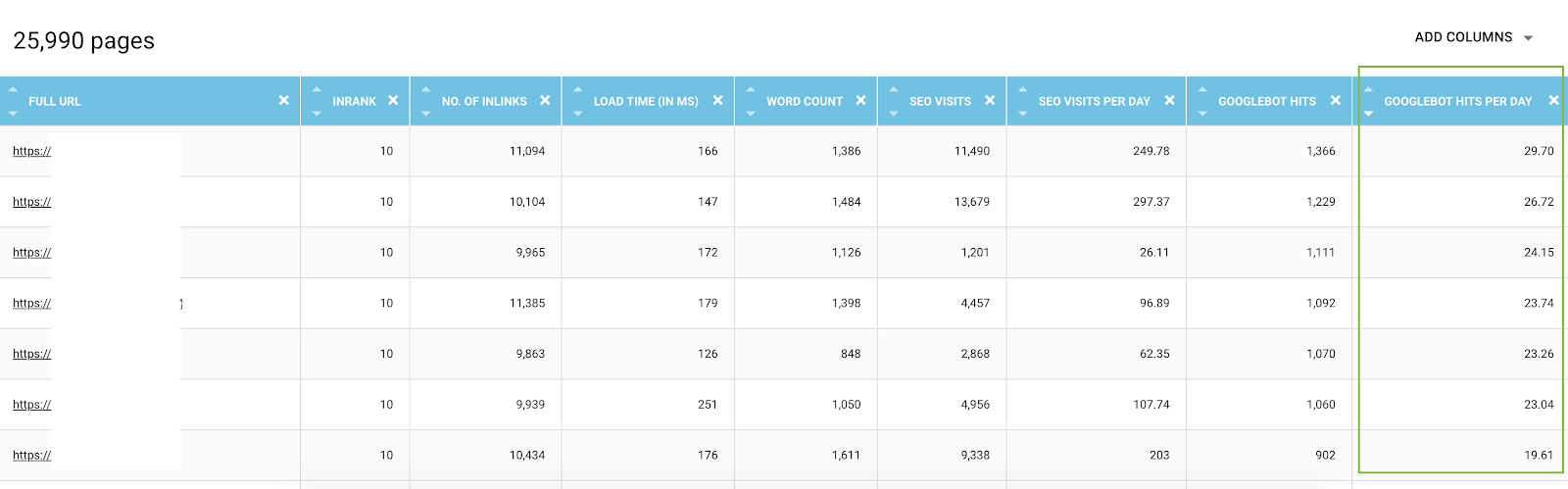
Liste de toutes les URL de l'explorateur de données avec des métriques de crawl et filtrées par les visites de bot par jour
En fait, certains facteurs peuvent déclencher ou réduire le budget de crawl. Nous avons ensuite établi une liste des métriques les plus importantes dans cet article sur l'importance de la page Google. La profondeur, le nombre de liens qui pointent vers une page, le nombre de mots-clés, la vitesse de la page, l'InRank (popularité interne) influencent l'exploration des bots. Vous en apprendrez plus dans le paragraphe suivant.
3# Connaissez vos meilleures pages SEO, vos pires pages SEO et déterminez les facteurs de succès des pages
Lorsque vous utilisez l'explorateur de données, vous avez accès à des métriques clés sur les pages, mais il peut être compliqué de comparer des centaines de lignes et de métriques ensemble. L'utilisation de colonnes pour segmenter les visites de robots par jour et les visites SEO par jour est un allié dans votre exploration de données.
- Téléchargez les fichiers JSON CS - Bot Hits by Day et CS - SEO visites by day ;
- Ajoutez-les en tant que nouvelles segmentations.
En effet, vous pouvez créer des segmentations basées sur ces deux valeurs issues de l'analyse du log pour avoir une première répartition de vos pages par groupes. Mais vous pouvez aussi filtrer chaque groupe de ces segmentations pour détecter rapidement – dans chaque rapport OnCrawl – quelles pages n'atteignent pas les valeurs attendues.
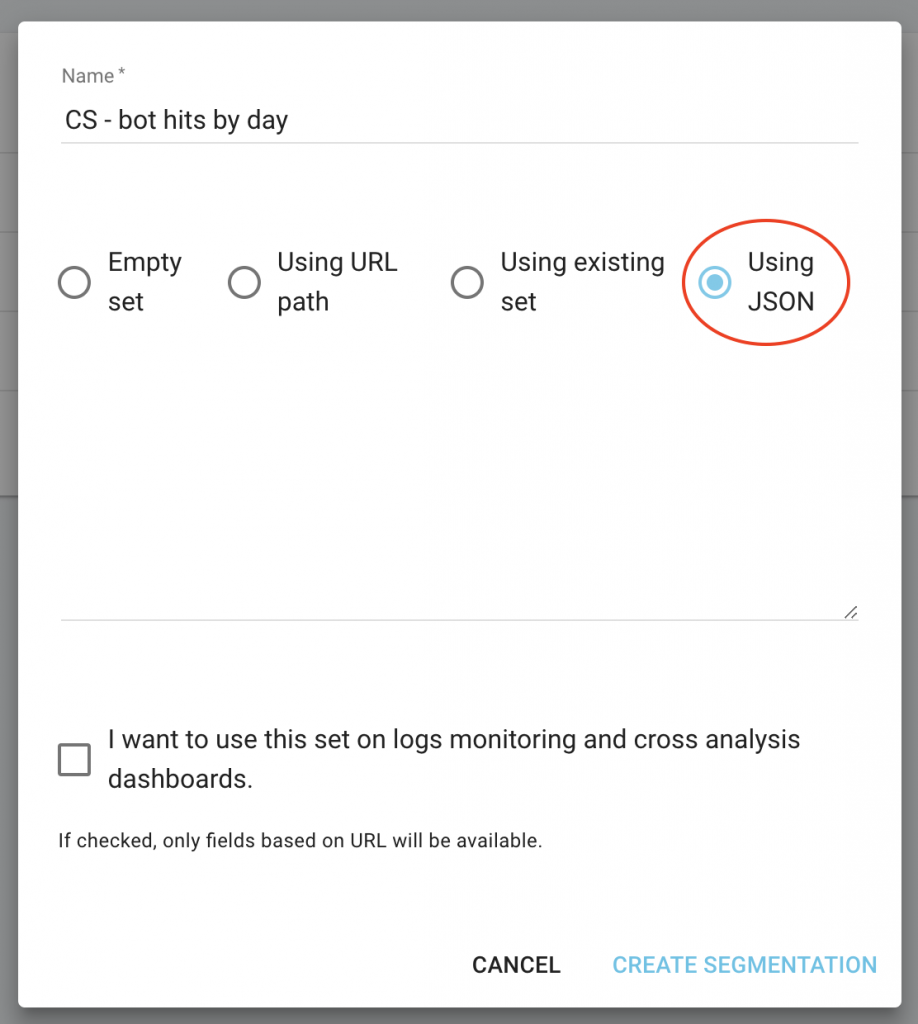
Sur la page d'accueil de votre projet, cliquez sur le bouton "Configurer la segmentation".

Créez ensuite une nouvelle segmentation

Utilisez l'import JSON en choisissant la capacité "Utiliser JSON" et copiez/collez les fichiers que vous avez téléchargés.

Vous pouvez désormais changer de segmentation à l'aide du menu supérieur de chaque rapport.
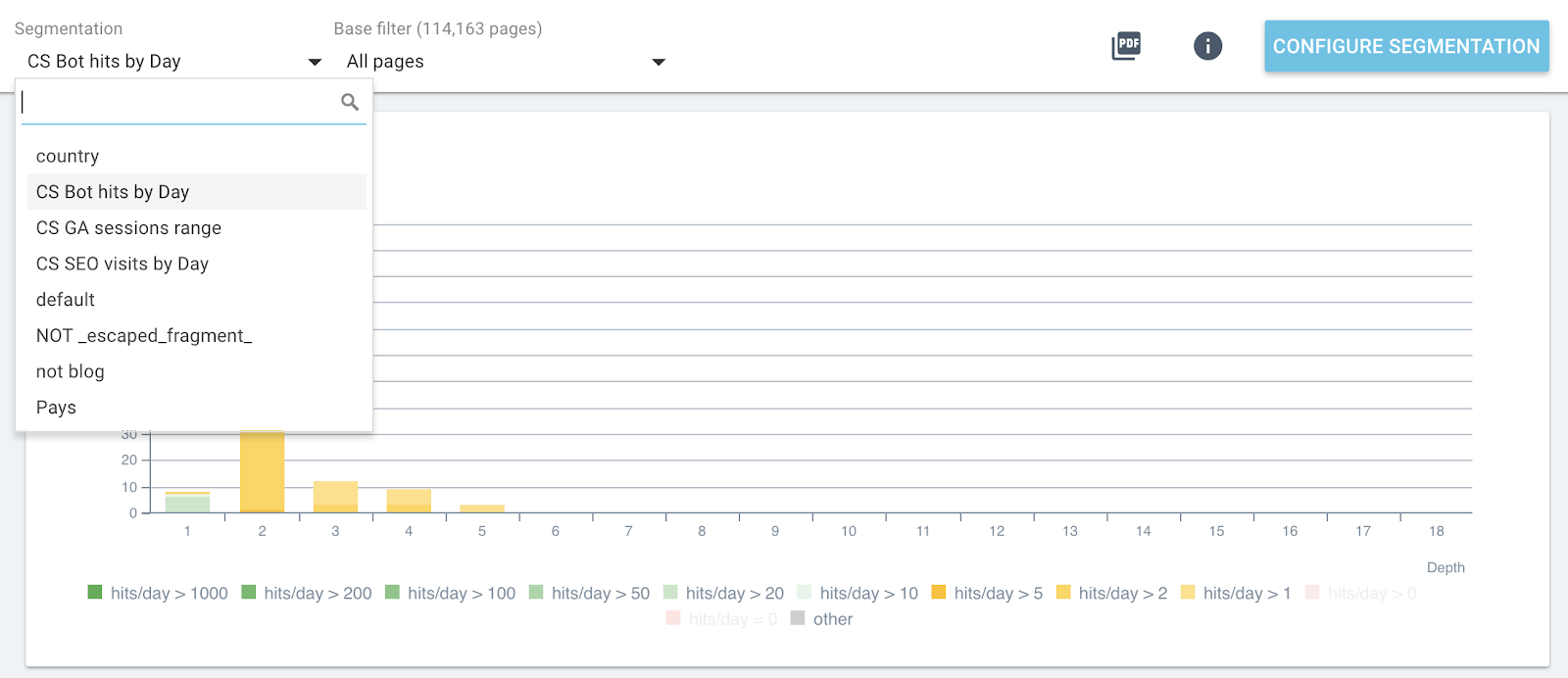
Changement de segmentation en direct dans tous les rapports OnCrawl
Cela vous donnera sur chaque graphique l'impact des métriques que vous analysez et liées aux pages regroupées par bot hits ou visites SEO.
Dans l'exemple suivant, nous avons utilisé ces segments pour comprendre l'impact de la popularité interne InRank - basée sur la puissance des liens par profondeur. De plus, les visites de robots et les visites SEO sont corrélées sur le même axe.
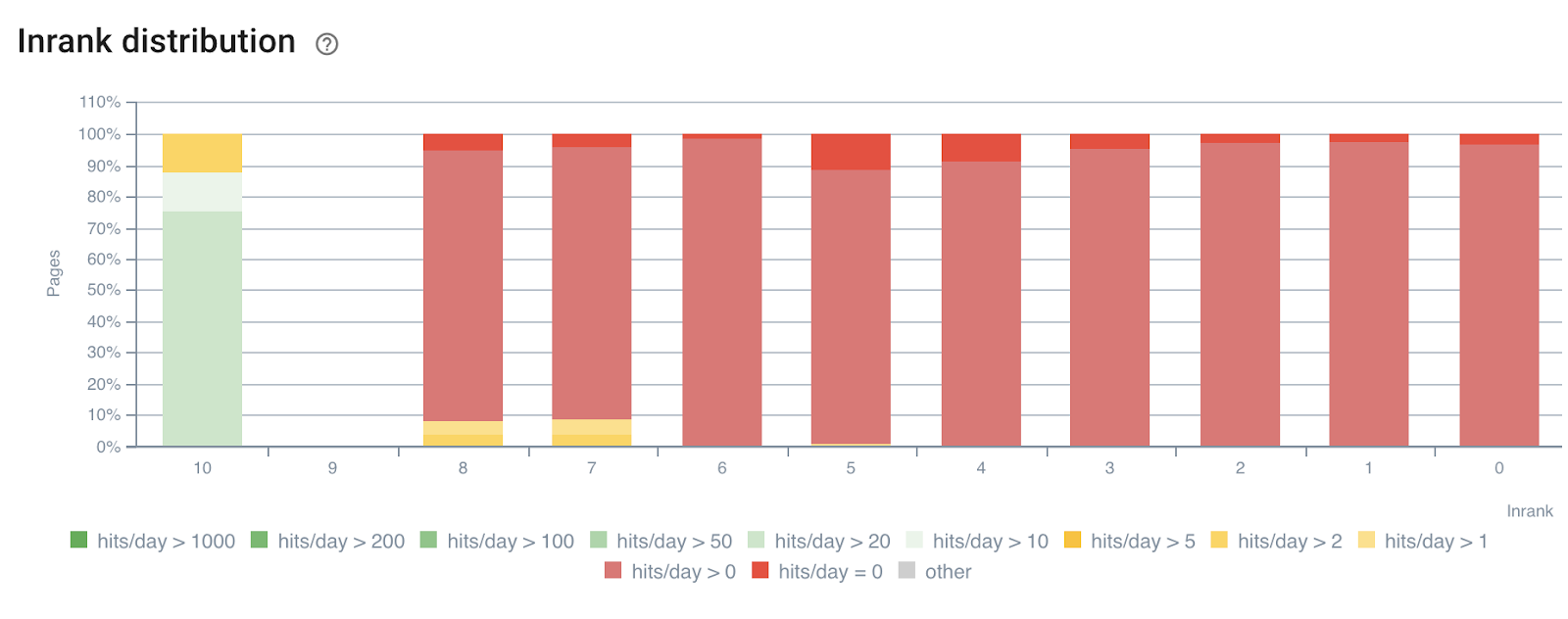
Répartition InRank par visites de robots par jour
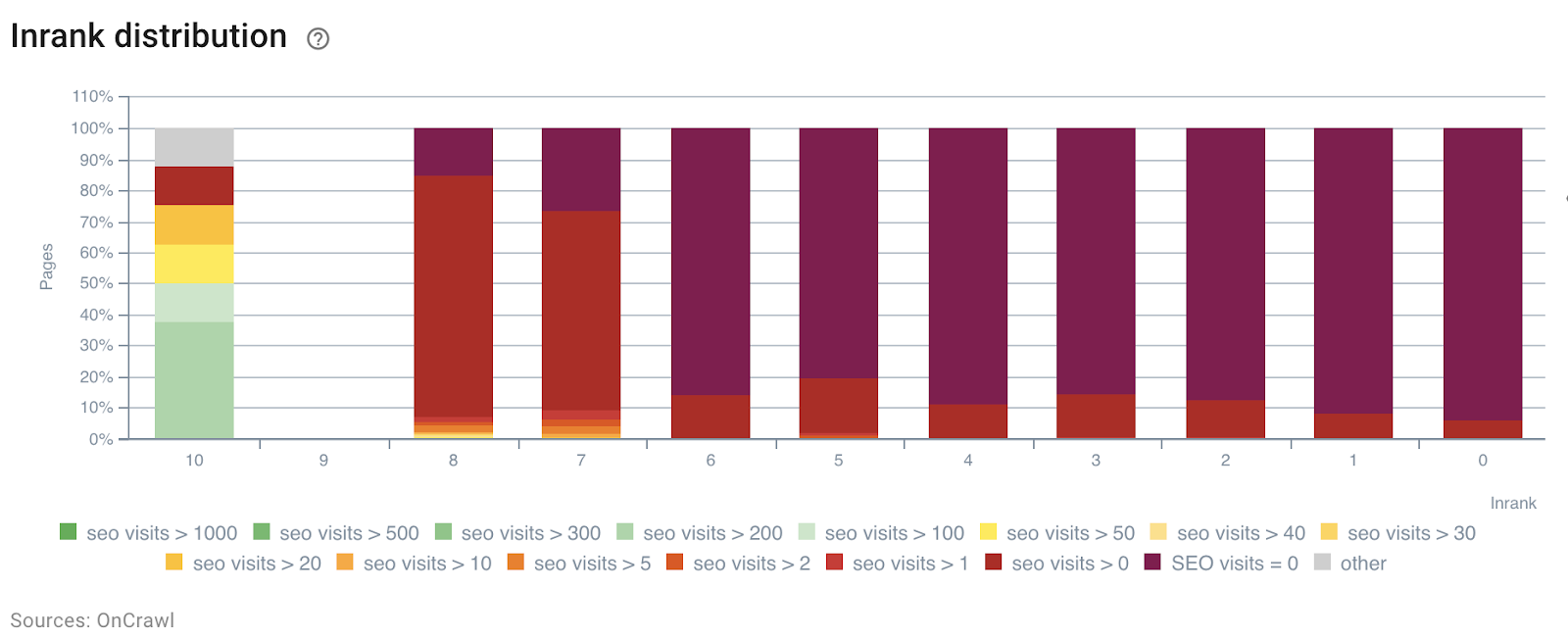
Répartition InRank par visites SEO par jour
La profondeur (le nombre de clics depuis la page d'accueil) a clairement un impact à la fois sur les visites des bots et sur les visites SEO.
De la même manière, chaque groupe de pages peut être sélectionné indépendamment pour mettre en évidence les données des pages les plus consultées ou visitées.
Cela permet de détecter rapidement les pages qui pourraient être plus performantes si elles étaient optimisées, nombre de mots dans la page, profondeur ou nombre de liens entrants par exemple.
Choisissez simplement la bonne segmentation et le groupe de pages que vous souhaitez analyser.
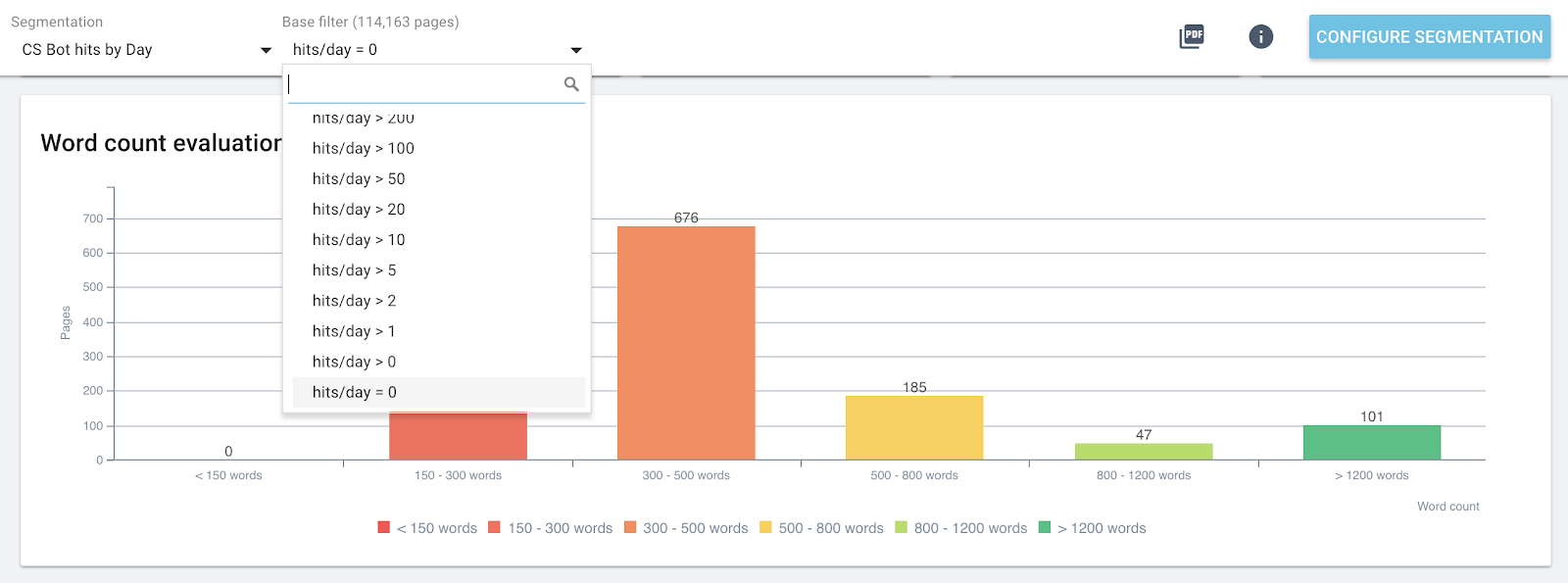
Répartition des mots dans la page pour le groupe contenant 0 bot touché par jour
4# Déterminer les valeurs seuils pour maximiser le budget de crawl et les visites SEO
Pour aller plus loin, le SEO Impact Report – crawl and log cross-data analysis – permet de détecter des valeurs seuils permettant d’augmenter les visites SEO, la fréquence de crawl ou la découverte de pages.
Impact du nombre de mots sur la fréquence de crawl
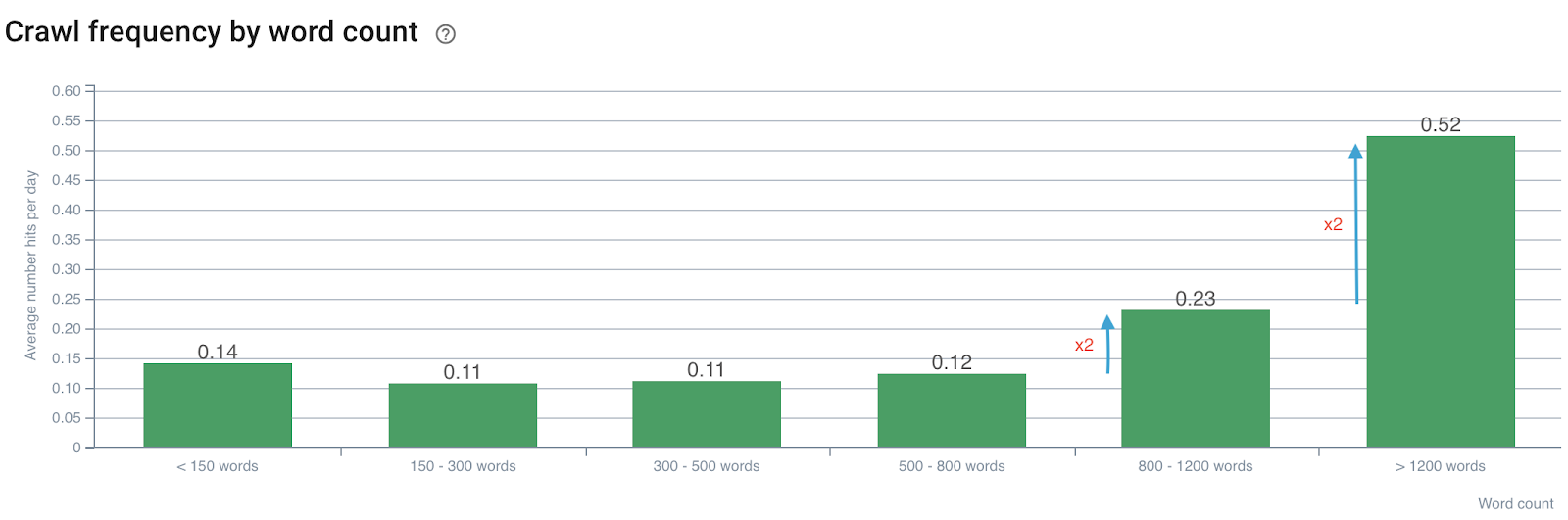
Fréquence de crawl par nombre de mots
On remarque que la fréquence de crawl est doublée lorsque le nombre de mots dépasse 800. Ensuite, elle est également doublée lorsque le nombre de mots dans la page dépasse 1200 mots.
Impact du nombre d'inlinks sur le crawl ratio
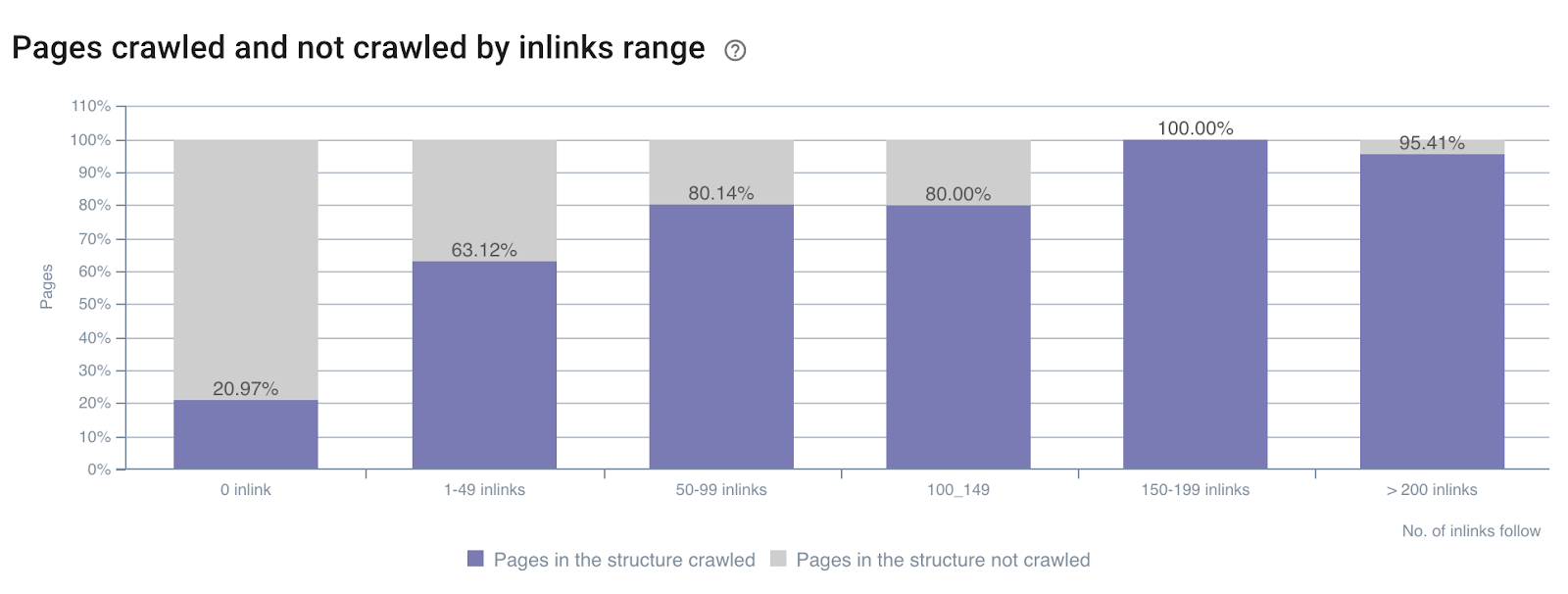
Ratio de crawl par nombre d'inlinks sur tout le site
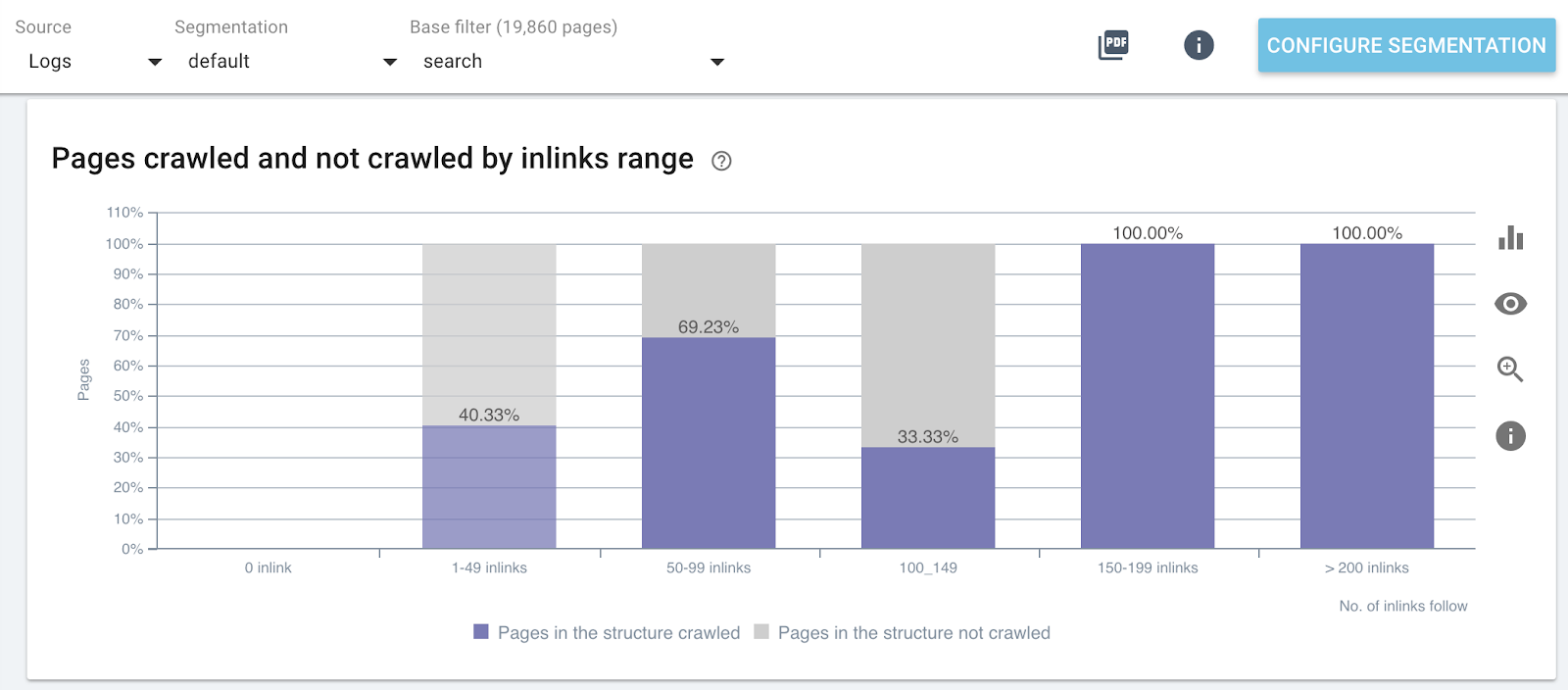
Ratio de crawl par nombre de liens entrants sur des parties spécifiques du site Web (pages de recherche)
Impact de la profondeur sur l'activité des pages
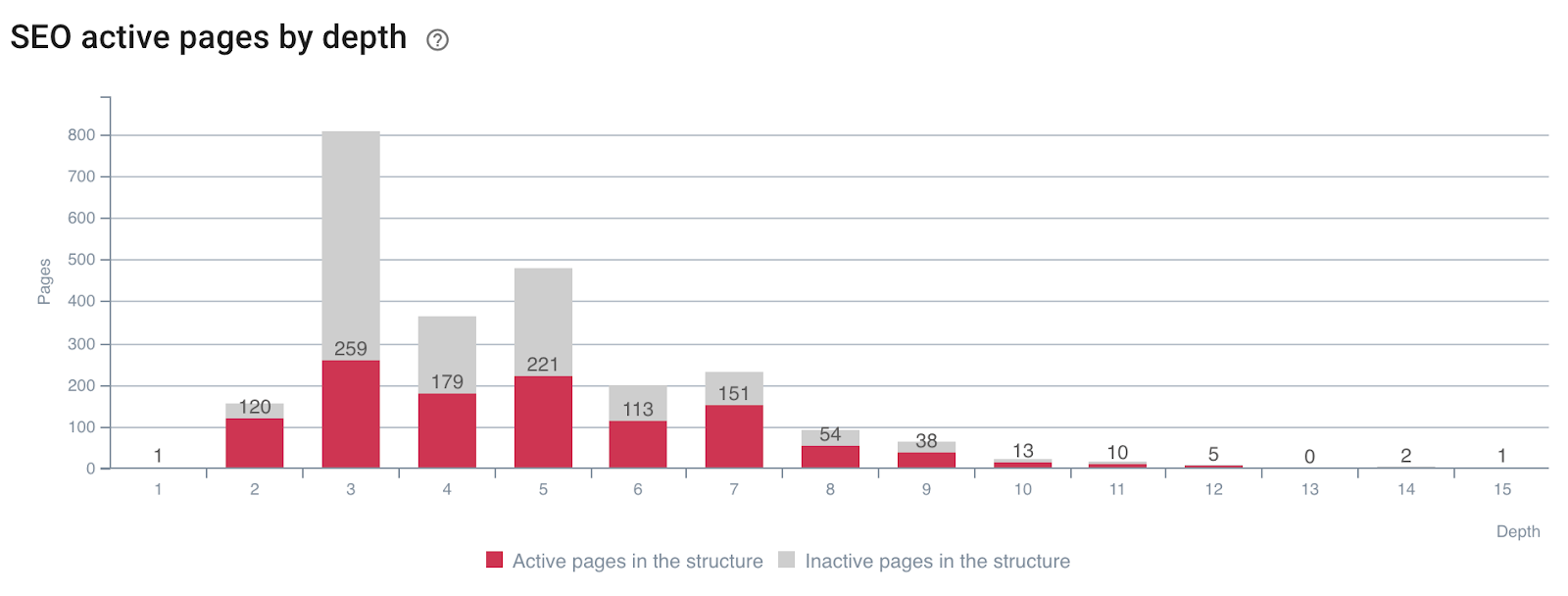
Pages générant des visites SEO (ou non) par profondeur
Vous pouvez voir qu'avoir les bonnes métriques de site lors d'un crawl et croiser les données des logs vous permet de détecter immédiatement quelles optimisations SEO sont nécessaires pour manipuler le crawl de Google et améliorer vos visites SEO.
5# Déterminez comment les facteurs de classement SEO influencent votre fréquence de crawl
Imaginez si vous pouviez savoir quelles valeurs cibler pour maximiser votre référencement ? C'est à cela que sert l'analyse croisée des données ! Il vous permet de déterminer précisément, pour chaque métrique, à partir de quel seuil la fréquence de crawl, le crawl rate ou l'activité sont maximisés.
Nous avons vu plus haut – sur l'exemple du nombre de mots par page et de la fréquence de crawl – qu'il existe des valeurs trigger de fréquence de crawl. Ces écarts doivent être analysés et comparés pour chaque type de page car nous recherchons des pics dans le comportement des bots ou des visites SEO.
Comme ceux présentés ci-dessous :
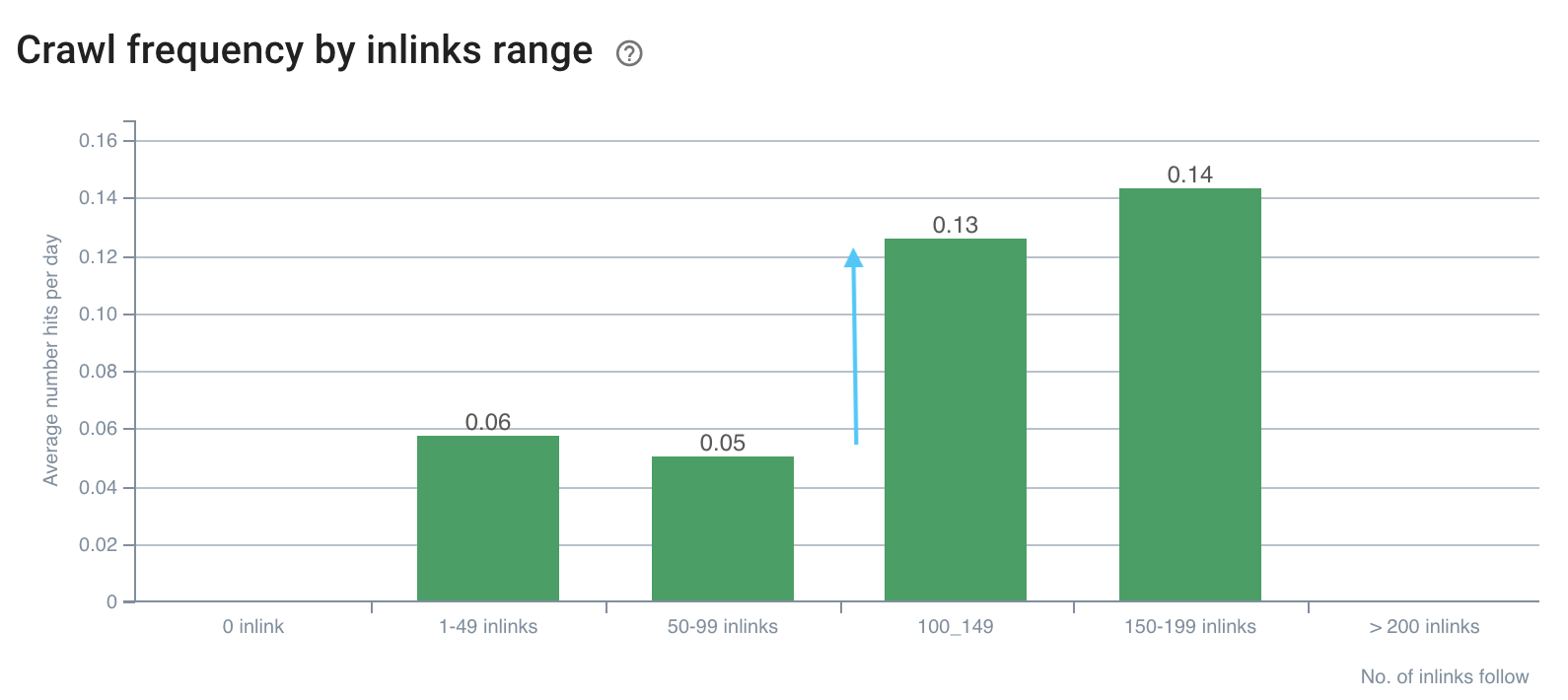
La fréquence de crawl a un écart sur plus de 100 liens entrants
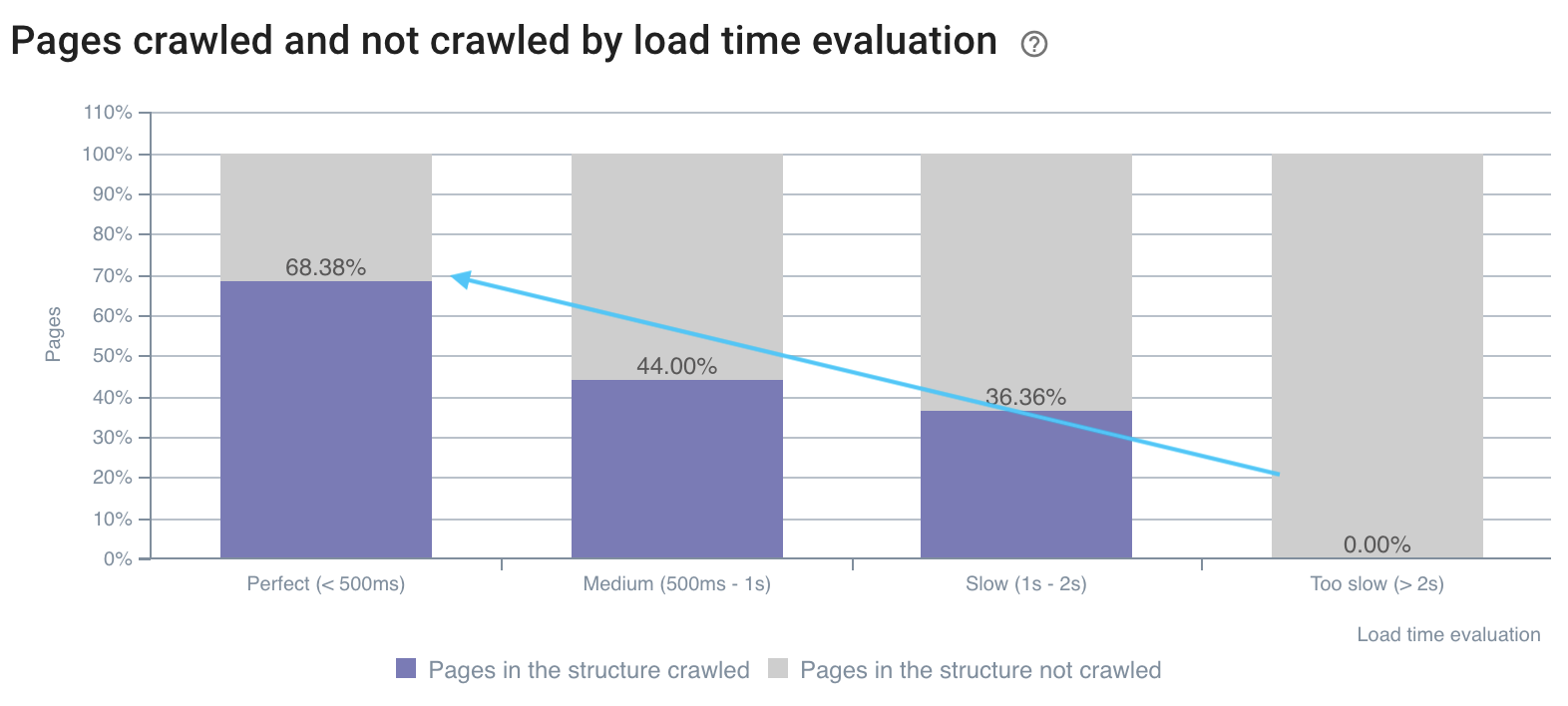
Le taux de crawl est meilleur sur les pages rapides
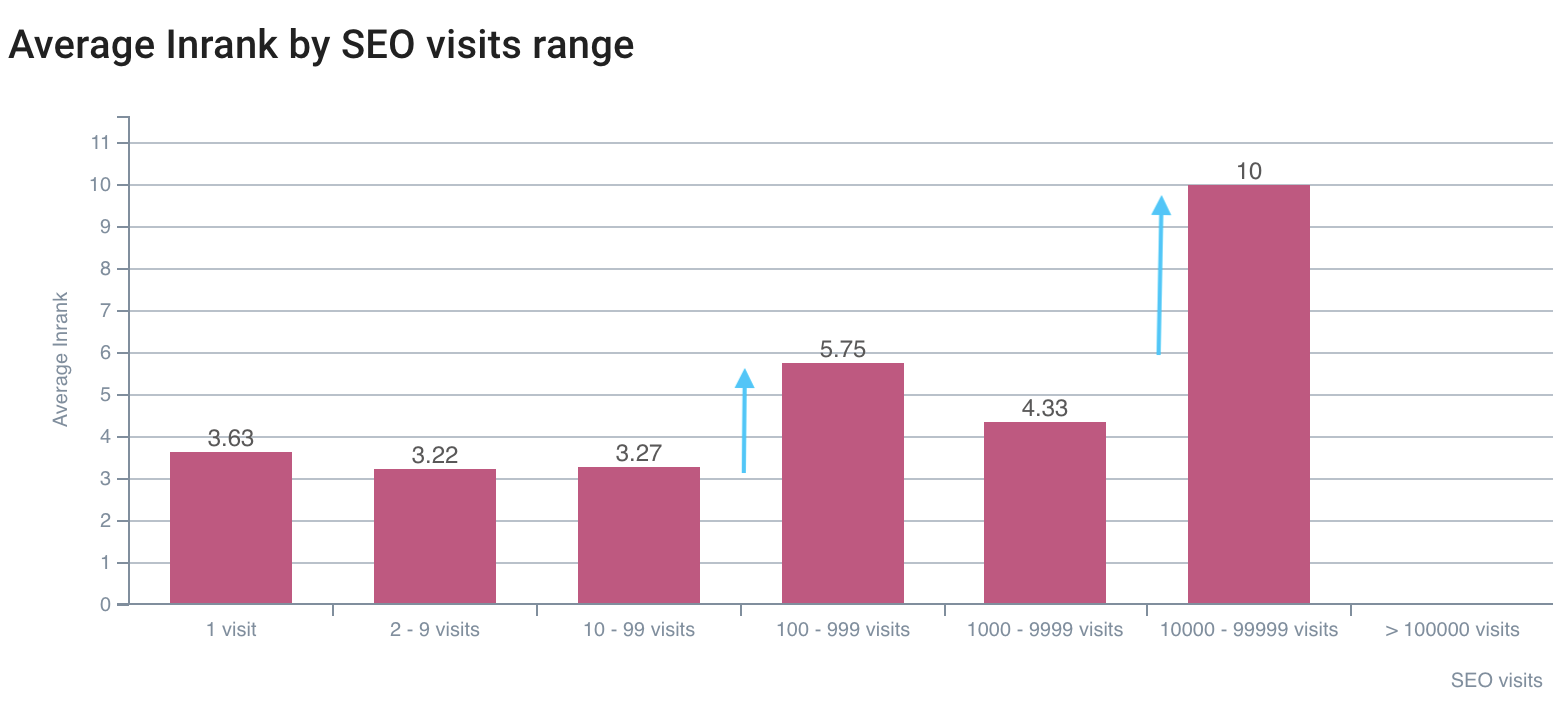
Le premier écart sur les visites SEO est sur InRank 5,75, le meilleur est sur InRank 10 (page d'accueil)
La combinaison des données de crawl et de logs vous permet d'ouvrir la boîte noire de Google et de déterminer exactement l'impact de vos métriques sur le crawl et les visites des bots. Lors de la mise en place de vos optimisations sur ces analyses, vous pouvez améliorer votre référencement au moment de chacune de vos releases. Cette utilisation avancée est pérenne dans le temps, puisque vous pouvez détecter de nouvelles valeurs à atteindre à chaque analyse de données croisées.
Avez-vous d'autres astuces avec l'analyse croisée des données que vous aimeriez partager ?