
Sitemap XML: recomendaciones clave para la optimización
Publicado: 2021-03-26El Sitemap.xml en su sitio puede actuar como una buena navegación para las páginas que desea que Google bot indexe. Te ayuda a encontrar tus páginas principales más rápido, incluso si no tienes un buen enlace interno.
En este artículo, presentaremos varias recomendaciones para la optimización de XML Sitemap y por qué es bueno hacerlo.
Funcionalidades y ventajas
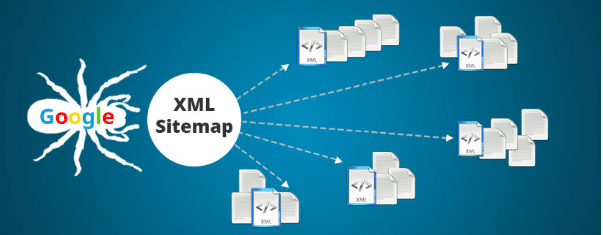
Facilite el trabajo de los bots y permita la posibilidad de obtener "informes" de páginas y enlaces en su sitio que no se pueden encontrar fácilmente.
Algunos de los beneficios de SEO son los siguientes:
- indexación más rápida: los motores de búsqueda encontrarán nuevas páginas mucho más rápido, por lo que el proceso de indexación y visualización del sitio web en los resultados de búsqueda será más rápido. Lo peculiar aquí es que también te puede ayudar con la desindexación (más información aquí);
- mejor indexación de las páginas internas: los motores de búsqueda pueden encontrar páginas que no se encontraron al rastrear el sitio web. Pero esto no significa necesariamente que todos serán indexados.
- seguimiento de páginas indexadas. En combinación con Google Search Console, puede averiguar qué URL están incluidas en el mapa del sitio XML que indexa Google.
¿Es importante un Sitemap XML?
Es importante para los sitios que:
- no tienen una buena estructura o no tienen una buena distribución de enlaces internos;
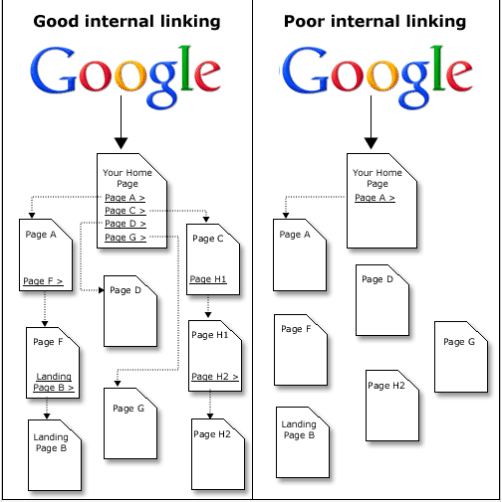
- tener muchas páginas: el mapa del sitio XML ayuda a los motores de búsqueda a encontrar páginas nuevas o actualizadas;
- no tenga muchos enlaces entrantes; esta será una excelente manera de encontrar sus páginas.
Requisitos y formatos
Google admite varios formatos de Sitemap. Todos los formatos y estándares se pueden encontrar en esta dirección: https://www.sitemaps.org/index.html.
Todos los formatos limitan el mapa del sitio a 50 MB (sin comprimir) y 50 000 direcciones. Si tiene un archivo más grande o más direcciones, deberá crear un archivo de índice con todos los mapas (descrito en el artículo a continuación).
Las principales recomendaciones son:
- el archivo debe estar codificado con UTF-8;
- debe comenzar con una etiqueta abierta y terminar con una etiqueta cerrada como …. ;
- especificar el protocolo estándar en la etiqueta;
- etiqueta principal para cada entrada de URL;
- especifique la URL que comienza con el protocolo (https o http) en la etiqueta, que debe participar en la etiqueta principal para guardar.
Atributos opcionales adicionales para mapas de sitio XML
Google no utiliza el atributo en sus sitios. Todos los demás atributos están disponibles, pero depende de si se reflejarán. Por lo tanto, tenga en cuenta que Google no se toma muy en serio estas etiquetas. Están:
- – representa la fecha del último cambio de archivo. Debe estar en formato de fecha y hora W3C;
- – con qué frecuencia es probable que se actualice la página. Este valor proporciona información general sobre los motores de búsqueda. Los valores válidos pueden ser siempre, cada hora, diario, semanal, mensual, anual, nunca.
Debe tenerse en cuenta que el valor de esta etiqueta se considera más como una pista que como un comando. Los robots ven esta información y la tienen en cuenta, pero finalmente deciden por sí mismos si la usan, dependiendo de muchos otros factores.
- – Prioriza la URL sobre otras URL en su sitio. Los valores válidos van desde 0.0. a 1.0.
Aquí nuevamente, debe tenerse en cuenta que esta prioridad es relativa y no es una condición obligatoria para los robots, o al menos aún no aceptada como tal. Sin embargo, si decide intentarlo, use la siguiente guía:
- 0 – 0,3: Noticias desactualizadas, información que ya no es válida, pero es históricamente útil;
- 4 – 0,7: artículos de blog, categorías de páginas, preguntas frecuentes;
- 8 – 1.0: Página de inicio, páginas de productos, todas las páginas con contenido bien optimizado.
El siguiente ejemplo muestra un mapa del sitio que contiene solo una URL y utiliza todas las etiquetas opcionales que están escritas en cursiva .
https://netpeak.bg
2018-09-15
mensual
0.8
Identificación de las páginas importantes
Agregue páginas de alta calidad y que estén bien optimizadas. La calidad general es de gran importancia para una mejor clasificación. Este es un factor serio para Google que puede darle una prioridad seria sobre la competencia.
No queremos visitar páginas de baja calidad, tampoco los bots de Google. Si lo guía a miles de páginas que no son útiles para los usuarios y no están bien optimizadas, esto solo puede ser perjudicial para usted. ¿Qué son las páginas de alta calidad? En pocas palabras, esas son páginas que:
- tener suficiente contenido único;
- involucrar rápidamente a sus usuarios incitando a la acción (comentarios, reseñas, etc.);
- incluir imágenes, videos, etc.;
- no violar las políticas de Google;
Páginas abiertas para indexación
El presupuesto de rastreo generalmente representa la cantidad de páginas rastreadas por unidad de tiempo (día, semana, mes, etc.). Por lo tanto, no es recomendable desperdiciarlo innecesariamente.
Las páginas que contienen la metaetiqueta "Noindex" no deben agregarse al mapa del sitio. seguir un orden lógico es importante para todo.
Es necesario hacer una verificación automatizada y no incluir direcciones que están cerradas para la indexación.
Se recomienda seguir estas instrucciones:
- Si la página https://example.com/category/product tiene una metaetiqueta “noindex”, no debe incluirse en el mapa XML del sitio;

- Cuando la página se cierra para la indexación a través de robots.txt, no debe incluirse en el mapa XML:
No permitir: /categoría/producto
Noindex: /categoría/producto
- Si la página está cerrada para la indexación a través de X-Robots-Tag en el encabezado HTTP, tampoco debe incluirse en el mapa XML del sitio:
HTTP/1.1 200 Aceptar
Fecha: martes, 25 de mayo de 2010 21:42:43 GMT
(…)
X-Robots-Etiqueta: noindex
(…)
Versiones canónicas de las páginas
Google considerará duplicado el acceso a una misma página a través de varias URL con contenido similar.

Debe usar el atributo "link rel canonical" para indicarle al bot cuál es la página "principal" y cuál debe rastrearse e indexarse.
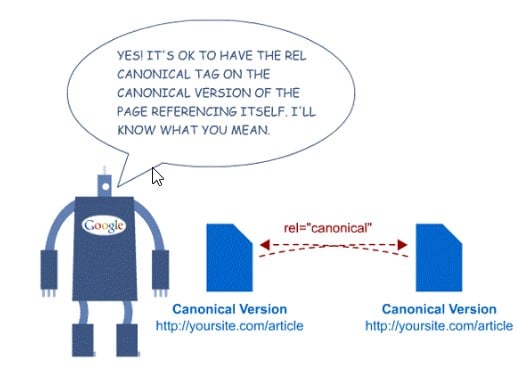
Por ejemplo, si la página https://example.com/category/product-1 tiene canonical para https://example.com/product, entonces http://example.com/category/product-1 no debe participar en el mapa del sitio XML.
Debe realizar una verificación automatizada ya que la automatización de procesos seguramente le traerá menos dolores de cabeza y le ahorrará tiempo para las inspecciones manuales.
Paginas que devuelven 200 OK
Incluya direcciones que devuelvan una respuesta 200 OK. Es importante realizar comprobaciones automáticas y no incluir direcciones que devuelvan una respuesta diferente a 200 OK, por ejemplo, 404, 301, etc.
Por ejemplo, si la página https://example.com/product devuelve una respuesta diferente a 200 OK, entonces no debería participar en el mapa del sitio.

Puede usar la siguiente herramienta para verificar: https://soft.galinov.com/ para verificar.
Páginas de paginación
No es necesario incluir absolutamente todas las páginas en sitemap.xml. El bot es lo suficientemente inteligente como para poder navegar desde la primera página en la categoría relevante si se describe correctamente. Se recomienda hacer lo siguiente:
- incluir solo las páginas principales de las categorías;
- marque las páginas con rel = next / rel = prev para que el robot pueda ver la conexión entre ellas;
- cada página de la paginación debe tener una guía canónica para sí misma, no para la página principal, porque si es al revés, significará que le estás diciendo al bot "No importa que tenga 5,000 productos y 20 páginas, ellos son los mismos que el primero.”
Por ejemplo, la página https://example.com/category/page-2 no debe participar en el mapa. Aquí puedes encontrar la opinión oficial de Google, así como sus recomendaciones:
Minimizar el tamaño del archivo
Google y Bing aumentaron el tamaño de los archivos de 10 MB a 50 MB en 2016, pero sigue siendo una buena práctica mantener su Sitemap lo más pequeño posible.

Por supuesto, no es algo de qué preocuparse, pero si su mapa del sitio contiene más de 50,000 URL o supera los 50 MB de tamaño, debe dividirse en más mapas XML. En este caso, las referencias a todos los mapas XML deben describirse en un archivo de índice de mapa de sitio separado.
¿Qué es un archivo de índice de mapa de sitio XML?
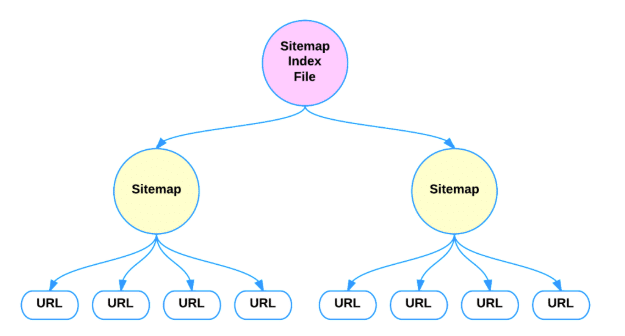
Puede enviar varios archivos de Sitemap, pero cada archivo debe cumplir con las reglas anteriores. Si lo desea, puede comprimir los archivos con gzip para reducir su tamaño según los requisitos.
El formato XML del archivo de índice es muy similar al formato de mapa de sitio normal. Debe contener:
- abrir y cerrar la etiqueta como;
- una entrada para cada Sitemap con el principal atributo XML siendo ;
- etiqueta al atributo principal.
También se incluye el atributo recomendado.
Nota: el archivo de índice del mapa del sitio solo puede enumerar mapas que se encuentran en el mismo sitio. Por ejemplo:
https://example.com/sitemap_index.xml puede incluir mapas en https://example.com, pero no en https://www.saitprimer.com o https://www.example.com
Al igual que con todos los demás archivos, el archivo de índice debe estar codificado con UTF-8.
El siguiente ejemplo muestra un índice de Sitemap que enumera dos mapas:
http://www.ejemplo.com/sitemap1.xml.gz
2018-10-01T18:23:17+00:00
http://www.ejemplo.com/sitemap2.xml.gz
2017-01-01
Descripción de la versión móvil
Necesitamos ayudar al bot de Google a encontrar nuestro contenido y comprender la conexión entre las páginas de escritorio y móviles. En el mapa del sitio XML se debe agregar el atributo rel = “alternate” para las páginas de la versión de escritorio, de la siguiente manera:
xmlns:xhtml=”http://www.w3.org/1999/xhtml”>
http://www.ejemplo.com/pagina-1/
<xhtml:enlace
rel=”alternativo”
media = "solo pantalla y (ancho máximo: 640px)"
href=”http://m.ejemplo.com/pagina-1″ />
Tenga en cuenta que cada página de escritorio debe corresponder a una página de la versión móvil. No se recomienda, por ejemplo, vincular varias páginas de escritorio mediante rel = “alternate” a una página de la versión móvil y viceversa.
También debe comprobar si hay redireccionamientos. Es importante que la página de escritorio corresponda al mismo contenido en la versión móvil, y que no redireccione a otra. Información adicional aquí.
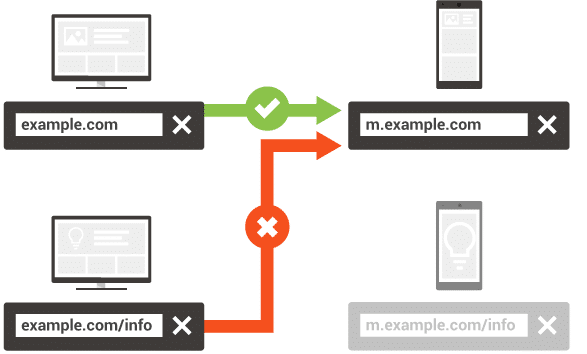
Cómo los bots pueden encontrar su Sitemap XML
Cuando haya terminado toda la automatización del proceso y lo haya subido a su servidor (o lo haya generado mediante un complemento), debe dejar una pista de dónde pueden encontrarlo los bots.
La mejor manera es incluir un enlace en su archivo robots.txt. Esto también se llama Sitemap Discovery y es algo que Google, Bing y Yahoo introdujeron en 2007 para ayudar a sus robots a encontrar XML Sitemaps.
Todo lo que tiene que hacer es incluir la ruta completa a su mapa o archivo de índice.

Transliteración correcta de direcciones
La documentación oficial de Google (Crear y enviar un mapa del sitio) enfatiza que todos los valores de datos (incluidas las URL) deben contener solo caracteres ASCII. No puede contener códigos de control o caracteres especiales como * o {}.
Si la URL de su sitio contiene estos caracteres, obtendrá un error cuando intente agregarlo.
Envía tu mapa a Google
Puede enviar su mapa del sitio a Google a través de Google Search Console.
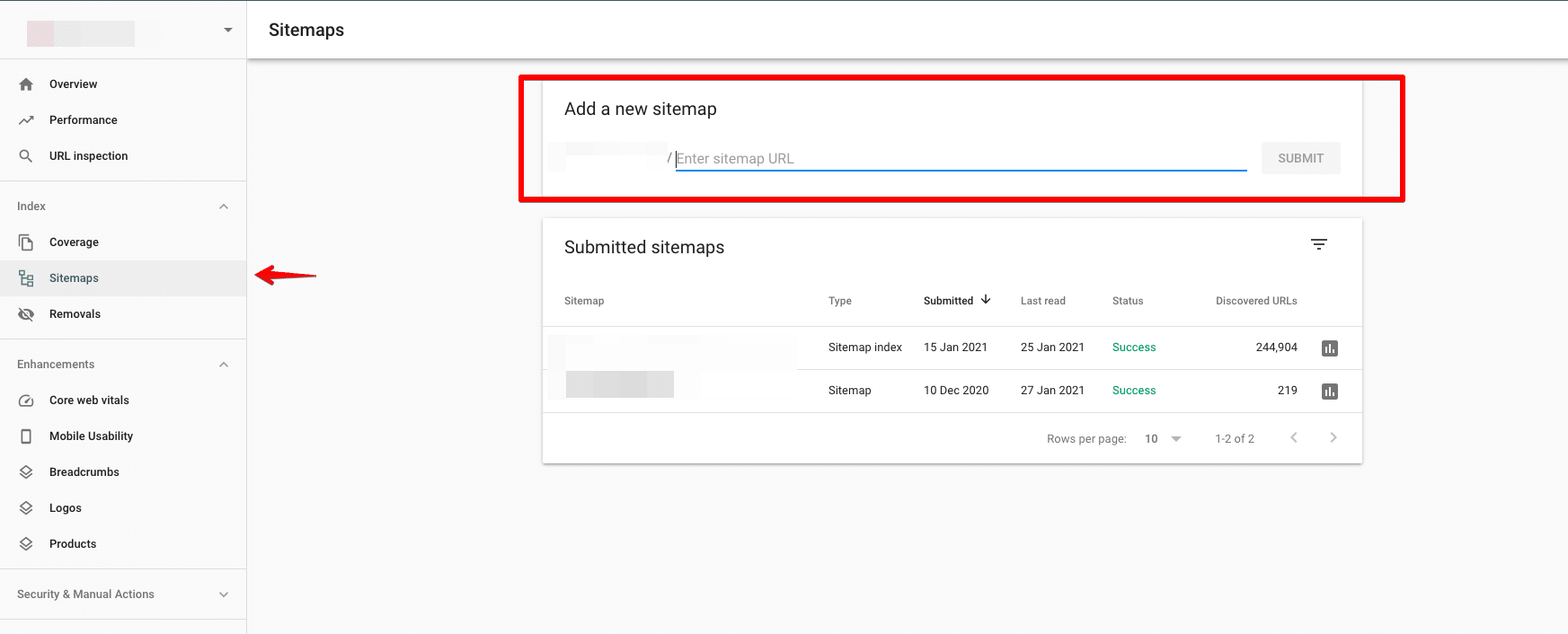
Compruebe si hay errores antes de enviar. Es importante aclarar cualquier error que pueda ser un obstáculo para indexar páginas de destino clave.
Idealmente, el número de páginas indexadas debería ser igual al número de páginas enviadas.
Conclusión
- Sea coherente: si la página está bloqueada por robots.txt o por “noindex”, es mejor que no esté en su mapa XML.
- Automatice su proceso: todas las recomendaciones anteriores deberían estar disponibles para la automatización, ya que esto le ahorrará tiempo, ayudará a que el presupuesto de rastreo se mantenga optimizado y también le ahorrará muchos dolores de cabeza.
- Si tiene un sitio muy grande, use un archivo de índice con diferentes mapas que le ahorrará tiempo de servidor y cubrirá todas las páginas importantes de su sitio.