
¿Qué es la indexación semántica latente y cómo funciona?
Publicado: 2020-04-02La indexación semántica latente (LSI) ha sido motivo de debate durante mucho tiempo entre los especialistas en marketing de búsqueda. Busque en Google el término 'indexación semántica latente' y encontrará defensores y escépticos en igual medida. No existe un consenso claro sobre los beneficios de considerar LSI en el contexto del marketing de motores de búsqueda. Si no está familiarizado con el concepto, este artículo resumirá el debate sobre LSI, para que pueda comprender lo que significa para su estrategia de SEO.
¿Qué es la indexación semántica latente?
LSI es un proceso que se encuentra en el procesamiento del lenguaje natural (NLP). NLP es un subconjunto de la lingüística y la ingeniería de la información, con un enfoque en cómo las máquinas interpretan el lenguaje humano. Una parte clave de este estudio es la semántica distribucional. Este modelo nos ayuda a comprender y clasificar palabras con significados contextuales similares dentro de grandes conjuntos de datos.
Desarrollado en la década de 1980, LSI utiliza un método matemático que hace que la recuperación de información sea más precisa. Este método funciona mediante la identificación de las relaciones contextuales ocultas entre las palabras. Puede que te sirva desglosarlo así:
- Latente → Oculto
- Semántica → Relaciones entre palabras
- Indexación → Recuperación de información
¿Cómo funciona la indexación semántica latente?
LSI funciona utilizando la aplicación parcial de Descomposición de valor singular (SVD). SVD es una operación matemática que reduce una matriz a sus partes constituyentes para cálculos simples y eficientes.
Al analizar una cadena de palabras, LSI elimina las conjunciones, los pronombres y los verbos comunes, también conocidos como palabras vacías. Esto aísla las palabras que comprenden el 'contenido' principal de una frase. Aquí hay un ejemplo rápido de cómo podría verse esto:
![]()
Estas palabras luego se colocan en una Matriz de Documento de Término (TDM). Un TDM es una cuadrícula 2D que enumera la frecuencia con la que aparece cada palabra (o término) específico en los documentos dentro de un conjunto de datos.
Las funciones de pesaje se aplican luego al TDM. Un ejemplo sencillo es clasificar todos los documentos que contienen la palabra con un valor de 1 y todos los que no lo contienen con un valor de 0. Cuando las palabras ocurren con la misma frecuencia general en estos documentos, se denomina co-ocurrencia . A continuación, encontrará un ejemplo básico de un TDM y cómo evalúa la concurrencia en varias frases:
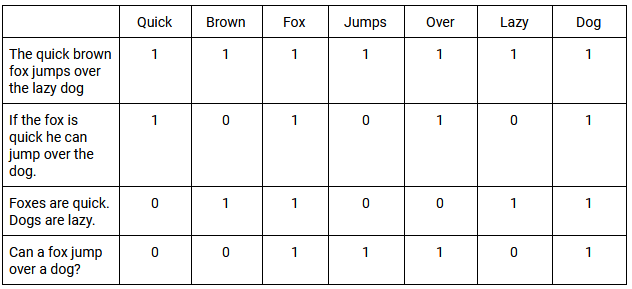
El uso de SVD nos permite aproximarnos a los patrones de uso de palabras en todos los documentos. Los vectores SVD producidos por LSI predicen el significado con mayor precisión que el análisis de términos individuales. En última instancia, LSI puede usar las relaciones entre palabras para comprender mejor su sentido o significado en un contexto específico.
[Estudio de caso] Impulsar el crecimiento en nuevos mercados con SEO en la página
 Lea el estudio de caso
Lea el estudio de caso¿Cómo se involucró la indexación semántica latente con el SEO?
En sus años de formación, Google descubrió que los motores de búsqueda clasificaban los sitios web según la frecuencia de una palabra clave en particular. Esto, sin embargo, no garantiza el resultado de búsqueda más relevante. En cambio, Google comenzó a clasificar los sitios web que consideraba árbitros de confianza de la información.
Con el tiempo, los algoritmos de Google filtrarían los sitios web irrelevantes y de baja calidad con mayor precisión. Por lo tanto, los especialistas en marketing deben comprender el significado detrás de una búsqueda, en lugar de confiar en las palabras exactas que se utilizan. Esta es la razón por la que Roger Montti describió a LSI como "ruedas de entrenamiento para motores de búsqueda" en un artículo sobre creencias obsoletas de SEO, y agregó que LSI tiene "poca o ninguna relevancia en la forma en que los motores de búsqueda clasifican los sitios web en la actualidad".
El significado de una consulta de búsqueda está estrechamente relacionado con la intención detrás de ella. Google mantiene un documento llamado Directrices del evaluador de calidad de búsqueda. En estas pautas, introducen cuatro categorías útiles para la intención del usuario:
- Know Query : representa la búsqueda de información sobre un tema. Una variante de esto es la consulta 'Conocer simple', que es cuando los usuarios buscan con una respuesta particular en mente.
- Hacer consulta : esto refleja el deseo de participar en una actividad particular, como una compra o descarga en línea. Todas estas consultas se pueden definir por un sentido de 'interacción'.
- Consulta del sitio web : esto es cuando los usuarios buscan un sitio web o una página específica. Estas búsquedas indican un conocimiento previo de un sitio web o marca en particular.
- Consulta de visita en persona : el usuario está buscando una ubicación física, como una tienda física o un restaurante.
La teoría detrás de LSI (definir el significado contextual de una palabra dentro de una frase) le dio a Google una ventaja competitiva. Sin embargo, comenzó a extenderse la idea de que las 'palabras clave LSI' eran de repente un boleto de oro para el éxito de SEO.

¿Existen realmente las 'palabras clave LSI'?
Muchas publicaciones notables siguen siendo firmes defensores de las palabras clave de LSI. Sin embargo, varias fuentes, como John Mueller, analista de tendencias para webmasters de Google, afirman que son un mito. Estas fuentes comenzaron planteando los siguientes puntos:
- LSI se desarrolló antes de la World Wide Web y no estaba destinado a aplicarse a un conjunto de datos tan grande y dinámico.
- La patente estadounidense sobre indexación semántica latente, concedida a una organización llamada Bell Communications Research Inc. en 1989, habría expirado en 2008. Por lo tanto, según Bill Slawski, Google usar LSI sería similar a "usar un dispositivo de telégrafo inteligente para conectarse a la web móvil.'
- Google utiliza RankBrain, un método de aprendizaje automático que transforma volúmenes de texto en "vectores", entidades matemáticas que ayudan a las computadoras a comprender el lenguaje escrito. RankBrain acomoda la web como un conjunto de datos en constante expansión, lo que la hace utilizable por Google, a diferencia de LSI.
En última instancia, LSI revela una verdad a la que los especialistas en marketing deben adherirse: explorar el contexto único de una palabra nos ayuda a comprender la intención del usuario mejor que las palabras clave incluidas en el contenido. Sin embargo, esto no necesariamente confirma que las posiciones de Google se basen en LSI. Por lo tanto, ¿sería seguro decir que LSI funciona en SEO como una filosofía, en lugar de una ciencia exacta?
Volvamos a la cita de Roger Montti sobre LSI como "ruedas de entrenamiento para motores de búsqueda". Una vez que aprendes a andar en bicicleta, tiendes a quitarte las ruedas de entrenamiento. ¿Podemos suponer que en 2020, Google ya no usa ruedas de entrenamiento?
Podemos considerar la reciente actualización del algoritmo de Google. En octubre de 2019, Pandu Nayak, vicepresidente de búsqueda, anunció que Google había comenzado a usar un sistema de inteligencia artificial llamado BERT (Representaciones de codificador bidireccional de transformadores). Esta es una de las mayores actualizaciones de Google de los últimos años, que afecta a más del 10 % de todas las consultas de búsqueda.
Al analizar una consulta de búsqueda, BERT considera una sola palabra en relación con todas las palabras de esa frase en particular. Este análisis es bidireccional, ya que considera todas las palabras antes o después de una palabra específica. La eliminación de una sola palabra podría afectar drásticamente la forma en que BERT entiende el contexto único de una frase.
Esto marca un contraste con LSI, que omite cualquier palabra vacía de su análisis. El siguiente ejemplo muestra cómo la eliminación de palabras vacías puede alterar la forma en que entendemos una frase:
![]()
A pesar de ser una palabra vacía, 'encontrar' es el quid de la búsqueda, que definiríamos como una consulta de 'visita en persona'.
Entonces, ¿qué deben hacer los especialistas en marketing?
Inicialmente, se pensó que LSI podía ayudar a Google a relacionar contenido con consultas relevantes. Sin embargo, parece que el debate en marketing en torno al uso de LSI aún no ha llegado a una sola conclusión. A pesar de esto, los especialistas en marketing aún pueden tomar muchas medidas para garantizar que su trabajo siga siendo estratégicamente relevante.
En primer lugar, los artículos, la copia web y las campañas pagas deben optimizarse para incluir sinónimos y variantes. Esto explica las formas en que las personas con intenciones similares usan el lenguaje de manera diferente.
Los especialistas en marketing deben continuar escribiendo con autoridad y claridad. Esta es una necesidad absoluta si quieren que su contenido resuelva un problema específico. Este problema podría ser la falta de información o la necesidad de un determinado producto o servicio. Una vez que los especialistas en marketing hacen esto, demuestra que realmente comprenden la intención del usuario.
Finalmente, también deben hacer un uso frecuente de datos estructurados. Ya sea un sitio web, una receta o una pregunta frecuente, los datos estructurados brindan el contexto para que Google comprenda lo que está rastreando.