
[Resumen del seminario web] SEO en órbita: nuevas perspectivas sobre el contenido duplicado
Publicado: 2019-11-20El seminario web Nuevas perspectivas sobre el contenido duplicado es el episodio final de la serie SEO en órbita y se emitió el 24 de junio de 2019. En este episodio, únase al Embajador de OnCrawl Omi Sido y Alexis Sanders mientras exploran la cuestión del contenido duplicado. Abordan preguntas como: ¿Cómo afectan los factores de clasificación y las tecnologías de búsqueda en evolución la forma en que manejamos el contenido duplicado? Y: ¿Qué depara el futuro para contenido similar en la web?
SEO in Orbit es la primera serie de seminarios web que envía SEO al espacio. A lo largo de la serie, discutimos el presente y el futuro del SEO técnico con algunos de los mejores especialistas en SEO y enviamos sus mejores consejos al espacio el 27 de junio de 2019.
Mira la repetición aquí:
Presentando a Alexis Sanders
Alexis Sanders trabaja como gerente técnico de cuentas de SEO en Merkle. El equipo técnico de SEO garantiza la precisión, viabilidad y escalabilidad de las recomendaciones técnicas de la agencia en todos los verticales. Es colaboradora del blog de Moz y creadora del desafío TechnicalSEO.expert y del podcast SEO in the Lab.
Este episodio fue presentado por Omi Sido. Omi es un orador internacional experimentado y es conocido en la industria por su humor y su capacidad para brindar información práctica que el público puede comenzar a usar de inmediato. Desde la consultoría de SEO con algunas de las compañías de viajes y telecomunicaciones más grandes del mundo hasta la gestión interna de SEO en HostelWorld y Daily Mail, a Omi le encanta sumergirse en datos complejos y encontrar los puntos brillantes. Actualmente, Omi es técnico sénior de SEO en Canon Europa y embajador de OnCrawl.
¿Qué es el contenido duplicado?
Omi proporciona la siguiente definición de contenido duplicado:
Contenido duplicado que es similar o casi similar al contenido que se encuentra en una URL diferente en el mismo sitio web (o en uno diferente).
El mito de la penalización por contenido duplicado
No hay penalización por contenido duplicado.
Este es un problema de rendimiento. No queremos que un bot mire dos URL en particular y piense que son dos contenidos diferentes que se pueden clasificar uno al lado del otro.
Alexis compara la comprensión de un bot de su sitio web con las imágenes de Joey de 10 Things I Hate About You: es imposible que un bot encuentre una diferencia material entre las dos versiones.

Desea evitar tener dos cosas exactamente iguales que tienen que competir entre sí en una situación de clasificación en los motores de búsqueda. En su lugar, desea tener una experiencia única y consolidada que pueda clasificarse y funcionar en los motores de búsqueda.
Diferencia entre lo que ven los usuarios y los bots
Un usuario puede ver una sola URL convincente, pero un bot aún puede ver varias versiones que le parecen esencialmente iguales.
– Efecto en el presupuesto de rastreo para sitios muy grandes
Para sitios que son muy grandes, como Zillow o Walmart, el presupuesto de rastreo puede variar para diferentes páginas.
Como explicó Alexis en un artículo de 2018 basado en una presentación de Frederic Dubut en SMX East, los presupuestos se establecen en diferentes niveles, en niveles de subdominio, en diferentes niveles de servidor. Los motores de búsqueda, ya sea Google o Bing, quieren ser rastreadores educados; no quieren ralentizar el rendimiento para los usuarios reales. Siempre que perciban un cambio en el rendimiento, retrocederán. Esto puede ocurrir en diferentes niveles, no solo en el nivel del sitio.
Si tiene un sitio enorme, quiere asegurarse de que está brindando la experiencia más consolidada que sea relevante para sus usuarios.
¿El contenido duplicado es un problema técnico o de contenido?
A pesar de la palabra "contenido" en "contenido duplicado", es en parte un problema técnico.
– Fuentes de duplicación – [07:50]
Hay muchos factores que pueden causar la duplicación. Incluso una lista parcial puede parecer interminable:
- Páginas repetitivas
- Sitios de ensayo
- URL HTTP frente a HTTPS
- Diferentes subdominios
- Casos diferentes
- Diferentes extensiones de archivo
- Barra diagonal
- Páginas de índice
- parámetros de URL
- facetas
- Ordena
- Version para imprimir
- página de entrada
- Inventario
- contenido sindicado
- comunicados de prensa
- Volver a publicar contenido
- contenido plagiado
- contenido localizado
- Contenido delgado
- Solo-imágenes
- Búsqueda interna del sitio
- Sitio móvil separado
- Contenido no único
- …
– Distribución de problemas entre SEO técnico y contenido
De hecho, estas fuentes de contenido duplicado se pueden dividir en fuentes técnicas y de desarrollo y fuentes basadas en contenido, y algunas que caen en una zona superpuesta entre las dos.
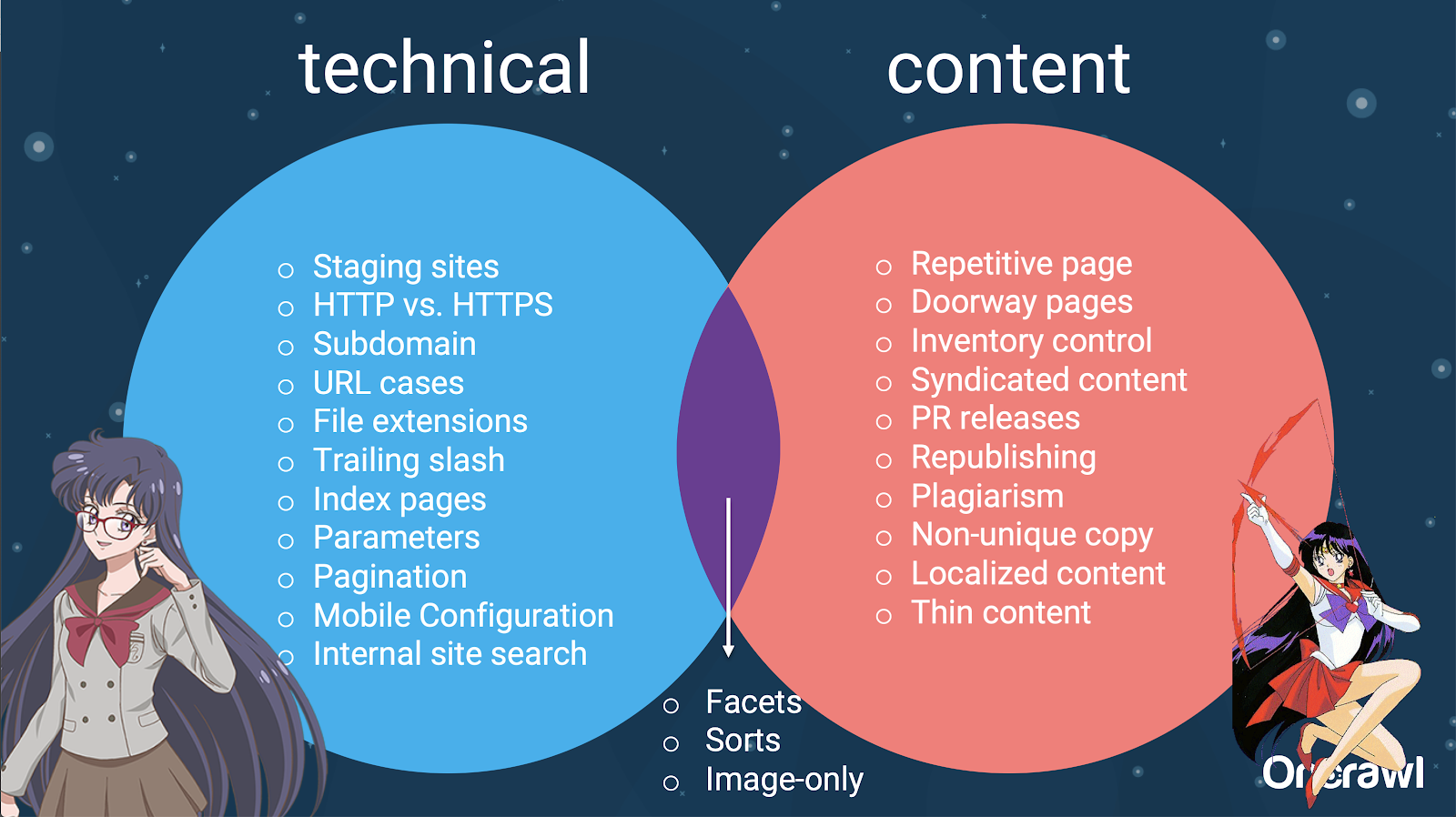
Esto hace que el contenido duplicado sea un problema entre equipos, que es parte de lo que lo hace tan interesante.
Cómo encontrar contenido duplicado
La mayoría del contenido duplicado no es intencional. Para Omi, esto indica que existe una responsabilidad compartida entre el contenido y los equipos técnicos para encontrar y reparar el contenido duplicado.
– La herramienta favorita de Omi: Grammarly
Grammarly es la herramienta favorita de Omi para encontrar contenido duplicado, y ni siquiera es una herramienta de SEO. Utiliza el verificador de plagio. Le pide al editor de contenido que verifique si ya se ha publicado una nueva pieza de contenido en otro lugar.
– Volumen de contenido duplicado no intencional
El problema del contenido duplicado no intencional es uno con el que los ingenieros están muy familiarizados. En un libro llamado Introducción a la recuperación de información (2008), que claramente está muy desactualizado, estimaron que alrededor del 40% de la web en ese momento estaba duplicada.

– Priorizar estrategias para tratar con contenido duplicado
Para lidiar con el contenido duplicado, debe:
- Comience por conocer su viaje de usuario, lo que lo ayudará a comprender dónde encaja cada contenido. Esto puede ser extremadamente difícil de hacer, particularmente cuando los sitios web se crearon hace 20 años, cuando no sabíamos qué tan grandes se volverían o cómo escalarían. Saber dónde se encuentra su usuario en un punto determinado de su recorrido lo ayudará a establecer prioridades en algunos de los siguientes pasos.
- Necesitará una jerarquía que funcione para proporcionar un lugar para cada tipo de contenido. Comprender su arquitectura de información es muy importante en los pasos para lidiar con contenido duplicado.
- Priorice el contenido duplicado que afecta el rendimiento. La lista parcial de fuentes anterior es demasiado larga para ser algo que pueda atacar de manera realista a todos a la vez.
- Tratar con 100% de duplicación
- Señalar contenido duplicado
- Tome decisiones estratégicas sobre cómo manejar la duplicación: consolide, cree, elimine, optimice
- Tratar con contenido robado

– Herramientas: Uso de la segmentación en OnCrawl
A Alexis le gusta mucho la capacidad de segmentar su sitio web en OnCrawl, lo que le permite sumergirse en cosas que son significativas para usted.
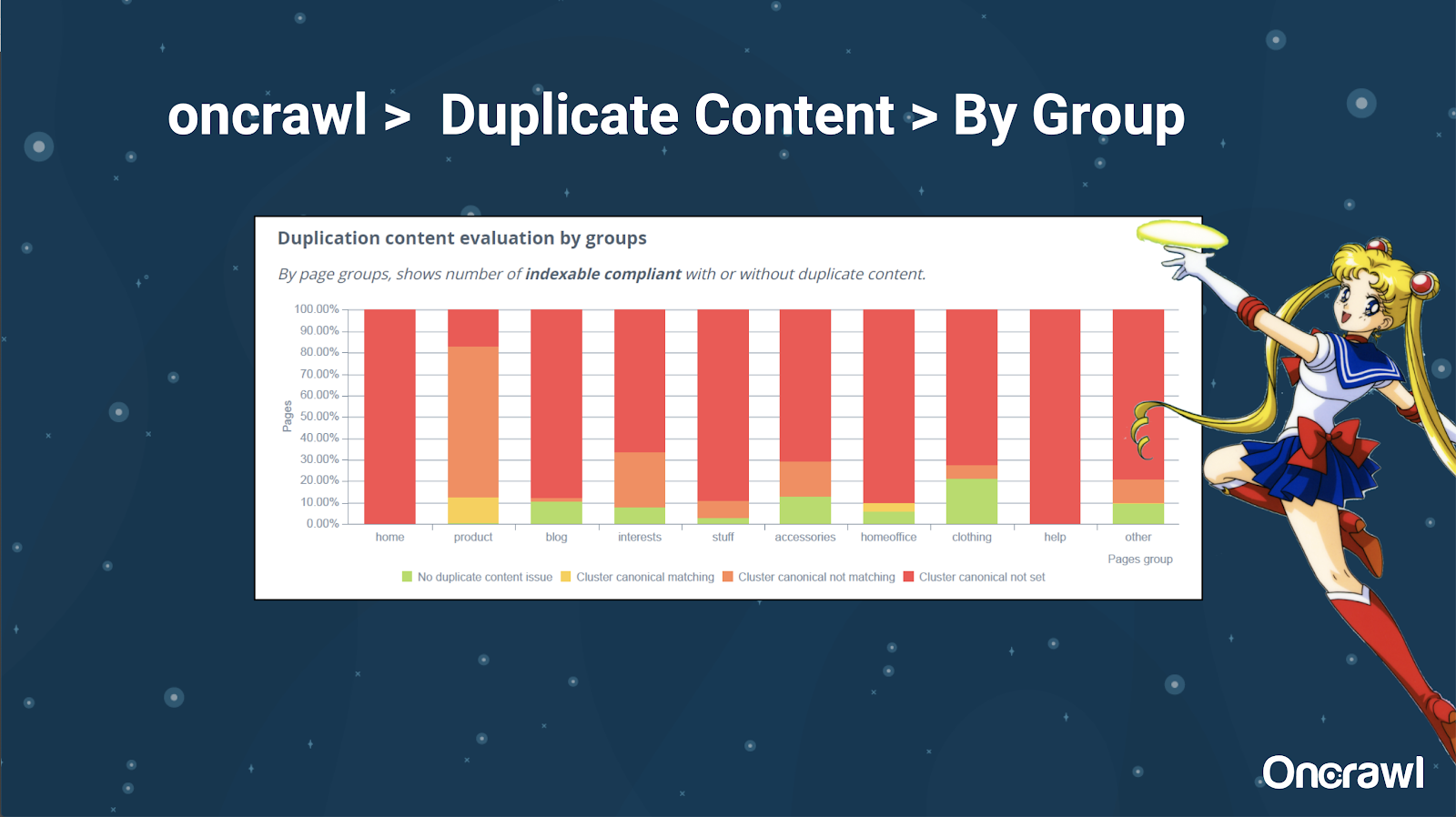
Diferentes tipos de páginas tienen diferentes cantidades de duplicación; esto permite obtener una vista de las secciones que tienen más problemas. En el ejemplo anterior, el sitio necesita mucha atención.
– Herramientas: búsqueda de Google y GSC
También puede comprobar si hay contenido duplicado utilizando el propio motor de búsqueda. En Google puedes:
- Usa citas directas
- Usar sitio: búsquedas
- Usando operadores adicionales como inurl:, intitle: o filetype:

Google Search Console también ha agregado un informe de contenido duplicado, que es muy útil para identificar lo que Google cree que es contenido duplicado por su parte.
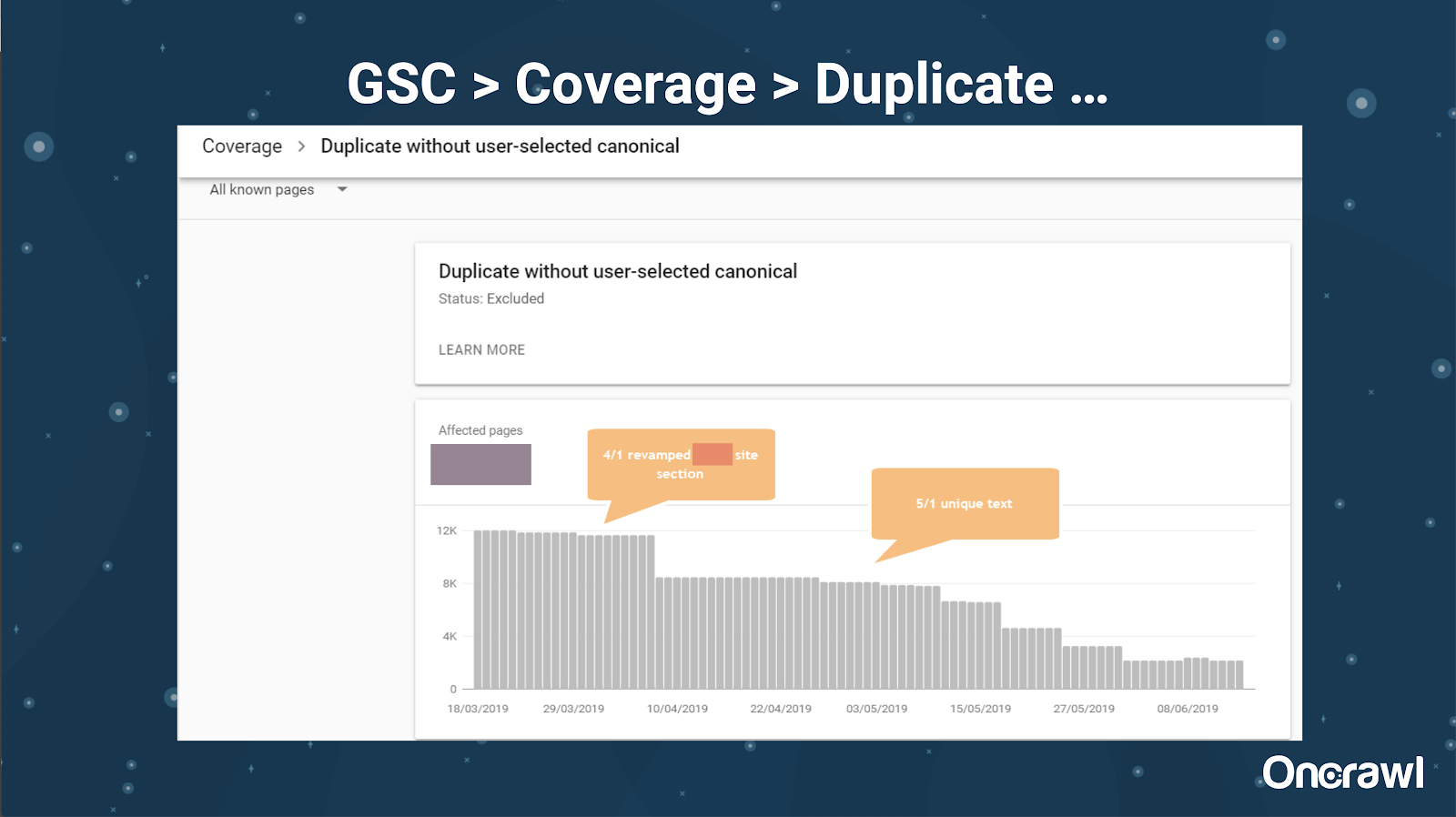
– Herramientas: herramientas de plagio
Al igual que Omi, Alexis también utiliza diferentes herramientas de plagio:
Quetexto
Sin plagas
Evaluador de papel
gramaticalmente
CopiarScape
Desea asegurarse de que su contenido no solo sea original, sino también desde la perspectiva de un bot, que no se perciba como extraído de otra fuente.
Estos también pueden ayudarlo a encontrar segmentos dentro de un artículo que podrían ser similares al contenido en otros lugares de Internet.
A Alexis le encanta que tengamos estas herramientas que nos permiten ser “empáticos con los bots de los buscadores”, ya que ninguno de nosotros somos robots. Cuando las herramientas nos dan señales de que el contenido es demasiado similar, incluso si sabemos que hay una diferencia, es una buena señal de que hay algo que investigar.

– Herramientas: herramientas de densidad de palabras clave
Dos ejemplos de herramientas de densidad de palabras clave que usa Alexis son:
etiquetamultitud
SEObook
Problemas que dependen del tipo de sitio
Resolver el contenido duplicado realmente depende del tipo de contenido que estés publicando y del tipo de problema al que te enfrentes. Los blogs no enfrentan los mismos casos de contenido duplicado que los sitios de comercio electrónico, por ejemplo.
Casos memorables
Alexis comparte casos recientes de clientes en los que encontró problemas memorables de contenido duplicado.
– Sitio enormemente grande: resultados después de agregar contenido único
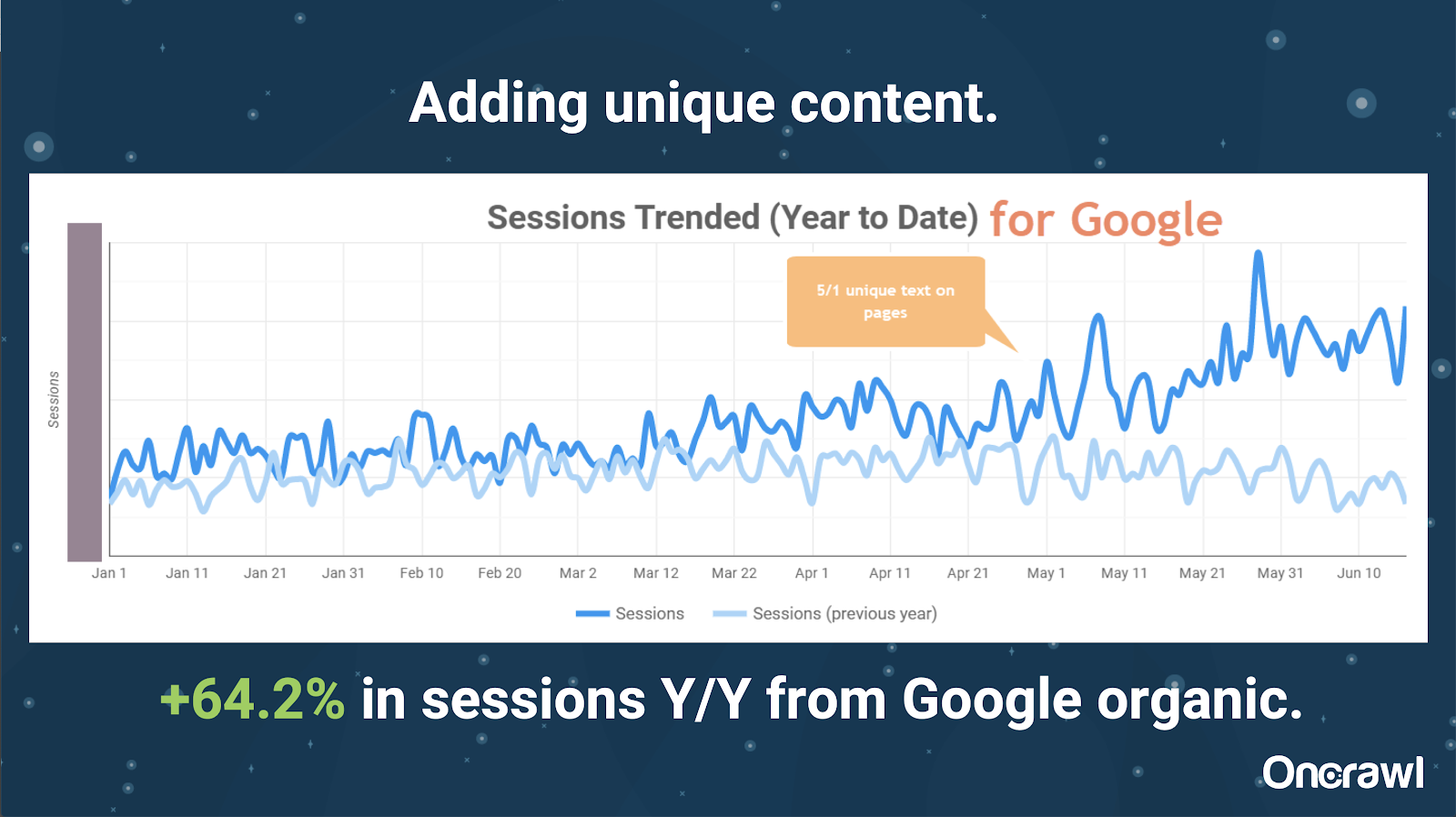
Este sitio era enormemente grande y tiene problemas de presupuesto de rastreo. Tiene 86 millones de páginas que aún no han sido indexadas, y solo alrededor del 1% de sus páginas han sido indexadas.
Este es un sitio de bienes raíces, por lo que gran parte del contenido no es particularmente único, y muchas de sus páginas son muy, muy similares. Alexis terminó agregando contenido a la página para agregar información específica de la ubicación para diferenciar las páginas. Fue sorprendente lo rápido que esto produjo resultados. (Estos son solo datos orgánicos de Google).
Para Alexis, este es un caso de estudio bastante genérico. Por mucho que hablemos hoy de EAT y cosas similares, esto demuestra que tan pronto como los motores de búsqueda ven el contenido como único y valioso, eso sigue siendo recompensado.

En este sitio, un problema de etiqueta canónica accidental provocó que unas 250 páginas se enviaran al protocolo incorrecto.
Este es un caso en el que las etiquetas canónicas indicaron la página principal incorrecta, empujando las páginas HTTP en lugar de la página HTTPS.
Cambios en los últimos 18 meses
Alexis escribió un artículo muy completo, Contenido duplicado y resolución estratégica, unos 18 meses antes de este seminario web. El SEO cambia rápidamente y necesitas renovar y reevaluar constantemente tus conocimientos.
Para Alexis, la mayor parte de lo que se menciona en el artículo sigue siendo relevante hoy en día, con la excepción de rel=next/prev. Sin embargo, espera que deje de ser relevante en los próximos cinco a diez años.
Problemas técnicos manejados por los desarrolladores: demasiado manual
Muchos de los problemas relacionados con el contenido duplicado que manejan los desarrolladores son demasiado manuales. Alexis cree que deberían ser manejados por los CMS y Adobe. Por ejemplo, no debería tener que pasar manualmente y asegurarse de que todos los canónicos estén configurados y sean coherentes.
– Oportunidades de automatización/notificación
Hay muchas oportunidades para la automatización en el área de problemas técnicos con contenido duplicado. Para dar un ejemplo: deberíamos poder detectar inmediatamente si algún enlace va a HTTP cuando debería ir a HTTPS, y corregirlo.
– La edad del sitio y la infraestructura heredada como un obstáculo
Algunos sistemas de back-end son demasiado antiguos para soportar ciertos cambios y automatizaciones. Es extremadamente difícil migrar un antiguo CMS a uno nuevo. Omi da el ejemplo de la migración de los sitios web de Canon a un nuevo CMS personalizado. No solo fue caro, sino que les tomó 12 meses.
Rel anterior/siguiente y comunicación de Google
A veces, la comunicación de Google es un poco confusa. Omi cita un ejemplo en el que, al aplicar rel=prev/next, su cliente vio un aumento significativo en el rendimiento en 2018, a pesar del anuncio de Google en 2019 de que estas etiquetas no se han utilizado durante años.
– Falta de soluciones únicas para todos
La dificultad con el SEO es que lo que una persona observa que sucede en su sitio web no es necesariamente lo mismo que lo que otro SEO ve en su propio sitio web; no existe un SEO único para todos.
La capacidad de Google para hacer anuncios que son pertinentes para todos los SEO debe reconocerse como una gran hazaña, incluso algunas de sus declaraciones son un error, como en el caso de rel=next/prev.
Esperanzas para el futuro de la gestión de contenido duplicado
Las esperanzas de Alexis para el futuro:
- Menos contenido duplicado de base técnica (a medida que avanzan los CMS).
- Más automatización (pruebas unitarias y pruebas externas). Por ejemplo, herramientas como OnCrawl pueden rastrear regularmente su sitio y notificarle tan pronto como noten ciertos errores.
- Detecte automáticamente páginas y tipos de página de alta similitud para escritores y administradores de contenido. Esto automatizaría algunas de las verificaciones que actualmente se realizan manualmente en herramientas como Grammarly: cuando alguien intenta publicar, el CMS debería decir "esto es similar, ¿está seguro de que desea publicar esto?" Hay mucho valor en mirar sitios web individuales, así como en la comparación entre sitios web.
- Google continúa mejorando sus sistemas y detección existentes.
- Tal vez un sistema de alerta para escalar el problema de que Google no usa el canónico correcto. Sería útil poder alertar a Google sobre el problema y resolverlo.
Necesitamos mejores herramientas, mejores herramientas internas, pero con suerte, a medida que Google desarrolle sus sistemas, agregarán elementos para ayudarnos un poco.
Los trucos técnicos favoritos de Alexis
Alexis tiene varios trucos técnicos favoritos:
- Instancia de computadora remota EC2. Esta es una manera realmente excelente de acceder a una computadora real para rastreos muy grandes, o cualquier cosa que requiera mucha potencia informática. Es extremadamente rápido una vez que lo configuras. Solo asegúrese de terminarlo cuando haya terminado, ya que cuesta dinero.
- Verifique la primera herramienta de prueba móvil. Google ha mencionado que esta es la imagen más precisa de lo que están viendo. Mira el DOM.
- Cambia el agente de usuario a Googlebot. Esto le dará una idea de lo que realmente ven los Googlebots.
- Utilizando la herramienta robots.txt de TechnicalSEO.com. Esta es una de las herramientas de Merkle, pero a Alexis realmente le encanta porque robots.txt puede ser muy confuso a veces.
- Utilice un analizador de registros.
- Hecho con el verificador htaccess de Love.
- Usar Google Data Studio para informar sobre los cambios (sincronizar hojas con actualizaciones, filtrar cada página por actualizaciones relevantes).
Dificultades técnicas de SEO: robots.txt
Robots.txt es realmente confuso.
Es un archivo arcaico que parece que debería ser compatible con RegEx, pero no lo es.
Tiene diferentes reglas de precedencia para prohibir y permitir reglas, lo que puede resultar confuso.
Diferentes bots pueden ignorar diferentes cosas, aunque se supone que no deben hacerlo.
Tus suposiciones sobre lo que es correcto no siempre son correctas.

Preguntas y respuestas
– HSTS: ¿se requiere protocolo dividido?
Debe tener todo HTTPS para contenido duplicado si tiene HSTS.
– ¿El contenido traducido es contenido duplicado?
A menudo, cuando usa hreflang, lo usa para eliminar la ambigüedad entre versiones localizadas dentro del mismo idioma, como una página en inglés de EE. UU. e Irlanda. Alexis no consideraría este contenido duplicado, pero definitivamente recomendaría asegurarse de tener las etiquetas hreflang configuradas correctamente para indicar que esta es la misma experiencia, optimizada para diferentes audiencias.
– ¿Puede usar etiquetas canónicas en lugar de redireccionamientos 301 para una migración HTTP/HTTPS?
Sería útil verificar qué está sucediendo realmente en los SERP. El instinto de Alexis es decir que esto estaría bien, pero depende de cómo se comporte realmente Google. Idealmente, si estas son exactamente la misma página, querría usar un 301, pero ella ha visto que las etiquetas canónicas funcionan en el pasado para este tipo de migración. De hecho, incluso ha visto que esto sucedió accidentalmente.
Según la experiencia de Omi, recomendaría encarecidamente usar 301 para evitar problemas: si está migrando el sitio web, también podría migrarlo correctamente para evitar errores actuales y futuros.
– Efecto de títulos de página duplicados
Supongamos que tiene un título que es muy similar para diferentes ubicaciones, pero el contenido es muy diferente. Si bien eso no es contenido duplicado para Alexis, ella cree que los motores de búsqueda tratan esto como algo de tipo "general", y los títulos son algo que se puede usar para identificar áreas con posibles problemas.
Aquí es donde es posible que desee utilizar una búsqueda [site: + intitle:].
Sin embargo, el hecho de que tenga la misma etiqueta de título no provocará un problema de contenido duplicado.
Aún debe apuntar a títulos únicos y meta descripciones, incluso en páginas paginadas u otras páginas muy similares. Esto no se debe a contenido duplicado, sino a la forma de querer optimizar la forma en que presentas tus páginas en las SERP.
Consejo superior
“El contenido duplicado es un desafío tanto técnico como de marketing de contenido”.
SEO en órbita fue al espacio
Si te perdiste nuestro viaje al espacio el 27 de junio, míralo aquí y descubre todos los consejos que enviamos al espacio.