
Uso de Python y Sitemaps para auditar estrategias de contenido
Publicado: 2020-10-08El interés en lo que se puede hacer en nombre del SEO con Python Libraries ya no es un secreto. Sin embargo, la mayoría de las personas con poca experiencia en programación tienen dificultades para importar y usar una gran cantidad de bibliotecas o impulsar los resultados más allá de lo que cualquier rastreador común o herramienta de SEO puede hacer.
Esta es la razón por la que una biblioteca de Python creada específicamente para SEO, SEM, SMO, verificación de SERP y análisis de contenido es útil para todos.
En este artículo, veremos algunas de las cosas que se pueden hacer con la biblioteca de Python de Advertools para SEO, creada y desarrollada por Elias Dabbas, y para la cual veo un gran potencial en SEO, PPC y capacidades de codificación. en muy poco tiempo. Además, utilizaremos secuencias de comandos de Python personalizadas junto con otras bibliotecas de Python de forma educativa y adaptable.
Vamos a examinar lo que se puede aprender para SEO de un mapa del sitio gracias a la función sitemap_to_df de Elias Dabbas, que ayuda a descargar y analizar mapas del sitio XML (un mapa del sitio es un documento en formato XML que se usa para informar URL rastreables e indexables a los motores de búsqueda).
Este artículo le mostrará cómo puede escribir códigos Python personalizados para analizar diferentes sitios web de acuerdo con su estructura diferente, cómo interpretar los datos en términos de SEO y cómo pensar como un motor de búsqueda cuando se trata de perfiles de contenido, URL y estructuras de sitios. .
Análisis de la escala de contenido y la estrategia de un sitio web en función de su mapa del sitio
Un mapa del sitio es un componente de un sitio web que puede capturar muchos tipos diferentes de datos, como la frecuencia con la que un sitio web publica contenido, categorías de contenido, fechas de publicación, información del autor, tema del contenido...
En condiciones normales, puede extraer un mapa del sitio con scrapy, convertirlo en un DataFrame con Pandas e interpretarlo con muchas bibliotecas auxiliares diferentes si lo desea.
Pero en este artículo, solo usaremos Advertools y algunos métodos y atributos de la biblioteca de Pandas. Se activarán algunas bibliotecas para visualizar los datos que hemos adquirido.
Profundicemos y seleccionemos un sitio web para usar su mapa del sitio para concluir algunas ideas importantes de SEO.
Extracción y creación de marcos de datos de mapas de sitios con Advertools
En Advertools, puede descubrir, explorar y combinar todos los mapas de sitio de un sitio web con solo una línea de código.
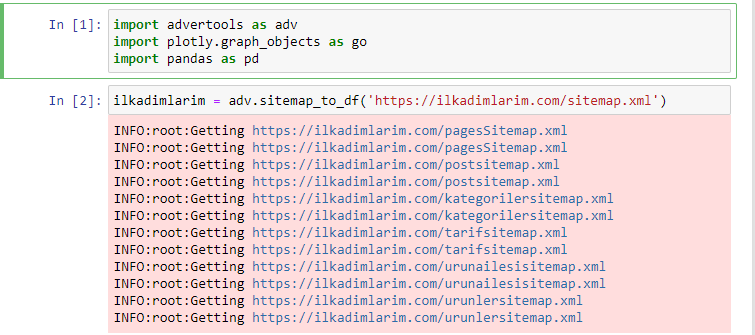
Me encanta usar Jupyter Notebook en lugar de un editor de código normal o IDE.
En la primera celda hemos importado Pandas y Advertools para recopilar y organizar datos y Plotly.graph_objects para visualizar datos.
El comando adv.sitemap_to_df('dirección del mapa del sitio') simplemente recopila todos los mapas del sitio y los unifica como un marco de datos.
Si hace lo mismo con Pandas y Advertools, puede descubrir qué URL está disponible en qué mapa del sitio.
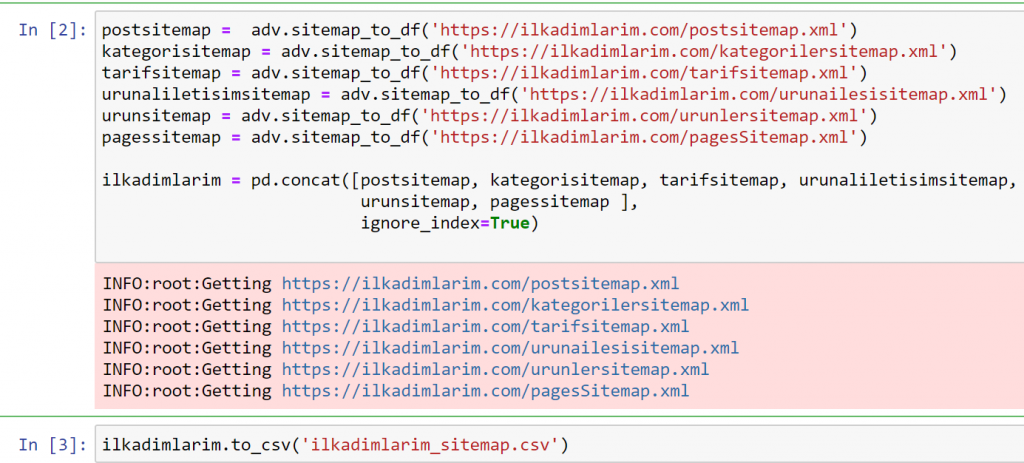
En el ejemplo anterior, extrajimos los mismos mapas de sitio por separado y luego los combinamos con el comando pd.concat y transferimos el resultado a CSV. El ejemplo anterior usó el archivo de índice del mapa del sitio, en cuyo caso la función va a recuperar todos los demás mapas del sitio. Por lo tanto, tiene la opción de seleccionar mapas de sitio específicos como lo hicimos aquí si está interesado en una sección particular del sitio web.
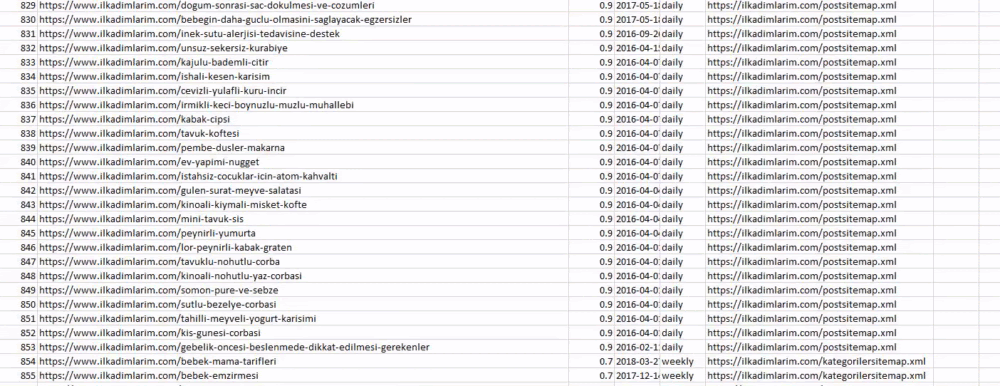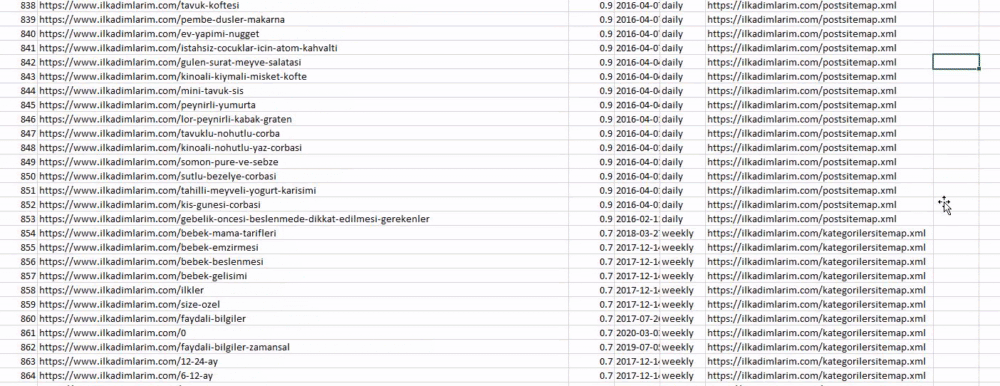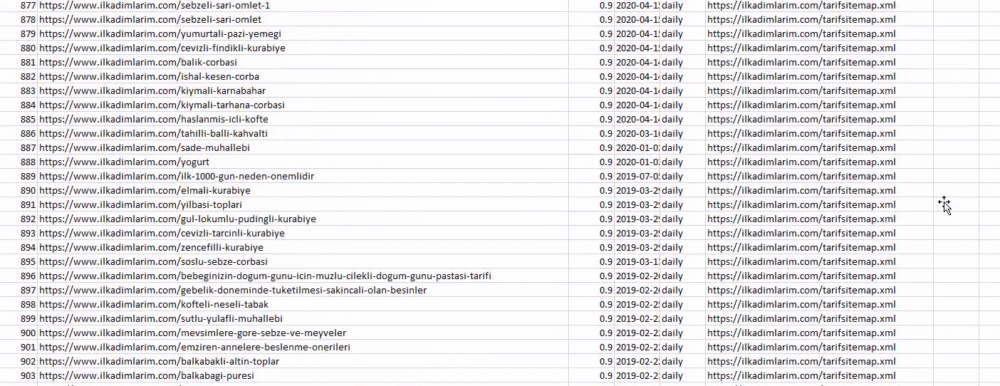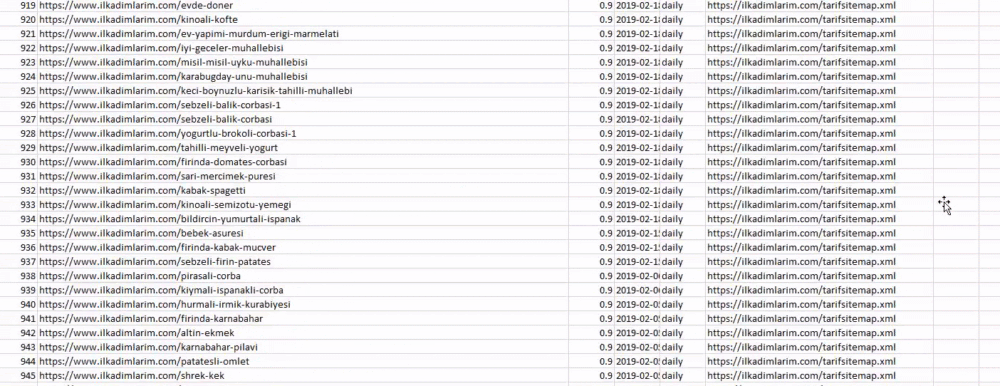
Puede ver una columna con diferentes nombres de mapas de sitios arriba. ignore_index=La sección True es para ordenar ordenadamente los números de índice de diferentes DataFrames, si ha fusionado varios juntos.
Datos de seguimiento³
 Aprende más
Aprende másLimpiar y preparar el marco de datos del mapa del sitio para el análisis de contenido con Python
Para entender el perfil de contenido de un sitio web a través de un sitemap, necesitamos prepararlo para poder revisar el DataFrame que obtuvimos con Advertools.
Usaremos algunos comandos básicos de la biblioteca de Pandas para dar forma a nuestros datos:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columnas = 'Sin nombre: 0')
ilkadimlarim['últimamodificación'] = pd.to_datetime(ilkadimlarim['últimamodificación'])
ilkadimlarim = ilkadimlarim.set_index('últimomod')
“Ilkadimlarim” significa “mis primeros pasos” en turco, y como puedes imaginar, es un sitio para bebés, embarazo y maternidad.
Hemos realizado tres operaciones con estas líneas.
- Sin nombre: Quitamos una columna vacía denominada 0 del DataFrame. Además, si usa 'index = False' con la función pd.to_csv() , no verá esta columna 'Sin nombre 0' al principio.
- Convertimos los datos de la columna Última modificación a Fecha y hora.
- Trajimos la columna "lastmod" a la posición de índice.
A continuación puede ver la versión final del DataFrame.
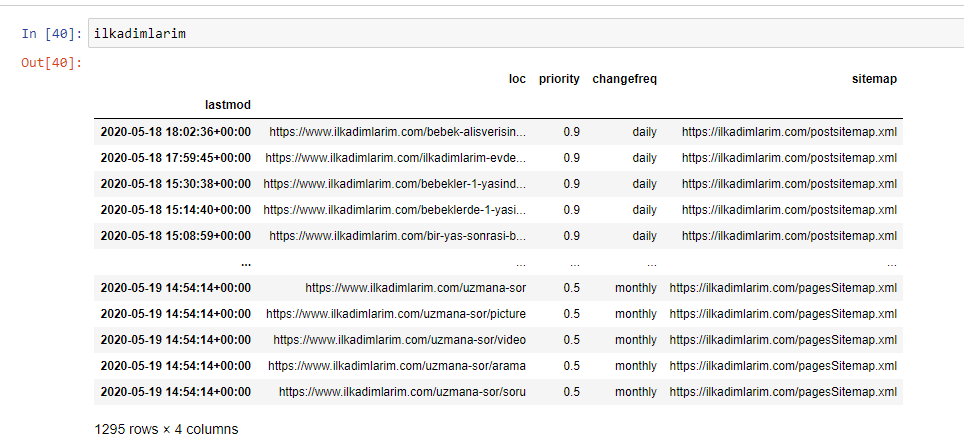
Sabemos que Google no usa la información de prioridad y frecuencia de cambios de los sitemaps. Lo llaman “una bolsa de ruido”. Pero si le da importancia al rendimiento de su sitio web para otros motores de búsqueda, puede resultarle útil examinarlos también. Personalmente, no me importan mucho estos datos, pero aún así no necesito eliminarlos del DataFrame.
Necesitamos una línea de código más para categorizar los mapas de sitio en otra columna.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
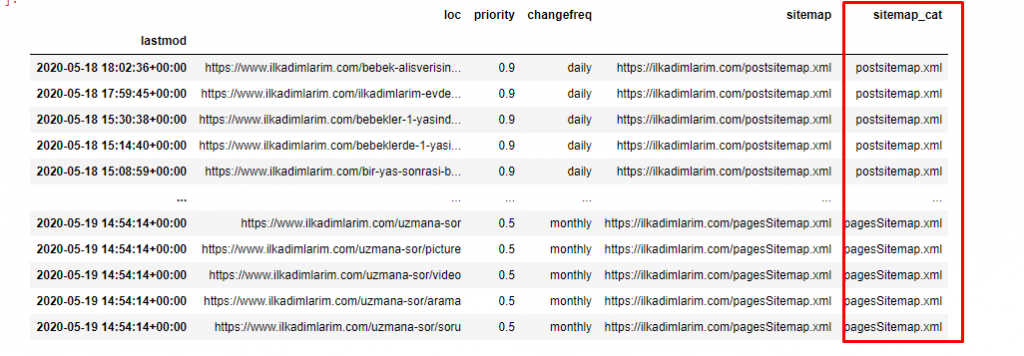
En Pandas, puede agregar nuevas columnas o filas a un DataFrame o puede actualizarlas fácilmente. Hemos creado una nueva columna con el fragmento de código DataFrame['new_columns'] . DataFrame['column_name'].str nos permite realizar diferentes operaciones cambiando el tipo de datos en una columna. Dividimos los datos de la cadena en la columna relacionada con .split ('/') por el carácter / y los ponemos en una lista. Con .str [number] , creamos el contenido de la nueva columna seleccionando un elemento particular en esa lista.
Análisis del perfil de contenido según el recuento y los tipos de mapas del sitio
Después de colocar los mapas de sitio en una columna diferente según sus tipos, podemos verificar qué % de los contenidos hay en cada mapa de sitio. Así, también podemos hacer una inferencia sobre qué parte del sitio web es más importante.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] está seleccionando la columna que queremos hacer un proceso.
- value_counts() cuenta la frecuencia de los valores en la columna.
- normalize=True toma la proporción de valores en decimal.
- Hacemos que sea más fácil de leer haciendo que los números decimales sean más grandes con *100.
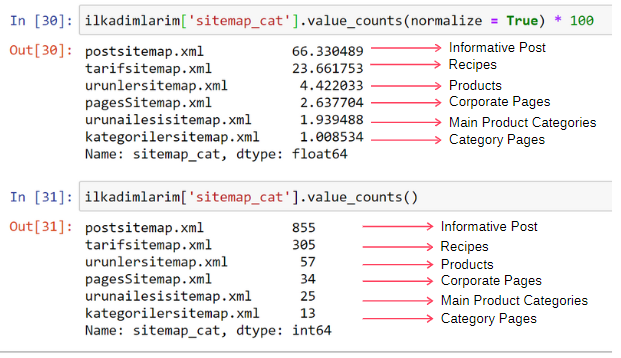
Vemos que el 65 % del contenido está en el mapa del sitio de publicaciones y el 23 % está en el mapa del sitio de recetas. El Product Sitemap tiene solo el 2% del contenido.
Esto demuestra que tenemos un sitio web que tiene que crear contenido informativo para una amplia audiencia para comercializar sus propios productos. Comprobemos si nuestra tesis es correcta.
Antes de continuar, debemos cambiar el nombre de la columna ilkadimlarim['sitemap_cat'] a 'URL_Count' con el siguiente código:
ilkadimlarim.rename(columnas={'sitemap_cat' : 'URL_Count'}, inplace=True)
- La función rename() es útil para modificar el nombre de sus columnas o índices para conectar los datos y su significado en un nivel más profundo.
- Hemos cambiado el nombre de la columna para que sea permanente gracias al atributo 'inplace=True' .
- También puede cambiar los estilos de letras de sus columnas e índices con ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . Esto escribe solo las primeras letras en mayúsculas de cada columna en Ilkadimlarim.

Ahora, podemos proceder.
Para ver esta información en un solo cuadro, puede usar el siguiente código:
(ilkadimlarim['sitemap_cat']
.value_counts()
.enmarcar()
.assign(porcentaje=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', porcentaje='{:.1%}')))
- to_frame() se usa para enmarcar los valores medidos por value_counts() en la columna seleccionada.
- asignar() se usa para agregar ciertos valores al marco.
- lambda se refiere a funciones anónimas en Python.
- Aquí, la función Lambda y los tipos de mapas del sitio se dividen por el número total del mapa del sitio mediante el método div() de Pandas.
- style() determina cómo se escriben los valores finales especificados.
- Aquí, establecemos cuántos dígitos se escriben después del punto con el método format() .
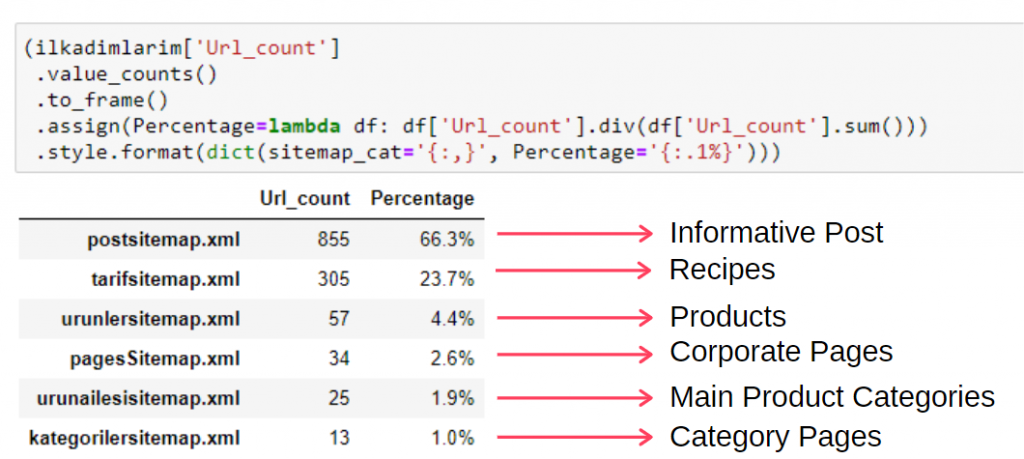
Por lo tanto, vemos la importancia del marketing de contenidos para este sitio web. También podemos consultar sus tendencias de publicación de artículos por año con dos líneas de código para examinar su situación más profundamente.
Examen y visualización de tendencias de publicación de contenido por año a través de Sitemaps y Python
Hicimos la coincidencia de contenido e intención del sitio web examinado de acuerdo con las categorías del mapa del sitio, pero aún no hemos hecho una clasificación basada en el tiempo. Usaremos el método resample() para lograr esto.
post_por_mes = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample es un método en la biblioteca de Pandas. resample('A') comprueba la serie de datos para un DataFrame anual. Durante semanas, puede usar 'W', durante meses, puede usar 'M'.
Loc aquí simboliza el índice; count significa que desea contar la suma de los ejemplos de datos.
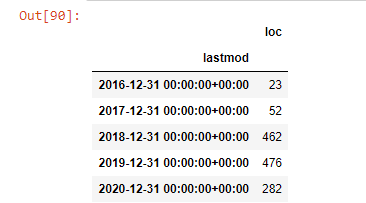
Vemos que comenzaron a publicar artículos en 2016, pero su principal tendencia de publicación aumentó después de 2017. También podemos poner esto en un gráfico con la ayuda de Plotly Graph Objects.
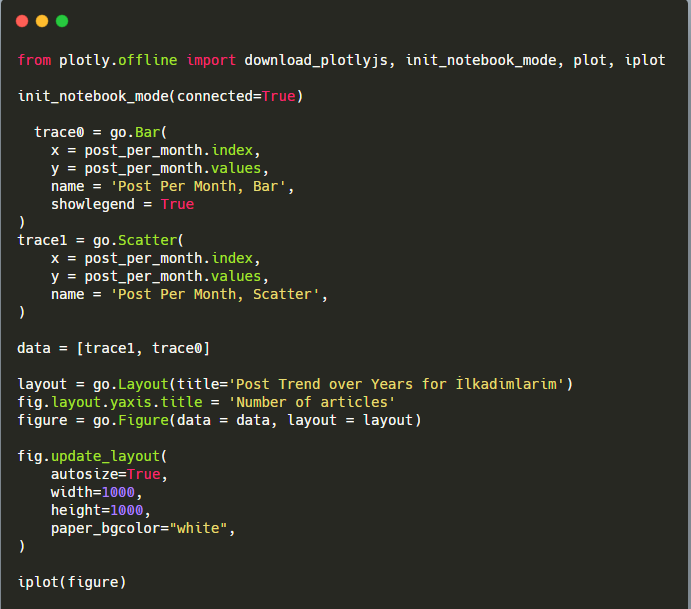
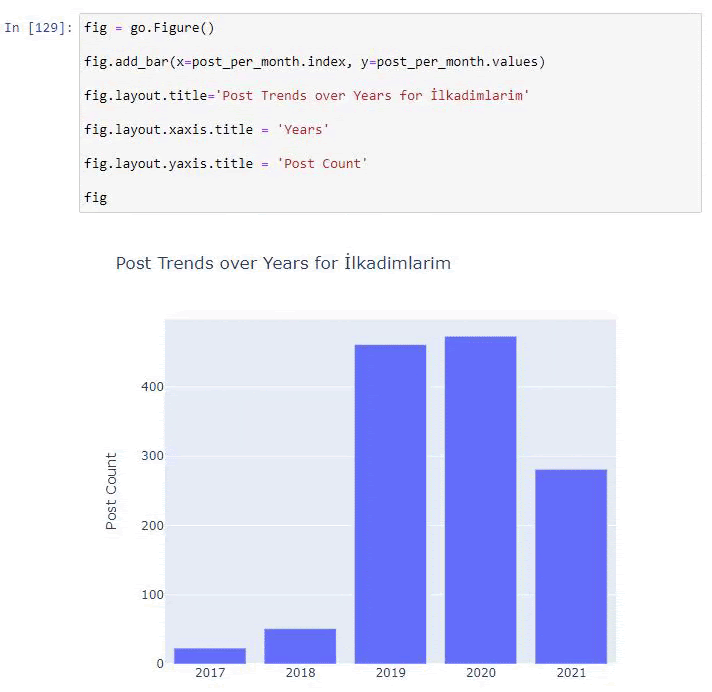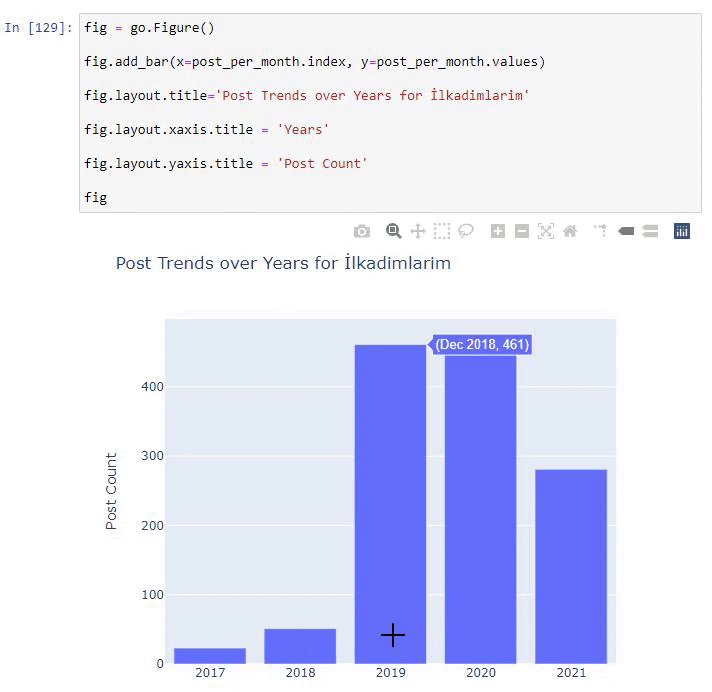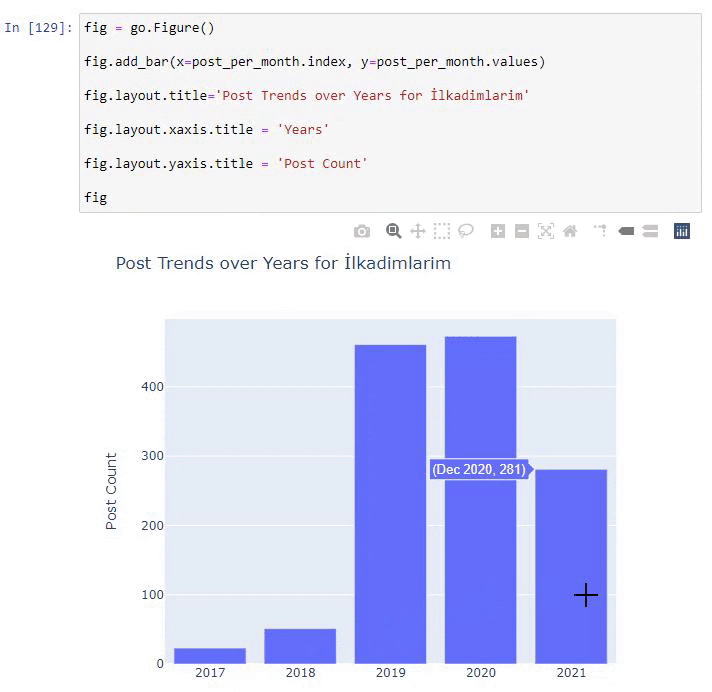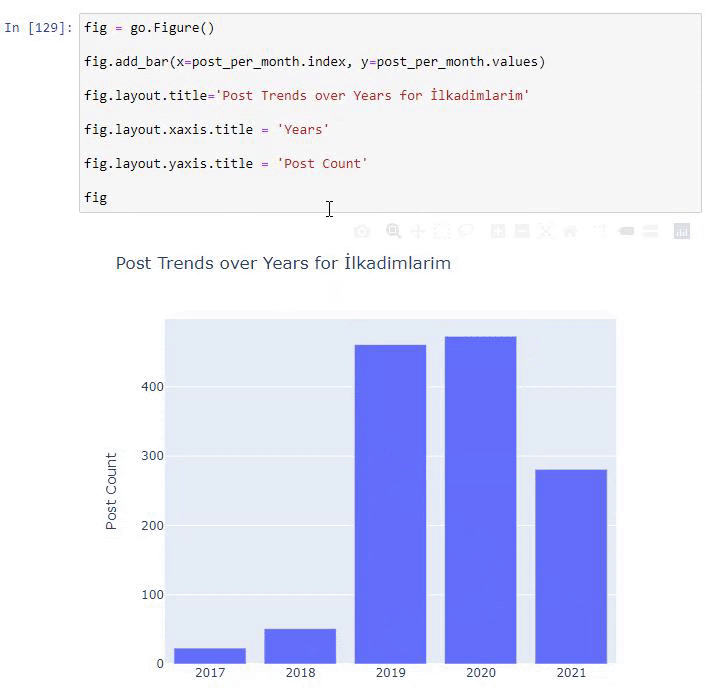
Explicación de este fragmento de código Plotly Bar Plot:
- fig = go.Figure() es para crear una figura.
- fig.add_bar() es para agregar un diagrama de barras a la figura. También determinamos qué ejes X e Y estarán dentro de los paréntesis.
- Fig.layout es para crear un título general para la figura y los ejes.
- En la última línea estamos llamando a la trama que hemos creado con el comando fig que es igual a go.Figure()
A continuación, encontrará los mismos datos por mes, con diagrama de dispersión y diagrama de barras:
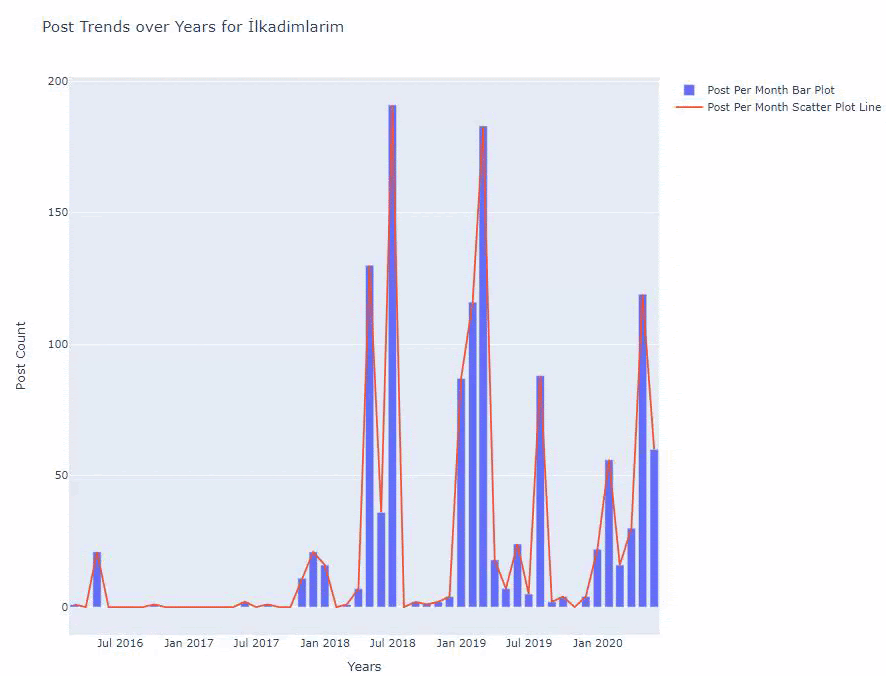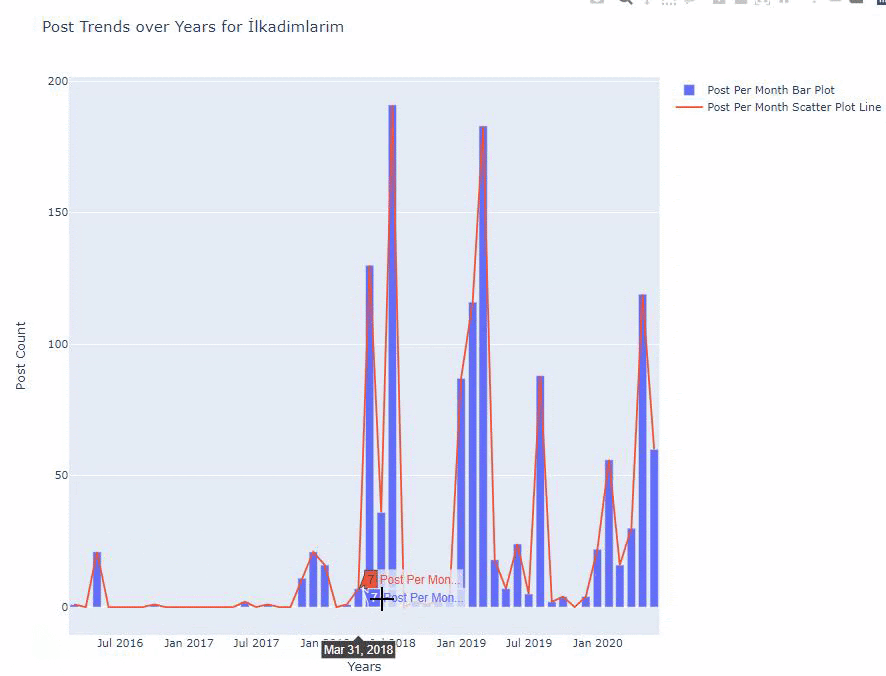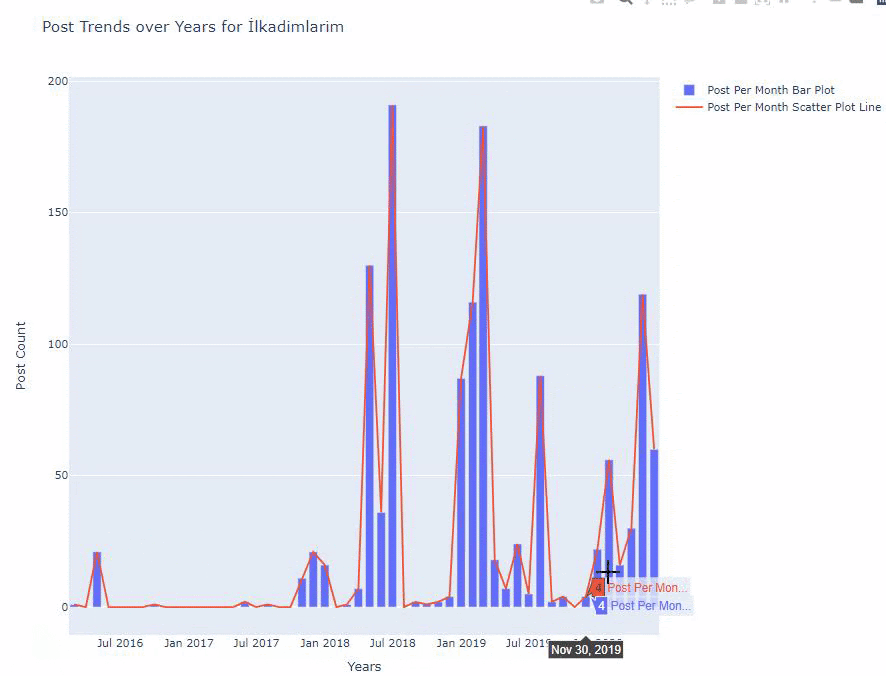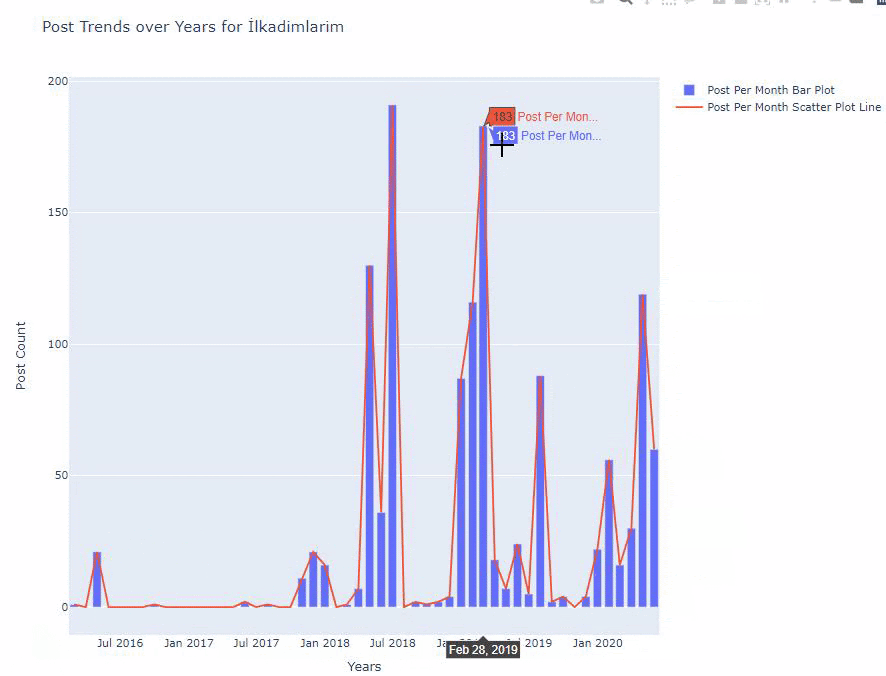
Aquí están los códigos para crear esta figura:
Agregamos una segunda gráfica con fig.add_scatter() y también cambiamos los nombres usando el atributo de nombre. fig.update_layout() es para cambiar el tamaño y el color de fondo de la trama.
También puede cambiar el modo de desplazamiento, la distancia entre las barras y más. Creo que es suficiente compartir solo los códigos, ya que explicar cada código aquí por separado puede hacer que nos alejemos del tema principal.
También podemos comparar las tendencias de publicación de contenido de los competidores según categorías como las siguientes:
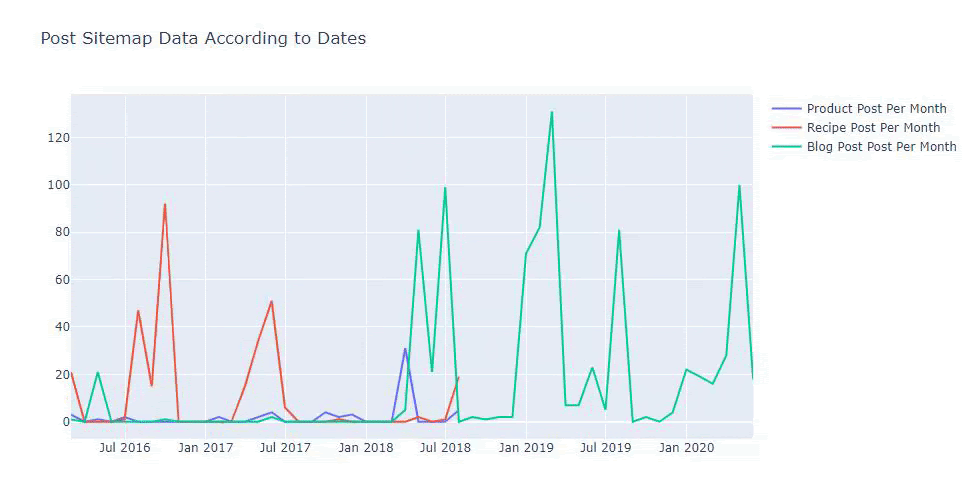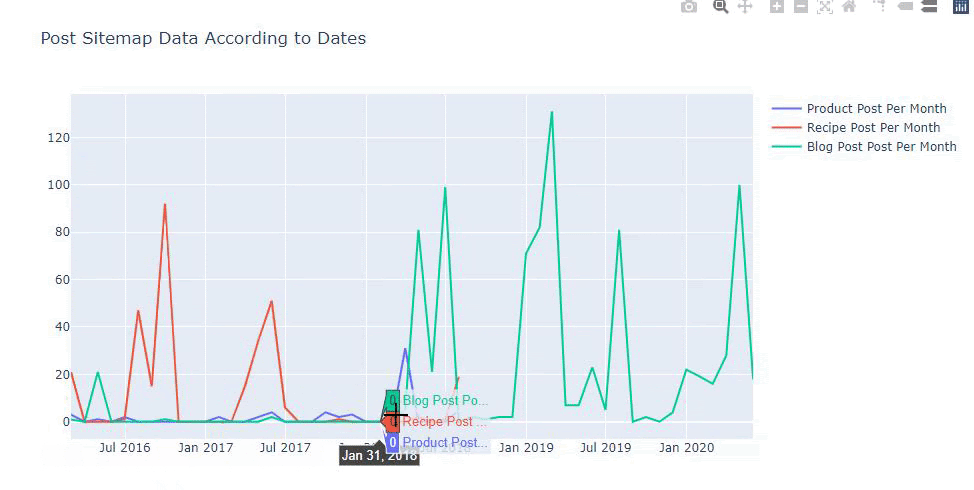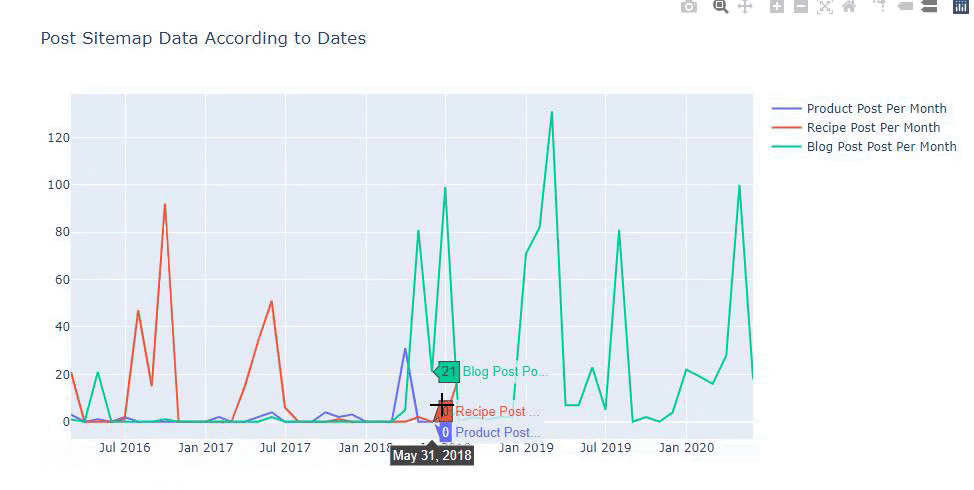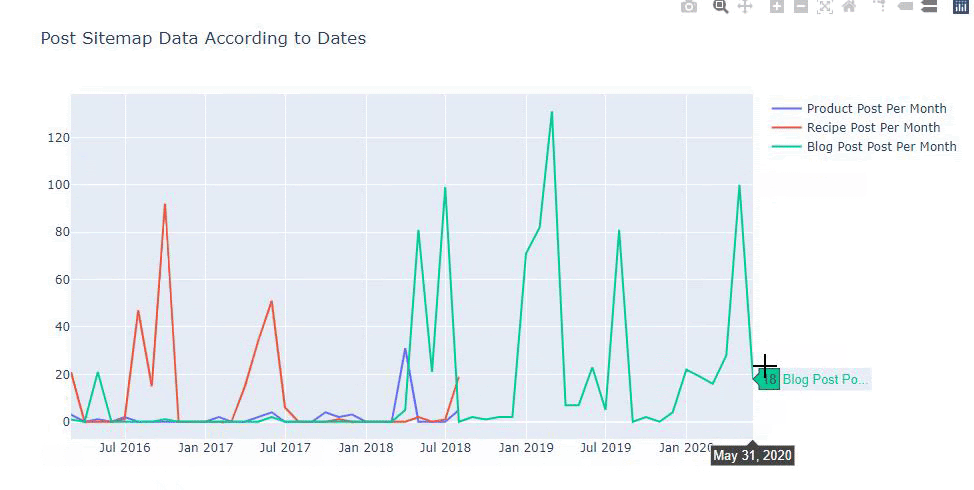
Este gráfico ha sido creado con el segundo método, como puedes ver no hay diferencia pero uno de ellos es bastante simple.
Para trazar la frecuencia y la tendencia de publicación de contenido de tres mapas de sitio separados, debemos colocar el mapa de sitio, que tiene el intervalo más largo, en el eje X. Por lo tanto, podemos comparar la frecuencia con la que el sitio web que estamos examinando publica cada tipo diferente de contenido para diferentes intentos de búsqueda.
Cuando examine los códigos relevantes a continuación, verá que no es muy diferente del anterior.
Para crear un diagrama de dispersión con múltiples ejes Y, puede usar el código a continuación.
Existen otros métodos, como unificar diferentes mapas de sitio y usar un bucle for para que las columnas usen múltiples ejes Y en el diagrama de dispersión, pero para un sitio tan pequeño no necesitamos eso. En su mayor parte, sería más lógico utilizar este método en sitios web con cientos de sitemaps.
Además, debido a que el sitio web es pequeño, el gráfico puede parecer superficial, pero como verá más adelante en el artículo sobre un sitio web con millones de URL, dichos gráficos son una excelente manera de comparar diferentes sitios, así como comparar diferentes categorías de la mismo sitio web.
Examen y visualización de categorías de contenido, intenciones y tendencias de publicación con mapas de sitio y Python
En esta sección, comprobaremos que escribieron una gran cantidad de contenido en un dominio de conocimiento específico para comercializar una pequeña cantidad de productos, como decíamos al principio del artículo. Gracias a esto, podemos ver si tienen una asociación de contenido con otras marcas o no.
Para mostrar qué más se puede encontrar en los mapas de sitio, continuaremos investigando un poco más. También podemos obtener información de la parte 'loc' del mapa del sitio, como otros.
No hay un desglose de categorías en las URL de Ilkadimlarim. Si un sitio web tiene un desglose de categorías en sus URL, podemos aprender mucho más sobre la distribución de contenido. Si no, podemos acceder a los mismos datos escribiendo código adicional, pero solo con menos certeza.
En este punto, puede imaginar cuánto menos costosos son los desgloses de URL para los motores de búsqueda que rastrean miles de millones de sitios para comprender su sitio web.
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
Bebek: bebe
Hamile: embarazada
Haftalik: semanal o “semanas de embarazo”
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
El método str() aquí nuevamente nos permite establecer la columna donde seleccionamos ciertas operaciones.
Con el método contains() , determinamos los datos para verificar si están incluidos en los datos convertidos en una cadena.
Aquí, “|” entre los términos significa “o” .
Luego asignamos los datos que filtramos a una variable y usamos el método resample() que usamos anteriormente.
el método de recuento , por otro lado, mide qué datos se utilizan y cuántas veces.
El resultado obtenido con count() se adjunta nuevamente con to_frame() .
Además, str.contains() toma valores Regex de forma predeterminada, lo que significa que puede crear condiciones de filtrado más complicadas con menos código.
En otras palabras, en este punto, asignamos las URL que contienen las palabras "bebé", "semanal", "embarazada" a una variable en ilkadimlarim , y luego ponemos la fecha de publicación de las URL en las condiciones apropiadas para este filtro. creado en un marco.
Luego hacemos lo mismo con las URL que contienen la palabra 'aptamil'. Aptamil es el nombre de un producto de nutrición infantil presentado por Ilkadimlarim. Por tanto, también podemos prestar atención a la densidad de emisión de contenidos informativos y comerciales.
Y puede ver los dos grupos de contenido diferentes publicando programas a lo largo de los años para diferentes intentos de búsqueda con más certeza e información precisa de las URL.
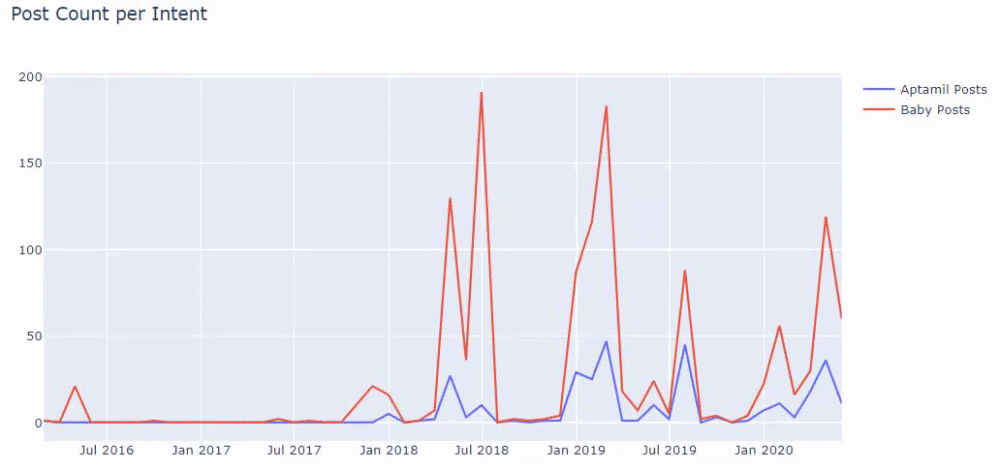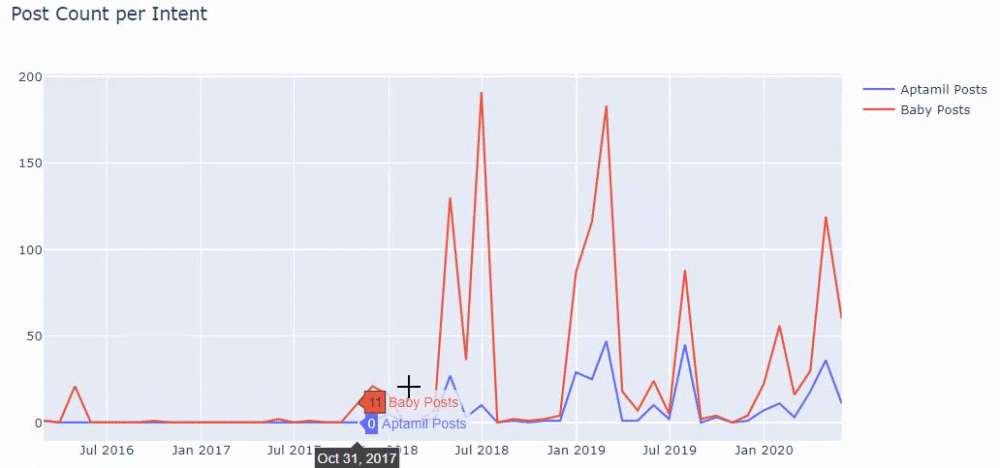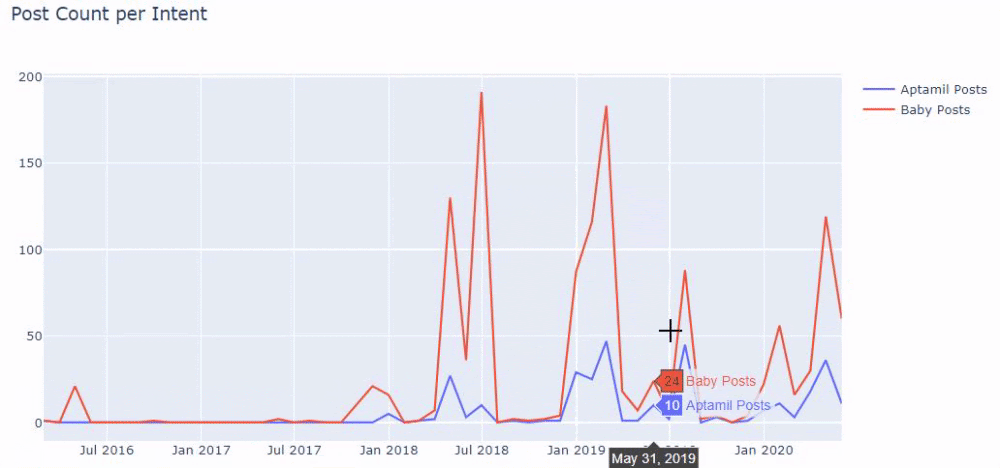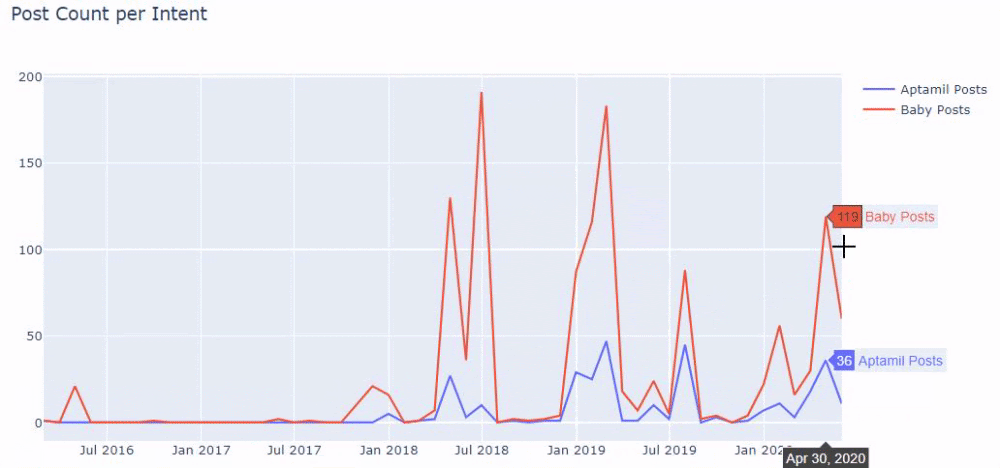
El código para producir este gráfico no se compartió porque es el mismo que se usó para el gráfico anterior.
Con la ayuda de los operadores de búsqueda en Google, obtengo 38 resultados cuando quiero las páginas donde se usa la palabra Aptamil en el texto de anclaje en Ilkadimlarim.com. Un número importante de estas páginas son de carácter informativo y enlazan contenidos comerciales.
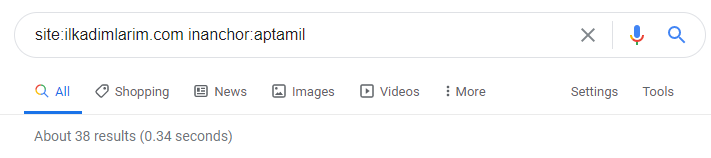
Nuestra tesis ha sido probada.
“Mis Primeros Pasos” utiliza cientos de piezas de contenido informativo sobre la maternidad, el cuidado del bebé y el embarazo para llegar a su público objetivo. “Ilkadimlarim” vincula las páginas que contienen productos Aptamil de este contenido y dirige a los usuarios allí.
Comparación de perfiles de contenido y análisis de la estrategia de contenido a través de Sitemaps con Python
Ahora, si quieres, hagamos lo mismo para una empresa de la misma industria y hagamos una comparación para entender el aspecto general de esta industria y las diferencias de estrategia entre estas dos marcas.

Como segundo ejemplo, elegí Prima.com.tr, que es Pampers, pero usa la marca Prima en Turquía. Dado que Prima tiene un solo mapa de sitio, no podremos clasificar por mapas de sitio, pero al menos tienen diferentes rupturas en sus URL. Así que tenemos mucha suerte: tendremos que escribir menos código.
¡Imagínese cuánto más costosos son los algoritmos que Google tiene que ejecutar para usted cuando crea un sitio difícil de entender! Esto puede ayudar a que el cálculo del costo de rastreo sea más tangible en su mente, incluso solo con respecto a la estructura de la URL.
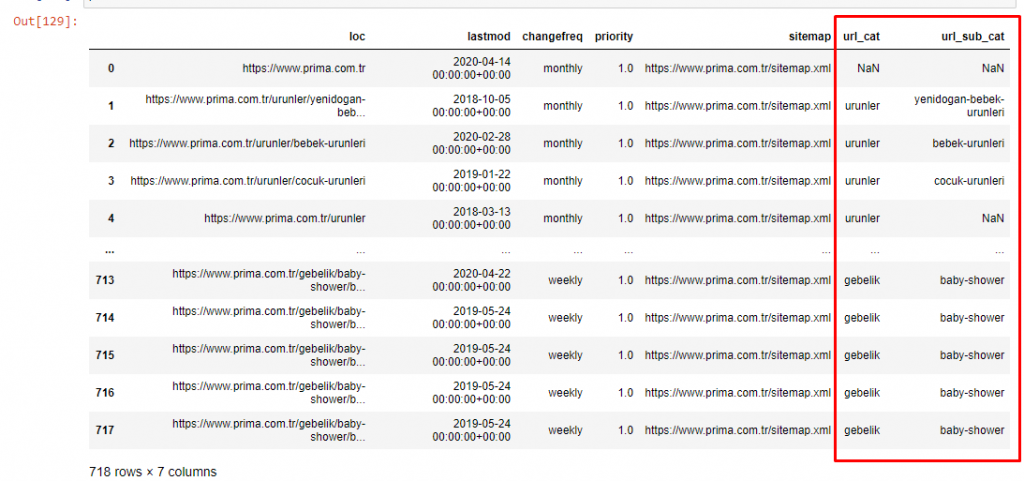
Para no aumentar más el volumen del artículo, no colocamos los códigos de los procesos que son similares a los que ya hemos hecho.
Ahora, podemos examinar su distribución de categorías de contenido por categorías de URL y subcategorías de URL. Vemos que tienen un exceso de páginas web corporativas. Estas páginas web corporativas se ubican en la sección “prima-hakkinda” (“Acerca de Prima”). Pero cuando los reviso con Python, veo que han unificado sus productos y páginas web corporativas en una sola categoría. Puedes ver su distribución de contenido a continuación:

Podemos hacer lo mismo para las siguientes subcategorías.
Es interesante notar que Prima usa "gebelik" (embarazo en turco) que es una variante de "hamilelik" (embarazo en árabe), y ambos significan período de embarazo.

Ahora vemos una categorización más profunda en su contenido. El 9,2 % del contenido trata sobre el embarazo saludable, el 7,3 % trata sobre el proceso de crecimiento de los bebés, el 8,3 % del contenido trata sobre actividades que se pueden realizar con los bebés, el 0,7 % trata sobre el orden de sueño de los bebés. Incluso hay temas como la dentición con un 3,9 %, la seguridad del bebé con un 1,9 % y revelar un embarazo a la familia con un 1,4 %. Como puede ver, puede conocer una industria con solo URL y su porcentaje de distribución.
Esta no es la categorización perfecta, pero al menos podemos ver la mentalidad y las tendencias de marketing de contenido de nuestros competidores, y el contenido de su sitio web según las categorías. Ahora vamos a comprobar la frecuencia de publicación de contenido por mes.
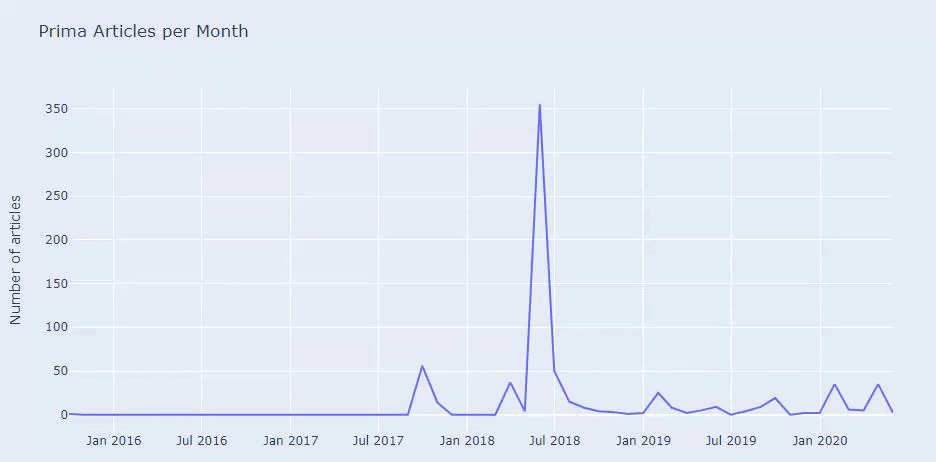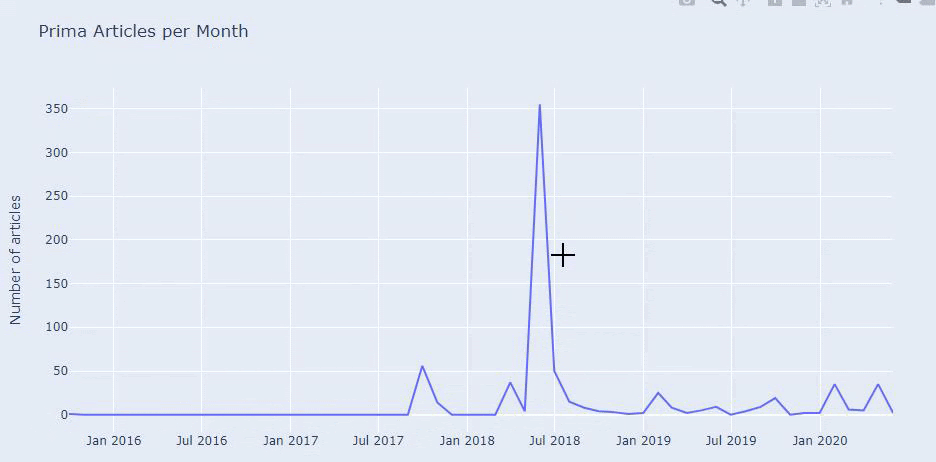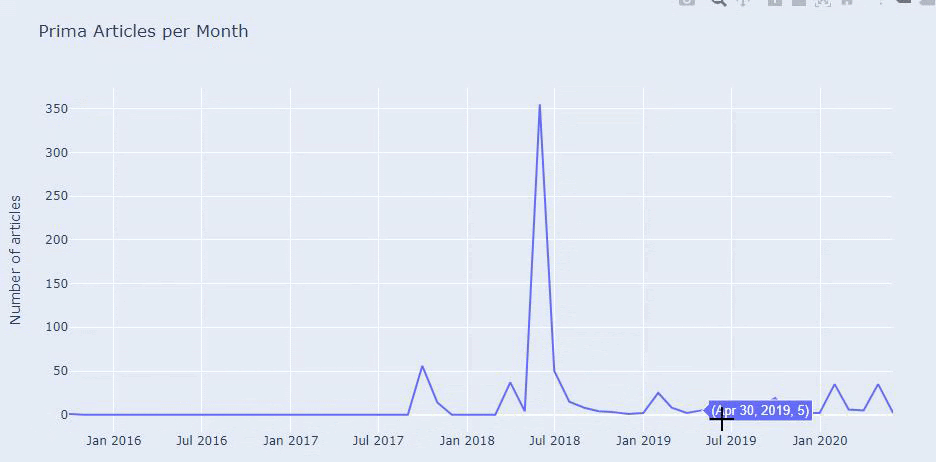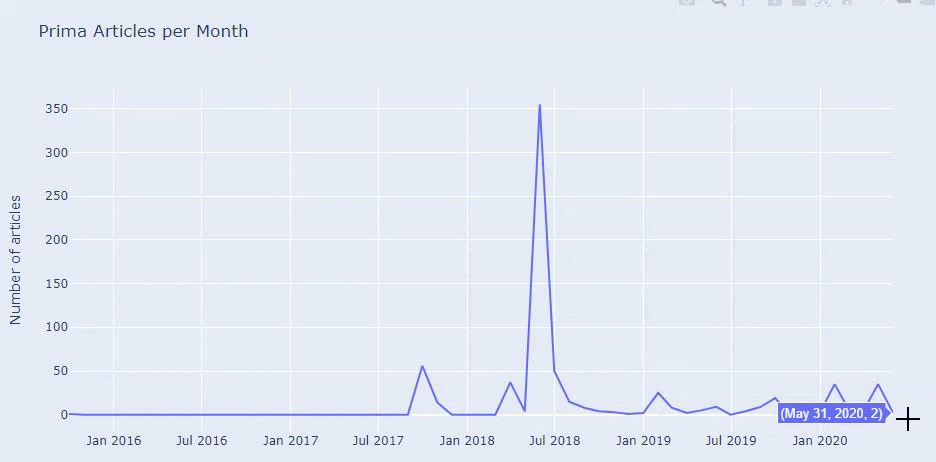
Vemos que publicaron 355 artículos en julio de 2018 y, según Sitemap, sus contenidos no se actualizan desde entonces. También podemos comparar sus tendencias de publicación de contenido según las categorías a lo largo de los años. Como puede ver, su contenido se ubica principalmente en cuatro categorías diferentes y la mayoría de ellos se publican en el mismo mes.
Antes de continuar, debo decir que los datos del mapa del sitio pueden no ser siempre correctos. Por ejemplo, es posible que los datos de Lastmod se hayan actualizado para todas las URL porque renovaron todos los mapas del sitio en esta fecha. Para evitar esto, también podemos verificar que no hayan cambiado su contenido desde entonces usando Wayback Machine.
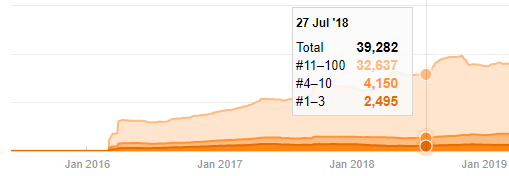
Aunque parezca sospechoso, estos datos pueden ser reales. Muchas empresas en Turquía tienen tendencia a dar un alto número de pedidos y publicar contenido un momento antes. Cuando compruebo su recuento de palabras clave, veo un salto en este período de tiempo. Por lo tanto, si está realizando un perfil de contenido comparativo y un análisis de estrategia, también debe pensar en estos temas.
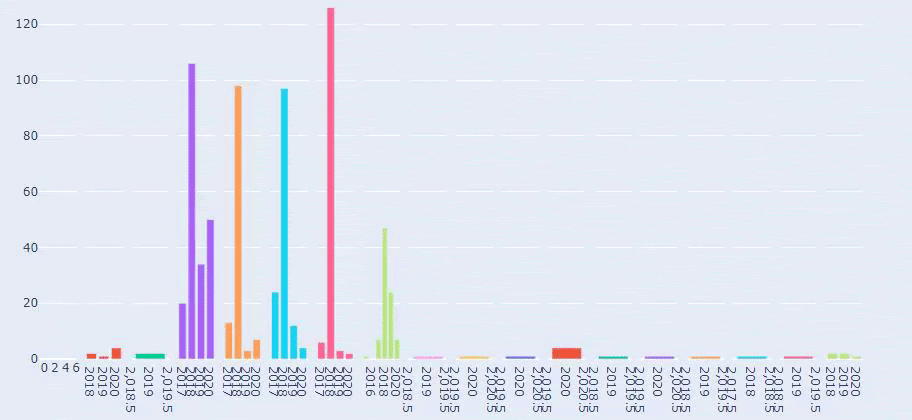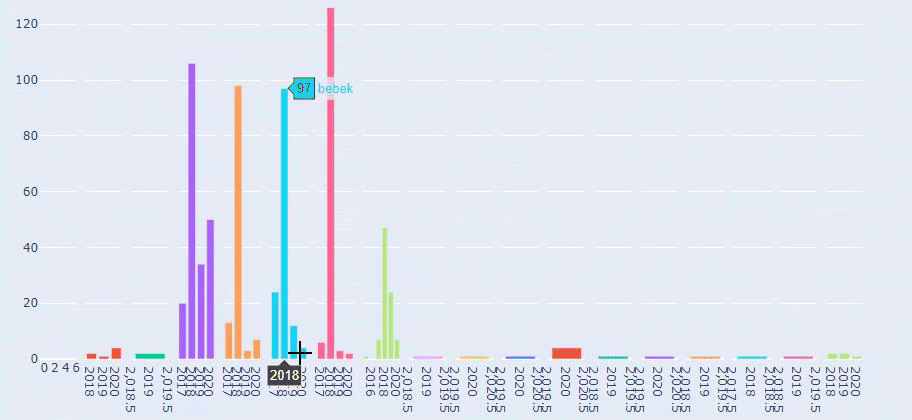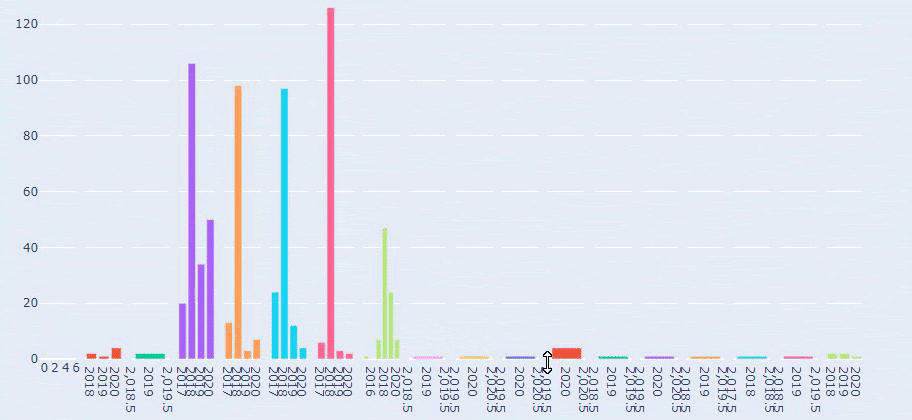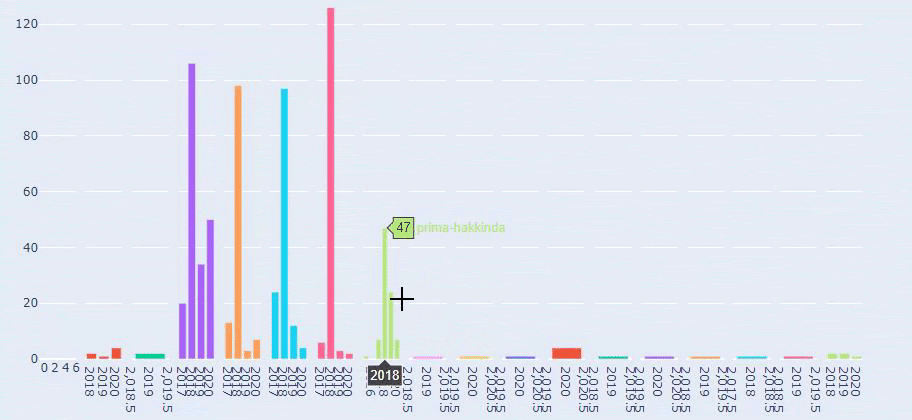
Esta es una comparación entre la tendencia de publicación de contenido de cada categoría a lo largo de los años para Prima.com.tr
Ahora, podemos comparar las categorías de contenido de los dos sitios web diferentes y sus tendencias de publicación.
Cuando observamos la frecuencia con la que Prima publica artículos sobre el crecimiento del bebé, el embarazo y la maternidad, vemos una similitud con Ilkadimlarim:
- La mayoría de los artículos fueron publicados en un momento determinado.
- Hacía mucho tiempo que no se actualizaban.
- El número de productos y páginas era muy bajo en comparación con el número de páginas de contenido informativo.
- Recientemente, acaban de agregar nuevos productos a sus sitios.
Podemos considerar que estas cuatro características son la mentalidad predeterminada de la industria y podemos usar estas debilidades a favor de nuestra campaña. Después de todo, la calidad exige frescura (como afirma Amit Singhal, Google Fellow).
En este punto, también vemos que la industria no está familiarizada con el comportamiento de Googlebot. En lugar de cargar 250 piezas de contenido en un día y luego no hacer cambios durante un año, es mejor agregar periódicamente contenido nuevo y actualizar el contenido antiguo con regularidad. Por lo tanto, puede mantener la calidad del contenido, Googlebot puede comprender su sitio más fácilmente y sus valores de frecuencia de demanda de rastreo serán más altos que los de sus competidores.
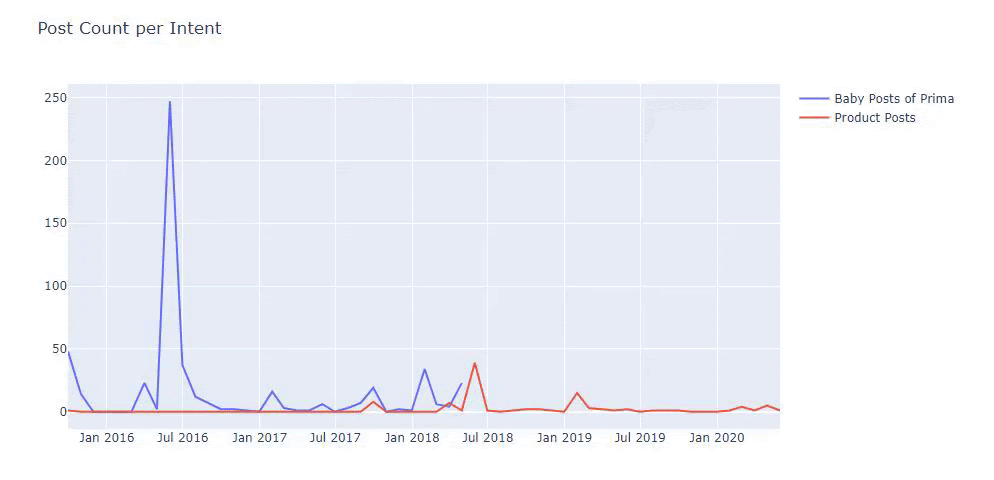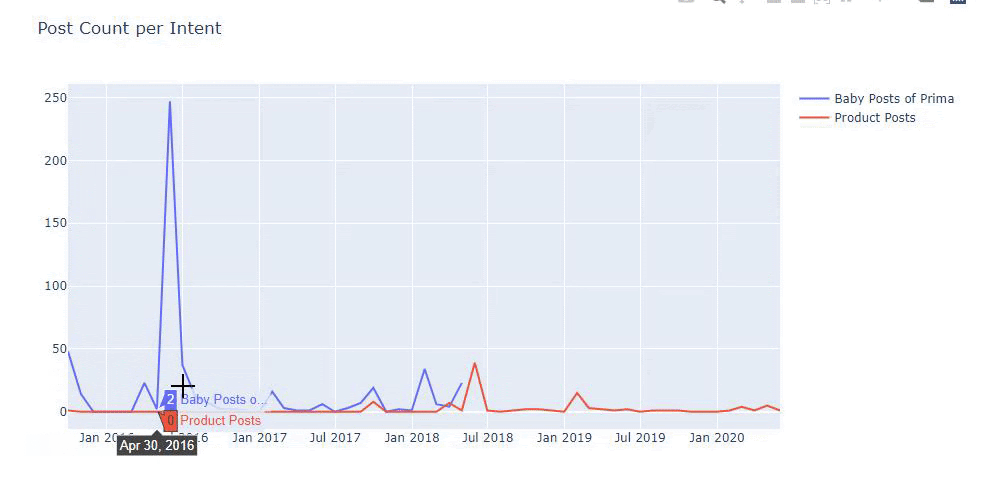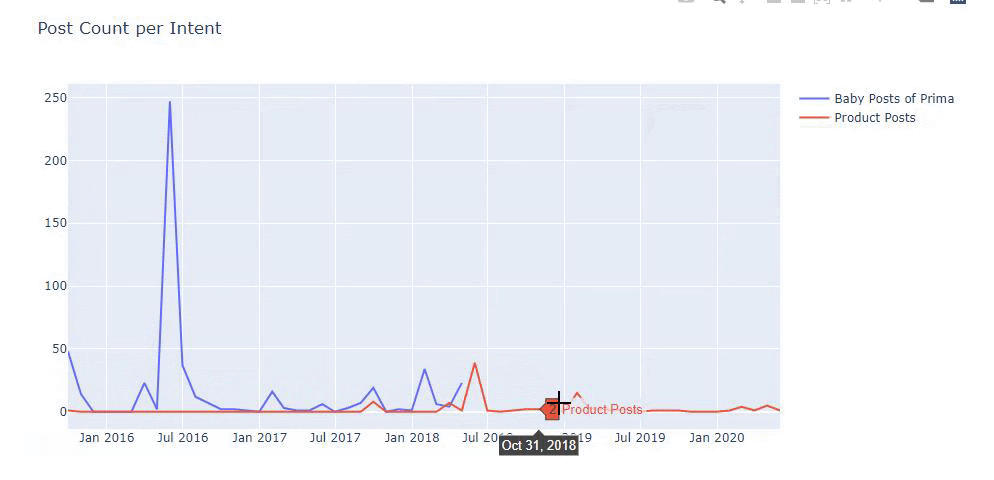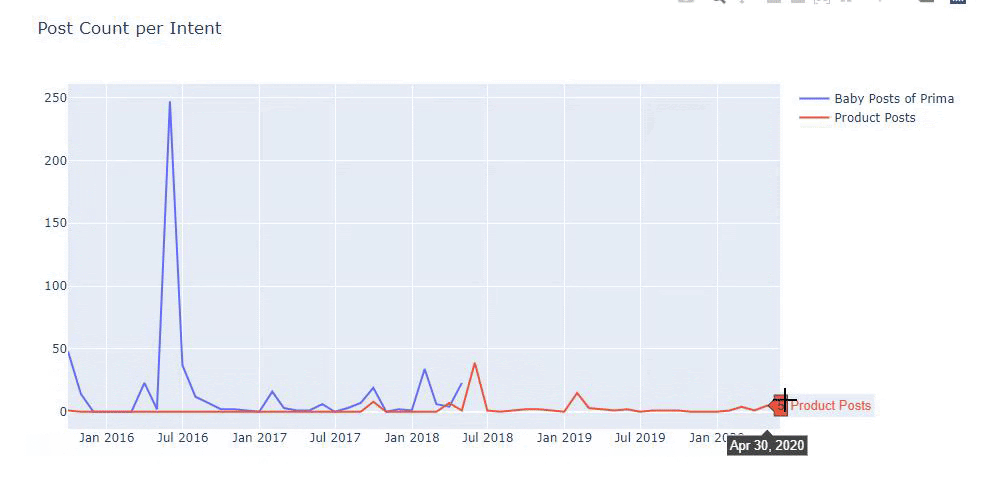
Usé los métodos anteriores para distinguir entre páginas de productos y de contenido informativo y perfilé las palabras más utilizadas en las URL. Baby Posts aquí significa que se trata de contenido informativo.
Como puede ver, han agregado 247 contenidos en un día. Además, no publicaron ni actualizaron contenido informativo en más de un año, y ocasionalmente agregan algunas páginas de nuevos productos.
Ahora comparemos sus tendencias editoriales en una sola figura pero con dos tramas diferentes. He usado los siguientes códigos para crear esta figura:
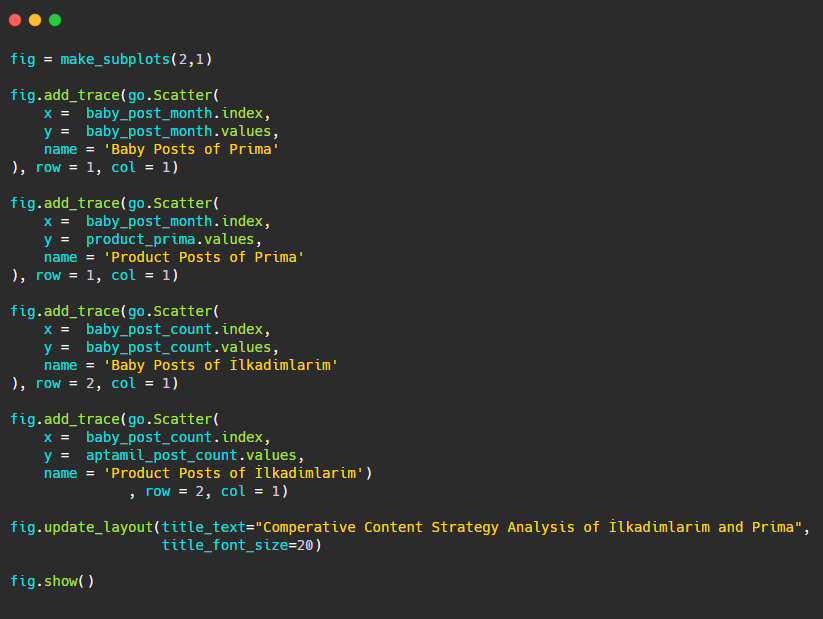
Como este gráfico es diferente a los anteriores, quería mostrarles el código. Aquí, dos parcelas separadas se colocan en la misma figura. Para esto se llamó al método make_subplots con el comando de plotly.subplots import make_subplots.
Se creó como una figura de dos filas y una columna con make_subplots (2,1) .
Por lo tanto, col y fila se escriben al final de las trazas y se especifican sus posiciones. Es un sistema que cualquier persona familiarizada con el sistema de grillas en CSS puede reconocer fácilmente.
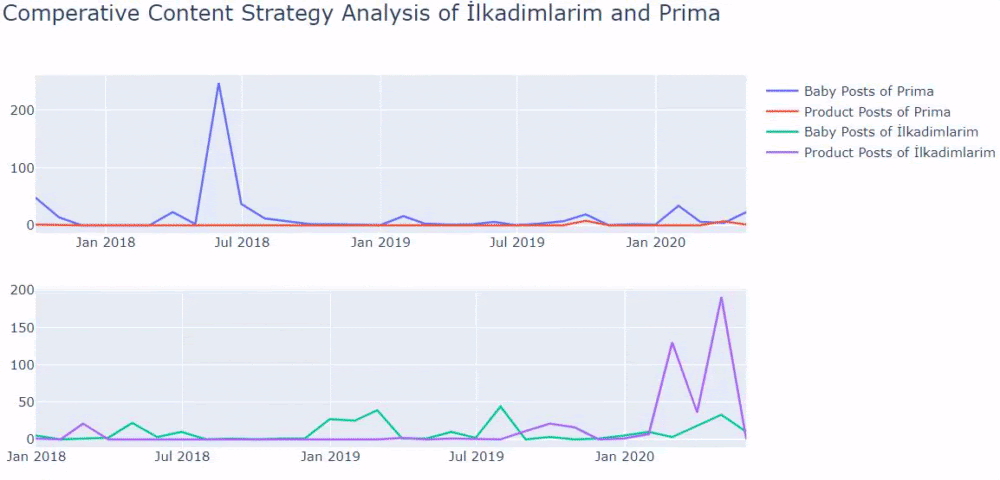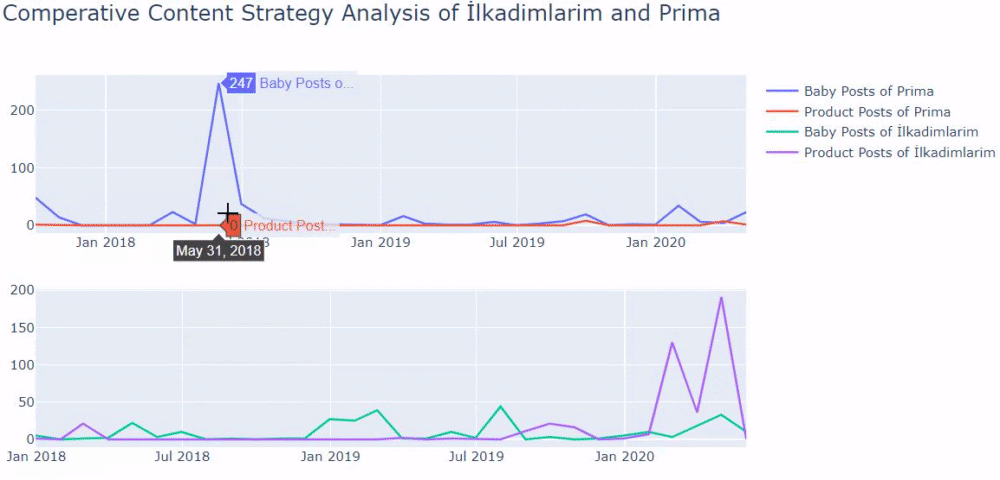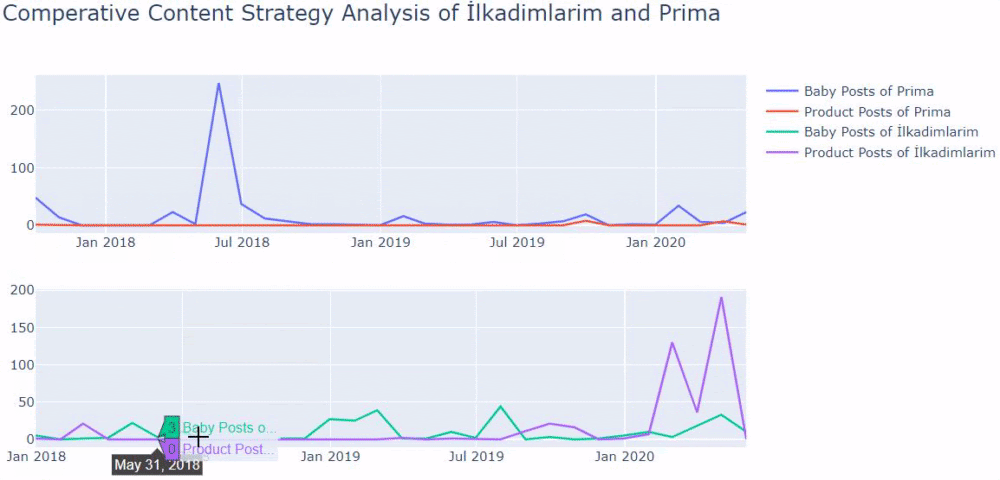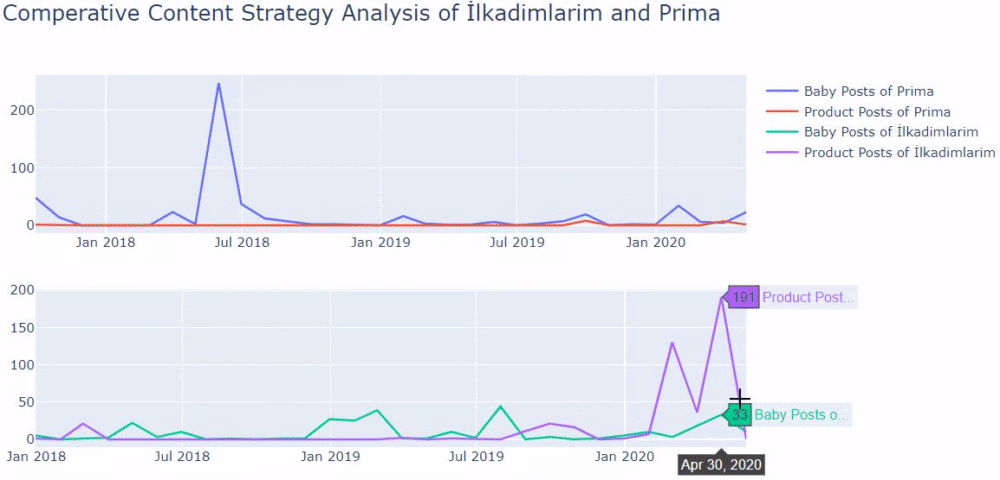
Si tiene un cliente en el mismo sector, puede usar estos datos para crear una estrategia de contenido, para ver las debilidades de sus competidores y su red de consultas/páginas de destino sobre SERP. Además, puede comprender qué cantidad de contenido debe publicar en el mismo dominio de conocimiento o para la misma intención del usuario.
Antes de concluir con lo que podemos aprender de los sitemaps como parte de un análisis de estrategia de contenido, podemos examinar un último sitio web con un recuento de URL mucho más alto de otra industria.
Análisis de estrategia de contenido de entidades web de noticias sobre divisas con Python y Sitemaps
En esta sección, utilizaremos el diagrama de mapa de calor de Seaborn y también algunos métodos más sofisticados de elaboración y extracción de datos.

Elias Dabbas tiene un Kaggle Archive interesante y realmente útil en términos de ciencia de datos y SEO. Este mes, abrió una nueva sección de conjuntos de datos de Kaggle para sitios de noticias turcos para que escriba los códigos necesarios y realice un análisis de estrategia de contenido con Advertools a través de mapas de sitio.
Antes de comenzar a usar estas técnicas en Kaggle, me gustaría mostrar algunos ejemplos de lo que sucedería si usáramos las mismas técnicas en entidades web más grandes en este artículo.
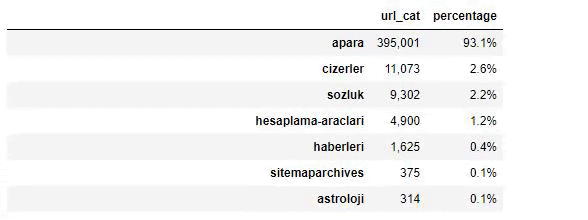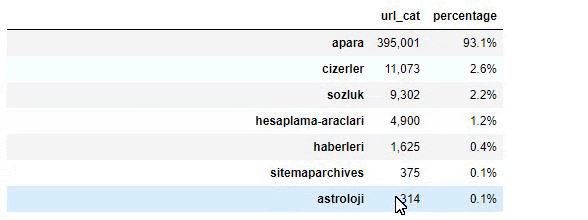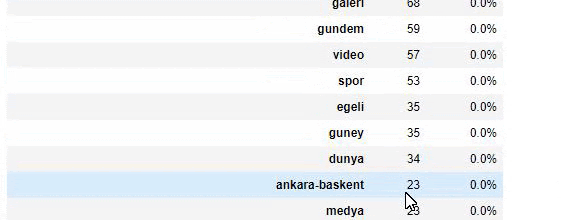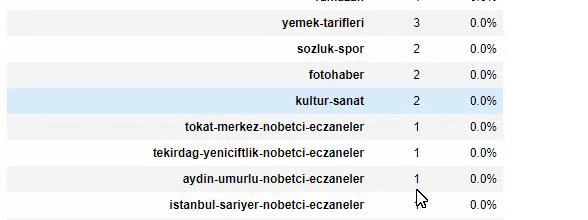
Cuando analizamos el contenido de Sabah Newspaper, vemos que una parte importante de sus contenidos (81%) se encuentra en una categoría denominada “apara”. Además, tienen algunas categorías importantes para astrología, cálculo, diccionario, clima y noticias mundiales. (Para significa el dinero en turco)
Para Sabah Newspaper, también podemos analizar contenido con sitemaps que hemos recopilado solo con Advertools, pero dado que el periódico en cuestión es muy grande, no lo preferí debido a la gran cantidad de sitemaps y al contenido de diferentes sitemaps que contienen la misma URL. Categoría.
A continuación también puedes ver el exceso de sitemaps con Advertools.
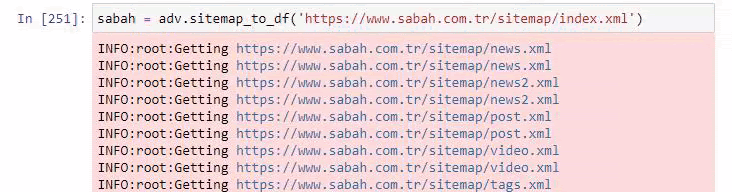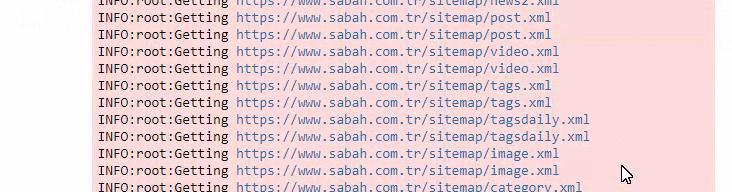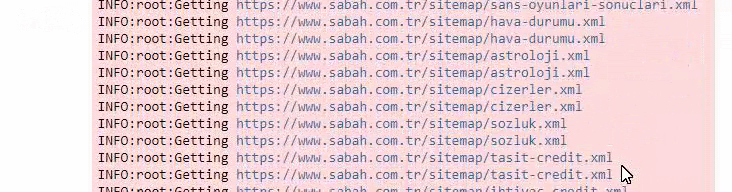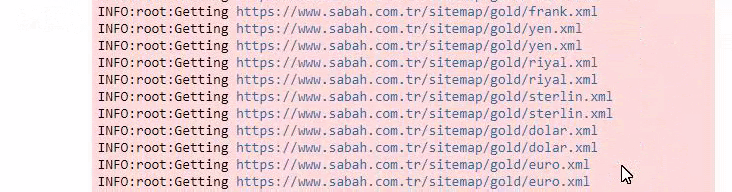
Es posible que veamos que tienen diferentes mapas de sitio para las mismas categorías de URL, como oro, crédito, monedas, etiquetas, tiempos de oración y horas de trabajo de farmacia, etc.
En resumen, podemos lograr estos detalles centrándonos en subcategorías de URL. En lugar de unificar diferentes mapas de sitio a través de variables. Por lo tanto, he unificado todos los mapas del sitio con el método sitemap_to_df() de Advertools, como al principio del artículo.
También podemos usar otro conjunto de funciones creadas por Elias Dabbas para crear mejores marcos de datos. Si revisa las funciones de dataset_utilites, puede ver algunos ejemplos. El siguiente código proporciona el total y el porcentaje de una expresión regular de URL específica junto con la suma acumulada mediante el estilo.
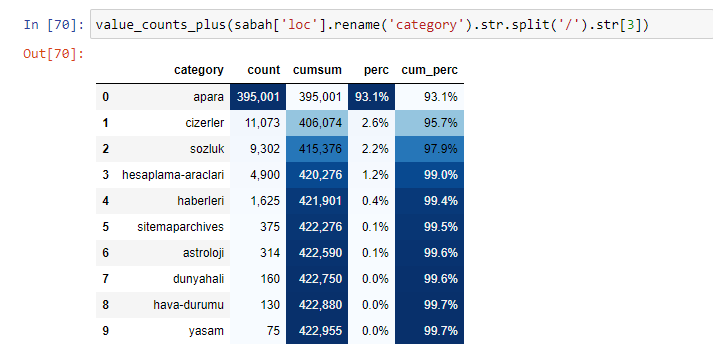
Si hacemos lo mismo con un desglose de sub-URL de Sabah Newspaper, obtendremos el siguiente resultado.
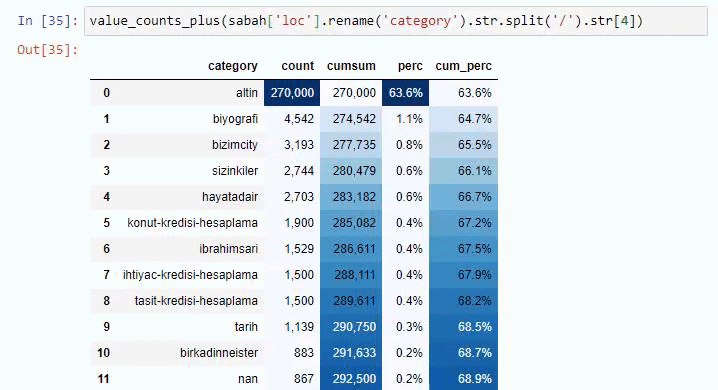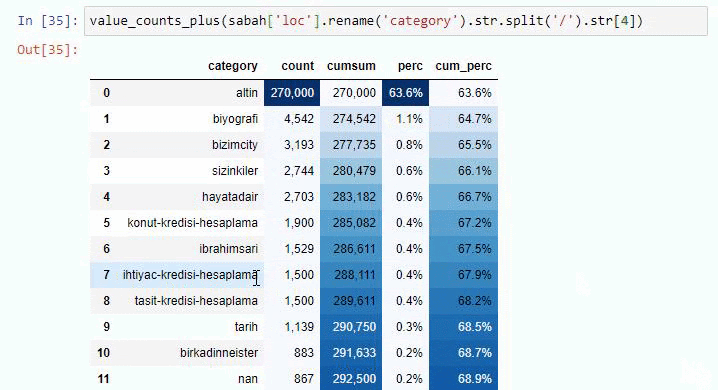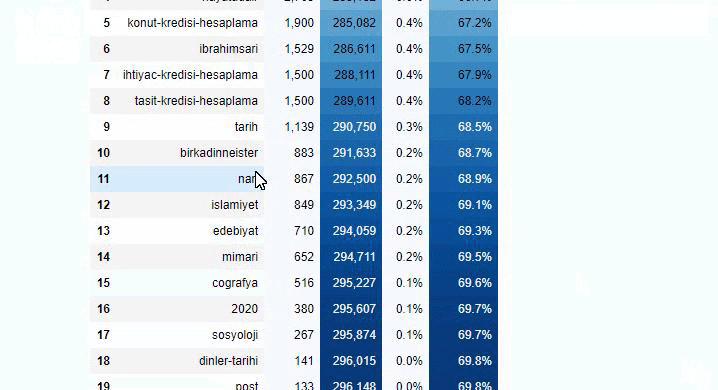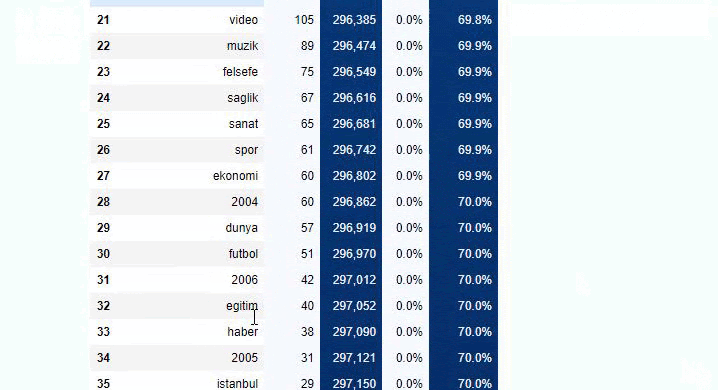
Puede aumentar el número de líneas que generará la función en cuestión cambiando la línea a continuación. Además, si examinas el contenido de la función, verás que es similar a las que hemos usado antes.
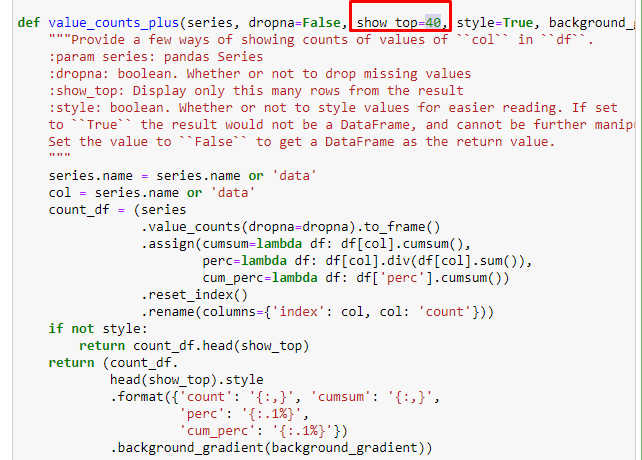
En sub-rupturas, vemos diferentes desgloses como "Historia de la religión", "Biografía", "Nombres de ciudades", "Fútbol", "Bizimcity (caricatura)", "Crédito hipotecario". El mayor desglose se encuentra en la categoría "Oro".
Entonces, ¿cómo puede un periódico tener 295 000 URL para los precios del oro?
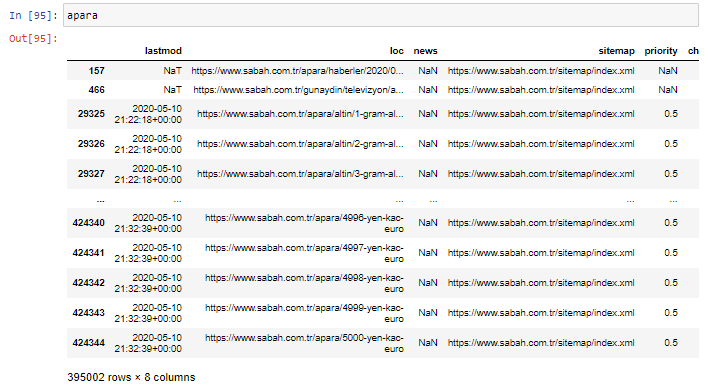
En primer lugar, tiro todas las URL que contienen el "apara" en el primer desglose de URL de Sabah Newspaper en una variable.
apara = sabah[sabah['loc'].str.contains('apara')]
Aquí está el resultado:
También podemos filtrar las columnas con el método .filter():
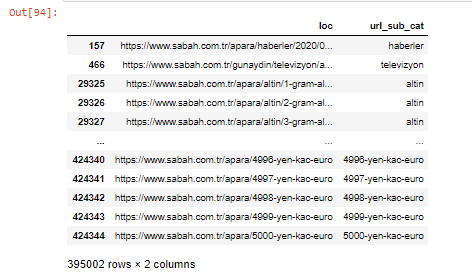
Ahora, podemos ver en la parte inferior del DataFrame por qué Sabah Newspaper tiene una cantidad excesiva de URL de Apara porque han abierto diferentes páginas web para cada cantidad de cálculo de moneda, como 5000 Euros, 4999 Euros, 4998 Euros y más...
Pero, antes de llegar a ninguna conclusión, debemos estar seguros porque más de 250.000 de estas URL pertenecen a la categoría 'altin (gold)'.
apara.filter(['loc', 'url_sub_cat' ]).tail(60) nos mostrará las últimas 60 líneas de este marco de datos:

Podemos hacer lo mismo con el desglose de URL dorado dentro del grupo Apara.
oro = apara[apara['loc'].str.contains('altin')]
oro.filter(['ubicación','url_sub_cat']).tail(85)
oro.filter(['ubicación','url_sub_cat']).head(85)
En este punto, vemos que Sabah Newspaper ha abierto 5000 páginas diferentes para convertir cada moneda a dólar, euro, oro y TL (liras turcas). Hay una página de cálculo separada para cada unidad de dinero entre 1 y 5000. Puede ver el ejemplo de las primeras 85 y últimas 85 líneas del grupo dorado a continuación. Se ha abierto una página separada para cada gramo de precio del oro.


No tenemos ninguna duda de que estas páginas son innecesarias, con mucho contenido duplicado y excesivamente grandes, pero Sabah Newspaper es un sitio web con una marca tan fuerte que Google continúa mostrándolo en casi todas las consultas, en el primer lugar.
En este punto, también podemos ver que la tolerancia del costo de rastreo es alta para un sitio de noticias antiguo con mucha autoridad.
Sin embargo, esto no explica por qué la categoría dorada tiene más URL que otras.
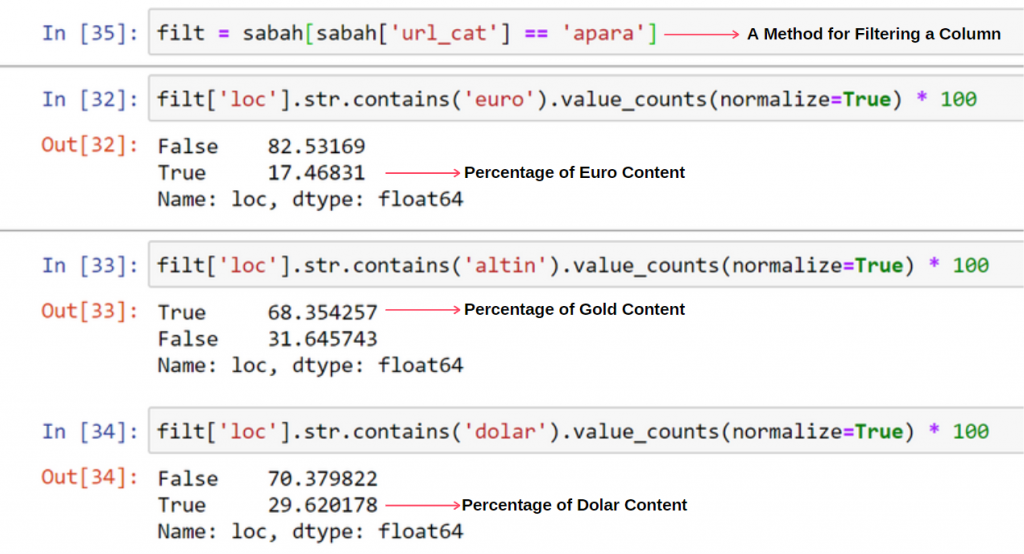
No veo nada extraño en que los valores superpuestos sumen más del 100 %.
¿A menos que me esté perdiendo algo?
Como notará, cuando sumamos todos los Valores Verdaderos, obtenemos el resultado de 115.16%. La razón de esto está abajo.
Incluso el grupo principal tiene una intersección entre sí como esta. También podríamos analizar estas intersecciones, pero podría ser tema de otro artículo.
Vemos que el 68% de los contenidos del grupo Apara URL están relacionados con GOLD.
Para comprender mejor esta situación, lo primero que debemos hacer es escanear las URL en la refracción dorada.
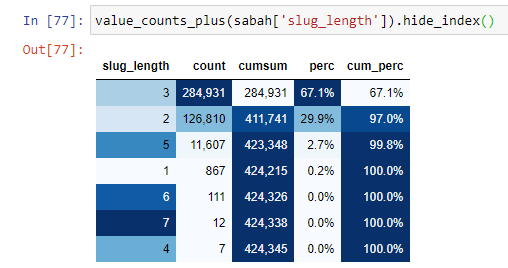
Cuando clasificamos las URLs según la cantidad de '/' que tienen desde la sección raíz, vemos que el número de URLs con un máximo de 3 saltos es alto. Cuando analizamos estas URL, vemos que 270.000 de las 3 URL de slug_length están en la categoría Gold.
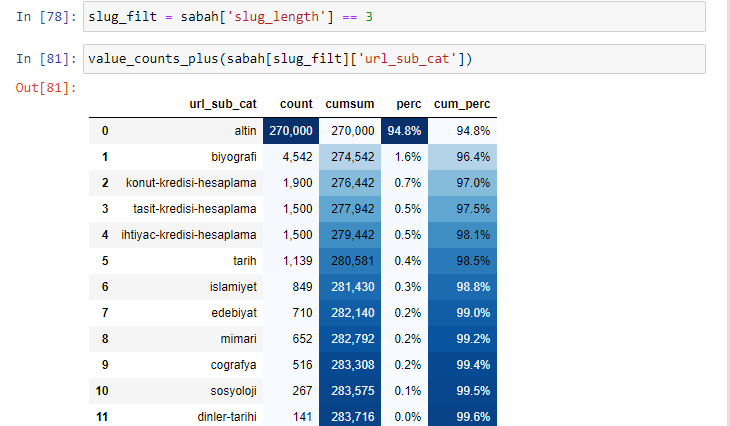
morning_filt = morning ['slug_length'] == 3 Significa que solo obtienes los que son iguales a 3 del grupo de datos de tipo de datos int en una determinada columna de un determinado marco de datos. Luego, en función de esta información, enmarcamos las URL que son convenientes para la condición con las tasas de conteo, sumas y agregación con suma acumulativa.
Cuando extraemos las palabras más utilizadas en las URL doradas, nos encontramos con palabras que representan "completo", "república", "cuarto", "gramo", "mitad", "ancestro". Los tipos de oro Ata y Republic son exclusivos de Turquía. Uno de ellos representa a la Soberanía Turca y el otro es el Fundador de la República, Kemal Ataturk. Es por eso que sus volúmenes de búsqueda de consultas son altos.
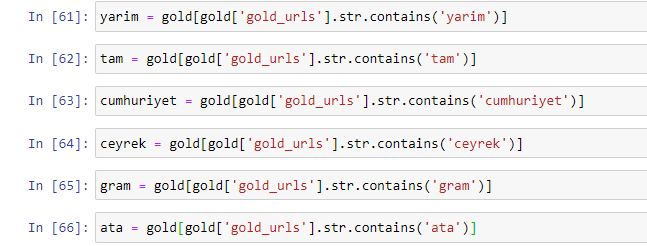
En primer lugar, hemos eliminado las palabras comunes que se encuentran en las URL y las hemos asignado a variables separadas. A continuación, usaremos estas variables en Gold DataFrame para crear columnas específicas para sus tipos.
Después de crear nuevas columnas a través de variables, debemos filtrarlas junto con valores booleanos.
Como puede ver, pudimos categorizar todas las URL doradas con 270 000 filas y 6 columnas. La razón principal de la gran cantidad de páginas específicas de oro es que el dólar o el euro no tienen tipos separados, mientras que el oro tiene tipos separados. Al mismo tiempo, la diversidad de páginas cruzadas entre el oro y las diferentes monedas es mayor que otras monedas debido a su confianza tradicional en los turcos.
En mi opinión, todos los tipos de páginas de oro deberían distribuirse por igual, ¿no?
Podemos probar esto fácilmente con la función Heatmap de Seaborn.
importar seaborn como sns
importar matplotlib.pyplot como plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=Falso,cbar=Falso,cmap=”viridis”)
plt.mostrar()
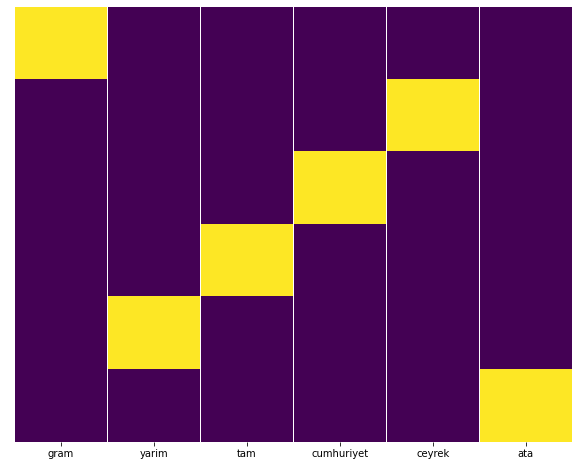
Aquí, en el Mapa de calor, los Verdaderos en cada columna simplemente están marcados. Como se puede ver, el tamaño de cada uno es simétrico entre sí y está bien organizado en el mapa.
Por lo tanto, hemos tomado una perspectiva amplia sobre la política de contenido del periódico Sabah.com.tr sobre monedas y cálculo de moneda.
En el futuro, escribiré Sitios web de noticias turcas y sus estrategias de contenido basadas en Sitemaps Kaggle, que fue lanzado por Elias Dabbas, pero en este artículo, hemos hablado lo suficiente sobre lo que se puede descubrir en sitios web grandes y pequeños con mapas de sitio. .
Conclusión y conclusiones
Creo que hemos visto lo fácil que es entender un sitio web, gracias a una estructura de URL fluida y semántica. También debemos recordar lo valiosa que puede ser una estructura de URL adecuada para Google.
En el futuro, veremos muchos SEO que están cada vez más familiarizados con la ciencia de datos, la visualización de datos, la programación front-end y más… Veo este proceso como el comienzo de un cambio inevitable: la brecha entre los SEO y los desarrolladores se cerrará por completo. en unos años.
Con Python, puede llevar este tipo de análisis aún más lejos: es posible obtener datos desde la comprensión de las opiniones políticas de un sitio de noticias, hasta quién escribe sobre qué, con qué frecuencia y con qué sentimientos. Prefiero no entrar en eso aquí, ya que estos procesos tienen más que ver con la ciencia de datos pura que con el SEO (y este artículo ya es bastante largo).
Pero si está interesado, hay muchos otros tipos de auditorías que se pueden realizar a través de Sitemaps y Python, como verificar los códigos de estado de las URL en un mapa del sitio.
Tengo muchas ganas de experimentar y compartir otras tareas de SEO que puedes hacer con Python y Advertools.