
Comprender la IA: cómo enseñamos el lenguaje natural a las computadoras
Publicado: 2023-11-28La frase “inteligencia artificial” se ha utilizado en relación con las computadoras desde la década de 1950, pero hasta el año pasado, la mayoría de la gente probablemente pensaba que la IA era más ciencia ficción que realidad tecnológica.
La llegada de ChatGPT de OpenAI en noviembre de 2022 cambió repentinamente la percepción de la gente sobre lo que era capaz de hacer el aprendizaje automático, pero ¿qué tenía exactamente ChatGPT que hizo que el mundo se sentara y se diera cuenta de que la inteligencia artificial estaba aquí a gran escala?
En una palabra, el lenguaje: la razón por la que ChatGPT se sintió como un salto adelante tan notable fue porque parecía fluido en el lenguaje natural de una manera que ningún chatbot lo había hecho antes.
Esto marca una nueva etapa notable en el “procesamiento del lenguaje natural” (PNL), la capacidad de las computadoras para interpretar el lenguaje natural y generar respuestas convincentes. ChatGPT se basa en un "modelo de lenguaje grande" (LLM), que es un tipo de red neuronal que utiliza aprendizaje profundo entrenado en conjuntos de datos masivos que pueden procesar y generar contenido.
"¿Cómo logró un programa de computadora tal fluidez lingüística?"
¿Pero como llegamos aquí? ¿Cómo logró un programa de computadora tal fluidez lingüística? ¿Cómo suena tan infaliblemente humano?
ChatGPT no se creó en el vacío: se basó en innumerables innovaciones y descubrimientos diferentes de las últimas décadas. La serie de avances que llevaron a ChatGPT fueron hitos en la informática, pero es posible verlos como una imitación de las etapas por las cuales los humanos adquieren el lenguaje.
¿Cómo aprendemos el idioma?
Para comprender cómo la IA ha llegado a esta etapa, vale la pena considerar la naturaleza del aprendizaje de idiomas en sí: comenzamos con palabras individuales y luego comenzamos a combinarlas en secuencias más largas hasta que podemos comunicar conceptos, ideas e instrucciones complejos.
Por ejemplo, algunas etapas comunes de la adquisición del lenguaje en los niños son:
- Etapa holofrástica: entre los 9 y los 18 meses, los niños aprenden a usar palabras únicas que describen sus necesidades o deseos básicos. Comunicarse con una sola palabra significa que hay un énfasis en la claridad sobre la integridad conceptual. Si un niño tiene hambre, no dirá “quiero algo de comida” o “tengo hambre”, sino que simplemente dirá “comida” o “leche”.
- Etapa de dos palabras: entre los 18 y 24 meses, los niños comienzan a utilizar agrupaciones simples de dos palabras para mejorar sus habilidades de comunicación. Ahora pueden comunicar sus sentimientos y necesidades con expresiones como “más comida” o “leer libro”.
- Etapa telegráfica: entre los 24 y 30 meses, los niños comienzan a unir varias palabras para formar frases y oraciones más complejas. La cantidad de palabras utilizadas es todavía pequeña, pero comienza a aparecer un orden correcto de las palabras y una mayor complejidad. Los niños comienzan a aprender la construcción de oraciones básicas, como "quiero mostrárselo a mamá".
- Etapa de varias palabras: después de los 30 meses, los niños comienzan la transición a la etapa de varias palabras. En esta etapa, los niños comienzan a utilizar oraciones más complejas, gramaticalmente correctas y con varias cláusulas. Esta es la etapa final de la adquisición del lenguaje y los niños eventualmente se comunican con oraciones complejas como "Si llueve, quiero quedarme en casa y jugar".
Una de las primeras etapas clave en la adquisición del lenguaje es la capacidad de empezar a utilizar palabras sueltas de una forma muy sencilla. Entonces, el primer obstáculo que los investigadores de IA debían superar era cómo entrenar modelos para aprender asociaciones simples de palabras.
Modelo 1: aprendizaje de palabras individuales con Word2Vec (prueba 1 y prueba 2)
Uno de los primeros modelos de redes neuronales que intentó aprender asociaciones de palabras de esta manera fue Word2Vec, desarrollado por Tomaš Mikolov y un grupo de investigadores de Google. Se publicó en dos artículos en 2013 (lo que muestra lo rápido que se han desarrollado las cosas en este campo).
Estos modelos se entrenaron aprendiendo a asociar palabras que se usaban comúnmente juntas. Este enfoque se basó en la intuición de los primeros pioneros lingüísticos como John R. Firth, quien señaló que el significado podía derivarse de la asociación de palabras: “Conocerás una palabra por la compañía que tiene”.
La idea es que las palabras que comparten un significado semántico similar tienden a aparecer juntas con mayor frecuencia. Las palabras "gatos" y "perros" generalmente aparecen juntas con más frecuencia que palabras como "manzanas" o "computadoras". En otras palabras, la palabra "gato" debería parecerse más a la palabra "perro" que "gato" a "manzana" o "computadora".
Lo interesante de Word2Vec es cómo fue entrenado para aprender estas asociaciones de palabras:
- Adivina la palabra objetivo: al modelo se le asigna un número fijo de palabras como entrada, falta la palabra objetivo y tiene que adivinar la palabra objetivo que falta. Esto se conoce como Bolsa Continua de Palabras (CBOW).
- Adivina las palabras circundantes: al modelo se le da una sola palabra y luego se le pide que adivine las palabras circundantes. Esto se conoce como Skip-Gram y es el enfoque opuesto al CBOW en el sentido de que predecimos las palabras circundantes.
Una ventaja de estos enfoques es que no es necesario tener datos etiquetados para entrenar el modelo; etiquetar datos, por ejemplo describir texto como "positivo" o "negativo" para enseñar análisis de sentimientos, es un trabajo lento y laborioso, después de todo.
Una de las cosas más sorprendentes de Word2Vec fueron las complejas relaciones semánticas que capturó con un enfoque de capacitación relativamente simple. Word2Vec genera vectores que representan la palabra de entrada. Al realizar operaciones matemáticas en estos vectores, los autores pudieron demostrar que los vectores de palabras no solo capturaban elementos sintácticamente similares sino también relaciones semánticas complejas.
Estas relaciones están relacionadas con cómo se usan las palabras. El ejemplo que observaron los autores fue la relación entre palabras como "Rey" y "Reina" y "Hombre" y "Mujer".
Pero si bien fue un paso adelante, Word2Vec tenía límites. Solo tenía una definición por palabra; por ejemplo, todos sabemos que "banco" puede significar cosas diferentes dependiendo de si planeas retener uno o pescar desde uno. A Word2Vec no le importaba, solo tenía una definición de la palabra "banco" y la usaría en todos los contextos.
Sobre todo, Word2Vec no podía procesar instrucciones ni siquiera frases. Solo podía tomar una palabra como entrada y generar una "incrustación de palabra", o representación vectorial, que había aprendido para esa palabra. Para aprovechar esta base de una sola palabra, los investigadores necesitaban encontrar una manera de unir dos o más palabras en una secuencia. Podemos imaginar esto como algo similar a la etapa de dos palabras en la adquisición del lenguaje.
Modelo 2: aprendizaje de secuencias de palabras con RNN y secuencias de texto
Una vez que los niños han comenzado a dominar el uso de una sola palabra, intentan juntar palabras para expresar pensamientos y sentimientos más complejos. De manera similar, el siguiente paso en el desarrollo de la PNL fue desarrollar la capacidad de procesar secuencias de palabras. El problema con el procesamiento de secuencias de texto es que no tienen una longitud fija. Una oración puede variar en longitud desde unas pocas palabras hasta un párrafo largo. No toda la secuencia será importante para el significado y contexto generales. Pero necesitamos poder procesar toda la secuencia para saber qué partes son más relevantes.
Ahí es donde surgieron las redes neuronales recurrentes (RNN).
Desarrollado en la década de 1990, un RNN funciona procesando su entrada en un bucle donde la salida de los pasos anteriores se transporta a través de la red a medida que recorre cada paso de la secuencia.
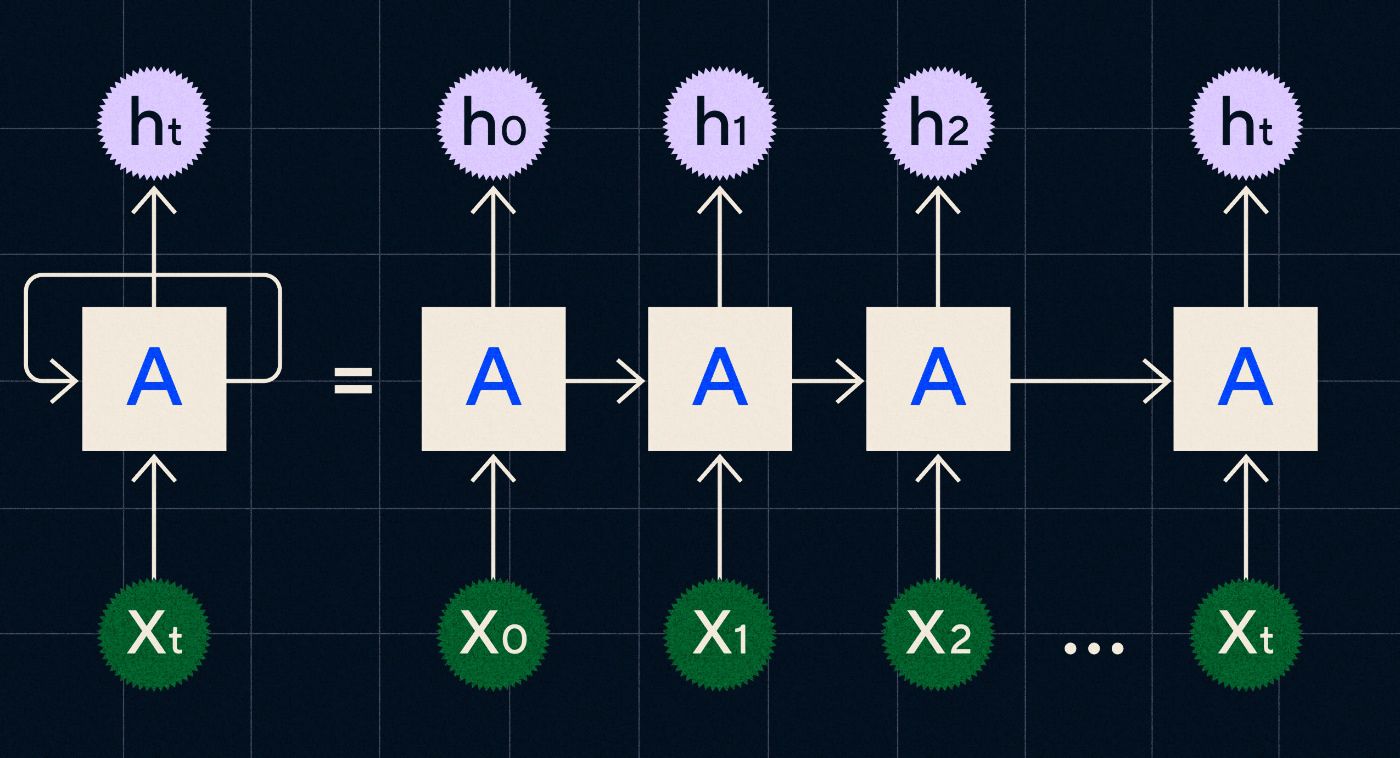
Fuente: publicación del blog de Christopher Olah sobre RNN
El diagrama anterior muestra cómo imaginar un RNN como una serie de redes neuronales (A) donde la salida del paso anterior (h0, h1, h2…ht) se lleva al siguiente paso. En cada paso la red también procesa una nueva entrada (X0, X1, X2… Xt).
Los RNN (y específicamente las redes de memoria a largo plazo, o LSTM, un tipo especial de RNN introducido por Sepp Hochreiter y Jurgen Schmidhuber en 1997) nos permitieron crear arquitecturas de redes neuronales que podían realizar tareas más complejas, como la traducción.
En 2014, Ilya Sutskever (cofundador de OpenAI), Oriol Vinyals y Quoc V Le de Google publicaron un artículo que describía los modelos de secuencia a secuencia (Seq2Seq). Este artículo mostró cómo se puede entrenar una red neuronal para que tome un texto de entrada y devuelva una traducción de ese texto. Puede pensar en esto como un ejemplo temprano de una red neuronal generativa, donde le da un mensaje y devuelve una respuesta. Sin embargo, la tarea estaba arreglada, por lo que si estaba entrenado en traducción, no podía "pedirle" que hiciera nada más.
Recuerde que el modelo anterior, Word2Vec, sólo podía procesar palabras sueltas. Entonces, si le pasara una oración como "el dentista me sacó el diente", simplemente generaría un vector para cada palabra como si no estuvieran relacionadas.
Sin embargo, el orden y el contexto son importantes para tareas como la traducción. No puedes simplemente traducir palabras individuales, necesitas analizar secuencias de palabras y luego generar el resultado. Aquí es donde los RNN permitieron que los modelos Seq2Seq procesaran palabras de esta manera.
La clave de los modelos Seq2Seq fue el diseño de la red neuronal, que utilizaba dos RNN consecutivos. Uno era un codificador que convertía la entrada de texto en una incrustación, y el otro era un decodificador que tomaba como entrada las incrustaciones generadas por el codificador:
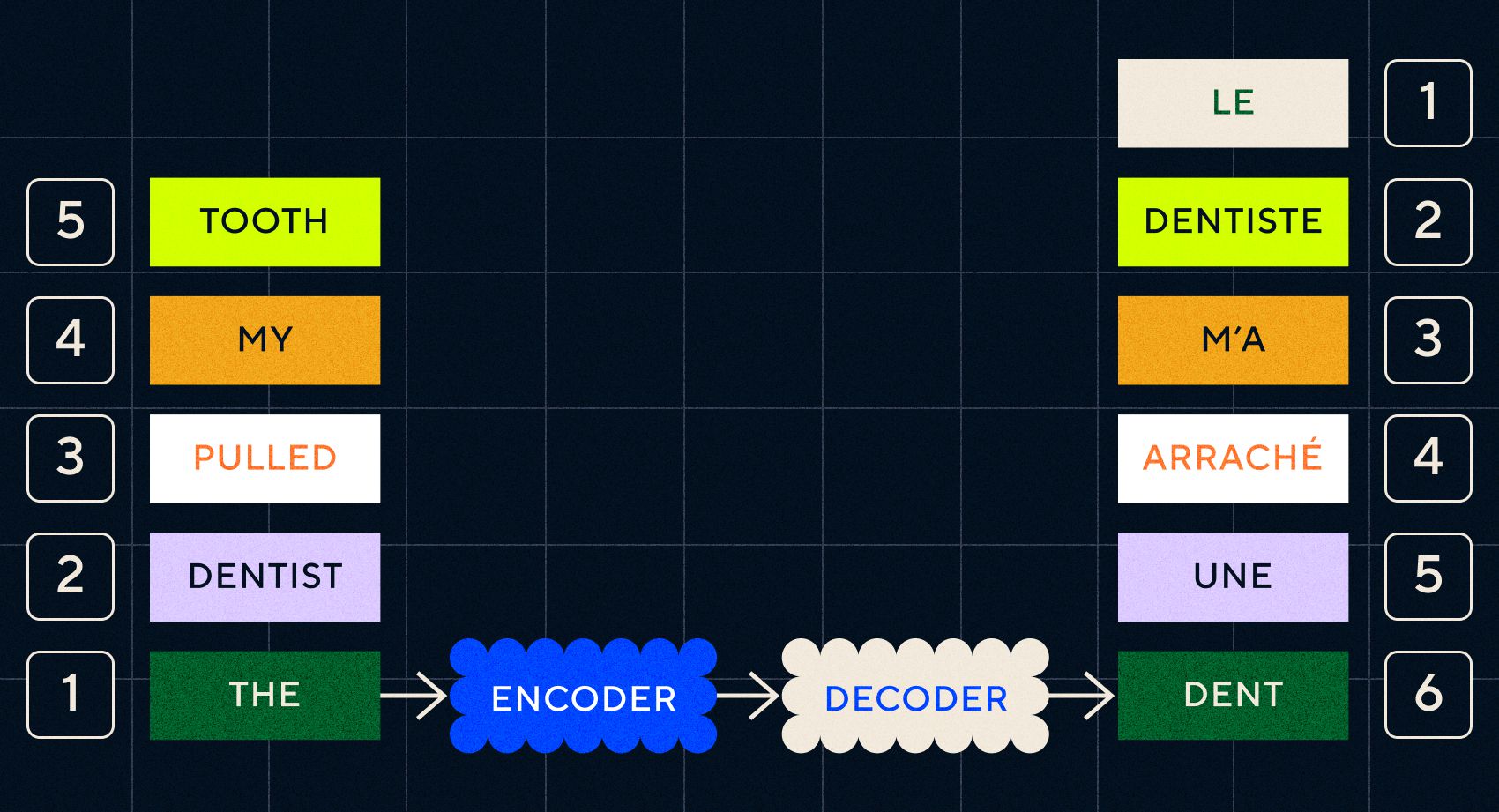
Una vez que el codificador ha procesado las entradas en cada paso, comienza a pasar la salida al decodificador, que convierte las incrustaciones en un texto traducido.
Podemos ver con la evolución de estos modelos que están empezando a parecerse, de alguna forma simple, a lo que vemos hoy con ChatGPT. Sin embargo, también podemos ver lo limitados que eran estos modelos en comparación. Al igual que con el desarrollo de nuestro propio lenguaje, para mejorar realmente nuestras habilidades lingüísticas necesitamos saber exactamente a qué prestar atención para crear frases y oraciones más complejas.
Modelo 3: aprendizaje por atención y escalamiento con Transformers
Anteriormente notamos que las etapas telegráficas eran donde los niños comenzaban a crear oraciones cortas con dos o más palabras. Un aspecto clave de esta etapa de adquisición del lenguaje es que los niños comienzan a aprender a construir oraciones adecuadas.
Los modelos RNN y Seq2Seq ayudaron a los modelos de lenguaje a procesar múltiples secuencias de palabras, pero aún estaban limitados en la longitud de las oraciones que podían procesar. A medida que aumenta la longitud de la oración, debemos prestar atención a la mayoría de los elementos de la oración.
Por ejemplo, tomemos la siguiente frase “Había tanta tensión en la habitación que se podía cortar con un cuchillo”. Están sucediendo muchas cosas allí. Para saber que aquí no estamos literalmente cortando algo con un cuchillo, debemos vincular "cortar" con "tensión" al principio de la oración.
A medida que aumenta la longitud de la oración, se vuelve más difícil saber qué palabras se refieren a cuál para inferir el significado correcto. Aquí es donde las RNN comenzaron a encontrar límites y necesitábamos un nuevo modelo para pasar a la siguiente etapa de adquisición del lenguaje.
“Piense en intentar resumir una conversación a medida que se hace más y más larga con un límite fijo de palabras. A cada paso empiezas a perder más y más información”
En 2017, un grupo de investigadores de Google publicó un artículo que proponía una técnica para permitir que los modelos presten atención al contexto importante en un fragmento de texto.
Lo que desarrollaron fue una forma para que los modelos de lenguaje buscaran más fácilmente el contexto que necesitaban mientras procesaban una secuencia de entrada de texto. Llamaron a este enfoque "arquitectura transformadora" y representó el mayor avance en el procesamiento del lenguaje natural hasta la fecha.
Este mecanismo de búsqueda facilita que el modelo identifique cuál de las palabras anteriores proporcionó más contexto a la palabra actual que se está procesando. Los RNN intentan proporcionar contexto pasando un estado agregado de todas las palabras que ya se han procesado en cada paso. Piense en intentar resumir una conversación a medida que se hace más y más larga con un límite fijo de palabras. A cada paso empiezas a perder más y más información. En cambio, los transformadores ponderaron las palabras (o tokens, que no son palabras completas sino partes de palabras) en función de su importancia para la palabra actual en términos de su contexto. Esto facilitó el procesamiento de secuencias de palabras cada vez más largas sin el cuello de botella que se observa en los RNN. Este nuevo mecanismo de atención también permitió que el texto se procesara en paralelo en lugar de secuencialmente como un RNN.
Imaginemos una frase como “El animal no cruzó la calle porque estaba demasiado cansado”. Para un RNN, sería necesario representar todas las palabras anteriores en cada paso. A medida que aumenta el número de palabras entre "eso" y "animal", se vuelve más difícil para el RNN identificar el contexto adecuado.

Con la arquitectura del transformador, el modelo ahora tiene la capacidad de buscar la palabra que probablemente se refiera a "eso". El siguiente diagrama muestra cómo los modelos transformadores pueden centrarse en la parte "del animal" del texto mientras intentan procesar una oración.
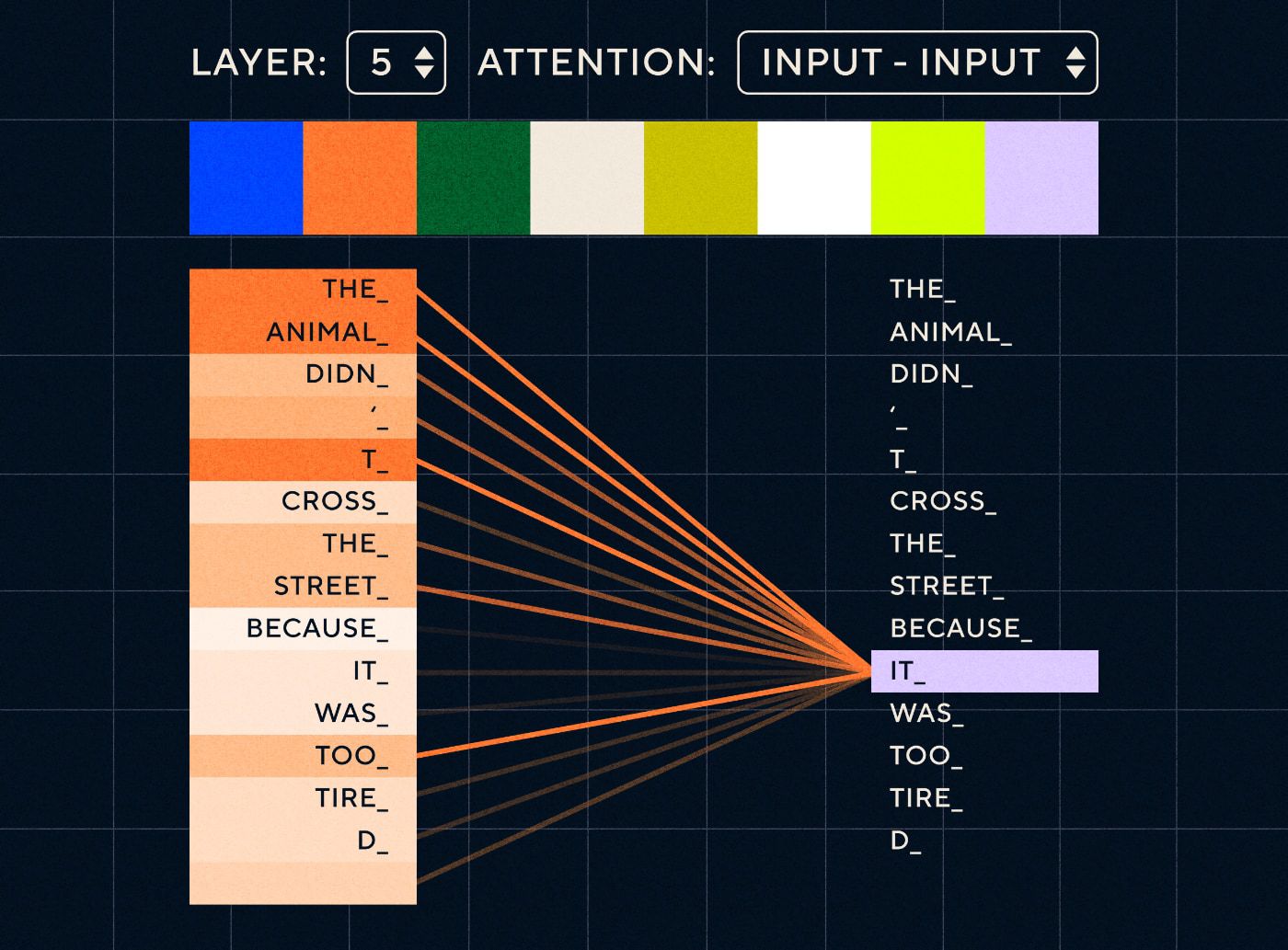
Fuente: El transformador ilustrado
El diagrama anterior muestra la atención en la capa 5 de la red. En cada capa, el modelo está aumentando su comprensión de la oración y “prestando atención a” una parte particular de la entrada que cree que es más relevante para el paso que está procesando en ese momento, es decir, está poniendo más atención en “la animal” para el “eso” en esta capa. Fuente: El transformador ilustrado.
Piense en ello como una base de datos donde puede recuperar la palabra con la puntuación más alta que probablemente esté relacionada con "eso".
Con este desarrollo, los modelos de lenguaje no se limitaron a analizar secuencias textuales cortas. En su lugar, podría utilizar secuencias de texto más largas como entradas. Sabemos que exponer a los niños a más palabras a través de una “conversación participativa” ayuda a mejorar el desarrollo de su lenguaje.
De manera similar, con el nuevo mecanismo de atención, los modelos lingüísticos pudieron analizar más y más variados tipos de datos de entrenamiento textuales. Esto incluía artículos de Wikipedia, foros en línea, Twitter y cualquier otro dato de texto que pudiera analizar. Al igual que con el desarrollo infantil, la exposición a todas estas palabras y su uso en diferentes contextos ayudó a los modelos lingüísticos a desarrollar capacidades lingüísticas nuevas y más complicadas.
Fue en esta fase que comenzamos a ver una carrera de escalamiento en la que la gente arrojaba cada vez más datos a estos modelos para ver qué podían aprender. Estos datos no necesitaban ser etiquetados por humanos: los investigadores podían simplemente buscar en Internet y alimentarlo al modelo y ver qué aprendía.
“Los modelos como BERT batieron todos los récords disponibles en el procesamiento del lenguaje natural. De hecho, los conjuntos de datos de prueba que se utilizaron para estas tareas eran demasiado simples para estos modelos de transformadores”.
El modelo BERT (Representaciones de codificador bidireccional de transformadores) merece una mención especial por varias razones. Fue uno de los primeros modelos en utilizar la función de atención que es el núcleo de la arquitectura Transformer. En primer lugar, BERT era bidireccional porque podía ver el texto tanto a la izquierda como a la derecha de la entrada actual. Esto era diferente de los RNN que solo podían procesar texto secuencialmente de izquierda a derecha. En segundo lugar, BERT también utilizó una nueva técnica de entrenamiento llamada "enmascaramiento" que, en cierto modo, obligó al modelo a aprender el significado de diferentes entradas "ocultando" o "enmascarando" tokens aleatorios para garantizar que el modelo no pudiera "hacer trampa" y céntrese en un solo token en cada iteración. Y, por último, BERT podría ajustarse para realizar diferentes tareas de PNL. No fue necesario capacitarlo desde cero para estas tareas.
Los resultados fueron sorprendentes. Modelos como BERT batieron todos los récords disponibles en el procesamiento del lenguaje natural. De hecho, los conjuntos de datos de prueba que se utilizaron para estas tareas eran demasiado simples para estos modelos de transformadores.
Ahora teníamos la capacidad de entrenar modelos de lenguaje grandes que sirvieron como modelos básicos para nuevas tareas de procesamiento del lenguaje natural. Anteriormente la gente entrenaba principalmente a sus modelos desde cero. Pero ahora los modelos previamente entrenados como BERT y los primeros modelos GPT eran tan buenos que no tenía sentido hacerlo usted mismo. De hecho, estos modelos eran tan buenos que la gente descubrió que podían realizar nuevas tareas con relativamente pocos ejemplos; fueron descritos como "aprendices de pocas oportunidades", similar a cómo la mayoría de las personas no necesitan demasiados ejemplos para comprender nuevos conceptos.
Este fue un enorme punto de inflexión en el desarrollo de estos modelos y sus capacidades lingüísticas. Ahora sólo necesitábamos mejorar en la elaboración de instrucciones.
Modelo 4: aprendizaje de instrucciones con InstructGPT
Una de las cosas que los niños aprenden en la etapa final de la adquisición del lenguaje, la etapa de palabras múltiples, es la capacidad de usar palabras funcionales para conectar los elementos que contienen información en una oración. Las palabras funcionales nos informan sobre la relación entre diferentes palabras en una oración. Si queremos crear instrucciones, los modelos de lenguaje deberán poder crear oraciones con palabras de contenido y palabras funcionales que capturen relaciones complejas. Por ejemplo, la siguiente instrucción tiene las palabras funcionales resaltadas en negrita:
- “ Quiero que escribas una carta…”
- “ Dime qué piensas sobre el texto anterior ”
Pero antes de que pudiéramos intentar entrenar modelos de lenguaje para que siguieran instrucciones, necesitábamos comprender exactamente lo que ya sabían sobre las instrucciones.
El GPT-3 de OpenAI se lanzó en 2020. Fue un vistazo de lo que estos modelos eran capaces de hacer, pero aún necesitábamos comprender cómo desbloquear las capacidades subyacentes de estos modelos. ¿Cómo podríamos interactuar con estos modelos para que realicen diferentes tareas?
Por ejemplo, GPT-3 demostró que aumentar el tamaño del modelo y los datos de entrenamiento permitió lo que los autores llamaron "metaaprendizaje": aquí es donde el modelo de lenguaje desarrolla un amplio conjunto de habilidades lingüísticas, muchas de las cuales eran inesperadas, y puede usarlas. Habilidades para comprender una tarea determinada.
"¿El modelo podría comprender la intención de la instrucción y ejecutar la tarea en lugar de simplemente predecir la siguiente palabra?"
Recuerde, GPT-3 y los modelos de lenguaje anteriores no fueron diseñados para desarrollar estas habilidades; en su mayoría fueron entrenados para predecir la siguiente palabra en una secuencia de texto. Pero, gracias a los avances con RNN, Seq2Seq y redes de atención, estos modelos pudieron procesar más texto, en secuencias más largas y centrarse mejor en el contexto relevante.
Puede pensar en GPT-3 como una prueba para ver hasta dónde podemos llegar. ¿Qué tamaño podríamos hacer los modelos y cuánto texto podríamos alimentar? Luego, después de hacer eso, en lugar de simplemente alimentar al modelo con un texto de entrada para que lo complete, podríamos usar el texto de entrada como instrucción. ¿Podría el modelo comprender la intención de la instrucción y ejecutar la tarea en lugar de simplemente predecir la siguiente palabra? En cierto modo, era como intentar comprender en qué etapa de adquisición del lenguaje habían llegado estos modelos.
Ahora describimos esto como “incitación”, pero en 2020, en el momento en que se publicó el artículo, era un concepto muy nuevo.
Alucinaciones y alineación
El problema con GPT-3, como sabemos ahora, era que no era muy bueno para seguir estrictamente las instrucciones del texto de entrada. GPT-3 puede seguir instrucciones pero pierde la atención fácilmente, solo puede entender instrucciones simples y tiende a inventar cosas. En otras palabras, los modelos no están “alineados” con nuestras intenciones. Así que el problema ahora no es tanto mejorar la capacidad lingüística de los modelos sino más bien su capacidad para seguir instrucciones.
Vale la pena señalar que GPT-3 nunca fue realmente entrenado con instrucciones. No se le dijo qué era una instrucción, ni en qué se diferenciaba de otro texto, ni cómo se suponía que debía seguir las instrucciones. En cierto modo, fue "engañado" para que siguiera instrucciones haciendo que "completara" un mensaje como otras secuencias de texto. Como resultado, OpenAI necesitaba entrenar un modelo que fuera más capaz de seguir instrucciones como un humano. Y lo hicieron en un artículo acertadamente titulado Entrenamiento de modelos de lenguaje para seguir instrucciones con retroalimentación humana publicado a principios de 2022. InstructGPT resultaría ser un precursor de ChatGPT más adelante ese mismo año.
Los pasos descritos en ese documento también se utilizaron para entrenar ChatGPT. La formación de instrucción siguió 3 pasos principales:
- Paso 1: Ajustar GPT-3: dado que GPT-3 parecía funcionar tan bien con un aprendizaje de pocas tomas, se pensó que sería mejor si se ajustara con ejemplos de instrucción de alta calidad. El objetivo era facilitar la alineación de la intención de la instrucción con la respuesta generada. Para hacer esto, OpenAI consiguió que etiquetadores humanos crearan respuestas a algunas indicaciones enviadas por personas que usaban GPT-3. Al utilizar instrucciones reales, los autores esperaban capturar una "distribución" realista de las tareas que los usuarios intentaban que GPT-3 realizara. Estas se utilizaron para ajustar GPT-3 y ayudarlo a mejorar su capacidad de respuesta rápida.
- Paso 2: hacer que los humanos clasifiquen el nuevo y mejorado GPT-3: para evaluar la nueva instrucción GPT-3 ajustada, los etiquetadores ahora calificaron el rendimiento de los modelos en diferentes indicaciones sin una respuesta predefinida. La clasificación estaba relacionada con importantes factores de alineación, como ser útil, veraz y no tóxico, parcial o dañino. Así que asigne una tarea al modelo y califique su desempeño en función de estas métricas. El resultado de este ejercicio de clasificación se utilizó luego para entrenar un modelo separado para predecir qué resultados probablemente preferirían los etiquetadores. Este modelo se conoce como modelo de recompensa (RM).
- Paso 3: utilice el RM para entrenar con más ejemplos: finalmente, se utilizó el RM para entrenar el nuevo modelo de instrucción para generar mejores respuestas que estén alineadas con las preferencias humanas.
Es complicado comprender completamente lo que está sucediendo aquí con el aprendizaje reforzado a partir de la retroalimentación humana (RLHF), los modelos de recompensa, las actualizaciones de políticas, etc.
Una forma sencilla de pensarlo es que es sólo una forma de permitir a los humanos generar mejores ejemplos de cómo seguir instrucciones. Por ejemplo, piense en cómo intentaría enseñarle a un niño a decir gracias:
- Padre: “Cuando alguien te da X, le dices gracias”. Este es el paso 1, un conjunto de datos de ejemplo de indicaciones y respuestas apropiadas.
- Padre: “Ahora, ¿qué le dices a Y aquí?”. Este es el paso 2, donde le pedimos al niño que genere una respuesta y luego el padre la calificará. "Sí eso es bueno."
- Finalmente, en encuentros posteriores, los padres recompensarán al niño basándose en buenos o malos ejemplos de respuestas en escenarios similares en el futuro. Este es el paso 3, donde tiene lugar la conducta de refuerzo.
Por su parte, OpenAI afirma que todo lo que hace es simplemente desbloquear capacidades que ya estaban presentes en modelos como GPT-3, "pero que eran difíciles de obtener únicamente mediante ingeniería rápida", como dice el documento.
En otras palabras, ChatGPT no está realmente aprendiendo “ nuevas ” capacidades, sino simplemente aprendiendo una mejor “ interfaz ” lingüística para utilizarlas.
La magia del lenguaje
ChatGPT parece un salto mágico hacia adelante, pero en realidad es el resultado de un minucioso progreso tecnológico durante décadas.
Al observar algunos de los principales desarrollos en el campo de la IA y la PNL en la última década, podemos ver cómo ChatGPT está "sobre los hombros de gigantes". Los modelos anteriores aprendieron por primera vez a identificar el significado de las palabras. Luego, los modelos posteriores juntaron estas palabras y pudimos entrenarlos para realizar tareas como la traducción. Una vez que pudieron procesar oraciones, desarrollamos técnicas que permitieron a estos modelos de lenguaje procesar cada vez más texto y desarrollar la capacidad de aplicar estos aprendizajes a tareas nuevas e imprevistas. Y luego, con ChatGPT finalmente desarrollamos la capacidad de interactuar mejor con estos modelos especificando nuestras instrucciones en un formato de lenguaje natural.
"Dado que el lenguaje es el vehículo de nuestros pensamientos, ¿enseñar a las computadoras todo el poder del lenguaje conducirá a, bueno, una inteligencia artificial independiente?"
Sin embargo, la evolución de la PNL revela una magia más profunda a la que normalmente estamos ciegos: la magia del lenguaje en sí y cómo nosotros, como humanos, lo adquirimos.
Todavía hay muchas preguntas abiertas y controversias sobre cómo los niños aprenden el lenguaje en primer lugar. También hay dudas sobre si existe una estructura subyacente común a todos los idiomas. ¿Han evolucionado los humanos para utilizar el lenguaje o es al revés?
Lo curioso es que, a medida que ChatGPT y sus descendientes mejoren su desarrollo lingüístico, estos modelos pueden ayudar a responder algunas de estas importantes preguntas.
Finalmente, dado que el lenguaje es el vehículo de nuestros pensamientos, ¿enseñar a las computadoras todo el poder del lenguaje conducirá a, bueno, una inteligencia artificial independiente? Como siempre en la vida, queda mucho por aprender.
