
Hackear The Topic Graph con Wikipedia y Google Language API
Publicado: 2019-08-27Una de mis diapositivas favoritas de los últimos diez años fue realizada por Mark Johnstone en 2014, cuando todavía estaba en Distilled. El mazo se llamaba Cómo producir mejores ideas de contenido y lo usé como mi biblia durante algunos años mientras formaba equipos para hacer el arduo trabajo de promoción de contenido.
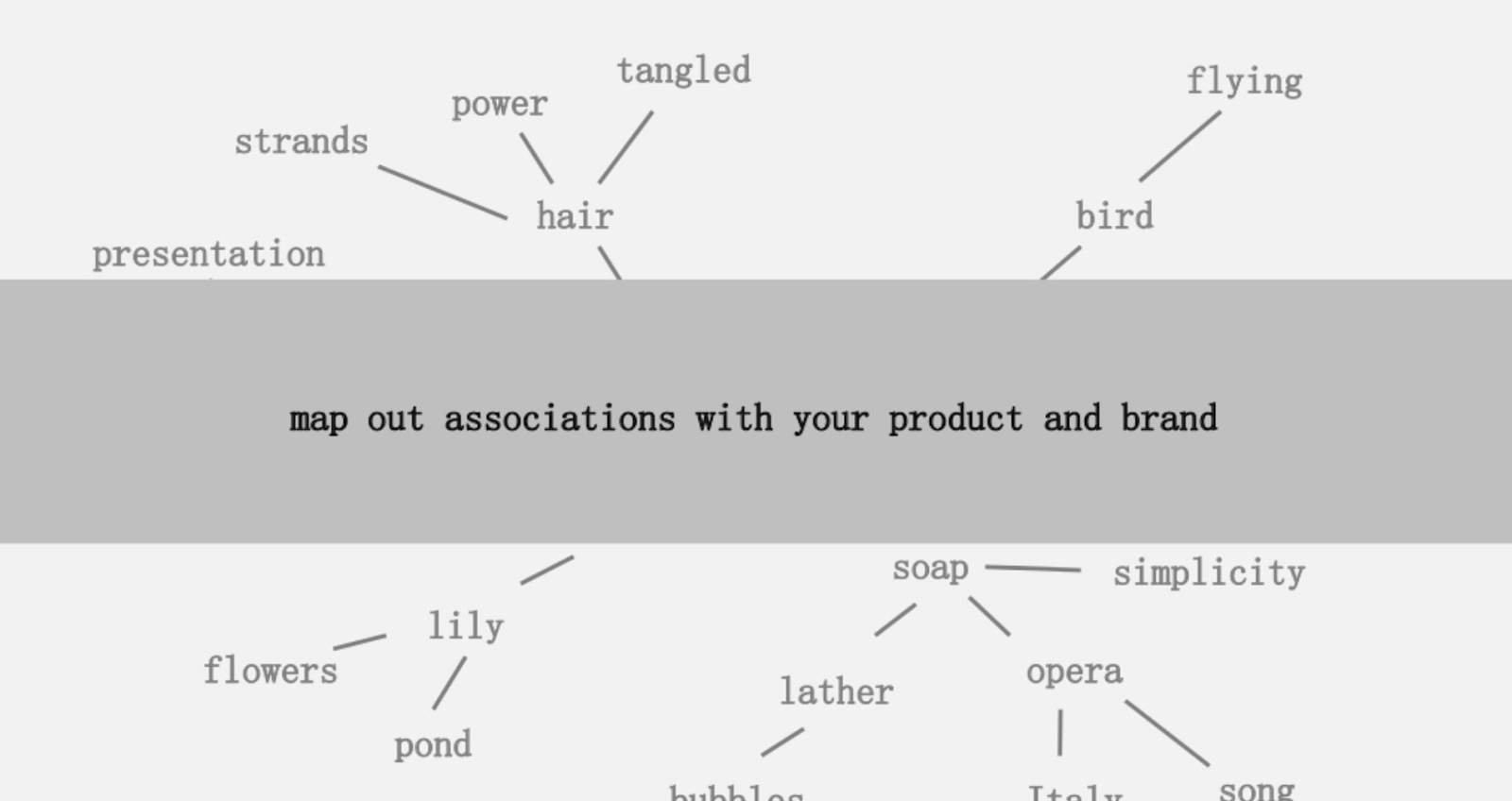
Una de las ideas ofrecidas fue crear un mapa visual de la conexión de las palabras asociadas con su producto o marca para que pueda retroceder y buscar formas de combinar las asociaciones en algo interesante. El objetivo es la producción de ideas, que él define como “ una combinación novedosa de elementos previamente desconectados de una manera que agrega valor”.
En este artículo, adoptamos un enfoque mucho más centrado en el lado izquierdo del cerebro, mediante el uso de Python, la API de lenguaje de Google, junto con Wikipedia, para explorar las asociaciones de entidades que existen a partir de un tema inicial. El objetivo es una vista de alto nivel de las relaciones entre entidades a lo largo del gráfico de temas. Este artículo no es para el lector promedio. Los lectores que estén familiarizados con Python y tengan al menos un nivel básico de capacidad de codificación lo encontrarán mucho más instructivo.
La idea
Siguiendo la idea de mapeo de Mark Johnstone, pensé que sería interesante dejar que Google y Wikipedia definieran una estructura de temas a partir de un tema inicial o una página web. El objetivo es construir visualmente el mapeo de las relaciones con el tema principal, en un gráfico en forma de árbol que se puede revisar para buscar conexiones y posiblemente generar ideas de contenido. La siguiente imagen representa la idea de diseño inicial.
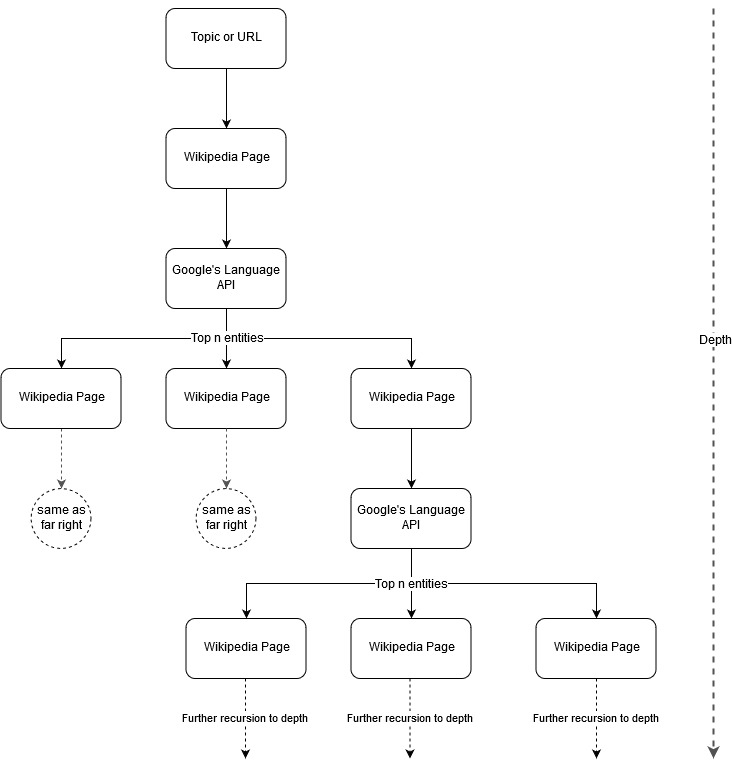
Esencialmente, le damos a la herramienta un tema o URL, y dejamos que la API de idioma de Google seleccione las n principales (3 en nuestros ejemplos) entidades (que incluyen las URL de Wikipedia) para cada página de entidad y continuamos construyendo recursivamente un gráfico de red para cada entidad encontrada. hasta una profundidad máxima.
Antecedentes de herramientas utilizadas
API de idioma de Google
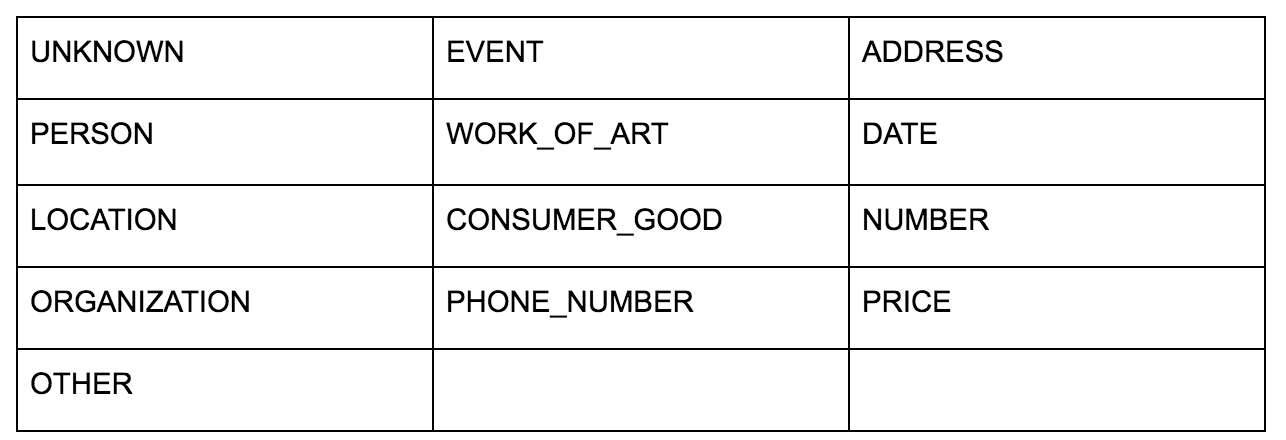
La API de idioma de Google le permite pasar texto sin formato o HTML y mágicamente devuelve todas las diversas entidades asociadas con el contenido. La API hace más que esto, pero para este análisis, nos centraremos solo en esta parte. Aquí hay una lista de los tipos de entidades que devuelve:
La identificación de entidades ha sido una parte fundamental del Procesamiento del Lenguaje Natural (NLP) durante mucho tiempo y la terminología correcta para la tarea es Reconocimiento de Entidades Nombradas (NER). NER es una tarea difícil porque muchas palabras tienen diferentes significados según el contexto utilizado, por lo que las herramientas de NLP o las API deben comprender el contexto completo que rodea a los términos para poder identificarlos correctamente como una entidad particular.
Ofrecí una descripción bastante detallada de esta API, y de las entidades en particular, en un artículo en opensource.com si desea ponerse al día con algún contexto antes de terminar este artículo.
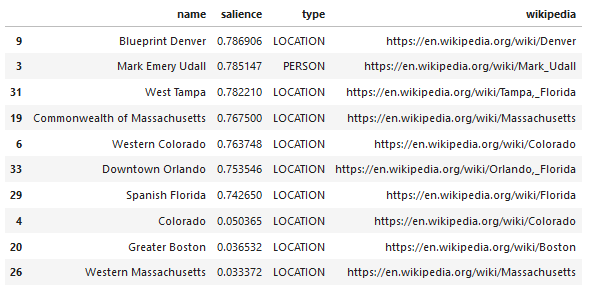
Una característica interesante de Language API de Google es que, además de encontrar entidades relevantes, también marca qué tan relacionadas están con el documento general (prominencia) y, para algunos, proporciona un artículo relacionado de Wikipedia (gráfico de conocimiento) que representa la entidad.
Aquí hay un resultado de muestra de lo que devuelve la API (ordenado por prominencia):
Desarrollador Oncrawl
 Aprende más
Aprende másPitón
Python es un lenguaje de software que se ha vuelto popular en el espacio de la ciencia de datos debido a un conjunto grande y creciente de bibliotecas que facilitan la ingesta, limpieza, manipulación y análisis de grandes conjuntos de datos. También se beneficia de un entorno colaborativo llamado cuadernos Jupyter que permite a los usuarios probar y anotar fácilmente su código sin esfuerzo.
Para esta revisión, usaremos algunas bibliotecas clave que nos permitirán hacer algunas cosas interesantes con los datos de NLP de Google.
- Pandas: piense en poder crear scripts de Microsoft Excel para leer, guardar, analizar o reorganizar hojas de cálculo y tendrá una idea de lo que hace Pandas. Pandas es increíble. (Enlace)
- Networkx: Networkx es una herramienta para construir gráficos de nodos y aristas que definen las relaciones entre los nodos. También tiene soporte incorporado para trazar los gráficos para que sean fáciles de visualizar. (Enlace)
- Pywikibot: Pywikibot es una biblioteca que te permite interactuar con Wikipedia para buscar, editar, encontrar relaciones, etc., con todo el contenido de cada sitio de Wikipedia. (Enlace)
El proceso
Estamos compartiendo un cuaderno de Google Colab aquí que se puede usar para seguir. (Un agradecimiento especial a Tyler Reardon por verificar la cordura del artículo y este cuaderno).
configurando
Las primeras celdas del cuaderno se ocupan de la instalación de algunas bibliotecas, haciendo que esas bibliotecas estén disponibles para Python y proporcionando credenciales y un archivo de configuración para la API de lenguaje de Google y Pywikibot, respectivamente. Aquí están todas las bibliotecas que necesitamos instalar para garantizar que la herramienta pueda ejecutarse:
- pandas
- peticiones
- httplib2
- Google-nube-lenguaje
- piwikibot
- redx
- validadores
- Bs4
Nota: La parte más difícil de poder ejecutar este portátil es obtener las credenciales de Google para acceder a sus API. Para aquellos sin experiencia con esto, esto tomará una hora más o menos para averiguarlo. Vinculamos las Instrucciones para obtener las credenciales de la cuenta de servicio en la parte superior del cuaderno para ayudarlo. A continuación se muestra un ejemplo de cómo incluimos el nuestro.
Funciones para ganar
En la celda indicada por "Definir algunas funciones para Google NLP", desarrollamos ocho funciones que manejan cosas como consultar la API de lenguaje, interactuar con Wikipedia, extraer texto de páginas web y crear y trazar gráficos. Las funciones son esencialmente pequeñas unidades de código que toman algunos datos de configuración, hacen algún trabajo y producen algo. Todas las funciones se comentan para indicar las variables que toman y lo que producen.

Probando la API
Las siguientes dos celdas toman una URL, extraen el texto de la URL y extraen las entidades de la API de idioma de Google. Uno extrae solo las entidades que tienen URL de Wikipedia y el otro extrae todas las entidades de esa página.
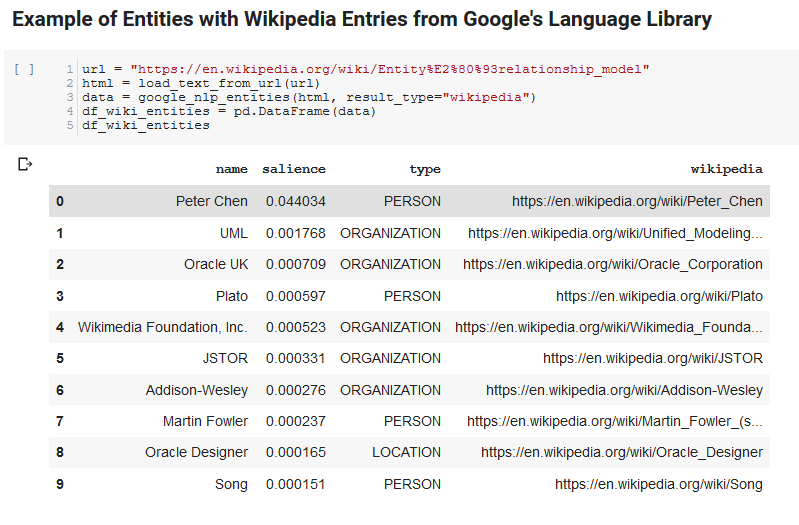
Este fue un primer paso importante solo para obtener la parte de extracción de contenido correcta y comprender cómo funcionaba Language API y devolvía datos.
Redx
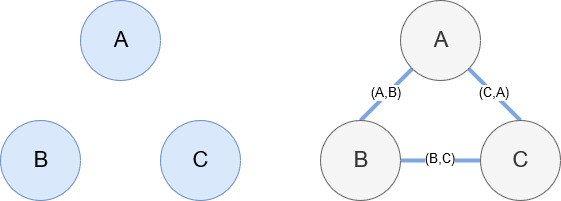
Networkx, como se mencionó anteriormente, es una biblioteca maravillosa con la que es bastante intuitivo jugar. Esencialmente, debe decirle cuáles son sus nodos y cómo están conectados los nodos. Por ejemplo, en la imagen de abajo, le damos a Networkx tres nodos (A,B,C). Luego le decimos a Networkx que están conectados por aristas (A,B), (B,C), (C,A) que definen las relaciones entre los nodos. Para nuestro uso, las entidades con URL de Wikipedia serán los nodos y los bordes están definidos por nuevas entidades que se encuentran en una página de entidad actual. Entonces, si estamos revisando la página de Wikipedia para la Entidad A, y en esa página se descubre la Entidad B, entonces esa es una ventaja entre la Entidad A y la Entidad B.
Poniendolo todo junto
La siguiente sección del cuaderno se llama Bifurcación de temas de Wikipedia por URL. Aquí es donde ocurre la magia. Anteriormente habíamos definido una función especial (recurse_entities) que se repite a través de páginas en Wikipedia siguiendo nuevas entidades definidas por la API de lenguaje de Google. También agregamos una función realmente difícil de entender (hierarchy_pos) que extrajimos de Stack Overflow que hace un buen trabajo al presentar un gráfico similar a un árbol con muchos nodos. En la celda a continuación, definimos la entrada como "Optimización del motor de búsqueda" y especificamos una profundidad de 3 (esta es la cantidad de páginas que sigue recursivamente) y un límite de 3 (esta es la cantidad de entidades que extrae por página).
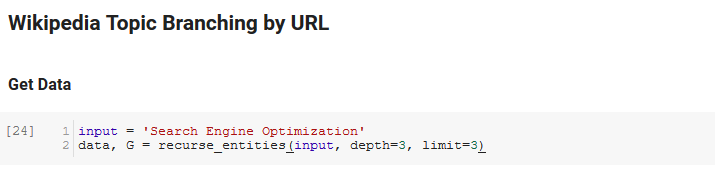
Ejecutándolo para el término "Optimización de motor de búsqueda" podemos ver el siguiente camino que tomó la herramienta, comenzando en la página de Optimización de motor de búsqueda de Wikipedia (Nivel 0) y siguiendo, recursivamente, las páginas hasta la profundidad máxima especificada (3).

Luego tomamos todas las entidades encontradas y las agregamos a un DataFrame de Pandas, lo que hace que sea muy fácil guardarlo como un CSV. Clasificamos estos datos por prominencia (que es la importancia de la entidad para la página en la que se encontró), pero esta puntuación es un poco engañosa en este contexto porque no le dice qué tan relacionada está la entidad con su término original (" optimización de motores de búsqueda”). Dejaremos ese trabajo adicional al lector.

Finalmente, trazamos el gráfico construido por la herramienta para mostrar la conexión de todas las entidades. En la celda de abajo, los parámetros que puede pasar a la función son: ( G : el Gráfico construido antes por la función recurse_entities, w: el ancho de la gráfica, h: la altura de la gráfica, c: el porcentaje circular de la trama y nombre de archivo: el archivo PNG que se guarda en la carpeta de imágenes).

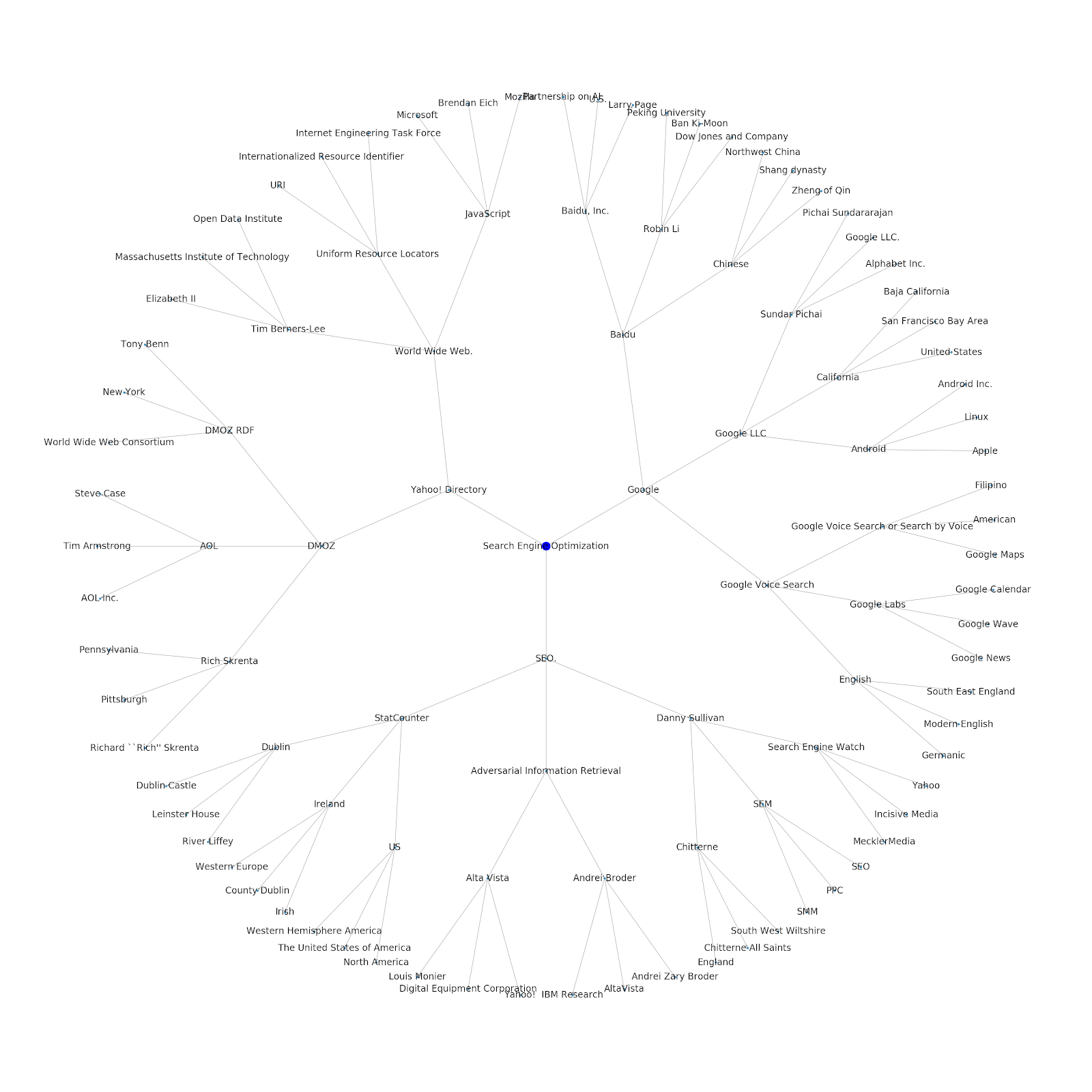
Agregamos la capacidad de darle un tema inicial o una URL inicial. En este caso, observamos las entidades asociadas con el artículo Los problemas de indexación de Google continúan, pero este es diferente
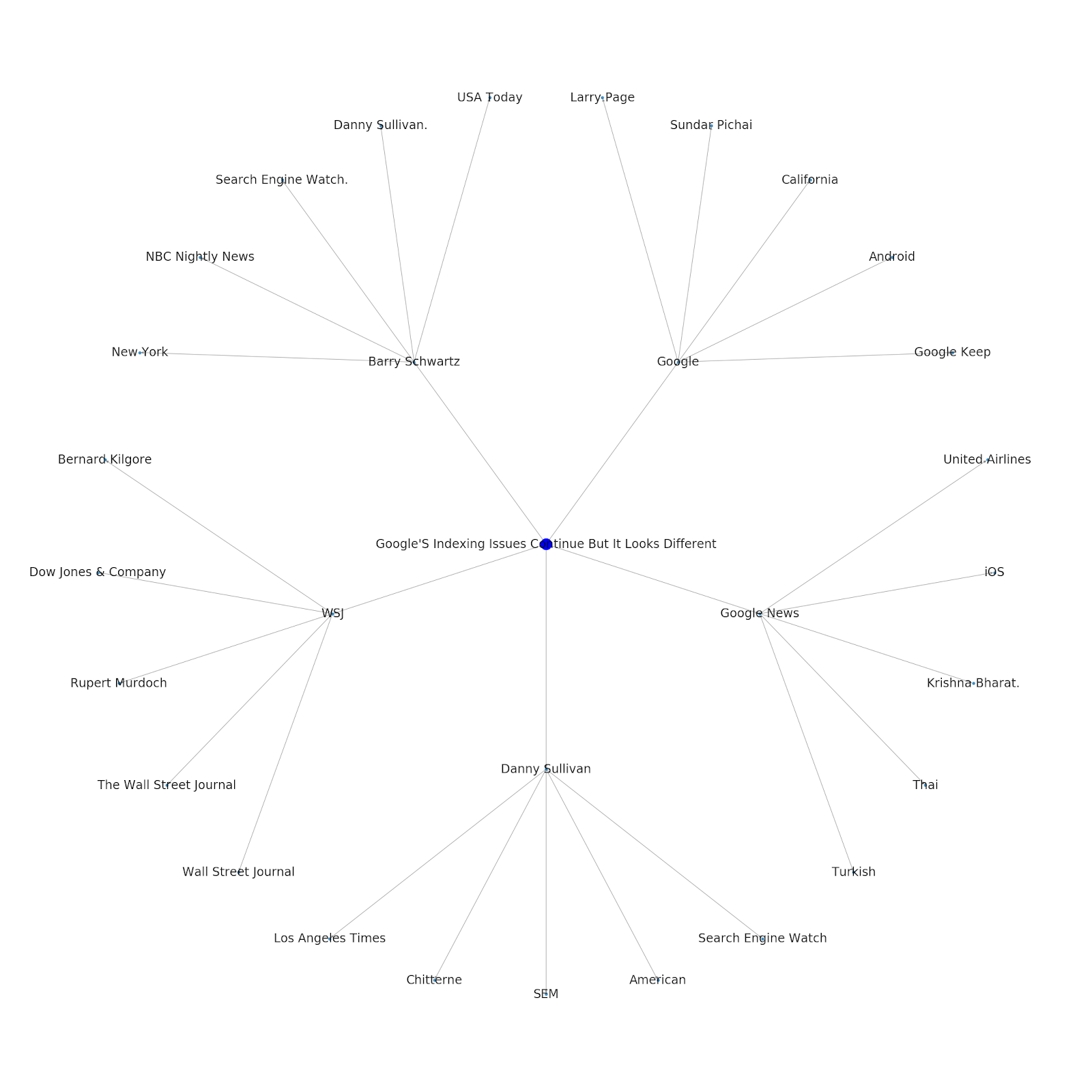
Aquí está el gráfico de entidades de Google/Wikipedia para Python.
Lo que esto significa
Comprender la capa de temas de Internet es interesante desde el punto de vista de SEO porque te obliga a pensar en términos de cómo se conectan las cosas y no solo en consultas individuales. Dado que Google está utilizando esta capa para hacer coincidir las afinidades de los usuarios individuales con los temas, como se menciona en su reintroducción de Google Discover, puede convertirse en un flujo de trabajo más importante para los SEO centrados en datos. En el gráfico "Python" anterior, se puede inferir que la familiaridad de un usuario con los temas relacionados con un tema semilla puede ser un indicador razonable de su nivel de experiencia con el tema semilla.
El siguiente ejemplo muestra a dos usuarios resaltados en verde que muestran su interés histórico o su afinidad con temas relacionados. El usuario de la izquierda, que entiende qué es un IDE y qué significan PyPy y CPython, sería un usuario mucho más experimentado con Python que alguien que sabe que es un lenguaje, pero no mucho más. Esto sería fácil de convertir en puntajes numéricos para cada tema, para cada usuario.

Conclusión
Mi objetivo hoy era compartir un proceso bastante estándar por el que paso para probar y revisar la eficacia de varias herramientas o API que usan Jupyter Notebooks. Explorar el gráfico de temas es increíblemente interesante y esperamos que encuentre que las herramientas compartidas le brindan la ventaja que necesita para comenzar a explorar por sí mismo. Con estas herramientas, puede crear gráficos de temas que exploran muchos niveles de relación, solo limitados al alcance de la cuota de la API de idiomas de Google (que es 800,000 por día). (Actualización: el precio se basa en unidades de 1,000 caracteres Unicode enviados a la API y es gratis hasta 5k unidades. Dado que los artículos de Wikipedia pueden ser largos, desea controlar su gasto. Felicitaciones a John Murch por señalar esto). Si mejora el cuaderno o encuentra casos interesantes, espero que me lo haga saber. Puedes encontrarme en @jroakes en Twitter.