
Las claves para construir un Robots.txt que funcione
Publicado: 2020-02-18Los bots, también conocidos como rastreadores o arañas, son programas que "viajan" a través de la Web automáticamente de un sitio web a otro utilizando los enlaces como camino. Aunque siempre han presentado ciertas curiosidades, los archivos robot.txt pueden ser herramientas muy eficaces. Los motores de búsqueda como Google y Bing usan bots para rastrear el contenido de la web. El archivo robots.txt brinda orientación a los diferentes bots sobre qué páginas no deben rastrear en su sitio. También puede vincular a su mapa del sitio XML desde robots.txt para que el bot tenga un mapa de cada página que debe rastrear.
¿Por qué es útil robots.txt?
robots.txt limita la cantidad de páginas que un bot necesita rastrear e indexar en el caso de los bots de motores de búsqueda. Si desea evitar que Google rastree las páginas de administración, puede bloquearlas en su archivo robots.txt para intentar mantener una página fuera de los servidores de Google.
Además de evitar que las páginas se indexen, los archivos robots.txt son excelentes para optimizar el presupuesto de rastreo. El presupuesto de rastreo es la cantidad de páginas que Google ha determinado que rastreará en su sitio. Por lo general, los sitios web con más autoridad y más páginas tienen un presupuesto de rastreo mayor que los sitios web con un número bajo de páginas y poca autoridad. Dado que no sabemos cuánto presupuesto de rastreo se asigna a nuestro sitio, queremos aprovechar al máximo este tiempo permitiendo que Googlebot acceda a las páginas más importantes en lugar de rastrear las páginas que no queremos que se indexen.
Un detalle muy importante que debe saber sobre robots.txt es que, si bien Google no rastreará las páginas bloqueadas por robots.txt, aún pueden indexarse si la página está vinculada desde otro sitio web. Para evitar correctamente que sus páginas se indexen y aparezcan en los resultados de búsqueda de Google, debe proteger con contraseña los archivos en su servidor, usar la etiqueta meta noindex o el encabezado de respuesta, o eliminar la página por completo (responda con 404 o 410). Para obtener más información sobre el rastreo y el control de la indexación, puede leer la guía de robots.txt de OnCrawl.
[Estudio de caso] Administrar el rastreo de bots de Google
 Lea el estudio de caso
Lea el estudio de casoSintaxis correcta de Robots.txt
La sintaxis de robots.txt a veces puede ser un poco complicada, ya que diferentes rastreadores interpretan la sintaxis de manera diferente. Además, algunos rastreadores sin reputación ven las directivas de robots.txt como sugerencias y no como una regla definitiva que deben seguir. Si tiene información confidencial en su sitio, es importante usar protección con contraseña además de bloquear a los rastreadores usando robots.txt
A continuación, he enumerado algunas cosas que debe tener en cuenta cuando trabaje en su archivo robots.txt:
- El archivo robots.txt debe vivir bajo el dominio y no bajo un subdirectorio. Los rastreadores no buscan archivos robots.txt en los subdirectorios.
- Cada subdominio necesita su propio archivo robots.txt:
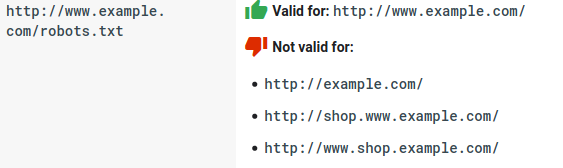
- Robots.txt distingue entre mayúsculas y minúsculas:
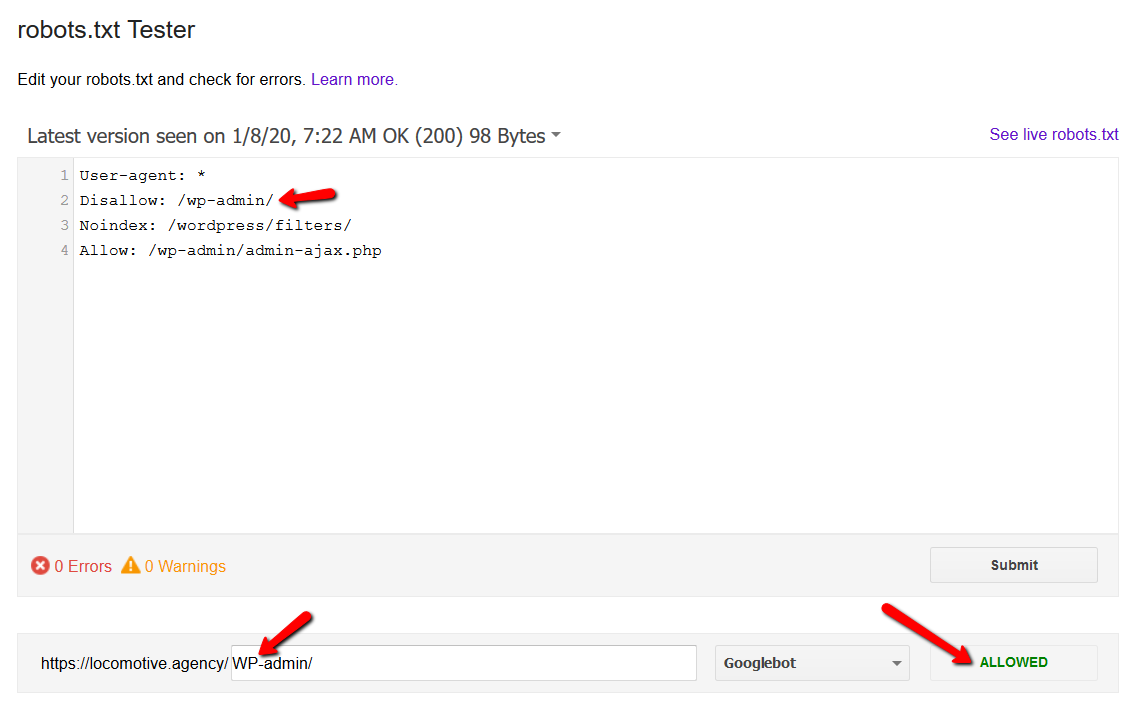
- La directiva noindex: cuando usa noindex en robots.txt, funcionará de la misma manera que disallow. Google dejará de rastrear la página pero la mantendrá en su índice. @jroakes y yo creamos una prueba en la que usamos la directiva Noindex en el artículo /wordpress/filters/ y enviamos la página a Google. Puede ver en la captura de pantalla a continuación que muestra que la URL ha sido bloqueada:
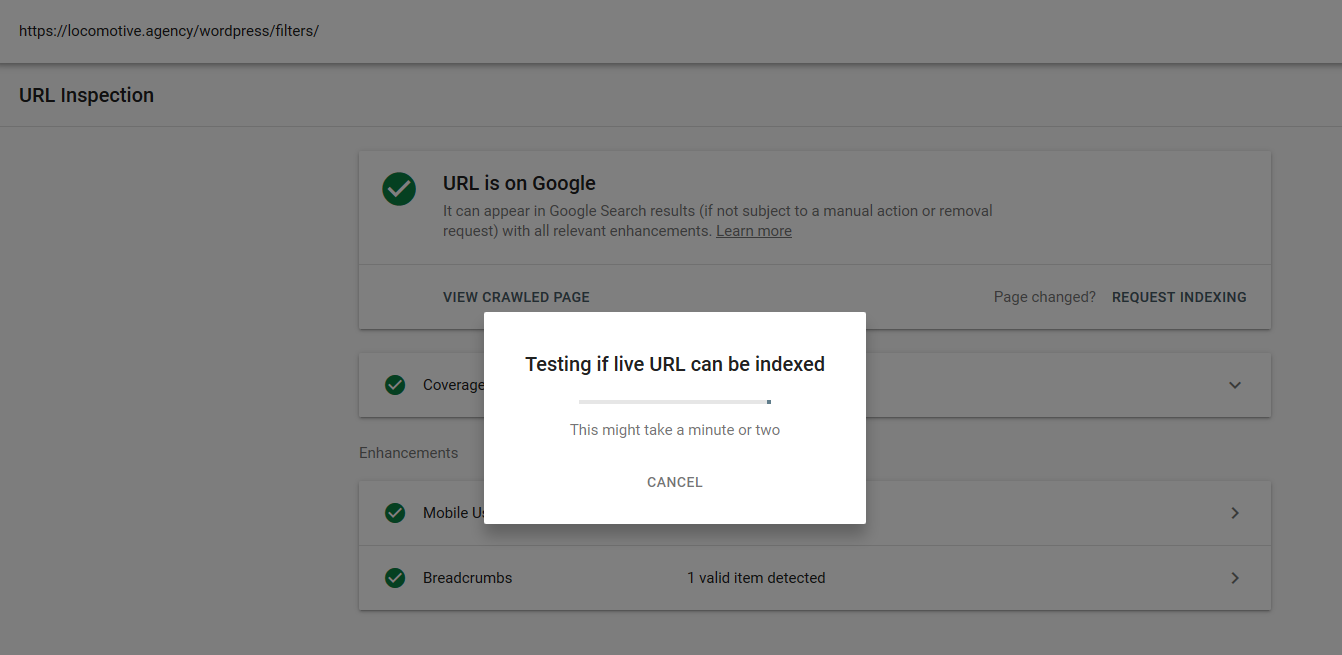
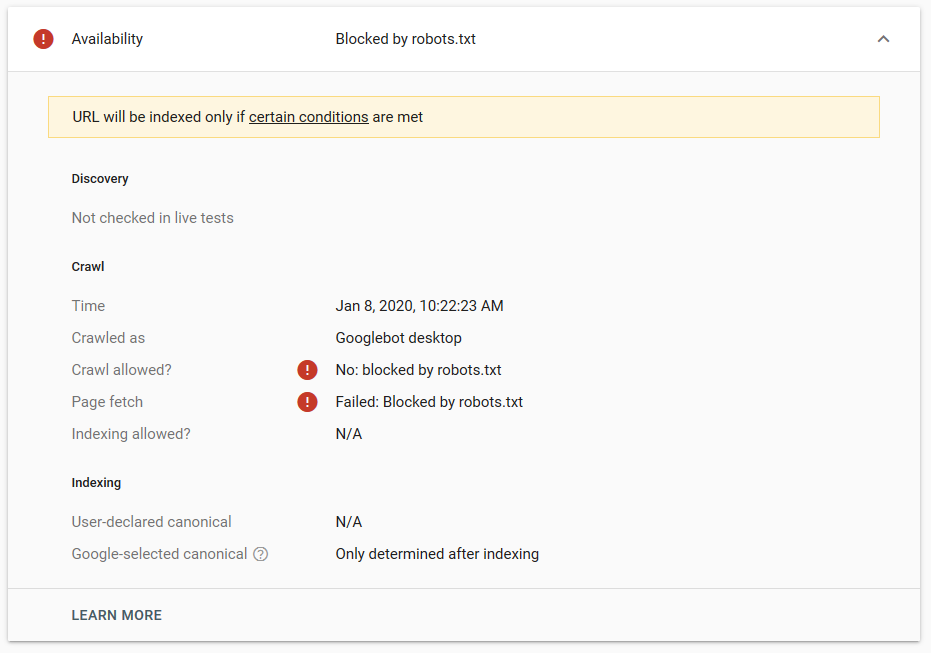
Hicimos varias pruebas en Google y la página nunca fue eliminada del índice:
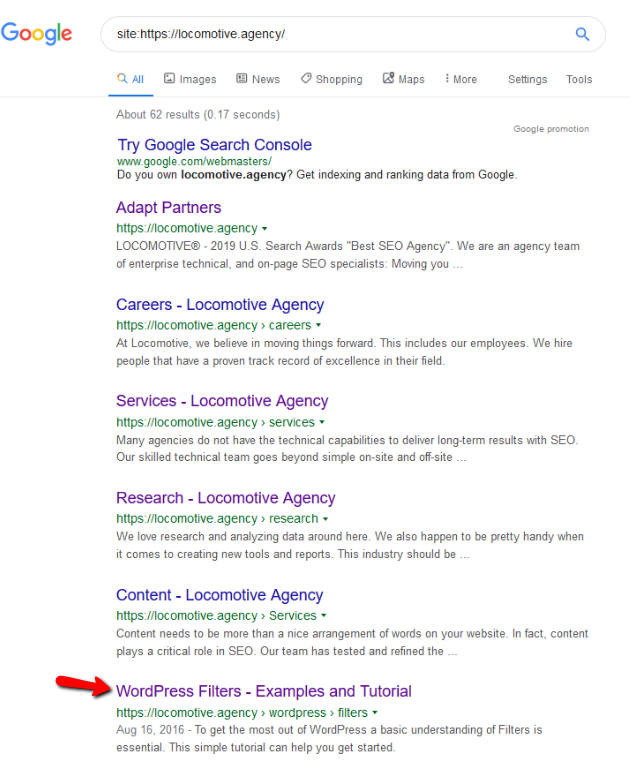

Hubo una discusión el año pasado sobre el funcionamiento de la directiva noindex en robots.txt, eliminando páginas excepto Google. Aquí hay un hilo donde Gary Illyes declaró que iba a desaparecer. En esta prueba, podemos ver que la solución de Google está en su lugar, ya que la directiva noindex no eliminó la página de los resultados de búsqueda.
Recientemente, hubo otro hilo interesante en Twitter de Christian Oliveira, donde compartió varios detalles a tener en cuenta al trabajar en su archivo robots.txt.
- Si queremos tener reglas genéricas y reglas solo para Googlebot, debemos duplicar todas las reglas genéricas en el conjunto de reglas User-agent: Google bot. Si no se incluyen, Googlebot ignorará todas las reglas:

- Otro comportamiento confuso es que la prioridad de las reglas (dentro del mismo grupo User-agent) no está determinada por su orden, sino por la longitud de la regla.
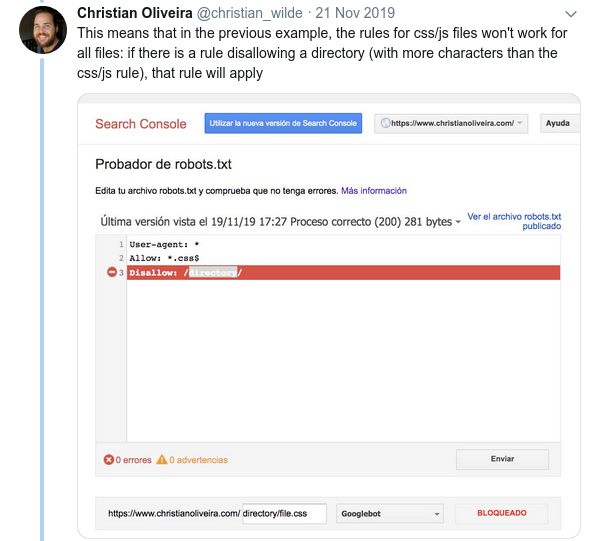
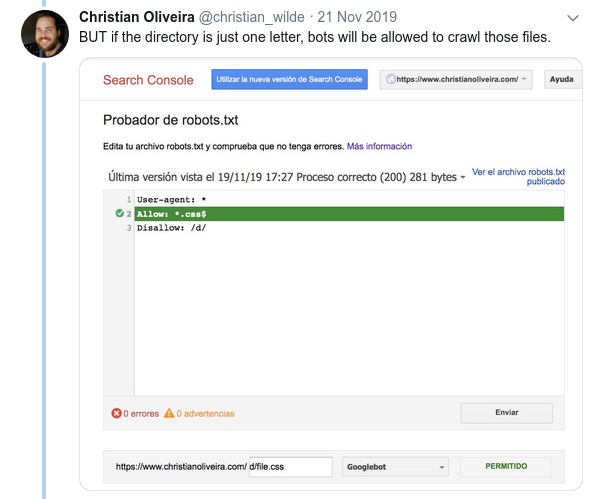
- Ahora, cuando tiene dos reglas, con la misma longitud y comportamiento opuesto (una que permite el rastreo y la otra que no lo permite), se aplica la regla menos restrictiva:
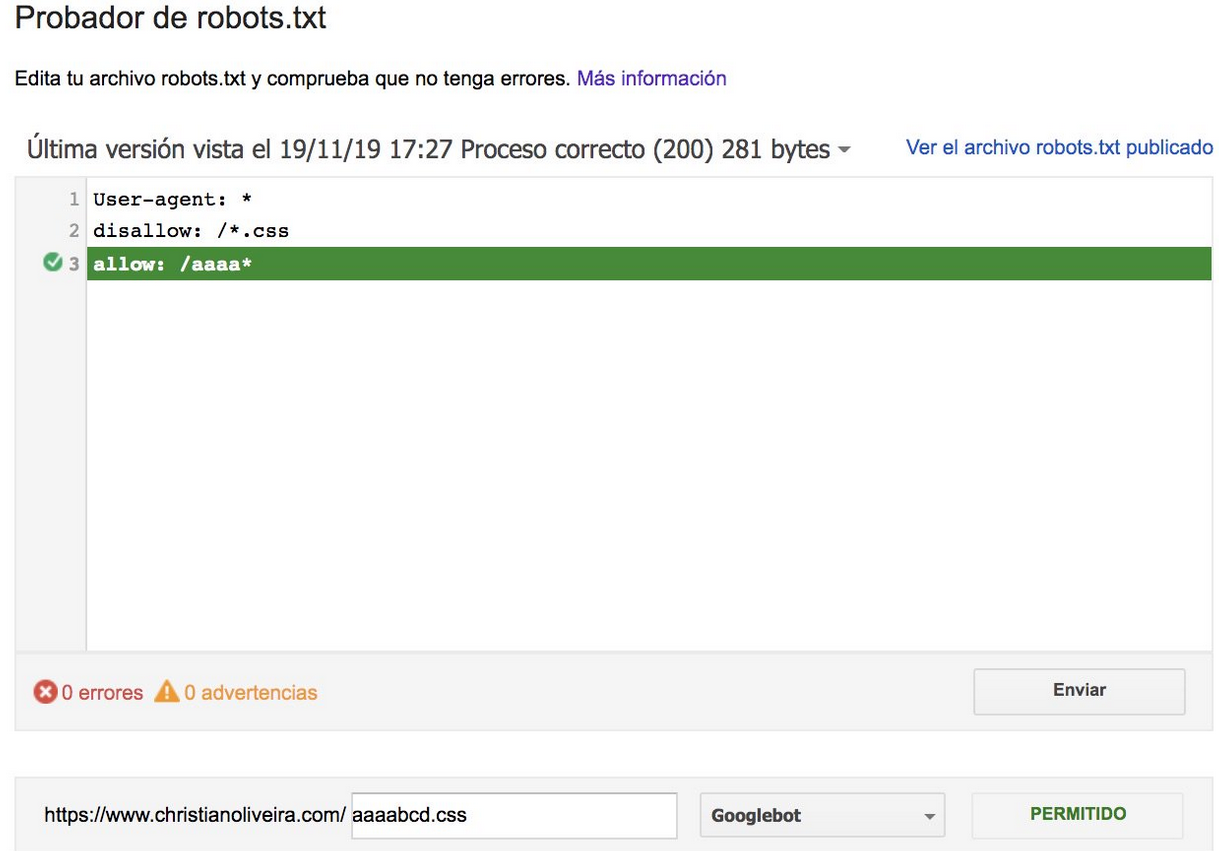
Para obtener más ejemplos, lea las especificaciones de robots.txt proporcionadas por Google.
Herramientas para probar su Robots.txt
Si desea probar su archivo robots.txt, hay varias herramientas que pueden ayudarlo y también un par de repositorios de github si desea crear el suyo propio:
- Destilado
- Google ha dejado la herramienta de prueba de robots.txt de la antigua consola de búsqueda de Google aquí
- en pitón
- en C++
Resultados de muestra: uso efectivo de Robots.txt para comercio electrónico
A continuación, incluí un caso en el que estábamos trabajando con un sitio de Magento que no tenía un archivo robots.txt. Magento, así como otros CMS, tienen páginas de administración y directorios con archivos que no queremos que Google rastree. A continuación, incluimos un ejemplo de algunos de los directorios que incluimos en el archivo robots.txt:
# # Directorios generales de Magento No permitir: /aplicación/ No permitir: / descargador / No permitir: / errores / No permitir: / incluye / No permitir: /lib/ No permitir: /pkginfo/ No permitir: / caparazón / No permitir: /var/ # # No indexe la página de búsqueda y las categorías de enlaces no optimizados No permitir: /catalog/product_compare/ No permitir: /catálogo/categoría/vista/ No permitir: /catálogo/producto/ver/ No permitir: /catálogo/producto/galería/ No permitir: /búsqueda de catálogo/
La gran cantidad de páginas que no estaban destinadas a ser rastreadas estaba afectando su presupuesto de rastreo y Googlebot no podía rastrear todas las páginas de productos en el sitio.
Puede ver en la imagen a continuación cómo aumentaron las páginas indexadas después del 25 de octubre, que fue cuando se implementó el archivo robots.txt:
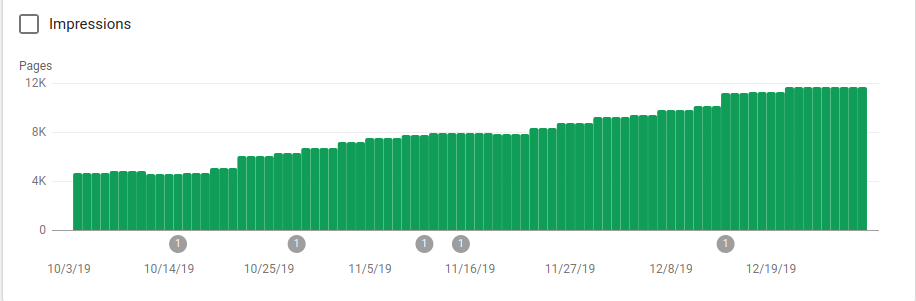
Además de bloquear varios directorios que no estaban destinados a ser rastreados, los robots incluyeron un enlace a los mapas del sitio. En la captura de pantalla a continuación, puede ver cómo aumentó la cantidad de páginas indexadas en comparación con las páginas excluidas:
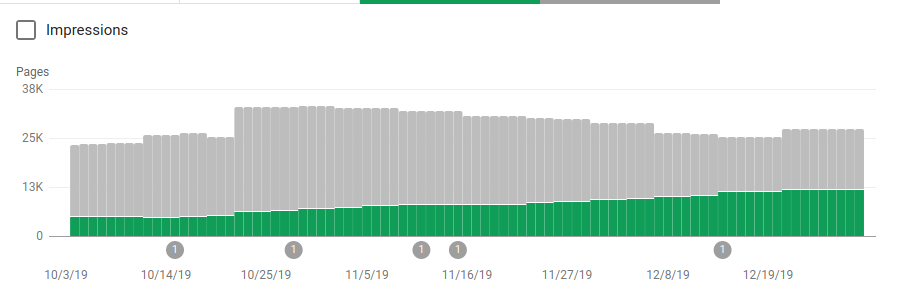
Hay una tendencia positiva en las páginas válidas indexadas como lo muestran las barras verdes y una tendencia negativa en las páginas excluidas representadas por las barras grises.
Terminando
La importancia de robots.txt a veces puede subestimarse y, como puede ver en esta publicación, hay muchos detalles que deben tenerse en cuenta al crear uno. Pero el trabajo vale la pena: he mostrado algunos de los resultados positivos que puede obtener al configurar correctamente un archivo robots.txt.