
Cómo dar forma a un fragmento en la era de Google como editor
Publicado: 2019-10-22Google se ha visto a sí mismo como un editor de contenido durante mucho tiempo, aunque la tendencia se ha vuelto difícil de ignorar en los últimos años. Esto se ha visto facilitado en parte por los avances en el aprendizaje automático y por las nuevas características de la página de resultados del motor de búsqueda (SERP).
“Google como editor de contenido” es un problema potencial para muchos propietarios de sitios web, ya que presenta una elección difícil. Deberías:
- ¿Protege tu contenido y corres el riesgo de quedar fuera de los resultados de Google?
- ¿Proporcionar fuentes de contenido gratuitas a Google sabiendo que es posible que Google no envíe visitantes a su sitio?
Las nuevas etiquetas de administración de fragmentos que entrarán en vigencia a fines de octubre de 2019 pueden verse como una declaración de intenciones de Google. También son un paso en la dirección correcta al brindarles a los propietarios de sitios web un medio para proteger su contenido y controlar cómo aparecen sus páginas en los SERP.
¿Por qué preocuparse por el contenido de calidad?
Las propiedades de Google todavía proporcionan alrededor del 60 % del tráfico a los sitios web, dependiendo de la vertical, por lo que no jugar el juego de Google tiene un efecto negativo potencialmente enorme en la visibilidad y el tráfico de un sitio web. Pero al mismo tiempo, a través de EAT y de las Directrices para evaluadores de calidad, Google ha establecido claramente que el contenido de calidad es lo que buscan los usuarios de Internet, y que los sitios web deben invertir en producirlo para poder sobrevivir.
Esa inversión en contenido único y de alta calidad es algo que, naturalmente, el propietario de un sitio web debería querer proteger. Al regalar contenido, los sitios web permiten que otros proveedores (en este caso, motores de búsqueda) se beneficien de su tiempo, dinero y experiencia.
¿Cómo utiliza Google el contenido?
Google usa, remezcla y reescribe el contenido para brindar respuestas a las preguntas que plantean los usuarios de los motores de búsqueda. Estas respuestas se muestran en muchas formas en los SERP.
Listados de resultados de búsqueda, o "fragmentos"
Google compone un fragmento para una página web determinada en los resultados de búsqueda utilizando diferentes elementos extraídos originalmente de la propia página web:
- etiqueta <título>
- <meta descripción=”Fragmento de texto”> etiqueta
- Marcado de Schema.org para datos estructurados admitidos
- URL
- Favicon (en resultados móviles en algunas regiones)
Hoy en día, pocos de estos se utilizan tal cual. Google se reserva el derecho de reemplazar el favicon. Google declara explícitamente que su "generación de títulos y descripciones de página está completamente automatizada y... [Google usa] una serie de fuentes diferentes para esta información, incluida la información descriptiva en el título y las metaetiquetas de cada página". Finalmente, Google ha comenzado a suprimir las URL en las SERP, como se vio en pruebas recientes.
La eliminación de URL de Google en SERP puede ayudar ligeramente a los TLD "malos".
Si no puede saber si es un .io, .org, .net, .ie, etc., no puede predisponerse contra ellos y hacer clic en ese .com que parece más legítimo. Puede que no sea un gran impacto, pero podría ser uno sutil que se vuelve más grande con el tiempo. pic.twitter.com/CcQ2E0lVtZ
— Ross Hudgens (@RossHudgens) 21 de octubre de 2019
Fragmentos destacados
Google crea fragmentos destacados, que aparecen antes de las listas de resultados de búsqueda, al extraer contenido de una página web que parece responder a la pregunta del buscador. Hubo varios episodios de fragmentos destacados que aparecieron sin una atribución (o sin una atribución visible o de fácil acceso) en febrero y junio de 2019. En cada caso, Google denunció la intención de eludir los derechos de los editores y afirmó que la falta de atribución era un error.
Definiciones, clima y comida.
La búsqueda de definiciones de diccionario o el clima en una ubicación específica produce una respuesta en el cuadro de autocompletar, sin atribución y sin necesidad de ejecutar una búsqueda.
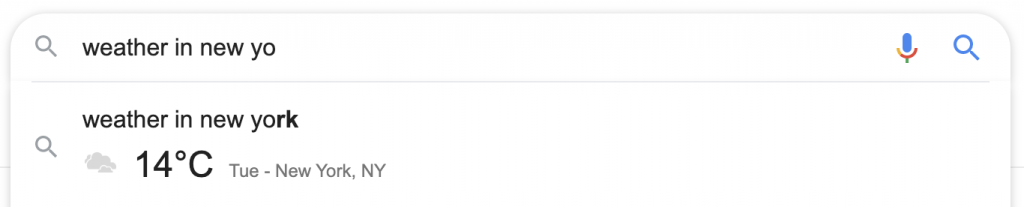
En el caso de una definición, si se presiona el botón de búsqueda, está disponible la definición completa, completa con sonido, sinónimos y otras características en SERP. El buscador no necesita visitar el sitio del diccionario de Oxford, y la atribución de Oxford aparece en un pequeño texto gris debajo del cuadro de definición.
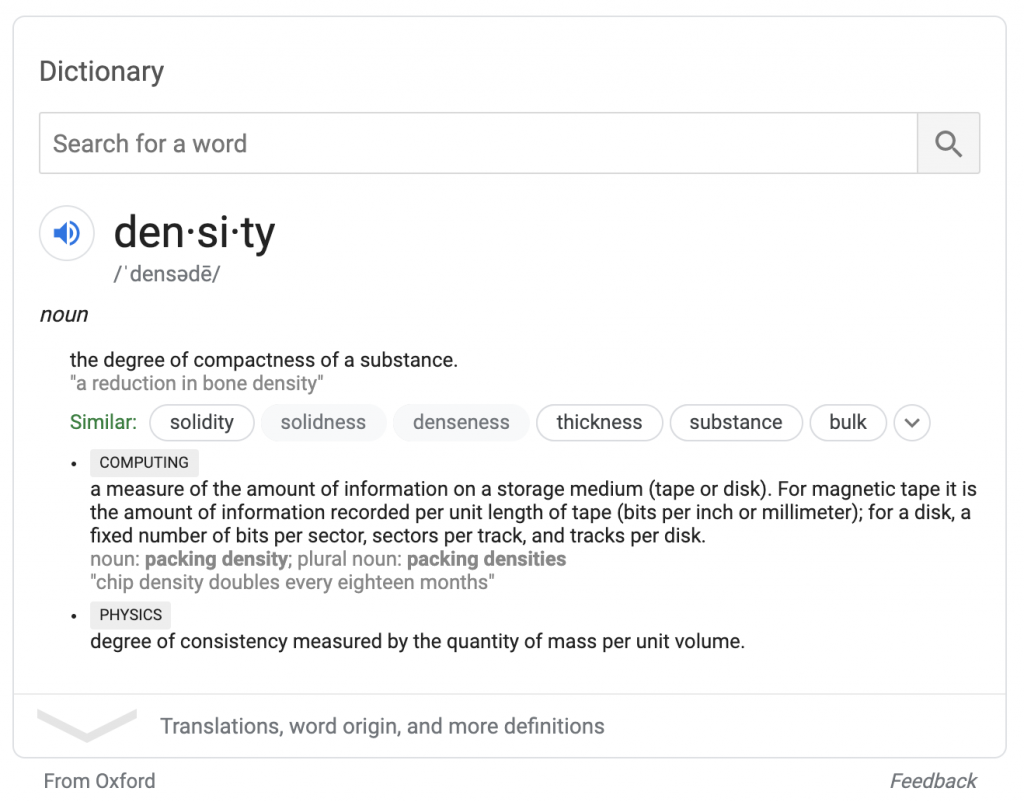
Las búsquedas meteorológicas completas proporcionan un cuadro de pronóstico similar basado en datos de weather.com. Al igual que la atribución de Oxford, la atribución de weather.com aparece debajo del cuadro; los buscadores pueden interactuar con los datos en el cuadro sin tener que visitar weather.com.
Otro resultado de búsqueda similar es para datos nutricionales y composición de alimentos:
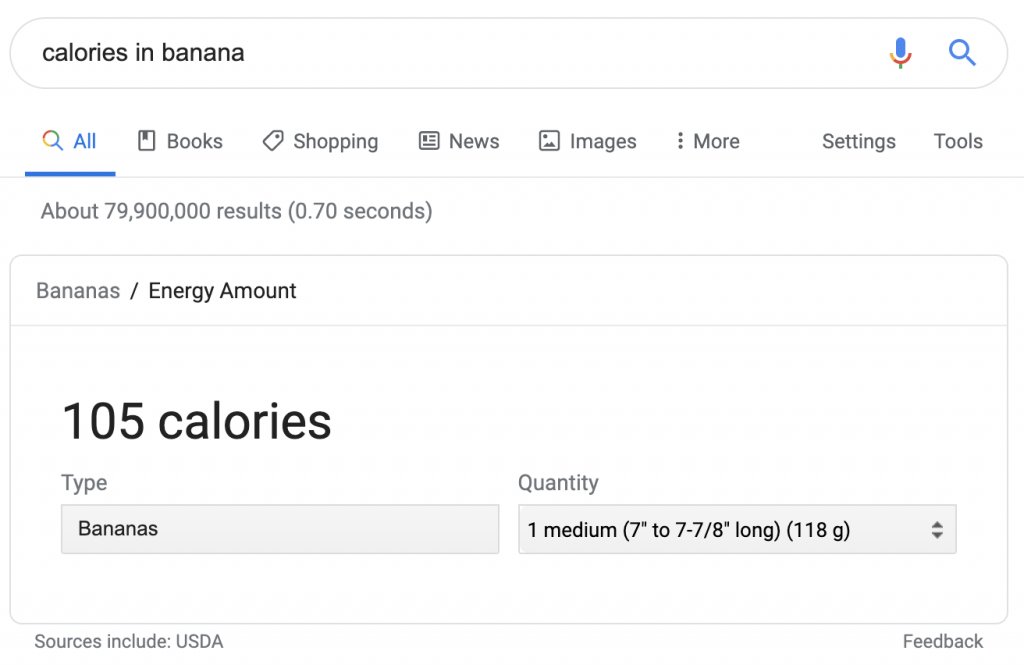
Sin embargo, en este caso, la atribución aparece como "fuentes incluidas". Si se utilizan otras fuentes, no son visibles ni accesibles.
Resultados orientados a lo local
Muchos resultados relacionados con la actividad local también se basan en diversas fuentes para crear un SERP que proporciona una variedad de información agregada y cotejada. En lugar de visitar diferentes sitios web, un buscador puede, por ejemplo, ver la lista de películas que se están proyectando cerca de ellos, buscar horarios en diferentes cines y encontrar detalles (críticas, sinopsis y más) sobre películas individuales. En ningún momento el buscador necesita abandonar el SERP seleccionado por Google.
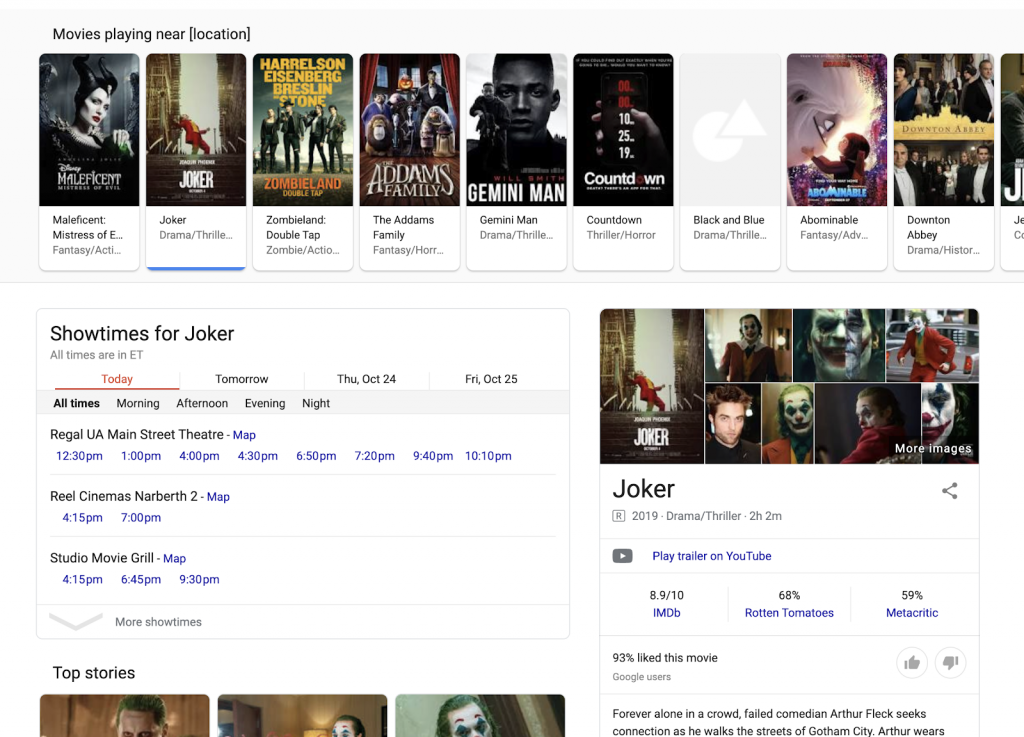
Este tipo de SERP se está expandiendo a muchas áreas diferentes, incluidos los viajes.
Historias de AMP
Las historias de AMP proporcionan un modo "centrado en la historia" para el "consumo de noticias en dispositivos móviles". Son un ejemplo de cómo la indexación basada en entidades ha mejorado la capacidad de Google para extraer contenido de diferentes fuentes y remezclarlo. En algunas historias creadas por Google para apariciones de celebridades, Google ha emparejado una imagen de una fuente con texto de otra, por ejemplo.
Paneles de conocimiento
Los paneles de conocimiento son "cuadros de información que aparecen en Google cuando busca entidades" que forman parte del gráfico de conocimiento de Google. La información que se muestra en estos paneles proviene de múltiples fuentes, que Google enumera como:
- socios de datos que proporcionan datos fidedignos sobre temas específicos como películas o música
- fuentes web abiertas
- entidades verificadas que han sugerido ediciones a los hechos en sus propios paneles de conocimiento
- una vista previa de los resultados de Google Images para la entidad
Google indicó anteriormente que su Knowledge Graph se basa en fuentes como Wikipedia/Wikidata, el World Factbook de la CIA, datos estructurados en la web pública, Google My Business y más.
También pueden mostrar entidades relacionadas, lo que permite a los usuarios de búsqueda navegar por Knowledge Graph sin salir del sitio web del motor de búsqueda.
Otras características SERP
Otras características de SERP incluyen elementos de predicción de consultas que intentan responder o volver a canalizar la actividad de búsqueda sin enviar al usuario de búsqueda a un sitio web diferente. Los ejemplos incluyen las respuestas sin resultados en la búsqueda móvil o autocompletar, así como los cuadros "La gente también pregunta" (PAA).


Ejemplo de una búsqueda sin resultados (móvil), que se muestra como respuesta directamente en el cuadro de autocompletar en el escritorio
Gestión de contenido en los resultados de búsqueda
Marcado de Schema.org
Con poco control directo sobre los otros elementos que forman una lista de búsqueda, los SEO se han apoyado enormemente en el poder de los fragmentos enriquecidos a través del marcado de Schema.org para hacer que sus listados se destaquen en los SERP.
Sin embargo, Google ha tomado medidas enérgicas contra el uso abusivo del marcado enriquecido, incluidas las estrellas de revisión y el marcado de preguntas frecuentes:
Google Review Stars en los resultados de búsqueda cayó un 14% desde la actualización:
— Los sitios de finanzas bajaron un 46 %
— Los sitios de Bienes Raíces bajaron un 46%
— Los sitios de Law & Government bajaron un 28 %Nuevos datos vía @dr_pete https://t.co/DdlrCFIrsm pic.twitter.com/w2lj9WzpLR
– Ciro (@CyrusShepard) 24 de septiembre de 2019
Para evitar tener SERP llenos de resultados de preguntas frecuentes, #Google parece haber establecido el límite en 3 resultados de preguntas frecuentes #SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
— AJ Ghergich (@SEO) 8 de octubre de 2019
Indicaciones explícitas de qué contenido no se puede usar
Esta semana, Google está implementando etiquetas de administración de fragmentos que se pueden usar para indicarle a Google algunos límites sobre lo que se puede usar para crear el fragmento de página en los SERP.
Las nuevas etiquetas de administración tienen dos limitaciones principales:
- No se aplican a los datos estructurados (marcado de Schema.org) en la página . Los datos estructurados de Schema.org compatibles con Google siempre se pueden mostrar en los resultados de búsqueda.
- Pueden evitar que su página se use en ciertas "funciones especiales" en las SERP, incluidos los fragmentos destacados , si no cumplen con las longitudes mínimas requeridas por la función SERP. Debido a que la longitud varía según el idioma, Google no publica las longitudes mínimas de los fragmentos destacados. En cambio, "[a]quellos que no desean que el contenido aparezca como fragmentos destacados pueden experimentar con longitudes máximas de fragmentos más bajas".
Los propietarios de sitios web tienen dos opciones para implementar estas etiquetas:
1. Etiquetas de metarobots
A partir de finales de octubre, en todo el mundo, estas etiquetas de meta robots se pueden agregar a la página <head> o en el encabezado HTTP de x-robots.
- <meta name=”robots” content=” nosnippet “> – no mostrar fragmentos de texto para esta página. Todavía se puede usar una miniatura de imagen.
- <meta name=”robots” content=” max-snippet: 50″> – establezca la longitud máxima en número de caracteres para el fragmento. Una longitud de fragmento de "0" es el equivalente de "nosnippet"; una longitud de fragmento de "-1" se interpreta como que no hay límite para la longitud del fragmento.
- <meta name=”robots” content=” max-video-preview: 3″>: establezca la duración máxima, en segundos, para una vista previa de video. Una duración de video de "0" evitará que se muestren vistas previas de video; una duración de video de "-1" se interpreta como que no hay límite para la duración de la vista previa del video.
- <meta name=”robots” content=” max-image-preview: standard”>: establezca el tamaño máximo de imagen para las imágenes de esta página. Las opciones son: “ninguno”, “estándar” o “grande”.
Puede usar más de un operador de administración de fragmentos en la misma etiqueta de meta robots. Separe cada operador por una coma.
2. Atributo HTML Data-nosnippet
A fines de 2019, Google reconocerá un nuevo atributo HTML: data-nosnippet . Se puede aplicar a las etiquetas <span>, <div> o <selection>.
El atributo data-nosnippet evita que el texto dentro de la etiqueta a la que se aplica se muestre en el fragmento de la página.
Permiso explícito para la reutilización de contenido para la prensa europea en Francia
La remezcla y republicación de contenido de noticias de Google ya roza los límites de la ley de derechos de autor en algunos lugares. Francia ha estado recientemente en el centro de atención:
Debido a los cambios en la ley de derechos de autor en Francia, la Búsqueda de Google no mostrará fragmentos de texto ni miniaturas de imágenes de las publicaciones de prensa europeas afectadas en Francia, a menos que el sitio web haya implementado metaetiquetas para permitir vistas previas de búsqueda. (Fuente)
En otras palabras, Google excluirá de los resultados de búsqueda en Francia cualquier publicación europea que no le permita explícitamente volver a publicar y eventualmente remezclar contenido.
Irónicamente, los medios para otorgar permisos no son particularmente claros: la única etiqueta de meta robots explícitamente permisiva es "todos", que "es el valor predeterminado y no tiene efecto si se enumera explícitamente", excepto, ahora, en los SERP franceses.
De lo contrario, los editores solo pueden indicar la falta de límite en la duración de las vistas previas de texto y video a través de una convención no incluida en el anuncio sobre la gestión de fragmentos, o pueden imponer límites arbitrarios para indicar que no quieren prohibir las vistas previas de búsqueda. .
Caminando por la cuerda floja
Cada sitio web deberá encontrar el equilibrio adecuado entre proteger su contenido y dar forma a su presencia en los SERP de Google.
A medida que Google se comporta cada vez más como un editor de contenido, podemos esperar más funciones SERP con atribuciones mínimas, así como más países donde la ley de derechos de autor, destinada a proteger a los propietarios y creadores de contenido, tiene un impacto en lo que Google puede y no puede mostrar.
Sin embargo, lo que sí creo que es interesante son las implicaciones de derechos de autor de esto... La gente se queja de que G toma contenido sin permiso: las etiquetas de fragmentos serán un permiso tácito. ¿Pasará mucho antes de que sean necesarios?
— Jenny Halasz (@jennyhalasz) 15 de octubre de 2019
Afortunadamente, las nuevas herramientas de administración de fragmentos brindan a los propietarios de sitios web los inicios de una caja de herramientas para determinar qué partes, y cuánto, de su contenido puede reutilizar Google en los SERP.
Por ahora, creo que sería prudente implementar etiquetas de administración de fragmentos según corresponda en sitios web con contenido original sustancial, aunque me preocupa que las etiquetas que solo son restrictivas no sean útiles para todos los sitios web. A pesar de esta advertencia, todavía hay formas de usarlos para optimizar la experiencia en las SERP y obtener más tráfico.
Creo que la gente adoptará las nuevas etiquetas. Creo que hay bastantes oportunidades para "dar forma" a un fragmento con esas etiquetas para brindar una mejor experiencia que la que Google extrae automáticamente y optimizar los CTR.
— Kevin_Indig (@Kevin_Indig) 16 de octubre de 2019
Tengo muchas ganas de ver la experimentación en diferentes verticales para encontrar lo que funciona mejor.