
Por qué nos mudamos a la informática sin servidor para implementar compilaciones personalizadas
Publicado: 2018-11-22
Foto de panumas nikhomkhai de Pexels
Como parte de nuestro compromiso de capacitar a los especialistas en marketing de rendimiento para hacer más, con menos, sin preocupaciones , los equipos de TUNE siempre están buscando nuevas formas de servir a nuestros clientes. En este caso, nuestro equipo de ingeniería de soluciones descubrió una tecnología que simplifica la forma en que implementan y admiten compilaciones personalizadas en nuestra plataforma. Como resultado, ahora pueden dedicar más tiempo (y menos dinero) a trabajar con más clientes para crear las soluciones que necesitan.
En TUNE, nos enorgullecemos de brindar una plataforma de marketing de desempeño integral y flexible que permite a las redes y a los anunciantes administrar sus campañas de marketing digital, las relaciones con los editores, los pagos y más, desde el primer momento, sin tener que escribir una sola línea de código. . Pero a veces, al igual que con otros sistemas SaaS totalmente administrados, nuestros clientes requieren configuraciones, funcionalidades o integraciones personalizadas que solo se pueden lograr arremangándonos y activando el antiguo editor de código. Recientemente, hicimos la transición a una nueva tecnología que está cambiando la forma en que construimos estas soluciones: la computación sin servidor.
En esta publicación, repasaré los problemas que encontramos con el desarrollo personalizado, los pasos que tomamos para configurar nuestro proceso de compilación sin servidor y cómo esta nueva metodología está resolviendo los desafíos de costo y escala.
Desafío: mantenerse al día con la demanda de soluciones personalizadas
Cuando comenzamos el equipo de ingeniería de soluciones en TUNE, tratamos cada compilación personalizada del cliente como una compilación separada. La mayoría de estas compilaciones tenían un componente de front-end, que normalmente se implementaba como una página personalizada en nuestra plataforma, y un componente de back-end que constaba de un servidor, una base de datos y cualquier otra infraestructura necesaria para mantener los servidores actualizados. -fecha y operativa.
Al principio, esta metodología funcionó para nosotros. Al tener un equipo pequeño y delgado con algunas compilaciones personalizadas complejas, nuestro método de aprovisionamiento y configuración de un servidor diferente para cada compilación funcionó para nosotros. Nos permitió crear experiencias increíbles para nuestros clientes.
Pero a medida que crecía el número de compilaciones, comenzamos a tener problemas:
- ¡Demasiados servidores! Como puede imaginar, el aprovisionamiento de un mínimo de dos cajas por compilación nos llevó a tener demasiados servidores. La gran cantidad de servidores y todas las molestias que los acompañan (como las actualizaciones de seguridad y las copias de seguridad) nos estaban costando más tiempo del que nos gustaría admitir.
- Mantenga esos servidores activos. Dado que cada servidor tiene su propia entidad, éramos responsables de asegurarnos de que cada servidor estuviera siempre activo y operativo.
- PHP no es para mí. La mayoría de nuestras compilaciones se crean a partir de una imagen base de Docker PHP. Pero a medida que nuestro equipo creció, supimos que obligar a las personas a escribir las compilaciones de sus clientes en PHP 5.0 cuando eran magos de Python no tenía ningún sentido.
- Esto se está poniendo caro. Con todos nuestros servidores implementados en ec2/RDS, comenzamos a ver un costo mensual significativo.
- Seguridad primero. Como estos servicios manejaban datos confidenciales de los clientes, tuvimos que proporcionar un método de autenticación para nuestras URL públicas para garantizar la seguridad de esos datos.
- Los crones son duros. Muchos servicios de back-end consistían en scripts cron y no teníamos una forma eficiente de administrarlos.
Con la aparición de estos desafíos, sabíamos que teníamos que encontrar una forma más sencilla y rentable de proporcionar funcionalidad de back-end a las compilaciones de nuestros clientes. Pero después de mucho debate y sin un candidato claro para una solución, comenzamos a quedarnos sin ideas. (Además, con la demanda de nuevas construcciones personalizadas creciendo como loco, el tiempo definitivamente no estaba de nuestro lado).
Solución: informática sin servidor al rescate
Si no ha oído hablar de la informática sin servidor , es posible que se esté preguntando lo mismo que nosotros cuando oímos hablar de ella por primera vez. ¿Cómo se puede ejecutar código sin un servidor? (No se preocupe, su comprensión fundamental de la programación sigue siendo correcta y no, no abusamos del especial de la hora feliz antes de escribir esto).
"Sin servidor" es un término realmente confuso para una nueva tecnología porque, no seamos tontos, definitivamente todavía hay un servidor que ejecuta código. Entonces, ¿qué es exactamente sin servidor?
La computación sin servidor es un modelo de ejecución de computación en la nube en el que el proveedor de la nube actúa como servidor, administrando dinámicamente la asignación de recursos de la máquina. –Wikipedia _
Las soluciones en la nube sin servidor le permiten crear y ejecutar aplicaciones y servicios sin pensar en las molestias asociadas con los servidores. Básicamente, la informática sin servidor le permite hacer lo que mejor sabe hacer: escribir código.
El proceso de configuración sin servidor
Para mostrarle la esencia de cómo funciona la tecnología sin servidor, le mostraré los pasos que usamos para configurar esta funcionalidad.
Nota: Hay muchos proveedores de nube con funcionalidad sin servidor. En este ejemplo, usamos AWS Lambda .

- Primero, cree una nueva función Lambda y seleccione " Blueprints ". Luego, escriba " http " en el campo de palabra clave y seleccione Python o Node microservice-http-endpoint. (Los blueprints son bloques de código prediseñados destinados a acelerar el desarrollo. ¿Qué tan increíble es eso?) Una vez que haya hecho una selección, haga clic en " Configurar ".
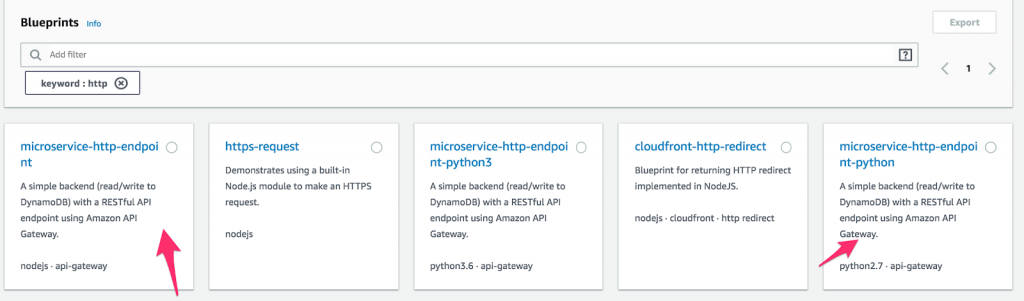
Cómo configurar una función en AWS Lambda.
- Agregue un nombre de función y un rol. A continuación, seleccione un disparador de API Gateway con la opción de seguridad " Abrir con clave de API ". Esta puerta de enlace API proporcionará una URL pública que activará su función Lambda. Agregar la clave API proporciona un método de autenticación, que es muy recomendable.
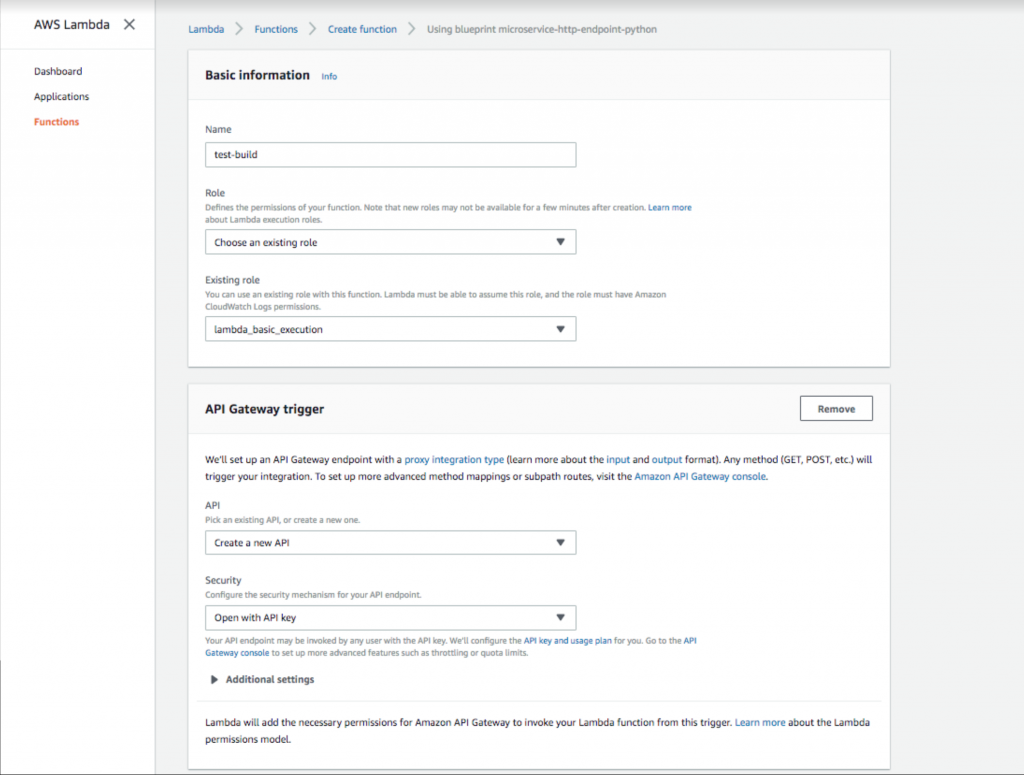
Configuración de una clave de puerta de enlace de API abierta en AWS Lambda.
- Una vez que crea la función, ahora puede realizar configuraciones en su código. Como puede ver, el modelo ya le ha brindado un atractivo punto de entrada que le permite interactuar con una tabla de Dynamo (si desea agregar una base de datos). Lo que esté debajo de lambda_handler se ejecutará cuando se cargue la URL pública. Dado que también estamos agregando una base de datos, vayamos a Dynamo y creemos una.
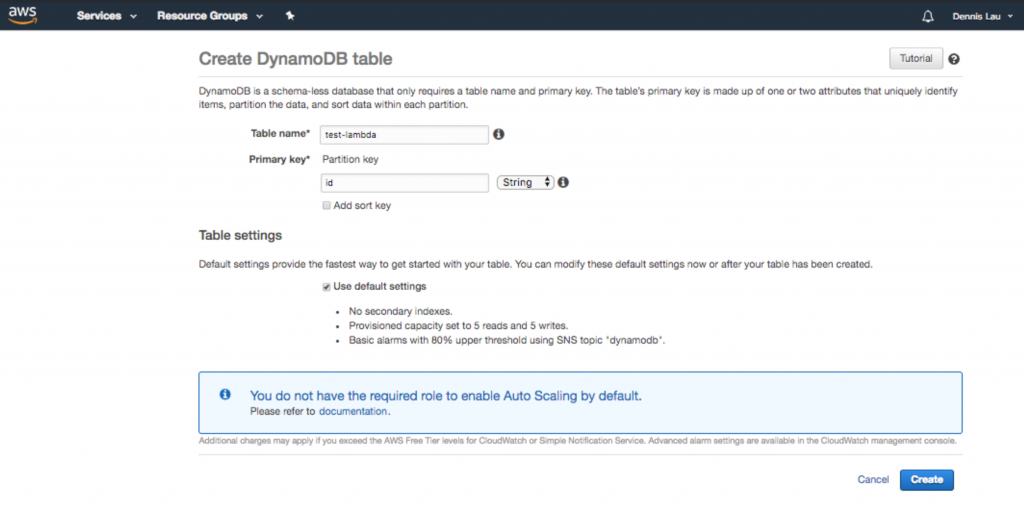
Creación de una tabla de base de datos de Dynamo en AWS Lambda.
- Una vez que se crea la tabla de Dynamo, hagamos una llamada a esta función de Lambda desde una URL pública. Vuelva a su función y haga clic en el ícono " API Gateway " en la parte superior. Debería ver que el punto final y la clave API ya se han creado para usted.
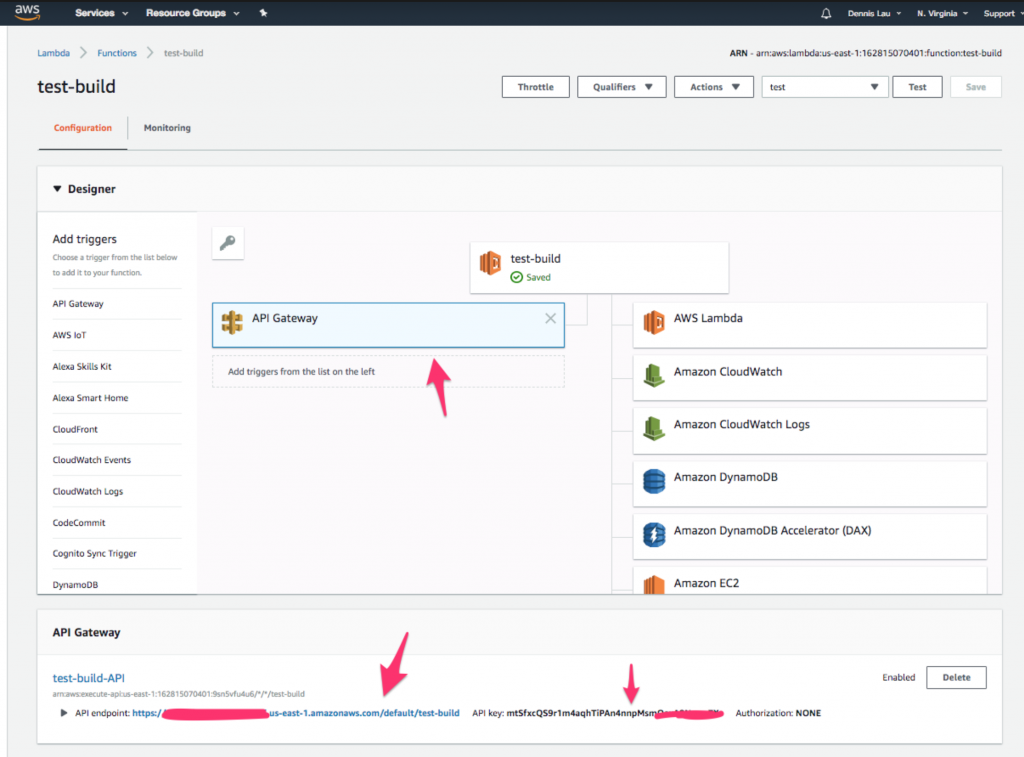
Dónde encontrar el icono de API Gateway en las funciones de AWS Lambda.
- Ahora abra el terminal y agregue la clave API debajo del encabezado " x-api-key" , luego agregue el nombre de la tabla que creó bajo el parámetro de cadena de consulta TableName .

Ingrese su clave y el nombre de la base de datos en la terminal para finalizar.
- Primero, cree una nueva función Lambda y seleccione " Blueprints ". Luego, escriba " http " en el campo de palabra clave y seleccione Python o Node microservice-http-endpoint. (Los blueprints son bloques de código prediseñados destinados a acelerar el desarrollo. ¿Qué tan increíble es eso?) Una vez que haya hecho una selección, haga clic en " Configurar ".
¡Eso es todo! Ahora tiene un back-end seguro y en funcionamiento conectado a una base de datos. Todo lo que necesitó fueron cinco sencillos pasos.
Cómo la informática sin servidor abordó nuestros desafíos
Ahora que le hemos mostrado cómo configurar compilaciones sin servidor, echemos un vistazo y veamos cómo este modelo basado en la nube se compara con nuestra lista de verificación de problemas.
- ¡Demasiados servidores! Sin servidor... lo que significa que no hay más servidores, ¿verdad?
- Mantenga esos servidores activos. Dado que la computación sin servidor es administrada por el proveedor de la nube, obtiene el beneficio de tener estos proveedores (junto con sus métodos comprobados y probados) para monitorear sus servidores. Para aquellos de ustedes que quieran jugar a Sherlock Holmes, también pueden ver todos los registros del servidor generados por su función en Cloudwatch .
- PHP no es para mí. Los modelos sin servidor le permiten escribir en C#, Python, NodeJS, Go e incluso Java.
- Esto se está poniendo caro. Con las soluciones sin servidor, los costos se miden en función del tiempo de ejecución (por 100 milisegundos) y la cantidad de datos transferidos. A diferencia de pagar por mes, que incluye el tiempo que sus servidores permanecen inactivos, solo paga por lo que usa. Con costos tan bajos como $ 0.000000208 por 100 ms de ejecución, la informática sin servidor podría ahorrarle una gran cantidad de dinero.
- Seguridad primero. ¿Es seguro sin servidor? Con un sistema de autenticación de clave API incorporado, puede apostar que lo es.
- Los crones son duros. Con un sistema de administración de cron creado de forma nativa en Cloudwatch, solo establezca una ventana de tiempo y olvídese. Cloudwatch maneja todo el registro y la ejecución.
Pensamientos finales
Para el equipo de ingeniería de soluciones aquí en TUNE, pasar a la computación sin servidor ha sido un cambio de juego. Su facilidad de uso, ahorro de costos y características ágiles han cambiado la forma en que manejamos todas las compilaciones de nuevos clientes. Las soluciones basadas en la nube sin servidor están configuradas para cambiar el mundo de la informática del lado del servidor. No sé ustedes, pero una cosa es segura: el equipo de Ingeniería de Soluciones TUNE está listo.
Para obtener más información sobre la plataforma TUNE y los servicios de desarrollo personalizado que brindamos, visite nuestra página de Servicios profesionales .