
7 fallas de SEO que se ven en la naturaleza (y cómo puedes evitarlas)
Publicado: 2022-06-12
A menudo recibimos preguntas de personas que se preguntan por qué su sitio no está clasificado o por qué los motores de búsqueda no lo indexan.
Recientemente, me encontré con varios sitios con errores importantes que podrían corregirse fácilmente, si los propietarios supieran mirar. Si bien algunos errores de SEO son bastante complejos, estos son algunos de los errores de "golpe de cabeza" que a menudo se pasan por alto.
Así que echa un vistazo a estos errores de SEO y cómo puedes evitar cometerlos tú mismo.
Error de SEO #1: Problemas de Robots.txt
El archivo robots.txt tiene mucho poder. Indica a los robots de los motores de búsqueda qué excluir de sus índices.
En el pasado, he visto sitios que se olvidan de eliminar una sola línea de código de ese archivo después de un rediseño del sitio y hunden todo su sitio en los resultados de búsqueda.
Entonces, cuando un sitio de flores destacó un problema, comencé con una de las primeras comprobaciones que siempre hago en un sitio: mirar el archivo robots.txt.
Quería saber si el archivo robots.txt del sitio estaba impidiendo que los motores de búsqueda indexaran su contenido. Pero en lugar del archivo de texto esperado, vi una página que ofrecía enviar flores a Robots.Txt.
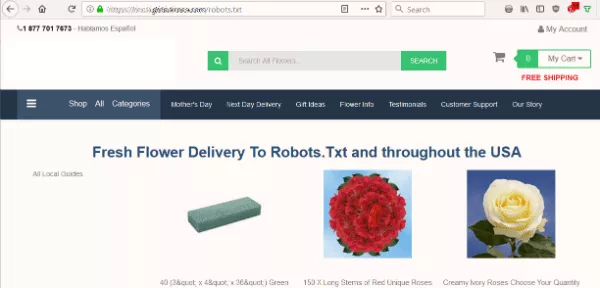
El sitio no tenía robots.txt, que es lo primero que busca un bot cuando rastrea un sitio. Ese fue su primer error. Pero tomar ese archivo como destino… ¿en serio?
Error de SEO n.º 2: la autogeneración se vuelve loca
En segundo lugar, el sitio generaba automáticamente contenido sin sentido. Probablemente se lo enviaría a Papá Noel o al texto que puse en la URL.
Ejecuté una herramienta Verificar página del servidor para ver qué estado mostraba la página generada automáticamente. Si fuera un 404 (no encontrado), los bots ignorarían la página como deberían. Sin embargo, el encabezado del servidor de la página dio un estado 200 (OK). Como resultado, las páginas falsas estaban dando luz verde a los motores de búsqueda para ser indexadas.
Los motores de búsqueda quieren ver contenido único y significativo por página. Por lo tanto, indexar estas páginas que no son páginas podría dañar su SEO.
SEO Fail #3: Errores canónicos
Luego, revisé para ver qué pensaban los motores de búsqueda de este sitio. ¿Podrían rastrear e indexar las páginas?
Mirando el código fuente de varias páginas, noté otro error importante.
Cada página tenía un elemento de enlace canónico que apuntaba a la página de inicio:
<enlace rel=”canonical” href=”https://www.dominio.com/” />
En otras palabras, a los motores de búsqueda se les decía que cada página era en realidad una copia de la página de inicio. Según esta etiqueta, los bots deberían ignorar el resto de las páginas de ese dominio.
Afortunadamente, Google es lo suficientemente inteligente como para descubrir cuándo es probable que estas etiquetas se usen por error. Así que todavía estaba indexando algunas de las páginas del sitio. Pero esa solicitud canónica universal no estaba ayudando al SEO del sitio.
Cómo evitar estos errores de SEO
Para los múltiples errores del sitio de flores, aquí están las correcciones:
- Tener un archivo robots.txt válido para indicar a los motores de búsqueda cómo rastrear e indexar el sitio. Incluso si es un archivo en blanco, debe existir en la raíz de su dominio.
- Genere un elemento de enlace canónico adecuado para cada página. Y no apunte lejos de una página que desea indexar.
- Muestre una página 404 personalizada cuando no exista una URL de página. Asegúrese de que devuelva un código de servidor 404 para dar a los motores de búsqueda un mensaje claro.
- Tenga cuidado con las páginas autogeneradas. Evite producir páginas sin sentido o duplicadas para los motores de búsqueda y los usuarios.
Incluso si no está experimentando un problema en el sitio, estos son buenos puntos para revisar periódicamente, solo para estar seguro.
Ah, y nunca pongas una etiqueta canónica en tu página 404 , especialmente apuntando a tu página de inicio... simplemente no lo hagas.
Fallo de SEO n.º 4: Caída libre de las clasificaciones de la noche a la mañana
A veces, un simple cambio puede ser un error costoso. Esta historia proviene de una experiencia con uno de nuestros clientes de SEO.
Cuando la extensión .org de su nombre de dominio estuvo disponible, la recogieron. Hasta aquí todo bien. Pero su siguiente movimiento condujo al desastre.
Inmediatamente configuraron una redirección 301 que apuntaba el .org recién adquirido a su sitio web principal .com. Su razonamiento tenía sentido: capturar a los visitantes descarriados que podrían escribir la extensión incorrecta.
Pero al día siguiente, nos llamaron, frenéticos. El tráfico de su sitio era inexistente. No tenían idea de por qué.
Unas cuantas comprobaciones rápidas revelaron que sus rankings de búsqueda habían desaparecido de Google de la noche a la mañana. No se necesitaron demasiadas preguntas y respuestas para averiguar qué había sucedido.

Pusieron la redirección en su lugar sin considerar el riesgo. Investigamos un poco y descubrimos que .org tenía un pasado sórdido.
El dueño anterior del sitio .org lo había usado para spam. ¡Con la redirección, Google estaba asignando todo ese veneno al sitio principal de la compañía! Solo nos llevó dos días restaurar la posición del sitio en Google.
Cómo evitar este error de SEO
Siempre investigue el perfil de enlace y el historial de cualquier nombre de dominio bajo el que se registre.
Un consultor SEO calificado puede hacer esto. También hay herramientas que puede ejecutar para ver qué esqueletos pueden estar en el armario del sitio.
Cada vez que elijo un nuevo dominio, me gusta dejarlo inactivo durante seis meses a un año al menos antes de intentar hacer algo con él. Quiero que los motores de búsqueda diferencien claramente la nueva encarnación de mi sitio de su vida pasada. Es una precaución adicional para proteger su inversión.
SEO Fail #5: Páginas que no desaparecerán
A veces, los sitios pueden tener un problema diferente: demasiadas páginas en el índice de búsqueda.
Los motores de búsqueda a veces retienen páginas que ya no son válidas. Si las personas llegan a páginas de error cuando provienen de los resultados de búsqueda, es una mala experiencia para el usuario.
Algunos propietarios de sitios, frustrados, enumeran las URL individuales en el archivo robots.txt. Esperan que Google capte la indirecta y deje de indexarlos.
¡Pero este enfoque falla! Si Google respeta el archivo robots.txt, no rastreará esas páginas. Por lo tanto, Google nunca verá el estado 404 y no descubrirá que las páginas no son válidas.
Cómo evitar este error de SEO
La primera parte de la solución es no prohibir estas URL en robots.txt. QUIERES que los bots se rastreen y sepan qué URL deben eliminarse del índice de búsqueda.
Después de eso, configure una redirección 301 en la URL anterior. Envíe al visitante (ya los motores de búsqueda) a la página de reemplazo más cercana en el sitio. Esto se ocupa de sus visitantes, ya sea que provengan de una búsqueda o de un enlace directo.
SEO Fail #6: Equidad de enlace perdido
Seguí un enlace del sitio web de una universidad y recibí un error 404 (no encontrado).
Esto no es raro, excepto que el enlace era a /home.html, la antigua URL de la página de inicio del sitio.
En algún momento, deben haber cambiado la arquitectura de su sitio web y eliminado el estilo antiguo /home.html, perdiendo la redirección en el orden aleatorio.
Irónicamente, su página 404 dice que puede comenzar de nuevo desde la página de inicio, que es a lo que estaba tratando de llegar en primer lugar.
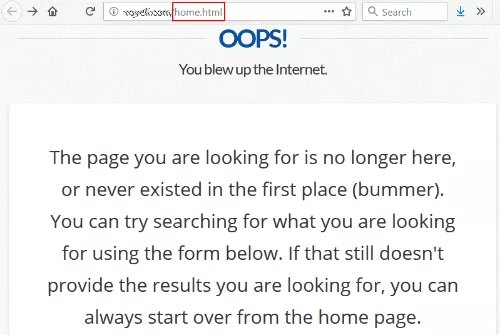
Es una apuesta bastante segura que a este sitio le encantaría tener un buen enlace de una universidad respetada que vaya a su página de inicio. Y lograr esto está completamente bajo su control. Ni siquiera tienen que ponerse en contacto con el sitio de enlace.
Cómo solucionar este error
Para arreglar este enlace, solo necesitan colocar una redirección 301 que apunte a /home.html a la página de inicio actual. (Consulte nuestro artículo sobre cómo configurar una redirección 301 para obtener instrucciones).
Para obtener crédito adicional, vaya a Google Search Console y revise el Informe de estado de cobertura del índice. Mire todas las páginas que se informa que devuelven un error 404 y trabaje para corregir tantos errores aquí como sea posible.
Error de SEO n.° 7: el error de copiar/pegar
Se inicia el rediseño del sitio, se colocan las etiquetas canónicas y se instala el nuevo Administrador de etiquetas de Google. Sin embargo, todavía hay problemas de clasificación. De hecho, una nueva página de destino no muestra ningún visitante en Google Analytics.
El equipo de desarrollo responde que han hecho todo al pie de la letra y han seguido los ejemplos al pie de la letra.
Tienen toda la razón. Siguieron los ejemplos, ¡incluso dejar el código de ejemplo! Después de copiar y pegar, los desarrolladores olvidaron ingresar la información de su propio sitio de destino.
Aquí hay tres ejemplos que nuestros analistas han encontrado en el código del sitio web:
- <enlace rel=”canonical” href=”http://example.com/”>
- 'analyticsAccountNumber': 'UA-123456-1'
- _gaq.push(['_setAccount', 'UA-000000-1']);
Cómo evitar este error de SEO
Cuando las cosas no funcionan bien, mire más allá de "¿este elemento está en el código fuente?" Es posible que los códigos de validación, los números de cuenta y las URL correctos nunca se hayan especificado en su código HTML.
Los errores ocurren, y las personas son solo humanos. Espero que estos ejemplos te ayuden a evitar errores de SEO similares. Para su beneficio, hemos creado una guía detallada de SEO que describe consejos y mejores prácticas de SEO.
Pero algunos problemas de SEO son más complejos de lo que piensas. Si tiene problemas de indexación, estamos aquí para ayudarlo. Llámenos o rellene nuestro formulario de solicitud y nos pondremos en contacto.
¿Como esta publicación? Suscríbete a nuestro blog para recibir nuevas publicaciones en tu bandeja de entrada.