
Agrupación de palabras clave semánticas en Python
Publicado: 2021-04-19En un mundo lleno de mitos de marketing digital, creemos que lo que necesitamos es encontrar soluciones prácticas a los problemas cotidianos.
En PEMAVOR, siempre compartimos nuestra experiencia y conocimiento para satisfacer las necesidades de los entusiastas del marketing digital. Por lo tanto, a menudo publicamos secuencias de comandos de Python complementarias para ayudarlo a aumentar su ROI.
Nuestro agrupamiento de palabras clave de SEO con Python allanó el camino para obtener nuevos conocimientos para grandes proyectos de SEO, con solo menos de 50 líneas de códigos de Python.
La idea detrás de este script era permitirle agrupar palabras clave sin pagar 'tarifas exageradas' a... bueno, sabemos quién...
Pero nos dimos cuenta de que este guión no es suficiente por sí solo. Se necesita otro script, para que puedan comprender mejor sus palabras clave: deben poder “ agrupar palabras clave por significado y relaciones semánticas. ”
Ahora es el momento de llevar Python para SEO un paso más allá.
Datos de seguimiento³
 Aprende más
Aprende másLa forma tradicional de agrupamiento semántico
Como sabe, el método tradicional para la semántica es construir modelos word2vec y luego agrupar palabras clave con Word Mover's Distance .
Pero estos modelos requieren mucho tiempo y esfuerzo para construir y entrenar. Por lo tanto, nos gustaría ofrecerle una solución más sencilla. 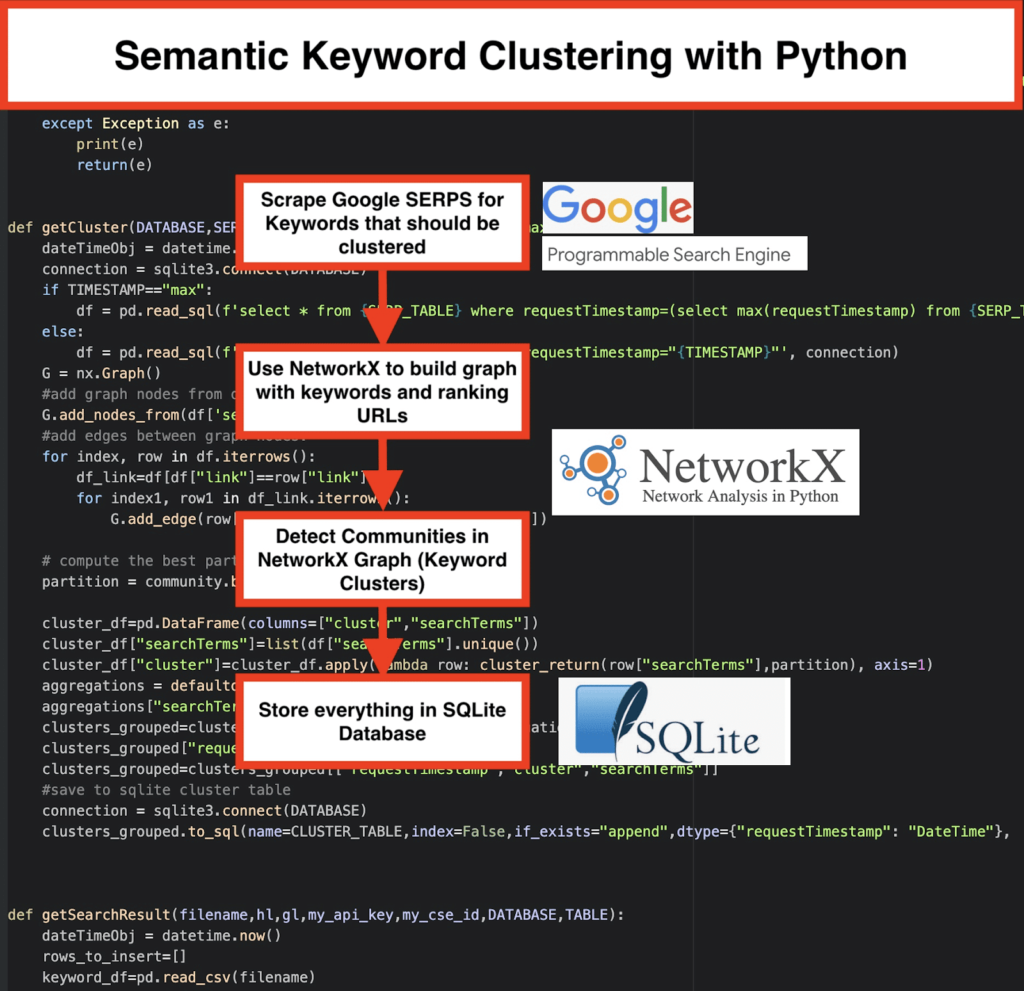
Resultados SERP de Google y descubrimiento de la semántica
Google utiliza modelos NLP para ofrecer los mejores resultados de búsqueda. Es como abrir la caja de Pandora, y no lo sabemos exactamente.
Sin embargo, en lugar de construir nuestros modelos, podemos usar este cuadro para agrupar palabras clave por su semántica y significado.
Así es como lo hacemos:
️ Primero, cree una lista de palabras clave para un tema.
️ Luego, raspe los datos SERP para cada palabra clave.
️ A continuación, se crea un gráfico con la relación entre las páginas de clasificación y las palabras clave.
️ Siempre que las mismas páginas se clasifiquen para diferentes palabras clave, significa que están relacionadas entre sí. Este es el principio central detrás de la creación de grupos de palabras clave semánticas.
Es hora de poner todo junto en Python
Python Script ofrece las siguientes funciones:
- Al usar el motor de búsqueda personalizado de Google, descargue los SERP para la lista de palabras clave. Los datos se guardan en una base de datos SQLite . Aquí, debe configurar una API de búsqueda personalizada.
- Entonces, haz uso de la cuota gratuita de 100 solicitudes diarias. Pero también ofrecen un plan pago por $5 por cada 1000 misiones si no quieres esperar o si tienes grandes conjuntos de datos.
- Es mejor optar por las soluciones de SQLite si no tiene prisa: los resultados de SERP se agregarán a la tabla en cada ejecución. (Simplemente tome una nueva serie de 100 palabras clave cuando tenga cuota nuevamente al día siguiente).
- Mientras tanto, debe configurar estas variables en Python Script .
- CSV_FILE=”keywords.csv” => almacena tus palabras clave aquí
- IDIOMA = “es”
- PAÍS = “es”
- API_KEY = "xxxxxxx"
- CSE_ID=”xxxxxxx”
- Ejecutar
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)escribirá los resultados SERP en la base de datos. - El agrupamiento lo realiza networkx y el módulo de detección de la comunidad. Los datos se obtienen de la base de datos SQLite : la agrupación se llama con
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Los resultados de la agrupación en clúster se pueden encontrar en la tabla SQLite ; siempre que no cambie, el nombre es "keyword_clusters" de forma predeterminada.
A continuación, verá el código completo:
# Clustering semántico de palabras clave por Pemavor.com # Autor: Stefan Neefischer ([email protected]) de googleapiclient.discovery compilación de importación importar pandas como pd importar Levenstein desde fechahora fechahora de importación de fuzzywuzzy importar fuzz desde urllib.parse importar urlparse desde tld importar get_tld importar lánguido importar json importar pandas como pd importar numpy como np importar redx como nx comunidad de importación importar sqlite3 importar matematicas importar yo desde colecciones importar predeterminadodict def cluster_return(términobúsqueda,partición): devolver partición[término de búsqueda] def language_detection(str_lan): lan=langid.clasificar(str_lan) volver lan[0] def extract_domain(url, remove_http=Verdadero): uri = urlparse(url) si remove_http: nombre_dominio = f"{uri.netloc}" más: nombre_dominio = f"{uri.netloc}://{uri.netloc}" devolver nombre_dominio def extract_mainDomain(url): res = get_tld(url, as_object=True) volver res.fld def fuzzy_ratio(str1,str2): volver fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): devuelve fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): probar: servicio = compilación("búsqueda personalizada", "v1", desarrolladorKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() volver res excepto Excepción como e: imprimir (e) volver(e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): probar: servicio = compilación("búsqueda personalizada", "v1", desarrolladorKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).ejecutar() volver res excepto Excepción como e: imprimir (e) volver(e) def getCluster(BASE DE DATOS,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = fechahora.ahora() conexión = sqlite3.connect (BASE DE DATOS) si TIMESTAMP=="max": df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', conexión) más: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', conexión) G = nx.Graph() #agregar nodos gráficos de la columna del marco de datos G.add_nodes_from(df['searchTerms']) #añadir bordes entre los nodos del gráfico: para índice, fila en df.iterrows(): df_link=df[df["enlace"]==fila["enlace"]] para índice1, fila1 en df_link.iterrows(): G.add_edge(fila["términos de búsqueda"], fila1['términos de búsqueda']) # calcular la mejor partición para la comunidad (clústeres) partición = comunidad.mejor_partición(G) cluster_df=pd.DataFrame(columnas=["clúster","términos de búsqueda"]) cluster_df["searchTerms"]=lista(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(fila lambda: cluster_return(fila["searchTerms"],partición), eje=1) agregaciones = defaultdict() agregaciones["searchTerms"]=' | '.unirse clusters_grouped=cluster_df.groupby("cluster").agg(agregaciones).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #guardar en la tabla de clúster de sqlite conexión = sqlite3.connect (BASE DE DATOS) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=conexión) def getSearchResult(nombre de archivo,hl,gl,my_api_key,my_cse_id,BASE DE DATOS,TABLA): dateTimeObj = fechahora.ahora() filas_a_insertar=[] keyword_df=pd.read_csv(nombre de archivo) palabras clave=palabra_clave_df.iloc[:,0].tolist() para consulta en palabras clave: si hl=="predeterminado": resultado = google_search_default_language(consulta, my_api_key, my_cse_id,gl) más: resultado = google_search (consulta, my_api_key, my_cse_id, hl, gl) si "elementos" en el resultado y "consultas" en el resultado: para la posición en el rango (0, len (resultado ["elementos"])): resultado["elementos"][posición]["posición"]=posición+1 resultado["elementos"][posición]["dominio_principal"]= extract_mainDomain(resultado["elementos"][posición]["enlace"]) result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query) result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) para la posición en el rango (0, len (resultado ["elementos"])): filas_para_insertar.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "resultadostotales":resultado["consultas"]["solicitud"][0]["resultadostotales"],"enlace":resultado["elementos"][posición]["enlace"], "displayLink":resultado["elementos"][posición]["displayLink"],"dominio_principal":resultado["elementos"][posición]["dominio_principal"], "posición":resultado["elementos"][posición]["posición"],"fragmento":resultado["elementos"][posición]["fragmento"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":resultado["elementos"][posición]["snippet_matchScore_token"],"título":resultado["elementos"][posición]["título"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(filas_a_insertar) #guardar resultados de serp en la base de datos sqlite conexión = sqlite3.connect (BASE DE DATOS) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=conexión) ############################################## ############################################## ####################################### #Léeme: # ############################################## ############################################## ####################################### #1- Debe configurar un motor de búsqueda personalizado de Google. # # Proporcione la clave API y el ID de búsqueda. # # También configure su país e idioma donde desea monitorear los resultados SERP. # # Si aún no tiene una clave API y un ID de búsqueda, # # puede seguir los pasos en la sección de requisitos previos en esta página https://developers.google.com/custom-search/v1/overview#prerequisites # # # #2- También debe ingresar los nombres de la base de datos, la tabla serp y la tabla de clúster que se usarán para guardar los resultados. # # # #3- ingrese el nombre del archivo csv o la ruta completa que contiene las palabras clave que se usarán para serp # # # #4- Para la agrupación de palabras clave, ingrese la marca de tiempo para los resultados de serp que se usarán para la agrupación. # # Si necesita agrupar los resultados del último serp, ingrese "max" para la marca de tiempo. # # o puede ingresar una marca de tiempo específica como "2021-02-18 17:18:05.195321" # # # #5- Examine los resultados a través del navegador DB para el programa Sqlite # ############################################## ############################################## ####################################### #csv nombre de archivo que tiene palabras clave para serp CSV_FILE="palabras clave.csv" # determinar el idioma IDIOMA = "es" #destruir ciudad PAÍS = "es" #google búsqueda personalizada clave json api API_KEY="INTRODUZCA LA CLAVE AQUÍ" #ID del motor de búsqueda CSE_ #sqlite nombre de la base de datos BASE DE DATOS="palabras clave.db" #nombre de la tabla para guardar los resultados del serp en ella SERP_TABLE="palabras clave_serps" # ejecutar serp para palabras clave getSearchResult(CSV_FILE,IDIOMA,PAÍS,API_KEY,CSE_ID,BASE DE DATOS,SERP_TABLE) #nombre de la tabla en la que se guardarán los resultados del clúster. CLUSTER_TABLE="keyword_clusters" #Ingrese la marca de tiempo, si desea crear grupos para una marca de tiempo específica #Si necesita crear grupos para el último resultado de serp, envíelo con el valor "máximo" #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="máximo" #ejecutar grupos de palabras clave de acuerdo con las redes y los algoritmos de la comunidad getCluster(BASE DE DATOS,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Resultados SERP de Google y descubrimiento de la semántica
Esperamos que haya disfrutado de este script con su atajo para agrupar sus palabras clave en grupos semánticos sin depender de modelos semánticos. Dado que estos modelos suelen ser complejos y costosos, es importante buscar otras formas de identificar palabras clave que comparten propiedades semánticas.
Al tratar juntas las palabras clave relacionadas semánticamente, puede cubrir mejor un tema, vincular mejor los artículos de su sitio entre sí y aumentar la clasificación de su sitio web para un tema determinado.