
Comprender el informe de cobertura de Search Console
Publicado: 2019-08-15Introducción al informe de cobertura y cómo interpretar los datos
El Informe de cobertura de Search Console proporciona información sobre qué páginas de su sitio se han indexado y enumera las URL que han presentado algún problema mientras Googlebot intenta rastrearlas e indexarlas.
La página principal del informe de cobertura muestra las URL de su sitio agrupadas por estado:
- Error: la página no está indexada. Hay varias razones para esto, páginas que responden con 404, páginas blandas 404, entre otras cosas.
- Válido con advertencias: la página está indexada pero tiene problemas.
- Válido: la página está indexada.
- Excluido: la página no está indexada, Google sigue reglas en el sitio, como etiquetas noindex en robots.txt o metaetiquetas, etiquetas canónicas, etc. que evitan que las páginas se indexen.
Este informe de cobertura brinda mucha más información que la antigua consola de búsqueda de Google. Google realmente ha mejorado los datos que comparte, pero todavía hay algunas cosas que necesitan mejorar.
Como puede ver a continuación, Google muestra un gráfico con la cantidad de URL en cada categoría. Si hay un aumento repentino de errores, puede ver las barras e incluso correlacionarlo con las impresiones para determinar si un aumento en las URL con errores o advertencias puede reducir las impresiones.

Después de que se lanza un sitio o crea nuevas secciones, desea ver un recuento creciente de páginas indexadas válidas. Google tarda unos días en indexar las páginas nuevas, pero puede usar la herramienta de inspección de URL para solicitar la indexación y reducir el tiempo que tarda Google en encontrar su nueva página.

Sin embargo, si ve una disminución en el número de URL válidas o si ve picos repentinos, es importante trabajar en la identificación de las URL en la sección Errores y solucionar los problemas enumerados en el informe. Google proporciona un buen resumen de elementos de acción para llevar a cabo cuando hay un aumento de errores o advertencias.
Google proporciona información sobre cuáles son los errores y cuántas URL tienen ese problema:

Recuerda que Google Search Console no muestra información 100% precisa. De hecho, ha habido varios informes sobre errores y anomalías en los datos. Además, la consola de búsqueda de Google tarda en actualizarse, se sabe que los datos tienen entre 16 y 20 días de retraso. Además, el informe mostrará a veces una lista de más de 1000 páginas en categorías de errores o advertencias, como puede ver en la imagen de arriba, pero solo le permite ver y descargar una muestra de 1000 URL para que las audite y verifique.
Sin embargo, esta es una gran herramienta para encontrar problemas de indexación en su sitio:
Cuando haga clic en un error específico, podrá ver la página de detalles que enumera ejemplos de URL:

Como puede ver en la imagen de arriba, esta es la página de detalles de todas las URL que responden con 404. Cada informe tiene un enlace "Más información" que lo lleva a una página de documentación de Google que proporciona detalles sobre ese error específico. Google también proporciona un gráfico que muestra el número de páginas afectadas a lo largo del tiempo.
Puede hacer clic en cada URL para inspeccionar la URL, que es similar a la antigua función "buscar como Googlebot" de la antigua Google Search Console. También puede probar si la página está bloqueada por su robots.txt
Después de corregir las URL, puede solicitar a Google que las valide para que el error desaparezca de su informe. Debe priorizar la solución de problemas que se encuentran en el estado de validación "fallido" o "no iniciado".
Es importante mencionar que no debe esperar que todas las URL de su sitio estén indexadas. Google afirma que el objetivo del webmaster debe ser indexar todas las URL canónicas. Las páginas duplicadas o alternativas se clasificarán como excluidas ya que tienen un contenido similar al de la página canónica.
Es normal que los sitios tengan varias páginas incluidas en la categoría excluida. La mayoría de los sitios web tendrán varias páginas sin metaetiquetas de índice o bloqueadas a través de robots.txt. Cuando Google identifica una página duplicada o alternativa, debe asegurarse de que esas páginas tengan una etiqueta canónica que apunte a la URL correcta e intente encontrar el equivalente canónico en la categoría válida.
Google ha incluido un filtro desplegable en la parte superior izquierda del informe para que pueda filtrar el informe por todas las páginas conocidas, todas las páginas enviadas o URL en un mapa de sitio específico. El informe predeterminado incluye todas las páginas conocidas, lo que incluye todas las URL descubiertas por Google. Todas las páginas enviadas incluyen todas las URL que ha informado a través de un mapa del sitio. Si ha enviado varios mapas de sitio, puede filtrar por URL en cada mapa de sitio.
[Estudio de caso] Aumentar el presupuesto de rastreo en páginas estratégicas
 Lea el estudio de caso
Lea el estudio de casoErrores, Advertencias, URL Válidas y Excluidas
Error
- Error del servidor (5xx): el servidor devolvió un error 500 cuando Googlebot intentó rastrear la página.
- Error de redireccionamiento: cuando Googlebot rastreó la URL, hubo un error de redireccionamiento, ya sea porque la cadena era demasiado larga, hubo un bucle de redireccionamiento, la URL superó la longitud máxima de URL o había una URL incorrecta o vacía en la cadena de redireccionamiento.
- URL enviada bloqueada por robots.txt: las URL de esta lista están bloqueadas por su archivo robts.txt.
- URL enviada marcada como 'noindex': las URL de esta lista tienen una etiqueta de meta robots 'noindex' o un encabezado http.
- La URL enviada parece ser un 404 suave: se produce un error 404 suave cuando una página que no existe (ha sido eliminada o redirigida) muestra un mensaje de "página no encontrada" al usuario pero no devuelve un código de estado HTTP 404. Los 404 suaves también ocurren cuando las páginas se redireccionan a páginas no relevantes, por ejemplo, una página que redirige a la página de inicio en lugar de devolver un código de estado 404 o redirigir a una página relevante.
- La URL enviada devuelve una solicitud no autorizada (401): la página enviada para la indexación devuelve una respuesta HTTP 401 no autorizada.
- URL enviada no encontrada (404): la página respondió con un error 404 No encontrado cuando Googlebot intentó rastrear la página.
- La URL enviada tiene un problema de rastreo: Googlebot experimentó un error de rastreo mientras rastreaba estas páginas que no se encuentran en ninguna de las otras categorías. Deberá verificar cada URL y determinar cuál podría haber sido el problema.
Advertencia
- Indexada, aunque bloqueada por robots.txt: la página se indexó porque Googlebot accedió a ella a través de enlaces externos que apuntan a la página; sin embargo, la página está bloqueada por su archivo robots.txt. Google marca estas URL como advertencias porque no está seguro de si la página debería bloquearse para que no aparezca en los resultados de búsqueda. Si desea bloquear una página, debe usar una etiqueta meta 'noindex' o usar un encabezado de respuesta HTTP noindex.
Si Google tiene razón y la URL se bloqueó incorrectamente, debe actualizar su archivo robots.txt para permitir que Google rastree la página.
Válido
- Enviado e indexado: las URL que envió a Google a través del sitemap.xml para indexar y fueron indexadas.
- Indexado, no enviado en el mapa del sitio: Google descubrió la URL y la indexó, pero no se incluyó en su mapa del sitio. Se recomienda actualizar su mapa del sitio e incluir todas las páginas que desea que Google rastree e indexe.
Excluido
- Excluido por la etiqueta 'noindex': cuando Google intentó indexar la página, encontró una etiqueta de meta robots 'noindex' o un encabezado HTTP.
- Bloqueado por la herramienta de eliminación de página: alguien ha enviado una solicitud a Google para que no indexe esta página mediante la solicitud de eliminación de URL en Google Search Console. Si desea que esta página se indexe, inicie sesión en la Consola de búsqueda de Google y elimínela de la lista de páginas eliminadas.
- Bloqueado por robots.txt: el archivo robots.txt tiene una línea que excluye el rastreo de la URL. Puede verificar qué línea está haciendo esto usando el probador de robots.txt.
- Bloqueado debido a una solicitud no autorizada (401): igual que en la categoría Error, las páginas aquí regresan con un encabezado HTTP 401.
- Anomalía de rastreo: esta es una especie de categoría general, las URL aquí responden con códigos de respuesta de nivel 4xx o 5xx; Estos códigos de respuesta impiden la indexación de la página.
- Rastreado: actualmente no indexado: Google no proporciona una razón por la cual la URL no se indexó. Sugieren volver a enviar la URL para su indexación. Sin embargo, es importante comprobar si la página tiene contenido reducido o duplicado, si está canonicalizada en una página diferente, si tiene una directiva sin índice, si las métricas muestran una mala experiencia de usuario, si la página tarda mucho en cargarse, etc. Puede haber varias razones por las que Google no quiere indexar la página.
- Descubierta – actualmente no indexada: La página fue encontrada pero Google no la ha incluido en su índice. Puede enviar la URL para la indexación para acelerar el proceso como mencionamos anteriormente. Google afirma que la razón típica por la que esto sucede es que el sitio estaba sobrecargado y Google reprogramó el rastreo.
- Página alternativa con la etiqueta canónica adecuada: Google no indexó esta página porque tiene una etiqueta canónica que apunta a una URL diferente. Google ha seguido la regla canónica y ha indexado correctamente la URL canónica. Si quería que esta página no se indexara, entonces no hay nada que arreglar aquí.
- Duplicado sin canónico seleccionado por el usuario: Google ha encontrado duplicados para las páginas enumeradas en esta categoría y ninguno utiliza etiquetas canónicas. Google ha seleccionado una versión diferente como etiqueta canónica. Debe revisar estas páginas y agregar una etiqueta canónica que apunte a la URL correcta.
- Duplicado, Google eligió un canónico diferente al del usuario: Google descubrió las URL en esta categoría sin una solicitud de rastreo explícita. Google los encontró a través de enlaces externos y ha determinado que hay otra página que hace un mejor canónico. Google no ha indexado estas páginas por este motivo. Google recomienda marcar estas URL como duplicados de la canónica.
- No encontrado (404): cuando Googlebot intenta acceder a estas páginas, responde con un error 404. Google afirma que estas URL no se han enviado, estas URL se han encontrado a través de enlaces externos que apuntan a estas URL. Es una buena idea redirigir estas URL a páginas similares para aprovechar la equidad del enlace y también asegurarse de que los usuarios lleguen a una página relevante.
- Página eliminada debido a un reclamo legal: alguien se quejó de estas páginas debido a problemas legales, como una violación de derechos de autor. Puede apelar la queja legal presentada aquí.
- Página con redireccionamiento: estas URL están redireccionando, por lo tanto, están excluidas.
- Soft 404: como se explicó anteriormente, estas URL están excluidas porque deberían responder con un 404. Verifique las páginas y asegúrese de que si tiene un mensaje "no encontrado" para que respondan con un encabezado HTTP 404.
- URL enviada duplicada no seleccionada como canónica: similar a "Google eligió una canónica diferente a la del usuario", sin embargo, las URL en esta categoría fueron enviadas por usted. Es una buena idea revisar sus mapas de sitio y asegurarse de que no se incluyan páginas duplicadas.
Cómo usar los datos y elementos de acción para mejorar el sitio
Al trabajar en una agencia, tengo acceso a muchos sitios diferentes y sus informes de cobertura. Llevo tiempo analizando los errores que reporta Google en las diferentes categorías.
Ha sido útil encontrar problemas con la canonicalización y el contenido duplicado, sin embargo, a veces encuentras discrepancias como la reportada por @jroakes:

Parece que Google Search Console > Inspección de URL > Prueba en vivo informa incorrectamente todos los archivos JS y CSS como Rastreo permitido: No: bloqueado por robots.txt. Pruebe alrededor de 20 archivos en 3 dominios. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) 16 de julio de 2019
AJ Koh, escribió un gran artículo poco después de que la nueva Consola de búsqueda de Google estuviera disponible, donde explica que el valor real de los datos es usarlos para pintar una imagen de la salud para cada tipo de contenido en su sitio:
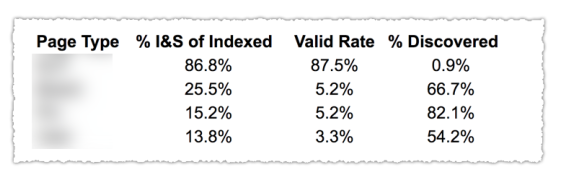
Como puede ver en la imagen de arriba, las URL de las diferentes categorías en el informe de cobertura se clasificaron por plantilla de página, como blog, página de servicio, etc. El uso de varios mapas de sitio para diferentes tipos de URL puede ayudar con esta tarea, ya que Google permite para filtrar la información de cobertura por mapa del sitio. Luego incluyó tres columnas con la siguiente información % de páginas indexadas y enviadas, tasa válida y % de descubiertas.
Esta tabla realmente le brinda una excelente descripción general de la salud de su sitio. Ahora, si desea profundizar en las diferentes secciones, le recomiendo revisar los informes y verificar los errores que presenta Google.
Puede descargar todas las URL presentadas en diferentes categorías y usar OnCrawl para verificar su estado HTTP, etiquetas canónicas, etc. y crear una hoja de cálculo como esta:
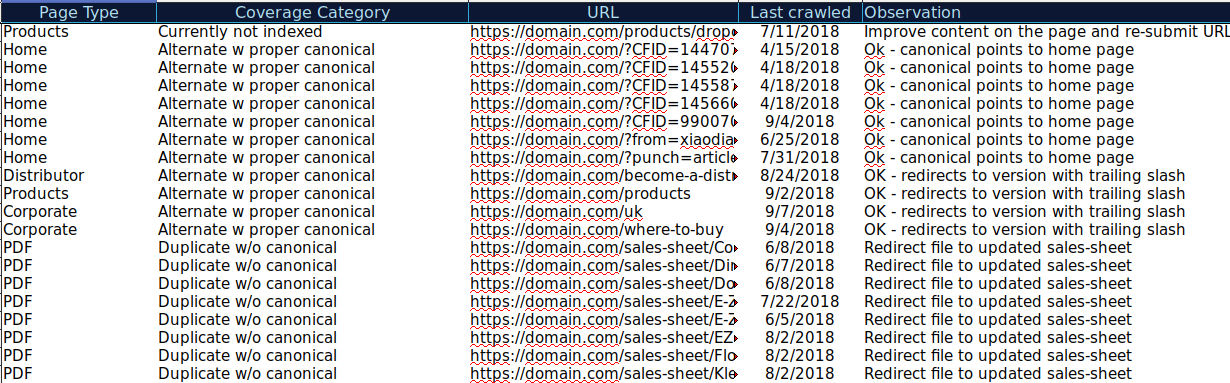
Organizar sus datos de esta manera puede ayudar a realizar un seguimiento de los problemas, así como agregar elementos de acción para las URL que deben mejorarse o corregirse. Además, puede marcar las URL que son correctas y no se necesitan elementos de acción en el caso de esas URL con parámetros con la implementación de etiquetas canónicas correcta.
Comience su prueba gratuita de 14 días
 Comience su prueba
Comience su pruebaIncluso puede agregar más información a esta hoja de cálculo de otras fuentes, como ahrefs, Majestic y Google Analytics con las integraciones de OnCrawl. Esto le permitiría extraer datos de enlaces, así como datos de tráfico y conversión para cada una de las URL en Google Search Console. Todos estos datos pueden ayudarlo a tomar mejores decisiones sobre qué hacer para cada página, por ejemplo, si tiene una lista de páginas con 404, puede vincular esto con vínculos de retroceso para determinar si está perdiendo alguna equidad de enlace de los dominios que se vinculan a páginas rotas en su sitio. O puede verificar las páginas indexadas y cuánto tráfico orgánico están recibiendo. Puede identificar las páginas indexadas que no reciben tráfico orgánico y trabajar para optimizarlas (mejorar el contenido y la usabilidad) para ayudar a atraer más tráfico a esa página.
Con estos datos adicionales, puede crear una tabla de resumen en otra hoja de cálculo. Puede usar la fórmula =CONTAR.SI(rango, criterio) para contar las URL en cada tipo de página (esta tabla puede complementar la tabla que AJ Kohn sugirió anteriormente). También podría usar otra fórmula para agregar backlinks, visitas o conversiones que extrajo para cada URL y mostrarlas en su tabla de resumen con la siguiente fórmula =SUMAR.SI (rango, criterios, [suma_rango]). Obtendrías algo como esto:
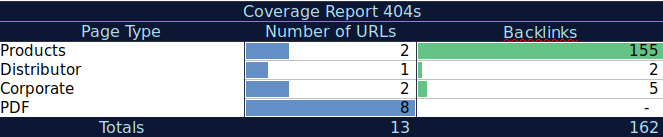
Realmente me gusta trabajar con tablas de resumen que pueden brindarme una vista resumida de los datos y pueden ayudarme a identificar las secciones en las que debo concentrarme primero.
Pensamientos finales
Lo que debe tener en cuenta al trabajar para solucionar problemas y consultar los datos de este informe es: ¿Mi sitio está optimizado para el rastreo? ¿Mis páginas indexadas y válidas están aumentando o disminuyendo? ¿Las páginas con errores están aumentando o disminuyendo? ¿Estoy permitiendo que Google dedique tiempo a las URL que aportarán más valor a mis usuarios o está encontrando muchas páginas inútiles? Con las respuestas a estas preguntas, puede comenzar a realizar mejoras en su sitio para que Googlebot pueda gastar su presupuesto de rastreo en páginas que puedan brindar valor a sus usuarios en lugar de páginas sin valor. Puede usar su archivo robots.txt para ayudar a mejorar la eficiencia del rastreo, eliminar URL inútiles cuando sea posible o usar etiquetas canónicas o sin índice para evitar contenido duplicado.
Google continúa agregando funcionalidades y actualizando la precisión de los datos en los diferentes informes de la consola de búsqueda de Google, por lo que esperamos seguir viendo más datos en cada una de las categorías en el informe de cobertura, así como en otros informes en la consola de búsqueda de Google.