
Auditoría técnica SEO rápida y sucia de 11 pasos para la salud general del sitio web
Publicado: 2020-02-27El SEO técnico es importante porque es el punto de partida de cualquier proyecto. Desde el punto de vista de un experto en SEO, cada sitio web es un nuevo proyecto. Un sitio web debe tener una base sólida para obtener buenos resultados y alcanzar los KPI más importantes en las clasificaciones de SEO.
Cada vez que comienzo con un nuevo proyecto, lo primero que hago es una auditoría técnica de SEO. La mayoría de las veces, solucionar problemas técnicos puede obtener resultados sorprendentes tan pronto como se vuelve a rastrear el sitio web.
Me hace gracia cuando la gente habla de contenido y más contenido, pero no dice una palabra sobre SEO técnico. Una cosa es segura, la salud del sitio web y el SEO técnico son dos cosas importantes que serán cruciales en 2020. No quiero decir que el contenido no sea importante. Lo es, pero sin solucionar los problemas técnicos en un sitio web, no creo que el contenido pueda dar resultados.
He visto casos en los que páginas importantes han sido bloqueadas por directivas en el archivo robots.txt, o las páginas de servicios o categorías más importantes están rotas o bloqueadas por meta robots como noindex, nofollow. ¿Cómo es posible tener éxito sin priorizar solucionando estos problemas?
Puede ser sorprendente ver la cantidad de SEO que no saben cómo identificar problemas tecnológicos para informar a los especialistas en desarrollo web para que los solucionen. Recuerdo que una vez, mientras trabajaba en el campo corporativo, creé una hoja de lista de verificación de auditoría de Tech SEO para que la usara mi equipo. En ese momento, me di cuenta de que tener a mano una hoja de arreglos rápidos como esta puede ayudar enormemente a un equipo y generar un impulso rápido para un cliente. Es por eso que considero de suma importancia invertir en una herramienta/software que pueda ayudarlo con el diagnóstico y las recomendaciones técnicas de SEO.
Comencemos el proceso práctico sobre cómo realizar una auditoría de SEO de tecnología rápida que marcará una gran diferencia. Este es un ejercicio rápido que le llevará alrededor de una hora, incluso si no es un profesional. Para mí, usar una herramienta Tech SEO como OnCrawl para avanzar rápidamente todas las cosas en cinco minutos sin tener que hacer todo el trabajo manual me facilita la vida.
Repasaré las cosas más importantes que se deben verificar al realizar una auditoría técnica de SEO. Hay más cosas que podemos verificar en busca de problemas en la página, pero quiero centrarme solo en las cosas que crearán problemas de indexación y desperdicio de presupuesto. Priorizar esto es la manera de asegurarse de que Googlebot rastreará las páginas más importantes.
- Indexación
- Archivo robots.txt
- Etiqueta de metarobots
- errores 4xx
- Mapas del sitio
- HTTP/HTTPS (problemas de seguridad del sitio web, contenido mixto y contenido duplicado)
- Paginación
- 404 página
- Profundidad y estructura del sitio
- Largas cadenas de redirección
- Implementación de etiquetas canónicas
1) Indexación
Esto es lo primero que hay que comprobar. Muchas veces, la indexación puede verse afectada por la configuración de un complemento o cualquier error menor, pero el impacto en la capacidad de búsqueda puede ser enorme, ya que hoy en día hay más de 6.160 millones de páginas web indexadas. Debe comprender que cualquier motor de búsqueda está haciendo un esfuerzo e incluso Google debe priorizar la página más relevante para la experiencia del usuario. Si no considera facilitarle las cosas a Googlebot, su competencia lo hará y ganará mucha más confianza que viene con un sitio web saludable.
Cuando hay problemas de indexación, los problemas de salud de su sitio web se reflejarán en la pérdida de tráfico orgánico. El proceso de indexación significa que un motor de búsqueda rastrea una página web y organiza la información que luego la ofrece en SERP. Los resultados dependen de la relevancia para la intención del usuario. Si una página web no puede o tiene problemas con el rastreo, esto favorecerá que otras páginas en el mismo nicho tengan una ventaja.
Usando operadores de búsqueda, por ejemplo:
Sitio: www.abc.com
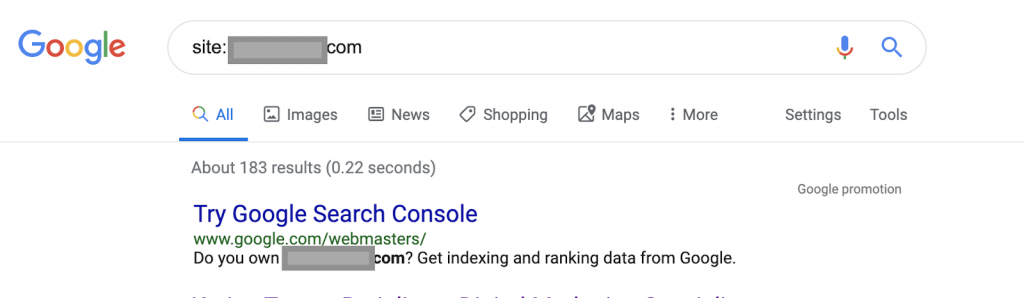
La consulta devolverá 183 páginas indexadas por Google. Esta es una estimación aproximada del número de páginas que Google ha indexado. Puede consultar Google Search Console para obtener el número exacto.
También debe usar un rastreador web como OnCrawl para enumerar todas las páginas a las que Google tiene acceso. Esto muestra un número diferente como se puede ver a continuación:
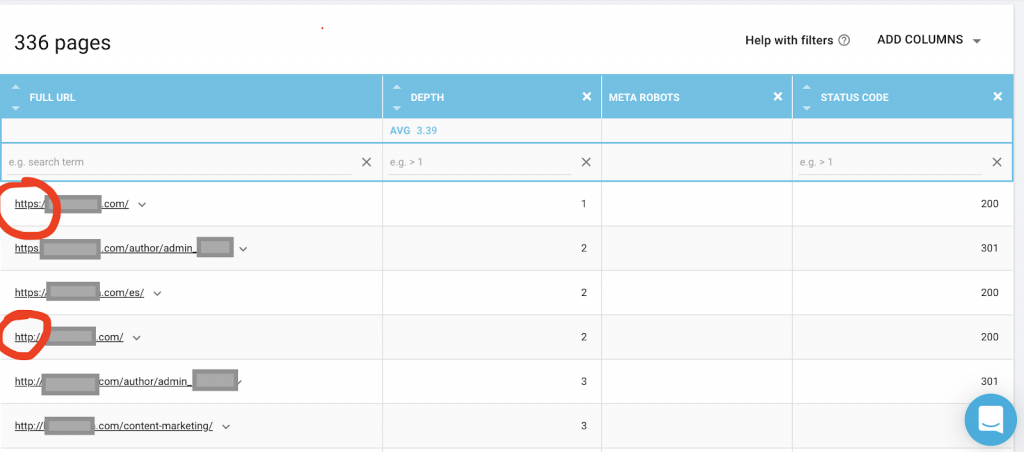
Este sitio web tiene casi el doble de páginas rastreables que páginas indexadas.
Esto podría revelar un problema de contenido duplicado o incluso un problema de versión de seguridad del sitio web entre HTTP y HTTPS. Hablaré de esto más adelante en este artículo.
En este caso, el sitio web se migró de HTTP a HTTPS. Podemos ver en OnCrawl que las páginas HTTP han sido redirigidas. Googlebot aún puede acceder a las versiones HTTP y HTTPS, y es posible que rastree todas las páginas duplicadas, en lugar de priorizar las páginas más importantes que el propietario desea clasificar, lo que genera una pérdida de presupuesto de rastreo.
Otro problema común entre los sitios web descuidados o los sitios web grandes, como los sitios de comercio electrónico, son los problemas de contenido mixto. Para acortar una larga historia, los problemas surgen cuando su página segura tiene recursos como archivos multimedia (más frecuentemente: imágenes) cargados desde una versión no segura.
Como arreglarlo:
Puede pedirle a un desarrollador web que fuerce todas las páginas HTTP a la versión HTTPS y redirija las direcciones HTTP a HTTPS una vez usando un código de estado 301.
Para problemas de contenido mixto, puede verificar manualmente la fuente de la página y buscar recursos cargados como "src = http://example.com/media/images", lo cual es casi una locura hacerlo, especialmente para sitios web grandes. Es por eso que necesitamos usar una herramienta técnica de SEO.
2) archivo Robots.txt:
El archivo robots.txt indica a los agentes de rastreo qué páginas no deben rastrear. La guía de especificaciones de Robots.txt indica que el formato del archivo debe ser texto sin formato con un tamaño máximo de 500 KB.
Recomendaré agregar el mapa del sitio a robots.txt.file. No todo el mundo hace esto, pero creo que es una buena práctica. El archivo robots.txt debe colocarse en su servidor alojado en public_html y va después del dominio raíz.
Podemos usar directivas en el archivo robots.txt para evitar que los motores de búsqueda rastreen páginas innecesarias o páginas con información confidencial, como la página de administración, las plantillas o el carrito de compras (/cart, /checkout, /login, carpetas como /tag utilizadas en blogs) , agregando estas páginas en el archivo robots.txt.
Consejo : asegúrese de no bloquear la carpeta de archivos de medios porque esto excluirá de la indexación sus imágenes, videos u otros medios autohospedados. Los medios pueden ser muy importantes para la relevancia de la página, así como para la clasificación orgánica y el tráfico de imágenes o videos.
3) Etiqueta Meta Robots
Este es un fragmento de código HTML que indica a los motores de búsqueda si deben rastrear e indexar una página, con todos los enlaces dentro de esa página. La etiqueta HTML va en el encabezado de su página web. Hay 4 etiquetas HTML comunes para robots:
- No seguir
- Seguir
- Índice
- Sin índice
Cuando no hay etiquetas de meta robots presentes, los motores de búsqueda seguirán e indexarán el contenido de forma predeterminada.
Puedes utilizar cualquier combinación que mejor se adapte a tus necesidades. Por ejemplo, al usar OnCrawl descubrí que una "página de autor" de este sitio web no tiene meta robots. Esto significa que por defecto la dirección es (“seguir, indexar”)
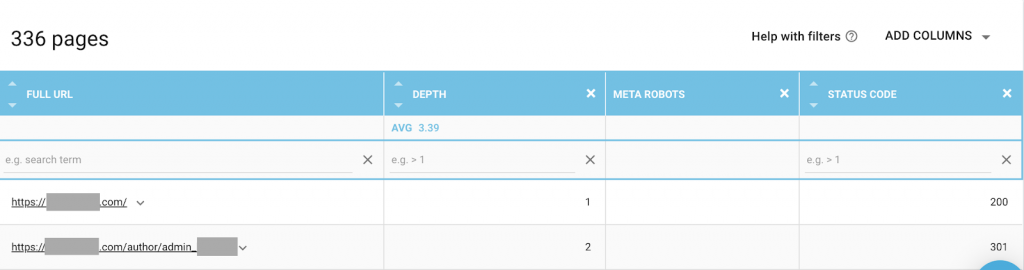
Esto debería ser ("noindex, nofollow").
¿Por qué?
Cada caso es diferente, pero esta web es un pequeño blog personal. Solo hay un autor que publica en el blog, y el dominio es el nombre del autor. En este caso, la página del "autor" no proporciona información adicional aunque la genere la plataforma de blogs.
Otro escenario puede ser un sitio web donde las categorías en el blog son importantes. Cuando el propietario quiere clasificar por categorías en su blog, los meta robots deben ser ("seguir, indexar") o estar predeterminados en las páginas de categoría.
En un escenario diferente, para un sitio web grande y conocido donde los principales expertos en SEO escriben artículos que son seguidos por la comunidad, el nombre del autor en Google actúa como una marca. En este caso, probablemente querrá indexar algunos nombres de autores.
Como puede ver, los meta robots se pueden usar de muchas maneras diferentes.
Como arreglarlo:
Pídele a un desarrollador web que cambie la etiqueta del meta robot según lo necesites. En el caso anterior de un sitio web pequeño, puedo hacerlo yo mismo yendo a cada página y cambiándola manualmente. Si está utilizando WordPress, puede cambiar esto desde la configuración de RankMath o Yoast.
4) errores 4xx:
Estos son errores del lado del cliente y pueden ser 401, 403 y 404.
- 404 Pagina no encontrada:
Este error ocurre cuando una página no está disponible en la dirección URL indexada. Podría haberse movido o eliminado, y la dirección anterior no se ha redirigido correctamente utilizando la función 301 del servidor web. Los errores 404 son una mala experiencia para los usuarios y representan un problema técnico de SEO que debe abordarse. Es bueno verificar a menudo los 404 y corregirlos, y no dejar que los agentes rastreadores los intenten una y otra vez desperdiciando su presupuesto.
Como arreglarlo:
Necesitamos encontrar las direcciones que devuelven 404 y arreglarlas usando redireccionamientos 301 si el contenido aún existe. O, si son imágenes, se pueden reemplazar por otras nuevas manteniendo el mismo nombre de archivo.
- 401 no autorizado
Este es un problema de permisos. El error 401 generalmente ocurre cuando se requiere autenticación, como nombre de usuario y contraseña.
Como arreglarlo:
Aquí hay dos opciones: la primera es bloquear la página de los motores de búsqueda usando robots.txt. La segunda opción es eliminar el requisito de autenticación.
- 403 Prohibido
Este error es similar al error 401. El error 403 ocurre porque la página tiene enlaces que no son accesibles al público.

Como arreglarlo:
Cambie el requisito en el servidor para permitir el acceso a la página (solo si esto es un error). Si necesita que esta página sea inaccesible, elimine todos los enlaces internos y externos de la página.
- 400 Petición Incorrecta
Esto ocurre cuando el navegador no puede comunicarse con el servidor web. Este error suele ocurrir por una mala sintaxis de URL.
Como arreglarlo:
Encuentre enlaces a estas URL y corrija la sintaxis. Si esto no se puede solucionar, deberá ponerse en contacto con el desarrollador web para solucionarlo.
Nota: Podemos encontrar errores 400 con herramientas o en Google Console

5) Mapas del sitio
El mapa del sitio es una lista de todas las URL que contiene el sitio web. Tener un mapa del sitio mejora la capacidad de búsqueda porque ayuda a los rastreadores a encontrar y comprender su contenido.
Tenemos diferentes tipos de sitemaps y debemos asegurarnos de que todos estén en buenas condiciones.
Los sitemaps que deberíamos tener son:
- Mapa del sitio HTML: estará en su sitio web y ayudará a los usuarios a navegar y encontrar las páginas de su sitio web.
- Mapa del sitio XML: este es un archivo que ayudará a los motores de búsqueda a rastrear su sitio web (como práctica recomendada, debe incluirse en su archivo robots.txt).
- Mapa del sitio XML de vídeo: Igual que el anterior.
- Mapa del sitio XML de imágenes: también es el mismo que el anterior. Se recomienda crear mapas de sitio separados para imágenes, videos y contenido.
Para sitios web grandes, se recomienda tener varios mapas de sitio para una mejor capacidad de rastreo porque los mapas de sitio no deben contener más de 50.000 URL.
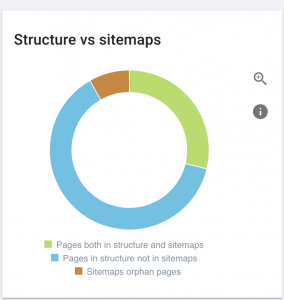
Este sitio web tiene problemas con el mapa del sitio.
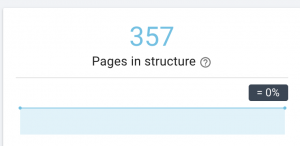
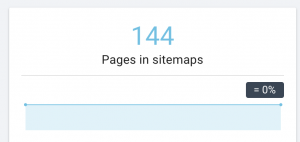
Cómo lo arreglamos:
Arreglamos esto generando diferentes mapas de sitio para: contenido, imágenes y videos. Luego, los enviamos a través de Google Search Console y también creamos un mapa del sitio HTML para el sitio web. No necesitamos un desarrollador web para esto. Podemos utilizar cualquier herramienta online gratuita para generar sitemaps.
6) HTTP/HTTPS (contenido duplicado)
Muchos sitios web tienen estos problemas como resultado de la migración de HTTP a HTTPS. Si este es el caso, el sitio web mostrará las versiones HTTP y HTTPS en los motores de búsqueda. Como consecuencia de este problema técnico común, las clasificaciones se diluyen. Estos problemas también generan problemas de contenido duplicado.
![]()

Como arreglarlo:
Pida a un desarrollador web que solucione este problema forzando todo HTTP a HTTPS.
Nota : nunca redirija todo el HTTP a la página de inicio de HTTPS porque generará un error 404 suave. (Debe decirle esto al desarrollador web; recuerde que no son SEO).
7) Paginación
Es el uso de una etiqueta HTML (“rel=prev” y “rel=next”) que establece relaciones entre páginas y le muestra a los motores de búsqueda que el contenido que se presenta en diferentes páginas debe identificarse o relacionarse con una sola. La paginación se usa para limitar el contenido para UX y el peso de una página para la parte técnica, manteniéndolos por debajo de los 3 MB. Podemos usar una herramienta gratuita para comprobar la paginación.
La paginación debe tener referencias autocanónicas e indicar "rel = anterior" y "rel = siguiente". La única información duplicada será el meta título y la meta descripción, pero los desarrolladores pueden cambiar esto para crear un pequeño algoritmo para que cada página tenga un meta título y una meta descripción generados.
Como arreglarlo:
Solicite a un desarrollador web que implemente etiquetas HTML de paginación con etiquetas autocanónicas.
Rastreador de SEO Oncrawl
 Descubrir
Descubrir8) Página personalizada 404 no encontrada
Una respuesta 404 es, como discutimos antes, un error " No encontrado " que lleva a los usuarios a un enlace roto o a una página inexistente. Esta es una oportunidad para redirigir a los usuarios al lugar correcto. Hay excelentes ejemplos de páginas 404 personalizadas. Esta es una necesidad.
Aquí hay un ejemplo de una gran página personalizada 404:

Como arreglarlo:
Cree una página 404 personalizada: piense en algo increíble para agregarle. Convierte este error en una oportunidad para tu negocio.
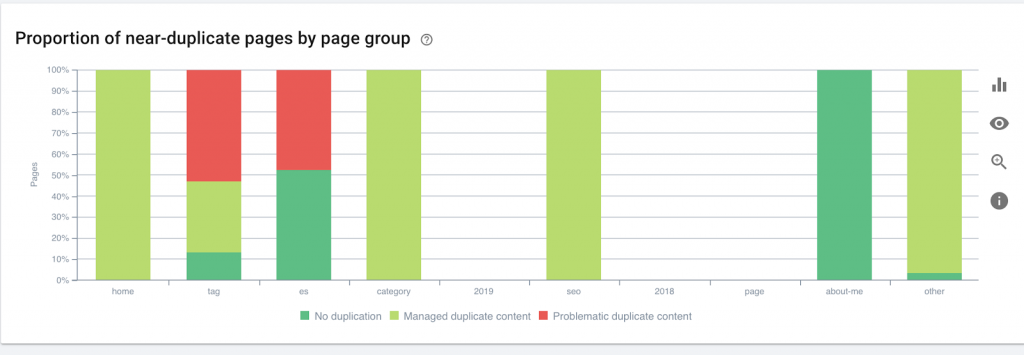
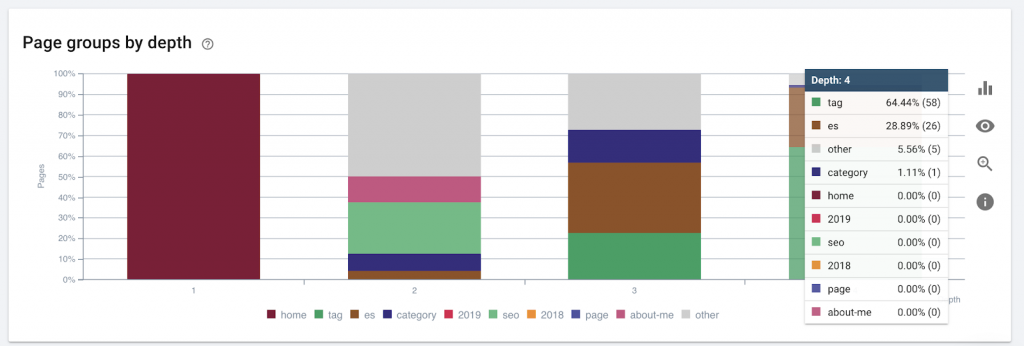
9)Profundidad/estructura del sitio
La profundidad de la página es el número de clics en los que se encuentra su página desde el dominio raíz. John Mueller de Google dijo que “las páginas más cercanas a la página de inicio tienen más peso”. Por ejemplo, imaginemos que la página aquí requiere la siguiente navegación para poder llegar:

La página “alfombras” está a 4 clics de la página de inicio. Se recomienda no tener páginas ubicadas a más de 4 clics de la casa, ya que los motores de búsqueda tienen dificultades para rastrear páginas más profundas.
Este gráfico muestra el grupo de páginas por profundidad. Nos ayuda a comprender si la estructura de un sitio web necesita ser reelaborada.
Como arreglarlo:
Las páginas que son más importantes deben estar más cerca de la página de inicio para UX, para facilitar el acceso de los usuarios y para una mejor estructura del sitio web. Es muy importante tener esto en cuenta al momento de crear la estructura de un sitio web o reestructurar un sitio web.
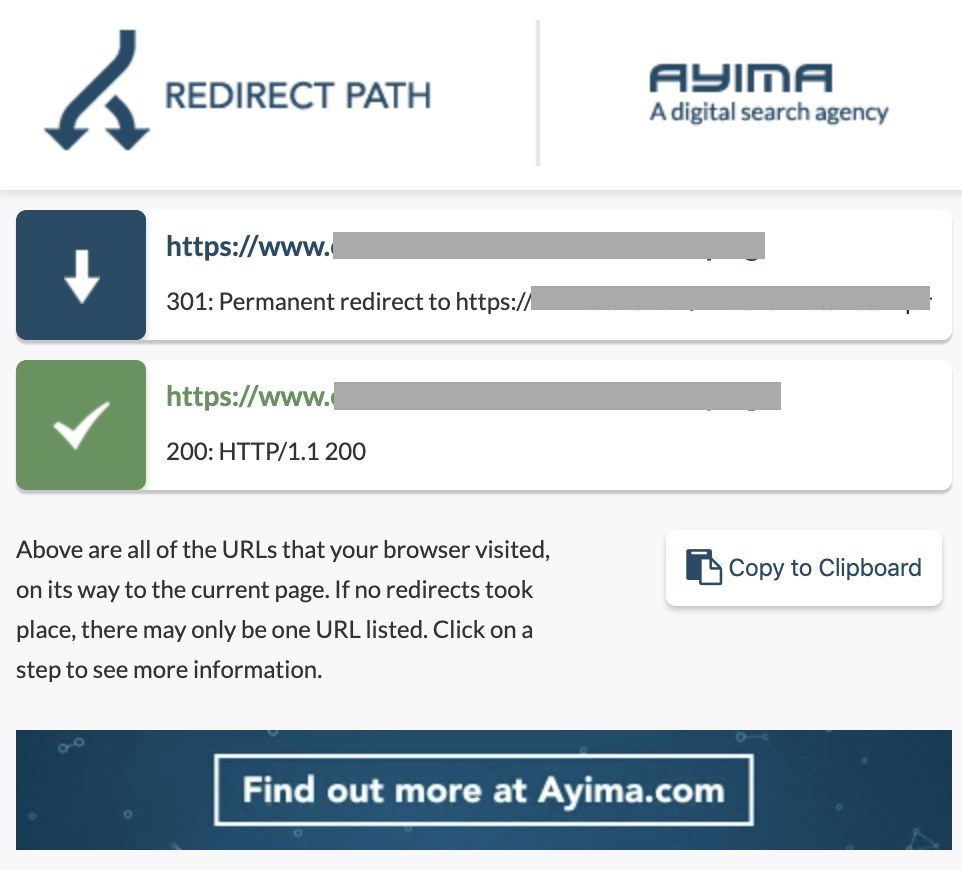
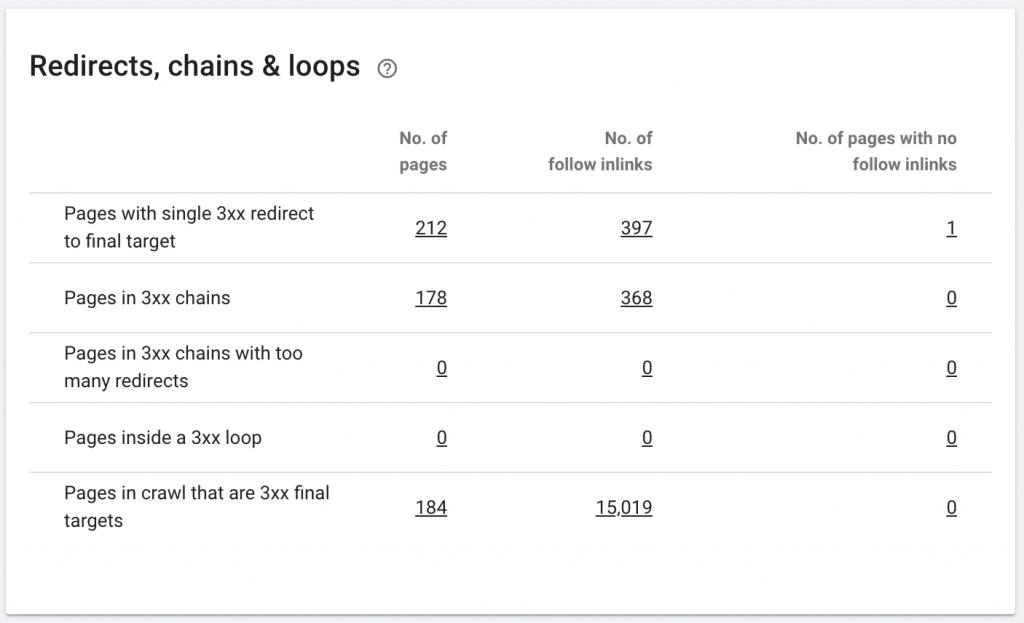
10. Cadenas de redirección
Una cadena de redireccionamiento es cuando ocurre una serie de redireccionamientos entre URL. Estas cadenas de redirección también pueden crear bucles. También presenta problemas para Googlebot y desperdicia el presupuesto de rastreo.
Podemos identificar cadenas de redirecciones usando la ruta de redirección de la extensión de Chrome, o en OnCrawl.
Como arreglarlo:
Arreglar esto es realmente fácil si está trabajando con un sitio web de WordPress. Simplemente vaya a la redirección y busque la cadena: elimine todos los enlaces involucrados en la cadena si esos cambios ocurrieron hace más de 2 o 3 meses y simplemente deje la última redirección a la URL actual. Los desarrolladores web también pueden ayudar con esto haciendo todos los cambios necesarios en el archivo .htacces, si es necesario. Puede verificar y cambiar las largas cadenas de redireccionamiento en sus complementos de SEO.
11) Canónicas
Una etiqueta canónica le dice a los motores de búsqueda que la URL es una copia de otra página. Este es un gran problema que está presente en muchos sitios web. No implementar canónicos de la manera correcta, o implementarlos en absoluto, creará problemas de contenido duplicado.
Los canónicos se usan comúnmente en sitios web de comercio electrónico donde un producto se puede encontrar varias veces en diferentes categorías, como: tamaño, color, etc.

Puede usar OnCrawl para saber si sus páginas tienen etiquetas canónicas y si están implementadas correctamente o no. A continuación, puede explorar y corregir cualquier problema.
Cómo lo arreglamos:
Podemos solucionar problemas canónicos usando Yoast SEO si estamos trabajando en WordPress. Vamos al panel de control de WordPress y luego a Yoast -configuración- avanzada.
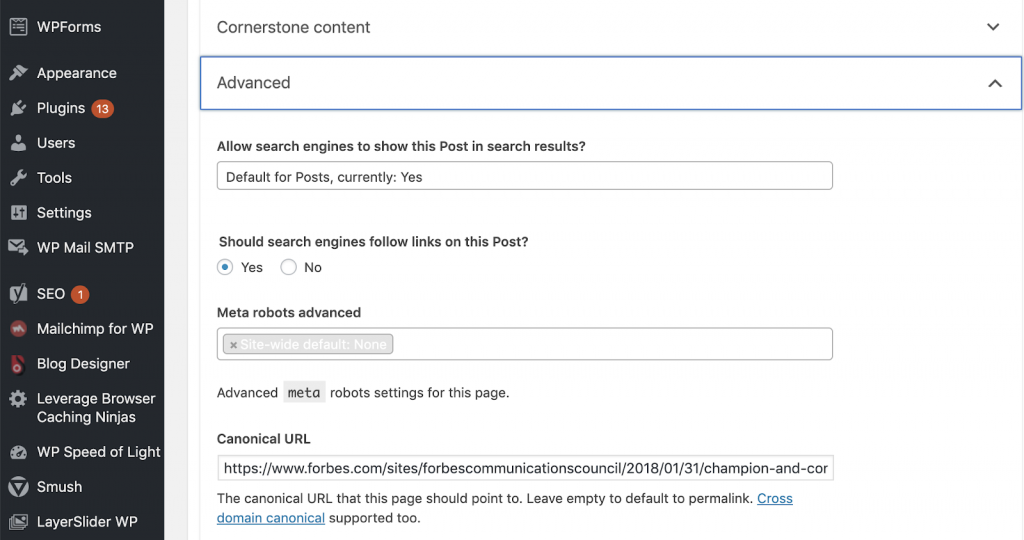
Ejecutar su propia auditoría
Los SEO que desean comenzar a sumergirse en el SEO técnico necesitan una guía de pasos rápidos a seguir para mejorar la salud del SEO. Hablando sobre SEO técnico con John Shehata, vicepresidente de Audience Grow en Conde Nast y fundador de NewzDash en el Global Marketing Day en Nueva York el pasado octubre de 2019.
Esto es lo que me dijo:
“Muchas personas en la industria de SEO no son técnicas. Ahora, no todos los SEO entienden cómo codificar y es difícil pedirle a la gente que haga esto. Algunas empresas, lo que hacen es contratar desarrolladores y capacitarlos para que se conviertan en SEO para llenar la brecha técnica de SEO”.
En mi opinión, los SEO que no tienen el conocimiento completo del código aún pueden hacerlo muy bien en Tech SEO al saber cómo ejecutar una auditoría, identificar elementos clave, informar, solicitar a los desarrolladores web la implementación y, finalmente, probar los cambios.
¿Listo para comenzar? Descargue la lista de verificación para estos problemas principales.
