
Evaluación de la calidad de las predicciones de impacto causal
Publicado: 2022-02-15CausalImpact es uno de los paquetes más populares utilizados en la experimentación de SEO. Su popularidad es comprensible.
La experimentación de SEO proporciona ideas interesantes y formas para que los SEO informen sobre el valor de su trabajo.
Sin embargo, la precisión de cualquier modelo de aprendizaje automático depende de la información de entrada que se le proporcione.
En pocas palabras, la entrada incorrecta puede devolver una estimación incorrecta.
En esta publicación, mostraremos cuán confiable (y no confiable) puede ser CausalImpact. También aprenderemos cómo tener más confianza en los resultados de sus experimentos.
En primer lugar, proporcionaremos una breve descripción general de cómo funciona CausalImpact. Luego, discutiremos la confiabilidad de las estimaciones de CausalImpact. Finalmente, aprenderemos sobre una metodología que se puede utilizar para estimar los resultados de sus propios experimentos de SEO.
¿Qué es CausalImpact y cómo funciona?
CausalImpact es un paquete que utiliza estadísticas bayesianas para estimar el efecto de un evento en ausencia de un experimento. Esta estimación se llama inferencia causal.
La inferencia causal estima si un cambio observado fue causado por un evento específico.
A menudo se utiliza para evaluar el rendimiento de los experimentos de SEO.
Por ejemplo, cuando se le da la fecha de un evento, CausalImpact (CI) utilizará los puntos de datos antes de la intervención para predecir los puntos de datos después de la intervención. Luego comparará la predicción con los datos observados y estimará la diferencia con un cierto umbral de confianza.
Además, los grupos de control se pueden utilizar para hacer que las predicciones sean más precisas.
Diferentes parámetros también tendrán un impacto en la precisión de la predicción:
- Tamaño de los datos de prueba.
- Duración del período previo al experimento.
- Elección del grupo de control con el que se comparará.
- Hiperparámetros de estacionalidad.
- Número de iteraciones.
Todos estos parámetros ayudan a proporcionar más contexto al modelo y mejorar su confiabilidad.
Inteligencia de negocios en rastreo
 Descubrir
Descubrir¿Por qué es importante evaluar la precisión de los experimentos de SEO?
En los últimos años, analicé muchos experimentos de SEO y algo me llamó la atención.
Muchas veces, el uso de diferentes grupos de control y marcos de tiempo en conjuntos de pruebas y fechas de intervención idénticos arrojó resultados diferentes.
A modo de ilustración, a continuación se muestran dos resultados del mismo evento.
El primero arrojó una disminución estadísticamente significativa. 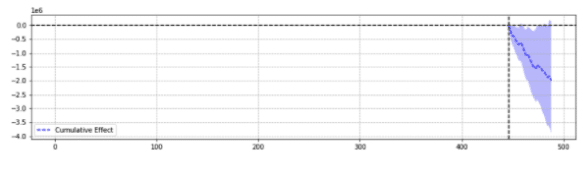
El segundo no fue estadísticamente significativo. 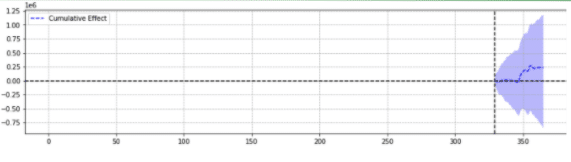
En pocas palabras, para el mismo evento, se devolvieron diferentes resultados en función de los parámetros elegidos.
Uno tiene que preguntarse qué predicción es precisa.
Al final, ¿no se supone que “estadísticamente significativo” aumenta la confianza en nuestras estimaciones?
Definiciones
Para comprender mejor el mundo de los experimentos SEO, el lector debe conocer los conceptos básicos de los experimentos SEO:
- Experimento : un procedimiento llevado a cabo para probar una hipótesis. En el caso de la inferencia causal, tiene una fecha de inicio específica.
- Grupo de prueba : un subconjunto de los datos a los que se aplica un cambio. Puede ser un sitio web completo o una parte del sitio.
- Grupo de control : un subconjunto de los datos al que no se le aplicó ningún cambio. Puede tener uno o varios grupos de control. Esto puede ser un sitio separado en la misma industria o una parte diferente del mismo sitio.
El siguiente ejemplo ayudará a ilustrar estos conceptos:
La modificación del título (experimento) debería aumentar el CTR orgánico en un 1% (hipótesis) de las páginas de productos en cinco ciudades (grupo de prueba). Las estimaciones se mejorarán utilizando un título sin cambios en todas las demás ciudades (grupo de control).
Pilares de la predicción precisa de experimentos de SEO
- Para simplificar, he recopilado algunas ideas interesantes para los profesionales de SEO que aprenden a mejorar la precisión de los experimentos:
- Algunas entradas en CausalImpact devolverán estimaciones incorrectas, incluso cuando sean estadísticamente significativas. Esto es lo que llamamos “falsos positivos” y “falsos negativos”.
- No existe una regla general que rija qué control usar contra un conjunto de prueba. Se requiere un experimento para definir los mejores datos de control para usar en un conjunto de prueba específico.
- El uso de CausalImpact con el control correcto y la longitud correcta de los datos previos al período puede ser muy preciso, con un error promedio tan bajo como 0,1 %.
- Alternativamente, el uso de CausalImpact con el control incorrecto puede conducir a una alta tasa de error. Experimentos personales mostraron variaciones estadísticamente significativas de hasta un 20%, cuando en realidad no hubo cambio.
- No todo se puede probar. Algunos grupos de prueba casi nunca arrojan estimaciones precisas.
- Los experimentos con o sin grupos de control necesitan diferentes longitudes de datos antes de la intervención.
No todos los grupos de prueba arrojarán estimaciones precisas
Algunos grupos de prueba siempre devolverán predicciones inexactas. No deben ser utilizados para la experimentación.
Los grupos de prueba con grandes variaciones de tráfico anormales a menudo arrojan resultados poco confiables.
Por ejemplo, en el mismo año, un sitio web tuvo una migración del sitio, se vio afectado por la pandemia de covid y parte del sitio estuvo "no indexado" durante 2 semanas debido a un error técnico. Hacer experimentos en ese sitio proporcionará resultados poco fiables.
Las conclusiones anteriores se recopilaron a través de una extensa serie de pruebas realizadas utilizando la metodología que se describe a continuación.
Cuando no se utilizan grupos de control
- Usar un control en lugar de un simple pre-post puede aumentar hasta 18 veces la precisión de la estimación.
- Usar 16 meses de datos anteriores fue tan preciso como usar 3 años.
Cuando se usan grupos de control
- Usar el control correcto a menudo es mejor que usar múltiples controles. Sin embargo, un solo control aumenta los riesgos de predicción errónea en los casos en que el tráfico del control varía mucho.
- Elegir el control correcto puede aumentar la precisión 10 veces (p. ej., uno reporta +3.1% y el otro +4.1% cuando en realidad fue +3%).
- La mayoría de los patrones de tráfico correlacionados entre los datos de prueba y los datos de control no significan necesariamente mejores estimaciones.
- Usar 16 meses de datos anteriores NO fue tan preciso como usar 3 años.
Tenga cuidado con la longitud de los datos antes de los experimentos
Curiosamente, al experimentar con grupos de control, el uso de 16 meses de datos anteriores puede causar una tasa de error muy intensa.
De hecho, los errores pueden ser tan grandes como estimar un aumento de tráfico de 3x cuando no hubo cambios reales.
Sin embargo, el uso de 3 años de datos eliminó esa tasa de error. Esto contrasta con los experimentos simples previos y posteriores en los que esa tasa de error no aumentó al aumentar la duración de 16 a 36 meses.
Eso no significa que usar controles sea malo. Es todo lo contrario.

Simplemente muestra cómo la adición de control afecta las predicciones.
Este es el caso cuando hay grandes variaciones en el grupo de control.
Esta conclusión es especialmente importante para los sitios web que han tenido variaciones anormales de tráfico en el último año (error técnico crítico, pandemia de COVID, etc.).
¿Cómo evaluar la predicción del impacto causal?
Ahora, no hay un puntaje de precisión integrado en la biblioteca CausalImpact. Por lo tanto, debe inferirse lo contrario.
Uno puede ver cómo otros modelos de aprendizaje automático estiman la precisión de sus predicciones y darse cuenta de que la Suma de errores cuadrados (SSE) es una métrica muy común.
La suma de errores cuadrados, o suma residual de cuadrados, calcula la suma de todas las (n) diferencias entre las expectativas (yi) y los resultados reales (f(xi)), al cuadrado. 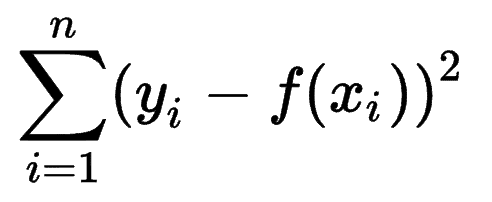
Cuanto menor sea el SSE, mejor será el resultado.
El desafío es que con los experimentos previos a la publicación sobre el tráfico de SEO, no hay resultados reales.
Aunque no se realizaron cambios en el sitio, algunos cambios pueden haber ocurrido fuera de su control (p. ej., actualización del algoritmo de Google, nuevo competidor, etc.). El tráfico SEO tampoco varía en un número fijo, sino que varía progresivamente hacia arriba y hacia abajo.
Los especialistas en SEO pueden preguntarse cómo superar el desafío.
Introducción de variaciones falsas
Para estar seguro del tamaño de la variación causada por un evento, el experimentador puede introducir variaciones fijas en diferentes puntos en el tiempo y ver si CausalImpact estimó con éxito el cambio.
Aún mejor, el experto en SEO puede repetir el proceso para diferentes grupos de prueba y control.
Usando Python, se introdujeron variaciones fijas a los datos en diferentes fechas de intervención para el período posterior.
Luego se estimó la suma de cuadrados de errores entre la variación reportada por CausalImpact y la variación introducida.
La idea es así:
- Elija una prueba y datos de control.
- Introducir intervenciones falsas en los datos reales en diferentes fechas (por ejemplo, 5% de aumento).
- Compare las estimaciones de CausalImpact con cada una de las variaciones introducidas.
- Calcule los errores de la suma de los cuadrados (SSE).
- Repita el paso 1 con varios controles.
- Elija el control con el SSE más pequeño para experimentos del mundo real
La metodología
Con la metodología a continuación, creé una tabla que podría usar para identificar qué control tenía las mejores y peores tasas de error en diferentes momentos.
Primero, elija una prueba y datos de control e introduzca variaciones de -50% a 50%.
Luego, ejecute CausalImpact (CI) y reste las variaciones informadas por CI a la variación que realmente introdujo.
Después, calcule los cuadrados de estas diferencias y sume todos los valores.
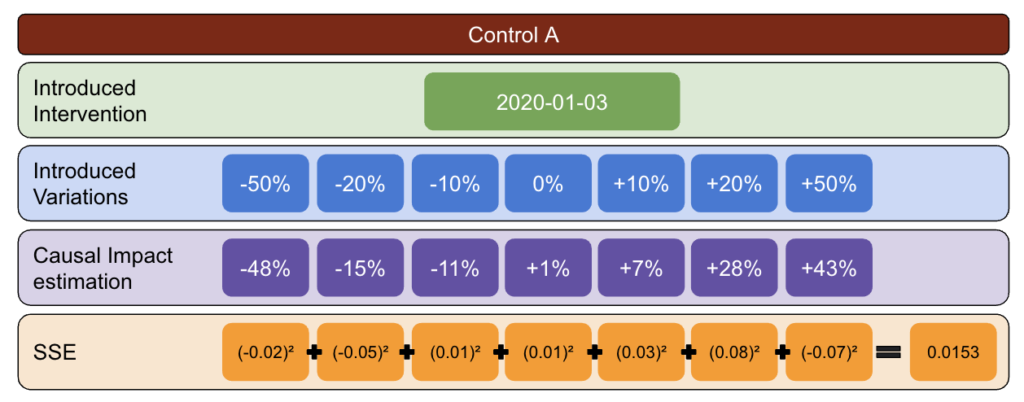
Luego, repita el mismo proceso en diferentes fechas para reducir el riesgo de un sesgo causado por una variación real en una fecha específica.
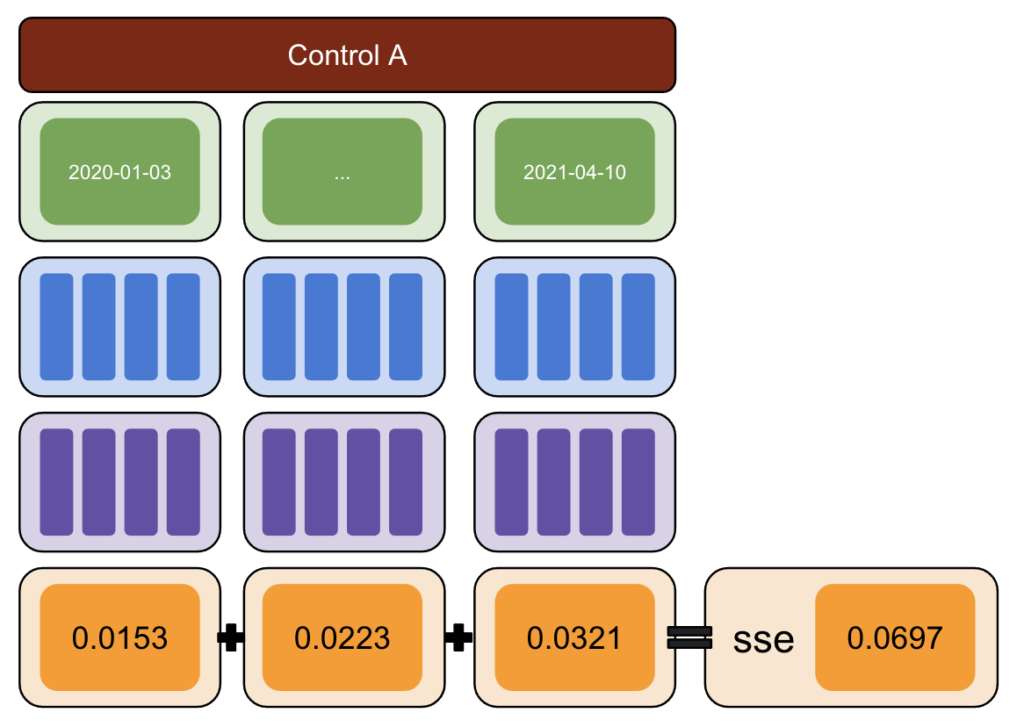
Nuevamente, repita con múltiples grupos de control.
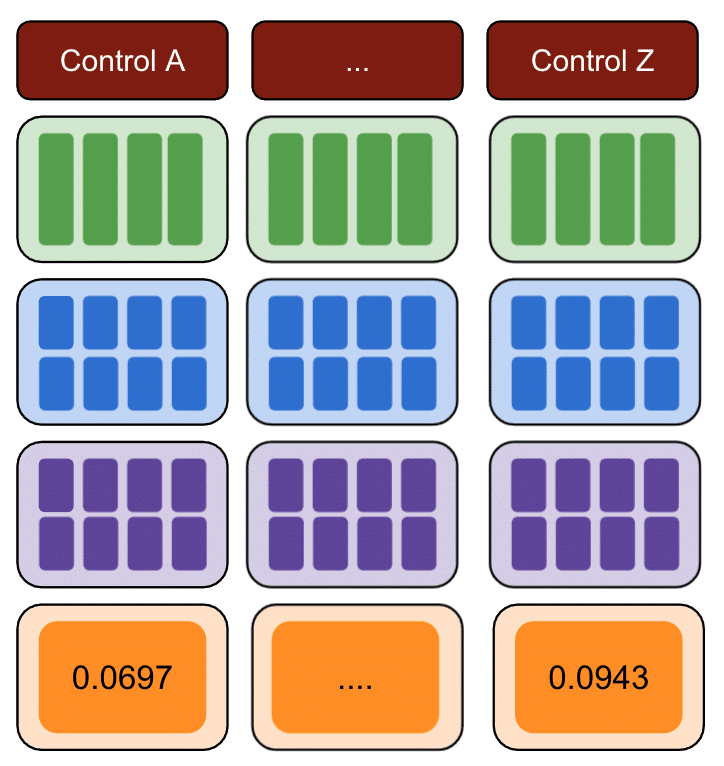
Finalmente, el control con la suma más pequeña de errores cuadrados es el mejor grupo de control para usar con sus datos de prueba.
Si repite cada uno de los pasos para cada uno de sus datos de prueba, el resultado variará.
En la tabla resultante, cada fila representa un grupo de control, cada columna representa un grupo de prueba. Los datos dentro son el SSE.
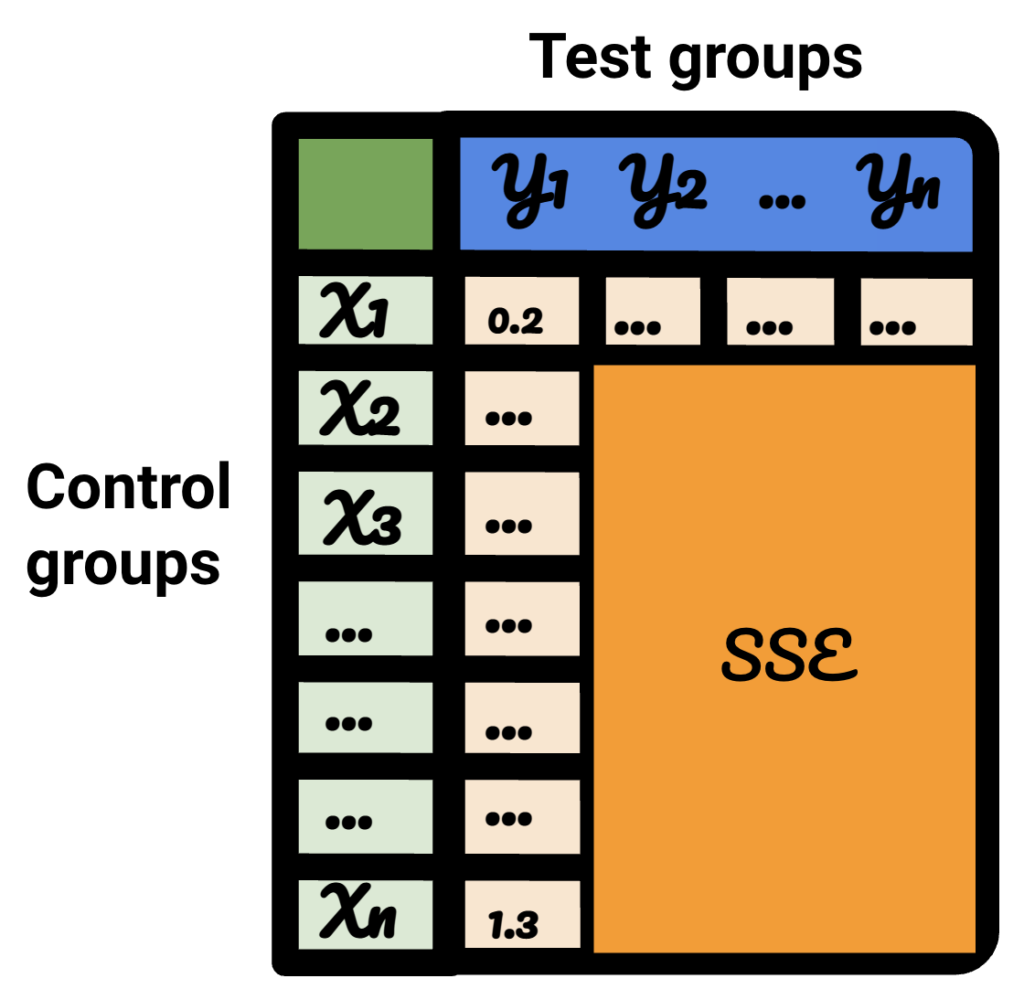
Ordenando esa tabla, ahora estoy seguro de que, para cada uno de los grupos de prueba, puedo seleccionar el mejor grupo de control para ello.
¿Deberíamos usar grupos de control o no?
La evidencia muestra que el uso de grupos de control ayuda a tener mejores estimaciones que el simple pre-post.
Sin embargo, esto es cierto solo si elegimos el grupo de control correcto.
¿Cuánto debe durar el período de estimación?
La respuesta a eso depende de los controles que estemos seleccionando.
Cuando no se utiliza un control, un experimento previo de 16 meses parece suficiente.
Al usar un control, usar solo 16 meses puede generar tasas de error masivas. El uso de 3 años ayuda a reducir el riesgo de mala interpretación.
¿Deberíamos usar 1 control o múltiples controles?
La respuesta a esa pregunta depende de los datos de prueba.
Los datos de prueba muy estables pueden funcionar bien cuando se comparan con múltiples controles. En este caso, esto es bueno porque usar mucho control hace que el modelo se vea menos afectado por fluctuaciones insospechadas en uno de los controles.
En otros conjuntos de datos, el uso de varios controles puede hacer que el modelo sea entre 10 y 20 veces menos preciso que el uso de uno solo.
Trabajo interesante en la comunidad SEO
CausalImpact no es la única biblioteca que se puede usar para pruebas de SEO, ni la metodología anterior es la única solución para probar su precisión.
Para conocer soluciones alternativas, lea algunos de los increíbles artículos compartidos por personas de la comunidad SEO.
En primer lugar, Andrea Volpini escribió un artículo interesante sobre cómo medir la eficacia del SEO mediante el análisis de impacto causal.
Luego, Daniel Heredia cubrió el paquete Prophet de Facebook para pronosticar tráfico SEO con Prophet y Python.
Si bien la biblioteca Prophet es más adecuada para realizar pronósticos que para experimentos, vale la pena aprender varias bibliotecas para obtener una comprensión sólida del mundo de las predicciones.
Finalmente, me complació mucho la presentación de Sandy Lee en Brighton SEO, donde compartió información sobre la ciencia de datos para las pruebas de SEO y planteó algunas de las trampas de las pruebas de SEO.
Cosas a considerar al hacer experimentos de SEO
- Las herramientas de prueba dividida de SEO de terceros son excelentes, pero también pueden ser inexactas. Sea minucioso al elegir su solución.
- Aunque escribí sobre esto en el pasado, no puede hacer experimentos de pruebas divididas de SEO con Google Tag Manager, a menos que esté del lado del servidor. La mejor manera es implementar a través de CDN.
- Sea audaz al probar. CausalImpact no suele detectar pequeños cambios.
- Las pruebas de SEO no siempre deben ser su primera opción.
- Existen alternativas para probar cambios más pequeños, como etiquetas de título. Pruebas A/B de Google Ads o pruebas A/B en plataforma. Las pruebas A/B reales son más precisas que las pruebas divididas de SEO y, por lo general, brindan más información sobre la calidad de sus títulos.
Resultados reproducibles
En este tutorial, quería centrarme en cómo se podría mejorar la precisión de los experimentos de SEO sin la carga de saber codificar. Además, la fuente de los datos puede variar y cada sitio es diferente.
Por lo tanto, el código de Python que utilicé para producir este contenido no formaba parte del alcance de este artículo.
Sin embargo, con la lógica, puede reproducir los experimentos anteriores.
Conclusión
Si solo tuviera una conclusión que sacar de este artículo, sería que el análisis CausalImpact puede ser muy preciso, pero siempre puede estar muy lejos.
Es muy importante que los SEO que deseen utilizar este paquete entiendan a qué se enfrentan. El resultado de mi propio viaje es que no confiaría en CausalImpact sin probar primero la precisión del modelo en los datos de entrada.