
Potenciar la seguridad bancaria: aprendizaje automático para la detección de fraude
Publicado: 2023-11-14Con cada oportunidad viene una amenaza. El cambio hacia la digitalización en la industria bancaria mejoró la experiencia del cliente y amplió las bases de clientes a poblaciones que antes no estaban bancarizadas. La desventaja fue que las transacciones en línea y las soluciones de pago digitales abrieron nuevas vías para que las explotaran los estafadores.
Los resultados de una encuesta sobre fraude de KMPG indican que los ciberataques están aumentando en frecuencia y gravedad, lo que genera pérdidas de miles de millones de dólares.
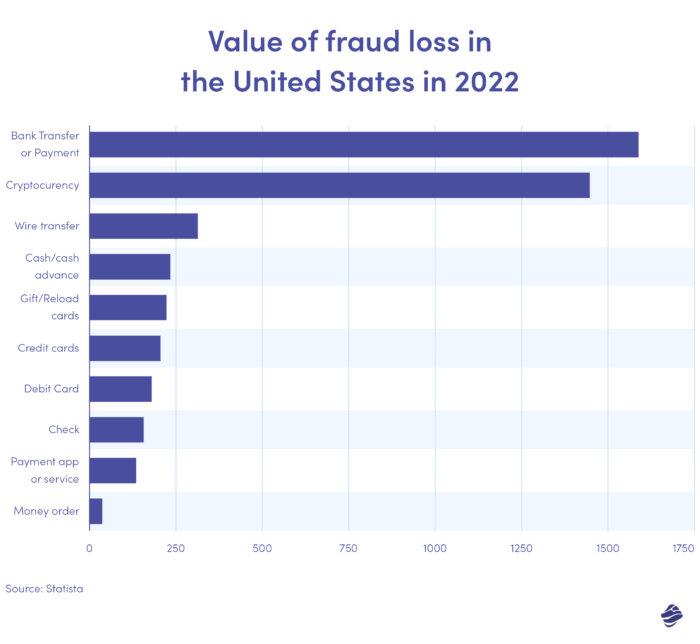
El gráfico anterior ilustra el valor de las pérdidas por fraude por método de pago en los Estados Unidos en 2022. Las transferencias y pagos bancarios fueron los más altos, con una pérdida de 1.590 millones de dólares.
Estas pérdidas han obligado a las instituciones bancarias a adoptar nuevas soluciones para detectar, mitigar y prevenir el fraude financiero. Uno de esos métodos es la inteligencia artificial (IA), específicamente el aprendizaje automático.
En este artículo, analizaremos todo lo que necesita saber sobre el aprendizaje automático para la detección de fraude , incluidos los beneficios y las aplicaciones de la vida real.
Evolución de la detección de fraude
La detección de fraude tradicional sigue un enfoque basado en reglas. Como sugiere el nombre, opera bajo un conjunto de reglas o condiciones que determinan si una transacción es genuina o fraudulenta. Las condiciones habituales incluyen la ubicación (¿la compra está fuera de la zona habitual del usuario?) y la frecuencia (¿el número y tipo de compra es habitual para el usuario?).
Una transacción sólo se realiza cuando cumple las condiciones. Por ejemplo, un cliente en Ohio de repente tiene un cargo de POS en Nueva Zelanda. La ubicación está fuera del código de área del usuario, por lo que el sistema marca las transacciones como fraudulentas.
Este tipo de sistema de detección de fraude presenta varios inconvenientes.
- Produce un elevado número de falsos positivos. Aquí es donde bloqueas los pagos de clientes genuinos.
- Es inflexible. El enfoque basado en reglas utiliza resultados fijos, lo que dificulta la adaptación a las tendencias de la banca digital. Debe cambiar las reglas para detectar nuevas formas de fraude.
- No escala. Cuando los datos aumentan, también aumenta el esfuerzo necesario para evitarlos. Cualquier cambio en el sistema se realiza manualmente, lo que lo hace costoso y requiere mucho tiempo.
La detección de fraude basada en reglas funciona. Sin embargo, sus desventajas lo hacen inadecuado para los entornos digitales modernos. No puede reconocer patrones y depende de la intervención humana.
Además, los piratas informáticos no siguen un horario de 9 a 5 y pueden implementar métodos sofisticados como la suplantación de ubicación y la suplantación del comportamiento del cliente para engañar a los sistemas de detección de fraude. Por lo tanto, necesita un sistema igualmente altamente desarrollado que funcione 24 horas al día, 7 días a la semana.
Ingrese al aprendizaje automático.
El aprendizaje automático es una inteligencia artificial (IA) que utiliza datos para entrenar algoritmos de detección de fraude para descubrir patrones y relaciones de datos, obtener información y hacer predicciones.
Ya estás familiarizado con el aprendizaje automático, aunque no lo sepas. Por ejemplo, cada vez que interactúas con una publicación de Instagram, le proporcionas al algoritmo información sobre el tipo de contenido que te gusta. Luego busca en la aplicación contenido similar para agregar a su feed.
Cómo el aprendizaje automático transformará la detección de fraude
La detección de fraude en la banca mediante el aprendizaje automático ya está cambiando la industria, con una identificación y respuesta al fraude más rápida, flexible y precisa.
El sistema de IA analiza patrones en los datos de los clientes y cambia automáticamente las reglas en función de amenazas históricas y emergentes.
¿Recuerda el cargo de POS de Nueva Zelanda que mencionamos anteriormente? La detección de fraude mediante aprendizaje automático consideraría que la misma tarjeta bancaria tiene una compra para un vuelo a esa ubicación. Por lo tanto, lo más probable es que el nuevo débito sea legítimo.
Se utilizan dos modelos para entrenar algoritmos para detectar fraude: aprendizaje automático supervisado y aprendizaje automático no supervisado.
Aprendizaje automático supervisado
El modelo de aprendizaje supervisado alimenta a los algoritmos con grandes cantidades de datos etiquetados como fraudulentos o no fraudulentos. El algoritmo estudia estos ejemplos y aprende qué patrones y relaciones distinguen las transacciones legítimas de las fraudulentas.
Este modelo de aprendizaje requiere mucho tiempo ya que requiere el etiquetado manual de datos. Además, sus conjuntos de datos deben estar correctamente etiquetados y bien organizados. Una transacción etiquetada incorrectamente afectará la precisión del algoritmo.
Además, sólo aprende de las entradas incluidas en el conjunto de formación. Por lo tanto, las transacciones a través de las funciones de su aplicación de banca móvil recientemente lanzada que no formaran parte de los datos históricos no se marcarían. Ahora existe un vacío legal que los estafadores pueden aprovechar.
Aprendizaje automático no supervisado
El modelo de aprendizaje no supervisado utiliza una mínima aportación humana. El algoritmo aprende patrones y relaciones a partir de grandes cantidades de datos sin etiquetar, agrupando conjuntos de datos en función de similitudes y diferencias.
El objetivo es detectar actividad inusual no incluida en el conjunto de datos de entrenamiento. Por lo tanto, el aprendizaje no supervisado se recupera donde el aprendizaje supervisado disminuye y detecta nuevos fraudes.
Recuerde que no tiene que elegir entre un modelo de aprendizaje automático supervisado o no supervisado. Puedes utilizarlos juntos (modelo de aprendizaje semisupervisado) o de forma independiente.
Beneficios de utilizar ML para la detección de fraude
Hemos insinuado los beneficios de la detección de fraude mediante el aprendizaje automático en la banca, pero analicémoslos más a fondo.
- Velocidad
Los cálculos de aprendizaje automático se realizan rápidamente y brindan decisiones sobre fraude en tiempo real. Si bien los algoritmos basados en reglas también deciden en tiempo real, se basan en reglas escritas para detectar fraudes.
¿Qué sucede en nuevos escenarios sin reglas predefinidas? Conduce a falsos positivos o falsos negativos.
El aprendizaje automático detecta nuevos patrones automáticamente, analiza la actividad habitual de los clientes y calcula los resultados adecuados en milisegundos.
- Exactitud
Los sistemas de detección basados en reglas bloquean transacciones genuinas o permiten transacciones fraudulentas porque no detectan matices en el comportamiento del cliente.
Los sistemas de aprendizaje automático consideran variables más allá de las reglas escritas, por ejemplo, comportamientos fraudulentos conocidos. Estas variables ayudan a contextualizar la transacción, reduciendo la tasa de falsos positivos.
- Flexibilidad
El aprendizaje automático es flexible y reactivo. La capacidad de autoaprendizaje permite a este sistema adaptarse a nuevos escenarios y detectar nuevas amenazas. Los sistemas basados en reglas son rígidos y no tienen capacidades de aprendizaje. Por lo tanto, sólo puede responder a actividades fraudulentas según reglas predefinidas.
- Eficiencia
Los algoritmos de aprendizaje automático pueden analizar miles de datos de transacciones por segundo. En lugar de gastar mano de obra y costos generales en investigar casos de fraude de bajo a moderado, el aprendizaje automático puede procesar fraudes repetitivos o claros. Permite a los especialistas en fraude centrarse en patrones complejos que necesitan conocimiento humano.
- Escalabilidad
El aumento del volumen de datos ejerce presión sobre los sistemas basados en reglas. Las nuevas reglas aumentan la complejidad del sistema, lo que dificulta su mantenimiento. Cualquier error o contradicción puede hacer que todo el modelo sea ineficaz.
Los sistemas de aprendizaje automático son todo lo contrario. No sólo asimilan grandes volúmenes de nuevos datos, sino que también mejoran.
Técnicas de aprendizaje automático utilizadas en la detección de fraude
Antes de examinar los diferentes algoritmos utilizados en la detección de fraude mediante IA, repasemos cómo funciona el sistema.
El primer paso es la entrada de datos. La precisión del modelo depende del volumen y la calidad de los datos. Cuantos más datos de alta calidad agregue, más preciso será el modelo.
A continuación, el modelo analiza los datos y extrae características clave que describen comportamientos normales frente a comportamientos fraudulentos. Estas características incluyen identidad del cliente (correo electrónico o número de teléfono), ubicación (IP o dirección de envío), métodos de pago (nombre del titular de la tarjeta y país de origen) y más.
El tercer paso es entrenar el algoritmo (con más datos) para distinguir entre transacciones genuinas y fraudulentas. El modelo recibe un conjunto de datos de entrenamiento y predice la probabilidad de fraude en varios casos. Una vez que el algoritmo esté suficientemente entrenado, estará listo para ejecutarlo.
Ahora, veamos los diversos algoritmos que puede utilizar.
1. Regresión logística
La regresión logística es un algoritmo de aprendizaje supervisado. Calcula la probabilidad de fraude en una escala binaria (fraude o no fraude) en función de los parámetros del modelo.
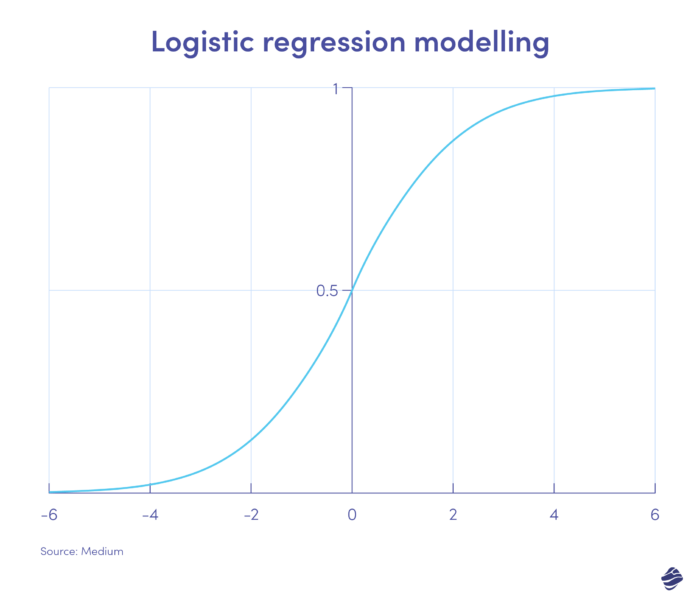
Las transacciones que se encuentran en el lado positivo del gráfico probablemente sean fraudulentas, mientras que las del lado negativo probablemente sean legítimas.
2. Árbol de decisión
Un árbol de decisión es un algoritmo de aprendizaje supervisado, pero va más allá de los algoritmos de regresión logística. Es una estructura de decisión jerárquica que analiza datos en niveles para determinar si una transacción es genuina o fraudulenta.
A continuación se muestra una ilustración de un árbol de decisiones para la detección de fraudes con tarjetas de crédito.
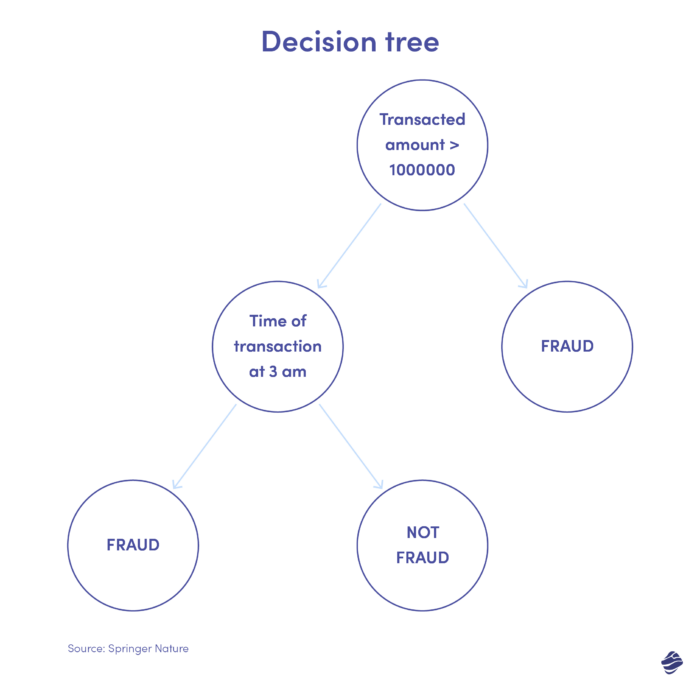
La condición para identificar si la transacción es fraudulenta es el monto de la transacción. Si el valor de la transacción supera un umbral establecido, el algoritmo la considera fraudulenta. De lo contrario, el árbol verifica otra condición: el tiempo de transacción. Si el horario es inusual (aquí, las 3 am), es probable que se trate de un fraude. En caso contrario, verifica otra condición. Continúa.
3. Bosque aleatorio
El bosque aleatorio es una combinación de muchos árboles de decisión, donde cada árbol de decisión verifica diferentes condiciones: identidad, ubicación, etc.
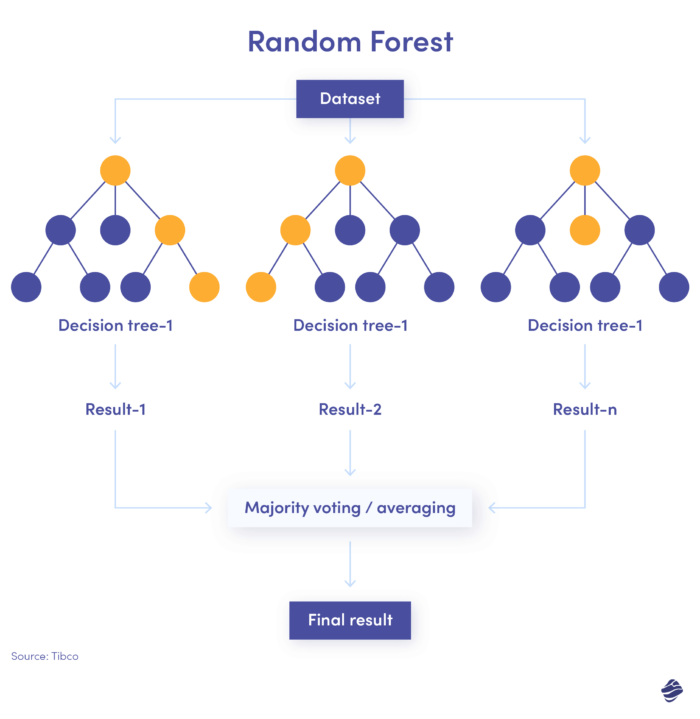
Después de comprobar todos los parámetros, cada subárbol ofrece una decisión. El total combinado determina si la transacción es genuina o fraudulenta.

4. Redes neuronales
Las redes neuronales son algoritmos complejos y no supervisados. Inspiradas en el cerebro humano, las redes neuronales procesan datos en múltiples capas para extraer características de alto nivel. Este algoritmo va de la mano del aprendizaje profundo, que puede reconocer patrones en imágenes, texto, audio y otros datos.
Aquí hay una versión simplificada de una red neuronal.
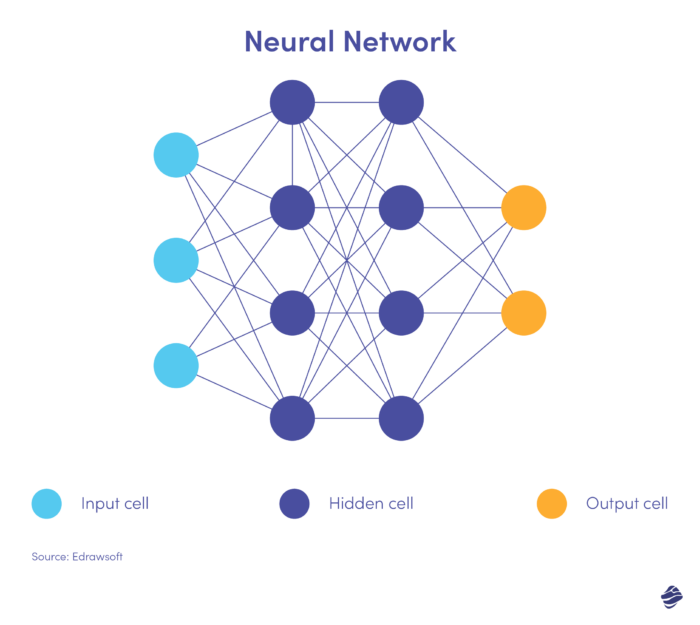
Una red neuronal tiene tres capas: entrada, oculta y salida. La capa de entrada procesa datos, la capa oculta analiza los datos de la capa de entrada para identificar patrones ocultos y la capa de salida clasifica los datos.
Las redes neuronales profundas tienen varias capas ocultas. Son excelentes para identificar relaciones no lineales y detectar escenarios de fraude sin precedentes.
5. Máquina de vectores de soporte
Las máquinas de vectores de soporte (SVM) son algoritmos de aprendizaje supervisado que predicen, clasifican y detectan valores atípicos.
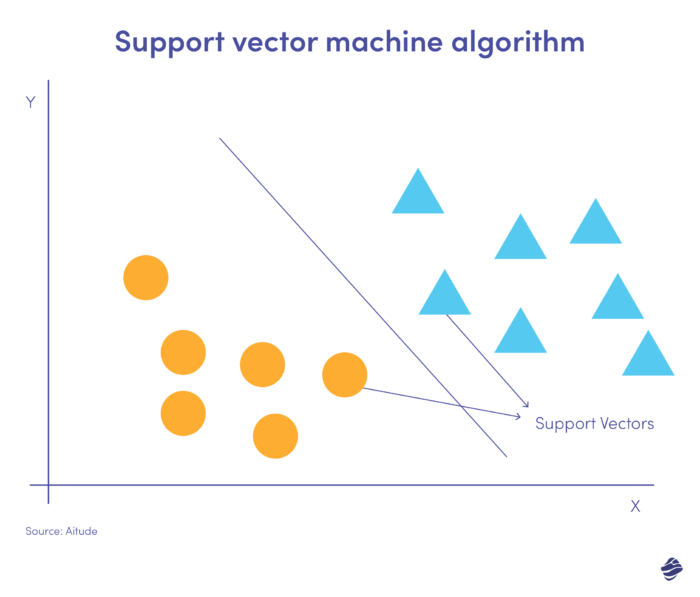
Esta ilustración lineal de SVM muestra dos conjuntos de datos separados por una línea recta llamada hiperplano. Es el límite de decisión el que clasifica los datos como fraudulentos o no fraudulentos.
Los puntos de datos más alejados del hiperplano se clasifican fácilmente. Los vectores de soporte (los más cercanos al hiperplano) son difíciles de categorizar. Estos valores atípicos pueden afectar la posición del hiperplano si se eliminan.
6. K-vecino más cercano
K-vecino más cercano (KNN) es un algoritmo de aprendizaje supervisado. Opera bajo el supuesto de que existen elementos similares cerca unos de otros.
A continuación se muestra una ilustración sencilla.
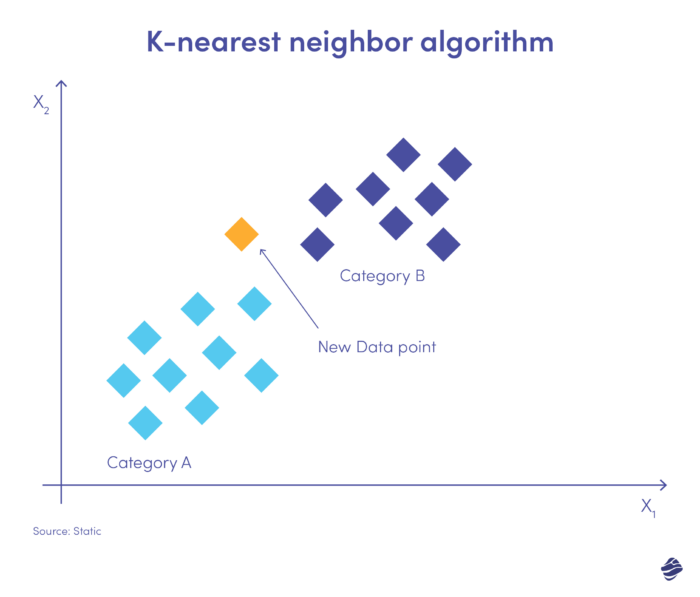
La nueva entrada de datos debe colocarse en la categoría A o B. El algoritmo calcula la distancia entre puntos de datos utilizando una ecuación matemática llamada distancia euclidiana. El nuevo punto de datos pertenece al grupo con más vecinos. Si el conjunto de datos más cercano está etiquetado como "fraude", esa transacción se clasifica como fraudulenta.
Navegando desafíos y consideraciones estratégicas
Como toda tecnología, existen dificultades crecientes asociadas con la integración del aprendizaje automático para la detección de fraude. A continuación se detallan algunos desafíos comunes que puede enfrentar.
Infraestructura inadecuada
Muchos sistemas bancarios no pueden analizar grandes cantidades de datos complejos. Además, la mayoría de los datos están aislados y alojados en instalaciones de almacenamiento independientes.
Desafortunadamente, no existe una solución rápida para este problema. Tienes que invertir en el hardware y software adecuados.
Deberá asociarse con una agencia de desarrollo de aplicaciones Fintech con experiencia y configurar una infraestructura para seleccionar automáticamente algoritmos apropiados para conjuntos de datos específicos, importar datos sin procesar y prepararlos para el aprendizaje automático, visualizar los datos, probar el algoritmo y más.
Calidad y seguridad de los datos
La calidad de los datos es un tema importante para las instituciones financieras que buscan implementar el aprendizaje automático para la detección de fraude. Los modelos de aprendizaje automático no distinguen entre datos buenos y malos. Por lo tanto, si el algoritmo está contaminado con datos irrelevantes o incompletos, la precisión de su modelo será incorrecta.
Las soluciones de ingesta de datos como Amazon Kinesis recopilan, limpian y transforman datos sin procesar, lo que los hace adecuados para modelos de aprendizaje automático. Una vez que los datos estén limpios y organizados, debe separar los datos confidenciales de los insensibles. Cifre la información confidencial y guárdela en instalaciones seguras. También debe limitar el acceso a estos datos.
falta de talento
A pesar de lo que la gente teme, el aprendizaje automático no está robando empleos. Es todo lo contrario. Todavía necesitamos analistas de fraude para gestionar casos complejos que requieren conocimiento y experiencia humanos. Además, el aprendizaje automático es una tecnología nueva y no hay suficientes expertos en el campo.
Esta es una buena noticia para quienes buscan empleo, pero no para las instituciones que no pueden aprovechar todo el potencial del aprendizaje automático. Puede superar este obstáculo asociándose con empresas con las habilidades necesarias para implementar el aprendizaje automático.
Estudios de casos de detección de fraude en banca mediante aprendizaje automático
Ahora, veamos ejemplos de la vida real de detección de fraude en la banca mediante el aprendizaje automático.
Detección de fraude
Danske Bank es una corporación financiera multinacional danesa. Es el banco más grande de Dinamarca y un banco minorista líder en el norte de Europa. Bajo el sistema de detección basado en reglas, el banco luchó por mitigar el fraude. Tenía una tasa de detección de fraude del 40% y una tasa de falsos positivos del 99,5%.
Al trabajar con Teradata, una empresa de software de datos, Danske integró software de aprendizaje profundo para ayudar a identificar posibles actividades fraudulentas. El resultado fue una reducción del 60 % en los falsos positivos y un aumento del 50 % en los verdaderos positivos.
Anti lavado de dinero
OakNorth es un banco de préstamos comerciales en el Reino Unido que brinda servicios financieros personales y comerciales a empresas en expansión. El banco tenía un proceso de selección fracturado, con un proveedor para los controles contra el lavado de dinero y otro para los clientes. Además, los exámenes de detección de personas políticamente expuestas (PEP) generaron muchos falsos positivos.
Al trabajar con ComplyAdvantage, una empresa de detección de fraude y AML, el banco integró una solución de detección y monitoreo continuo para optimizar el cumplimiento y consolidar los datos. Esto facilitó la rápida transferencia de datos entre las operaciones de préstamo y ahorro del banco.
Suscripción de crédito
Hawaii USA Credit Union es la cooperativa de crédito más grande de Hawái y una de las mejores cooperativas de crédito de la revista Forbes. Quería ser competitivo frente a las empresas Fintech y hacer crecer su cartera de préstamos personales sin aumentar el riesgo.
Al trabajar con Zest AI, la cooperativa de crédito automatizó sus procesos de toma de decisiones utilizando un modelo de préstamos personales impulsado por IA. El modelo utilizó 278 variables para proporcionar información más profunda que el sistema de calificación crediticia VantageScore. El resultado fue un aumento del 21% en la tasa de aprobaciones y una tasa de fraude en solicitudes de préstamo/incumplimiento del 0%.
Consideraciones clave al utilizar ML para la detección de fraude
Si bien la detección de fraude en la banca mediante el aprendizaje automático es eficiente, también resulta desalentadora. Estos sistemas exigen muchos datos precisos o los modelos no funcionan tan bien como deberían.
Por eso, a continuación se ofrecen algunos consejos para optimizar el proceso de aprendizaje automático.
1. Limite el número de variables de entrada
A lo largo de este artículo, hemos dicho que más es más. Esto sigue siendo cierto respecto del volumen de datos. Sin embargo, menos es más con la cantidad de variables de detección de fraude.
Las características típicas a considerar al investigar el fraude incluyen:
- dirección IP
- Dirección de correo electrónico
- Dirección de envío
- Valor medio de pedido/transacción
El beneficio de tener menos funciones es que los tiempos de entrenamiento de algoritmos son más cortos. También evita problemas de conjuntos de datos superpuestos o irrelevantes.
2. Garantizar el cumplimiento normativo
Prevenir el fraude es una parte de la seguridad de los datos. El otro es la privacidad de los datos. Muchos países tienen leyes sobre cómo las instituciones pueden recopilar, utilizar y almacenar datos de los clientes. Está la Ley de Protección de Información Personal de China (PIPL), la Ley de Privacidad del Consumidor de California (CCPA) y el Reglamento General de Protección de Datos (GDPR) de la Unión Europea, por nombrar algunos.
Estas leyes tienen implicaciones para los datos utilizados en el aprendizaje automático. El principio fundamental en la mayoría de las normas de cumplimiento de privacidad de datos es el aviso/consentimiento. Debe notificar y recibir permiso para utilizar los datos del cliente para fines distintos a las solicitudes de los usuarios, incluidos datos para entrenar algoritmos de aprendizaje automático.
La forma más sencilla de garantizar el cumplimiento de los estándares de privacidad es utilizar socios técnicos con funciones que cumplan con las normativas. Por ejemplo, debería asociarse con una empresa de desarrollo de aplicaciones bancarias que sepa cómo mantener la privacidad y la seguridad de los datos.
3. Establecer un umbral razonable
Las reglas de valor de transacción tienen requisitos mínimos para desencadenar una respuesta de aceptación o rechazo. Quiere un umbral que equilibre la seguridad y la experiencia del usuario. Si el umbral es demasiado estricto, corre el riesgo de bloquear transacciones legítimas. Si el umbral es demasiado laxo, aumentará la tasa de fraude exitoso.
Calcule su apetito por el riesgo para encontrar el equilibrio adecuado. Los niveles de riesgo difieren para cada institución financiera o producto. Por ejemplo, una oferta bancaria de microcréditos puede establecer un umbral alto para préstamos de bajo valor. Un banco comercial no puede ser tan generoso con los préstamos hipotecarios.
Anticipando el futuro
El futuro es ahora, pero solo el 17 % de las organizaciones utilizan el aprendizaje automático en programas antifraude. No te quedes atrás.
A continuación se muestran algunos avances que puede esperar en la seguridad de su banco a través del aprendizaje automático.
- Perfilado de dispositivos : identifique los diferentes dispositivos que se conectan a su red bancaria, analizando las características y comportamientos de cada dispositivo.
- Detección y respuesta automatizadas de anomalías : identifique comportamientos fraudulentos de dispositivos conocidos y aísle los sistemas afectados.
- Detección de día cero : identifique vulnerabilidades y malware previamente desconocidos para proteger a las organizaciones de los ciberataques.
- Enmascaramiento de datos : detecta automáticamente y anonimiza datos confidenciales.
- Información ampliada : identifique tendencias de fraude en múltiples dispositivos y ubicaciones.
- Política innovadora : utilice conocimientos de aprendizaje automático para impulsar políticas de seguridad relevantes.
Ya sea que sea una institución de gestión patrimonial o una cooperativa de crédito, la inteligencia artificial y el aprendizaje automático ofrecen enormes oportunidades para la detección de fraude.
Sin embargo, es fundamental recordar que los piratas informáticos también utilizan estas tecnologías para eludir las medidas de protección. Actualice sus modelos de aprendizaje automático para adelantarse a estos ataques. También puede fortalecer su seguridad basada en IA con la vieja inteligencia humana.