
Una introducción al rastreador web
Publicado: 2016-03-08Cuando hablo con la gente sobre lo que hago y qué es el SEO, por lo general lo entienden bastante rápido o actúan como lo hacen. Una buena estructura del sitio web, un buen contenido, buenos backlinks de respaldo. Pero a veces, se vuelve un poco más técnico y termino hablando de motores de búsqueda que rastrean tu sitio web y generalmente los pierdo...
¿Por qué rastrear un sitio web?
El rastreo web comenzó con el mapeo de Internet y cómo cada sitio web estaba conectado entre sí. También fue utilizado por los motores de búsqueda para descubrir e indexar nuevas páginas en línea. Los rastreadores web también se utilizaron para probar la vulnerabilidad del sitio web al probar un sitio web y analizar si se detectó algún problema.
Ahora puede encontrar herramientas que rastrean su sitio web para brindarle información. Por ejemplo, OnCrawl proporciona datos sobre su contenido y SEO en el sitio o Majestic, que proporciona información sobre todos los enlaces que apuntan a una página.
Los rastreadores se utilizan para recopilar información que luego se puede usar y procesar para clasificar documentos y proporcionar información sobre los datos recopilados.
La construcción de un rastreador es accesible para cualquier persona que sepa un poco de código. Sin embargo, hacer un rastreador eficiente es más difícil y lleva tiempo.
Como funciona ?
Para rastrear un sitio web o la web, primero necesita un punto de entrada. Los robots necesitan saber que su sitio web existe para poder visitarlo. En el pasado, habría enviado su sitio web a los motores de búsqueda para decirles que su sitio web estaba en línea. ¡Ahora puede crear fácilmente algunos enlaces a su sitio web y listo!
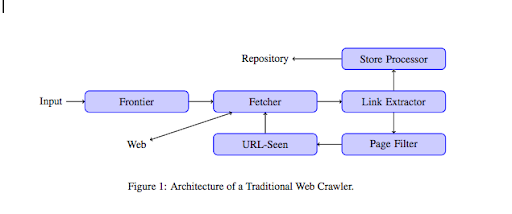
Una vez que un rastreador aterriza en su sitio web, analiza todo su contenido línea por línea y sigue cada uno de los enlaces que tiene, ya sean internos o externos. Y así hasta que llegue a una página sin más enlaces o encuentre errores como 404, 403, 500, 503.
Desde un punto de vista más técnico, un rastreador funciona con una semilla (o lista) de URL. Esto se pasa a un Fetcher que recuperará el contenido de una página. Luego, este contenido se traslada a un extractor de enlaces que analizará el HTML y extraerá todos los enlaces. Estos enlaces se envían a un procesador Store que, como su nombre indica, los almacenará. Estas URL también pasarán por un filtro de página que enviará todos los enlaces interesantes a un módulo visto por URL. Este módulo detecta si la URL ya ha sido vista o no. Si no, se envía a Fetcher, que recuperará el contenido de la página y así sucesivamente.
Tenga en cuenta que algunos contenidos son imposibles de rastrear para las arañas, como Flash. Javascript está siendo rastreado correctamente por GoogleBot, pero de vez en cuando no rastrea nada de eso. Las imágenes no son contenido que Google pueda rastrear técnicamente, ¡pero se volvió lo suficientemente inteligente como para comenzar a comprenderlas!
Si a los robots no se les dice lo contrario, rastrearán todo. Aquí es donde el archivo robots.txt se vuelve muy útil. Les dice a los rastreadores (puede ser específico por rastreador, es decir, GoogleBot o MSN Bot; obtenga más información sobre los bots aquí) qué páginas no pueden rastrear. Digamos, por ejemplo, que tiene navegación mediante facetas, es posible que no desee que los robots las rastreen todas, ya que tienen poco valor agregado y usarán el presupuesto de rastreo. Usar esta sencilla línea te ayudará a evitar que cualquier robot la rastree
Agente de usuario: *
No permitir: /carpeta-a/
Esto le dice a todos los robots que no rastreen la carpeta A.
Agente de usuario: GoogleBot
No permitir: /repertorio-b/
Esto, por otro lado, especifica que solo Google Bot no puede rastrear la carpeta B.
También puede usar una indicación en HTML que le dice a los robots que no sigan un enlace específico usando la etiqueta rel=”nofollow”. Algunas pruebas han demostrado que incluso el uso de la etiqueta rel=”nofollow” en un enlace no impedirá que Googlebot lo siga. Esto es contradictorio con su propósito, pero será útil en otros casos.
[Estudio de caso] Aumente la visibilidad mejorando la capacidad de rastreo del sitio web para Googlebot
 Lea el estudio de caso
Lea el estudio de caso
Mencionaste el presupuesto de rastreo, pero ¿qué es?
Digamos que tiene un sitio web que ha sido descubierto por los motores de búsqueda. Regularmente vienen a ver si ha realizado alguna actualización en su sitio web y si ha creado nuevas páginas.
Cada sitio web tiene su propio presupuesto de rastreo que depende de varios factores, como la cantidad de páginas que tiene su sitio web y la cordura del mismo (si tiene muchos errores, por ejemplo). Puede tener fácilmente una idea rápida de su presupuesto de rastreo iniciando sesión en la consola de búsqueda.
Su presupuesto de rastreo fijará la cantidad de páginas que rastrea un robot en su sitio web cada vez que lo visita. Está vinculado proporcionalmente a la cantidad de páginas que tiene en su sitio web y ya se ha rastreado. Algunas páginas se rastrean con más frecuencia que otras, especialmente si se actualizan regularmente o si están vinculadas desde páginas importantes.
Por ejemplo, su casa es su punto de entrada principal, que se rastreará muy a menudo. Si tiene un blog o una página de categoría, se rastrearán a menudo si está vinculado a la navegación principal. Un blog también se rastreará con frecuencia, ya que se actualiza periódicamente. Una publicación de blog puede rastrearse con frecuencia cuando se publicó por primera vez, pero después de unos meses probablemente no se actualice.
Cuanto más a menudo se rastrea una página, más importante considera un robot que es importante en comparación con otros. Aquí es cuando necesita comenzar a trabajar para optimizar su presupuesto de rastreo.
Optimización de su presupuesto de rastreo
Para optimizar su presupuesto y asegurarse de que sus páginas más importantes reciban la atención que merecen, puede analizar los registros de su servidor y ver cómo se rastrea su sitio web:
- ¿Con qué frecuencia se rastrean sus páginas principales?
- ¿Puedes ver páginas menos importantes que se rastrean más que otras más importantes?
- ¿Los robots suelen recibir un error 4xx o 5xx al rastrear su sitio web?
- ¿Los robots encuentran trampas para arañas? (Matthew Henry escribió un gran artículo sobre ellos)
Al analizar sus registros, verá qué páginas que considera menos importantes se rastrean mucho. Luego, debe profundizar en su estructura de enlaces internos. Si se está rastreando, debe tener muchos enlaces que apunten a él.
También puede trabajar para corregir todos estos errores (4xx y 5xx) con OnCrawl. Mejorará la capacidad de rastreo, así como la experiencia del usuario, es un caso de ganar-ganar.
¿Arrastrarse VS raspar?
Arrastrarse y raspar son dos cosas diferentes que se utilizan para diferentes propósitos. Rastrear un sitio web es aterrizar en una página y seguir los enlaces que encuentra cuando escanea el contenido. Luego, un rastreador se moverá a otra página y así sucesivamente.
Raspar, por otro lado, es escanear una página y recopilar datos específicos de la página: etiqueta de título, meta descripción, etiqueta h1 o un área específica de su sitio web, como una lista de precios. Los raspadores generalmente actúan como "humanos", ignorarán cualquier regla del archivo robots.txt, archivarán en formularios y usarán un agente de usuario del navegador para no ser detectados.
Los rastreadores de motores de búsqueda generalmente actúan como scrappers y necesitan recopilar datos para procesarlos para su algoritmo de clasificación. No buscan datos específicos en comparación con scrapper, solo usan todos los datos disponibles en la página y aún más (el tiempo de carga es algo que no se puede obtener de una página). Los rastreadores de los motores de búsqueda siempre se identificarán como rastreadores para que el propietario de un sitio web pueda saber cuándo fue la última vez que visitó su sitio web. Esto puede ser muy útil cuando realiza un seguimiento de la actividad real del usuario.
Entonces, ahora que sabe un poco más sobre el rastreo, cómo funciona y por qué es importante, el siguiente paso es comenzar a analizar los registros del servidor. Esto le proporcionará información detallada sobre cómo interactúan los robots con su sitio web, qué páginas visitan con frecuencia y cuántos errores encuentran al visitar su sitio web.
Para obtener más información técnica e histórica sobre el rastreador web, puede leer "Una breve historia de los rastreadores web"