
Cómo pronosticar ingresos de tráfico orgánico sin marca en función de la posición de la URL con Python
Publicado: 2022-05-24¿Qué es la previsión SEO?
La previsión de SEO, o estimación de tráfico orgánico, es el proceso de utilizar los datos de su propio sitio o datos de terceros para estimar el tráfico orgánico futuro de su sitio, los ingresos de SEO y el ROI de SEO. Esta estimación se puede calcular utilizando muchos métodos diferentes basados en nuestros datos.
En este tutorial, queremos predecir nuestros ingresos orgánicos sin marca y el tráfico orgánico sin marca en función de las posiciones de nuestras URL y sus ingresos actuales. Esto puede ayudarnos como SEO a obtener más aceptación de otras partes interesadas: desde un mayor presupuesto mensual, trimestral o anual hasta más horas de trabajo del producto y del equipo de desarrollo.
Tenga en cuenta que este tutorial no solo se aplica al tráfico orgánico sin marca; al hacer algunos cambios y conocer Python, puede usarlo para estimar el tráfico de sus páginas de destino.
Como resultado, podemos producir una hoja de cálculo de Google como la imagen de abajo.
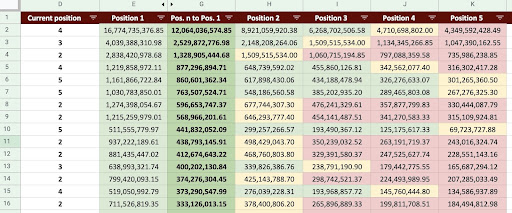
Imagen de Hojas de cálculo de Google
Pronóstico de tráfico SEO sin marca
La primera pregunta que puede hacerse después de leer la introducción es: "¿Por qué calcular el tráfico orgánico sin marca?".
Consideremos una empresa como Amazon. Cuando desee comprar un libro o una máscara, simplemente busque "comprar máscara amazon".
Las marcas a menudo son lo más importante y cuando desea comprar algo, su preferencia es comprar las cosas que necesita de estas compañías. En cada industria, hay empresas de marca que afectan el comportamiento de los usuarios en las búsquedas de Google.
Si revisáramos los datos de Google Search Console (GSC) de Amazon, probablemente encontraríamos que recibe mucho tráfico de consultas de marca y, la mayoría de las veces, el primer resultado de las consultas de marca es el sitio de esa marca.
Como SEO, como yo, probablemente hayas escuchado muchas veces eso: "¡Solo nuestra marca ayuda a nuestro SEO!" ¿Cómo podemos decir: "No, ese no es el caso" y mostrar el tráfico y los ingresos de las consultas que no son de marca?
Es aún más complicado probar esto porque sabemos que los algoritmos de Google son muy complejos y es difícil separar claramente las búsquedas de marca de las que no lo son. Pero esto es lo que hace que lo que hacemos como SEO sea aún más importante.
En este tutorial, le mostraré cómo distinguir entre los dos, con marca y sin marca, y le mostraré cuán poderoso puede ser el SEO.
Incluso si su empresa no tiene una marca, aún puede obtener mucho de este artículo: puede aprender a estimar los datos orgánicos de su sitio.
SEO ROI basado en estimación de tráfico
No importa dónde se encuentre o qué haga, existe una limitación de recursos; ya sea un presupuesto o simplemente la cantidad de horas en la jornada laboral. Saber cuál es la mejor manera de asignar sus recursos juega un papel importante en el retorno de la inversión (ROI) general y de SEO.
Un CMO, un vicepresidente de marketing o un especialista en marketing de rendimiento tienen diferentes KPI y requieren diferentes recursos para alcanzar sus objetivos. La mejor manera de asegurarse de obtener lo que necesita es probar su necesidad demostrando los beneficios que traerá a la empresa. El ROI de SEO no es diferente. Cuando llega la época del año en que se asigna el presupuesto y su equipo quiere solicitar un presupuesto mayor, estimar su ROI de SEO puede darle la ventaja en la negociación. Una vez que haya calculado la estimación del tráfico sin marca, podrá evaluar mejor el presupuesto necesario para lograr los resultados deseados.
El efecto de la predicción SEO en la estrategia SEO
Como sabemos, cada 3 o 6 meses revisamos nuestra estrategia de SEO y la ajustamos para obtener los mejores resultados posibles. Pero, ¿qué sucede cuando no sabe dónde está la mayor ganancia para su empresa? Puede tomar decisiones, pero no serán tan efectivas como las decisiones tomadas cuando tiene una visión más completa del tráfico del sitio.
La estimación de ingresos de tráfico orgánico sin marca se puede combinar con sus páginas de destino y la segmentación de consultas para proporcionar una imagen general que lo ayudará a desarrollar mejores estrategias como gerente o estratega de SEO.
Las diferentes formas de pronosticar el tráfico orgánico
Hay muchos métodos diferentes y scripts públicos en la comunidad SEO para predecir el tráfico orgánico futuro.
Algunos de estos métodos incluyen:
- Pronóstico de tráfico orgánico en todo el sitio
- Pronóstico de tráfico orgánico en las páginas específicas (blog, productos, categorías, etc.) o una sola página
- Pronóstico de tráfico orgánico en las consultas específicas (las consultas contienen "comprar", "cómo hacerlo", etc.) o una consulta
- Pronóstico de tráfico orgánico para períodos específicos (especialmente para eventos estacionales)
Mi método es para páginas específicas y el plazo es de un mes.
[Estudio de caso] Impulsar el crecimiento en nuevos mercados con SEO en la página
 Lea el estudio de caso
Lea el estudio de casoCómo calcular los ingresos por tráfico orgánico
La forma precisa se basa en sus datos de Google Analytics (GA). Si su sitio es nuevo, tendrá que usar herramientas de terceros. Prefiero evitar el uso de tales herramientas cuando tienes tus propios datos.
Recuerde, deberá comparar los datos de terceros que está utilizando con algunos de los datos de su página real para encontrar posibles errores en sus datos.
Cómo calcular los ingresos por tráfico de SEO sin marca con Python
Hasta ahora, hemos cubierto una gran cantidad de conceptos teóricos con los que deberíamos estar familiarizados para comprender mejor los diferentes aspectos de nuestra predicción de ingresos y tráfico orgánico. Ahora, nos sumergiremos en la parte práctica de este artículo.
Primero, comenzaremos calculando nuestra curva CTR. En mi artículo sobre la curva CTR en Oncrawl, explico dos métodos diferentes y también otros métodos que puedes usar haciendo algunos cambios en mi código. Le recomiendo que primero lea el artículo sobre la curva de clics; le da información sobre este artículo.
En este artículo, modifico algunas partes de mi código para obtener los resultados específicos que queremos en la estimación del tráfico. Luego, obtendremos nuestros datos de GA y usaremos la dimensión de ingresos de GA para estimar nuestros ingresos.
Pronosticar los ingresos de tráfico orgánico sin marca con Python: Primeros pasos
Puede ejecutar este código usted mismo, sin saber nada de Python. Sin embargo, prefiero que sepa un poco sobre la sintaxis de Python y conocimientos básicos sobre las bibliotecas de Python que usaré en este código de pronóstico. Esto lo ayudará a comprender mejor mi código y personalizarlo de una manera que sea útil para usted.
Para ejecutar este código, usaré Visual Studio Code con la extensión Python de Microsoft, que incluye la extensión "Jupyter". Pero puede usar el propio cuaderno Jupyter.
Para todo el proceso, necesitamos usar estas bibliotecas de Python:
- entumecido
- pandas
- trama
Además, importaremos algunas bibliotecas estándar de Python:
- JSON
- pprint
# Importando las bibliotecas que necesitamos para nuestro proceso importar json desde pprint importar pprint importar numpy como np importar pandas como pd importar plotly.express como px
Paso 1: Cálculo de la curva CTR relativa (Curva de clic relativa)
En el primer paso, queremos calcular nuestra curva CTR relativa. Pero, ¿qué es la curva CTR relativa?
¿Qué es la curva CTR relativa?
Comencemos primero hablando de la 'curva CTR absoluta'. Cuando calculamos la curva de CTR absoluto, decimos que el CTR mediano (o CTR medio) de la primera posición es 36% y la segunda posición es 20%, y así sucesivamente.
En la curva de CTR relativo, instante de porcentaje, dividimos la mediana de cada posición por el CTR de la primera posición. Por ejemplo, la curva CTR relativa de la primera posición sería 0,36/0,36 = 1, la segunda sería 0,20/0,36 = 0,55, y así sucesivamente.
Tal vez te estés preguntando por qué es útil calcular esto. Piense en una página clasificada en la posición uno, que tiene un CTR del 44%. Si esta página va a la posición dos, la curva CTR no disminuye al 20 %, es más probable que su CTR disminuya al 44 % * 0,55 = 24,2 %.
1. Obtener datos de tráfico orgánico de marca y sin marca de GSC
Para nuestro proceso de cálculo, necesitamos obtener nuestros datos de GSC. La primera vez, todos los datos se basarán en consultas de marca y la próxima vez, todos los datos se basarán en consultas sin marca.
Para obtener estos datos, puede utilizar diferentes métodos: desde scripts de Python o desde el complemento de Google Sheets "Search Analytics for Sheets". Usaré el explorador de API de GSC.
El resultado de estos datos son dos archivos JSON que muestran el rendimiento de cada página. Un archivo JSON que muestra el rendimiento de las páginas de destino en función de las consultas de marca y el otro muestra el rendimiento de las páginas de destino en función de las consultas sin marca.
Para obtener datos del explorador de API de GSC, siga estos pasos:
- Vaya a https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Maximice el explorador de API que se encuentra en la esquina superior derecha de la página.
- En el campo "
siteUrl", inserte su nombre de dominio. Por ejemplo, "https://www.example.com" o "http://your-domain.com". - En el cuerpo de la solicitud, primero debemos definir los parámetros "
startDate" y "endDate". Mi preferencia son los últimos 30 días. - Luego agregamos "
dimensions" y seleccionamos "page" para esta lista. - Ahora agregamos "
dimensionFilterGroups" para filtrar nuestras consultas. Una vez para las de marca y una segunda para las consultas sin marca. - Al final, establecemos nuestro "
rowLimit" en 25,000. Si las páginas de su sitio que reciben tráfico orgánico cada mes son más de 25K, debe modificar el cuerpo de su solicitud. - Después de realizar cada solicitud, guarde la respuesta JSON. Para el rendimiento de marca, guarde el archivo JSON como "
branded_data.json" y para el rendimiento sin marca, guarde el archivo JSON como "non_branded_data.json".
Una vez que comprendamos los parámetros en el cuerpo de nuestra solicitud, lo único que debe hacer es copiar y pegar debajo de los cuerpos de la solicitud. Considere reemplazar sus nombres de marca con " brand variation names ".
Debe separar las marcas con una canalización o “ | ”. Por ejemplo, “ amazon|amazon.com|amazn ”.
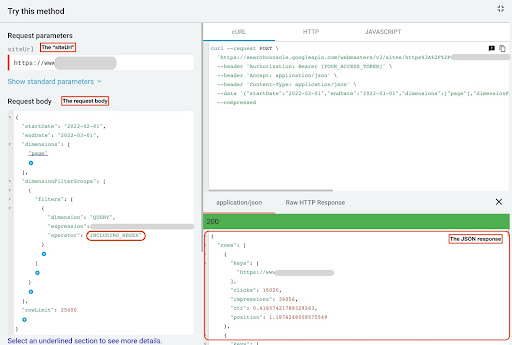
Explorador de API de GSC
Cuerpo de solicitud de marca:
{
"fechaInicio": "2022-02-01",
"fechafinalización": "2022-03-01",
"dimensiones": [
"página"
],
"grupos de filtros de dimensiones": [
{
"filtros": [
{
"dimensión": "CONSULTA",
"expresión": "nombres de variación de marca",
"operador": "INCLUYENDO_REGEX"
}
]
}
],
"límite de fila": 25000
}
Cuerpo de solicitud sin marca:
{
"fechaInicio": "2022-02-01",
"fechafinalización": "2022-03-01",
"dimensiones": [
"página"
],
"grupos de filtros de dimensiones": [
{
"filtros": [
{
"dimensión": "CONSULTA",
"expresión": "nombres de variación de marca",
"operador": "EXCLUDING_REGEX"
}
]
}
],
"límite de fila": 25000
}
2. Importar los datos a nuestro cuaderno Jupyter y extraer los directorios del sitio
Ahora, necesitamos cargar nuestros datos en nuestro cuaderno Jupyter para poder modificarlo y extraer lo que queramos de él. Retomemos donde lo dejamos arriba.
Para cargar datos de marca, debe ejecutar este bloque de código:
# Creación de un marco de datos para el rendimiento de las URL del sitio web en la marca y consultas de marca
con open("./branded_data.json") como json_file:
branded_data = json.loads(json_file.read())["filas"]
branded_df = pd.DataFrame(branded_data)
# Cambiar el nombre de la columna 'claves' a la columna 'página de destino' y convertir la lista de 'página de destino' en una URL
branded_df.rename(columns={"keys": "landing page"}, inplace=True)
branded_df["página de destino"] = branded_df["página de destino"].apply(lambda x: x[0])
Para el rendimiento sin marca de las páginas de destino, deberá ejecutar este bloque de código:
# Creación de un marco de datos para el rendimiento de las URL del sitio web en las consultas sin marca
con open("./non_branded_data.json") como json_file:
datos_sin_marca = json.loads(json_file.read())["filas"]
non_branded_df = pd.DataFrame(non_branded_data)
# Cambiar el nombre de la columna 'claves' a la columna 'página de destino' y convertir la lista de 'página de destino' en una URL
non_branded_df.rename(columns={"keys": "landing page"}, inplace=True)
non_branded_df["página de destino"] = non_branded_df["página de destino"].apply(lambda x: x[0])
Cargamos nuestros datos, luego necesitamos definir el nombre de nuestro sitio para extraer sus directorios.
# Definición del nombre de su sitio entre comillas. Por ejemplo, 'https://www.ejemplo.com/' o 'http://midominio.com/' SITE_NAME = "https://www.su_dominio.com/"
Solo necesitamos extraer los directorios del rendimiento sin marca.
# Obtener el directorio de cada página de destino (URL)
non_branded_df["directorio"] = non_branded_df["página de destino"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Luego imprimimos los directorios para seleccionar cuáles son importantes para este proceso. Es posible que desee seleccionar todos los directorios para obtener una mejor perspectiva de su sitio.

# Para obtener todos los directorios en la salida, necesitamos manipular las opciones de Pandas
pd.set_option("display.max_rows", Ninguno)
# Directorios de sitios web
non_branded_df["directorio"].value_counts()
Aquí, puede insertar los directorios que sean importantes para usted.
""" Elija qué directorios son importantes para obtener su curva CTR.
Inserte los directorios en la variable 'important_directories'.
Por ejemplo, 'producto, etiqueta, categoría de producto, revista'. Separe los valores del directorio con comas.
"""
IMPORTANTE_DIRECTORIES = "sus_directorios_importantes"
DIRECTORIOS_IMPORTANTES = DIRECTORIOS_IMPORTANTES.split(",")
3. Etiquetar las páginas según su posición y calcular la curva CTR relativa
Ahora necesitamos etiquetar nuestras páginas de destino según su posición. Hacemos esto porque necesitamos calcular la curva CTR relativa para cada directorio en función de la posición de su página de destino.
# Etiquetado de posiciones sin marca
para i en el rango (1, 11):
non_branded_df.loc[
(df_sin_marca["posición"] >= i) & (df_sin_marca["posición"] < i + 1),
"etiqueta de posición",
] = yo
Luego, agrupamos las páginas de destino según su directorio.
# Agrupación de páginas de destino en función de su valor de 'directorio' non_brand_grouped_df = non_branded_df.groupby(["directorio"])
Definamos la función para calcular la curva CTR relativa.
def each_dir_relative_ctr_curve(dir_df, clave):
"""La función calcula cada curva CTR relativa de DIRECTORIOS_IMPORTANTES.
"""
# Agrupando "non_brand_grouped_df" según su valor de 'etiqueta de posición'
dir_grouped_df = dir_df.groupby(["etiqueta de posición"])
# Una lista para guardar el CTR medio de cada posición
mediana_ctr_lista = []
# Almacenar cada directorio como una clave, y su valor es "median_ctr_list"
directorios_median_ctr = {}
# Bucle sobre cada grupo "dir_grouped_df"
para i en el rango (1, 11):
# Un intento, excepto para manejar aquellas situaciones en las que un directorio, por ejemplo, no tiene ningún dato para la posición 4
probar:
tmp_df = dir_grouped_df.get_group(i)
lista_ctr_mediana.append(np.mediana(tmp_df["ctr"]))
excepto:
mediana_ctr_lista.append(0)
# Cálculo de la curva CTR relativa
directorios_median_ctr[clave] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
volver directorios_median_ctr
Después de definir la función, la ejecutamos.
# Recorriendo directorios y ejecutando la función 'each_dir_relative_ctr_curve'
directorios_median_ctr_dict = dict()
para clave, artículo en non_brand_grouped_df:
si teclea DIRECTORIOS_IMPORTANTES:
directorios_median_ctr_dict.update(each_dir_relative_ctr_curve(elemento, clave))
pprint(directorios_median_ctr_dict)
Ahora, cargaremos el rendimiento de nuestras páginas de destino, con y sin marca, y calcularemos la curva de CTR relativa para nuestros datos sin marca. ¿Por qué hacemos esto solo para datos que no son de marca? Porque queremos predecir el tráfico y los ingresos orgánicos sin marca.
Paso 2: Predicción de los ingresos de tráfico orgánico sin marca
En este segundo paso, veremos cómo recuperar nuestros datos de ingresos y predecir nuestros ingresos.
1. Fusión de datos orgánicos de marca y sin marca
Ahora, fusionaremos nuestros datos de marca y sin marca. Esto nos ayudará a calcular el porcentaje de tráfico orgánico sin marca en cada página de destino en comparación con todo el tráfico.
# 'main_df' es una combinación de marcos de datos de 'datos de todo el sitio' y 'datos sin marca'.
# Con este DataFrame, puede averiguar dónde se encuentran la mayoría de nuestros clics e impresiones.
# provienen de consultas que no tienen marca.
main_df = non_branded_df.merge(
branded_df, on="página de destino", sufijos=("_non_brand", "_branded")
)
Luego modificamos las columnas para eliminar las inútiles.
# Modificando las columnas 'main_df' a las que necesitamos
principal_df = principal_df[
[
"página de destino",
"clics_sin_marca",
"ctr_sin_marca",
"directorio",
"etiqueta de posición",
"clicks_branded",
]
]
Ahora, calculemos el porcentaje de clics sin marca en el total de clics de una página de destino.
# Cálculo del porcentaje de clics de consultas sin marca en función de las páginas de destino para todos los clics de la página de destino
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clics_sin_marca"] / (x["clics_sin_marca"] + x["clics_con_marca"]),
eje=1,
)
[Ebook] Automatización de SEO con Oncrawl
 Leer el libro electrónico
Leer el libro electrónico2. Cargar los ingresos por tráfico orgánico
Al igual que recuperar los datos de GSC, tenemos varias formas de obtener los datos de GA: podríamos usar el "complemento Google Analytics Sheets" o la API de GA. En este tutorial, prefiero usar Google Data Studio (GDS) por su simplicidad.
Para obtener los datos de GA de GDS, siga estos pasos:
- En GDS, cree un nuevo informe o explorador y una tabla.
- Para la dimensión agregar “página de destino” y para la métrica, debemos agregar “Ingresos”.
- Luego, deberá crear un segmento personalizado en GA según la fuente y el medio. Filtre el tráfico “Google/orgánico”. Después de la creación del segmento, agréguelo a la sección de segmentos en GDS.
- En el paso final, exporte la tabla y guárdela como "
landing_pages_revenue.csv".
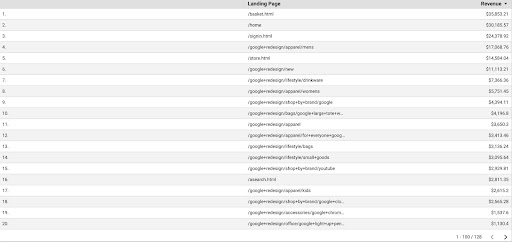
Exportación csv de ingresos de páginas de destino
Carguemos nuestros datos.
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Ahora, debemos agregar el nombre de nuestro sitio a las URL de las páginas de destino de GA.
Cuando exportamos nuestros datos de GA, las páginas de destino están en forma relativa, pero nuestros datos de GSC están en forma absoluta.
No olvide verificar los datos de sus páginas de destino de GA. En los conjuntos de datos con los que trabajé, descubrí que los datos de GA necesitan una pequeña limpieza cada vez.
# Concatenar las URL de las páginas de destino de GA con SITE_NAME.
# Además, renombrando las columnas
organic_revenue_df.loc[:, "Página de destino"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Landing Page": "landing page", "Revenue": "revenue"}, inplace=True)
Ahora, fusionemos nuestros datos de GSC con los datos de GA.
# En este paso, combino 'main_df' con 'dk_organic_revenue_df' DataFrame que contiene el porcentaje de datos de consultas sin marca main_df = main_df.merge(organic_revenue_df, on="landing page", how="left")
Al final de esta sección, hacemos una pequeña limpieza en nuestras columnas de DataFrame.
# Limpiando un poco el DataFrame 'main_df'
principal_df = principal_df[
[
"página de destino",
"clics_sin_marca",
"ctr_sin_marca",
"directorio",
"etiqueta de posición",
"clicks_non_brand_percentage",
"ingresos",
]
]
3. Cálculo de los ingresos sin marca
En esta sección, procesaremos datos para extraer la información que estamos buscando.
Pero antes que nada, filtremos nuestras páginas de destino en función de " IMPORTANT_DIRECTORIES ":
# Eliminando otras páginas de destino de directorios, no incluidas en "IMPORTANT_DIRECTORIES"
principal_df = (
main_df[main_df["directorio"].isin(IMPORTANT_DIRECTORIES)]
.dropna(subconjunto=["ingresos"])
.reset_index(soltar=Verdadero)
)
Ahora, calculemos el tráfico de ingresos orgánicos sin marca.
Definí una métrica que no podemos calcular fácilmente y es más la intuición que otra cosa lo que nos lleva a asignarle un número.
La métrica “ brand_influence ” muestra la fuerza de su marca. Si cree que las búsquedas sin marca generan menos ventas para su negocio, reduzca este número; algo como 0.8 por ejemplo.
# Si su marca es tan fuerte que consultar sin su marca puede vender tanto como consultar con su marca, entonces 1 es bueno para usted.
# Piense en buscar un libro sin una marca incluida en su consulta. Cuando ves Amazon, ¿compras en otros mercados o tiendas?
marca_influencia = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["revenue"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
Tracemos un gráfico circular para obtener una idea de los ingresos sin marca en función de los directorios importantes.
# En esta celda, quiero obtener todos los ingresos de las páginas de destino que no son de marca en función de su directorio
non_branded_directory_dist_revenue_df = pd.pivot_table(
principal_df,
índice="directorio",
valores=["ingresos_sin_marca"],
aggfunc={"non_brand_revenue": "suma"},
)
pastel_fig = px.pastel(
directorio_sin_marca_dist_revenue_df,
valores="ingresos_sin_marca",
names=non_branded_directory_dist_revenue_df.index,
title="Ingresos sin marca basados en directorios de sitios web",
)
pie_fig.update_traces(textposition="dentro", textinfo="porcentaje+etiqueta")
pie_fig.mostrar()
Este gráfico muestra la distribución de consultas sin marca en sus IMPORTANT_DIRECTORIES .
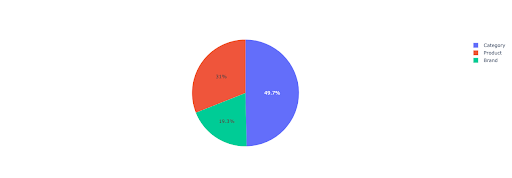
Distribución de consultas sin marca
Según los datos de mi curva CTR, veo que no puedo confiar en el CTR para posiciones superiores a 5. Debido a esto, filtro mis datos según la posición.
Puede modificar el siguiente bloque de código en función de sus datos.
# Debido a la precisión de CTR en nuestra curva de CTR, creo que podemos omitir los aterrizajes con una posición superior a 5. Debido a esto, filtré otras páginas de aterrizaje main_df = main_df[main_df["etiqueta de posición"] < 6].reset_index(drop=True)
4. Cálculo de “Ingresos por clic” (RPC)
Aquí, creé una métrica personalizada y la llamé "Ingresos por clic" o RPC. Esto nos muestra los ingresos generados por cada clic sin marca.
Puede utilizar esta métrica de diferentes maneras. Encontré una página con RPC alto, pero pocos clics. Cuando revisé la página, descubrí que estaba indexada hace menos de una semana y podemos usar diferentes métodos para optimizar la página.
# Cálculo de los ingresos generados con cada clic (RPC: Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x: x["ingresos_sin_marca"] / x["clics_sin_marca"], eje=1
)
5. ¡Predicción de los ingresos!
Estamos llegando al final, esperamos hasta ahora para predecir nuestros ingresos orgánicos sin marca.
Ejecutemos los últimos bloques de código.
# La función principal para calcular los ingresos en función de diferentes posiciones
para índice, valores_de_fila en main_df.iterrows():
# Cambiar entre directorios Lista CTR
ctr_curve = directorios_median_ctr_dict[row_values["directorio"]]
# Recorra la posición 1 a 5 y calcule los ingresos según el aumento o la disminución de CTR
para i en el rango (1, 6):
if i == valores_fila["etiqueta de posición"]:
main_df.loc[índice, i] = valores_de_fila["ingresos_sin_marca"]
más:
# main_df.loc[índice, i + 1] ==
main_df.loc[índice, i] = (
valores_de_fila["ingresos_sin_marca"]
* (ctr_curva[i - 1])
/ ctr_curve[int(row_values["etiqueta de posición"] - 1)]
)
# Cálculo de la métrica "N a 1". Esto muestra el aumento en los ingresos cuando su rango pasa de "N" a "1"
main_df.loc[índice, "N a 1"] = main_df.loc[índice, 1] - main_df.loc[índice, valores_fila["etiqueta de posición"]]
Mirando el resultado final, tenemos nuevas columnas. Los nombres de estas columnas son “1”, “2”, “3”, “4”, “5”.
¿Qué significan estos nombres? Por ejemplo, tenemos una página en la posición 3 y queremos predecir sus ingresos si mejora su posición, o queremos saber cuánto perderemos si bajamos de rango.
Las columnas "1" y "2" muestran los ingresos de la página cuando la posición promedio de esta página mejora y las columnas "4" y "5" muestran los ingresos de esta página cuando bajamos en el ranking.
La columna "3" en este ejemplo muestra los ingresos actuales de la página.
Además, creé una métrica llamada "N a 1". Esto le muestra si la posición promedio de esta página se mueve de "3" (o N) a "1" y cuánto puede afectar el movimiento a los ingresos.
Terminando
Cubrí mucho en este artículo y ahora es tu turno de ensuciarte las manos y predecir tus ingresos de tráfico orgánico sin marca.
Esta es la forma más sencilla en que podemos usar esta predicción. Podríamos hacer este algoritmo más complejo y combinarlo con algunos modelos de ML, pero eso complicaría el artículo.
Prefiero guardar estos datos en un CSV y subirlos a una hoja de cálculo de Google. O, si planeo compartirlo con otros miembros de mi equipo o de la organización, lo abriré con Excel y formatearé las columnas usando colores para que sea más fácil de leer.
En función de estos datos, puede predecir el ROI de su tráfico orgánico sin marca y utilizarlo en su proceso de negociación.