
Actualizaciones principales de Google: efectos, problemas y soluciones para sitios YMYL
Publicado: 2019-12-04En este estudio de caso, analizaré Hangikredi.com, que es uno de los mayores activos financieros y digitales de Turquía. Veremos subtítulos técnicos de SEO y algunos gráficos.
Este estudio de caso se presenta en dos artículos. Este artículo trata sobre la actualización principal de Google del 12 de marzo, que tuvo un fuerte efecto negativo en el sitio web, y lo que hicimos para contrarrestarlo. Veremos 13 problemas técnicos y soluciones, así como cuestiones holísticas.
Lea la segunda entrega para ver cómo apliqué el aprendizaje de esta actualización para convertirme en un ganador de cada actualización principal de Google.
Problemas y soluciones: corrección de los efectos de la actualización de Google Core del 12 de marzo
Hasta la actualización del algoritmo central del 12 de marzo, todo iba viento en popa para el sitio web, según los datos analíticos. En un día, después de que se publicaron las noticias sobre la actualización del algoritmo central, hubo una gran caída en las clasificaciones y una gran frustración en la oficina. Yo personalmente no vi ese día porque recién llegué cuando me contrataron para iniciar un nuevo Proyecto y Proceso SEO 14 días después.
[Estudio de caso] Mejora de clasificaciones, visitas orgánicas y ventas con análisis de archivos de registro
 Lea el estudio de caso
Lea el estudio de casoEl informe de daños para el sitio web de la empresa después de la actualización del algoritmo central del 12 de marzo se encuentra a continuación:
- 36% Pérdida de sesión orgánica
- 65% Haga clic en Soltar
- 30% de pérdida de CTR
- 33 % de pérdida orgánica de usuarios
- 100 000 impresiones perdidas por día.
- 9,72 % de pérdida de impresiones
- 8 000 palabras clave perdidas

Ahora, como dijimos al comienzo del artículo de estudio de caso, debemos hacer una pregunta. No podíamos preguntar "¿Cuándo ocurrirá la próxima actualización del algoritmo central?" porque ya ha pasado. Solo quedaba una pregunta.
"¿Qué criterios diferentes consideró Google entre mi competencia y yo?"
Como puede ver en el gráfico anterior y en el informe de daños, habíamos perdido nuestro tráfico principal y nuestras palabras clave.
1. Problema: enlace interno
Me di cuenta de que cuando verifiqué por primera vez el recuento de enlaces internos, el texto de anclaje y el flujo de enlaces, mi competidor estaba delante de mí.
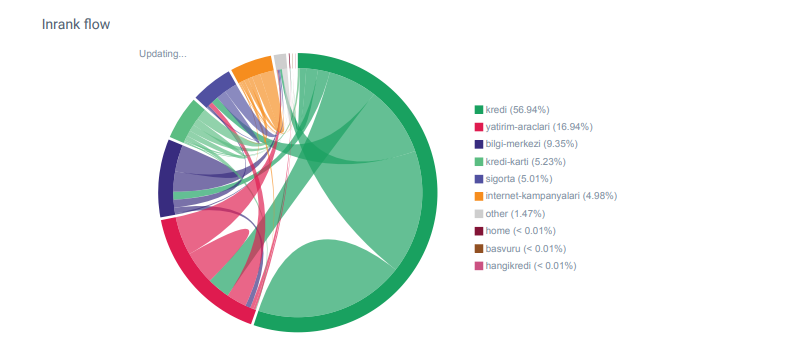
Informe Linkflow para las categorías de Hangikredi.com de OnCrawl
Mi principal competidor tiene más de 340 000 enlaces internos con miles de textos de anclaje. En estos días, nuestro sitio web solo tenía 70 000 enlaces internos sin textos de anclaje valiosos. Además, la falta de enlaces internos había afectado el presupuesto de rastreo y la productividad del sitio web. Aunque el 80% de nuestro tráfico se recopiló en solo 20 páginas de productos, el 90% de nuestro sitio consistía en páginas de guía con información útil para los usuarios. Y la mayoría de nuestras palabras clave y puntaje de relevancia para consultas financieras provienen de estas páginas. Además, había innumerables páginas huérfanas.
Debido a la falta de estructura de enlaces internos, cuando realicé Log Analysis con Kibana, noté que las páginas más rastreadas eran las que recibían menos tráfico. Además, cuando combiné esto con la red de enlaces internos, descubrí que las páginas corporativas de menor tráfico (Privacidad, Cookies, Seguridad, Páginas Acerca de nosotros) tienen la cantidad máxima de enlaces internos.
Como comentaré en la siguiente sección, esto provocó que Googlebot eliminara el factor de enlace interno de Pagerank cuando rastreó el sitio y se dio cuenta de que los enlaces internos no se construyeron según lo previsto.
2. Problema: arquitectura del sitio, PageRank interno, tráfico y eficiencia de rastreo
Según el comunicado de Google, los enlaces internos y los textos de anclaje ayudan a Googlebot a comprender la importancia y el contexto de una página web. El Pagerank interno o Inrank se calcula en función de más de un factor. Según Bill Slawski, los enlaces internos o externos no son todos iguales. El valor de un enlace para el flujo de Pagerank cambia según su posición, tipo, estilo y peso de fuente.

Si Googlebot comprende qué páginas son importantes para su sitio web, las rastreará más y las indexará más rápido. Los enlaces internos y el diseño correcto del Site-Tree son factores importantes para esto. Otros expertos también han comentado sobre esta correlación a lo largo de los años:
“La mayoría de los enlaces proporcionan un poco de contexto adicional a través de su texto de anclaje. Al menos deberían, ¿verdad?
–John Müller, Google 2017“Si tiene páginas que cree que son importantes en su sitio , no las entierre 15 enlaces en lo profundo de su sitio y no estoy hablando de la longitud del directorio, estoy hablando de lo real, tiene que hacer clic en 15 enlaces para encontrar esa página si hay una página que es importante o que tiene grandes márgenes de ganancia o convierte realmente, bueno, escale y coloque un enlace a esa página desde su página raíz, ese es el tipo de cosas donde puede tener mucho sentido”.
–Matt Cutts, Google 2011“Si una página se vincula a otra con la palabra “contacto” o la palabra “acerca de”, y la página a la que se vincula incluye una dirección, la ubicación de esa dirección podría considerarse relevante para la página que realiza el vínculo”.
12 métodos de análisis de enlaces de Google que podrían haber cambiado - Bill Slawski
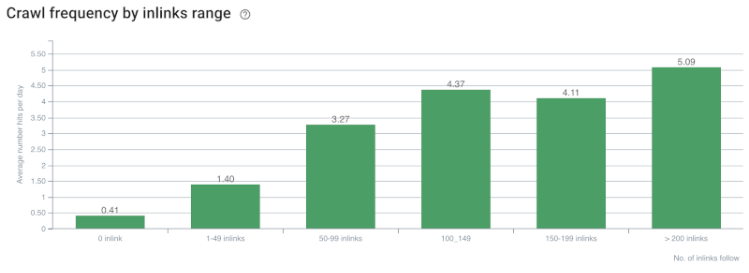
Tasa de rastreo/demanda y correlación de recuento de enlaces internos. Fuente: OnCrawl.
Hasta ahora, podemos hacer estas inferencias:
- Google se preocupa por la profundidad de los clics. Si una página web está más cerca de la página de inicio, debería ser más importante. Esto también fue confirmado por John Mueller el 1 de julio de 2018 en Google Webmaster Hangout en inglés.
- Si una página web tiene muchos enlaces internos que apuntan a ella, debería ser importante.
- Los textos de anclaje pueden dar poder contextual a una página web.
- Un enlace interno puede transmitir diferentes cantidades de Pagerank según su posición, tipo, peso de fuente o estilo.
- Un Site-Tree compatible con UX que brinda mensajes claros sobre la autoridad de la página interna a los rastreadores del motor de búsqueda es una mejor opción para la distribución de Inrank y la eficiencia del rastreo.
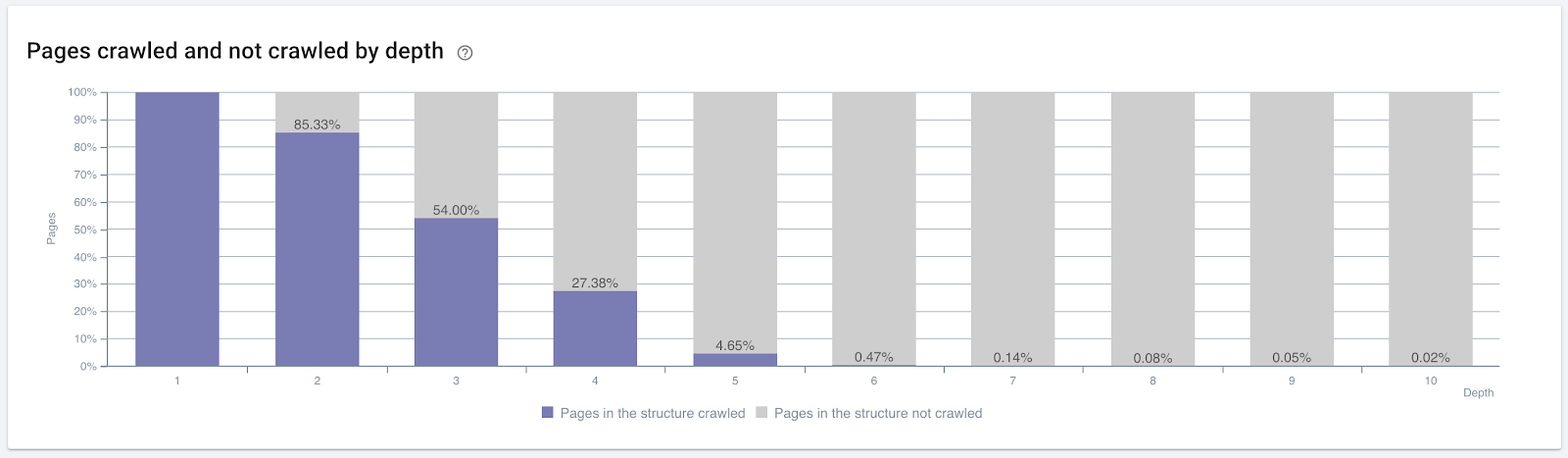
Porcentaje de páginas rastreadas por profundidad de clic. Fuente: OnCrawl.
Pero esto no es suficiente para comprender la naturaleza y los efectos de los enlaces internos en la eficiencia del rastreo.
Rastreador de SEO Oncrawl
 Aprende más
Aprende másSi la mayoría de las páginas vinculadas internamente no crean tráfico o no reciben clics, da señales que indican que su Site-Tree y la estructura de vínculos internos no se construyen de acuerdo con la intención del usuario. Y Google siempre intenta encontrar sus páginas más relevantes con la intención del usuario o entidades de búsqueda. Tenemos otra cita de Bill Slawski que aclara este tema:
“Si un recurso está vinculado por una cantidad de recursos que es desproporcionada con respecto al tráfico recibido por el uso de esos enlaces, ese recurso puede ser degradado en el proceso de clasificación”.
¿La actualización de Groundhog acaba de tener lugar en Google? —Bill Slawski“El puntaje de calidad de la selección puede ser más alto para una selección que resulte en un tiempo de permanencia prolongado (p. ej., mayor que un período de tiempo umbral) que el puntaje de calidad de la selección para una selección que resulte en un tiempo de permanencia corto”.
¿La actualización de Groundhog acaba de tener lugar en Google? —Bill Slawski
Así que tenemos dos factores más:
- Tiempo de permanencia en la página enlazada.
- Tráfico de usuarios que produce el enlace.
El número de enlaces internos y el estilo/posición no son los únicos factores. La cantidad de usuarios que siguen estos enlaces y sus métricas de comportamiento también son importantes. Además, sabemos que Google rastrea mucho más los enlaces y las páginas en los que se hace clic o se visitan que los enlaces y las páginas en los que no se hace clic ni se visitan.
“Nos hemos movido cada vez más hacia la comprensión de las secciones de un sitio para comprender la calidad de esas secciones”.
John Mueller, 2 de mayo de 2017, Hangout de webmasters de Google en inglés.
A la luz de todos estos factores, compartiré dos resultados diferentes y diferentes del Pagerank Simulator:
Estos cálculos de Pagerank se realizan asumiendo que todas las páginas son iguales, incluida la página de inicio. La diferencia real está determinada por la jerarquía de enlaces.
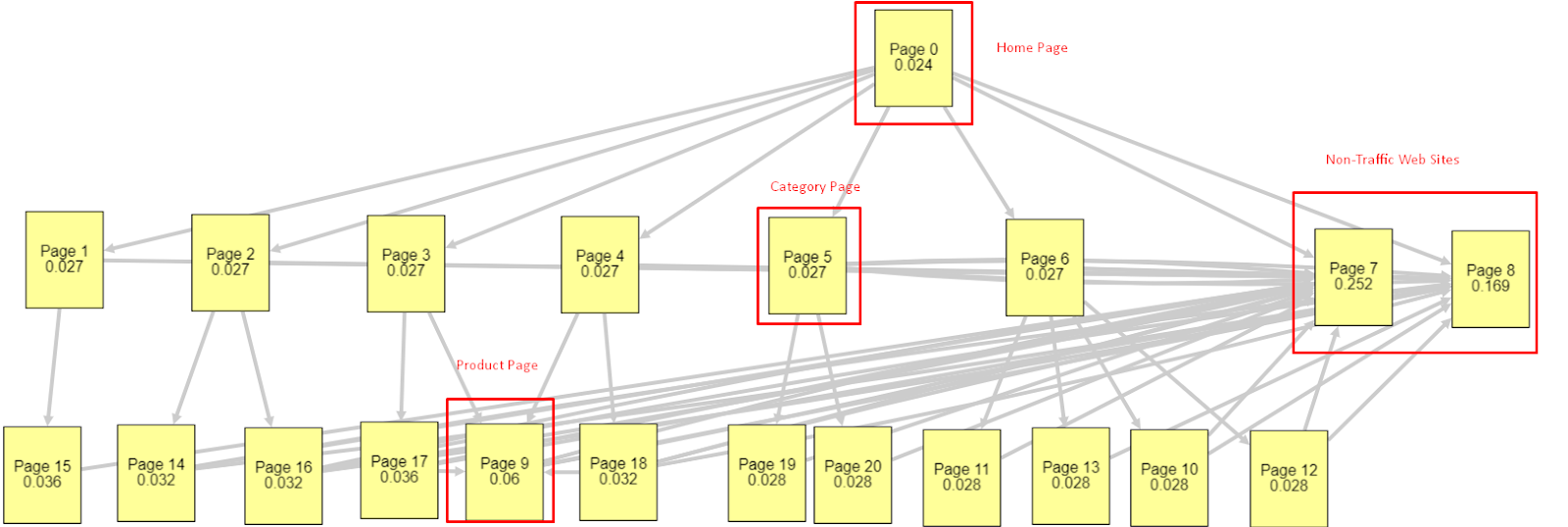
El ejemplo que se muestra aquí está más cerca de la estructura de enlaces internos antes del 12 de marzo. PR de página de inicio: 0,024, PR de página de categoría: 0,027, PR de página de producto: 0,06, PR de páginas web sin tráfico: 0,252.
Como puede notar, Googlebot no puede confiar en esta estructura de enlaces internos para calcular el PageRank interno y la importancia de las páginas internas. Las páginas sin tráfico y sin productos tienen 12 veces más autoridad que la página de inicio. Tiene más que páginas de productos.

Este ejemplo se acerca más a nuestra situación antes de la actualización del algoritmo central del 5 de junio. PR de la página de inicio: 0,033, página de categoría: 0,037, página del producto: 0,148 y PR de las páginas sin tráfico: 0,037.
Como puede notar, la estructura de enlaces internos aún no es correcta, pero al menos las páginas web sin tráfico no tienen más relaciones públicas que las páginas de categorías y las páginas de productos.
¿Cuál es una prueba más de que Google ha sacado el enlace interno y la estructura del sitio del alcance de Pagerank de acuerdo con el flujo de usuarios, las solicitudes y las intenciones? Por supuesto, el comportamiento de Googlebot y el Pagerank de Inlink y las correlaciones de clasificación:
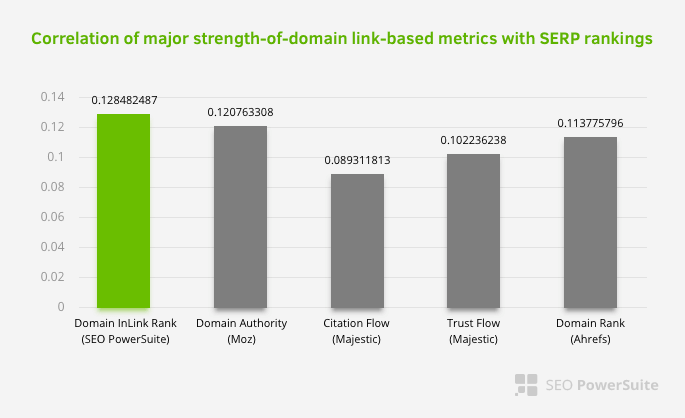
Esto no significa que la red de enlaces internos, especialmente, sea más importante que otros factores. La perspectiva SEO que se enfoca en un solo punto nunca puede tener éxito. En una comparación entre herramientas de terceros, muestra que el valor de Pagerank interno está progresando en relación con otros criterios.
De acuerdo con Inlink Rank y la investigación de correlación de rango realizada por Aleh Barysevich, las páginas con más enlaces internos tienen clasificaciones más altas que las otras páginas del sitio web. Según la encuesta realizada del 4 al 6 de marzo de 2019, se analizaron 1 000 000 de páginas según la métrica interna de Pagerank para 33 500 palabras clave. Los resultados de esta investigación realizada por SEO PowerSuite se compararon con las diferentes métricas de Moz, Majestic y Ahrefs y arrojaron resultados más precisos.
Estos son algunos de los números de enlaces internos de nuestro sitio antes de la actualización del algoritmo central del 12 de marzo:
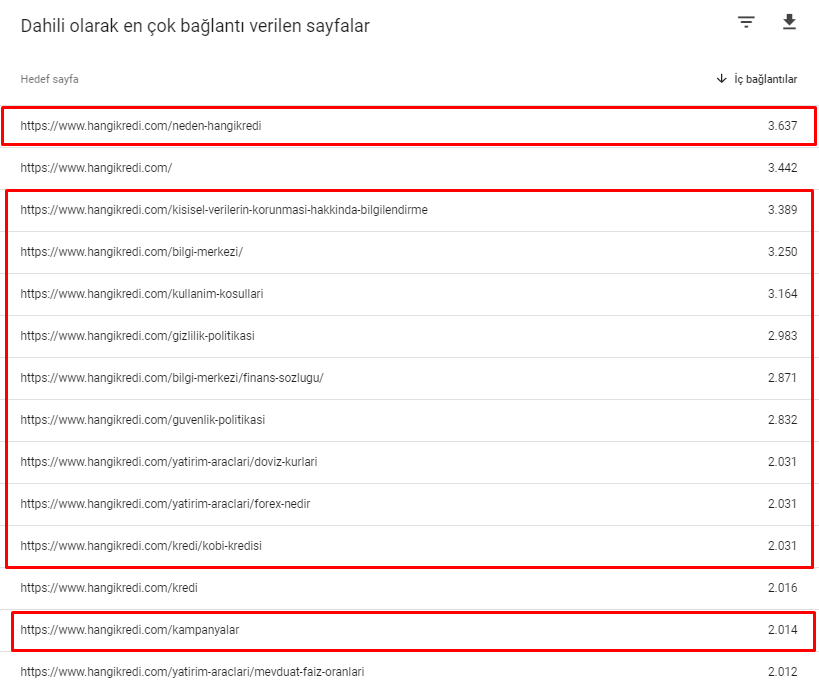
Como puede ver, nuestro esquema de conexión interna no reflejaba la intención y el flujo del usuario. Las páginas que reciben menos tráfico (páginas de productos menores) o que nunca reciben tráfico (en rojo) estaban directamente en la profundidad de 1er clic y reciben relaciones públicas desde la página de inicio. Y algunos tenían incluso más enlaces internos que la página de inicio.
A la luz de todo esto, sólo quedan los dos últimos puntos que podemos mostrar sobre este tema.
- Tasa de rastreo/demanda de las páginas más enlazadas internamente
- Modelado de enlaces y Pagerank
Entre el 1 de febrero y el 31 de marzo, estas son las páginas que Googlebot rastreó con mayor frecuencia:
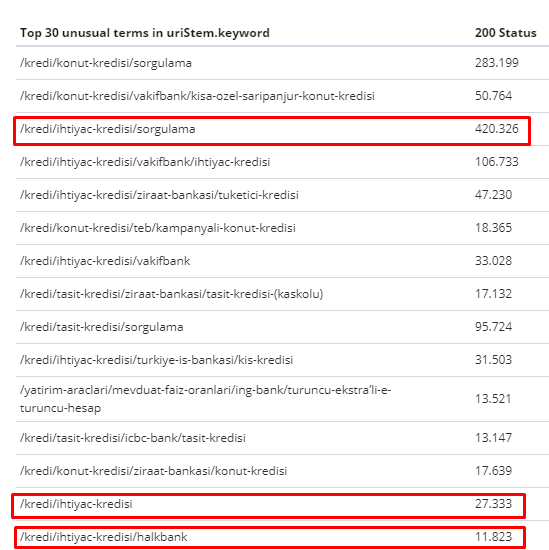
Como puede notar, las páginas rastreadas y las páginas que tienen la mayoría de los enlaces internos son completamente diferentes entre sí. Las páginas con la mayoría de los enlaces internos no eran convenientes para la intención del usuario; no tienen palabras clave orgánicas ni ningún tipo de valor SEO directo. (
Las direcciones URL en los cuadros rojos son nuestras categorías de página de productos más visitadas e importantes. Las otras páginas en esta lista son la segunda o tercera categoría más visitada e importante).
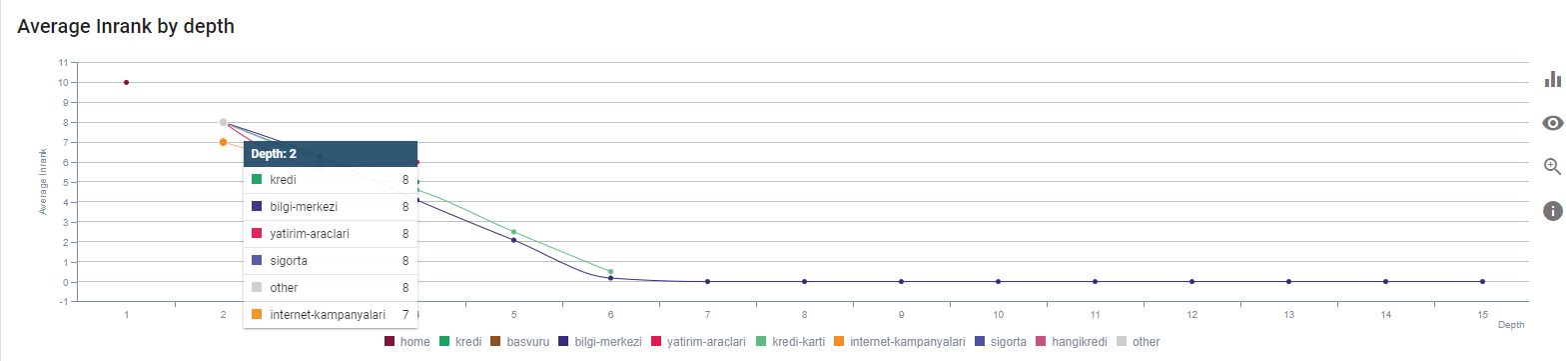
Nuestro Inrank actual por profundidad de página. Fuente: Oncrawl.
¿Qué es la escultura de enlaces y qué hacer con los enlaces no seguidos internamente?
Al contrario de lo que cree la mayoría de los SEO, los enlaces marcados con una etiqueta "nofollow" aún pasan el valor de Pagerank interno. Para mí, después de todos estos años, nadie ha narrado mejor este elemento SEO que Matt Cutts en su artículo Pagerank Sculpting del 15 de junio de 2009.
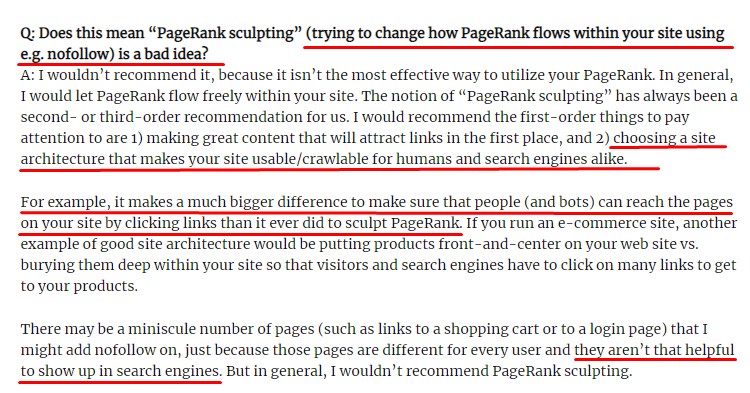
Una parte útil para Link Sculpting, que muestra el propósito real de Pagerank Sculpting.
"Recomendaría no usar nofollow para esculpir PageRank dentro de un sitio web porque probablemente no hace lo que crees que hace".
–John Müller, Google 2017
Si tiene páginas web sin valor en términos de Google y usuarios, no debe etiquetarlas con "nofollow". No detendrá el flujo de Pagerank. Debe rechazarlos del archivo robots.txt. De esta forma, Googlebot no los rastreará pero tampoco les pasará el Pagerank interno. Pero debe usar esto solo para páginas realmente sin valor, como dijo Matt Cutts hace diez años. Las páginas que realizan redireccionamientos automáticos para marketing de afiliación o páginas que en su mayoría no tienen contenido son algunos ejemplos convenientes aquí.
Solución: mejor y más natural estructura de enlace interno
Nuestro competidor tenía una desventaja. Su sitio web tenía más texto de anclaje, más enlaces internos, pero su estructura no era natural ni útil. Se usó el mismo texto de anclaje con la misma oración en cada página de su sitio. El párrafo de entrada de cada página se cubrió con este contenido repetitivo. Cada usuario y motor de búsqueda puede reconocer fácilmente que esta no es una estructura natural que considere el beneficio del usuario.
Así que decidí hacer tres cosas para arreglar la estructura del enlace interno:
- Site Information Architecture o Site-Tree debe seguir una ruta diferente a la de los enlaces colocados dentro del contenido. Debería seguir más de cerca la mente del usuario y una red neuronal de palabras clave.
- En cada pieza de contenido, las palabras clave secundarias deben usarse junto con las palabras clave principales de la página de destino.
- Los textos de anclaje deben ser naturales, adaptados al contenido y deben usarse en un punto diferente de cada página con atención a la percepción del usuario.
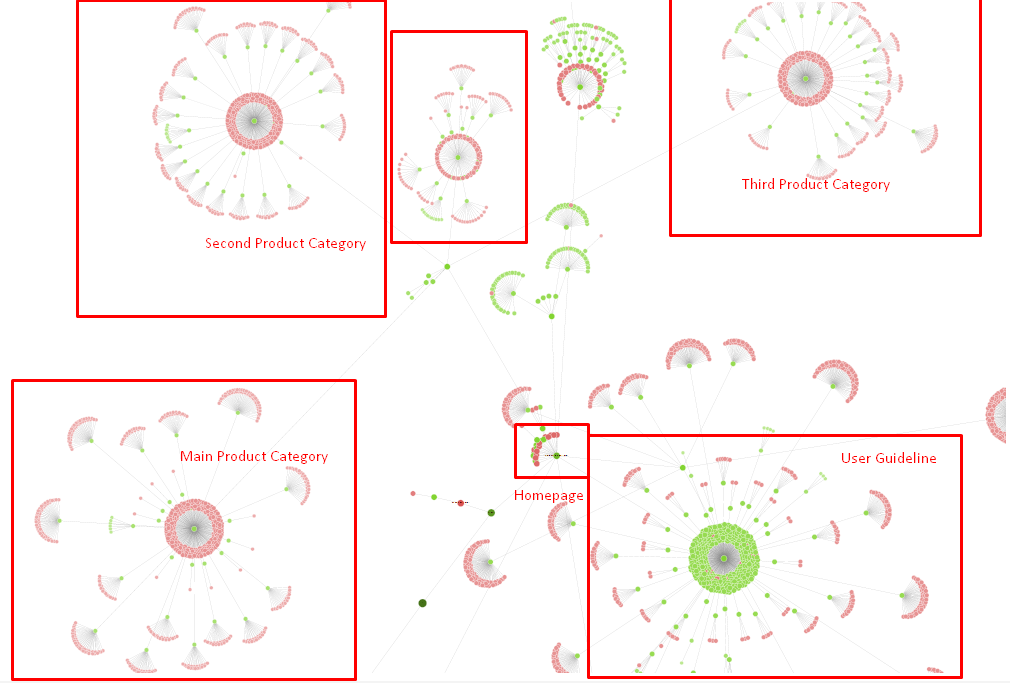
Nuestro árbol del sitio y una parte de la estructura de enlace por ahora.
En el diagrama anterior, puede ver nuestro enlace interno actual y el árbol del sitio.
Algunas de las cosas que hicimos para solucionar este problema están a continuación:
- Creamos 30 000 enlaces internos más con anclajes útiles.
- Utilizamos spots naturales y palabras clave para el usuario.
- No usamos las oraciones y patrones repetitivos para los enlaces internos.
- Dimos las señales correctas al Googlebot sobre el Inrank de una página web.
- Examinamos los efectos de la estructura correcta de enlaces internos en la eficiencia del rastreo a través de Log Analysis y vimos que nuestras páginas de productos principales se rastrearon más en comparación con las estadísticas anteriores.
- Creó más de 50 000 enlaces internos para páginas huérfanas.
- Se utilizaron enlaces internos de la página de inicio para potenciar las subpáginas y se crearon más fuentes de enlaces internos en la página de inicio.
- Para proteger Pagerank Power, también usamos la etiqueta nofollow para algunos enlaces externos innecesarios. (No se trataba de enlaces internos, pero tiene el mismo objetivo).
3. Problema: Estructura del contenido
Google dice que para los sitios web de YMYL, la confiabilidad y la autoridad son mucho más importantes que para otros tipos de sitios.

En los viejos tiempos, las palabras clave eran solo palabras clave. Pero ahora, también son entidades bien definidas, singulares, significativas y distinguibles. En nuestro contenido, había cuatro problemas principales:
- Nuestro contenido era breve. (Normalmente, la longitud del contenido no es importante. Pero en este caso, no contenían suficiente información sobre los temas).
- Los nombres de nuestros escritores no eran singulares, significativos o distinguibles como una entidad.
- Nuestro contenido no era agradable a la vista. En otras palabras, no era contenido de “comida rápida”. Era contenido sin subtítulos.
- Usamos lenguaje de marketing. En el espacio de un párrafo, podríamos identificar el nombre de la marca y su publicidad para el usuario.
- Había muchos botones que enviaban a los usuarios a las páginas de productos desde páginas informativas.
- En el contenido de nuestras páginas de productos, no había suficiente información o pautas completas.
- El diseño no era fácil de usar. Usábamos básicamente el mismo color para la fuente y el fondo. (Este sigue siendo el caso principalmente debido a problemas de infraestructura).
- Las imágenes y los videos no se habían visto como parte del contenido.
- La intención del usuario y la intención de búsqueda de una palabra clave específica no se consideraban importantes antes.
- Había mucho contenido duplicado, innecesario y repetitivo para el mismo tema.
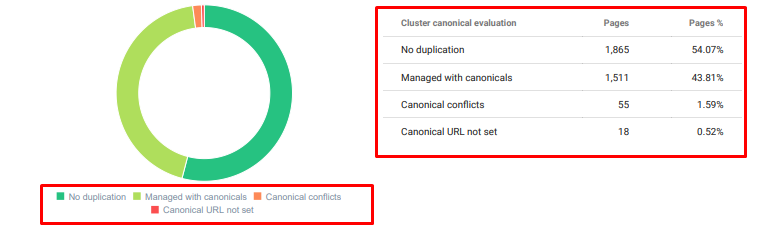
Oncrawl Auditoría de contenido duplicado a partir de hoy.
Solución: mejor estructura de contenido para la confianza del usuario
Al verificar un problema en todo el sitio, usar un programa de auditoría en todo el sitio como asistente es una mejor manera de organizar el tiempo dedicado a los proyectos de SEO. Al igual que en la sección de enlaces internos, utilicé Oncrawl Site Audit junto con otras herramientas e inspecciones Xpath.
En primer lugar, solucionar todos los problemas en la sección de contenido habría llevado demasiado tiempo. En aquellos días de crisis que colapsaban, el tiempo era un lujo. Así que decidí arreglar problemas rápidos como:
- Eliminación de contenido duplicado, innecesario y repetitivo
- Unificación de contenido corto y delgado que carece de información completa
- Volver a publicar contenido que carecía de subtítulos y estructura de seguimiento ocular
- Fijación del tono de marketing intensivo en el contenido
- Eliminar muchos botones de llamada a la acción del contenido
- Mejor comunicación visual con imágenes y videos
- Hacer que el contenido y las palabras clave objetivo sean compatibles con el usuario y la intención de búsqueda
- Usar y mostrar entidades financieras y educativas en el contenido para generar confianza
- Uso de la comunidad social para crear una prueba social de aprobación
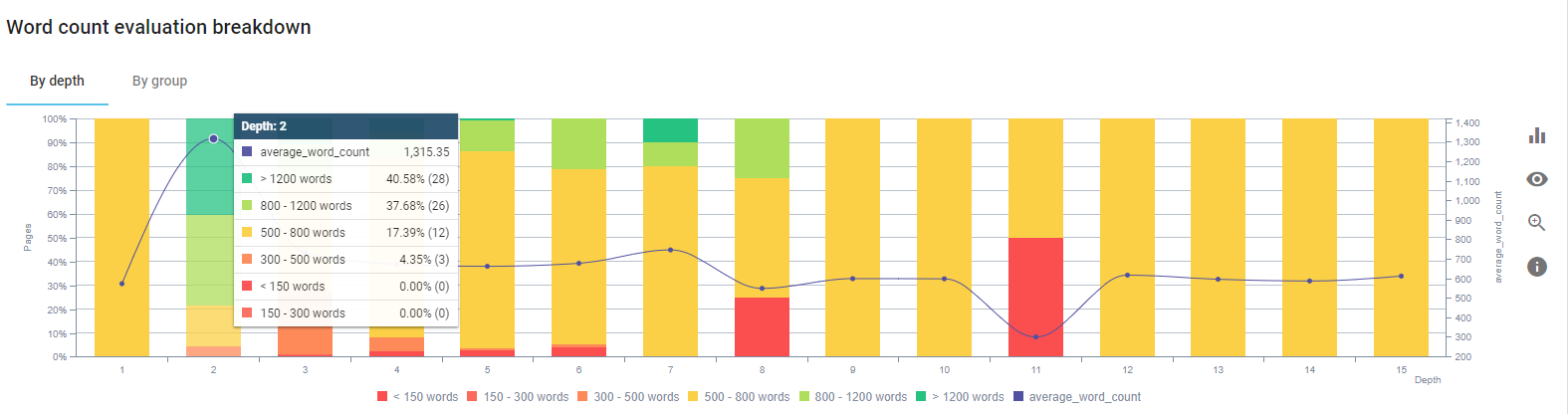

Nos concentramos en corregir el contenido de las páginas de productos y las páginas de guía más cercanas a ellos.
Al comienzo de este proceso, la mayoría de nuestras páginas de guía/aterrizaje de productos y transaccionales tenían menos de 500 palabras sin información completa.
En 25 días, las acciones que llevamos a cabo son las siguientes:
- Eliminadas 228 páginas con contenido duplicado, innecesario y repetitivo. (Los perfiles de vínculos de retroceso de Ccontent se verificaron antes del proceso de eliminación. Y usamos códigos de estado 301 o 410 para una mejor comunicación con Googlebot).
- Combinado más de 123 páginas que carecen de información completa.
- Subtítulos utilizados según su importancia y demanda de los usuarios en los contenidos.
- Se eliminaron el nombre de la marca y los botones de CTA con lenguaje de estilo de marketing.
- Incluya texto en las imágenes para reforzar el tema principal.
Esta es una captura de pantalla de Vision AI de Google. Google puede leer texto en imágenes y detectar sentimientos e identidades dentro de entidades.
- Activamos nuestra red social para atraer más usuarios.
- Examinó la brecha de contenido entre los competidores y nosotros y creó más de 80 nuevas piezas de contenido.
- Usó Google Analytics, Search Console y Google Data Studio para determinar las páginas de bajo rendimiento con una alta tasa de rebote y poco tráfico.
- Investigué los fragmentos destacados y sus palabras clave y estructura de contenido. Agregamos los mismos encabezados y estructura de contenido en nuestros contenidos relacionados. Esto aumentó nuestros fragmentos destacados.
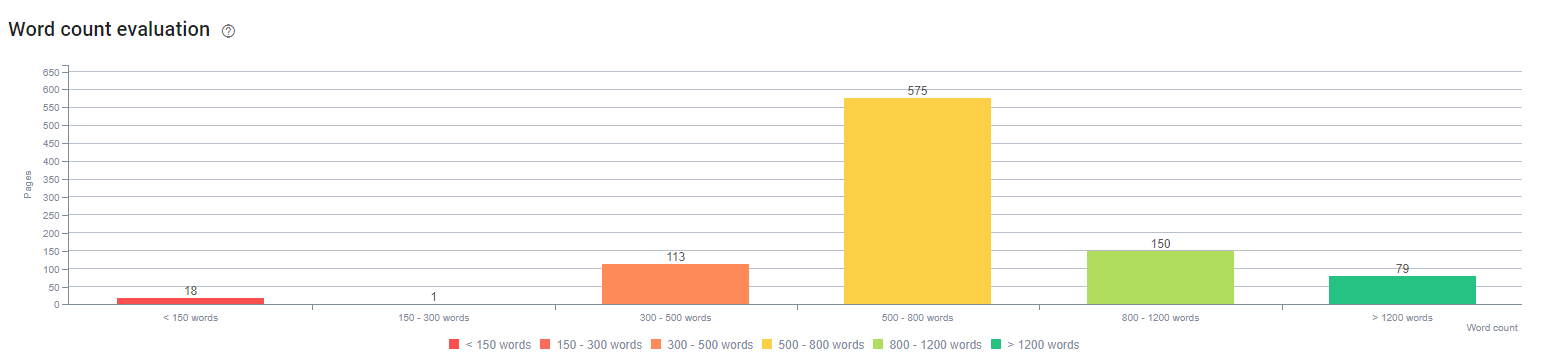
Al comienzo de este proceso, nuestros contenidos consistían en su mayoría entre 150 y 300 palabras. La longitud promedio de nuestro contenido aumentó en 350 palabras para todo el sitio.
4. Problema: Contaminación de Índices, Hinchazón y Etiquetas Canónicas
Google nunca ha hecho una declaración sobre la contaminación del índice y, de hecho, no estoy seguro de si alguien lo ha usado antes como término de SEO o no. Todas las páginas que no tengan sentido para Google para una puntuación de índice más eficiente deben eliminarse de las páginas de índice de Google. Las páginas que causan la contaminación del índice son páginas que no han generado tráfico durante meses. Tienen cero CTR y cero palabras clave orgánicas. En los casos en que tengan algunas palabras clave orgánicas, tendrían que convertirse en competidores de otras páginas de su sitio para las mismas palabras clave.
Además, llevamos a cabo una investigación sobre la hinchazón del índice y encontramos aún más páginas indexadas innecesarias. Estas páginas existían debido a una estructura de información del sitio errónea o debido a una estructura de URL incorrecta.
Otra razón de este problema fue el uso incorrecto de etiquetas canónicas. Durante más de dos años, las etiquetas canónicas se han tratado como simples sugerencias para Googlebot. Si se utilizan de forma incorrecta, Googlebot no los calculará ni les prestará atención al valorar el sitio. Y también, para este cálculo, probablemente consumirá su presupuesto de rastreo de manera ineficiente. Debido al uso incorrecto de etiquetas canónicas, se indexaron más de 300 páginas de comentarios con contenido duplicado.
El objetivo de mi teoría es mostrar a Google solo páginas necesarias y de calidad con potencial para obtener clics y crear valor para los usuarios.
Solución: Corrección de la contaminación y la hinchazón del índice
Primero, tomé el consejo de John Mueller de Google. Le pregunté si usaba la etiqueta noindex para estas páginas, pero aún permitía que Googlebot las siguiera, "¿perdería la equidad de los enlaces y la eficiencia del rastreo?"
Como puede adivinar, dijo que sí al principio, pero luego sugirió que el uso de enlaces internos puede superar este obstáculo.
También descubrí que el uso de etiquetas noindex al mismo tiempo que dofollow reducía la tasa de rastreo de Googlebot en estas páginas. Estas estrategias me permitieron hacer que Googlebot rastreara mi producto y las páginas de pautas importantes con más frecuencia. También modifiqué mi estructura de enlaces internos como aconsejó John Mueller.
En breve:
- Se descubrieron páginas indexadas innecesarias.
- Se eliminaron más de 300 páginas del índice.
- Se implementó la etiqueta Noindex.
- Se modificó la estructura de enlaces internos para las páginas que recibieron enlaces de páginas que fueron eliminadas del índice.
- La eficiencia y la calidad del rastreo se examinaron a lo largo del tiempo.
5. Problema: Códigos de estado incorrectos
Al principio, noté que Googlebot visita mucho contenido eliminado del pasado. Incluso se seguían rastreando páginas de hace ocho años. Esto se debió al uso de códigos de estado incorrectos, especialmente para el contenido eliminado.
Hay una gran diferencia entre las funciones 404 y 410. Uno de ellos es para una página de error donde no existe contenido y el otro es para contenido eliminado. Además, las páginas válidas también hacían referencia a muchas URL de origen y contenido eliminadas. Algunas imágenes eliminadas y recursos CSS o JS también se usaron en las páginas publicadas válidas como recursos. Finalmente, hubo muchas páginas 404 blandas, múltiples cadenas de redireccionamiento y redireccionamientos temporales 302-307 para páginas redireccionadas permanentemente.
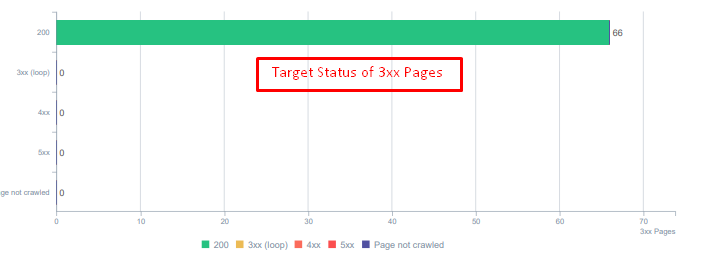
Códigos de estado para activos redirigidos hoy.
Solución: Corrección de códigos de estado erróneos
- Cada código de estado 404 se convirtió en código de estado 410. (Más de 30000)
- Cada recurso con código de estado 404 fue reemplazado por un nuevo recurso válido. (Más de 500)
- Cada redirección 302-307 se convirtió en redirección permanente 301. (Más de 1500)
- Las cadenas de redirección se eliminaron de los activos en uso.
- Cada mes, recibimos más de 25 000 visitas a páginas y recursos con un código de estado 404 en nuestro análisis de registro. Ahora, es menos de 50 para 404 códigos de estado por mes y cero aciertos para 410 códigos de estado...
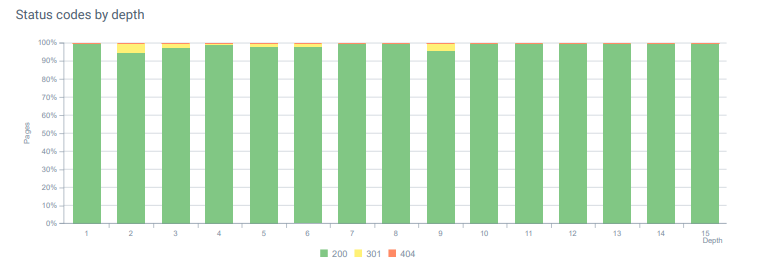
Códigos de estado a lo largo de la profundidad de la página hoy.
6. Problema: HTML semántico
La semántica se refiere a lo que algo significa. El HTML semántico incluye etiquetas que dan el significado del componente de la página dentro de una jerarquía. Con esta estructura de código jerárquico, puedes decirle a Google cuál es el propósito de una parte del contenido. Además, en el caso de que Googlebot no pueda rastrear todos los recursos necesarios para representar completamente su página, al menos puede especificar el diseño de su página web y las funciones de sus partes de contenido para Googlebot.
En Hangikredi.com, después de la actualización del algoritmo principal de Google del 12 de marzo, supe que no había suficiente presupuesto de rastreo debido a la estructura del sitio web no optimizada. Entonces, para que Googlebot entendiera más fácilmente el objetivo, la función, el contenido y la utilidad de la página web, decidí usar HTML semántico.
Solución: uso de HTML semántico
De acuerdo con las Directrices del evaluador de calidad de Google, cada buscador tiene una intención y cada página web tiene una función de acuerdo con esa intención. Para probar estas funciones a Googlebot, hicimos algunas mejoras en nuestra estructura HTML para algunas de las páginas que Googlebot rastrea menos.
- Usa la etiqueta <main> para mostrar el contenido principal y la función de la página.
- Usado <nav> para la parte de navegación.
- Usado <footer> para el pie de página del sitio.
- Usado <article> para el artículo.
- Etiquetas <section> usadas para cada etiqueta de encabezado.
- Se usaron etiquetas <imagen>, <tabla>, <citación> para imágenes, tablas y citas en el contenido.
- Se usa la etiqueta <aside> para el contenido complementario.
- Se corrigieron los problemas de jerarquía H1-H6 (a pesar de la última declaración de Google "usar dos H1 no es un problema", usar la estructura correcta ayuda a Googlebot).
- Al igual que en la sección Estructura del contenido, también usamos HTML semántico para fragmentos destacados, usamos tablas y listas para obtener más resultados de fragmentos destacados.

Para nosotros, esto no fue un desarrollo implementable de manera realista para todo el sitio. Aún así, con cada actualización de diseño, continuamos implementando etiquetas HTML semánticas para páginas web adicionales.
7. Problema: uso de datos estructurados
Al igual que el uso de HTML semántico, los datos estructurados pueden usarse para mostrar las funciones y definiciones de las partes de la página web a Googlebot. Además, los datos estructurados son obligatorios para obtener resultados enriquecidos. En nuestro sitio web, los datos estructurados no se usaron o, más comúnmente, se usaron incorrectamente hasta finales de marzo. Para crear mejores relaciones con las entidades en nuestro sitio web y nuestras cuentas fuera de la página, comenzamos a implementar datos estructurados.
Solución: uso correcto y probado de datos estructurados
Para las instituciones financieras y los sitios web de YMYL, los datos estructurados pueden solucionar muchos problemas. Por ejemplo, pueden mostrar la identidad de la marca, el tipo de contenido y crear una mejor vista de fragmentos. Utilizamos los siguientes tipos de datos estructurados para todo el sitio y páginas individuales:
- Preguntas frecuentes sobre datos estructurados para las principales páginas de productos
- Datos estructurados de la página web
- Organización de datos estructurados
- Datos estructurados de migas de pan
8. Mapa del sitio y optimización de Robots.txt
En Hangikredi.com, no hay Sitemap dinámico. El mapa del sitio existente en ese momento no incluía todas las páginas necesarias y también incluía contenido eliminado. Además, en el archivo Robots.txt, algunas de las páginas de referencia de afiliados con miles de enlaces externos no fueron rechazadas. Esto también incluyó algunos archivos JS de terceros que no están relacionados con el contenido y otros recursos adicionales que no eran necesarios para Googlebot.
Se aplicaron los siguientes pasos:
- Creó un sitemap_index.xml para múltiples mapas de sitio que se crean de acuerdo con las categorías del sitio para obtener mejores señales de rastreo y un mejor examen de cobertura.
- Algunos de los archivos JS de terceros y algunos archivos JS innecesarios no se permitieron en el archivo robots.txt.
- Se prohibieron las páginas de afiliados con enlaces externos y sin valor de página de destino, como mencionamos en la sección de Pagerank o Internal Link Sculpting.
- Se corrigieron más de 500 problemas de cobertura. (La mayoría de ellas eran páginas indexadas a pesar de que Robots.txt no las permitió).
Puede ver nuestra tasa de rastreo, la carga y el aumento de la demanda en el gráfico a continuación:
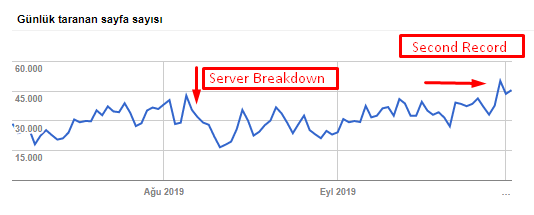
Recuento de páginas rastreadas por día por Googlebot. Hubo un aumento constante en las páginas rastreadas por día hasta el 1 de agosto. Después de que un ataque provocara una falla en el servidor a principios de agosto, recuperó su estabilidad en poco más de un mes.

La carga rastreada por día de Googlebot ha evolucionado en paralelo con la cantidad de páginas rastreadas por día.
9. Solucionar problemas de AMP
En el sitio web de la empresa, cada página de blog tiene una versión AMP. Debido a la implementación incorrecta del código y a la falta de canónicos de AMP, todas las páginas de AMP se eliminaron repetidamente del índice. Esto creó una puntuación de índice inestable y una falta de confianza en el sitio web. Además, las páginas de AMP tenían términos y palabras en inglés de forma predeterminada en contenido turco.
- Se corrigieron las etiquetas canónicas para más de 400 páginas AMP.
- Se encontraron y corrigieron implementaciones de código incorrectas. (Se debió principalmente a la implementación incorrecta de las etiquetas AMP-Analytics y AMP-Canonical).
- Los términos en inglés por defecto se tradujeron al turco.
- Se creó estabilidad en el índice y la clasificación para el lado del blog del sitio web de la empresa.
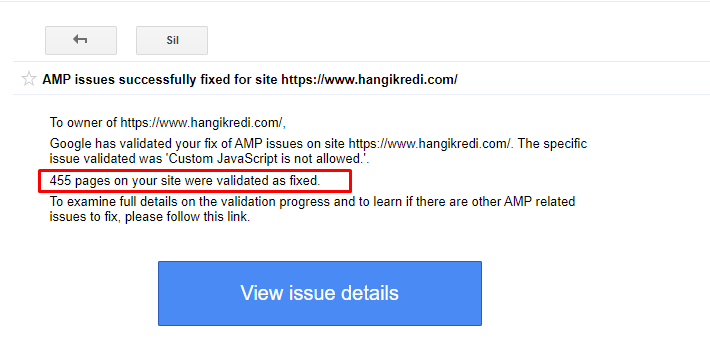
Un mensaje de ejemplo en GSC sobre las mejoras de AMP
10. Problemas y soluciones de metaetiquetas
Debido a los problemas de presupuesto de rastreo, a veces en consultas de búsqueda críticas para páginas de productos principales importantes, Google no indexaba ni mostraba contenido en las metaetiquetas. En lugar del metatítulo, la lista SERP mostraba solo el nombre de la empresa construido a partir de dos palabras. No se mostró ninguna descripción del fragmento. Esto estaba reduciendo nuestro CTR y dañando nuestra identidad de marca. Solucionamos este problema moviendo las etiquetas meta a la parte superior de nuestro código fuente como se muestra a continuación.
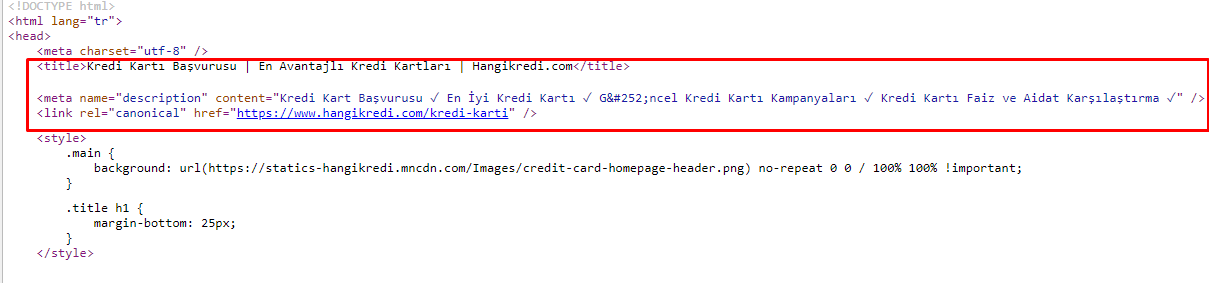
Además del presupuesto de rastreo, también optimizamos más de 600 metaetiquetas para páginas transaccionales e informativas:
- Longitud de caracteres optimizada para dispositivos móviles.
- Usó más palabras clave en los títulos
- Usé diferentes estilos de metaetiquetas y examiné el CTR, la brecha de palabras clave y los cambios de clasificación
- Creé más páginas con la estructura de árbol del sitio correcta para orientar mejor las palabras clave secundarias gracias a estos procesos de optimización.
- En nuestro sitio, todavía tenemos diferentes metatítulos, descripciones y encabezados para probar el algoritmo de Google y el CTR del usuario de búsqueda.
11. Problemas de rendimiento de imagen y soluciones
Los problemas de imagen se pueden dividir en dos tipos. Para la comodidad del contenido y la velocidad de la página. Para ambos, el sitio web de la firma todavía tiene mucho que hacer.
En marzo y abril, después de la actualización negativa del algoritmo básico del 12 de marzo:
- Las imágenes no tenían etiquetas alt o tenían etiquetas alt incorrectas.
- No tenían títulos.
- No tenían la estructura de URL correcta.
- No tenían extensiones de próxima generación.
- No se comprimieron.
- No tenían la resolución adecuada para cada tamaño de pantalla de dispositivo.
- No tenían subtítulos.
Para prepararse para la próxima actualización del algoritmo principal de Google:
- Las imágenes estaban comprimidas.
- Sus extensiones fueron parcialmente modificadas.
- Se escribieron etiquetas alt para la mayoría de ellos.
- Los títulos y subtítulos se arreglaron para el usuario.
- Las estructuras de URL se arreglaron parcialmente para el usuario.
- Encontramos algunas imágenes no utilizadas que el navegador aún está cargando y las eliminamos del sistema.
Debido a la infraestructura del sitio, implementamos parcialmente las correcciones de SEO de imágenes.
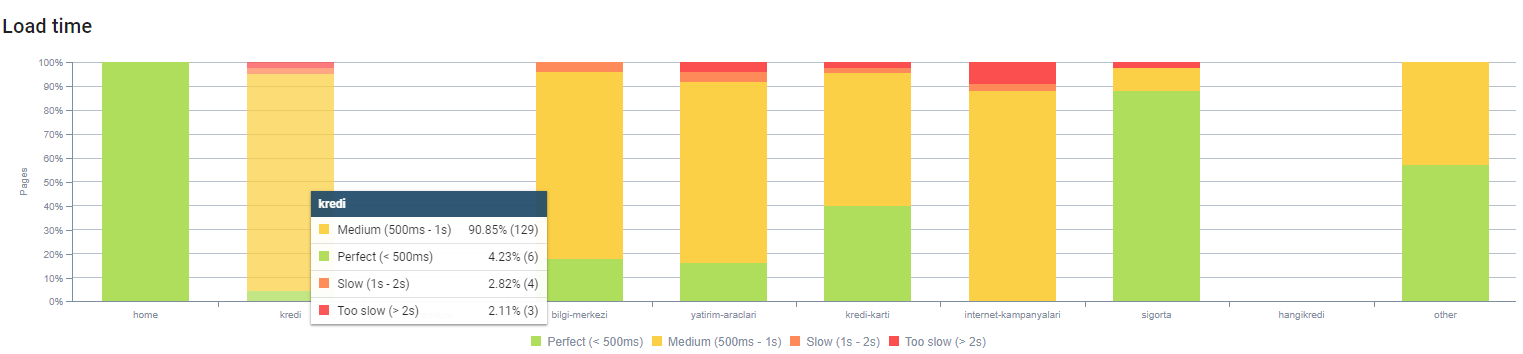
Puede observar el tiempo de carga de nuestra página por profundidad de página arriba. Como puede ver, la mayoría de las páginas de productos siguen siendo pesadas.
12. Problemas y soluciones de caché, captación previa y carga previa
Antes de la actualización del algoritmo central del 12 de marzo, había un sistema de caché suelto en el sitio web de la empresa. Algunas de las partes de contenido estaban en el caché, pero otras no. Esto fue especialmente un problema para las páginas de productos porque eran 2 veces más lentas que las páginas de productos de nuestros competidores. La mayoría de los componentes de nuestras páginas web son en realidad fuentes estáticas, pero aun así no tenían Etags para indicar el rango de caché.
Para prepararse para la próxima actualización del algoritmo principal de Google:
- Almacenamos en caché algunos componentes para cada página web y los hicimos estáticos.
- Estas páginas eran páginas de productos importantes.
- Todavía no usamos E-Tags debido a la infraestructura del sitio.
- Especialmente las imágenes, los recursos estáticos y algunas partes de contenido importantes ahora se almacenan en caché en todo el sitio.
- Hemos comenzado a usar el código dns-prefetch para algunos recursos subcontratados olvidados.
- Todavía no usamos el código de precarga, pero estamos trabajando en el viaje del usuario en el sitio para implementarlo en el futuro.
13. Optimización y minimización de HTML, CSS y JS
Debido a los problemas de infraestructura del sitio, no había muchas cosas que hacer para mejorar la velocidad del sitio. Traté de cerrar la brecha con todos los métodos que pude, incluida la eliminación de algunos componentes de la página. Para las páginas de productos importantes, limpiamos la estructura del código HTML, la minimizamos y la comprimimos.
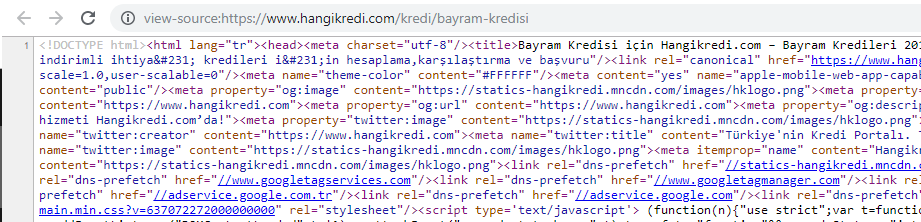
Una captura de pantalla del código fuente de una de nuestras páginas de productos estacionales pero importantes. El uso de datos estructurados de preguntas frecuentes, minimización de HTML, optimización de imágenes, actualización de contenido y enlaces internos nos dio el primer puesto en el momento adecuado. (La palabra clave es "Bayram Kredisi" en turco, que significa "Crédito de vacaciones")
También implementamos CSS Factoring, Refactoring y JS Compression parcialmente con pequeños pasos. Cuando las clasificaciones cayeron, examinamos la brecha de velocidad del sitio entre las páginas de nuestro competidor y las nuestras. Habíamos elegido algunas páginas urgentes que podíamos acelerar. También purificamos y comprimimos parcialmente archivos CSS críticos en estas páginas. Iniciamos el proceso de eliminación de algunos de los archivos JS de terceros utilizados por diferentes departamentos de la empresa, pero aún no se han eliminado. Para algunas páginas de productos, también pudimos cambiar el orden de carga de recursos.
Examinando a los competidores
Además de cada mejora técnica de SEO, inspeccionar a los competidores fue mi mejor guía para comprender la naturaleza y los objetivos de una actualización del algoritmo central. He utilizado algunos programas útiles y útiles para seguir los cambios de diseño, contenido, rango y tecnología de mi competidor.
- Para los cambios de clasificación de palabras clave, utilicé Wincher, Semrush y Ahrefs.
- Para las menciones de marca, utilicé Google Alerts, BuzzSumo, Talkwalker.
- Para los informes de obtención de nuevos enlaces y nuevas palabras clave, utilicé Ahrefs Alert.
- Para los cambios de contenido y diseño, utilicé Visualping.
- Para los cambios de tecnología, utilicé SimilarTech.
- Para Google Update News and Inspection, utilicé principalmente Semrush Sensor, Algoroo y CognitiveSEO Signals.
- Para inspeccionar el historial de URL de los competidores, utilicé Wayback Machine.
- Para la velocidad del servidor de la competencia, utilicé Chrome DevTools y ByteCheck.
- Para el costo de rastreo y procesamiento, utilicé "Cuánto cuesta mi sitio". (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.