
Pronóstico de tráfico SEO con Prophet y Python
Publicado: 2021-03-16Establecer objetivos y evaluar el cumplimiento a lo largo del tiempo es un ejercicio muy interesante para comprender qué somos capaces de lograr y si la estrategia que utilizamos es efectiva o no. Sin embargo, normalmente no es tan fácil establecer estos objetivos porque primero tendremos que hacer un pronóstico.
Crear un pronóstico no es fácil, pero gracias a algunos procedimientos de pronóstico disponibles, nuestra CPU y algunas habilidades de programación, podemos reducir bastante su complejidad. En esta publicación, le mostraré cómo podemos hacer predicciones precisas y cómo puede aplicar esto al SEO utilizando Python y la biblioteca Prophet y sin tener superpoderes de adivinos.
Si nunca has oído hablar de Prophet, quizás te preguntes qué es. En resumen, Prophet es un procedimiento para pronósticos que fue lanzado por el equipo Core Data Science de Facebook, que está disponible en Python y R y que trata muy bien los valores atípicos y los efectos estacionales para
ofrecer predicciones precisas y rápidas.
Cuando hablamos de pronóstico, debemos tener en cuenta dos cosas:
- Cuantos más datos históricos tengamos, más preciso será nuestro modelo y, por tanto, nuestras predicciones.
- El modelo predictivo solo será válido si los factores internos se mantienen y no hay factores externos que lo afecten. Esto significa que si, por ejemplo, hemos estado publicando una publicación por semana y comenzamos a publicar dos publicaciones por semana, este modelo podría no ser válido para predecir cuál será el resultado de este cambio de estrategia. Por otro lado, si hay una actualización del algoritmo, es posible que el modelo tampoco sea válido. Tenga en cuenta que el modelo se construye en base a datos históricos.
Para aplicar esto al SEO lo que vamos a hacer es predecir las sesiones de SEO para el próximo mes siguiendo los siguientes pasos:
- Obtener datos de Google Analytics sobre las sesiones orgánicas durante un período de tiempo específico.
- Entrenando a nuestro modelo.
- Pronosticar el tráfico SEO para el próximo mes.
- Evaluando qué tan bueno es nuestro modelo con el error absoluto medio.
¿Quiere saber más sobre cómo funciona este procedimiento de previsión? ¡Empecemos entonces!
Obtener los datos de Google Analytics
Podemos abordar la extracción de datos de Google Analytics de dos maneras: exportando un archivo de Excel desde la interfaz normal o usando la API para recuperar estos datos.
Importar los datos de un archivo de Excel
La forma más fácil de obtener estos datos de Google Analytics es ir a la sección Canales en la barra lateral, hacer clic en Orgánico y exportar los datos con el botón que se encuentra en la parte superior de la página. Asegúrese de seleccionar en el menú desplegable en la parte superior del gráfico la variable que le gustaría analizar, en este caso Sesiones.
Después de exportar los datos como un archivo de Excel, podemos importarlos a nuestro cuaderno con Pandas. Tenga en cuenta que el archivo de Excel con dichos datos contendrá diferentes pestañas, por lo que la pestaña con el tráfico mensual debe especificarse como argumento en el código que se encuentra a continuación. También borramos la última fila porque contiene la cantidad total de sesiones, lo que distorsionaría nuestro modelo.
importar pandas como pd
df = pd.read_excel ('.xlsx', sheet_name= "")
df = df.drop(len(df) - 1)
Podemos dibujar con Matplotlib cómo se ven los datos:
desde matplotlib importar pyplot
df["Sesiones"].plot(title = "Sesiones")
pyplot.mostrar() 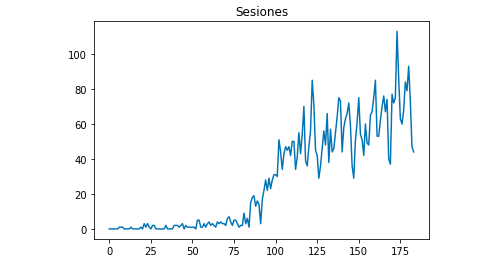
Uso de la API de Google Analytics
En primer lugar, para utilizar la API de Google Analytics, debemos crear un proyecto en la consola de desarrollador de Google, habilitar el servicio de informes de Google Analytics y obtener las credenciales. Jean-Christophe Chouinard explica muy bien en este artículo cómo configurar esto.
Una vez que se obtienen las credenciales, debemos autenticarnos antes de realizar nuestra solicitud. La autenticación debe realizarse con el archivo de credenciales que se obtuvo inicialmente de la consola de desarrollo de Google. También necesitaremos anotar en nuestro código el GA View ID de la propiedad que nos gustaría usar.
desde apiclient.discovery compilación de importación
de oauth2client.service_account import ServiceAccountCredentials
ÁMBITOS = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
VISTA_
credenciales = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
análisis = compilación ('informe de análisis', 'v4', credenciales = credenciales)Después de la autenticación, solo tenemos que hacer la solicitud. El que necesitamos usar para obtener los datos sobre las sesiones orgánicas de cada día es:
respuesta = análisis.informes().batchGet(cuerpo={
'solicitudes de informe': [{
'id de vista': VIEW_ID,
'Rangos de fechas': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'métricas': [
{"expresión": "ga:sesiones"}
], "dimensiones": [
{"nombre": "ga:fecha"}
],
"filtersExpression":"ga:channelGrouping=~Organic",
"includeEmptyRows": "verdadero"
}]}).ejecutar()Tenga en cuenta que seleccionamos el rango de tiempo en dateRanges. En mi caso voy a recuperar datos desde el 1 de septiembre hasta el 31 de enero: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
Después de esto, solo necesitamos obtener el archivo de respuesta para agregar a una lista los días con sus sesiones orgánicas:
lista_valores = [] para x en respuesta["informes"][0]["datos"]["filas"]: list_values.append([x["dimensiones"][0],x["métricas"][0]["valores"][0]])
Como puede ver, usar la API de Google Analytics es bastante simple y puede usarse para muchos objetivos. En este artículo, expliqué cómo puede usar la API de Google Analytics para crear alertas para detectar páginas de bajo rendimiento.

Adaptando las listas a Dataframes
Para hacer uso de Prophet, debemos ingresar un marco de datos con dos columnas que deben nombrarse: "ds" e "y". Si ha importado los datos de un archivo de Excel, ya lo tenemos como un marco de datos, por lo que solo deberá nombrar las columnas "ds" e "y":
df.columnas = ['ds', 'y']
En caso de que haya utilizado la API para recuperar los datos, debemos transformar la lista en un marco de datos y nombrar las columnas según sea necesario:
desde pandas importar DataFrame df_sessions = DataFrame(list_values,columns=['ds','y'])
Entrenando al modelo
Una vez que tenemos el Dataframe con el formato requerido, podemos determinar y entrenar nuestro modelo muy fácilmente con:
importar fbprophet de fbprophet importar Profeta modelo = profeta() modelo.fit(df_sessions)
Haciendo nuestras predicciones
¡Finalmente, después de entrenar nuestro modelo, podemos comenzar a pronosticar! Para proceder con las predicciones primero necesitaremos crear una lista con el rango de tiempo que nos gustaría predecir y ajustando el formato de fecha y hora:
de pandas importar to_datetime pronóstico_días = [] para x en el rango (1, 28): fecha = "2021-02-" + cadena (x) pronóstico_días.append([fecha]) pronóstico_días = Marco de datos (pronóstico_días) pronóstico_días.columnas = ['ds'] pronóstico_días['ds']= to_datetime(forecast_days['ds'])
En este ejemplo, uso un bucle que creará un marco de datos que contendrá todos los días desde febrero. Y ahora solo es cuestión de usar el modelo que se entrenó previamente:
pronóstico = modelo.predecir(forecast_days)
Podemos dibujar un gráfico que resalte el período de tiempo pronosticado:
desde matplotlib importar pyplot modelo.plot(pronóstico) pyplot.mostrar()
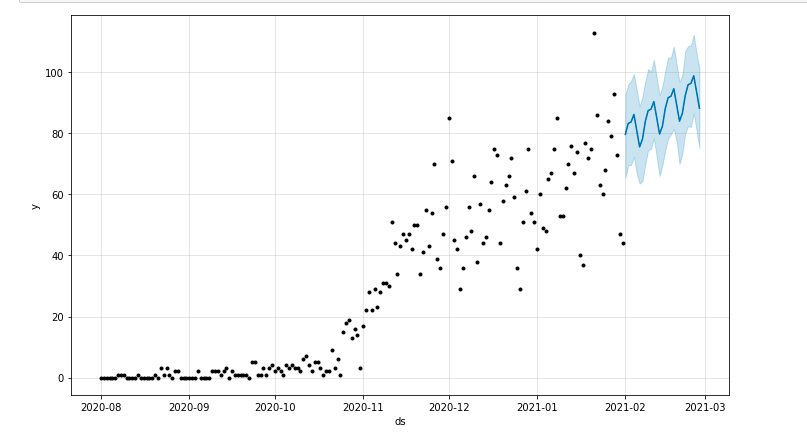
Evaluación del modelo
Finalmente, podemos evaluar qué tan preciso es nuestro modelo eliminando algunos días de los datos que se usan para entrenar el modelo, pronosticando las sesiones para esos días y calculando el error absoluto medio.
Como ejemplo, lo que voy a hacer es eliminar del dataframe original los últimos 12 días de enero, pronosticando las sesiones de cada día y comparando el tráfico real con el pronosticado.
Primero eliminamos del dataframe original los 12 últimos días con pop y creamos un nuevo dataframe que solo incluirá esos 12 días que se usarán para el pronóstico:
entrenar = df_sessions.drop(df_sessions.index[-12:]) futuro = df_sessions.loc[df_sessions["ds"]> tren.iloc[len(tren)-1]["ds"]]["ds"]
Ahora entrenamos el modelo, hacemos el pronóstico y calculamos el error absoluto medio. Al final, podemos dibujar un gráfico que mostrará la diferencia entre los valores pronosticados reales y los reales. Esto es algo que aprendí de este artículo escrito por Jason Brownlee.
de sklearn.metrics importar mean_absolute_error
importar numpy como np
de matriz de importación numpy
#Entrenamos al modelo
modelo = profeta()
modelo.fit(tren)
#Adapte el marco de datos que se utiliza para los días de pronóstico al formato requerido por Prophet.
futuro = lista(futuro)
futuro = trama de datos (futuro)
futuro = futuro.rename(columnas={0: 'ds'})
# Hacemos el pronóstico
pronóstico = modelo.predecir(futuro)
# Calculamos el MAE entre los valores reales y los valores predichos
y_true = df_sessions['y'][-12:].valores
y_pred = pronóstico['yhat'].valores
mae = mean_absolute_error(y_true, y_pred)
# Trazamos el resultado final para una comprensión visual
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, etiqueta='Actual')
pyplot.plot(y_pred, label='Predicted')
pyplot.leyenda()
pyplot.mostrar()
imprimir (mae) 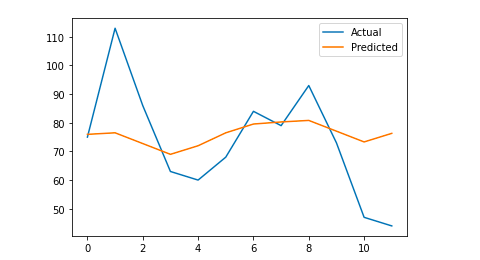
Mi error absoluto medio es 13, lo que significa que mi modelo pronosticado asigna a cada día 13 sesiones más que las reales, lo que parece ser un error aceptable.
¡Eso es todo amigos! Espero que este artículo te haya resultado interesante y puedas empezar a hacer tus predicciones SEO para fijar objetivos.
Más allá: OnCrawl Labs
Si ha disfrutado pronosticando su tráfico con este método, también estará interesado en OnCrawl Labs, el laboratorio de ciencia de datos y aprendizaje automático de OnCrawl que ofrece proyectos precodificados para sus flujos de trabajo de SEO.
En el pronóstico de SEO, OnCrawl Labs lo ayudará a refinar sus proyecciones de SEO:
- Obtenga una mejor comprensión de las teorías y el proceso detrás del algoritmo Facebook Prophet
- Analice un segmento de tráfico, como el tráfico solo de palabras clave de cola larga o solo de palabras clave de marca...
- Siga un proceso paso a paso para establecer eventos históricos, ajustando su influencia y la probabilidad de que se repitan.