
¿Cómo extraer contenido de texto relevante de una página HTML?
Publicado: 2021-10-13Contexto
En el departamento de I+D de Oncrawl buscamos cada vez más añadir valor al contenido semántico de tus páginas web. Utilizando modelos de aprendizaje automático para el procesamiento del lenguaje natural (PNL), es posible realizar tareas con un valor añadido real para el SEO.
Estas tareas incluyen actividades tales como:
- Afinar el contenido de sus páginas
- Realización de resúmenes automáticos
- Agregar nuevas etiquetas a sus artículos o corregir las existentes
- Optimización del contenido de acuerdo con los datos de Google Search Console
- etc.
El primer paso en esta aventura es extraer el contenido de texto de las páginas web que utilizarán estos modelos de aprendizaje automático. Cuando hablamos de páginas web, esto incluye HTML, JavaScript, menús, medios, encabezado, pie de página, … Extraer contenido de forma automática y correcta no es fácil. A través de este artículo, propongo explorar el problema y discutir algunas herramientas y recomendaciones para lograr esta tarea.
Problema
Extraer contenido de texto de una página web puede parecer sencillo. Con unas pocas líneas de Python, por ejemplo, un par de expresiones regulares (regexp), una biblioteca de análisis como BeautifulSoup4, y listo.
Si ignora por unos minutos el hecho de que cada vez más sitios utilizan motores de renderizado de JavaScript como Vue.js o React, analizar HTML no es muy complicado. Si desea contornear este problema aprovechando nuestro rastreador JS en sus rastreos, le sugiero que lea "¿Cómo rastrear un sitio en JavaScript?".
Sin embargo, queremos extraer texto que tenga sentido, que sea lo más informativo posible. Cuando lees un artículo sobre el último álbum póstumo de John Coltrane, por ejemplo, ignoras los menús, el pie de página… y obviamente, no estás viendo todo el contenido HTML. Estos elementos HTML que aparecen en casi todas sus páginas se denominan repetitivo. Queremos deshacernos de él y mantener solo una parte: el texto que lleva información relevante.
Por lo tanto, es solo este texto el que queremos pasar a los modelos de aprendizaje automático para su procesamiento. Por eso es fundamental que la extracción sea lo más cualitativa posible.
Soluciones
En general, nos gustaría deshacernos de todo lo que "permanece" en el texto principal: menús y otras barras laterales, elementos de contacto, enlaces de pie de página, etc. Hay varios métodos para hacerlo. Estamos principalmente interesados en proyectos de código abierto en Python o JavaScript.
soloTexto
jusText es una implementación propuesta en Python de una tesis doctoral: “Removing Boilerplate and Duplicate Content from Web Corpora”. El método permite que los bloques de texto de HTML se clasifiquen como "buenos", "malos", "demasiado cortos" de acuerdo con diferentes heurísticas. Estas heurísticas se basan principalmente en el número de palabras, la relación texto/código, la presencia o ausencia de enlaces, etc. Puede leer más sobre el algoritmo en la documentación.
trafilatura
trafilatura, también creada en Python, ofrece heurística tanto sobre el tipo de elemento HTML como sobre su contenido, por ejemplo, la longitud del texto, la posición/profundidad del elemento en el HTML o el número de palabras. trafilatura también usa jusText para realizar algún procesamiento.
legibilidad
¿Alguna vez has notado el botón en la barra de URL de Firefox? Es la Vista del lector: le permite eliminar el modelo estándar de las páginas HTML para mantener solo el contenido del texto principal. Bastante práctico para usar en sitios de noticias. El código detrás de esta función está escrito en JavaScript y Mozilla lo llama legibilidad. Se basa en el trabajo iniciado por el laboratorio Arc90.
Aquí hay un ejemplo de cómo representar esta función para un artículo del sitio web de France Musique. 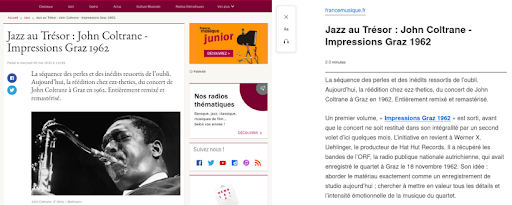
A la izquierda, es un extracto del artículo original. A la derecha, es una representación de la función Reader View en Firefox.
Otros
Nuestra investigación sobre las herramientas de extracción de contenido HTML también nos llevó a considerar otras herramientas:
- periódico: una biblioteca de extracción de contenido más bien dedicada a sitios de noticias (Python). Esta biblioteca se utilizó para extraer contenido del corpus OpenWebText2.
- calderapy3 es un puerto de Python de la biblioteca de calderas.
- La biblioteca Dragnet Python también está inspirada en Calderpipe.
Datos de seguimiento³
 Aprende más
Aprende másEvaluación y recomendaciones
Antes de evaluar y comparar las diferentes herramientas, queríamos saber si la comunidad de PNL utiliza algunas de estas herramientas para preparar su corpus (gran conjunto de documentos). Por ejemplo, el conjunto de datos llamado The Pile utilizado para entrenar GPT-Neo tiene más de 800 GB de textos en inglés de Wikipedia, Openwebtext2, Github, CommonCrawl, etc. Al igual que BERT, GPT-Neo es un modelo de lenguaje que utiliza transformadores de tipo. Ofrece una implementación de código abierto similar a la arquitectura GPT-3.

El artículo “The Pile: An 800GB Dataset of Diverse Text for Language Modeling” menciona el uso de jusText para una gran parte de su corpus de CommonCrawl. Este grupo de investigadores también había planeado hacer un benchmark de las diferentes herramientas de extracción. Desafortunadamente, no pudieron hacer el trabajo planeado debido a la falta de recursos. En sus conclusiones, cabe señalar que:
- jusText a veces eliminaba demasiado contenido, pero aun así proporcionaba una buena calidad. Dada la cantidad de datos que tenían, esto no fue un problema para ellos.
- trafilatura fue mejor en la preservación de la estructura de la página HTML, pero mantuvo demasiado repetitivo.
Para nuestro método de evaluación, tomamos una treintena de páginas web. Extrajimos el contenido principal “manualmente”. Luego comparamos la extracción de texto de las diferentes herramientas con este llamado contenido de "referencia". Utilizamos la puntuación ROUGE, que se utiliza principalmente para evaluar resúmenes de texto automáticos, como métrica.
También comparamos estas herramientas con una herramienta "hecha en casa" basada en reglas de análisis HTML. Resulta que trafilatura, jusText y nuestra herramienta casera funcionan mejor que la mayoría de las otras herramientas para esta métrica.
Aquí hay una tabla de promedios y desviaciones estándar del puntaje ROUGE:
| Instrumentos | Significar | estándar |
|---|---|---|
| trafilatura | 0.783 | 0.28 |
| oncrawl | 0.779 | 0.28 |
| soloTexto | 0.735 | 0.33 |
| calderapy3 | 0.698 | 0.36 |
| legibilidad | 0.681 | 0.34 |
| rastra | 0.672 | 0.37 |
En vista de los valores de las desviaciones estándar, tenga en cuenta que la calidad de la extracción puede variar mucho. La forma en que se implementa HTML, la consistencia de las etiquetas y el uso apropiado del lenguaje pueden causar mucha variación en los resultados de la extracción.
Las tres herramientas que funcionan mejor son trafilatura, nuestra herramienta interna llamada "oncrawl" para la ocasión y jusText. Como trafilatura usa jusText como alternativa, decidimos usar trafilatura como nuestra primera opción. Sin embargo, cuando este último falla y extrae cero palabras, usamos nuestras propias reglas.
Tenga en cuenta que el código de trafilatura también ofrece un punto de referencia en varios cientos de páginas. Calcula puntajes de precisión, puntaje f1 y precisión en función de la presencia o ausencia de ciertos elementos en el contenido extraído. Destacan dos herramientas: trafilatura y oca3. También es posible que desee leer:
- Elegir la herramienta adecuada para extraer contenido de la Web (2020)
- el repositorio de Github: punto de referencia de extracción de artículos: bibliotecas de código abierto y servicios comerciales
Conclusiones
La calidad del código HTML y la heterogeneidad del tipo de página dificultan la extracción de contenido de calidad. Como descubrieron los investigadores de EleutherAI, que están detrás de The Pile y GPT-Neo, no existen herramientas perfectas. Existe una compensación entre el contenido a veces truncado y el ruido residual en el texto cuando no se ha eliminado todo el texto repetitivo.
La ventaja de estas herramientas es que no tienen contexto. Eso significa que no necesitan ningún dato más que el HTML de una página para extraer el contenido. Usando los resultados de Oncrawl, podríamos imaginar un método híbrido usando las frecuencias de ocurrencia de ciertos bloques HTML en todas las páginas del sitio para clasificarlos como repetitivos.
En cuanto a los conjuntos de datos utilizados en los puntos de referencia que hemos encontrado en la Web, a menudo son el mismo tipo de página: artículos de noticias o publicaciones de blog. No incluyen necesariamente sitios de seguros, agencias de viajes, comercio electrónico, etc., donde el contenido del texto a veces es más complicado de extraer.
Respecto a nuestro benchmark y por falta de recursos, somos conscientes de que unas treinta páginas no son suficientes para obtener una visión más detallada de las puntuaciones. Idealmente, nos gustaría tener una mayor cantidad de páginas web diferentes para refinar nuestros valores de referencia. Y también nos gustaría incluir otras herramientas como goose3, html_text o inscriptis.