
Extraiga datos de la API de Google Search Console para el análisis de datos en Python
Publicado: 2022-03-01Google Search Console (GSC) es definitivamente una de las herramientas más útiles para los especialistas en SEO, ya que le permite obtener información sobre la cobertura del índice y especialmente las consultas para las que está clasificando actualmente. Sabiendo esto, mucha gente analiza los datos de GSC usando hojas de cálculo y está bien, siempre y cuando comprenda que hay mucho más margen de mejora con herramientas como los lenguajes de programación.
Desafortunadamente, la interfaz de GSC es bastante limitada tanto en términos de filas mostradas (solo 5000) como en el período de tiempo disponible, solo 16 meses. Está claro que esto puede limitar severamente su capacidad de obtener información y no es adecuado para sitios web más grandes.
Python le permite obtener datos de GSC con facilidad y automatizar cálculos más complejos que requerirían mucho más esfuerzo en el software de hoja de cálculo tradicional.
Esta es la solución para uno de los mayores problemas de Excel, a saber, el límite de fila y la velocidad. Hoy en día, tiene muchas más alternativas para analizar datos que antes y ahí es donde entra en juego Python.
No necesita ningún conocimiento avanzado de codificación para seguir este tutorial, solo la comprensión de algunos conceptos básicos y algo de práctica con Google Colab.
Primeros pasos con la API de Google Search Console
Antes de comenzar, es importante configurar la API de Google Search Console. El proceso es bastante simple, todo lo que necesita es una cuenta de Google. Los pasos son los siguientes:
- Cree un nuevo proyecto en Google Cloud Platform. Deberías tener una cuenta de Google y estoy bastante seguro de que tienes una. Vaya a la consola y luego debería encontrar una opción en la parte superior para crear un nuevo proyecto.
- Haga clic en el menú de la izquierda y seleccione "API y servicios", accederá a otra pantalla.
- Desde la barra de búsqueda en la parte superior, busque "Google Search Console API" y habilítelo.
- Luego pase a la pestaña "Credenciales", necesita algún tipo de permiso para usar la API.
- Configure la pantalla de “consentimiento”, ya que es obligatorio. No importa para el uso que le vayamos a hacer si es público o no.
- Puede elegir "Aplicación de escritorio" para el tipo de aplicación
- Usaremos OAuth 2.0 para este tutorial, debe descargar un archivo json y ya está.
Esta es en realidad la parte más difícil para la mayoría de las personas, especialmente para quienes no están acostumbrados a las API de Google. No te preocupes, los próximos pasos serán mucho más fáciles y menos problemáticos.
Obtener datos de la API de Google Search Console con Python
Mi recomendación es que uses una libreta como Jupyter Notebook o Google Colab. Este último es mejor ya que no tiene que preocuparse por los requisitos. Por tanto, lo que voy a explicar está basado en Google Colab.
Antes de comenzar, actualice su archivo json a Google Colab con el siguiente código:
de archivos de importación de google.colab archivos.subir()
Luego, instalemos todas las bibliotecas que necesitaremos para nuestro análisis y mejoremos la visualización de tablas con este fragmento de código:
%%captura #carga lo que se necesita !pip instalar git+https://github.com/joshcarty/google-searchconsole importar pandas como pd importar numpy como np importar matplotlib.pyplot como plt desde google.colab importar data_table !git clonar https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip instalar umap-aprender data_table.enable_dataframe_formatter() #para una mejor visualización de la tabla
Finalmente, puede cargar la biblioteca de la consola de búsqueda, que ofrece la forma más fácil de hacerlo sin depender de funciones largas. Ejecute el siguiente código con los argumentos que estoy usando y asegúrese de que client_config tenga el mismo nombre que el archivo json cargado.
importar consola de búsqueda cuenta = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Será redirigido a una página de Google para autorizar la aplicación, seleccione su cuenta de Google y luego copie y pegue el código que obtendrá en la barra de Google Colab.
Aún no hemos terminado, tienes que seleccionar la propiedad para la que vas a necesitar datos. Puede verificar fácilmente sus propiedades a través de account.webproperties para ver qué debe elegir.
property_name = input('Inserte el nombre de su sitio web como se indica en GSC:')
webproperty=cuenta[str(nombre_propiedad)]
Una vez que haya terminado, ejecutará una función personalizada para crear un objeto que contenga nuestros datos.
def extract_gsc_data(webproperty, start, stop, *args):
si la propiedad web no es Ninguno:
print(f'Extrayendo datos para {propiedad web}')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
devolver gsc_data
más:
print('Propiedad web no encontrada, seleccione la correcta')
volver Ninguno
La idea de la función es tomar la propiedad que definiste antes y un período de tiempo, en forma de fechas de inicio y finalización, junto con las dimensiones.
La elección de poder seleccionar dimensiones es crucial para los especialistas en SEO porque le permite comprender si necesita un cierto nivel de granularidad. Por ejemplo, es posible que no le interese obtener la dimensión de fecha, en algunos casos.
Mi sugerencia es elegir siempre consulta y página, ya que la interfaz de Google Search Console puede exportarlas por separado y es muy molesto fusionarlas cada vez. Este es otro beneficio de la API de Search Console.
En nuestro caso, también podemos obtener directamente la dimensión de la fecha, para mostrar algunos escenarios interesantes en los que debe tener en cuenta el tiempo.
ex = extract_gsc_data(webproperty, '2021-09-01', '2021-12-31', 'consulta', 'página', 'fecha')
Seleccione un marco de tiempo adecuado, teniendo en cuenta que para propiedades más grandes deberá esperar mucho tiempo. Para este ejemplo, solo estoy considerando un período de tiempo de 3 meses, que es suficiente para obtener información valiosa de la mayoría de los conjuntos de datos, en promedio.
Puede seleccionar incluso una semana si está tratando con una gran cantidad de datos, lo que nos importa es el proceso.
Lo que le mostraré aquí se basa en datos sintéticos o datos reales modificados para que sea adecuado para los ejemplos. Como consecuencia, lo que ve aquí es totalmente realista y puede reflejar escenarios del mundo real.
Limpieza de datos
Para aquellos que no saben, no podemos usar nuestros datos tal como están, hay algunos pasos adicionales para asegurarnos de que estamos trabajando correctamente. En primer lugar, tenemos que convertir nuestro objeto en un marco de datos de Pandas, una estructura de datos con la que debe estar familiarizado, ya que es la base del análisis de datos en Python.
df = pd.DataFrame(datos=ex) df.cabeza()
El método head puede mostrar las primeras 5 filas de su conjunto de datos, es muy útil para echar un vistazo a cómo se ven sus datos. Podemos contar cuántas páginas tenemos usando una función simple.
Una buena forma de eliminar duplicados es convertir un objeto en un conjunto, ya que los conjuntos no pueden contener elementos duplicados.
Algunos de los fragmentos de código se inspiraron en el cuaderno de Hamlet Batista y otro de Masaki Okazawa.
Eliminación de términos de marca
Lo primero que debe hacer es eliminar las palabras clave de marca, estamos buscando aquellas consultas que no contengan nuestros términos de marca. Esto es bastante sencillo de hacer con una función personalizada y, por lo general, tendrá un conjunto de términos de marca.
Para fines demostrativos, no es necesario que los filtre todos, pero hágalo para obtener análisis reales. Es uno de los pasos de limpieza de datos más importantes en SEO, de lo contrario corre el riesgo de presentar resultados engañosos.
nombre_dominio = str(input('Insertar términos de marca separados por una coma: ')).replace(',', '|')
importar re
nombre_dominio = re.sub(r"\s+", "", nombre_dominio)
print('Eliminar todos los espacios usando RegEx:\n')
df['Marca/Sin marca'] = np.where(
df['consulta'].str.contains(nombre_dominio), 'Marca', 'Sin marca'
)
Vamos a agregar una nueva columna a nuestro conjunto de datos para reconocer la diferencia entre las dos clases. Podemos visualizar a través de tablas o diagramas de barras cuánto representan el número total de consultas.
No les mostraré el diagrama de barras ya que es muy simple y creo que una tabla es mejor para este caso.
brand_count_df = df['Marca/Sin marca'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Porcentaje'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.formato
brand_count_df
Puede ver rápidamente cuál es la proporción entre las palabras clave de marca y sin marca para tener una idea de cuánto va a eliminar de su conjunto de datos. No existe una proporción ideal aquí, aunque definitivamente desea tener un porcentaje más alto de palabras clave sin marca.
Luego, podemos soltar todas las filas marcadas como marcadas y continuar con otros pasos.
#solo seleccione palabras clave sin marca df = df.loc[df['Marca/Sin marca'] == 'Sin marca']
Rellenar valores faltantes y otros pasos
Si su conjunto de datos presenta valores faltantes (o NA en la jerga), tiene varias opciones. Los más comunes son descartarlos todos o llenarlos con un valor de marcador de posición como 0 o la media de esa columna.
No hay una respuesta correcta y ambos enfoques tienen sus pros y sus contras, así como sus riesgos. Para los datos de Google Search Console, mi mejor consejo es poner un valor de marcador de posición como 0, para subestimar el efecto de algunas métricas.
df.fillna(0, en el lugar = Verdadero)
Antes de pasar al análisis de datos real, debemos ajustar nuestras características, es decir, las columnas de nuestro conjunto de datos. La posición es especialmente interesante, ya que queremos usarla para algunas tablas dinámicas geniales.
Podemos redondear la posición para que sea un número entero, lo que sirve para nuestro propósito.
df['posición'] = df['posición'].round(0).astype('int64')
Debe seguir todos los demás pasos de limpieza descritos anteriormente y luego ajustar la columna de fecha.
Estamos extrayendo meses y años con la ayuda de pandas. No necesita ser tan específico si trabaja con un marco de tiempo más corto, este es un ejemplo que tiene en cuenta medio año.
#convertir la fecha al formato adecuado df['fecha'] = pd.to_datetime(df['fecha']) #extraer meses df['mes'] = df['fecha'].dt.mes #extraer años df['año'] = df['fecha'].dt.año
[Ebook] SEO de datos: la próxima gran aventura
 Leer el libro electrónico
Leer el libro electrónicoAnálisis exploratorio de datos
La principal ventaja de Python es que puedes hacer las mismas cosas que haces en Excel pero con muchas más opciones y más fácil. Comencemos con algo que todo analista conoce muy bien: las tablas dinámicas.
Analizando el CTR promedio por grupo de posiciones
Analizando promedio El CTR por grupo de posición es una de las actividades más perspicaces, ya que le permite comprender la situación general de un sitio web. Aplique el pivote y luego grafiquémoslo.
pd.options.display.float_format = '{:.2%}'.formato
query_analysis = df.pivot_table(index=['posición'], valores=['ctr'], aggfunc=['media'])
query_analysis.sort_values(by=['position'], ascendente=True).head(10)
hacha = query_analysis.head(10).plot(tipo='barra')
ax.set_xlabel('Posición media')
ax.set_ylabel('CTR')
ax.set_title('CTR por posición promedio')
ax.grid('on')
hacha.get_legend().remove()
plt.xticks(rotación=0)
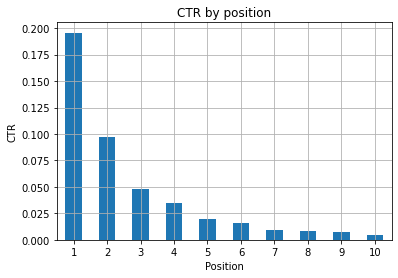
Figura 1: Representación de CTR por posición para detectar anomalías.
El escenario ideal aquí es tener un mejor CTR en el lado izquierdo del gráfico, ya que normalmente los resultados en la Posición 1 deberían presentar un CTR mucho más alto. Sin embargo, tenga cuidado, puede ver algunos casos en los que los primeros 3 lugares tienen un CTR más bajo de lo esperado, y debe investigar.
Considere también los casos extremos, por ejemplo, aquellos en los que la posición 11 es mejor que ser el primero. Como se explica en la documentación de Google para Search Console, esta métrica no sigue el orden que podrías pensar al principio.
Además, agrega que esta métrica es un promedio, ya que la posición del enlace cambia cada vez y es imposible tener una precisión del 100%.
A veces, sus páginas tienen una clasificación alta pero no son lo suficientemente convincentes, por lo que podría intentar corregir el título. Dado que esta es una descripción general de alto nivel, no verá diferencias granulares, así que espere actuar rápido si este problema es a gran escala.
Tenga en cuenta también cuándo un grupo de páginas en posiciones más bajas tiene un CTR promedio más alto que aquellos en mejores lugares.
Por esta razón, es posible que desee ampliar su análisis hasta la posición 15 o más, para detectar patrones extraños.
Recuento de consultas por posición y medición de los esfuerzos de SEO
Un aumento en las consultas para las que está clasificando siempre es una buena señal, pero no necesariamente significa mejores clasificaciones en el futuro. El recuento de consultas es el proceso de contar la cantidad de consultas para las que está clasificando y es una de las tareas más importantes que puede realizar con los datos de GSC.
Las tablas dinámicas son de gran ayuda una vez más, y podemos trazar los resultados.
ranking_consultas = df.pivot_table(index=['posición'], valores=['consulta'], aggfunc=['contar']) ranking_queries.sort_values(by=['position']).head(10)
Lo que desea como especialista en SEO es tener un mayor número de consultas en el lado izquierdo, los primeros lugares. La razón es bastante natural, las posiciones altas obtienen un mejor CTR en promedio, lo que puede traducirse en que más personas hagan clic en su página.
hacha = ranking_consultas.head(10).plot(tipo='barra')
ax.set_ylabel('Recuento de consultas')
ax.set_xlabel('Posición')
ax.set_title('Distribución de clasificación')
ax.grid('on')
hacha.get_legend().remove()
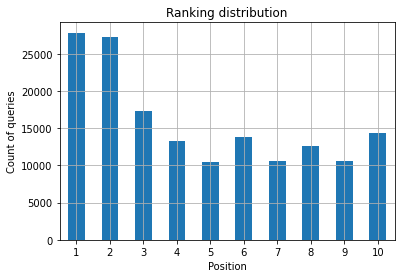
Figura 2: ¿Cuántas consultas tengo por puesto?
Lo que le importa es aumentar el número de consultas en las primeras posiciones a medida que pasa el tiempo.
Jugando con la dimensión de la fecha
Veamos cómo varían los clics en un intervalo de tiempo considerado, obtengamos primero la suma de los clics:
clicks_sum = df.groupby('fecha')['clics'].sum()
Estamos agrupando datos por la dimensión de fecha y obteniendo la suma de clics para cada uno de ellos, es un tipo de resumen.
Ahora estamos listos para trazar lo que obtuvimos, el código será bastante largo solo para mejorar la visualización, no se asuste por eso.

# Suma de clics a lo largo del período
%config InlineBackend.figure_format = 'retina'
de la figura de importación matplotlib.pyplot
figura (tamaño de figura = (8, 6), ppp = 80)
hacha = clicks_sum.plot(color='red')
ax.grid('on')
ax.set_ylabel('Suma de clics')
ax.set_xlabel('Mes')
ax.set_title('Cómo variaban los clics mensualmente')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('cursiva')
xlab.set_size(10)
ylab.set_style('cursiva')
ylab.set_size(10)
ttl = hacha.título
ttl.set_weight('negrita')
hacha.espinas['derecha'].set_color((.8,.8,.8))
hacha.espinas['superior'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_ between(clicks_sum.index, clicks_sum.values, facecolor='amarillo')
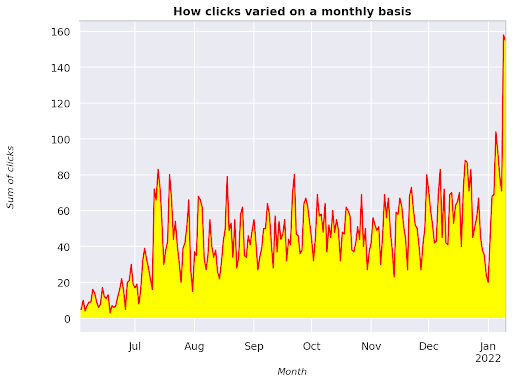
Figura 3: Trazado de la suma de clics en relación con la variable mes
Este es un ejemplo que comienza en junio de 2021 y va directamente a la mitad de enero de 2022. Todas las líneas que ve arriba tienen la función de hacer que esta visualización sea más bonita, puede intentar jugar con ella para ver qué sucede.
Recuento de consultas por posición, instantánea mensual
Otra visualización genial que podemos trazar en Python es el mapa de calor, que es incluso más visual que un simple diagrama de barras. Le mostraré cómo mostrar el número de consultas a lo largo del tiempo y según su posición.
importar seaborn como sns sns.set_tema() df_nuevo = df.loc[(df['posición'] <= 10) & (df['año'] != 2022),:] # Cargue el conjunto de datos de vuelos de ejemplo y conviértalo a formato largo df_heat = df_new.pivot_table(índice = "posición", columnas = "mes", valores = "consulta", aggfunc='recuento') # Dibuja un mapa de calor con los valores numéricos en cada celda f, hacha = plt.subparcelas (tamaño de figura = (20, 12)) x_axis_labels = ["Septiembre", "Octubre", "Noviembre", "Diciembre"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Mes', ylabel='Posición', title = 'Cómo cambia el recuento de consultas por posición con el tiempo') #rotate Etiquetas de posición para que sean más legibles plt.yticks(rotación=0)
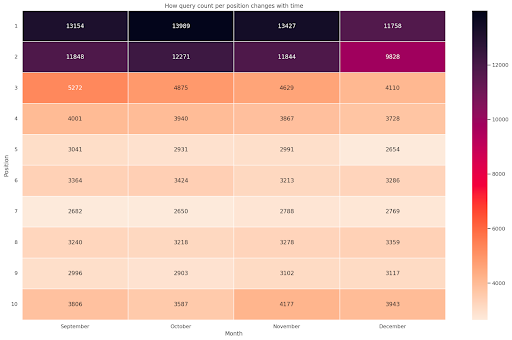
Figura 4: Mapa de calor que muestra el progreso del conteo de consultas según la posición y el mes.
Este es uno de mis favoritos, los mapas de calor pueden ser bastante efectivos para mostrar tablas dinámicas, como en este ejemplo. El período abarca más de 4 meses y, si lo lee horizontalmente, puede ver cómo cambia el recuento de consultas a medida que pasa el tiempo. Para la posición 10, tiene un pequeño aumento de septiembre a diciembre, pero para la posición 2 tiene una disminución sorprendente, como lo muestra el color púrpura.
En el siguiente escenario, tiene la mayoría de las consultas en los primeros lugares, lo que puede ser sorprendentemente inusual. Si eso sucede, es posible que desee volver y analizar el marco de datos, en busca de posibles términos de marca, si los hay.
Como puede ver en el código, no es tan difícil hacer tramas complejas, siempre y cuando entienda la lógica detrás.
El recuento de consultas debería aumentar con el tiempo si está haciendo las cosas "correctas" y podemos trazar la diferencia en dos marcos de tiempo diferentes. En el ejemplo que proporcioné, claramente no es el caso, ya que, especialmente para las posiciones superiores, donde se supone que debe tener un CTR más alto.
Introducción a algunos conceptos básicos de PNL
El procesamiento del lenguaje natural (NLP) es una bendición para el SEO y no es necesario ser un experto para aplicar los algoritmos básicos. Los N-gramas son una de las ideas más poderosas pero simples que pueden brindarle información con los datos de GSC.
Los N-gramas son secuencias contiguas de letras, sílabas o palabras. Para nuestro análisis las palabras serán la unidad de medida. Un n-grama se denomina bigrama cuando los elementos adyacentes son dos (un par) y trigrama si son tres, y así sucesivamente. Le sugiero que pruebe con diferentes combinaciones y que suba a 5 gramos como máximo.
De esta manera, puede detectar las oraciones más comunes en las páginas de sus competidores o evaluar las suyas propias. Dado que Google puede depender de la indexación basada en frases, es mejor optimizar para oraciones en lugar de palabras clave individuales, como lo muestran las patentes de Google relacionadas con este tema.
Como se indica en la página anterior por el mismo Bill Slawski, el valor de comprender los términos relacionados es de gran valor para la optimización y para sus usuarios.
La biblioteca nltk es muy famosa por las aplicaciones de PNL y nos brinda la posibilidad de eliminar palabras vacías en un idioma determinado, como el inglés. Piense en ellos como ruido que desea eliminar, de hecho, los artículos y las palabras muy frecuentes no agregan ningún valor en la comprensión de un texto.
importar nltk
nltk.download('palabras vacías')
de nltk.corpus importar palabras vacías
stoplist = stopwords.words('english')
de sklearn.feature_extraction.text import CountVectorizer
c_vec = CountVectorizer(stop_words=lista de parada, ngram_range=(2,3))
# matriz de ngramas
ngramas = c_vec.fit_transform(df['consulta'])
# frecuencia de conteo de ngramas
contar_valores = ngramas.toarray().sum(eje=0)
# lista de ngramas
vocabulario = c_vec.vocabulario_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columnas={0: 'frecuencia', 1:'bigrama/trigrama'})
df_ngram.head(20).estilo.background_gradient()
Tomamos la columna de consulta y contamos la frecuencia de bigramas para crear un marco de datos que almacene bigramas y su número de ocurrencias.
Este paso es realmente muy importante para analizar también los sitios web de los competidores. Simplemente puede raspar su texto y verificar cuáles son los n-gramas más comunes, ajustando la n cada vez para ver si detecta diferentes patrones en las páginas de alto rango.
Si lo piensa por un segundo, tiene mucho más sentido, ya que una palabra clave individual no le dice nada sobre el contexto.
Frutas maduras
Una de las cosas más bonitas que puedes hacer es comprobar las frutas maduras, esas páginas que puedes mejorar fácilmente para ver buenos resultados lo antes posible. Esto es crucial en los primeros pasos de cada proyecto de SEO para convencer a las partes interesadas. Por lo tanto, si existe la oportunidad de aprovechar dichas páginas, ¡simplemente hágalo!
Nuestros criterios para considerar una página como tal son cuantiles de impresiones y CTR. En otras palabras, estamos filtrando las filas que se ubican en el 80 % superior de las impresiones, pero que se encuentran en el 20 % que recibe el CTR más bajo. Estas filas tendrán un CTR peor que el 80% del resto.
top_impresiones = df[df['impresiones'] >= df['impresiones'].quantile(0.8)]
(impresiones_principales[impresiones_principales['ctr'] <= impresiones_principales['ctr'].quantile(0.2)].sort_values('impresiones', ascendente = False))
Ahora tienes una lista con todas las oportunidades ordenadas por Impresiones, en orden descendente.
Puedes pensar en otros criterios para definir qué es una fruta madura, según las necesidades de tu sitio web y su tamaño.
Para sitios web más pequeños, puede considerar buscar porcentajes más altos, mientras que en sitios web grandes ya debería obtener mucha información con los criterios que estoy usando.
[Ebook] SEO técnico para pensadores no técnicos
 Leer el libro electrónico
Leer el libro electrónicoIntroducción a querycat: clasificación y asociaciones
Querycat es una biblioteca simple pero poderosa que presenta minería de reglas de asociación para agrupar palabras clave y mucho más. Solo te mostraré las asociaciones ya que son más valiosas en este tipo de análisis.
Puede obtener más información sobre esta increíble biblioteca echando un vistazo al repositorio de GitHub de querycat.
Breve introducción sobre el aprendizaje de reglas de asociación
El aprendizaje de reglas de asociación es un método para encontrar reglas que definen asociaciones y co-ocurrencias entre conjuntos de elementos. Esto es ligeramente diferente de otro método de aprendizaje automático no supervisado, el llamado agrupamiento.
Sin embargo, el objetivo final es el mismo: obtener grupos de palabras clave para comprender el rendimiento de nuestro sitio web para algunos temas.
Querycat te da la posibilidad de elegir entre dos algoritmos: Apriori y FP-Growth. Vamos a elegir este último para obtener mejores resultados, por lo que puede ignorar el primero.
FP-Growth es una versión mejorada de Apriori para encontrar patrones frecuentes en conjuntos de datos. El aprendizaje de reglas de asociación también es muy útil para las transacciones de comercio electrónico, por ejemplo, puede estar interesado en comprender qué compran las personas juntas.
En este caso, nuestro enfoque está en las consultas, pero la otra aplicación que mencioné puede ser otra idea útil para los datos de Google Analytics.
Explicar estos algoritmos desde la perspectiva de la estructura de datos es bastante desafiante y, en mi opinión, no es necesario para sus tareas de SEO. Solo explicaré algunos conceptos básicos para entender lo que significan los parámetros.
Los 3 elementos principales de los 2 algoritmos son:
- Soporte: expresa la popularidad de un artículo o un conjunto de artículos. En términos técnicos, es el número de transacciones donde la consulta X y la consulta Y aparecen juntas dividido por el número total de transacciones.
Además, se puede utilizar como umbral para eliminar elementos poco frecuentes. Muy útil para aumentar la significancia estadística y el rendimiento. Establecer un buen soporte mínimo es muy bueno. - Confianza: puede pensar en ella como la probabilidad de co-ocurrencia de los términos.
- Elevación: la relación entre el soporte para (término 1 y término 2) y el soporte del término 1. Podemos ver su valor para obtener información sobre la relación entre los términos. Si es mayor que 1, los términos están correlacionados; si es menor que 1, es poco probable que los términos tengan una asociación: si lift es exactamente 1 (o cercano), no existe una relación significativa.
Se proporcionan más detalles en este artículo sobre querycat escrito por el autor de la biblioteca.
Ahora estamos listos para pasar a la parte práctica.
importar querycat
query_cat = querycat.Categorize(df, 'consulta', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascendente=False)
#crear grupo para filtrar categorías con menos de 15 clics (número arbitrario)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
grupo de filtros
#aplicar filtro
df = df.merge(filtergroup, on=['category','category'], how='inner')
Hemos filtrado categorías menos frecuentes en el proceso, elegí 15 como punto de referencia en mi caso. Es solo un número arbitrario, no hay criterio detrás de él.
Revisemos nuestras categorías con el siguiente fragmento:
df['categoría'].value_counts()
¿Qué pasa con las 10 categorías con más clics? Veamos cuántas consultas tenemos para cada uno de ellos.
df.groupby('categoría').sum()['clics'].sort_values(ascending=False).head(10)
El número a elegir es arbitrario, asegúrese de elegir uno que filtre un buen porcentaje de grupos. Una posible idea es obtener la mediana de las impresiones y dejar caer el 50 % más bajo, siempre que desee excluir grupos pequeños.
Obtención de clústeres y qué hacer con la salida
Mi recomendación es exportar su nuevo marco de datos para evitar ejecutar FP-Growth nuevamente, hágalo para ahorrar tiempo útil.
Tan pronto como tenga grupos, querrá saber los clics y las impresiones de cada uno de ellos para evaluar qué áreas necesitan más mejoras.
grouped_df = df.groupby('categoría')[['clics', 'impresiones']].agg('suma')
Con un poco de manipulación de datos, podemos mejorar los resultados de nuestra asociación y tener clics e impresiones para cada grupo.
group_ex = df.groupby(['categoría'])['consulta'].apply(' | '.join).reset_index()
#eliminar consultas duplicadas y luego ordenarlas alfabéticamente
group_ex['consulta'] = group_ex['consulta'].apply(lambda x: ' | '.join(ordenado(lista(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['categoría', 'categoría'], how='inner')
df_final.cabeza()
Ahora tiene un archivo CSV con todos sus grupos de palabras clave junto con los clics y las impresiones.
#guarde el archivo csv y descárguelo a su máquina local. Si usa Safari, considere cambiar a Chrome para descargar estos archivos, ya que es posible que no funcione.
df_final.to_csv('clusters_queries.csv')
archivos.download('clusters_queries.csv')
En realidad, hay mejores métodos para agrupar, este es solo un ejemplo de cómo puede usar querycat para realizar múltiples tareas para un uso inmediato. El objetivo principal aquí es obtener la mayor cantidad de información posible, especialmente para los sitios web nuevos en los que no tiene tanto conocimiento.
En este momento, los mejores enfoques involucran la semántica, por lo que si desea concentrarse en la agrupación, le sugiero que considere aprender gráficos o incrustaciones.
Sin embargo, estos son temas avanzados si es un novato y simplemente puede probar algunas aplicaciones Streamlit preconstruidas disponibles en línea.
Datos de seguimiento³
 Aprende más
Aprende másConclusión y lo que sigue
Python puede ofrecer una gran ayuda para analizar su sitio web y puede ayudarlo a combinar la limpieza, la visualización y el análisis de datos en un solo lugar. La extracción de datos de la API de GSC es definitivamente necesaria para tareas más avanzadas y es una introducción "suave" a la automatización de datos.
Si bien puedes hacer muchos cálculos más avanzados con Python, mi recomendación es verificar qué tiene sentido en términos de valor de SEO.
Por ejemplo, el Recuento de consultas es mucho más importante en su conjunto a largo plazo, ya que desea que su sitio web sea considerado para más consultas.
El uso de cuadernos es de gran ayuda para empaquetar código con comentarios y esta es la razón principal por la que te sugiero que te acostumbres a Google Colab.
Esto es solo el comienzo de lo que el análisis de datos puede ofrecerle, ya que las mejores ideas surgen de la fusión de diferentes conjuntos de datos.
Google Search Console es per se una herramienta poderosa y es totalmente gratis, la cantidad de información práctica que puede obtener es casi ilimitada en las buenas manos.