
¿Qué es una curva CTR y cómo calcularla con Python?
Publicado: 2022-03-22La curva CTR, o en otras palabras, la tasa de clics orgánicos basada en la posición, son datos que le muestran cuántos enlaces azules en una página de resultados del motor de búsqueda (SERP) obtienen CTR en función de su posición. Por ejemplo, la mayoría de las veces, el primer enlace azul en SERP obtiene la mayor CTR.
Al final de este tutorial, podrá calcular la curva de CTR de su sitio en función de sus directorios o calcular el CTR orgánico en función de las consultas de CTR. El resultado de mi código Python es un diagrama de caja y barra perspicaz que describe la curva CTR del sitio.
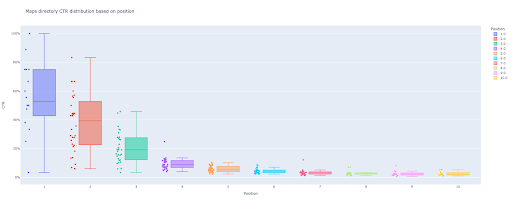
Si eres un principiante y no conoces la definición de CTR, te la explicaré más en la siguiente sección.
¿Qué es el CTR orgánico o la tasa de clics orgánicos?
El CTR proviene de dividir los clics orgánicos en impresiones. Por ejemplo, si 100 personas buscan "manzana" y 30 personas hacen clic en el primer resultado, el CTR del primer resultado es 30/100 * 100 = 30%.
Esto significa que de cada 100 búsquedas obtienes el 30% de ellas. Es importante recordar que las impresiones en Google Search Console (GSC) no se basan en la apariencia del enlace de su sitio web en la ventana de búsqueda. Si el resultado aparece en la SERP del buscador, obtienes una impresión por cada una de las búsquedas.
¿Cuáles son los usos de la curva CTR?
Uno de los temas importantes en SEO son las predicciones de tráfico orgánico. Para mejorar las clasificaciones en algún conjunto de palabras clave, debemos asignar miles y miles de dólares para obtener más acciones. Pero la pregunta a nivel de marketing de una empresa suele ser: "¿Es rentable para nosotros asignar este presupuesto?".
Además, además del tema de las asignaciones de presupuesto para proyectos de SEO, necesitamos obtener una estimación del aumento o disminución de nuestro tráfico orgánico en el futuro. Por ejemplo, si vemos que uno de nuestros competidores se esfuerza por reemplazarnos en nuestra posición en el ranking SERP, ¿cuánto nos costará?
En esta situación o en muchos otros escenarios, necesitamos la curva CTR de nuestro sitio.
¿Por qué no usamos estudios de curvas CTR y usamos nuestros datos?
En respuesta simple, no hay ningún otro sitio web que tenga las características de su sitio en SERP.
Hay mucha investigación sobre las curvas de CTR en diferentes industrias y diferentes características de SERP, pero cuando tiene sus datos, ¿por qué sus sitios no calculan el CTR en lugar de confiar en fuentes de terceros?
Vamos a empezar a hacer esto.
Cálculo de la curva CTR con Python: Primeros pasos
Antes de sumergirnos en el proceso de cálculo de la tasa de clics de Google en función de la posición, debe conocer la sintaxis básica de Python y tener una comprensión básica de las bibliotecas comunes de Python, como Pandas. Esto te ayudará a comprender mejor el código y personalizarlo a tu manera.
Además, para este proceso, prefiero usar un cuaderno Jupyter.
Para calcular el CTR orgánico según la posición, necesitamos usar estas bibliotecas de Python:
- pandas
- trama
- calido
Además, usaremos estas bibliotecas estándar de Python:
- sistema operativo
- json
Como dije, exploraremos dos formas diferentes de calcular la curva CTR. Algunos pasos son los mismos en ambos métodos: importar los paquetes de Python, crear una carpeta de salida de imágenes de trazado y configurar los tamaños de trazado de salida.
# Importación de bibliotecas necesarias para nuestro proceso importar sistema operativo importar json importar pandas como pd importar plotly.express como px importar plotly.io como pio importar kaleido
Aquí creamos una carpeta de salida para guardar nuestras imágenes de trazado.
# Creación de carpeta de salida de imágenes de trazado
si no os.path.exists ('./imágenes de trazado de salida'):
os.mkdir('./imágenes gráficas de salida')
Puede cambiar la altura y el ancho de las imágenes de trazado de salida a continuación.
# Establecer el ancho y la altura de las imágenes de la trama de salida pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Comencemos con el primer método que se basa en consultas CTR.
Primer método: calcule la curva CTR para un sitio web completo o una propiedad de URL específica basada en consultas CTR
En primer lugar, necesitamos obtener todas nuestras consultas con su CTR, posición promedio e impresión. Prefiero usar un mes completo de datos del último mes.
Para hacer esto, obtengo datos de consultas de la fuente de datos de impresión del sitio GSC en Google Data Studio. Alternativamente, puede adquirir estos datos de la forma que prefiera, como la API de GSC o el complemento de Google Sheets "Search Analytics for Sheets", por ejemplo. De esta forma, si su blog o páginas de productos tienen una propiedad de URL dedicada, puede usarlas como fuente de datos en GDS.
1. Obtener datos de consultas de Google Data Studio (GDS)
Para hacer esto:
- Cree un informe y agréguele un gráfico de tabla
- Agregue la fuente de datos "Impresión del sitio" de su sitio al informe
- Elija "consulta" para la dimensión, así como "ctr", "posición promedio" e "'impresión" para la métrica
- Filtre las consultas que contengan el nombre de la marca creando un filtro (las consultas que contengan marcas tendrán una tasa de clics más alta, lo que disminuirá la precisión de nuestros datos)
- Haga clic derecho en la tabla y haga clic en Exportar
- Guarde la salida como CSV
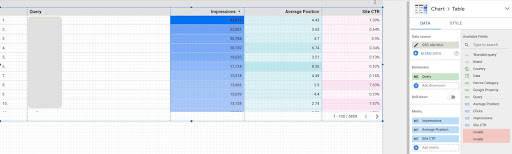
2. Cargar nuestros datos y etiquetar las consultas en función de su posición
Para manipular el CSV descargado, usaremos Pandas.
La mejor práctica para la estructura de carpetas de nuestro proyecto es tener una carpeta de 'datos' en la que guardamos todos nuestros datos.
Aquí, por el bien de la fluidez en el tutorial, no hice esto.
consulta_df = pd.read_csv('./downloaded_data.csv')
Luego etiquetamos nuestras consultas según su posición. Creé un ciclo 'for' para etiquetar las posiciones 1 a 10.
Por ejemplo, si la posición promedio de una consulta es 2.2 o 2.9, se etiquetará como "2". Al manipular el rango de posición promedio, puede lograr la precisión que desea.
para i en el rango (1, 11):
query_df.loc[(query_df['Posición promedio'] >= i) & (
query_df['Posición promedio'] < i + 1), 'etiqueta de posición'] = i
Ahora, agruparemos las consultas según su posición. Esto nos ayuda a manipular mejor los datos de cada consulta de posición en los siguientes pasos.
query_grouped_df = query_df.groupby(['etiqueta de posición'])
3. Filtrado de consultas en función de sus datos para el cálculo de la curva CTR
La forma más sencilla de calcular la curva CTR es utilizar todos los datos de las consultas y realizar el cálculo. Sin embargo; no olvide pensar en aquellas consultas con una impresión en la posición dos en sus datos.
Estas consultas, según mi experiencia, marcan una gran diferencia en el resultado final. Pero la mejor manera es probarlo usted mismo. Según el conjunto de datos, esto puede cambiar.
Antes de comenzar este paso, debemos crear una lista para la salida de nuestro gráfico de barras y un marco de datos para almacenar nuestras consultas manipuladas.
# Creando un DataFrame para almacenar datos manipulados 'query_df' df_modificado = pd.DataFrame() # Una lista para guardar la media de cada posición para nuestro gráfico de barras lista_ctr_media = []
Luego, recorremos los grupos query_grouped_df y agregamos el 20 % de las principales consultas en función de las impresiones al marco de datos modified_df .
Si calcular el CTR solo en función del 20% superior de las consultas que tienen la mayor cantidad de impresiones no es lo mejor para usted, puede cambiarlo.
Para hacerlo, puede aumentarlo o disminuirlo manipulando .quantile(q=your_optimal_number, interpolation='lower')] y your_optimal_number debe estar entre 0 y 1.
Por ejemplo, si desea obtener el 30% superior de sus consultas, your_optimal_num es la diferencia entre 1 y 0.3 (0.7).
para i en el rango (1, 11):
# Un intento, excepto para manejar aquellas situaciones en las que un directorio no tiene datos para algunas posiciones
probar:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impresiones'] >= query_grouped_df.get_group(i)['impresiones']
.quantile(q=0.8, interpolación='inferior')]
mean_ctr_list.append(tmp_df['ctr'].mean())
df_modificado = df_modificado.append(tmp_df, ignore_index=True)
excepto KeyError:
mean_ctr_list.append(0)
# Eliminar el marco de datos 'tmp_df' para reducir el uso de memoria
del [tmp_df]
4. Dibujar un diagrama de caja
Este paso es lo que hemos estado esperando. Para dibujar gráficos, podemos usar Matplotlib, seaborn como envoltorio para Matplotlib o Plotly.
Personalmente, creo que usar Plotly es una de las mejores opciones para los especialistas en marketing a los que les encanta explorar datos.
En comparación con Mathplotlib, Plotly es muy fácil de usar y con solo unas pocas líneas de código, puede dibujar un gráfico hermoso.
# 1. El diagrama de caja
box_fig = px.box(modified_df, x='etiqueta de posición', y='CTR del sitio', title='Consulta la distribución del CTR según la posición',
puntos = 'todos', color = 'etiqueta de posición', etiquetas = {'etiqueta de posición': 'Posición', 'CTR del sitio': 'CTR'})
# Mostrando los diez ticks de los ejes x
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Cambiar el formato de marca del eje y a porcentaje
box_fig.update_yaxes(tickformat=".0%")
# Guardando el gráfico en el directorio 'imágenes del gráfico de salida'
box_fig.write_image('./imágenes de gráfico de salida/gráfico de cuadro de consultas CTR curve.png')
Con solo estas cuatro líneas, puede obtener un hermoso diagrama de caja y comenzar a explorar sus datos.
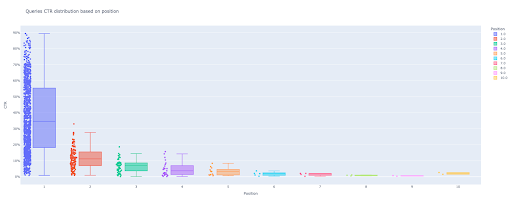
Si desea interactuar con esta columna, en una nueva celda ejecute:
box_fig.mostrar()
Ahora, tiene un diagrama de caja atractivo en la salida que es interactivo.
Cuando pasa el cursor sobre un gráfico interactivo en la celda de salida, el número importante que le interesa es el "hombre" de cada posición.
Esto muestra el CTR medio para cada posición. Debido a la importancia de la media, como recordarás, creamos una lista que contiene la media de cada posición. A continuación, pasaremos al siguiente paso para dibujar un gráfico de barras basado en la media de cada posición.
5. Dibujar un gráfico de barras
Al igual que un diagrama de caja, dibujar el diagrama de barras es muy fácil. Puede cambiar el title de los gráficos modificando el argumento de title de px.bar() .
# 2. El gráfico de barras
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='Consulta la distribución media de CTR basada en la posición',
etiquetas={'x': 'Posición', 'y': 'CTR'}, text_auto=True)
# Mostrando los diez ticks de los ejes x
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Cambiar el formato de marca del eje y a porcentaje
bar_fig.update_yaxes(tickformat='.0%')
# Guardando el gráfico en el directorio 'imágenes del gráfico de salida'
bar_fig.write_image('./imágenes de gráficos de salida/gráfico de barra de consultas CTR curve.png')
En la salida, obtenemos este gráfico:
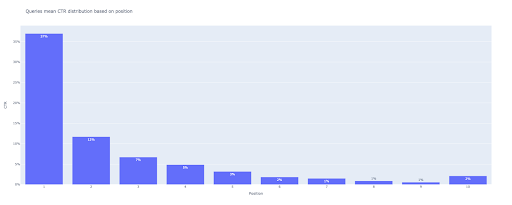
Al igual que con el gráfico de caja, puede interactuar con este gráfico ejecutando bar_fig.show() .
¡Eso es todo! Con unas pocas líneas de código, obtenemos la tasa de clics orgánica basada en la posición con los datos de nuestras consultas.
Si tiene una propiedad de URL para cada uno de sus subdominios o directorios, puede obtener estas consultas de propiedades de URL y calcular la curva CTR para ellas.
[Estudio de caso] Mejora de clasificaciones, visitas orgánicas y ventas con análisis de archivos de registro
 Lea el estudio de caso
Lea el estudio de casoSegundo método: calcular la curva de CTR en función de las URL de las páginas de destino de cada directorio
En el primer método, calculamos nuestro CTR orgánico en función del CTR de consultas, pero con este enfoque, obtenemos todos los datos de nuestras páginas de destino y luego calculamos la curva de CTR para nuestros directorios seleccionados.

Me encanta de esta manera. Como sabe, el CTR de nuestras páginas de productos es muy diferente al de nuestras publicaciones de blog u otras páginas. Cada directorio tiene su propio CTR basado en la posición.
De una manera más avanzada, puede categorizar cada página del directorio y obtener la tasa de clics orgánicos de Google en función de la posición de un conjunto de páginas.
1. Obtener datos de las páginas de destino
Al igual que el primer método, hay varias formas de obtener datos de Google Search Console (GSC). En este método, preferí obtener los datos de las páginas de destino del explorador de API de GSC en: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Para lo que se necesita en este enfoque, GDS no proporciona datos sólidos de la página de destino. Además, puede usar el complemento de Google Sheets "Search Analytics for Sheets".
Tenga en cuenta que Google API Explorer es una buena opción para aquellos sitios con menos de 25 000 páginas de datos. Para sitios más grandes, puede obtener datos de páginas de destino parcialmente y concatenarlos juntos, escribir una secuencia de comandos de Python con un bucle 'for' para obtener todos sus datos de GSC o usar herramientas de terceros.
Para obtener datos de Google API Explorer:
- Vaya a la página de documentación de la API de GSC "Search Analytics: consulta": https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Use el Explorador de API que se encuentra en el lado derecho de la página
- En el campo "siteUrl", inserte la dirección de su propiedad URL, como
https://www.example.com. Además, puede insertar la propiedad de su dominio de la siguiente manerasc-domain:example.com - En el campo "cuerpo de la solicitud", agregue
startDateyendDate. Prefiero obtener los datos del mes pasado. El formato de estos valores esYYYY-MM-DD - Agregar
dimensiony establecer sus valores en lapage - Cree un "dimensionFilterGroups" y filtre las consultas con nombres de variación de marca (reemplazando
brand_variation_namescon sus nombres de marca RegExp) - Agregue
rawLimity configúrelo en 25000 - Al final presione el botón 'EJECUTAR'
También puede copiar y pegar el cuerpo de la solicitud a continuación:
{
"fechaInicio": "2022-01-01",
"fechafinalización": "2022-02-01",
"dimensiones": [
"página"
],
"grupos de filtros de dimensiones": [
{
"filtros": [
{
"dimensión": "CONSULTA",
"expresión": "marca_variación_nombres",
"operador": "EXCLUDING_REGEX"
}
]
}
],
"límite de fila": 25000
}
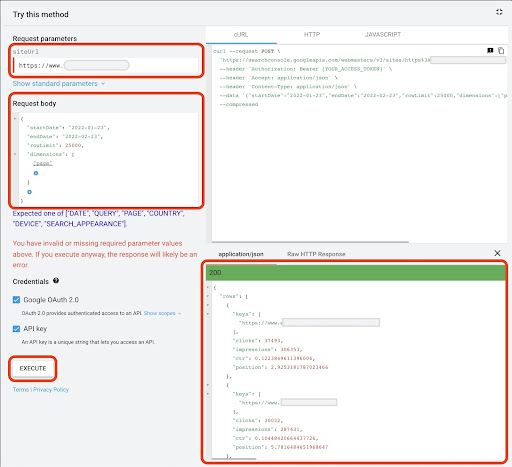
Después de ejecutar la solicitud, debemos guardarla. Debido al formato de respuesta, necesitamos crear un archivo JSON, copiar todas las respuestas JSON y guardarlo con el nombre de archivo downloaded_data.json .
Si su sitio es pequeño, como el sitio de una empresa SASS, y los datos de su página de destino tienen menos de 1000 páginas, puede configurar fácilmente su fecha en GSC y exportar los datos de las páginas de destino para la pestaña "PÁGINAS" como un archivo CSV.
2. Cargando datos de páginas de aterrizaje
Por el bien de este tutorial, supondré que obtiene datos de Google API Explorer y los guarda en un archivo JSON. Para cargar estos datos tenemos que ejecutar el siguiente código:
# Creando un DataFrame para los datos descargados
con open('./downloaded_data.json') como json_file:
landings_data = json.loads(json_file.read())['filas']
landings_df = pd.DataFrame(landings_data)
Además, necesitamos cambiar el nombre de una columna para darle más significado y aplicar una función para obtener las URL de la página de destino directamente en la columna "página de destino".
# Cambiar el nombre de la columna 'claves' a la columna 'página de destino' y convertir la lista de 'página de destino' en una URL
landings_df.rename(columns={'keys': 'landing page'}, inplace=True)
landings_df['página de destino'] = landings_df['página de destino'].apply(lambda x: x[0])
3. Obtener todos los directorios raíz de las páginas de aterrizaje
En primer lugar, necesitamos definir el nombre de nuestro sitio.
# Definición del nombre de su sitio entre comillas. Por ejemplo, 'https://www.ejemplo.com/' o 'http://midominio.com/' nombre_sitio = ''
Luego, ejecutamos una función en las URL de la página de destino para obtener sus directorios raíz y verlos en la salida para elegirlos.
# Obtener el directorio de cada página de destino (URL)
landings_df['directorio'] = landings_df['página de destino'].str.extract(pat=f'((?<={nombre_del_sitio})[^/]+)')
# Para obtener todos los directorios en la salida, necesitamos manipular las opciones de Pandas
pd.set_option("display.max_rows", Ninguno)
# Directorios de sitios web
landings_df['directorio'].value_counts()
Luego, elegimos para qué directorios necesitamos obtener su curva CTR.
Inserte los directorios en la variable important_directories .
Por ejemplo, product,tag,product-category,mag . Separe los valores del directorio con comas.
directorios_importantes = ''
directorios_importantes = directorios_importantes.split(',')
4. Etiquetado y agrupación de páginas de aterrizaje
Al igual que las consultas, también etiquetamos las páginas de destino según su posición promedio.
# Etiquetado de la posición de las páginas de destino
para i en el rango (1, 11):
landings_df.loc[(landings_df['posición'] >= i) & (
landings_df['posición'] < i + 1), 'etiqueta de posición'] = i
Luego, agrupamos las páginas de destino en función de su "directorio".
# Agrupación de páginas de destino en función de su valor de 'directorio' aterrizajes_agrupados_df = aterrizajes_df.groupby(['directorio'])
5. Generación de diagramas de caja y barra para nuestros directorios
En el método anterior, no usamos una función para generar los gráficos. Sin embargo; Para calcular la curva CTR para diferentes páginas de destino automáticamente, necesitamos definir una función.
# La función para crear y guardar cada gráfico de directorio
def each_dir_plot(dir_df, clave):
# Agrupar las páginas de destino del directorio en función de su valor de 'etiqueta de posición'
dir_grouped_df = dir_df.groupby(['etiqueta de posición'])
# Creando un DataFrame para almacenar datos manipulados 'dir_grouped_df'
df_modificado = pd.DataFrame()
# Una lista para guardar la media de cada posición para nuestro gráfico de barras
lista_ctr_media = []
'''
Recorriendo los grupos 'query_grouped_df' y agregando el 20 % de consultas principales basadas en las impresiones al marco de datos 'modified_df'.
Si calcular el CTR solo en función del 20% superior de las consultas que tienen la mayor cantidad de impresiones no es lo mejor para usted, puede cambiarlo.
Para cambiarlo, puede aumentarlo o disminuirlo manipulando '.quantile(q=your_optimal_number, interpolation='lower')]'.
'you_optimal_number' debe estar entre 0 y 1.
Por ejemplo, si desea obtener el 30% superior de sus consultas, 'your_optimal_num' es la diferencia entre 1 y 0.3 (0.7).
'''
para i en el rango (1, 11):
# Un intento, excepto para manejar aquellas situaciones en las que un directorio no tiene datos para algunas posiciones
probar:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impresiones'] >= dir_grouped_df.get_group(i)['impresiones']
.quantile(q=0.8, interpolación='inferior')]
mean_ctr_list.append(tmp_df['ctr'].mean())
df_modificado = df_modificado.append(tmp_df, ignore_index=True)
excepto KeyError:
mean_ctr_list.append(0)
# 1. El diagrama de caja
box_fig = px.box(modified_df, x='etiqueta de posición', y='ctr', title=f'distribución de CTR del directorio {clave} basada en la posición',
puntos='todos', color='etiqueta de posición', etiquetas={'etiqueta de posición': 'Posición', 'ctr': 'CTR'})
# Mostrando los diez ticks de los ejes x
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Cambiar el formato de marca del eje y a porcentaje
box_fig.update_yaxes(tickformat=".0%")
# Guardando el gráfico en el directorio 'imágenes del gráfico de salida'
box_fig.write_image(f'./imágenes de gráfico de salida/directorio {key}-Box plot CTR curve.png')
# 2. El gráfico de barras
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} directorio distribución media de CTR basada en la posición',
etiquetas={'x': 'Posición', 'y': 'CTR'}, text_auto=True)
# Mostrando los diez ticks de los ejes x
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Cambiar el formato de marca del eje y a porcentaje
bar_fig.update_yaxes(tickformat='.0%')
# Guardando el gráfico en el directorio 'imágenes del gráfico de salida'
bar_fig.write_image(f'./imágenes de trazado de salida/directorio {key}-Bar plot CTR curve.png')
Después de definir la función anterior, necesitamos un bucle 'for' para recorrer los datos de los directorios para los que queremos obtener su curva CTR.
# Recorriendo los directorios y ejecutando la función 'each_dir_plot'
para clave, artículo en landings_grouped_df:
si clave en directorios_importantes:
each_dir_plot(elemento, clave)
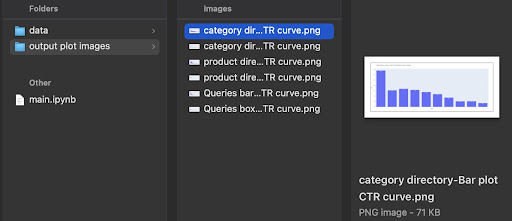
En la salida, obtenemos nuestros gráficos en la carpeta output plot images de gráficos de salida.
¡Consejo avanzado!
También puede calcular las curvas de CTR de los diferentes directorios utilizando la página de inicio de consultas. Con algunos cambios en las funciones, puede agrupar las consultas en función de sus directorios de páginas de destino.
Puede usar el cuerpo de la solicitud a continuación para realizar una solicitud de API en API Explorer (no olvide la limitación de 25000 filas):
{
"fechaInicio": "2022-01-01",
"fechafinalización": "2022-02-01",
"dimensiones": [
"consulta",
"página"
],
"grupos de filtros de dimensiones": [
{
"filtros": [
{
"dimensión": "CONSULTA",
"expresión": "marca_variación_nombres",
"operador": "EXCLUDING_REGEX"
}
]
}
],
"límite de fila": 25000
}
Consejos para personalizar el cálculo de la curva CTR con Python
Para obtener datos más precisos para calcular la curva CTR, necesitamos usar herramientas de terceros.
Por ejemplo, además de saber qué consultas tienen un fragmento destacado, puedes explorar más funciones SERP. Además, si usa herramientas de terceros, puede obtener el par de consultas con el rango de la página de destino para esa consulta, según las características de SERP.
Luego, etiquetar las páginas de destino con su directorio raíz (principal), agrupar las consultas según los valores del directorio, considerar las características de SERP y, finalmente, agrupar las consultas según la posición. Para los datos de CTR, puede fusionar los valores de CTR de GSC con sus consultas de pares.