
Importancia de la red semántica para SEO: creación de redes de contenido semántico con plantillas de consultas y documentos: estudio de caso
Publicado: 2022-01-11Una red semántica está conectada con el concepto de una base de conocimiento que puede representar información del mundo real para cosas que tienen conexiones relacionales. Una base de conocimientos puede tener miles de tipos de relaciones con miles de millones de entidades y billones de hechos. Se puede crear una red semántica a partir de cualquier existencia del mundo real con características comunes como peso, tamaño, tipo, olor o color. La relación entre las Redes Semánticas y la Web Semántica es creada por los motores de búsqueda y optimización semántica.
Las redes semánticas se utilizan en el análisis semántico, la desambiguación del sentido de las palabras, la creación de WordNet, la teoría de grafos, el procesamiento, la comprensión y la generación del lenguaje natural. La perspectiva de una red semántica se puede utilizar dentro de la optimización de motor de búsqueda semántica al proporcionar una red de contenido semántico.
En este estudio de caso de SEO, se explicarán dos sitios web diferentes con dos métodos diferentes con la misma perspectiva en función de las plantillas de Consulta, Documento, Intención y los pares entidad-atributo detrás de ellos.
Al comprender cómo los motores de búsqueda representan el conocimiento y cómo expanden su representación del conocimiento, puedo aprovechar eso para producir resultados de clasificación increíbles. Una vez que comprenda los conceptos básicos, explicaré cómo los apliqué a los dos sitios web diferentes y luego detallaré los métodos que utilicé.
¿Cómo pueden ayudar las Redes Semánticas al Ranking de su Sitio Web?
A continuación, encontrará los resultados brutos generales del Proyecto I.
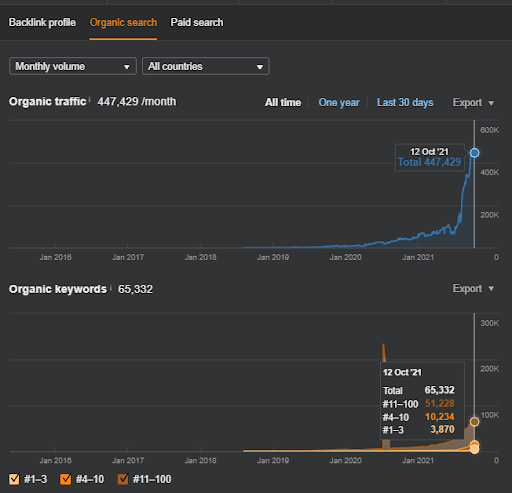
Resultados del Proyecto Uno que es IstanbulBogaziciEnstitu.com. Para demostrar que las "redes semánticas" se pueden usar para SEO con plantillas de consultas y documentos, demostraré dos redes de contenido diferentes del Proyecto Uno. Project One tendrá resultados mucho mejores en un futuro cercano gracias a Semantic Content Network Two. El cliente será responsable del despliegue de esta segunda red, pero también explicaré su lógica.
17 días después, aquí está el progreso realizado en el Proyecto I: 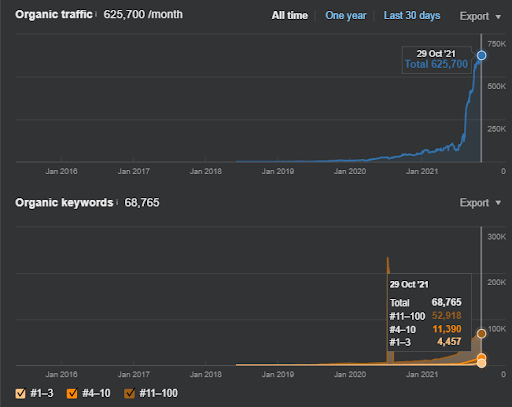
17 días después, el proceso de reclasificación de Semantic Content Network es más claro.
Los conceptos de la red de contenido semántico nos ayudan a comprender el valor de la consulta, la intención de búsqueda, el comportamiento y las plantillas de documentos para entidades del mismo tipo. En este estudio de caso de SEO centrado en la red semántica, se profundizará en el estudio de caso anterior de autoridad tópica y SEO semántico a través de los dos nuevos sitios web que utilizan redes de contenido creadas semánticamente en torno a los mismos tipos de entidades.
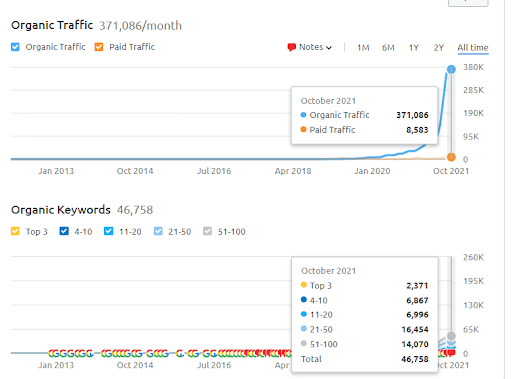
Este es el gráfico de SEMRush del Primer Proyecto. También debo mencionar que este sitio web ha perdido la actualización del algoritmo de núcleo amplio de junio, si no perdiera su "clasificación", los resultados serían mejores. Para la próxima actualización del algoritmo de núcleo amplio, con una mejor autoridad temática, cobertura y datos históricos, puede recuperar la "capacidad de clasificación" fácilmente.
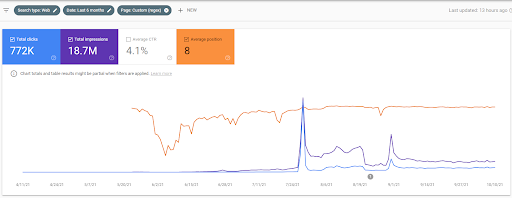
El nombre del Segundo Proyecto es Vizem.net. A diferencia de Project One, puede ver que Vizem.net tiene un aumento más lento pero constante. Es porque utilizan las redes de contenido semántico con perspectivas ligeramente diferentes. A continuación, puedes ver los resultados de Ahrefs del Segundo Proyecto.
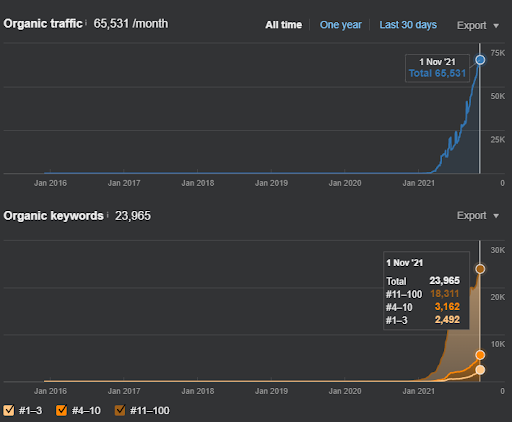
Los resultados del Segundo Proyecto representan un “Proceso de Reordenamiento Lento” al mejorar gradualmente la Cobertura Tópica y la Autoridad. Los términos “Re-ranking” y “Ranking Inicial” se explicarán después de los conceptos relacionados con las Redes de Contenido Semántico. Si te das cuenta de la “estabilidad” dentro de los gráficos es porque he dejado de publicar contenido nuevo en la fuente. Y afecta el proceso de reclasificación como se da cuenta de los recuentos de los 3 principales recuentos de consultas. Las relaciones “Momentum” y “Re-ranking” se encuentran después de las explicaciones de los conceptos fundamentales.
A continuación, puede encontrar los resultados de SEMRush de Vizem.net.
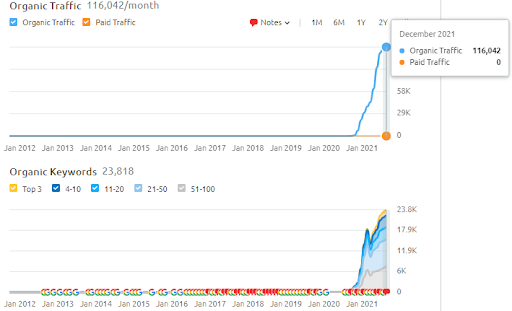
El tráfico real de este sitio web es 3 veces más del número que se indica en SEMRush. También puede darse cuenta de los mismos conceptos de "estabilidad" y "impulso" dentro de estos gráficos.
Mientras escribía el estudio de caso de Topical Authority SEO, agradecí a Bill Slawski por educar mi perspectiva. Lo repito también para el estudio de caso de SEO de la red de contenido semántico. Para comprender los conceptos de "Reclasificación" y "Clasificación inicial", se debe leer "Formas en que los motores de búsqueda pueden reclasificar los resultados de búsqueda".
El 18 de marzo de 2021, Oncrawl, RankSense y Holistic SEO & Digital publicaron un seminario web sobre Python SEO y ciencia de datos. En el seminario web, se ha grabado el SERP para animar las diferencias de resultados. Se puede ver que el motor de búsqueda cambia la clasificación de ciertas fuentes con otras con una frecuencia similar.
Antes de continuar, sé que este es un artículo largo. Pero, en realidad, esta es una breve explicación de una metodología de SEO altamente compleja. Las redes de contenido semántico requieren mucho pensamiento al diseñarlas y meses de educación para clientes, autores y junto con la incorporación. Por lo tanto, en este artículo, quiero centrarme en las definiciones de los conceptos con las mejores breves sugerencias ejecutables posibles e importantes Google, y otras patentes de motores de búsqueda, trabajos de investigación junto con sus propios conceptos. En la versión larga (básicamente, un libro), me he centrado en la “clasificación inicial” y la “reclasificación” de las redes de contenido semántico.
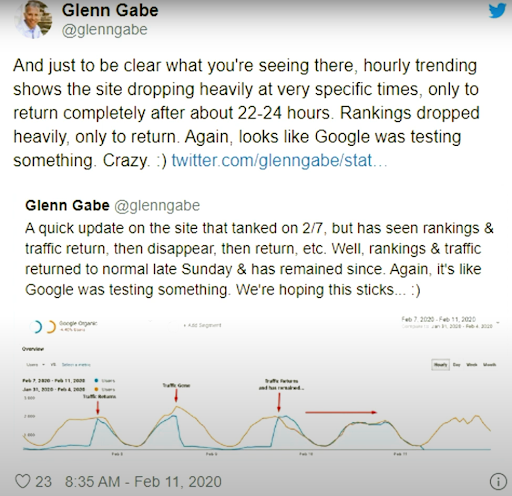
Desde el 11 de febrero de 2020, Glenn Gabe tiene un buen ejemplo para la metodología de reclasificación y prueba de los motores de búsqueda de forma visual.
Si desea obtener más información, lea la "Importancia de la clasificación inicial y la reclasificación para SEO".
Para profundizar en los datos del mundo real para el estudio de caso de SEO, los conceptos para comprender la red de contenido semántico deben procesarse con una perspectiva de comprensión y comunicación del motor de búsqueda.
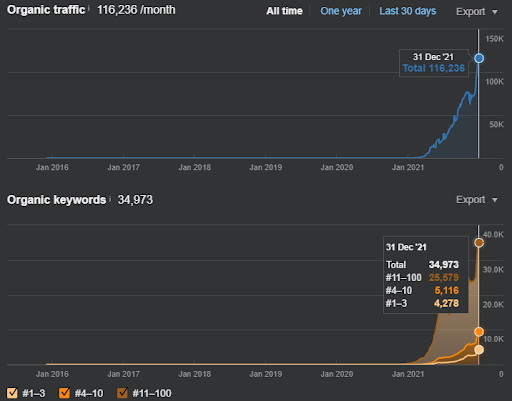
Como ejemplo de reclasificación de Vizem.net, la situación actualizada se puede ver arriba. En las secciones futuras del estudio de caso de SEO, habrá más explicaciones sobre los algoritmos de reposicionamiento de Google para SEO.
¿Qué es una Red Semántica?
Una red semántica se puede utilizar para conectar y analizar Internet de las cosas. Puede ser beneficioso para reconocer a los compradores potenciales en el mercado de la tecnología, o simplemente para el análisis de palabras compartidas para la creación y agrupación de redes de palabras clave. Una red semántica se puede utilizar para apoyar la navegación y revelar la estructura de las relaciones, o la importancia relativa de una cosa con respecto a otra. Semantic Network tiene los siguientes componentes:
- Semántica Léxica: Entender qué palabra y concepto están ligados a qué otros, con qué diferencias.
- Componente estructural: comprensión de qué nodo está conectado a qué borde con qué información.
- Componente Semántico: Definición de los hechos.
- Parte de procedimiento: ayuda a crear más conexiones entre los componentes.
Dado que las redes semánticas tienen múltiples propósitos, los algoritmos de PNL también se pueden usar para propósitos muy diversos, como ayudar a identificar problemas de salud complicados. La misma estructura de red semántica se puede implementar en muchas otras áreas siempre que estas otras áreas tengan una relación semántica entre sí.
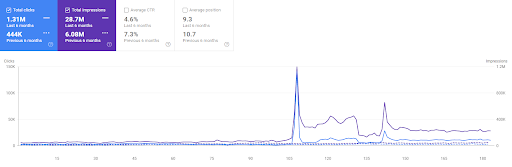
La comparación de los últimos 6 meses del Primer Proyecto.
¿Qué es una base de conocimientos?
Una base de conocimiento es una biblioteca de información con clasificación en una forma legible por máquina. Una base de conocimientos se puede utilizar como una enciclopedia que se puede reducir y profundizar en función de la consulta. Se puede formar una base de conocimiento basada en proposiciones, extracción de hechos y extracción de información. La relación entre una red semántica y una base de conocimiento es que todo lo que está en la red semántica se colocará en la base de conocimiento mientras se extraen los hechos.
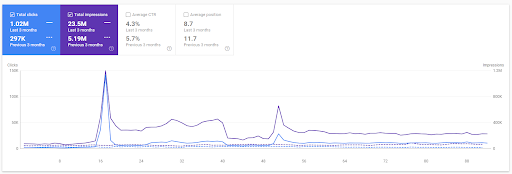
La comparación de los últimos 3 meses del Primer Proyecto
¿Qué es una red de contenido semántico?
Red de contenido semántico representa una red de contenido que se ha preparado en función de los componentes y la comprensión de la red semántica. Una red de contenido semántico puede incluir múltiples atributos de una entidad o entidades del mismo grupo para proporcionar una base de conocimiento con más detalle.
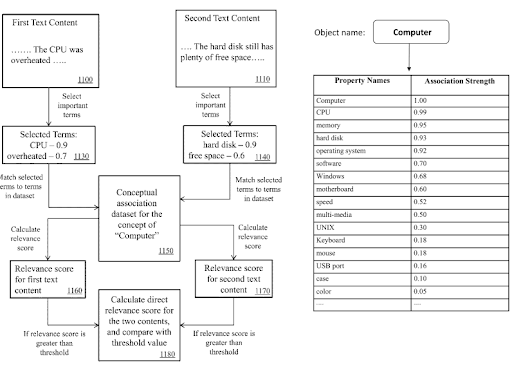
Dentro de una red de contenido semántico, los términos del dominio del conocimiento y los triples se pueden usar para señalar el propósito principal de un documento y las posibles piezas de contenido vecinas.
Un motor de búsqueda puede comparar su propia base de conocimientos con la base de conocimientos que se puede generar a partir del contenido de un sitio web. Si el sitio web tiene un alto nivel de precisión y exhaustividad para diferentes capas contextuales, el motor de búsqueda puede mejorar su propia base de conocimientos a partir del contenido del sitio web. Si un motor de búsqueda mejora y amplía su propia base de conocimiento desde otra fuente en la web abierta, es una señal de una Confianza basada en el conocimiento de alto nivel.
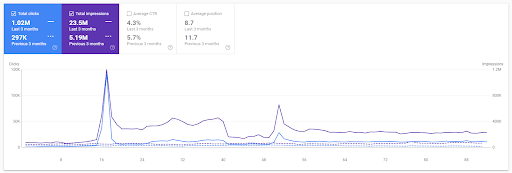
Comparación año tras año de los últimos 3 meses basada en el primer proyecto.
¿Qué es la confianza basada en el conocimiento?
La confianza basada en el conocimiento se centra en la web abierta basada en la "precisión de la información", no en el "PageRank". Es un algoritmo similar al RankMerge. La confianza basada en el conocimiento implica tripletes, extracción de hechos, verificación de precisión y comprensión del texto al eliminar la ambigüedad del texto. La confianza basada en el conocimiento se puede adquirir proporcionando redes de contenido semántico que tengan los componentes fuertemente conectados dentro del artículo, basados en capas contextuales diferentes pero relevantes.
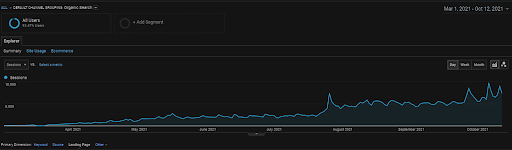
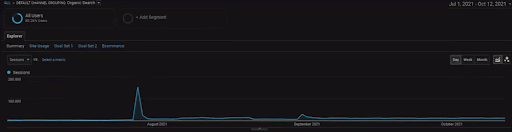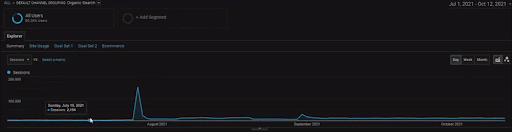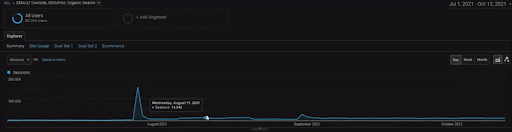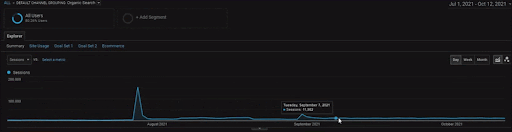
La sesión orgánica de Vizem.net de GA durante los últimos 6 meses.
A continuación, verá un ejemplo de una presentación de Confianza basada en el conocimiento de Luna Dong. Muestra cómo un motor de búsqueda puede centrarse en los "factores de clasificación internos" en lugar de los factores de clasificación exógenos. Explica que un PageRank alto no puede representar una alta calidad y precisión para el contenido por sí mismo. Entonces, tener un KBT (confianza basada en el conocimiento) es importante.
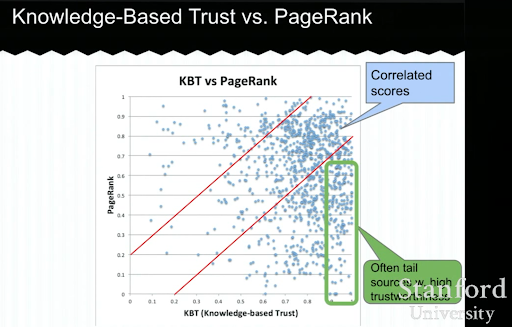
Muchas gracias a Arnout Hellemans que compartió esta conferencia educativa conmigo durante un chat privado de SEO. Si desea obtener más información sobre la confianza basada en el conocimiento: Seminario de Stanford: Bóveda de conocimiento y confianza basada en el conocimiento
¿Qué es la Cobertura Contextual?
La cobertura contextual y la cobertura temática no son lo mismo que el dominio del conocimiento y el dominio contextual no son lo mismo. Una cobertura contextual representa los ángulos de procesamiento de un concepto. Un concepto puede ser procesado en base a sus puntos mutuos con las otras cosas. Por ejemplo, si la entidad es un país, se puede procesar su postura sobre la crisis ambiental. Si otros países se procesan desde el mismo ángulo, significa que estamos cubriendo un dominio contextual.

Google Search Engine construye sus documentos de investigación y patentes a lo largo del tiempo. La cita de la derecha de la sección anterior es un atributo de los "vectores de contexto", mientras que la sección de la izquierda es un atributo de la "taxonomía de frases". Lo interesante es que, hasta el ejemplo es el mismo, que es “cámara digital”.
Los detalles profundizados y las subpartes de estas combinaciones representan las capas contextuales dentro de un dominio contextual. Cada entidad, tenga nombre o no, tiene muchos dominios contextuales. Así, Google extrae más dominios contextuales y los usuarios buscan consultas más largas cada año. Cuando se desarrollan el procesamiento del lenguaje natural y la comprensión del lenguaje natural, las consultas y los documentos se expanden juntos en términos de detalle y contexto.
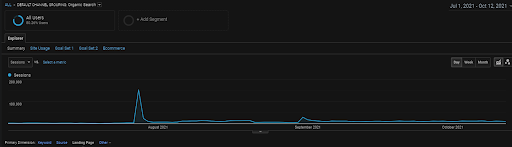
El gráfico de las Sesiones Orgánicas de AG de los últimos 4 meses del Proyecto BogaziciEnstitu. Debido a la "Etapa de obtención de datos históricos" del proyecto, los detalles aumentados no son claros para ser vistos como lineales.
Una cobertura contextual puede ser entendida por los “calificadores de contexto”. Un calificador de contexto puede ser un adjetivo, adverbial o cualquier otra preposición, como frases que comienzan con "for, in, at, during, while". Las siguientes preguntas relacionadas con la entidad no son las mismas en términos del dominio contextual:
- ¿Cuáles son las frutas más útiles para los niños con insomnio?
- ¿Cuáles son las frutas más útiles para los niños con ansiedad?
Las siguientes preguntas relacionadas con la entidad no son las mismas en términos de la capa contextual:
- ¿Cuáles son las frutas más útiles para niños mayores de 6 años con insomnio severo?
- ¿Cuáles son las frutas más útiles para niños menores de 6 años con bajo nivel de ansiedad?
Las siguientes preguntas relacionadas con la entidad no son las mismas en términos de dominios de conocimiento:
- ¿Cuáles son los libros más útiles para niños con insomnio severo mayores de 6 años?
- ¿Cuáles son los juegos más útiles para niños menores de 6 años con bajo nivel de ansiedad?
Pero todas estas preguntas pueden estar en la misma red de contenido semántico porque todas tratan sobre el mismo "concepto" y "área de interés" con actividad de búsqueda similar y actividad del mundo real relacionada con la búsqueda.
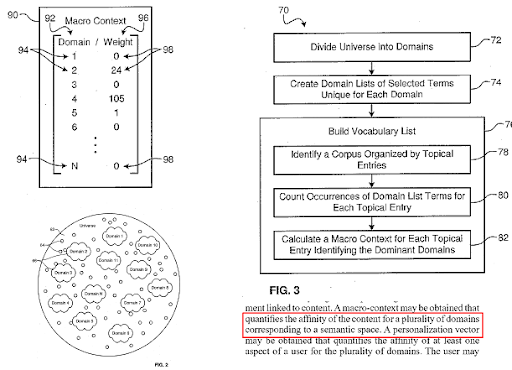
Un motor de búsqueda divide la web en diferentes dominios de conocimiento y calcula las puntuaciones de contexto macro y micro para una fuente, una página web y una sección de página web al mismo tiempo.
Sé que tengo muchos conceptos nuevos para ti, y dado que esta es la versión breve de este artículo, no podré hablar de todo aquí, pero en un futuro curso de SEO semántico, procesaré estas cosas como la diferencia entre "actividad de búsqueda" y "actividad del mundo real relacionada con la búsqueda".
Sigamos un poco con las cosas más concretas.
Para mostrar los detalles del Proyecto BogaziciEnstitu, puede consultar la versión de imagen interactiva. El proceso de prueba y reclasificación de los motores de búsqueda es más claro en este proyecto después del evento de la fuente de datos histórica.
¿Cómo se relaciona MuM con las redes de contenido semántico?
El aprendizaje multitarea con un transformador unificado o el modelo unificado multitarea entrena modelos de lenguaje para evaluar entradas visuales, así como texto. Es capaz de generar texto junto con la comprensión. Además, MuM es independiente del idioma, en otras palabras, el SEO semántico depende de la habilidad del idioma, pero no está restringido a un idioma. Dado que las entidades no tienen un idioma y el significado es universal, MuM aprovecha la información de múltiples idiomas y múltiples contextos en una sola base de conocimiento.
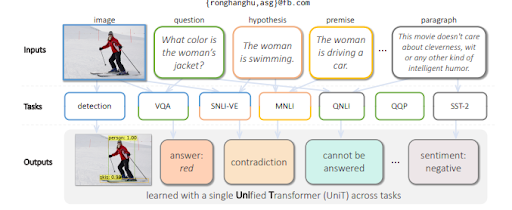
Para responder a las preguntas de una imagen, MuM genera preguntas basadas en los objetos detectados dentro de una imagen. En un futuro cercano, también se podrán generar preguntas relacionadas con audio y video.
MuM utiliza diferentes dominios para la detección de objetos y la comprensión del lenguaje natural con una estructura de codificador-decodificador de transformador. Cada entrada proviene de un área diferente de la web abierta, mientras que todas se evalúan desde un único decodificador compartido. A continuación, podrá ver otro ejemplo del trabajo de investigación.
Como nota, MuM puede ser 1000 veces más fuerte que BERT, pero BERT todavía se usa dentro del codificador de texto de MuM. La principal ventaja de MuM es que se puede usar para imágenes y audio directamente, por lo que se puede llamar un modelo "multitarea". La segunda ventaja es que elimina todas las barreras del idioma directamente. La tercera ventaja es que es capaz de conectar todo con otra cosa sin necesidad de intermediarios extra. La cuarta ventaja es que MuM también puede generar texto, a diferencia de BERT.
La conexión entre MuM, la base de conocimiento, las redes semánticas y la cobertura contextual es que el motor de búsqueda puede encontrar un dominio mucho más contextual a través de calificadores de contexto y sus combinaciones con posibles dominios de conocimiento. Por lo tanto, una red de contenido semántico bien estructurada con un mapa temático y un contexto de origen adecuados puede mejorar la confianza de la base de conocimiento, junto con la autoridad temática.
¿Cuál es el contexto de la fuente?
El contexto de la fuente representa dos cosas. La búsqueda central en Internet de la fuente y la actividad de búsqueda central que se puede realizar con la actividad de búsqueda relacionada. Para un sitio web de comercio electrónico, el contexto de origen es la compra de un producto específico o un tipo específico de producto. Si se trata de un sitio web de viajes, el contexto de la fuente es ir a algún lugar desde otro lugar para diferentes tipos de alimentos, paisajes o simplemente negocios. Según el contexto de la fuente, el diseño de la red de contenido semántico y el mapa temático deberán configurarse más. Esto requiere elegir las secciones centrales dentro del mapa temático y las secciones complementarias dentro del mapa temático.
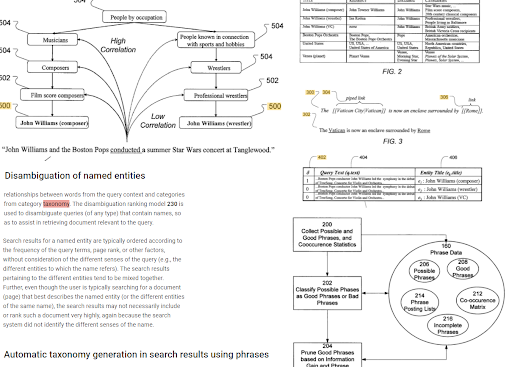
La indexación basada en frases y la comprensión de búsqueda orientada a entidades están conectadas entre sí en función de la semántica. Arriba, la "Desambiguación de la entidad nombrada" y la "Generación automática de taxonomía en los resultados de búsqueda usando frases" se pueden ver juntas para determinar el "contexto". Las buenas frases y la información única pero correlacionada de un tema ayudarán a mejorar la clasificación inicial y la reclasificación.
Nuevamente, algunos de estos conceptos, la "configuración del mapa temático", el "diseño de red de contenido semántico" aún no se han definido, y este no es el lugar adecuado para ello. Sin embargo, la actividad de búsqueda relacionada se ha explicado junto con la intención de búsqueda canónica y las frases representativas de estas intenciones de búsqueda canónicas.
Antecedentes del estudio de caso de SEO centrado en la red semántica
Basado en los conceptos anteriores, utilicé Semantic Networks para crear un estudio de caso de SEO. Veremos los dos proyectos de sitios web que mencioné al comienzo de este artículo y examinaremos los resultados y cómo implementé Semantic Networks para producirlos.
Para darle una idea de cuán poderosas pueden ser estas redes, a continuación se enumeran los resultados relacionados con SEO para el estudio de caso de SEO centrado en la red semántica.
- La comprensión de la red semántica es una necesidad para crear un mapa temático adecuado.
- Para ambos proyectos, el SEO técnico no se utiliza para aislar los efectos del SEO semántico.
- La optimización de velocidad de página no se utiliza, por la misma razón.
- No se utilizan el diseño y la optimización WUX (experiencia del usuario del sitio web).
- No se utilizan backlinks (referencias externas y flujo de PageRank).
- Ambas marcas no tienen datos históricos. Vizem.net es completamente nuevo, BogaziciEnstitusu tiene un historial más antiguo pero era más bajo que el de la empresa actual.
- No se utiliza OnPage SEO u otras verticales del SEO.
- Ambas marcas tienen un mejor servidor que el ejemplo anterior del estudio de caso de autoridad tópica.
Este estudio de caso de SEO centrado en la red semántica ayudará a las personas que desean mejorar su perspectiva de SEO semántico con dos metodologías y conceptos diferentes que se centran en dos sitios web diferentes.
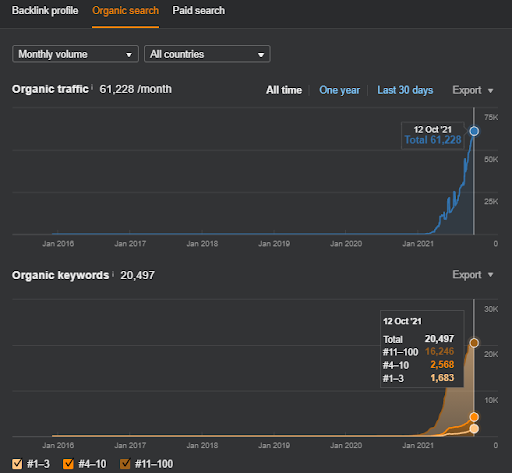
Proyecto dos: Vizem.net se enfoca en el proceso de solicitud de visa. Antes de escribir, publicar o incluso lanzar estos proyectos, he mostrado estos sitios web muchas veces a mis otros clientes o socios. Y, Vizem.net ha comenzado su viaje de "Autoridad tópica" recientemente.
El estudio de caso de SEO basado en redes semánticas se ha escrito en dos versiones diferentes. Si desea leer todas las patentes relacionadas, trabajos de investigación y exámenes profundamente detallados, interpretaciones desde el punto de vista del motor de búsqueda mientras comprende más los árboles de decisión de los motores de búsqueda, puede leer la importancia de la clasificación inicial y la reclasificación SEO Artículo de estudio de caso de más de 30.000 palabras. Si no tiene suficiente conocimiento teórico para SEO y antecedentes históricos, puede continuar leyendo el resumen ejecutivo.
A continuación, puede ver el gráfico del segundo proyecto (Vizem.net) de SEMRush.
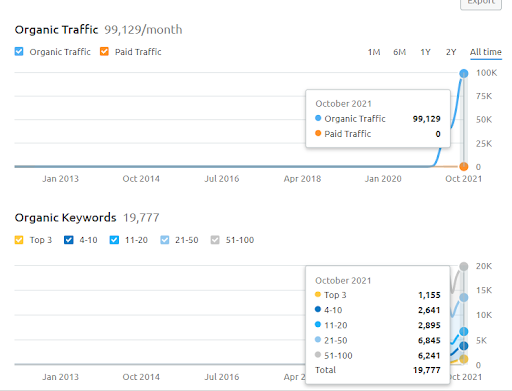
El gráfico SEMRush del Segundo Sitio Web. Vizem.net es una fuente completamente nueva que se dirige a industrias con un alto nivel de competidores arraigados, como "Solicitud de Visa". Especialmente, debido a los últimos eventos en Turquía, el nivel de competencia de la industria está aumentando. Por lo tanto, es útil utilizar la perspectiva de la red semántica para crear una red de contenido.
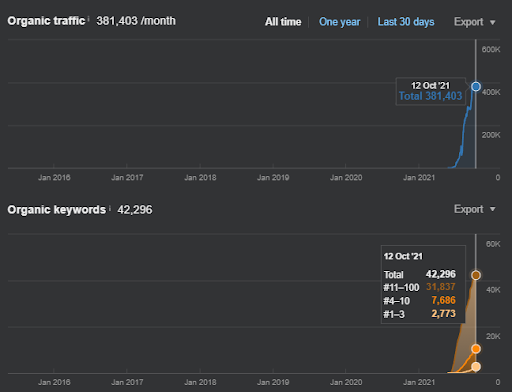
Primer proyecto: Istanbul Bogazici Enstitusu: 600 % de aumento de clics orgánicos en 3 meses: datos históricos apalancados y clasificación inicial
IstanbulBogazici Enstitusu es uno de los casos de estudio de SEO más difíciles que he realizado, no por los motores de búsqueda, sino por las personas y mis problemas de salud. Por lo tanto, dejé el proyecto y no publiqué la tercera red de contenido semántico que está diseñada para completar las relaciones semánticas basadas en el contexto de la fuente. Incluso si no tiene términos de dominio de conocimiento y frases contextuales implementados correctamente, está configurado con suficientes niveles de conexiones semánticas y precisión para permitir un rendimiento de búsqueda orgánica general de más de tres millones de sesiones por mes si la tercera red de contenido es se publicará en el futuro, lo que también explica el efecto creciente de la segunda red de contenido semántico.
A continuación, verá los gráficos cambiantes de IstanbulBogazici Enstitusu en GSC durante los últimos 12 meses. El proyecto se lanzó en mayo de 2021 de manera adecuada y finalizó en septiembre de 2021 con la publicación de dos Redes de contenido semántico.
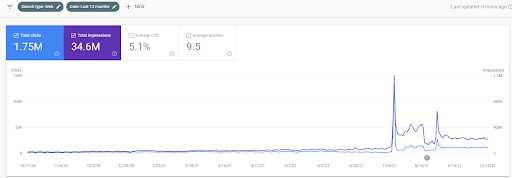
A continuación puede ver la versión más detallada. Desde 1400 clics diarios hasta 140 000 clics, y luego se pueden ver más de 10 000 clics regulares por día dentro del rendimiento de la búsqueda orgánica
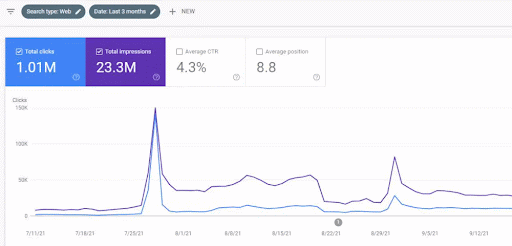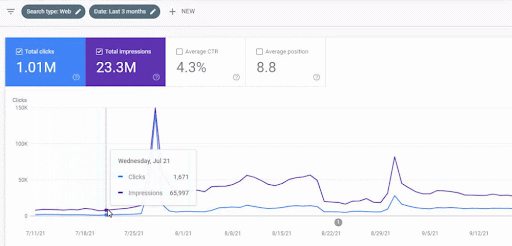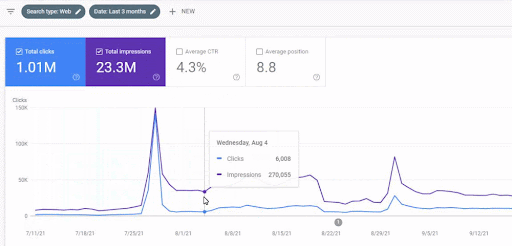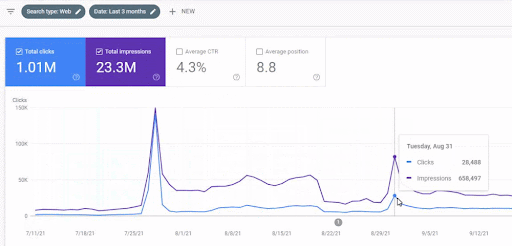
El aumento de tráfico de la primera red de contenido después del lanzamiento se puede ver a continuación.
Esta captura de pantalla muestra el cuarto mes de la Primera Red de Contenido Semántico.
Como puede ver en el gráfico, el tráfico general de todo el sitio web ha sido dominado y afectado por la Primera Red de Contenido Semántico que se enfoca en las “ramas educativas”. La segunda red de contenido que he lanzado con este sitio web se puede ver a continuación desde Google Search Console. La siguiente captura de pantalla corresponde al día 16 de la segunda red de contenido semántico.
La clasificación inicial y la reclasificación se han utilizado en el artículo porque definen las fases de los algoritmos de clasificación junto con sus tipos y propósitos antes de probar una fuente, y una página web de la fuente dentro del SERP para consultas más importantes que tienen popularidad. .
¿En qué consiste la Primera Red de Contenido Semántico del Primer Proyecto Enfocado?
La "red de contenido semántico" utiliza una red semántica de una base de conocimiento para explicar las relaciones principales, secundarias y terciarias entre las cosas dentro de la base de conocimiento. Por lo tanto, crear una red de contenido semántico requiere diseñar la próxima red de contenido semántico en función del contexto de la fuente, que es la función principal del sitio web. En este contexto, la primera red de contenido semántico se ha centrado en “los departamentos universitarios, las ramas educativas y las necesidades de una formación universitaria dentro de una organización y rama específica”.
A continuación, encontrará el Gráfico Ahrefs de la Primera Red de Contenido Semántico.
Esto es cinco días después de la captura de pantalla anterior.
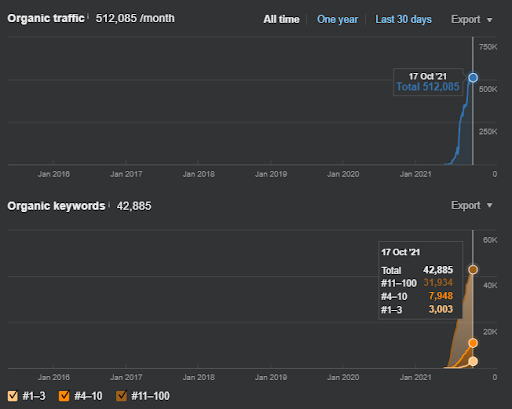
“Raíz: istanbulbogazicienstitu.com/bolum”, después de la primera fase de clasificación inicial, el proceso de reclasificación es más eficiente y productivo.
Puede ver la versión posterior de cuatro días a continuación para respaldar la naturaleza de la "reclasificación".
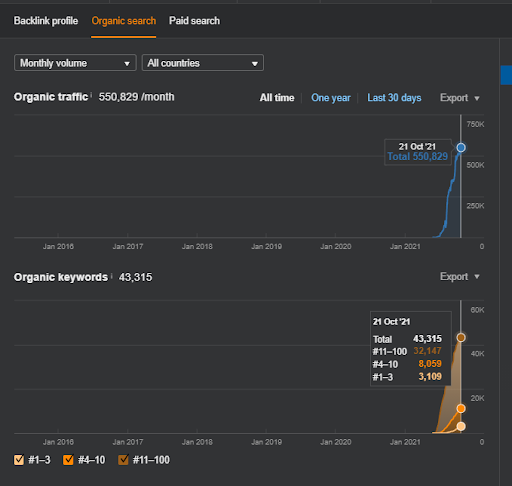
¿En qué consiste la Segunda Red de Contenido Semántico del Primer Proyecto Enfocado?
La segunda red de contenido semántico se ha centrado en las ocupaciones, trabajos, habilidades y educación necesaria para estas habilidades o rutina. Sobre la base de la primera red de contenido semántico, se ha soportado la segunda red de contenido semántico. Y, de acuerdo con las "plantillas de consulta-plantillas de intención", se crean dos redes de subcontenido semántico diferentes más y se colocan con las "conexiones relacionales" mientras se conectan a los niveles jerárquicos similares superiores.
Sé que estas secciones son complicadas para usted porque todavía no vio una definición para las cosas a continuación.
- Red de contenido semántico
- Contexto de origen
- Red de subcontenido semántico
- Base de conocimientos
- Conexiones relacionales
- Clasificación inicial
- Reclasificación
- Cobertura Contextual
- Clasificación de comparación
- Extracción de hechos
Después de explicar el segundo sitio web, será más fácil comprender estos conceptos y oraciones.
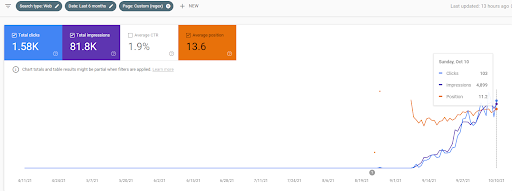
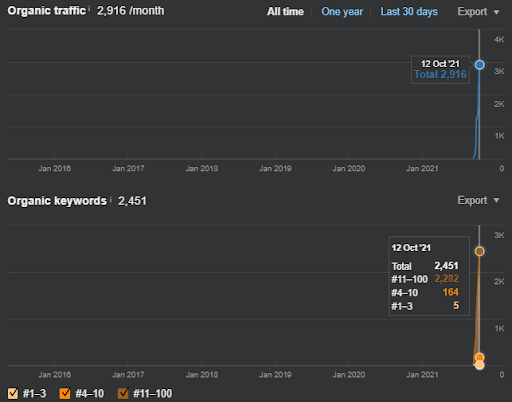
Vizem.net: de 0 a 9.000+ clics diarios por día en 6 meses: ranking comparativo apalancado con cobertura contextual
Puedes ver la gráfica de Vizem.net de los últimos 12 meses. Para este proyecto, debido al Covid-19, hemos tenido muchos problemas económicos ya que el inversionista es de la industria de los gimnasios. Por lo tanto, puedo decir que los problemas económicos ralentizaron el proyecto y provocaron cierta latencia para los "procesos de reclasificación".
Para comprender la clasificación inicial y volver a clasificar un poco más, puede usar el gráfico a continuación.
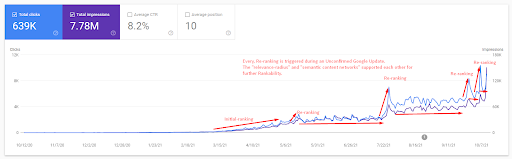
Algunas de las definiciones relacionadas con la clasificación inicial y la reclasificación del gráfico anterior se pueden encontrar a continuación.
- Los grandes saltos de clasificación ocurrieron durante las actualizaciones de Google no confirmadas. Algunas pruebas dieron algunos fragmentos destacados y la gente también hizo preguntas.
- Algunas pruebas de Google eliminaron las ganancias de FS y PAA.
- Cada vez, la línea de tiempo entre dos procesos de reclasificación fue más corta.
- Los procesos de reclasificación mejoraron la clasificación de la fuente cada vez.
- La fuente siempre mejoró su radio de relevancia mientras expandía los grupos de consultas.
Como solo una nota, puedo dejar una oración a continuación.
Si un motor de búsqueda indexa su página web, no significa que el motor de búsqueda entendió la página web. La indexación ocurre más rápido que la comprensión, y la mayoría de las veces, un motor de búsqueda clasifica una página web con predicciones, "inicialmente". Después de la comprensión, ocurre la "reclasificación". 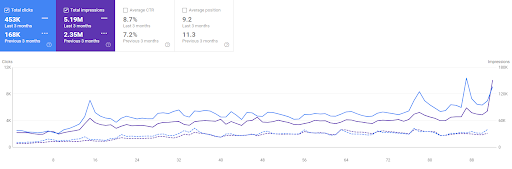
Comparación de los últimos 3 meses de Vizem.net
¿Cómo es la Red de Contenido Semántico de Vizem.net?
Recuerdo que para muchos de mis clientes, amigos o grupos secretos de SEO, durante las reuniones, les demostré estos dos sitios web diciendo: "explotarán". Y, mientras escribo este artículo, te digo esto:
Mire la red de contenido semántico “istanbulbogazicienstitu.com/meslek”, porque explotará. Y puede encontrar un video que publiqué antes de escribir este artículo mientras demostraba los "datos históricos" de un evento estacional y su efecto en los procesos inicial y de reclasificación. Puedes verlo a continuación.
En base a esto, la Red de contenido semántico de Vizem.net no es similar a la IstanbulBogazici Enstitusu, por lo tanto, no usé un "nivel intenso de cobertura temática y aumento de datos históricos", necesitaba crear la autoridad relacionada con ciertos tipos de entidades, sus atributos y posibles acciones detrás de las consultas para estos pares entidad-atributo. Vizem.net no tiene solo "ramas universitarias educativas", o las "ocupaciones y cursos en línea" dentro de él. Tiene “países para solicitudes de visa”. Por lo tanto, la creación de un nivel suficiente de autoridad tópica requiere coherencia a lo largo del tiempo con al menos 190 redes de contenido semántico diferentes.
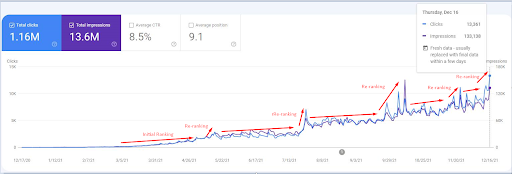
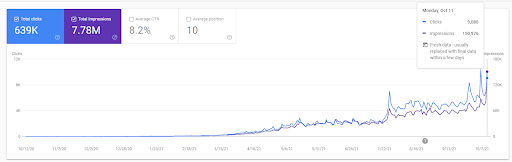
Una captura de pantalla del 18 de diciembre de 2021. Puede ver la reclasificación continua y el aumento de impresiones y clics. Esto es 4 semanas después de la captura de pantalla anterior.
Para ver los eventos de reclasificación, puede comparar la versión desnuda del gráfico de rendimiento de búsqueda orgánica que demuestra el efecto del SEO semántico. 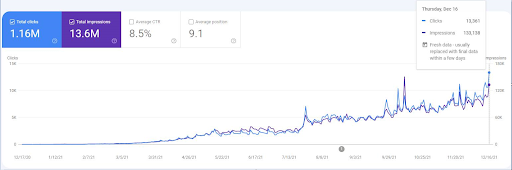
Estas 190 redes de contenido semántico diferentes se configuran en función del "país" en sí, y los países se colocan en el centro del mapa temático con todas las capas contextuales posibles para mejorar la cobertura de la actividad de búsqueda.
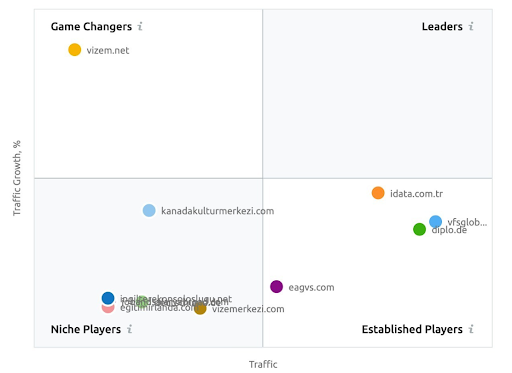
Una captura de pantalla de SEMRush que muestra su percepción de Vizem.net a diferencia de otros actores de la industria.
También he publicado otro video, solo para Vizem.net. En este video, la última situación del sitio web no existe, por lo que creo que también proporciona una buena comparación entre hoy y ese día.
Por último, publicar cosas irrelevantes dentro de un artículo, segmento de sitio web o fuente irrelevante puede disminuir la relevancia general de la entidad web para el dominio de conocimiento específico. Vizem.net mostrará su valor real y la clasificación en el futuro será mucho mejor.
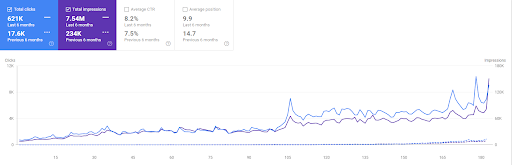
La comparación de los últimos 6 meses de Vizem.net.
Antes de continuar, sé que este es un artículo largo. Pero, en realidad, esta es una breve explicación de una metodología de SEO altamente compleja. Las redes de contenido semántico requieren mucho pensamiento al diseñarlas y meses de educación para clientes, autores y junto con la incorporación. Por lo tanto, en este artículo, quiero centrarme en las definiciones de los conceptos con las mejores breves sugerencias ejecutables posibles e importantes Google, y otras patentes de motores de búsqueda, trabajos de investigación junto con sus propios conceptos. En la versión larga (básicamente, un libro), me he centrado en la “clasificación inicial” y la “reclasificación” de las redes de contenido semántico.
Si desea obtener más información, lea la "Importancia de la clasificación inicial y la reclasificación para SEO".
Hasta ahora, hemos procesado las cosas a continuación.
- Red Semántica
- Base de conocimientos
- Red de contenido semántico
- Confianza basada en el conocimiento
- Cobertura Contextual
- Dominio contextual y capas
- La relevancia de MuM para las redes de contenido semántico
- Contexto de la fuente
Estos conceptos son para comprender cómo funcionan las redes de contenido semántico y cómo se pueden usar con un mapa temático. Las siguientes secciones tratarán sobre cómo un motor de búsqueda clasifica las redes de contenido semántico inicialmente y luego modificando. En este contexto, se procesarán las cosas a continuación.
- Clasificación inicial
- Reclasificación
- Plantilla de consulta
- Documento ejemplar
- Plantilla de intención de búsqueda
- Qué debe hacer para aprovechar las redes de contenido semántico
¿Qué es el ranking inicial para SEO?
Este es un término y concepto nuevo para SEO, pero antiguo para motores de búsqueda. La versión larga del "Estudio de caso de SEO centrado en la red semántica" se centra en los algoritmos de clasificación basados en algoritmos dependientes de consultas, dependientes de documentos, dependientes de fuentes y múltiples patentes. La recuperación de información predictiva o los algoritmos de clasificación predictiva intentan disminuir el costo del cálculo. Y, aunque la indexación se realice en un día, la comprensión de un documento puede llevar meses o incluso años. Calcular una clasificación inicial es, por lo tanto, una forma de mejorar la calidad SERP mientras se reduce el costo. Algunas tareas relacionadas con el motor de búsqueda tienen mayor prioridad que otras para mantener el índice vivo, actualizado y con la calidad suficiente.

El término clasificación inicial aparece en decenas de miles de diferentes patentes de Google y trabajos de investigación porque es una perspectiva clásica entre los creadores de motores de búsqueda. Por lo tanto, arriba, puede ver diferentes documentos de patente con continuación de los mismos párrafos y términos con cambios menores en torno al término de clasificación inicial.
La clasificación inicial representa la clasificación de un documento en el SERP inmediatamente después de ser indexado. La clasificación inicial de un documento representa la autoridad general y la relevancia de la fuente para el tema específico, la plantilla de consulta y la intención de búsqueda. El mismo contenido se puede clasificar de manera diferente en términos de clasificación inicial entre diferentes fuentes. La clasificación inicial es importante cuando se utilizan redes de contenido semántico para ver la calidad general y el aumento de autoridad de la fuente. Cada documento nuevo aumenta su clasificación inicial y reduce el retraso de la indexación si el diseño de la red de contenido semántico está estructurado correctamente.
La clasificación inicial respalda el proceso de reclasificación y su eficiencia para la fuente. Y, "Rankability de una fuente" debe procesarse con estos dos términos, initial y re-ranking.
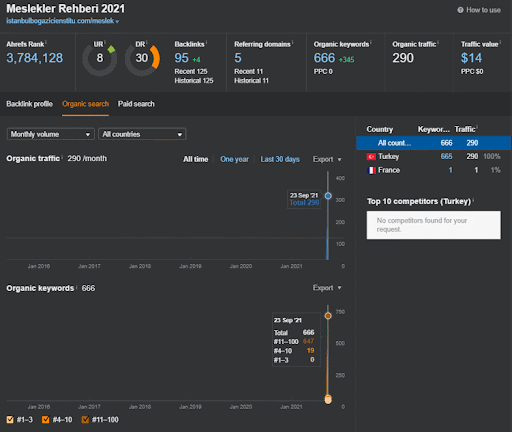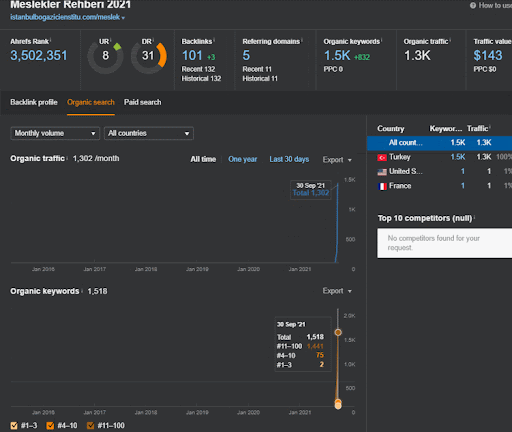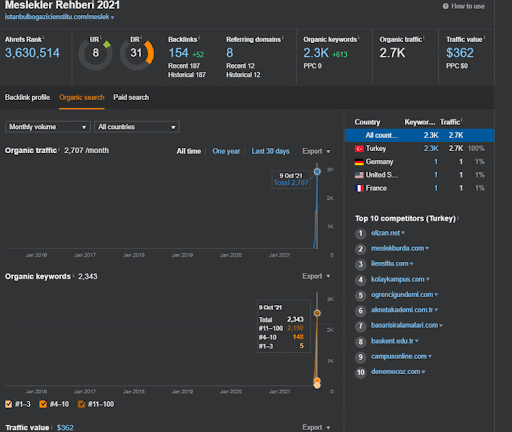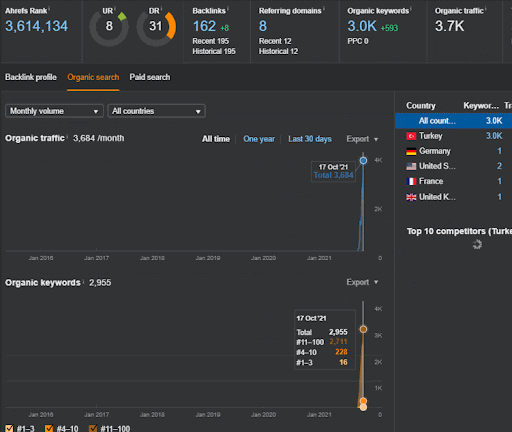
Puede ver los primeros 20 días del cambio de rendimiento orgánico de la Segunda red de contenido del Proyecto I.
En este contexto, cada vez que Vizem.net publica un nuevo documento, o cada vez que IstanbulBogazici Enstitu publica una nueva red de contenido semántico, la clasificación inicial es mejor que antes, mientras que el contenido se indexa más rápido.
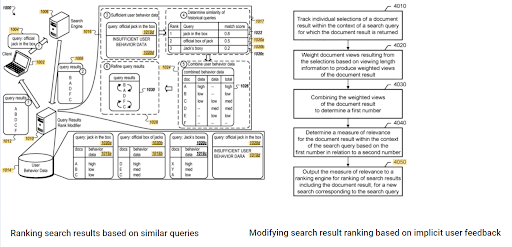
El protagonismo de la clasificación inicial y los datos históricos se puede ver entre estas dos patentes complementarias de Google. Uno es para documentos iniciales y de reclasificación en función de los comentarios implícitos del usuario. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 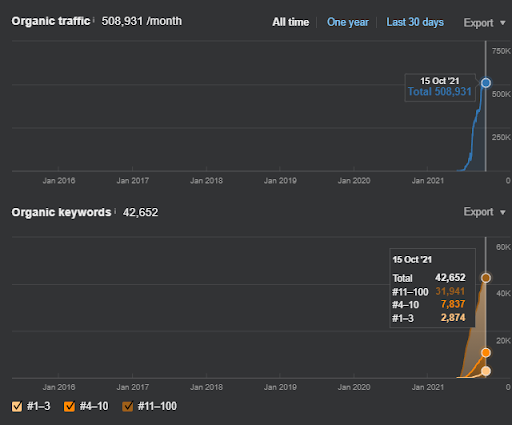
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 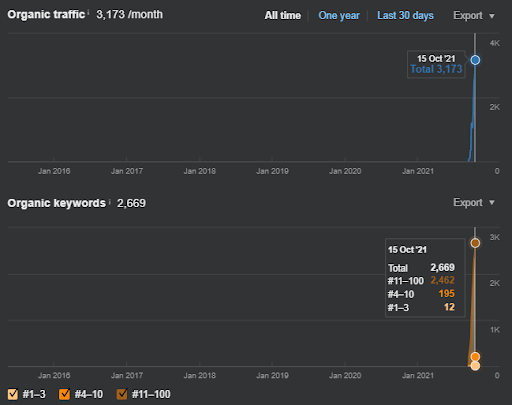
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 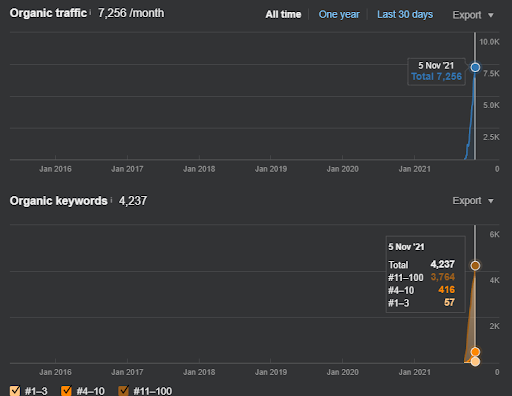
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 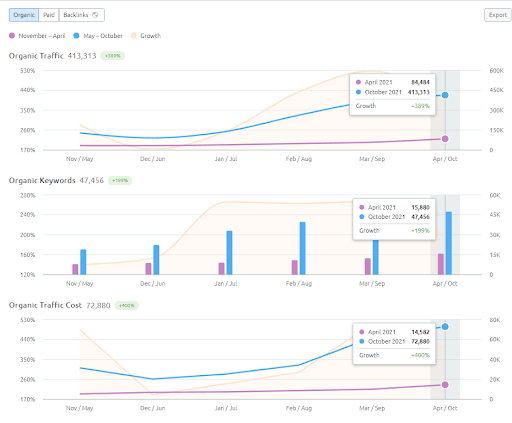
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.

Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.
The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Datos de seguimiento³
 Aprende más
Aprende másWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 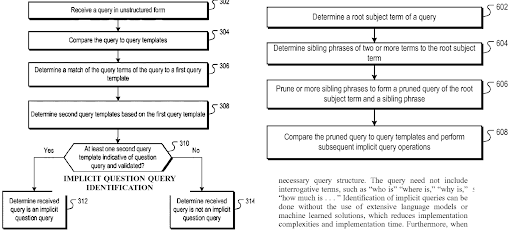
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Sí lo son. La clasificación probabilística y la clasificación de relevancia degradada son las columnas principales de un motor de búsqueda semántica para comprender a los usuarios y crear el SERP de la mejor calidad posible que esté preparado para los estados de posibilidades. 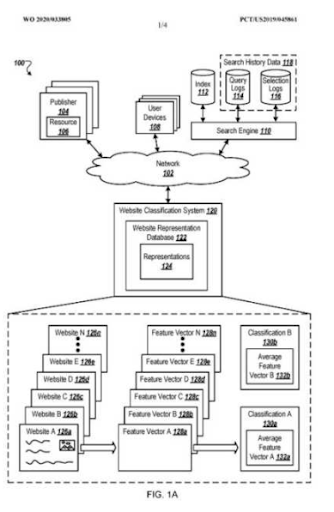
Previamente, para hacer del “diseño, apariencia o tonalidad del sitio web” un argumento para el aprendizaje de la representación para los sitios web, Bill Slawski ha escrito los “Vectores de representación del sitio web”.
¿Qué es una plantilla de intención de búsqueda?
Una plantilla de intención de búsqueda puede representarse por la necesidad detrás de la plantilla de consulta. Una plantilla de documento de consulta se puede unir en función de una plantilla de intención. Tener una plantilla de intención de búsqueda con una posible "clasificación de relevancia degradada" y la comprensión de la "clasificación probabilística" ayudará a crear la mejor actividad de búsqueda posible y la cobertura de intención de búsqueda con el orden correcto. Al crear una red de contenido semántico, lo más importante es ajustar la plantilla de intención de consulta de documento en función del contexto de la fuente para completar una red semántica basada en un dominio de conocimiento al mejorar la cobertura contextual para mejorar la confianza basada en el conocimiento y la autoridad temática. . 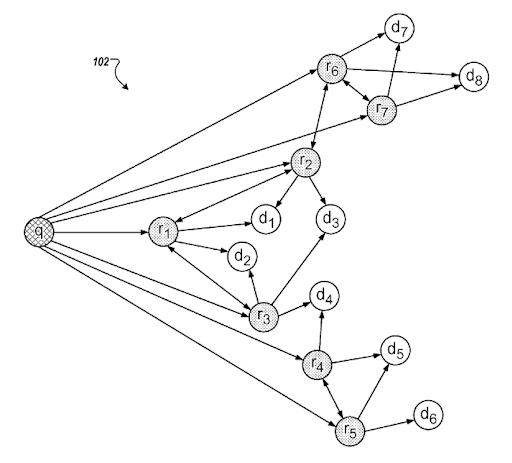
Una sección de "Refinamientos de consultas basados en la intención inferida" de Google. Funciona a través de grupos de consultas y plantillas de intenciones con conexiones semánticas. Puede experimentarlo en diferentes niveles de taxonomía de frases.
Antes de pasar a algunos ejemplos concretos y sugerencias para ayudarlo a crear una mejor red de contenido semántico, debo decirle que incluso la versión simple de este estudio de caso de SEO requiere un alto nivel de comprensión del motor de búsqueda y habilidades de comunicación. Así, aunque siento que doy información de alto nivel, sé que el curso de SEO Semántico que crearé te mostrará algunos más y mejores ejemplos concretos. 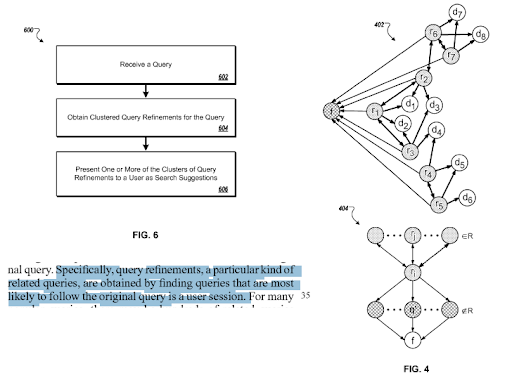
La misma patente explica las conexiones adecuadas entre diferentes "rutas de consulta" y "cambios de contexto".
¿Qué debe saber sobre cómo aprovechar las redes de contenido semántico?
Para crear una red de contenido semántico, a veces, incluso un resumen y diseño de contenido semántico simple puede llevar una hora, si coloca todos los detalles relevantes en función de la semántica léxica o los tipos de relación entre entidades y frases. Usando múltiples ángulos al mismo tiempo, como la indexación basada en frases y los vectores de palabras, o vectores de contexto para calcular la relevancia contextual de un contenido en general para un dominio contextual, o su relevancia según los tipos de subcontenidos individuales, requiere un alto nivel de comprensión del motor de búsqueda semántica.
Por lo tanto, utilizar una metodología generativa te facilitará todo con los conceptos que te he explicado anteriormente, porque aunque prepares perfectamente cada parte de la red de contenido semántico, los autores y escritores no podrán escribirla, ni los administradores de contenido. no será capaz de seguir su visión. Por lo tanto, puede cansarlo por nada y hacer que abandone un proyecto como lo hice yo para algunos de estos Proyectos de estudio de caso de SEO después de probar el concepto de una manera suficientemente viva y auditable.
Las sugerencias a continuación serán solo para pasos breves y fáciles de ejecutar que lo ayudarán.
1. No use enlaces fijos de la barra lateral de todas las redes de redes de contenido semántico
Cada enlace debe tener una descripción de conexión entre dos documentos de hipertexto como cada palabra dentro de una página web. El uso de HTML semántico puede ayudar a especificar la posición y la función de un documento en una página web mientras ayuda a los motores de búsqueda a ponderar las secciones de manera diferente en términos de contexto.
En el ejemplo de Vizem.net, no usé el mismo diseño de barra lateral. La barra lateral no mostraba las publicaciones más recientes o las más importantes. Las barras laterales solo muestran los atributos de las entidades centrales, y no son fijas, son dinámicas. En otras palabras, según la jerarquía dentro del mapa temático, las redes de la red de contenido semántico cambian incluso si están en la barra lateral. 
Pensar en los Modelos de Navegador Razonable y Navegador Cauteloso puede ayudar a un SEO a crear una mejor relevancia entre diferentes documentos de hipertexto.
Además, el enlace fluye en términos de prominencia y la popularidad debe seguir el contexto de la fuente desde las mejores conexiones posibles. A continuación, puede ver las secciones de la barra lateral con códigos HTML semánticos ajustados. 
De acuerdo con la jerarquía del artículo que está activo en la sesión del usuario, las pestañas, el orden de las pestañas, los enlaces dentro de las pestañas cambiarán. El ejemplo anterior es de la jerarquía de migas de pan a continuación. ![]()
2. Apoyar las Redes de Contenido Semántico con PageRank
Incluso si el PageRank externo no es imprescindible de las fuentes externas, si puede usarlo, se dará cuenta de que la clasificación inicial y la reclasificación serán mejores. Para estos dos proyectos, no los usé, pero esta vez, no era el propósito. Para Vizem.net, hubo problemas económicos y no quería gastar el presupuesto en relaciones públicas digitales y difusión. Para Istanbul BogaziciEnstitusu, organicé un par de "fuentes interconectadas localmente" para respaldar la autenticidad de la fuente para el tema específico, pero nuevamente, la empresa no pudo implementar esto debido a problemas de disciplina organizacional y de presupuesto. 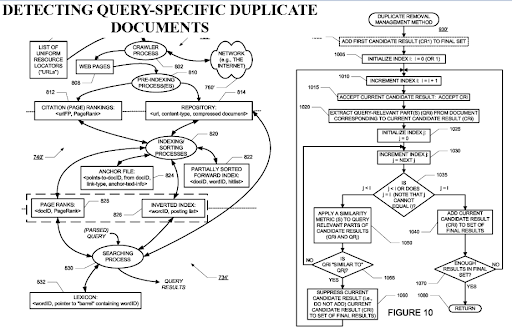
La detección de documentos duplicados específicos de la consulta es una perspectiva importante de los motores de búsqueda, ya que el PageRank puede ayudar a filtrar un documento como valioso incluso si está duplicado. Dado que las redes de contenido semántico altamente organizadas pueden ser similares entre sí, el flujo de PageRank y los datos históricos son útiles.
Cuando se trata de elegir el punto de flujo de PageRank externo para este tipo de redes de contenido semántico, utilice las fuentes con datos históricos. En mi caso, había organizado estos extremos de PageRank antes, antes de lanzar y publicar la primera red de contenido semántico. De esta manera, pude tomar referencias externas de competidores directos, pero cuando publiqué la red de contenido semántico, los competidores desistieron de vincular la fuente porque vieron el aumento masivo de la fuente como competidor.
Esta situación nos lleva a la tercera sugerencia. Si pudiéramos utilizar el flujo de PageRank de referencias externas, el proceso de reclasificación sería más rápido y la clasificación inicial sería más alta.
3. Use diferentes textos de anclaje del pie de página, el encabezado y el contenido principal para las partes prominentes de la red de contenido semántico
Anchor texts o el “texto de enlace” desde el punto de vista del motor de búsqueda señala la relevancia de un documento de hipertexto a otro. Según el documento original del PageRank, el número de enlaces es proporcional al flujo del PageRank. Pero, más tarde, Google cambió esto para evitar el "relleno de enlaces" y limitó los enlaces que realmente pueden pasar el PageRank. En base a esto, se desarrollan los modelos TrustRank, Cautious Surfer, Hilltop Algorithm o Reasonable Surfer. 
Estos son dos enlaces a las dos redes de contenido semántico diferentes para BogaziciEnstitusu, pero como no implementé mejoras técnicas de SEO o UX, puede darse cuenta de lo "barato" de los diseños de botones.
Según Google, el mismo enlace no puede pasar el PageRank por segunda vez a otra página web, mientras que el PageRank se pasará solo desde el primer enlace. Y, en la forma original del algoritmo de PageRank, un documento de hipertexto puede vincularse a sí mismo para mejorar su PageRank, o se pueden usar redireccionamientos 301 para tomar el PageRank del documento de destino del vínculo. Ambas situaciones crearon viejas técnicas de Black Hat, como redirigir una página web a otra temporalmente solo para tomar su PageRank. Esto fue desde los días en que los SEO podían ver el PageRank de una página web desde Google Search Console o SERP. Más tarde, Google comenzó a amortiguar el PageRank con cada redireccionamiento, mientras que Danny Sullivan explicó que los redireccionamientos 301 superarán completamente el PageRank. Además de todos estos cambios, lo importante aquí es que incluso si el segundo enlace no pasa el PageRank, aún pasa la relevancia del texto del enlace. 
Se han vinculado secciones destacadas de la red de contenido semántico desde la página de inicio en función de los "refinamientos de consulta intermedia" que incluyen los "verbos, predicados" o "actividades del buscador".
Por lo tanto, las secciones destacadas de la Red de contenido semántico deben vincularse desde el menú de encabezado y pie de página con las secciones de taxonomía superior, y los textos de los vínculos deben ser diferentes entre sí. En estos ejemplos, he usado los enlaces de encabezado con los textos de enlace destacados pero cortos, mientras que mantuve los ejemplos de pie de página más largos. 
Una sección de "Indización de etiquetas de anclaje en un sistema de rastreo web", resume la importancia de un texto de anclaje y un texto de anotación para posicionar una página web dentro de los grupos de consultas y grupos de páginas web.
Si la sección Red de contenido semántico es demasiado prominente, para pasar el PageRank y la prioridad de rastreo correctamente, he vinculado las secciones más importantes con textos de enlace adecuados y párrafos explicativos que incluyen los atributos destacados con diferentes variaciones de N-Grams relevantes. 
Esta es la segunda área vinculada desde la página de inicio de Vizem.net, está detrás de un acordeón, se enfoca en los países dentro de las consultas y vincula la sección central de la red de contenido semántico.
Nota: Alrededor de los Anchor Texts, siempre, se ha utilizado un “texto de anotación” planificado para mejorar la precisión del propósito del enlace.
4. Limite la restricción de recuento de enlaces y haga coincidir los enlaces de escritorio y móviles y el contenido principal
Ambos proyectos están restringidos a tener menos de 150 enlaces internos por página web. Con la ayuda del HTML semántico, los lugares de los enlaces y las funciones de los enlaces quedan claros para los rastreadores. El IstanbulBogazici Enstitusu tenía más de 450 enlaces por página web, y algunos de ellos eran autoenlaces (un enlace de la misma página a la misma página). Lo peor es que la mitad de estos enlaces no existían en la versión móvil del contenido. 
URL Keep Score, Crawl Score y otros tipos de puntajes se pueden usar para determinar la prominencia de un enlace dentro del mapa de URL interno, y las etiquetas de identificación de documentos dentro de los diferentes niveles se pueden usar para ordenar el índice según los puntajes de relevancia independientes de la consulta.
Dado que Google utiliza la indexación solo para dispositivos móviles, si el contenido no existe en la versión móvil, se ignorará y no se utilizará con fines de clasificación y evaluación de relevancia. Por lo tanto, el contenido móvil y de escritorio se ha configurado para que coincidan entre sí. Incluso si Google tolera las discrepancias de contenido entre las versiones de escritorio y móvil, sigue dificultando la comprensión y clasificación de una página web para los motores de búsqueda. 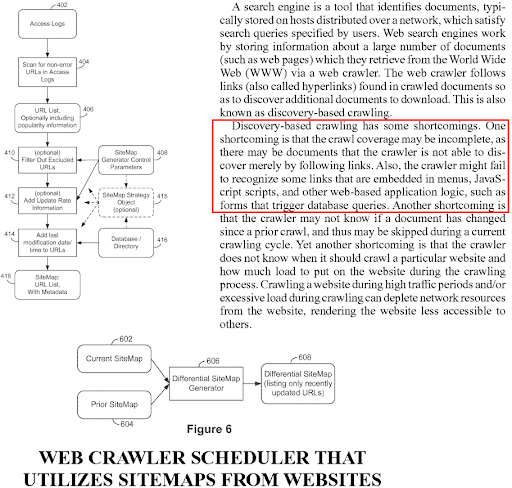
Un motor de búsqueda puede generar un mapa del sitio para el sitio web, y este mapa del sitio se puede volver a generar en un bucle, si los enlaces y los metadatos de URL no coinciden entre los agentes de usuario o las líneas de tiempo. Por lo tanto, es importante mantener la ruta de rastreo corta, la cola de rastreo breve y los enlaces internos consistentes.
Junto con los enlaces entre diferentes páginas web, también se utilizan enlaces para las subsecciones de las páginas web con la "tabla de contenido" y los "Fragmentos de URL". Estos fragmentos de URL apuntan a una subsección específica de la página web mientras la nombran correctamente, y la sección específica se ha colocado en una etiqueta de sección con h2. Con la ayuda de Fragmentos de URL con los "enlaces de navegación en la página", fue más fácil llevar a un usuario de SERP a la sección específica de la página web, mientras que las secciones inferiores del contenido se han hecho más prominentes para satisfacer la necesidad detrás de la consulta.
5. Ten una disciplina de nivel militar para tus proyectos de SEO
Este es un tema completamente diferente y se puede escribir otro artículo para definir qué significa la disciplina de nivel militar, o por qué es útil para un proyecto de SEO. Pero debo decirles que durante estos últimos 2 meses, he capacitado a muchos CEO y SEO de otras agencias junto con sus equipos para ver si el diseño de mi curso funcionará bien o no.
Cada vez que veo éxito y un alto nivel de aferramiento a las sesiones de educación que realizo, hay una fuerte voluntad y perseverancia. El principal problema es que el SEO semántico es mucho más difícil que los otros verticales de SEO. El SEO técnico es universal e incluso tiene guías escritas para cada paso. El OnPage SEO, o WUX y Layout Design se pueden rastrear con medidas numéricas. Cuando se trata de Semántica, es la práctica de unir la perspectiva de una máquina que funciona en base a un sistema adaptativo complejo con homo-sapiens que no entienden cómo funciona la máquina.
Esta distinción requiere una base de hormigón que se debe poner desde el primer día del proyecto. La mayoría de las veces, uso las reglas a continuación.
- Los diseños de contenido y la red de contenido semántico no tienen que ser lógicos para un autor o escritor.
- La tarea del administrador de contenido es auditar la compatibilidad del contenido con el diseño de contenido.
- La tarea del autor es escribir el contenido con la información relacionada que incluye un alto nivel de precisión y detalle.
- Los enlaces, definiciones, evidencias, comparaciones, proposiciones, referencias deben hacerse con ejemplos concretos, no con pelusa.
- Cada palabra innecesaria es una dilución para el contexto y el concepto.
Cuando lea, puede sonar fácil de implementar, pero no es tan fácil. Por lo tanto, puedo decir que incluso estuve a punto de despedir a algunos de mis propios empleados. Me alegro de no haberlo hecho, al menos por ahora. En condiciones normales, habrá muchas preguntas que le harán, si el propietario de la pregunta no es un SEO o propietario de la empresa, no responda. Guarde su energía en el almacenamiento de datos del motor de búsqueda que almacenará sus comentarios positivos, no los comentarios redundantes e irrelevantes para las clasificaciones.
6. Expanda la fuente con relevancia contextual
Esta sección se trata totalmente de comprender la necesidad de Google de crear el MuM. Cuando diseñe un mapa temático, incluirá muchas redes de contenido semántico que proporcionarán una mejor base de conocimientos a nivel del sitio. Por lo tanto, al publicar estas subsecciones, deberían poder conectarse al contexto de la fuente, o puede cambiar la forma en que el motor de búsqueda ve la fuente, y el tema del sitio web puede cambiar a otro dominio de conocimiento. Por ejemplo, conectar cosas en torno a conceptos y áreas de interés con posibles acciones requiere comprender las conexiones de significados complicados entre sí. Hacer que estas conexiones sean claras para un usuario, un escritor y también una máquina al mismo tiempo es el proceso de creación de la Red de contenido semántico. 
Para lograr esto, cada nueva sección del sitio web debe poder conectarse a la sección central del mapa temático. Estos puentes contextuales se pueden ver en el diseño y la explicación de LaMDA de Google.
Encuentro muchas preguntas como "¿debería escribir sobre otro tema?", "si tengo dos nichos diferentes, ¿me hará daño?". Si conecta todas estas subsecciones, segmentos de sitios web como componentes fuertemente conectados, estas redes de contenido semántico se apoyarán entre sí para obtener mejores clasificaciones en lugar de dividir la identidad de la marca y la autoridad temática en dos temas diferentes e irrelevantes.
7. Cree tráfico real y audite con la segmentación personalizada de Google Analytics
El tráfico real está conectado al RankMerge de la misma manera que la confianza basada en el conocimiento está conectada al PageRank. Pronto, estoy pensando en escribir otro artículo con el título de "Cuando el PageRank miente..." para explicar por qué el motor de búsqueda intenta afectar el PageRank con señales secundarias. De hecho, PageRank no es una señal definitiva que muestre la autoridad, la experiencia y la confiabilidad de una fuente. Puede ser una señal para la clasificación y un factor, pero no se puede confiar solo. RankMerge es el proceso de unir el tráfico del sitio web y el PageRank de manera que el sitio web pueda tener sentido para el motor de búsqueda. Un PageRank alto y un tráfico bajo pueden señalar el "tráfico impopular" o la "manipulación del PageRank".
Así, para mejorar los datos históricos de la fuente, he utilizado los Eventos SEO estacionales, y he aumentado las consultas “marca + término genérico”. El tráfico directo y las páginas web marcadas aumentan con el tráfico real y auténtico.
Estos tipos de datos ayudan a un motor de búsqueda a confiar en él para clasificarlo cada vez más alto en el SERP.
Para poder auditar este tráfico real que proviene de la Red de contenido semántico, un SEO puede crear un segmento personalizado desde Google Analytics para ver cómo llegan como tráfico directo. Además, se pueden crear objetivos personalizados, como crear un posible recorrido de búsqueda desde la primera red de contenido semántico hasta la segunda red de contenido. Esta es la prueba de concepto de que la red semántica se construye en torno a los intereses, conceptos y posibles acciones relacionadas con la búsqueda.
A continuación, encontrará solo un ejemplo de una de las páginas web que se colocan dentro de la primera Red de contenido semántico para demostrar el tráfico directo adquirido a través del tráfico orgánico. 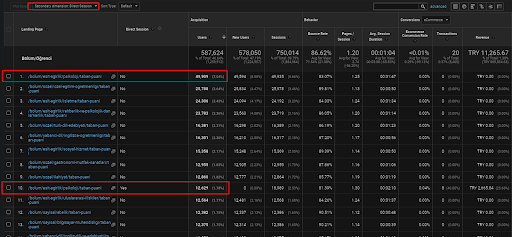
En los últimos 3 meses, solo una página web de la primera red de contenido semántico ha sido utilizada por los 49.000 usuarios orgánicos. Y, 12.900 usuarios adicionales llegaron como tráfico directo que fue adquirido por búsqueda orgánica por primera vez. Y, las métricas de sesión/página y la duración promedio de la sesión son más altas para estos segmentos de usuarios.
Como se dijo antes, un motor de búsqueda puede agrupar consultas, documentos, intenciones, conceptos, intereses, acciones, pero también puede agrupar usuarios. Si un grupo de usuarios deja comentarios positivos mientras crea un valor de marca agregando estas páginas web a los marcadores, escribiendo directamente en la barra de direcciones y buscando los términos genéricos junto con el nombre de la marca, muestra que la fuente mejora su autoridad y motor de búsqueda. es capaz de reconocer todo, desde SERP, Chrome y sus propias direcciones DNS. 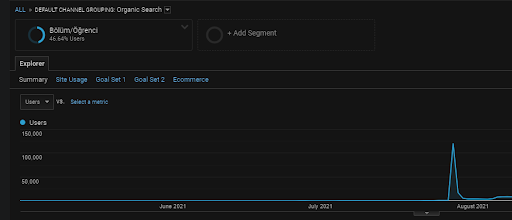
Arriba, puede ver el segmento de usuarios de la Primera red de contenido. Puede crear un segmento de usuario para cada red de contenido semántico con objetivos personalizados y también puede agregar segmentos de subusuarios para las redes de contenido secundario semántico.
8. Admite redes de contenido semántico con subsecciones basadas en actividades de búsqueda
Esta sección también trata sobre la resolución de atributos de entidad y el análisis, que es otro tema. Pero, en pocas palabras, algunos atributos de estas entidades basadas en dominios contextuales deben colocarse en una jerarquía inferior, no en la jerarquía superior. En este caso, el “Vizem.net” puede dar un mejor ejemplo, mientras que para el Bogazici Enstitusu, se puede demostrar con “Salarios de Ocupaciones” y “Puntos de Examen de Universidades”. Estos dos atributos destacados se han colocado en función de las plantillas de consultas y documentos en las redes de subcontenido semántico. 
La identificación de unidades semánticas desde dentro de una consulta de búsqueda es otra patente de Google que divide las frases en diferentes categorías semánticas y agrega la relevancia de un documento en función de su cercanía a todas las variaciones de la consulta.
En un estudio de caso de SEO anterior, no seguí este tipo de estructura, creé una ruta de rastreo basada en la "cronología" y los enlaces internos que están estrictamente limitados. En estos artículos la cantidad de enlaces internos colocados en el contenido principal es mayor que en el anterior.
9. Use palabras temáticas dentro de las URL
Si Google encuentra dos URL diferentes con el mismo contenido sin ninguna señal de canonicalización, elige la corta como canónica. Porque las URL cortas son más fáciles de analizar, resolver y solicitar. Cuando tiene billones de páginas web que actualiza miles de millones de veces todos los días, incluso las letras en las URL pueden mostrar el "equilibrio entre costo y calidad" de un sitio web. Como dije antes, el "costo de recuperación" debería ser menor que el "costo de no recuperación". Si desea que un motor de búsqueda lo entienda, debe colocar las "señales de contexto ordenadas y complementarias" en todos los niveles, incluidas las URL. 
Una sección de la clasificación "basada en evidencia" a través de la agregación de evidencia. Explica cómo se puede relacionar una respuesta con una pregunta.
En este contexto, la mayoría de las veces uso una sola palabra dentro de la URL. Estos pueden reflejar la jerarquía y la estructura de la red de contenido semántico. Algunos todavía piensan que el "recuento de capas" dentro de la URL afecta la frecuencia de rastreo, antes de 2019, era cierto. Pero, siempre que el contenido tenga sentido y satisfaga a los usuarios de un tema popular o destacado, no se verá afectado por tal situación.
Para demostrarlo, puede seguir el siguiente ejemplo.
- Root-domain/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Root-domain/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
Estas dos redes de contenido semántico pueden vincularse entre sí desde la misma jerarquía y también pueden vincularse en función de la relevancia. Hay más cosas aquí de las que podemos hablar, como el "Contenido del agrupador de entidades - Contenido del tipo de concentrador", pero el tema de otro día.
Nota: La tercera red de contenido semántica planificada también se puede procesar como una "red de contenido de agrupador conceptual". Y, si se publica, con el efecto de la Segunda Red de Contenido Semántico, el Tráfico Orgánico global puede superar los 3 millones de sesiones al mes.
10. Comprender la diferencia entre anidar y conectar
Como diferencia metodológica práctica, la conexión es conectar cosas similares entre sí en función de un dominio contextual, mientras que el anidamiento es agrupar el contenido similar con el mismo propósito. Este agrupamiento ayudará a un motor de búsqueda a encontrar contenido similar entre sí más rápido y creará un puntaje de calidad de fuente para estos grupos, o estos contenidos anidados basados en una red semántica serán más fáciles. 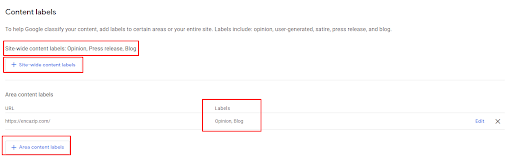
Imagine que hay dos caminos de rastreo diferentes como se muestra a continuación.
- Ruta de rastreo 1: encuentra direcciones URL al azar, sin plantilla, similitud ni relevancia contextual.
- Ruta de rastreo 2: encuentra URL que tienen sentido incluso desde la propia URL, con una plantilla, un alto nivel de similitud y relevancia según el contexto.
Si incluso desde la ruta de rastreo, el contenido tiene sentido, la "clasificación inicial" y la "reclasificación" serán mejores gracias a la "activación de reclasificación basada en la comprensión de la cobertura del motor de búsqueda".
Nota: El uso de enlaces internos con taxonomía de frases de manera adecuada es importante para anidar y conectar.
Esto nos lleva a compartir brevemente la metodología de las dos últimas prácticas. Y, este apartado vuelve a estar relacionado con el alto nivel de disciplina y suficiencia organizativa. 
Una patente de Trystan Upstill y Steven D. Baker para reconocer los términos concurrentes dentro de las Listas HTML. La importancia de esta patente es que muestra el valor de una sola Lista HTML para determinar las listas de términos concurrentes para un tema, o una parte de la taxonomía de frases.
11. Comprender cuándo publicar una red de contenido semántico con una frecuencia ajustada
Esto se ha explicado antes, pero en uno de estos Proyectos de estudio de caso de SEO, publiqué casi 400 piezas de contenido en un día. En lo que respecta al otro, comencé a publicar solo 10-15 contenido de repente, luego aumenté la velocidad con el tiempo con constancia hasta que comenzaron los problemas económicos relacionados con Covid.
Si una nueva fuente crea una nueva Red de contenido semántico, publicarla el primer día puede ser un poco más difícil de lo que piensa, verificar todos los enlaces internos, gramáticas e información en la página web no es tan fácil. Pero, si todo el contenido es solo de un solo tema y una plantilla de consulta, y si la fuente no tiene ningún historial sobre ese tema, publicar la mayor parte de la red de contenido semántico tiene ventajas como una indexación más rápida, comprensión y re-clasificación.
En mi situación, también hubo un evento histórico con estacionalidad. Por lo tanto, mi propósito era tener suficiente nivel de posición promedio hasta que el motor de búsqueda pueda probar las entidades específicas y las actividades de búsqueda en las fuentes más antiguas. Así, he publicado la primera Red de Contenido Semántico con un alto nivel de preparación antes de los 45 días del evento estacional.
Luego, puede ver cómo el motor de búsqueda probó la fuente repetidamente como se muestra a continuación. 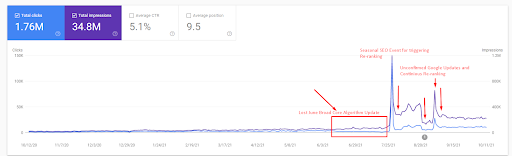
Una explicación más detallada se puede encontrar a continuación. 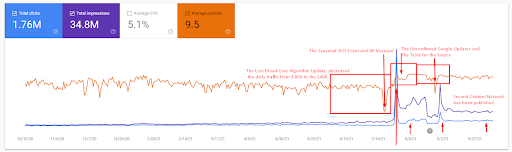
A continuación se puede encontrar una verificación de datos rápida para la explicación de la captura de pantalla anterior.
- La actualización del algoritmo de núcleo amplio ha disminuido el tráfico del sitio web en más de un 200 %.
- El sitio web también perdió más de 15.000 consultas.
- Esto afectó la indexación general de la fuente para la nueva red de contenido semántico, ya que se ha explicado mejor en el artículo detallado del estudio de caso de SEO.
- Gracias al evento de SEO estacional, la reclasificación ocurrió antes y, después del evento de SEO estacional, el motor de búsqueda normalizó la clasificación de la fuente en función del tráfico real durante las actualizaciones no confirmadas.
- Las consultas y las clasificaciones que se obtienen gracias a la Primera Red de Contenido Semántico y el Evento Estacional se han protegido y mejorado aún más.
- La primera Red de contenido semántico también apoyó la nueva y segunda Red de contenido semántico.
La pérdida de consultas y la pérdida de clasificación promedio también se pueden ver en Ahrefs como se muestra a continuación. Puede verificar el efecto de la actualización del algoritmo de núcleo amplio de Google (GBCAU) de junio de 2021 junto con el efecto de la actualización no confirmada. 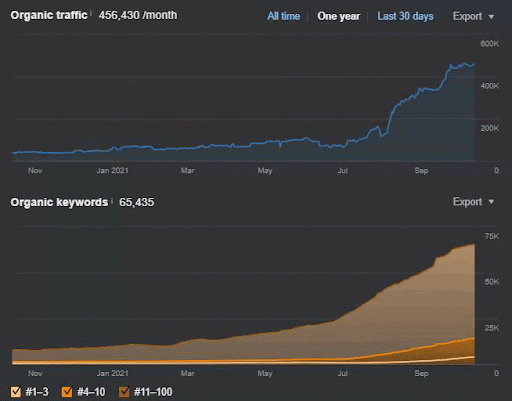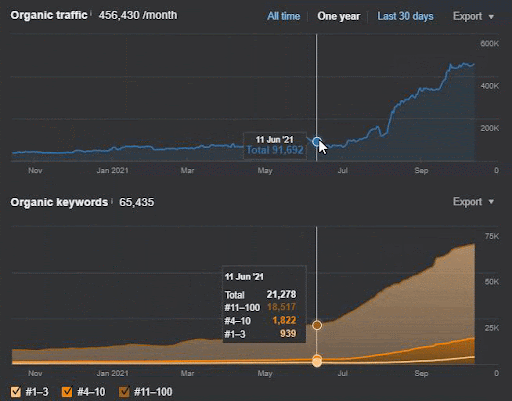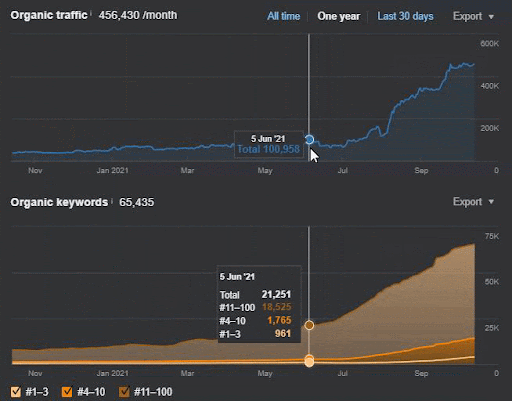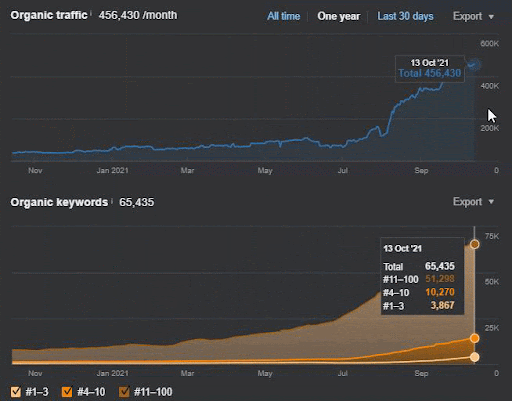
Por lo tanto, utilizar una Red de Contenido Semántico con múltiples estrategias posibles es una necesidad. Incluso si se pierde el GCBAU, aún así, gracias a otros factores relacionados con el motor de búsqueda, natura puede ayudar a un SEO. Por lo tanto, puede imaginar por qué explicar estas cosas a un autor o a un cliente es más difícil que el SEO técnico. El SEO semántico no usa valores numéricos, usa el conocimiento teórico que proviene de la comprensión del motor de búsqueda a través de patentes, trabajos de investigación, experiencia y anuncios históricos.
12. Use la optimización de oraciones en la página para una mejor estructura fáctica
Para ser honesto, incluso el décimo listado es un tema completamente nuevo y puede requerir incluso escribir 20,000 palabras aquí. Pero, voy a empezar con un ejemplo simple.
- X es Y.
- y es x
Para las oraciones de ejemplo anteriores, puede entender las cosas a continuación.
- Las oraciones anteriores no son contenido duplicado.
- Las proposiciones anteriores están duplicadas.
- Las explicaciones relacionales entre dos oraciones son las mismas.
- Las etiquetas de roles semánticos son 100% diferentes.
- La salida del reconocimiento de entidad nombrada es 100% igual.
La optimización de oraciones en la página está relacionada con los algoritmos de generación de preguntas y las tecnologías de emparejamiento de preguntas y respuestas. Un formato de pregunta requiere un cierto tipo de oración. Y ciertos tipos de preguntas deben responderse con ciertos tipos de oraciones. El formato del contenido, el NER y la extracción de hechos se verán afectados por la optimización de la estructura de la oración. 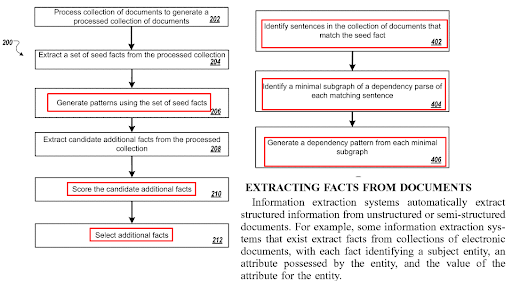
Los tripletes (un objeto, dos sujetos) se pueden extraer y verificar en términos de precisión más rápido. Dos oraciones similares no significa que estén duplicadas, significa que están cerca una de la otra en términos de la estructura de la oración. Siempre que la proposición sea diferente, el uso de oraciones similares entre plantillas de documentos similares para diferentes pares de intención de consulta es una necesidad para la creación de redes de contenido semántico. 
Las estructuras de oraciones claras con un patrón adecuado son útiles para hacer que las piezas de texto sean más relevantes entre sí mientras ayudan a un motor de búsqueda a reconocer entidades nombradas, y sujetos, atributos, junto con sus valores entre sí.
También ayudará a ver qué sección de un artículo se puede mejorar, y en Topical Nets, dónde su contenido se clasifica mejor para qué tipos de pares de palabras, vectores de palabras e intenciones. Porque, si se pueden observar ciertos tipos de estructuras de oraciones para ciertos tipos de preguntas en varias páginas web, ayudará para las pruebas A/B de SEO avanzadas con cantidades infinitas de muestras de datos y muestras de prueba. Puede crear múltiples diseños de oraciones en la página para verificar cómo un motor de búsqueda extrae los hechos para compararlos. 
Cuando se trata de dar los hechos, se debe recordar la "Bóveda del conocimiento" y el Luna Dong.
13. Proporcione información del mundo real con precisión y consistencia, no opiniones con pelusa
La precisión aquí significa poder compararse con valores numéricos, o relaciones conceptuales concretas. La consistencia significa que proteges tu postura para la proposición específica. Por ejemplo, no diga que "el producto X es mejor para Y" para cada revisión de producto relacionada con Y. No proporcione proposiciones contradictorias en todo el sitio. Y, si el producto es el mejor, ¿cuál es la prueba de ello? ¿El material, el tamaño o el color y el olor? Fluff dentro del texto significa que usa palabras puente innecesarias, o no dice cosas que no son posibles de probar, o que contradicen la verdad.
En el contexto de estas instrucciones no definitorias que son compatibles con algunos de los ejemplos, puede consultar uno de los modelos de lenguaje de Google, que es KeALM.
Sirve para generar texto a partir de una base de datos con los modelos de datos a texto y para comprobar la precisión del contenido. 
KELM es un ejemplo de Accuracy Audit para las proposiciones con métodos de texto a datos.
Esto también es un poco sobre la definición de "Triplete" y "Extracción de información abierta para entidades desconocidas", pero como saben, esta es la versión breve, y supongo que ya he dicho suficiente. Básicamente, cuando brinde información incorrecta en su sitio web, asegúrese de que Google pueda entenderla para disminuir la confianza basada en el conocimiento de la fuente. Aquí, es posible que también deba saber que, dado que puede expandir la base de conocimiento, un motor de búsqueda puede cambiar su propia base de conocimiento en función de su información, si tiene una fuente correlacionada con PageRank y confianza en la base de conocimiento. con alta precisión y trillizos únicos.
14. Comprender el árbol de dependencia semántica para entidades
Árbol de dependencia semántica significa que los atributos que señalan relaciones con otras entidades tienen una dependencia jerárquica entre ellos. El árbol de dependencia semántica se puede observar al verificar múltiples perfiles y ángulos de entidades, como que un país puede ser miembro de una organización y, como otra entidad, esta organización puede tener otros atributos que se pueden atribuir a los países conectados con relaciones inferidas.
A continuación, podrás ver un ejemplo sencillo desde el Buscador, directamente. 
REALM es un método que utiliza árboles de dependencia semántica para extraer información de texto ambiguo.
En la web abierta, la extracción de información abierta puede reconocer nuevas entidades nombradas y extraer estas mismas entidades como coexistentes con otras entidades. Estas co-ocurrencias y atributos mutuos dentro del artículo pueden asignar un contexto y un tipo de relación candidata entre entidades. Según las conexiones y el tipo de entidad, se puede crear el árbol de dependencia semántica. La misma lógica ocurre también con la semántica léxica. La palabra "niño" tiene algunos significados posibles y algunos otros significados exactos. Por ejemplo, un niño es un hombre y probablemente un adolescente que no está casado. También se puede usar cerca del estudiante. La palabra "Reina", por otro lado, incluye otros significados secundarios y exactos, como "mujer" y "ser gobernadora". Por lo tanto, tener algo que gobernar es una jerarquía de árbol de dependencia semántica natural que puede señalar ciertos tipos de plantillas de consulta como "Reina de..." o "Para Quen". These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 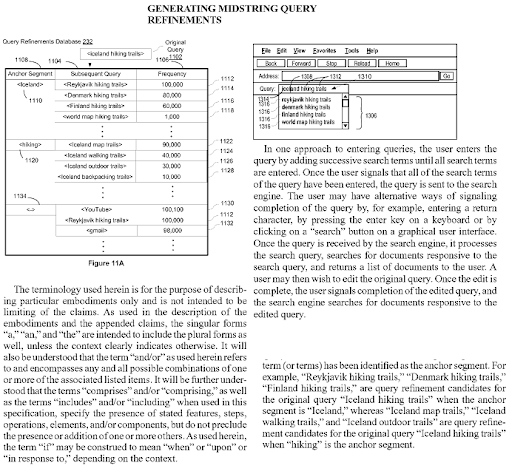
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.