
Controlar el rastreo y la indexación: una guía de SEO para Robots.txt y etiquetas
Publicado: 2019-02-19La optimización del presupuesto de rastreo y el bloqueo de bots de las páginas de indexación son conceptos que muchos SEO conocen. Pero el diablo está en los detalles. Especialmente porque las mejores prácticas han cambiado significativamente en los últimos años.
Un pequeño cambio en un archivo robots.txt o etiquetas de robots puede tener un impacto dramático en su sitio web. Para que el impacto sea siempre positivo para tu sitio, hoy vamos a profundizar en:
Optimización del presupuesto de rastreo
¿Qué es un archivo Robots.txt?
¿Qué son las etiquetas Meta Robots?
¿Qué son las etiquetas de X-Robots?
Directivas de Robots y SEO
Lista de verificación de mejores prácticas de robots
Optimización del presupuesto de rastreo
La araña de un motor de búsqueda tiene una "concesión" de cuántas páginas puede y quiere rastrear en su sitio. Esto se conoce como "presupuesto de rastreo".
Encuentre el presupuesto de rastreo de su sitio en el informe "Estadísticas de rastreo" de Google Search Console (GSC). Tenga en cuenta que el GSC es un agregado de 12 bots que no están todos dedicados a SEO. También reúne bots de AdWords o AdSense que son bots SEA. Por lo tanto, esta herramienta le brinda una idea de su presupuesto de rastreo global, pero no su distribución exacta.
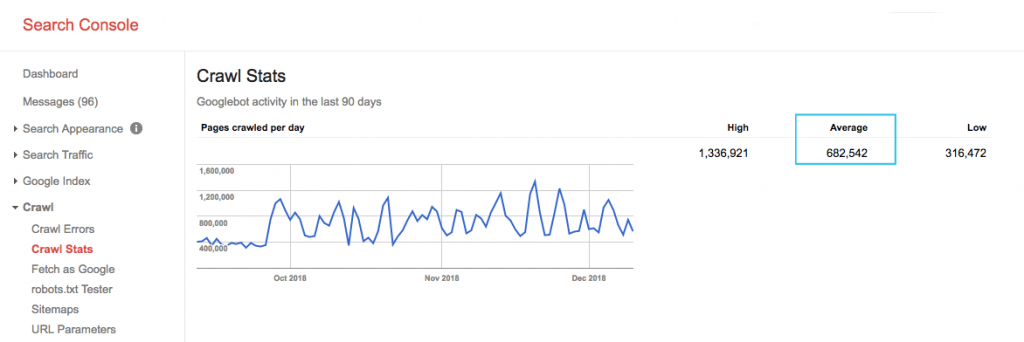
Para que el número sea más procesable, divida el promedio de páginas rastreadas por día por el total de páginas rastreables en su sitio; puede pedirle a su desarrollador el número o ejecutar un rastreador de sitio ilimitado. Esto le dará una relación de rastreo esperada para que comience a optimizar.
¿Quieres ir más profundo? Obtenga un desglose más detallado de la actividad de Googlebot, como qué páginas se visitan, así como estadísticas de otros rastreadores, analizando los archivos de registro del servidor de su sitio.
Hay muchas maneras de optimizar el presupuesto de rastreo, pero un lugar fácil para comenzar es verificar el informe de "Cobertura" de GSC para comprender el comportamiento actual de rastreo e indexación de Google.
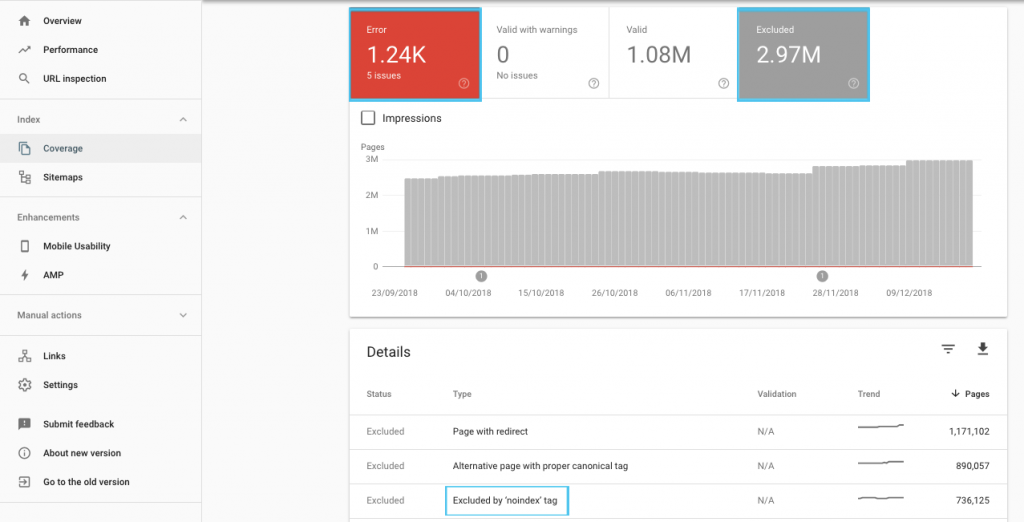
Si ve errores como "URL enviada marcada como 'noindex'" o "URL enviada bloqueada por robots.txt", trabaje con su desarrollador para corregirlos. Para cualquier exclusión de robots, investíguelos para comprender si son estratégicos desde una perspectiva de SEO.
En general, los SEO deben tener como objetivo minimizar las restricciones de rastreo de los robots. Mejorar la arquitectura de su sitio web para que las URL sean útiles y accesibles para los motores de búsqueda es la mejor estrategia.
Los propios Google señalan que "una arquitectura de información sólida probablemente sea un uso mucho más productivo de los recursos que centrarse en la priorización del rastreo".
Dicho esto, es beneficioso comprender lo que se puede hacer con los archivos robots.txt y las etiquetas de robots para guiar el rastreo, la indexación y el paso de la equidad de los enlaces. Y lo que es más importante, cuándo y cómo aprovecharlo mejor para el SEO moderno.
[Estudio de caso] Administrar el rastreo de bots de Google
 Lea el estudio de caso
Lea el estudio de caso¿Qué es un archivo Robots.txt?
Antes de que un motor de búsqueda rastree cualquier página, verificará el archivo robots.txt. Este archivo le dice a los bots qué rutas de URL tienen permiso para visitar. Pero estas entradas son solo directivas, no mandatos.
Robots.txt no puede evitar de manera confiable el rastreo como un firewall o protección con contraseña. Es el equivalente digital de un cartel de "por favor, no entre" en una puerta abierta.
Los rastreadores educados, como los principales motores de búsqueda, generalmente obedecerán las instrucciones. Los rastreadores hostiles, como los rastreadores de correo electrónico, los robots de spam, el malware y las arañas que analizan las vulnerabilidades del sitio, a menudo no prestan atención.
Además, es un archivo disponible públicamente . Cualquiera puede ver sus directivas.
No utilice su archivo robots.txt para:
- Para ocultar información sensible. Utilice protección con contraseña.
- Para bloquear el acceso a su sitio de ensayo y/o desarrollo. Utilice la autenticación del lado del servidor.
- Para bloquear explícitamente a los rastreadores hostiles. Utilice el bloqueo de IP o el bloqueo de agentes de usuario (también conocido como impedir el acceso de un rastreador específico con una regla en su archivo .htaccess o una herramienta como CloudFlare).
Cada sitio web debe tener un archivo robots.txt válido con al menos una agrupación de directivas. Sin uno, todos los bots tienen acceso completo de forma predeterminada, por lo que cada página se trata como rastreable. Incluso si esto es lo que pretende, es mejor dejar esto claro para todas las partes interesadas con un archivo robots.txt. Además, sin uno, los registros de su servidor estarán plagados de solicitudes fallidas de robots.txt.
Estructura de un archivo robots.txt
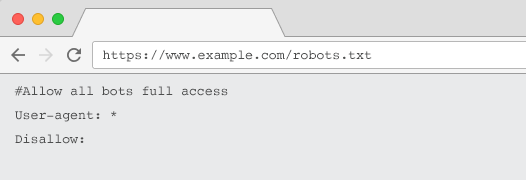
Para que los rastreadores lo reconozcan, su archivo robots.txt debe:
- Sea un archivo de texto llamado “robots.txt”. El nombre del archivo distingue entre mayúsculas y minúsculas. "Robots.TXT" u otras variaciones no funcionarán.
- Estar ubicado en el directorio de nivel superior de su dominio canónico y, si corresponde, subdominios. Por ejemplo, para controlar el rastreo en todas las URL debajo de https://www.example.com, el archivo robots.txt debe estar ubicado en https://www.example.com/robots.txt y para el subdominio.example.com en subdominio.ejemplo.com/robots.txt.
- Devuelve un estado HTTP de 200 OK.
- Use una sintaxis de robots.txt válida: compruébelo con la herramienta de prueba de robots.txt de Google Search Console.
Un archivo robots.txt se compone de grupos de directivas. Las entradas consisten principalmente en:
- 1. Agente de usuario: se dirige a los diversos rastreadores. Puede tener un grupo para todos los robots o usar grupos para nombrar motores de búsqueda específicos.
- 2. No permitir: especifica los archivos o directorios que se excluirán del rastreo del agente de usuario anterior. Puede tener una o más de estas líneas por bloque.
Para obtener una lista completa de nombres de agentes de usuario y más ejemplos de directivas, consulte la guía de robots.txt en Yoast.
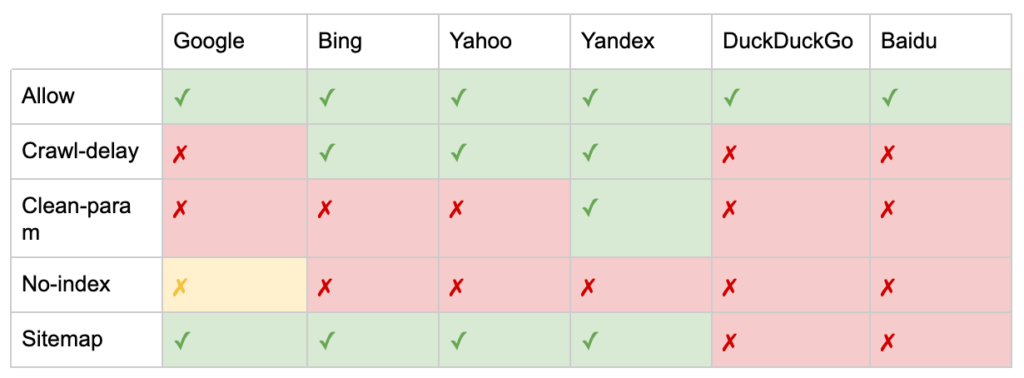
Además de las directivas "User-agent" y "Disallow", existen algunas directivas no estándar:
- Permitir: especifique excepciones a una directiva de rechazo para un directorio principal.
- Crawl-delay: acelere los rastreadores pesados diciéndoles a los bots cuántos segundos deben esperar antes de visitar una página. Si obtiene pocas sesiones orgánicas, el retraso del rastreo puede ahorrar ancho de banda del servidor. Pero invertiría el esfuerzo solo si los rastreadores están causando problemas de carga del servidor de forma activa. Google no reconoce este comando, ofrece la opción de limitar la tasa de rastreo en Google Search Console.
- Clean-param: evite volver a rastrear contenido duplicado generado por parámetros dinámicos.
- Sin índice: diseñado para controlar la indexación sin utilizar ningún presupuesto de rastreo. Ya no es compatible oficialmente con Google. Si bien hay evidencia de que aún puede tener un impacto, no es confiable y no lo recomiendan expertos como John Mueller.
@maxxeight @google @DeepCrawl Realmente evitaría usar el noindex allí.
— ???? John ???? (@JohnMu) 1 de septiembre de 2015
- Mapa del sitio: la forma óptima de enviar su mapa del sitio XML es a través de Google Search Console y las Herramientas para webmasters de otros motores de búsqueda. Sin embargo, agregar una directiva de mapa del sitio en la base de su archivo robots.txt ayuda a otros rastreadores que pueden no ofrecer una opción de envío.
Limitaciones de robots.txt para SEO
Ya sabemos que robots.txt no puede evitar el rastreo de todos los bots. Del mismo modo, no permitir que los rastreadores accedan a una página no impide que se incluya en las páginas de resultados de los motores de búsqueda (SERP).
Si una página bloqueada tiene otras señales de clasificación sólidas, Google puede considerarla relevante para mostrarla en los resultados de búsqueda. A pesar de no haber rastreado la página.
Debido a que Google desconoce el contenido de esa URL, el resultado de la búsqueda se ve así:

Para bloquear definitivamente una página para que no aparezca en las SERP, debe usar una metaetiqueta de robots "noindex" o un encabezado HTTP X-Robots-Tag.
En este caso, no rechace la página en robots.txt , ya que la página debe rastrearse para que la etiqueta "noindex" se vea y se obedezca. Si la URL está bloqueada, todas las etiquetas de robots son ineficaces.
Es más, si una página ha acumulado una gran cantidad de enlaces entrantes, pero robots.txt impide que Google rastree esas páginas, mientras que Google conoce los enlaces , se pierde la equidad del enlace .
¿Qué son las etiquetas Meta Robots?
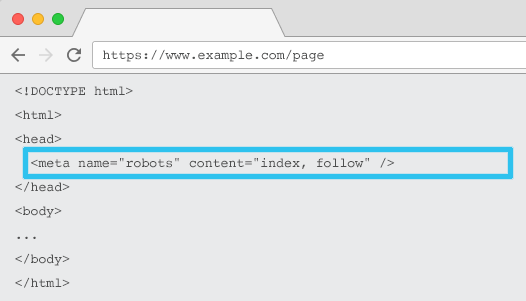
Colocado en el HTML de cada URL, meta name=”robots” les dice a los rastreadores si y cómo “indexar” el contenido y si “seguir” (es decir, rastrear) todos los enlaces en la página, transmitiendo la equidad del enlace.
Usando el meta nombre general = "robots", la directiva se aplica a todos los rastreadores. También puede especificar un agente de usuario específico. Por ejemplo, metanombre=”googlebot”. Pero es raro necesitar usar múltiples etiquetas de meta robots para establecer instrucciones para arañas específicas.
Hay dos consideraciones importantes al usar etiquetas de meta robots:
- Al igual que robots.txt, las etiquetas meta son directivas, no mandatos, por lo que algunos bots pueden ignorarlas.
- La directiva de robots nofollow solo se aplica a los enlaces en esa página. Es posible que un rastreador siga el enlace desde otra página o sitio web sin un nofollow. Por lo tanto, el bot aún puede llegar e indexar su página no deseada.
Aquí está la lista de todas las directivas de etiquetas de meta robots:
- índice: indica a los motores de búsqueda que muestren esta página en los resultados de búsqueda. Este es el estado predeterminado si no se especifica ninguna directiva.
- noindex: indica a los motores de búsqueda que no muestren esta página en los resultados de búsqueda.
- seguir: le dice a los motores de búsqueda que sigan todos los enlaces en esta página y pasen la equidad, incluso si la página no está indexada. Este es el estado predeterminado si no se especifica ninguna directiva.
- nofollow: le dice a los motores de búsqueda que no sigan ningún enlace en esta página o pasen la equidad.
- all: Equivalente a “indexar, seguir”.
- none: Equivalente a “noindex, nofollow”.
- noimageindex: le dice a los motores de búsqueda que no indexen ninguna imagen en esta página.
- noarchive: indica a los motores de búsqueda que no muestren un enlace en caché a esta página en los resultados de búsqueda.
- nocache: Igual que noarchive, pero solo lo usan Internet Explorer y Firefox.
- nosnippet: indica a los motores de búsqueda que no muestren una meta descripción o una vista previa del video de esta página en los resultados de búsqueda.
- notranslate: le dice al motor de búsqueda que no ofrezca la traducción de esta página en los resultados de búsqueda.
- no disponible_después: indica a los motores de búsqueda que ya no indexen esta página después de una fecha específica.
- noodp: ahora en desuso, una vez impidió que los motores de búsqueda usaran la descripción de la página de DMOZ en los resultados de búsqueda.
- noydir: ahora en desuso, una vez impidió que Yahoo usara la descripción de la página del directorio de Yahoo en los resultados de búsqueda.
- noyaca: evita que Yandex use la descripción de la página del directorio de Yandex en los resultados de búsqueda.
Como documenta Yoast, no todos los motores de búsqueda admiten todas las metaetiquetas de robots, o incluso tienen claro lo que admiten y lo que no.
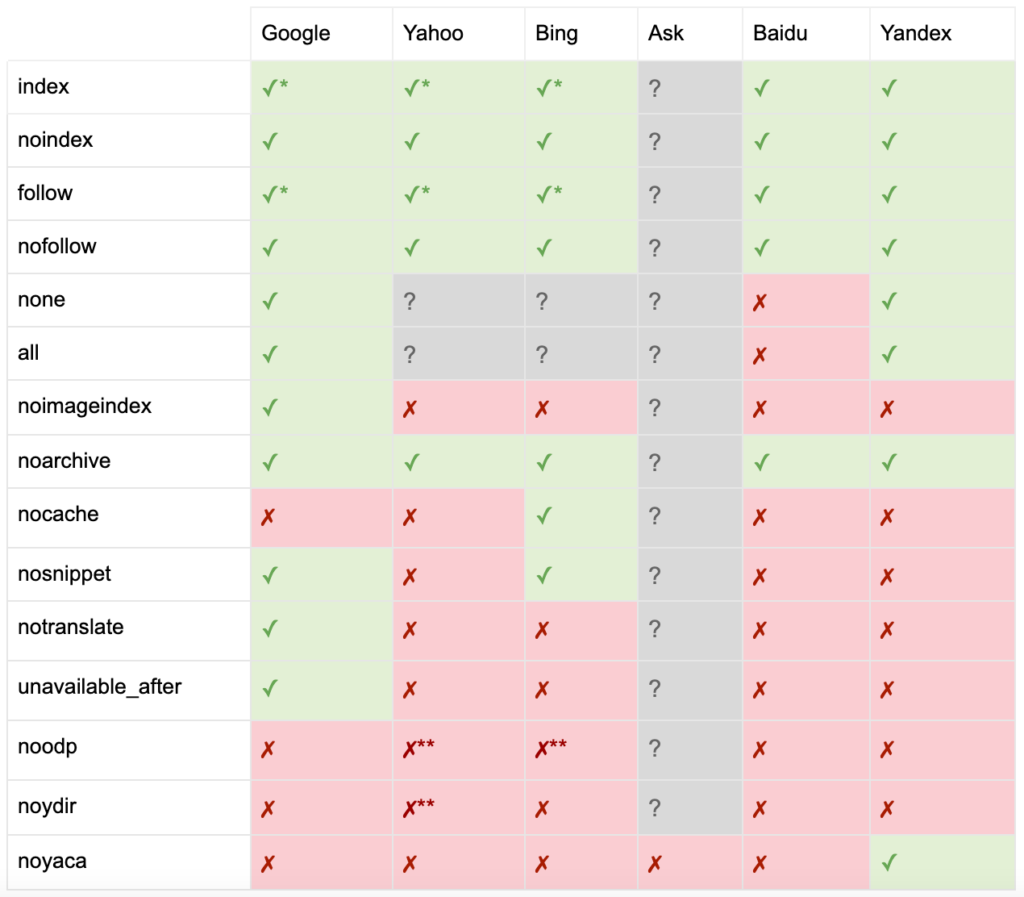
* La mayoría de los motores de búsqueda no tienen documentación específica para esto, pero se supone que la compatibilidad con parámetros de exclusión (p. ej., nofollow) implica la compatibilidad con el equivalente positivo (p. ej., follow).
** Si bien los atributos noodp y noydir aún pueden ser 'compatibles', los directorios ya no existen y es probable que estos valores no hagan nada.
Por lo general, las etiquetas de robots se establecerán en "indexar, seguir". Algunos SEO consideran que agregar esta etiqueta en el HTML es tan redundante como predeterminado. El contraargumento es que una especificación clara de las directivas puede ayudar a evitar cualquier confusión humana.

Tenga en cuenta: las URL con una etiqueta "noindex" se rastrearán con menos frecuencia y, si está presente durante mucho tiempo, eventualmente llevará a Google a no seguir los enlaces de la página.
Es raro encontrar un caso de uso para "no seguir" todos los enlaces en una página con una etiqueta de meta robots. Es más común ver “nofollow” agregado en enlaces individuales usando un atributo de enlace rel=”nofollow”. Por ejemplo, puede considerar agregar un atributo rel=”nofollow” a los comentarios generados por el usuario o enlaces pagados.
Es aún más raro tener un caso de uso de SEO para directivas de etiquetas de robots que no aborden la indexación básica y el comportamiento de seguimiento, como el almacenamiento en caché, la indexación de imágenes y el manejo de fragmentos, etc.
El desafío con las etiquetas de meta robots es que no se pueden usar para archivos que no sean HTML, como imágenes, videos o documentos PDF. Aquí es donde puede recurrir a X-Robots-Tags.
¿Qué son las etiquetas de X-Robots?
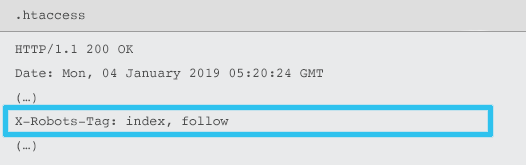
X-Robots-Tag son enviados por el servidor como un elemento del encabezado de respuesta HTTP para una URL dada usando archivos .htaccess y httpd.conf.
Cualquier directiva de metaetiqueta de robots también se puede especificar como una etiqueta X-Robots. Sin embargo, un X-Robots-Tag ofrece cierta flexibilidad y funcionalidad adicional en la parte superior.
Usaría X-Robots-Tag sobre las etiquetas de meta robots si desea:
- Controle el comportamiento de los robots para archivos que no sean HTML, en lugar de solo para archivos HTML.
- Controle la indexación de un elemento específico de una página, en lugar de la página en su conjunto.
- Agregue reglas sobre si una página debe indexarse o no. Por ejemplo, si un autor tiene más de 5 artículos publicados, indexe su página de perfil.
- Aplique las directivas de índice y seguimiento a nivel de todo el sitio, en lugar de una página específica.
- Usa expresiones regulares.
Evite usar meta robots y la etiqueta x-robots en la misma página; hacerlo sería redundante.
Para ver X-Robots-Tags, puede usar la función "Buscar como Google" en Google Search Console.
Directivas de Robots y SEO
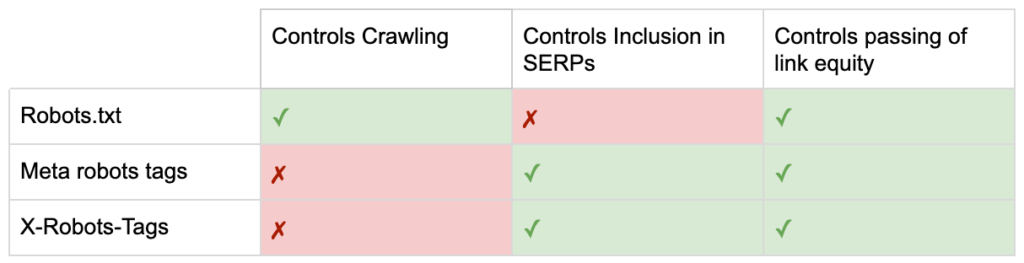
Así que ahora conoces las diferencias entre las tres directivas de robots.
robots.txt se centra en ahorrar presupuesto de rastreo, pero no evitará que una página se muestre en los resultados de búsqueda. Actúa como el primer guardián de su sitio web, dirigiendo a los bots para que no accedan antes de que se solicite la página.
Ambos tipos de etiquetas de robots se enfocan en controlar la indexación y el paso de la equidad del enlace. Las etiquetas meta de Robots solo son efectivas después de que se haya cargado la página . Mientras que los encabezados X-Robots-Tag ofrecen un control más granular y son efectivos después de que el servidor responde a una solicitud de página.
Con este entendimiento, los SEO pueden evolucionar la forma en que usamos las directivas de robots para resolver los desafíos de rastreo e indexación.
Bloqueo de bots para ahorrar ancho de banda del servidor
Problema: al analizar sus archivos de registro, verá que muchos agentes de usuario toman ancho de banda pero devuelven poco valor.
- Rastreadores SEO, como MJ12bot (de Majestic) o Ahrefsbot (de Ahrefs).
- Herramientas que guardan contenido digital sin conexión, como Webcopier o Teleport.
- Motores de búsqueda que no son relevantes en su mercado, como Baiduspider o Yandex.
Solución subóptima: bloquear estas arañas con robots.txt, ya que no se garantiza que se respete y es una declaración bastante pública, lo que podría brindar a las partes interesadas información competitiva.
Enfoque de mejores prácticas: la directiva más sutil de bloqueo de agente de usuario. Esto se puede lograr de diferentes maneras, pero comúnmente se hace editando su archivo .htaccess para redirigir cualquier solicitud de araña no deseada a una página 403 - Prohibida.
Páginas internas de búsqueda del sitio con presupuesto de rastreo
Problema: en muchos sitios web, las páginas internas de resultados de búsqueda del sitio se generan dinámicamente en direcciones URL estáticas, que luego consumen el presupuesto de rastreo y pueden causar contenido delgado o problemas de contenido duplicado si se indexan.
Solución subóptima: no permitir el directorio con robots.txt. Si bien esto puede evitar las trampas de los rastreadores, limita su capacidad de clasificar para búsquedas de clientes clave y para que dichas páginas pasen la equidad de enlace.
Enfoque de mejores prácticas: asigne consultas relevantes y de alto volumen a URL compatibles con motores de búsqueda existentes. Por ejemplo, si busco "teléfono Samsung", en lugar de crear una nueva página para /buscar/teléfono-samsung, redirigir a /teléfonos/samsung.
Cuando esto no sea posible, cree una URL basada en parámetros. A continuación, puede especificar fácilmente si desea que el parámetro se rastree o no en Google Search Console.
Si permite el rastreo, analice si dichas páginas tienen la calidad suficiente para clasificar. De lo contrario, agregue una directiva "noindex, siga" como una solución a corto plazo mientras elabora una estrategia para mejorar la calidad de los resultados para ayudar tanto al SEO como a la experiencia del usuario.
Bloqueo de parámetros con robots
Problema: los parámetros de cadena de consulta, como los generados por la navegación por facetas o el seguimiento, son conocidos por consumir el presupuesto de rastreo, crear URL de contenido duplicado y dividir las señales de clasificación.
Solución subóptima: no permitir el rastreo de parámetros con robots.txt o con una metaetiqueta de robots "noindex", ya que ambos (el primero inmediatamente, el segundo durante un período más largo) evitarán el flujo de equidad de enlace.
Enfoque de mejores prácticas: asegúrese de que cada parámetro tenga una razón clara para existir e implemente reglas de ordenación, que usan claves solo una vez y evitan valores vacíos. Agregue un atributo de enlace rel=canonical a las páginas de parámetros adecuadas para combinar la capacidad de clasificación. Luego configure todos los parámetros en Google Search Console, donde hay una opción más granular para comunicar las preferencias de rastreo. Para obtener más detalles, consulte la guía de manejo de parámetros de Search Engine Journal.
Bloqueo de áreas administrativas o de cuenta
Problema: evita que el motor de búsqueda rastree e indexe cualquier contenido privado.
Solución subóptima: usar robots.txt para bloquear el directorio, ya que esto no garantiza que las páginas privadas queden fuera de las SERP.
Enfoque de mejores prácticas: use protección con contraseña para evitar que los rastreadores accedan a las páginas y una alternativa a la directiva "noindex" en el encabezado HTTP.
Bloqueo de páginas de destino de marketing y páginas de agradecimiento
Problema: a menudo, debe excluir las URL que no están destinadas a la búsqueda orgánica, como el correo electrónico dedicado o las páginas de destino de la campaña de CPC. Del mismo modo, no desea que las personas que no se han convertido visiten sus páginas de agradecimiento a través de SERP.
Solución subóptima: deshabilite los archivos con robots.txt ya que esto no evitará que el enlace se incluya en los resultados de búsqueda.
Enfoque de mejores prácticas: utilice una metaetiqueta "noindex".
Administrar contenido duplicado en el sitio
Problema: algunos sitios web necesitan una copia de contenido específico por razones de experiencia del usuario, como una versión para imprimir de una página, pero quieren asegurarse de que los motores de búsqueda reconozcan la página canónica, no la página duplicada. En otros sitios web, el contenido duplicado se debe a prácticas de desarrollo deficientes, como presentar el mismo artículo para la venta en URL de varias categorías.
Solución subóptima: no permitir las URL con robots.txt evitará que la página duplicada transmita señales de clasificación. La no indexación para robots eventualmente llevará a que Google trate los enlaces como "nofollow" y evitará que la página duplicada transmita cualquier valor de enlace.
Enfoque de mejores prácticas: si el contenido duplicado no tiene ningún motivo para existir, elimine la fuente y redirija 301 a la URL compatible con el motor de búsqueda. Si hay una razón para existir, agregue un atributo de enlace rel=canonical para consolidar las señales de clasificación.
Contenido reducido de las páginas relacionadas con cuentas accesibles
Problema: las páginas relacionadas con la cuenta, como inicio de sesión, registro, carrito de compras, pago o formularios de contacto, a menudo tienen poco contenido y ofrecen poco valor a los motores de búsqueda, pero son necesarias para los usuarios.
Solución subóptima: deshabilite los archivos con robots.txt ya que esto no evitará que el enlace se incluya en los resultados de búsqueda.
Enfoque de mejores prácticas: para la mayoría de los sitios web, estas páginas deben ser muy pocas y es posible que no vea ningún impacto en los KPI al implementar el manejo de robots. Si siente la necesidad, es mejor usar una directiva "noindex", a menos que haya consultas de búsqueda para tales páginas.
Etiquetar páginas con presupuesto de rastreo
Problema: el etiquetado descontrolado consume el presupuesto de rastreo y, a menudo, genera problemas de contenido reducido.
Soluciones subóptimas: No permitir con robots.txt o agregar una etiqueta "noindex", ya que ambos dificultarán la clasificación de las etiquetas relevantes de SEO y (inmediatamente o eventualmente) evitarán el paso de la equidad del enlace.
Enfoque de mejores prácticas: evalúe el valor de cada una de sus etiquetas actuales. Si los datos muestran que la página agrega poco valor a los motores de búsqueda o a los usuarios, 301 los redirige. Para las páginas que sobreviven a la selección, trabaje para mejorar los elementos de la página para que sean valiosos tanto para los usuarios como para los bots.
Rastreo de JavaScript y CSS
Problema: Anteriormente, los bots no podían rastrear JavaScript ni otro contenido multimedia enriquecido. Eso ha cambiado y ahora se recomienda encarecidamente permitir que los motores de búsqueda accedan a los archivos JS y CSS para mostrar páginas de forma opcional.
Solución subóptima: no permitir archivos JavaScript y CSS con robots.txt para ahorrar presupuesto de rastreo puede dar como resultado una indexación deficiente y un impacto negativo en las clasificaciones. Por ejemplo, bloquear el acceso del motor de búsqueda a JavaScript que sirve un anuncio intersticial o redirigir a los usuarios puede verse como encubrimiento.
Enfoque de mejores prácticas: verifique si hay problemas de representación con la herramienta "Obtener como Google" u obtenga una descripción general rápida de qué recursos están bloqueados con el informe "Recursos bloqueados", ambos disponibles en Google Search Console. Si se bloquea algún recurso que podría impedir que los motores de búsqueda rendericen correctamente la página, elimine el archivo robots.txt no permitido.
Rastreador de SEO Oncrawl
 Aprende más
Aprende másLista de verificación de mejores prácticas de robots
Es terriblemente común que un sitio web haya sido eliminado accidentalmente de Google por un error de control de robots.
Sin embargo, el manejo de robots puede ser una poderosa adición a su arsenal de SEO cuando sabe cómo usarlo. Solo asegúrese de proceder sabiamente y con precaución.
Para ayudar, aquí hay una lista de verificación rápida:
- Asegure la información privada mediante el uso de protección con contraseña
- Bloquee el acceso a los sitios de desarrollo mediante la autenticación del lado del servidor
- Restrinja los rastreadores que toman ancho de banda pero ofrecen poco valor con el bloqueo de agente de usuario
- Asegúrese de que el dominio principal y los subdominios tengan un archivo de texto llamado "robots.txt" en el directorio de nivel superior que devuelve un código 200
- Asegúrese de que el archivo robots.txt tenga al menos un bloque con una línea de agente de usuario y una línea de rechazo
- Asegúrese de que el archivo robots.txt tenga al menos una línea del mapa del sitio, ingresada como la última línea
- Valide el archivo robots.txt en el probador de robots.txt de GSC
- Asegúrese de que cada página indexable especifique sus directivas de etiquetas de robots
- Asegúrese de que no haya directivas contradictorias o redundantes entre robots.txt, metaetiquetas de robots, X-Robots-Tags, archivo .htaccess y manejo de parámetros GSC
- Solucione cualquier error de "URL enviada marcada como 'noindex'" o "URL enviada bloqueada por robots.txt" en el informe de cobertura de GSC
- Comprender el motivo de las exclusiones relacionadas con robots en el informe de cobertura de GSC
- Asegúrese de que solo se muestren las páginas relevantes en el informe "Recursos bloqueados" de GSC
Ve a comprobar el manejo de tus robots y asegúrate de que lo estás haciendo bien.