
Rastreo, indexación y Python: todo lo que necesitas saber
Publicado: 2021-05-31Me gustaría comenzar este artículo con una ecuación muy simple: si sus páginas no se rastrean, nunca se indexarán y, por lo tanto, su rendimiento de SEO siempre se verá afectado (y apestará).
Como consecuencia de eso, los SEO deben esforzarse por encontrar la mejor manera de hacer que sus sitios web sean rastreables y proporcionar a Google sus páginas más importantes para indexarlas y comenzar a adquirir tráfico a través de ellas.
Afortunadamente, tenemos muchos recursos que pueden ayudarnos a mejorar la capacidad de rastreo de nuestro sitio web, como Screaming Frog, Oncrawl o Python. Le mostraré cómo Python puede ayudarlo a analizar y mejorar su facilidad de rastreo e indicadores de indexación. La mayoría de las veces, este tipo de mejoras también conducen a mejores clasificaciones, mayor visibilidad en los SERP y, finalmente, más usuarios que ingresan a su sitio web.
1. Solicitud de indexación con Python
1.1. para google
La solicitud de indexación para Google se puede hacer de varias formas, aunque lamentablemente no me convence mucho ninguna de ellas. Te guiaré a través de tres opciones diferentes con sus pros y sus contras:
- Selenium y Google Search Console: desde mi punto de vista y tras probarlo y el resto de opciones, esta es la solución más efectiva. Sin embargo, después de varios intentos, es posible que aparezca una ventana emergente de captcha que lo rompa.
- Hacer ping a un mapa del sitio: definitivamente ayuda hacer que los mapas del sitio se rastreen según lo solicitado, pero no las URL específicas, por ejemplo, en el caso de que se hayan agregado nuevas páginas al sitio web.
- API de indexación de Google: no es muy confiable, excepto para los sitios web de las emisoras y las plataformas de trabajo. Ayuda a aumentar las tasas de rastreo, pero no a indexar URL específicas.
Después de esta breve descripción general de cada método, profundicemos en ellos uno por uno.
1.1.1. Selenium y Google Search Console
Esencialmente, lo que haremos en esta primera solución es acceder a Google Search Console desde un navegador con Selenium y replicar el mismo proceso que seguiríamos manualmente para enviar muchas URL para indexar con Google Search Console, pero de forma automatizada.
Nota: no abuse de este método y envíe una página para su indexación solo si su contenido se ha actualizado o si la página es completamente nueva.
El truco para poder iniciar sesión en Google Search Console con Selenium es acceder primero al OUATH Playground, como expliqué en este artículo sobre cómo automatizar la descarga del informe de estadísticas de rastreo de GSC.
#Importamos estos módulos
tiempo de importación
desde el controlador web de importación de selenio
desde webdriver_manager.chrome importar ChromeDriverManager
de selenium.webdriver.common.keys importar claves
#Instalamos nuestro Driver Selenium
controlador = webdriver.Chrome(ChromeDriverManager().install())
#Accedemos a la cuenta del parque infantil de la OUATH para iniciar sesión en los Servicios de Google
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#Esperamos un poco para asegurarnos de que el renderizado esté completo antes de seleccionar elementos con Xpath e introducir nuestra dirección de correo electrónico.
tiempo.dormir(10)
form1=controlador.find_element_by_xpath('//*[@]')
form1.send_keys("<tu dirección de correo electrónico>")
form1.send_keys(Teclas.ENTER)
#Igual aquí, esperamos un poco y luego introducimos nuestra contraseña.
tiempo.dormir(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<su contraseña>")
form2.send_keys(Teclas.ENTER)
Después de eso, podemos acceder a nuestra URL de Google Search Console:
driver.get('https://search.google.com/search-console?resource_id=your_domain”')
tiempo.dormir(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/entrada[2]')
box.send_keys("tu_URL")
box.send_keys(Teclas.ENTER)
tiempo.dormir(5)
indexación = controlador.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexación.click()
tiempo.dormir(120)
Desafortunadamente, como se explica en la introducción, parece que después de una serie de solicitudes comienza a requerir un captcha de rompecabezas para continuar con la solicitud de indexación. Dado que el método automatizado no puede resolver el captcha, esto es algo que dificulta esta solución.
1.1.2. Hacer ping a un mapa del sitio
Las URL del mapa del sitio se pueden enviar a Google con el método de ping. Básicamente, solo necesitaría realizar una solicitud al siguiente punto final introduciendo la URL de su mapa del sitio como parámetro:
http://www.google.com/ping?sitemap=URL/of/file
Esto se puede automatizar muy fácilmente con Python y solicitudes como expliqué en este artículo.
importar urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" respuesta = urllib.request.urlopen(url)
1.1.3. API de indexación de Google
La API de indexación de Google puede ser una buena solución para mejorar sus tasas de rastreo, pero generalmente no es un método muy efectivo para indexar su contenido, ya que se supone que solo debe usarse si su sitio web tiene JobPosting o BroadcastEvent incrustado en un VideoObject. Sin embargo, si desea probarlo y probarlo usted mismo, puede seguir los siguientes pasos.
En primer lugar, para comenzar con esta API, debe ir a Google Cloud Console, crear un proyecto y una credencial de cuenta de servicio. Después de eso, deberá habilitar la API de indexación desde la Biblioteca y agregar la cuenta de correo electrónico que se proporciona con las credenciales de la cuenta de servicio como propietario de la propiedad en Google Search Console. Es posible que deba usar la versión anterior de Google Search Console para poder agregar esta dirección de correo electrónico como propietario.
Una vez que siga los pasos anteriores, podrá comenzar a solicitar la indexación y desindexación con esta API utilizando el siguiente código:
de oauth2client.service_account import ServiceAccountCredentials
importar httplib2
ÁMBITOS = [ "https://www.googleapis.com/auth/indexing" ]
PUNTO FINAL = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "ruta_a_sus_credenciales.json"
credenciales = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
si las credenciales son Ninguna o credenciales.inválidas:
credenciales = herramientas.run_flow(flujo, almacenamiento)
http = credenciales.autorizar(httplib2.Http())
list_urls = ["https://www.ejemplo.com", "https://www.ejemplo.com/prueba2/"]
para la iteración en el rango (len(list_urls)):
contenido = '''{
'url': "'''+str(lista_urls[iteración])+'''",
'tipo': "URL_ACTUALIZADO"
}''''
respuesta, contenido = http.request(ENDPOINT, method="POST", body=content)
imprimir (respuesta)
imprimir (contenido)Si desea solicitar la desindexación, deberá cambiar el tipo de solicitud de "URL_UPDATED" a "URL_DELETED". El código anterior imprimirá las respuestas de la API con los tiempos de notificación y sus estados. Si el estado es 200, la solicitud se habrá realizado correctamente.
1.2. para Bing
Muchas veces cuando hablamos de SEO solo pensamos en Google, pero no podemos olvidar que en algunos mercados existen otros buscadores predominantes y/u otros buscadores que tienen una cuota de mercado respetable como Bing.
Es importante mencionar desde el principio que Bing ya tiene una característica muy conveniente en las Herramientas para webmasters de Bing que le permite solicitar el envío de hasta 10,000 URL por día en la mayoría de los casos. A veces, su cuota diaria puede ser inferior a 10 000 URL, pero tiene la opción de solicitar un incremento de cuota si cree que necesitaría una cuota mayor para satisfacer sus necesidades. Puedes leer más sobre esto en esta página.
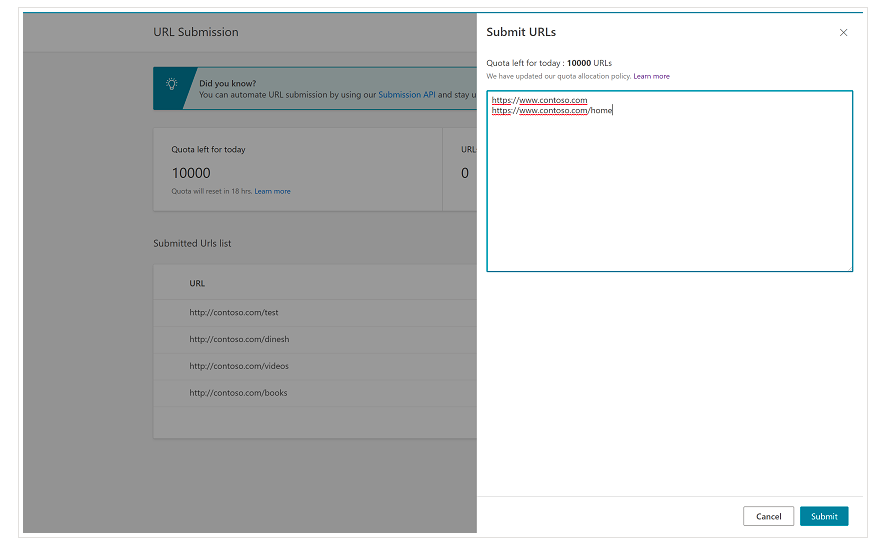
De hecho, esta característica es muy conveniente para envíos masivos de URL, ya que solo necesitará introducir sus URL en diferentes líneas en la herramienta de envío de URL desde la interfaz normal de Bing Webmaster Tools.
1.2.1. API de indexación de Bing
La API de indexación de Bing se puede utilizar con una clave de API que debe introducirse como parámetro. Esta clave de API se puede obtener en Bing Webmaster Tools, yendo a la sección de acceso a la API y luego generando la clave de API.
Una vez que se obtuvo la clave API, podemos jugar con la API con el siguiente código (solo necesita agregar su clave API y la URL de su sitio):
solicitudes de importación
list_urls = ["https://www.ejemplo.com", "https://www.ejemplo/prueba2/"]
para y en list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
encabezados = {'Tipo de contenido': 'aplicación/json; juego de caracteres=utf-8'}
x = solicitudes.post(url, data=myobj, headers=headers)
imprimir(cadena(y) + ": " + cadena(x))Esto imprimirá la URL y su código de respuesta en cada iteración. A diferencia de la API de indexación de Google, esta API se puede utilizar para cualquier tipo de sitio web.
[Estudio de caso] Aumente la visibilidad mejorando la capacidad de rastreo del sitio web para Googlebot
 Lea el estudio de caso
Lea el estudio de caso2. Análisis, creación y carga de sitemaps
Como todos sabemos, los sitemaps son elementos muy útiles para proporcionar a los bots de los motores de búsqueda las URL que queremos que rastreen. Para que los bots de los motores de búsqueda sepan dónde están nuestros mapas de sitio, deben cargarse en Google Search Console y Bing Webmaster Tools e incluirse en el archivo robots.txt para el resto de los bots.
Con Python podemos trabajar principalmente en tres aspectos diferentes relacionados con los sitemaps: su análisis, creación y subida y eliminación desde Google Search Console.
2.1. Importación y análisis de sitemaps con Python
Advertools es una gran biblioteca creada por Elias Dabbas que se puede utilizar para la importación de mapas de sitios, así como para muchas otras tareas de SEO. Podrás importar mapas de sitios en Dataframes simplemente usando:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Esta biblioteca admite mapas de sitio XML normales, mapas de sitio de noticias y mapas de sitio de video.
Por otro lado, si solo está interesado en importar las URL del mapa del sitio, también puede usar las solicitudes de biblioteca y BeautifulSoup.
solicitudes de importación
de bs4 importar BeautifulSoup
r = solicitudes.get("https://www.example.com/your_sitemap.xml")
xml = r.texto
sopa = SopaHermosa(xml)
urls = sopa.find_all("loc")
urls = [[x.text] para x en urls]
Una vez que se ha importado el mapa del sitio, puede jugar con las URL extraídas y realizar un análisis de contenido como lo explica Koray Tugberk en este artículo.
2.2. Creación de sitemaps con Python
También puede utilizar Python para crear sitemaps.xml a partir de una lista de URL, como explicó JC Chouinard en este artículo. Esto puede ser especialmente útil para sitios web muy dinámicos cuyas URL cambian rápidamente y, junto con el método de ping que se explicó anteriormente, puede ser una excelente solución para proporcionar a Google las nuevas URL y hacer que las rastreen e indexen rápidamente.
Recientemente, Greg Bernhardt también creó una aplicación con Streamlit y Python para generar mapas de sitios.
2.3. Cargar y eliminar mapas de sitio de Google Search Console
Google Search Console tiene una API que se puede usar principalmente de dos maneras diferentes: para extraer datos sobre el rendimiento web y manejar mapas de sitios. En esta publicación, nos centraremos en la opción de cargar y eliminar mapas de sitio.
Primero, es importante crear o usar un proyecto existente de Google Cloud Console para obtener una credencial OUATH y habilitar el servicio Google Search Console. JC Chouinard explica muy bien los pasos que debes seguir para acceder a la API de Google Search Console con Python y cómo realizar tu primera solicitud en este artículo. Básicamente, podemos hacer uso completo de su código, pero solo introduciendo un cambio, en los ámbitos agregaremos "https://www.googleapis.com/auth/webmasters" en lugar de "https://www.googleapis.com". /auth/webmasters.readonly”, ya que usaremos la API no solo para leer, sino también para cargar y eliminar mapas de sitio.

Una vez que nos conectamos con la API, podemos comenzar a jugar con ella y enumerar todos los mapas de sitio de nuestras propiedades de Google Search Console con el siguiente código:
para site_url en Verified_sites_urls:
imprimir (sitio_url)
# Recuperar la lista de sitemaps enviados
sitemaps = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
si 'mapa del sitio' en los mapas del sitio:
sitemap_urls = [s['ruta'] para s en sitemaps['sitemap']]
imprimir (" " + "\n ".join(sitemap_urls))
Cuando se trata de mapas de sitio específicos, podemos realizar tres tareas que desarrollaremos en las siguientes secciones: cargar, eliminar y solicitar información.
2.3.1. Subir un mapa del sitio
Para cargar un mapa del sitio con Python, solo necesitamos especificar la URL del sitio y la ruta del mapa del sitio y ejecutar este código:
SITIO WEB = 'supropiedadGSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. Eliminar un mapa del sitio
La otra cara de la moneda es cuando nos gustaría eliminar un mapa del sitio. También podemos eliminar mapas de sitios de Google Search Console con Python usando el método "eliminar" en lugar de "enviar".
SITIO WEB = 'supropiedadGSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. Solicitud de información de los sitemaps
Finalmente, también podemos solicitar información del mapa del sitio usando el método “get”.
SITIO WEB = 'supropiedadGSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=SITIO WEB, feedpath=SITEMAP_PATH).execute()
Esto devolverá una respuesta en formato JSON como: 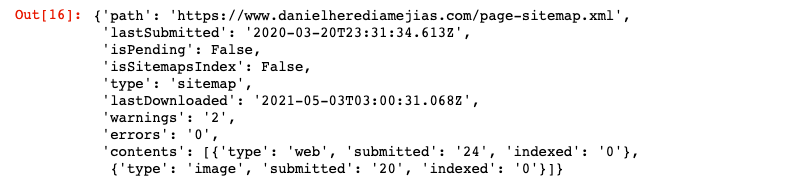
3. Análisis y oportunidades de enlaces internos
Tener una estructura de enlace interna adecuada es muy útil para facilitar el rastreo de su sitio web a los robots de los motores de búsqueda. Algunos de los principales problemas con los que me he encontrado al auditar varios sitios web con configuraciones técnicas muy sofisticadas son:
- Enlaces introducidos con eventos on-click: en resumen, Googlebot no hace clic en los botones, por lo que si tus enlaces se insertan con un evento on-click, Googlebot no podrá seguirlos.
- Enlaces renderizados del lado del cliente: a pesar de que Googlebot y otros motores de búsqueda están mejorando mucho en la ejecución de JavaScript, todavía es algo bastante desafiante para ellos, por lo que es mucho mejor renderizar estos enlaces del lado del servidor y servirlos en HTML sin formato para bots de motores de búsqueda que esperar que ejecuten scripts de JavaScript.
- Ventanas emergentes de inicio de sesión y/o edad: las ventanas emergentes de inicio de sesión y las puertas de edad pueden evitar que los robots de los motores de búsqueda rastreen el contenido que está detrás de estos "obstáculos".
- Uso excesivo de atributos Nofollow: el uso de muchos atributos Nofollow que apunten a páginas internas valiosas evitará que los robots de los motores de búsqueda las rastreen.
- Noindex y follow: técnicamente, la combinación de las directivas noindex y follow debería permitir que los robots de los motores de búsqueda rastreen los enlaces que se encuentran en esa página. Sin embargo, parece que Googlebot deja de rastrear esas páginas con directivas noindex después de un tiempo.
Con Python podemos analizar nuestra estructura de enlaces internos y encontrar nuevas oportunidades de enlaces internos en modo masivo.
3.1. Análisis de enlaces internos con Python
Hace algunos meses escribí un artículo sobre cómo usar Python y la biblioteca Networkx para crear gráficos para mostrar la estructura de enlaces internos de una manera muy visual:
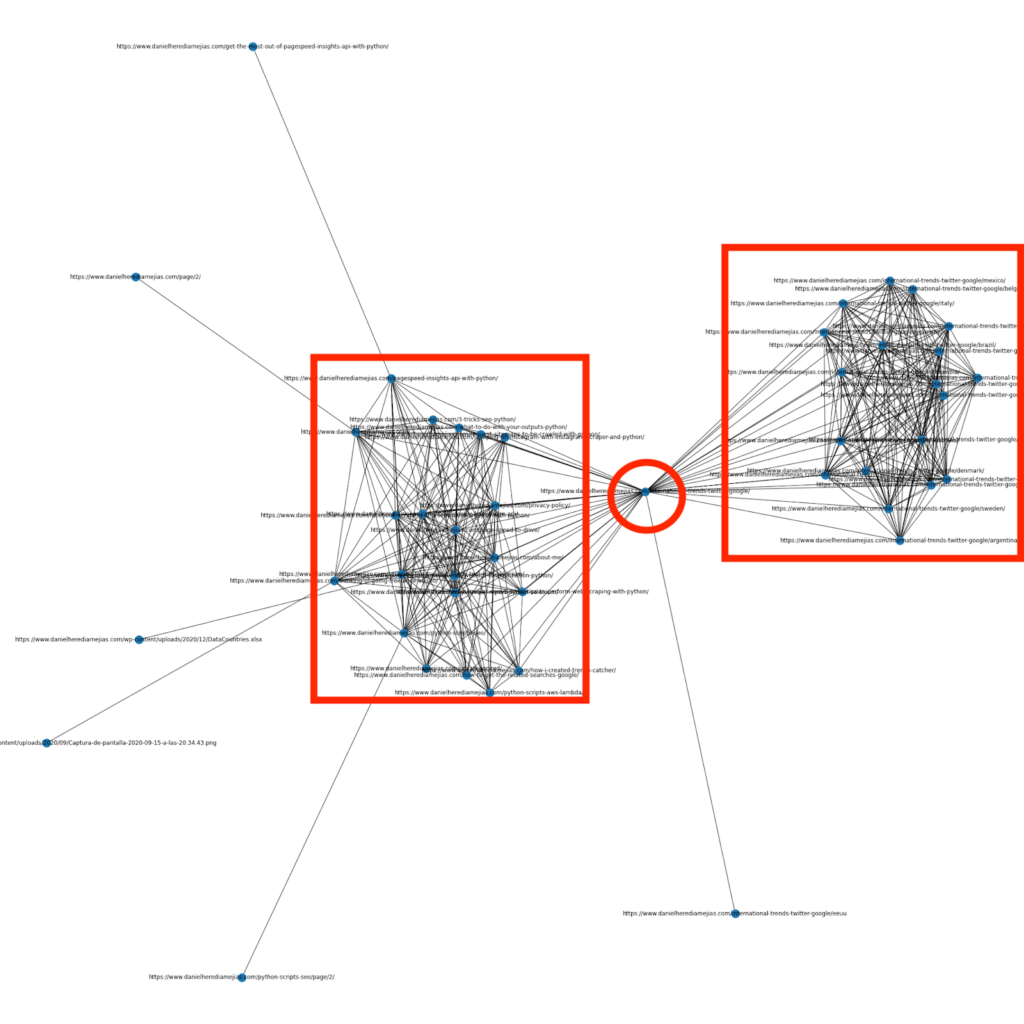
Esto es algo muy similar a lo que puedes obtener de Screaming Frog, pero la ventaja de usar Python para este tipo de análisis es que básicamente puedes elegir los datos que te gustaría incluir en estos gráficos y controlar la mayoría de los elementos del gráfico, como como colores, tamaños de nodos o incluso las páginas que le gustaría agregar.
3.2. Encontrar nuevas oportunidades de enlaces internos con Python
Además de analizar las estructuras del sitio, también puede utilizar Python para encontrar nuevas oportunidades de enlaces internos al proporcionar una cantidad de palabras clave y URL e iterar sobre esas URL en busca de los términos proporcionados en sus piezas de contenido.
Esto es algo que puede funcionar muy bien con las exportaciones de Semrush o Ahrefs para encontrar poderosos enlaces contextuales internos de algunas páginas que ya están clasificadas por palabras clave y, por lo tanto, que ya tienen algún tipo de autoridad.
Puedes leer más sobre este método aquí.
4. Velocidad del sitio web, 5xx y páginas de errores leves
Como lo indica Google en esta página sobre lo que significa el presupuesto de rastreo para Google, hacer que su sitio sea más rápido mejora la experiencia del usuario y aumenta la tasa de rastreo. Por otro lado, también hay otros factores que pueden afectar el presupuesto de rastreo, como las páginas de errores leves, el contenido de baja calidad y el contenido duplicado en el sitio.
4.1. Velocidad de página y Python
4.2.1 Analizando la velocidad de su sitio web con Python
La API de Page Speed Insights es muy útil para analizar el rendimiento de su sitio web en términos de velocidad de página y para obtener una gran cantidad de datos sobre muchas métricas de velocidad de página diferentes (casi 50) además de Core Web Vitals.
Trabajar con Page Speed Insights con Python es muy sencillo, solo se necesita una clave de API y solicitudes para utilizarlo. Por ejemplo:
importar urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=su_URL&strategy=mobile&locale=en&key=suAPIKey" #Tenga en cuenta que puede insertar su URL con el parámetro URL y también puede modificar el parámetro del dispositivo si desea obtener los datos para el escritorio. respuesta = urllib.request.urlopen(url) datos = json.loads(respuesta.leer())
Además, también puede pronosticar con la calculadora Python y Lighthouse Scoring cuánto mejoraría su puntaje de rendimiento general en caso de realizar los cambios solicitados para mejorar la velocidad de su página como se explica en este artículo.
4.2.2 Optimización de imágenes y cambio de tamaño con Python
Relacionado con la velocidad del sitio web, Python también se puede usar para optimizar, comprimir y cambiar el tamaño de las imágenes, como se explica en estos artículos escritos por Koray Tugberk y Greg Bernhardt:
- Automatice la compresión de imágenes con Python sobre FTP.
- Cambiar el tamaño de las imágenes con Python a granel.
- Optimiza imágenes a través de Python para SEO y UX.
4.2. Extracción de errores de 5xx y otros códigos de respuesta con Python
Los errores de código de respuesta 5xx pueden indicar que su servidor no es lo suficientemente rápido para hacer frente a todas las solicitudes que está recibiendo. Esto puede tener un impacto muy negativo en su tasa de rastreo y también puede dañar la experiencia del usuario.
Para asegurarse de que su sitio web funcione como se espera, puede automatizar la descarga del informe de estadísticas de rastreo con Python y Selenium y puede vigilar de cerca sus archivos de registro.
4.3. Extracción de páginas de error suave con Python
Recientemente, Jose Luis Hernando publicó un artículo en honor a Hamlet Batista sobre cómo puedes automatizar la extracción de reportes de cobertura con Node.js. Esta puede ser una solución increíble para extraer las páginas de errores leves e incluso los errores de respuesta 5xx que podrían afectar negativamente su tasa de rastreo.
También podemos replicar este mismo proceso con Python para recopilar en una sola pestaña de Excel todas las URL que proporciona Google Search Console como erróneas, válidas con advertencias, válidas y excluidas.
Primero, debemos iniciar sesión en Google Search Console como se explicó anteriormente en este artículo con Python con Selenium. Después de eso, seleccionaremos todos los cuadros de estado de URL, agregaremos hasta 100 filas por página y comenzaremos a iterar sobre todos los tipos de URL informados por GSC y descargaremos cada archivo de Excel.
tiempo de importación
desde el controlador web de importación de selenio
desde webdriver_manager.chrome importar ChromeDriverManager
de selenium.webdriver.common.keys importar claves
controlador = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
tiempo.dormir(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<sudirección de correo electrónico>")
searchBox.send_keys(Keys.ENTER)
tiempo.dormir(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<tucontraseña>")
searchBox.send_keys(Keys.ENTER)
tiempo.dormir(5)
yourdomain = str(input("Inserte aquí su propiedad o dominio http. Si es un dominio, incluya: 'sc-domain':"))
controlador.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Tipo'] = valores de lista
list_results = df1.valores.tolist()
demás:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Cobertura-Desglose-" + hoy + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Tipo'] = valores de lista
lista_resultados = lista_resultados + df2.valores.tolist()
df = pd.DataFrame(list_results, column= ["URL","TimeStamp", "Tipo"])
df.to_csv('<nombre de archivo>.csv', encabezado=Verdadero, índice=Falso, codificación = "utf-8")
El resultado final se parece a: 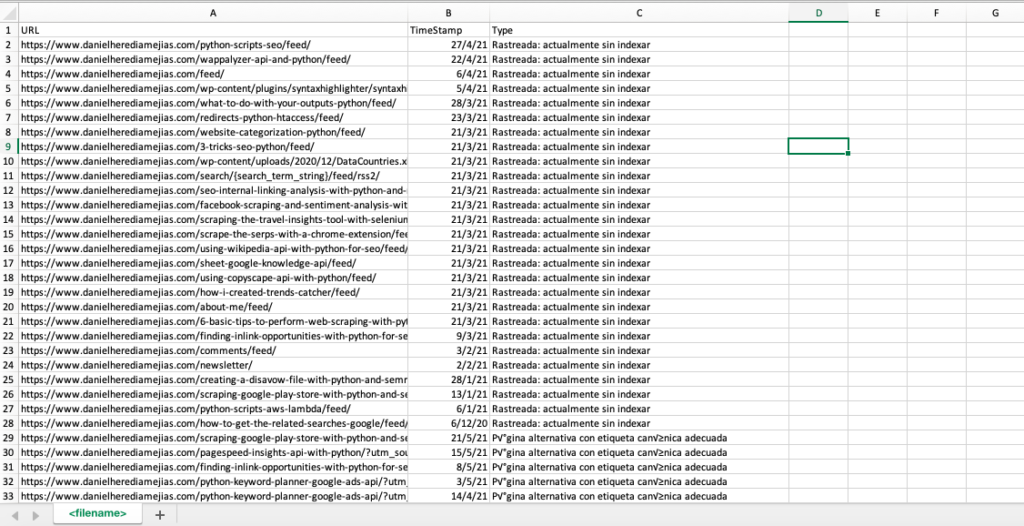
4.4. Análisis de archivos de registro con Python
Además de los datos que están disponibles en el informe de estadísticas de rastreo de Google Search Console, también puede analizar sus propios archivos utilizando Python para obtener mucha más información sobre cómo los robots de los motores de búsqueda rastrean su sitio web. Si aún no está utilizando un analizador de registros para SEO, puede leer este artículo de SEO Garden donde se explica el análisis de registros con Python.
[Ebook] Cuatro casos de uso para aprovechar el análisis de registros de SEO
Descárgalo gratis5. Conclusiones finales
Hemos visto que Python puede ser un gran activo para analizar y mejorar el rastreo y la indexación de nuestros sitios web de muchas maneras diferentes. También hemos visto cómo hacer la vida mucho más fácil al automatizar la mayoría de las tareas tediosas y manuales que requerirían miles de horas de su tiempo.
Debo decir que lamentablemente no me convencen del todo las soluciones que ofrece en estos momentos Google para solicitar la indexación de un gran número de URLs, aunque entiendo hasta cierto punto su miedo a ofrecer una solución mejor: muchos SEOs pueden tender a abusar de ella.
En contraste con eso, está Bing, que ofrece soluciones excepcionales y convenientes para solicitar la indexación de URL a través de API e incluso a través de la interfaz normal de Bing Webmaster Tools.
Debido al hecho de que la API de indexación de Google tiene margen de mejora, otros elementos, como tener un mapa del sitio accesible y actualizado, sus enlaces internos, la velocidad de su página, sus páginas de errores leves y su contenido duplicado y de baja calidad se vuelven aún más importantes para garantizar que su sitio web se rastrea correctamente y sus páginas más importantes están indexadas.