
10 problemas comunes de SEO técnico y cómo detectarlos
Publicado: 2019-06-04Habiendo llevado a cabo servicios de SEO en una variedad de industrias, a veces puede detectar problemas comunes, especialmente cuando trabaja en un CMS común como WordPress, Shopify o SquareSpace.
Aquí he resumido 10 problemas técnicos de SEO bastante comunes con los que puede encontrarse al optimizar un sitio web.
No estoy diciendo que estos problemas definitivamente serán problemáticos para usted o su cliente; muy a menudo, el contexto sigue siendo muy importante. No siempre hay una solución única para todos, pero probablemente sea bueno tener cuidado con los escenarios que se describen a continuación.
1 – Archivo Robots.txt que bloquea el acceso a Googlebot
Esto no es nada nuevo para la mayoría de los SEO técnicos, pero aún así es muy fácil olvidarse de verificar el archivo de robots, y no solo en el momento de realizar una auditoría técnica, sino como una verificación recurrente.
Puede usar una herramienta como Search Console (la versión anterior) para revisar si Google tiene problemas de acceso, o simplemente puede intentar rastrear su sitio como Googlebot con una herramienta como OnCrawl (simplemente seleccione su agente de usuario). OnCrawl obedecerá el archivo robots.txt a menos que usted indique lo contrario.
Exporte los resultados del rastreo y compárelos con una lista conocida de páginas en su sitio y verifique que no haya puntos ciegos del rastreador.
Para mostrar que esto todavía sucede con bastante frecuencia, y en algunos sitios bastante grandes, hace unas semanas noté que la herramienta de prueba de velocidad de Pingdom estaba bloqueada en Google.
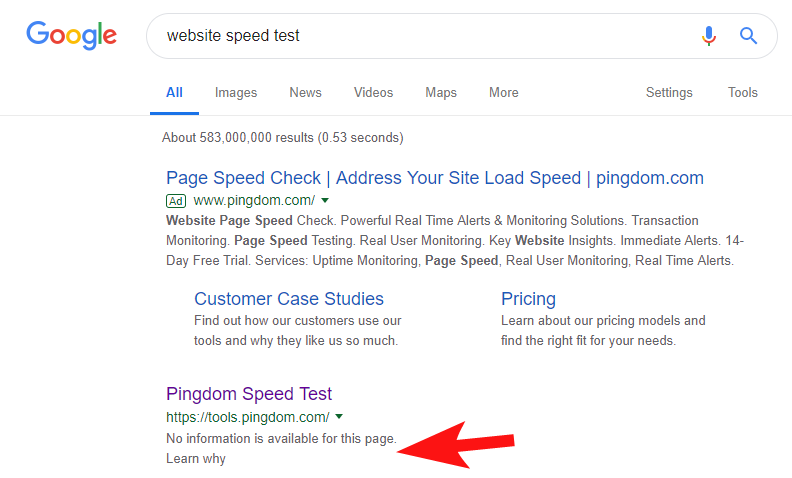
Ver su archivo de robots (y luego intentar rastrear su página desde OnCrawl como Googlebot) confirmó mis sospechas de que estaban bloqueando el acceso a su sitio.
El archivo culpable robots.txt se muestra a continuación:

Me acerqué a ellos con un "FYI" pero no obtuve respuesta, pero unos días después vi que todo había vuelto a la normalidad. ¡Uf, podría volver a dormir tranquilamente!
En su caso, parecía que cada vez que escaneaba su sitio como parte de su auditoría de velocidad, estaba creando una URL que incluía el carácter hash resaltado en el archivo de robots anterior.
Tal vez estos fueron rastreados e incluso indexados de alguna manera, y querían controlar eso (lo cual sería muy comprensible). En este caso, probablemente no probaron completamente el impacto potencial, que al final probablemente fue mínimo.
Aquí están sus robots actuales para cualquiera que esté interesado.

Vale la pena señalar que, en algunos casos, puede acceder a los cambios históricos del archivo robots.txt utilizando Internet Wayback Machine. Según mi experiencia, esto funciona mejor en sitios más grandes, como puede imaginar: el archivador de Wayback Machine los rastrea con mucha más frecuencia.
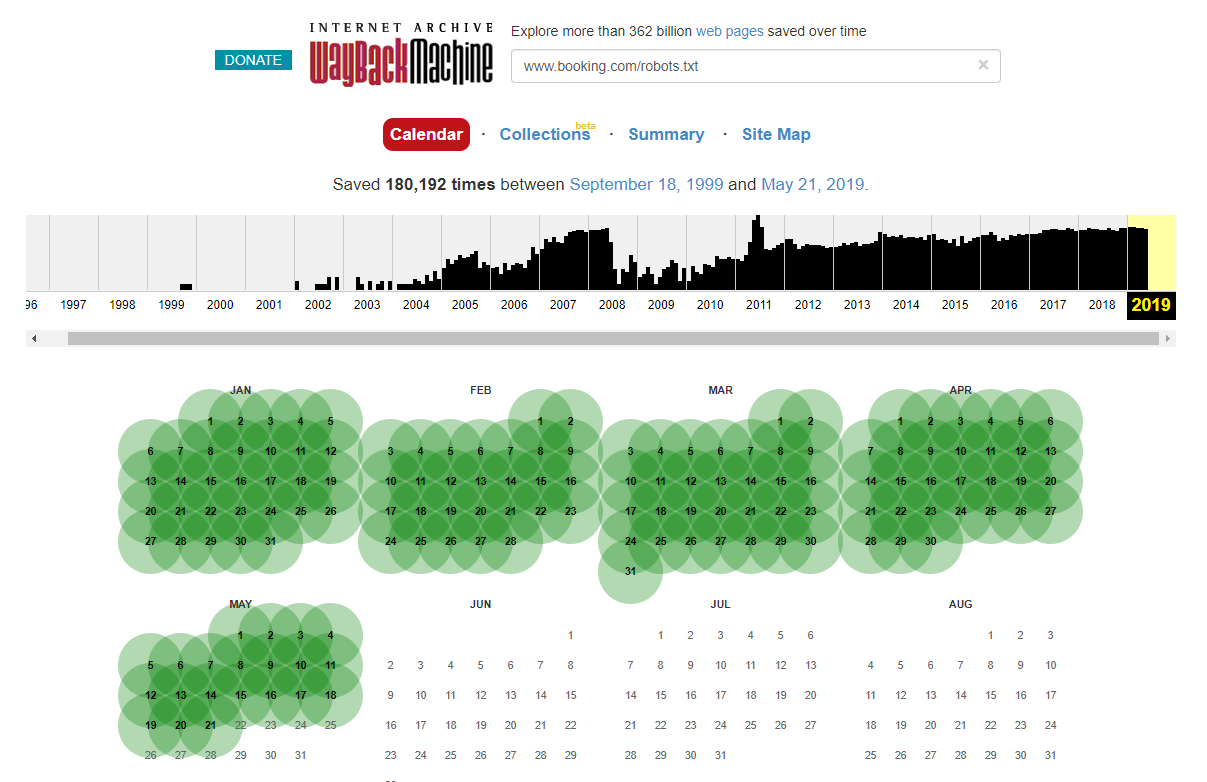
No es la primera vez que veo un archivo robots.txt en vivo causando un poco de caos en las SERPS. Y definitivamente no será el último: es algo tan simple de ignorar (después de todo, es literalmente un archivo), pero verificarlo debe ser parte del programa de trabajo continuo de cada SEO.
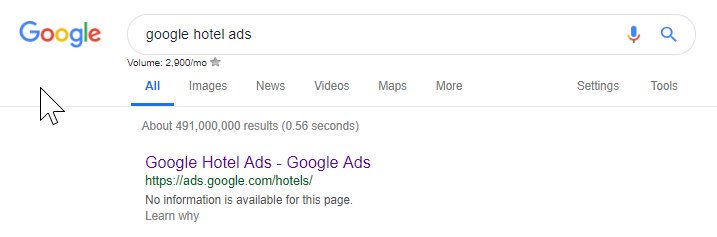
De lo anterior, puede ver que incluso Google desordena su archivo de robots a veces, impidiendo que accedan a su contenido. Esto podría haber sido intencional, pero mirando el idioma de su archivo de robots a continuación, de alguna manera lo dudo.
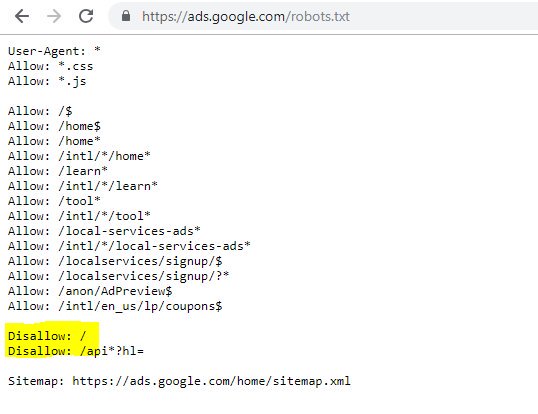
El Disallow resaltado: / en este caso impidió el acceso a cualquier ruta URL; Hubiera sido más seguro enumerar las secciones específicas del sitio que no deberían rastrearse.
2 – Problemas de configuración de dominio a nivel de DNS
Este es sorprendentemente común, pero por lo general es una solución rápida. Este es uno de esos cambios de SEO de bajo costo, *potencialmente* de alto impacto que aman los técnicos de SEO.
A menudo, con las implementaciones de SSL, no veo la versión del dominio que no es WWW configurada correctamente, como el redireccionamiento 302 a la siguiente URL y la formación de una cadena, o en el peor de los casos, no se carga en absoluto.
Un buen ejemplo es el del sitio web de Hotel Football.
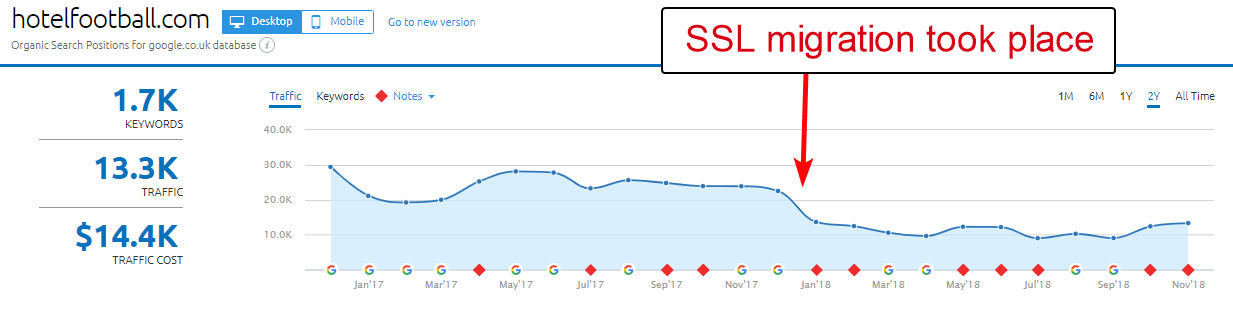
Se sometieron a una migración SSL a principios del año pasado, que no resultó tan buena para ellos a juzgar por el informe de descripción general de dominios de SEMRush anterior.
Me di cuenta de esto hace un tiempo, ya que he trabajado mucho en la industria de viajes y hotelería, y con un gran amor por el fútbol, estaba interesado en ver cómo era su sitio web (¡además de cómo estaba funcionando orgánicamente, por supuesto! ).
En realidad, esto fue muy fácil de diagnosticar: el sitio tenía un montón de backlinks extremadamente buenos, todos apuntando al dominio WWW sin SSL en http://www.hotelfootball.com/
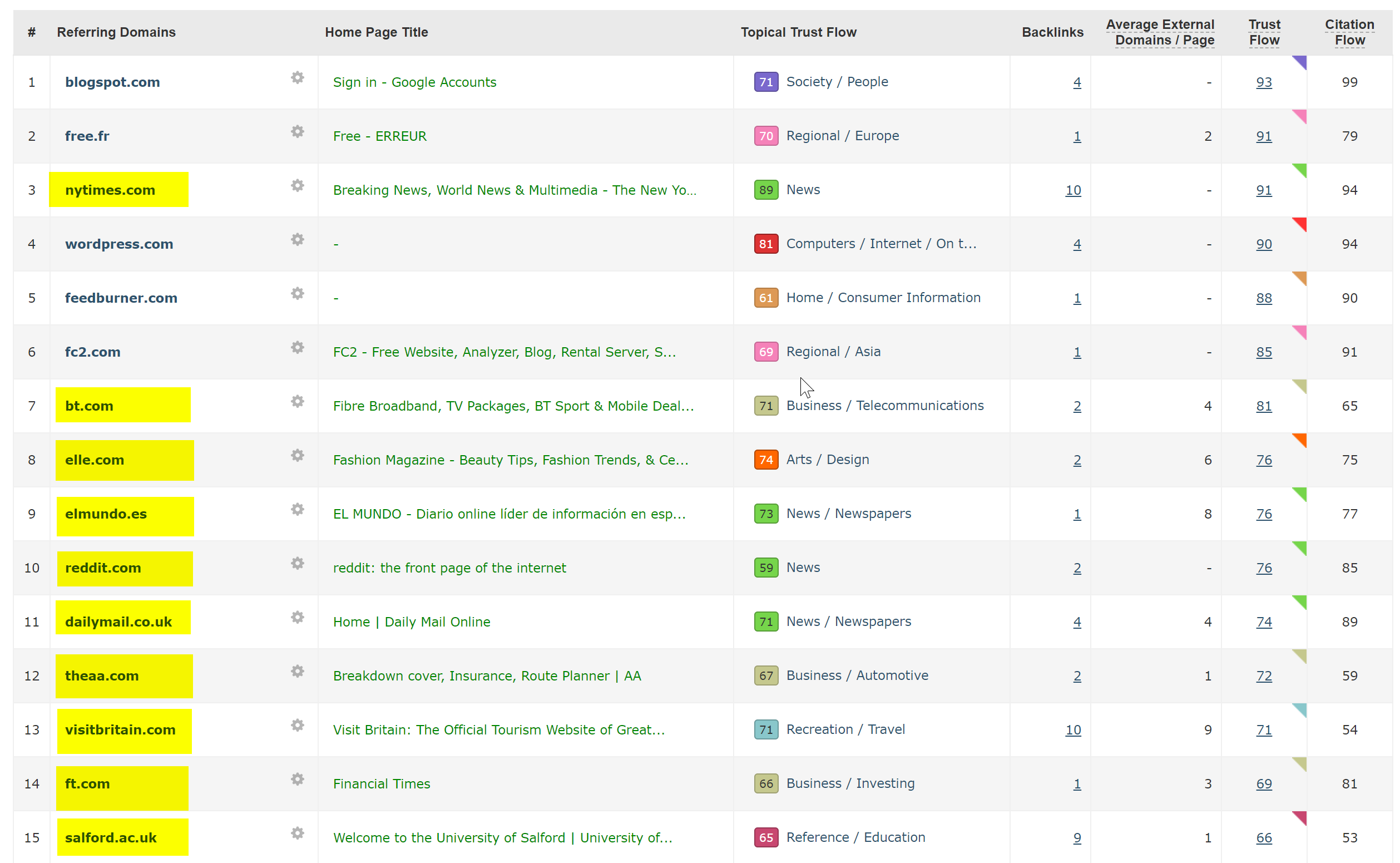
Sin embargo, si intenta acceder a esa URL anterior, no se carga. Ups. Y ha sido así durante unos 18 meses, por lo menos. Me comuniqué con la agencia que administra el sitio a través de Twitter para informarles al respecto, pero no obtuve respuesta.
Con este, todo lo que necesitan hacer es asegurarse de que la configuración de la zona DNS sea correcta, con un registro "A" para la versión "WWW" del dominio, que apunta a la dirección IP correcta (también funcionaría un CNAME). Esto evitará que el dominio no se resuelva.
El único inconveniente, o la razón por la que tarda tanto en resolverse, es que puede ser complicado obtener acceso al panel de administración de dominios de un sitio, o incluso que se han perdido las contraseñas, o no se considera de alta prioridad.
Enviar instrucciones para arreglar a una persona que no es experta en tecnología y que posee las claves del nombre de dominio tampoco es siempre una buena idea.
Estaría muy interesado en ver el impacto orgánico si / cuando puedan hacer el ajuste anterior, especialmente considerando todos los vínculos de retroceso que el dominio no WWW ha acumulado desde que los ex futbolistas del Manchester United, Gary Neville, Ryan Giggs, lanzaron el hotel. y compañía.
Si bien ocupan el puesto número 1 en Google por el nombre de su hotel (como puede imaginar), no parecen tener clasificaciones sólidas para ninguno de sus términos de búsqueda sin marca más competitivos (actualmente están en la posición 10 en Google para "hotel cerca de Old Trafford").
Marcaron un poco de autogol con lo anterior, pero solucionar este problema podría ayudar al menos a resolverlo de alguna manera.
Rastreador de SEO Oncrawl
 Aprende más
Aprende más3 – Páginas no autorizadas dentro del mapa del sitio XML
Nuevamente, este es bastante básico, pero es extrañamente común: al revisar el mapa del sitio XML de un sitio (que casi siempre se encuentra en domain.com/sitemap.xml o domain.com/sitemap_index.xml, puede haber páginas enumeradas aquí que realmente no No tiene ninguna necesidad de ser indexado.
Los culpables típicos incluyen páginas de agradecimiento ocultas (gracias por enviar un formulario de contacto), páginas de destino de PPC que pueden estar causando problemas de contenido duplicado u otras formas de páginas/publicaciones/taxonomías que ya no ha indexado en otro lugar.
Incluirlos de nuevo en el mapa del sitio XML puede enviar señales contradictorias a los motores de búsqueda: solo debe enumerar las páginas que desea que encuentren e indexen, que es principalmente el objetivo del mapa del sitio.
Ahora puede usar el práctico informe dentro de Search Console para averiguar si las páginas se han incluido o no en el mapa del sitio XML de un sitio a través de la opción Inspeccionar URL.
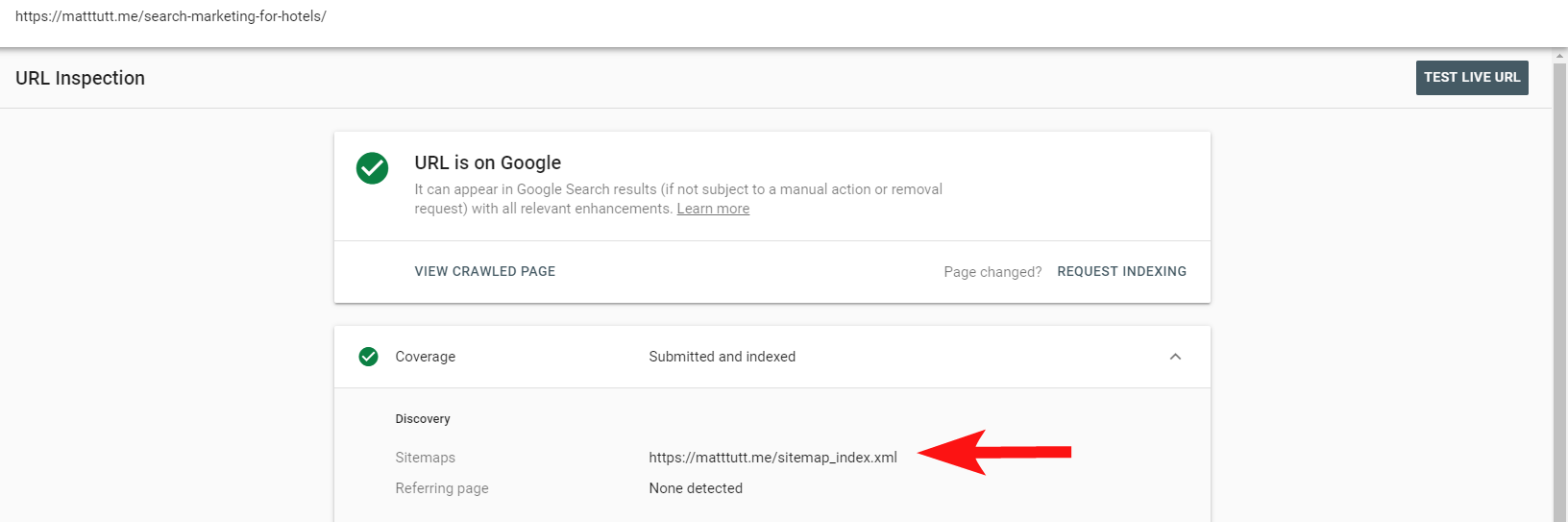
Si tiene un sitio bastante pequeño, probablemente pueda revisar manualmente su mapa del sitio XML dentro de su navegador; de lo contrario, descárguelo y compárelo con un rastreo completo de sus URL indexables.
A menudo, puede detectar este tipo de contenido invaluable y de baja calidad haciendo una búsqueda en site:domain.com en Google para obtener todo lo que se ha indexado.
Vale la pena señalar aquí que esto puede contener contenido antiguo y no se debe confiar en que esté 100% actualizado, pero es una verificación fácil para asegurarse de que no haya un montón de contenido que infle los esfuerzos de SEO y consuma los presupuestos de rastreo.
4 – Problemas con Googlebot al renderizar su contenido
Este es digno de un artículo completo dedicado a él, y personalmente siento que he pasado toda mi vida jugando con la herramienta de búsqueda y renderizado de Google.
Se ha dicho mucho sobre esto (y sobre JavaScript) por parte de algunos SEO muy capaces, por lo que no profundizaré demasiado en esto, pero verificar cómo Googlebot está representando su sitio siempre valdrá la pena.
Ejecutar algunas verificaciones a través de herramientas en línea puede ayudar a descubrir puntos ciegos de Googlebot (áreas en el sitio a las que no pueden acceder), problemas con su entorno de alojamiento, JavaScript problemático que quema recursos e incluso problemas de escalado de pantalla.
Normalmente, estas herramientas de terceros son bastante útiles para diagnosticar el problema (Google incluso le dice cuándo un recurso está bloqueado debido a su archivo de robots, por ejemplo), pero a veces puede encontrarse dando vueltas en círculos.
Para mostrar un ejemplo en vivo de un sitio problemático, me pegaré un tiro en el pie y haré referencia a mi propio sitio web personal, y un tema de WordPress particularmente frustrante que estoy usando.
A veces, cuando ejecuto una inspección de URL desde Search Console, recibo la advertencia "La página no es compatible con dispositivos móviles" (ver más abajo).
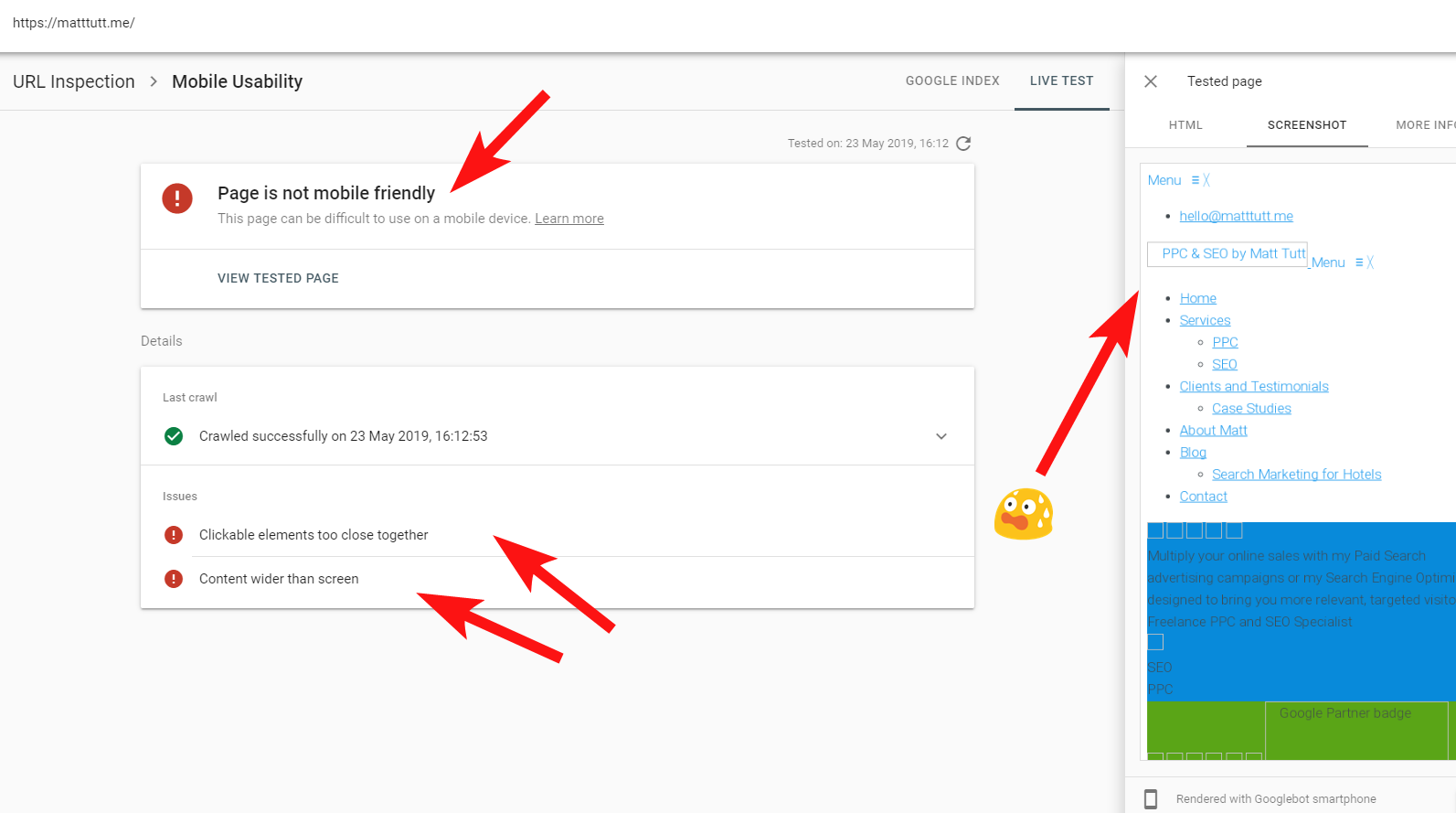
Al hacer clic en la pestaña Más información (arriba a la derecha), se muestra una lista de recursos a los que Googlebot no pudo acceder, que son principalmente CSS y archivos de imagen.
Es probable que esto se deba a que Googlebot no siempre puede dar su "energía" total para mostrar la página; a veces se debe a que Google desconfía de bloquear mi sitio (que es un poco de ellos), y otras veces puedo estar limitado como lo han usado. muchos recursos para buscar y renderizar mi sitio ya.
A veces, debido a lo anterior, vale la pena realizar estas pruebas varias veces a intervalos separados para obtener una historia más real. También recomiendo verificar los registros del servidor si puede, para verificar cómo Googlebot accedió (o no accedió) al contenido de su sitio.
Los estados 404 u otros malos para estos recursos serían claramente una mala señal, especialmente si es consistente.
En mi caso, Google llama al sitio por no ser compatible con dispositivos móviles, lo que se debe principalmente a que ciertos archivos de estilo CSS fallan durante el renderizado, lo que puede hacer sonar las alarmas.
Para hacer las cosas más confusas, cuando se ejecuta la Prueba de compatibilidad móvil de Google o cuando se utiliza cualquier otra herramienta de terceros, no se detectan problemas: el sitio es compatible con dispositivos móviles.
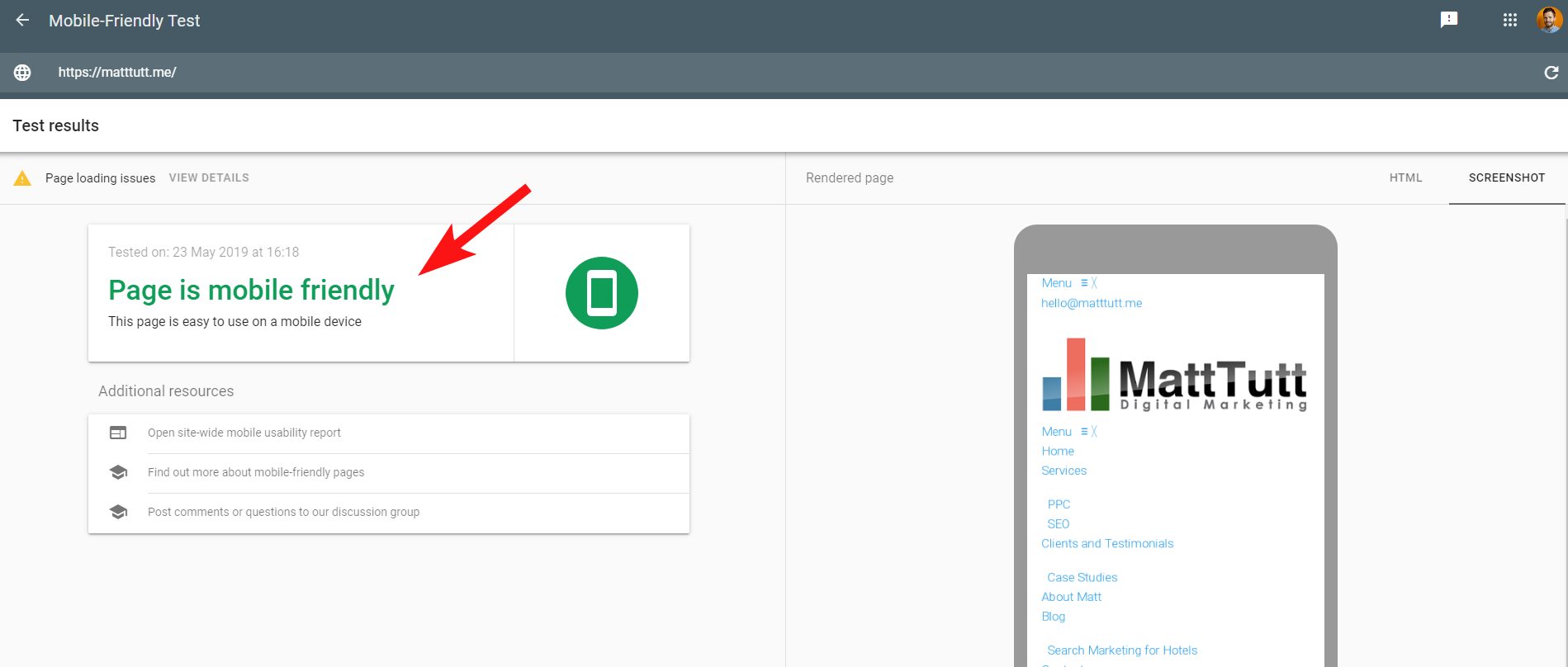
Estos mensajes contradictorios de Google pueden ser difíciles de decodificar para los desarrolladores web y SEO. Para comprender mejor, me comuniqué con John Mueller, quien sugirió que verificara mi servidor web (sin problemas) y que Google puede almacenar en caché el archivo CSS.
Search Console utiliza un Servicio de representación web (WRS) más antiguo en comparación con la Herramienta compatible con dispositivos móviles, por lo que hoy en día tiendo a dar más peso a esta última.
Con Google anunciando un Googlebot más nuevo con las últimas capacidades de representación, todo esto podría configurarse para cambiar, por lo que vale la pena mantenerse actualizado sobre qué herramientas son las mejores para usar en las comprobaciones de representación.
Otro consejo aquí: si desea ver una representación desplazable completa de una página, puede cambiar a la pestaña HTML desde la herramienta de prueba móvil de Google, presionar CTRL+A para resaltar todo el código HTML representado, luego copiar y pegar en un editor de texto y guardar como un archivo HTML.
Abrir eso en su navegador (¡crucemos los dedos, a veces depende del CMS utilizado!) le dará un renderizado desplazable. Y el beneficio de esto es que puede verificar cómo se procesa cualquier sitio; no necesita acceso a Search Console.
5 – Sitios pirateados y backlinks spam
Este es bastante divertido de atrapar y, a menudo, puede colarse en sitios que se ejecutan en versiones anteriores de WordPress u otras plataformas CMS que requieren actualizaciones de seguridad periódicas.
Con este cliente (un spa de belleza), noté que aparecían algunos términos de búsqueda extraños en Search Console.
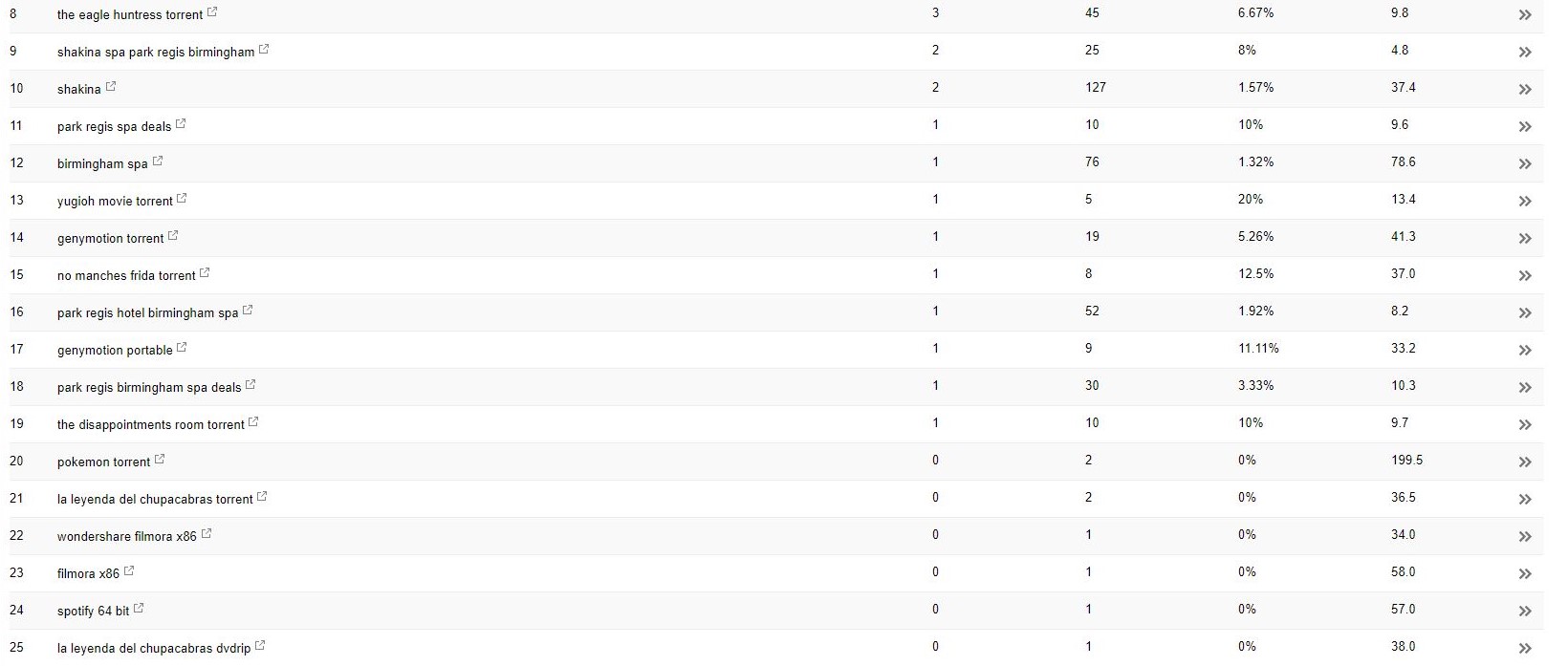
Sorprendentemente, no solo tenían impresiones en Search Console, sino también clics, lo que significa que algo debe haber sido indexado en el dominio.
A juzgar por las consultas, claramente era muy spam y no era algo con lo que el cliente quisiera asociar su negocio.
Al hacer una simple búsqueda de "sitio: dominio.com" en Google, se descubrieron cientos de páginas de supuestos torrents que el cliente supuestamente alojaba en su sitio.
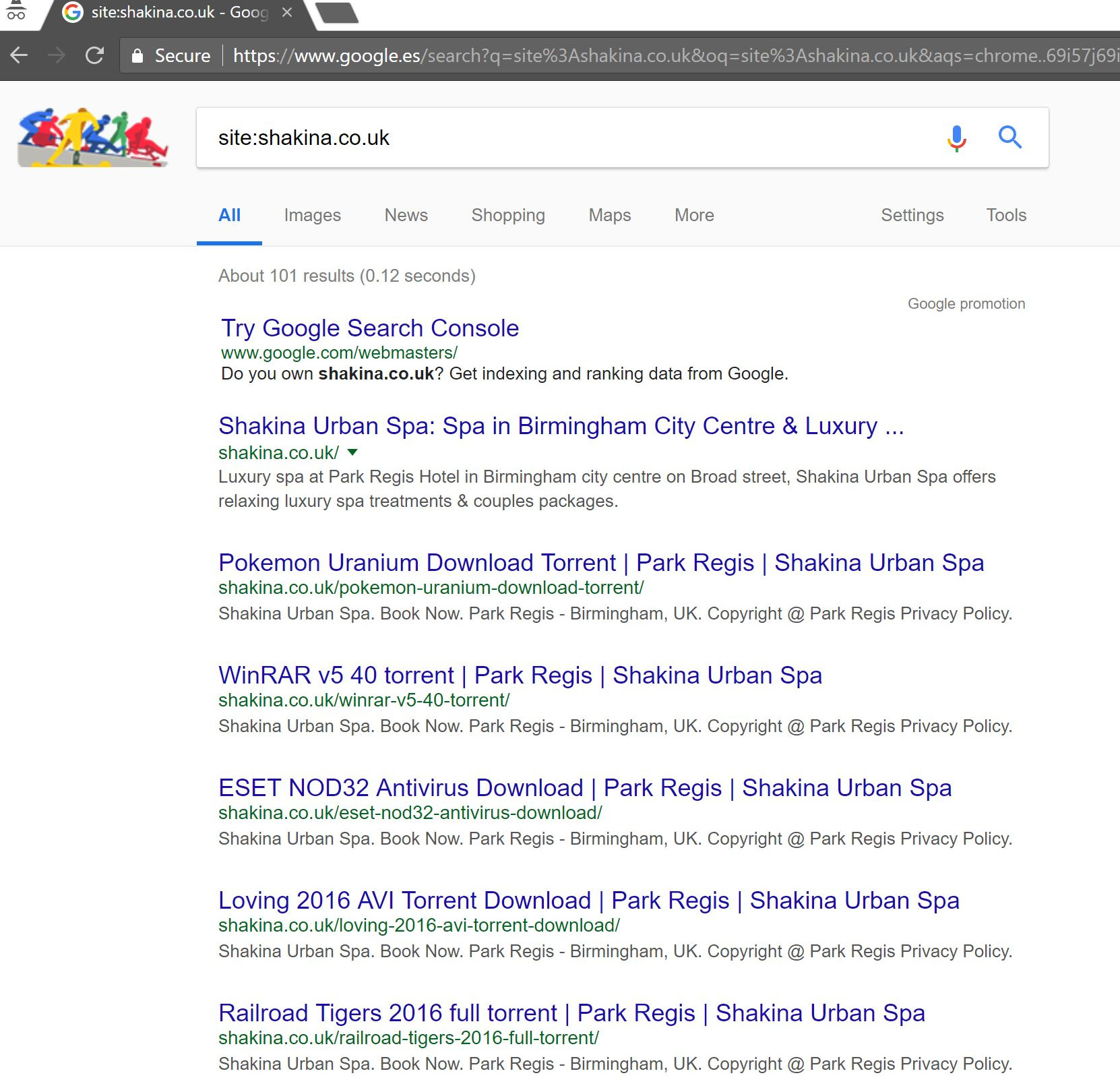
Visitar cualquiera de esas URL en realidad resultó en un 404, pero todavía estaban indexadas (también revisé varios agentes de usuario y todos obtuvieron el mismo error 404).
A continuación, pasé el dominio por el verificador de vínculos de retroceso de Majestic y me dio una larga lista de vínculos de retroceso de muy baja calidad que apuntaban a estas páginas en los sitios de los clientes, lo que probablemente ayudó a indexarlos.
Mirar la Anchor Cloud de los backlinks de Majestic realmente mostró el alcance del problema.


La única solución aquí fue desautorizar todos esos vínculos de retroceso por dominio y luego ejecutar una limpieza general de la instalación de WordPress con la esperanza de aclarar cualquier inyección de código o instalar una copia nueva de WordPress.
Si está realmente preocupado por el contenido indexado en casos como el anterior, también podría proporcionar un código de estado 410 para aclarar realmente las cosas con los rastreadores de búsqueda.
Lo anterior sería adecuado para aquellos sitios que han recibido advertencias legales debido a reclamos de derechos de autor de productores de películas, lo que a veces puede ocurrir en situaciones como esta si el problema no se resuelve rápidamente.
6 – Malas configuraciones de SEO internacional
Estando en España pero navegando por Internet en mi inglés nativo, a menudo me encuentro redirigido automáticamente a una versión en español de un sitio web.
Si bien entiendo la lógica (reside en España, por lo tanto, quiero navegar por el sitio en español), es bastante molesto desde la perspectiva de la experiencia del usuario y, si no se hace correctamente, también puede causar un poco de estragos en su SEO internacional.
Sitios como Google Ads llevan esto a otro nivel: hacen uso de Angular JavaScript para generar contenido dinámicamente en función de mi ubicación, sin siquiera pasar por una redirección de página de ningún tipo y cargar el contenido directamente en el DOM.
Mi método preferido de elección cuando hay varios idiomas disponibles es redirigir 302 a un usuario a un idioma según la configuración de su navegador de Internet.
Por lo tanto, si alguien tiene el alemán como idioma predeterminado en Google Chrome, es probable que se sienta cómodo leyendo el sitio en alemán, independientemente de su ubicación física.
Esto también ayuda a sortear las dificultades cuando alguien vive en una región donde se hablan varios idiomas, como en Suiza, donde se usan el francés, el italiano, el alemán y el romanche.
También es clave para fines de usabilidad garantizar que haya una opción para cambiar de idioma según sus preferencias, en caso de que quieran cambiar.
En un caso, trabajé con un hotel con sede en Barcelona, donde se agregó un script de redirección de lenguaje JavaScript a un sitio sin considerar el impacto de SEO.
Este script redirigió a los usuarios según la configuración de idioma de su navegador (que no es tan malo en sí mismo) a través de una redirección de JavaScript del lado del cliente.
Lamentablemente, en este caso, la secuencia de comandos no se configuró correctamente debido a una configuración extraña de los enlaces permanentes de los sitios, y cuando se combinó con el hecho de que faltaba la etiqueta HTML lang en todas las páginas del sitio, Googlebot se volvió un poco loco...
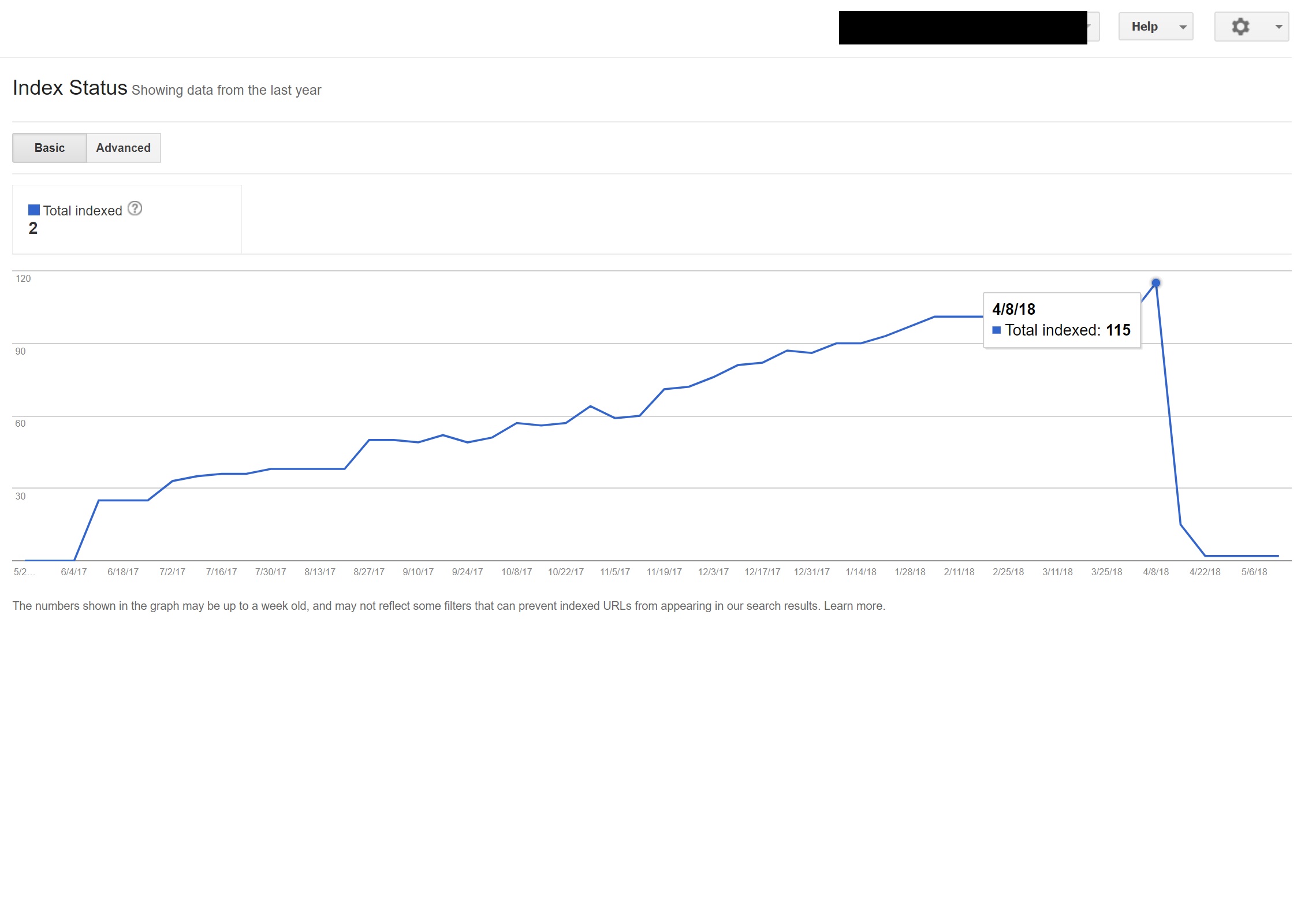
En este ejemplo, Google desindexó casi todo el contenido que no estaba en inglés en el sitio porque estaba siendo redirigido a páginas que no existían, lo que generaba múltiples errores 404.
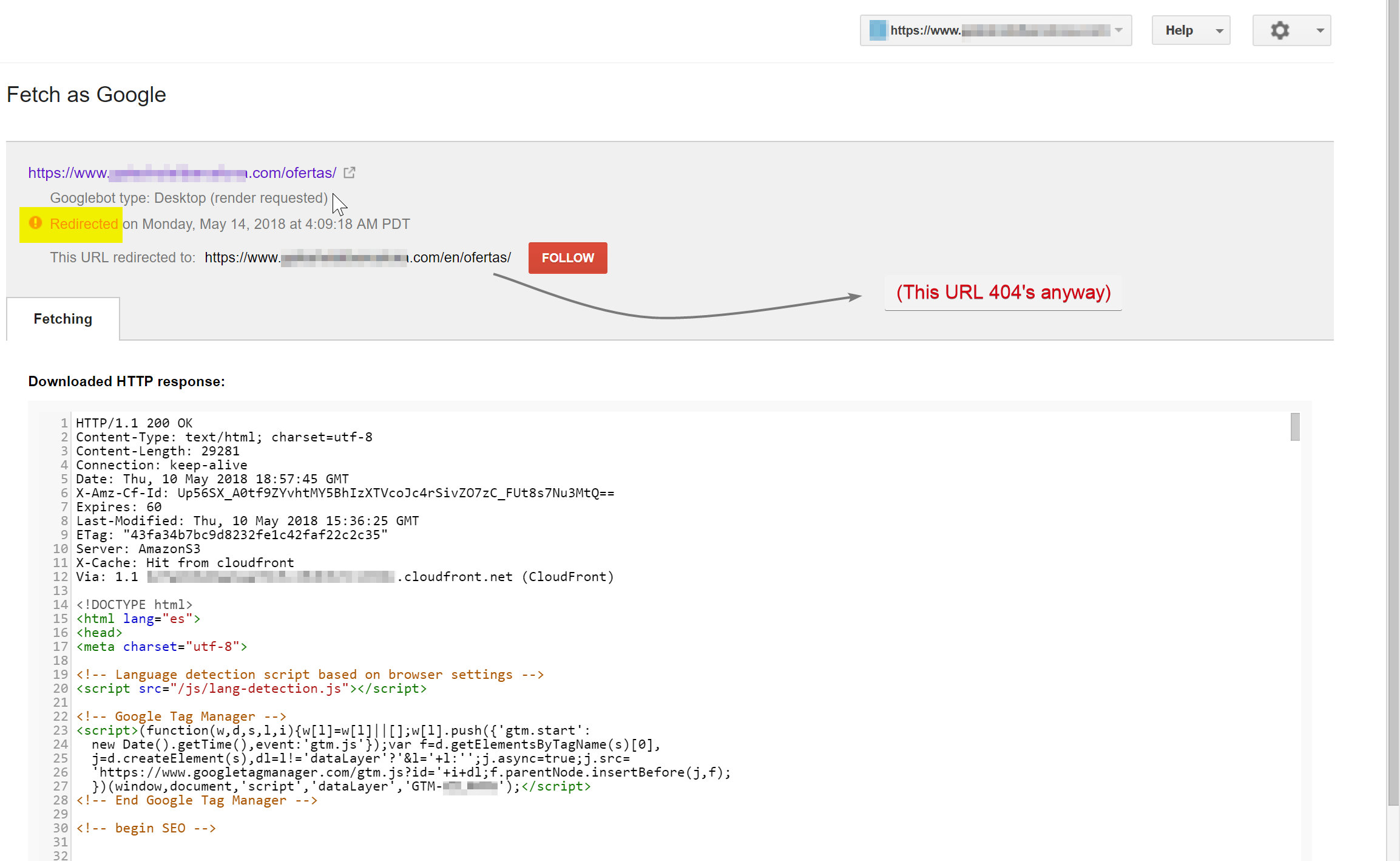
Googlebot intentaba rastrear el contenido en español (que existía en hotelname.com/ofertas) y estaba siendo redirigido a hotelname.com/en/ofertas, una URL inexistente.
Sorprendentemente, en este caso, Googlebot estaba siguiendo todos estos redireccionamientos de JavaScript y, como no pudo encontrar estas URL, se vio obligado a eliminarlas de su índice.
En el caso anterior, pude confirmarlo accediendo a los registros del servidor del sitio, filtrándolos hasta Googlebot y verificando dónde se estaban sirviendo los 404.
La eliminación del script de redirección de JavaScript defectuoso resolvió el problema y, afortunadamente, las páginas traducidas no se desindexaron por mucho tiempo.
Siempre es una buena idea probar las cosas por completo: invertir en una VPN puede ayudar a diagnosticar este tipo de escenarios, o incluso cambiar su ubicación y/o idioma dentro del navegador Chrome.
[Estudio de caso] Manejo de múltiples auditorías de sitios
 Lea el estudio de caso
Lea el estudio de caso7 – Contenido duplicado
El contenido duplicado es un problema bastante común y bien discutido, y hay muchas maneras de verificar si hay contenido duplicado en su sitio: Richard Baxter escribió recientemente un excelente artículo sobre el tema.
En mi caso, el problema es probablemente un poco más simple. He visto regularmente sitios que publican contenido excelente, a menudo como una publicación de blog, pero luego comparten casi instantáneamente ese contenido en un sitio web de terceros como Medium.com.
Medium es un gran sitio para reutilizar el contenido existente para llegar a un público más amplio, pero se debe tener cuidado con la forma en que se aborda.
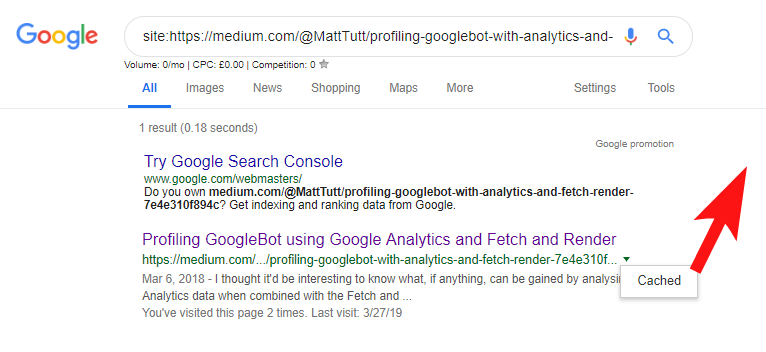
Al importar contenido de WordPress a Medium, durante este proceso, Medium usará la URL de su sitio web como su etiqueta canónica. Entonces, en teoría, debería ayudar darle a su sitio web el crédito por el contenido, como la fuente original.
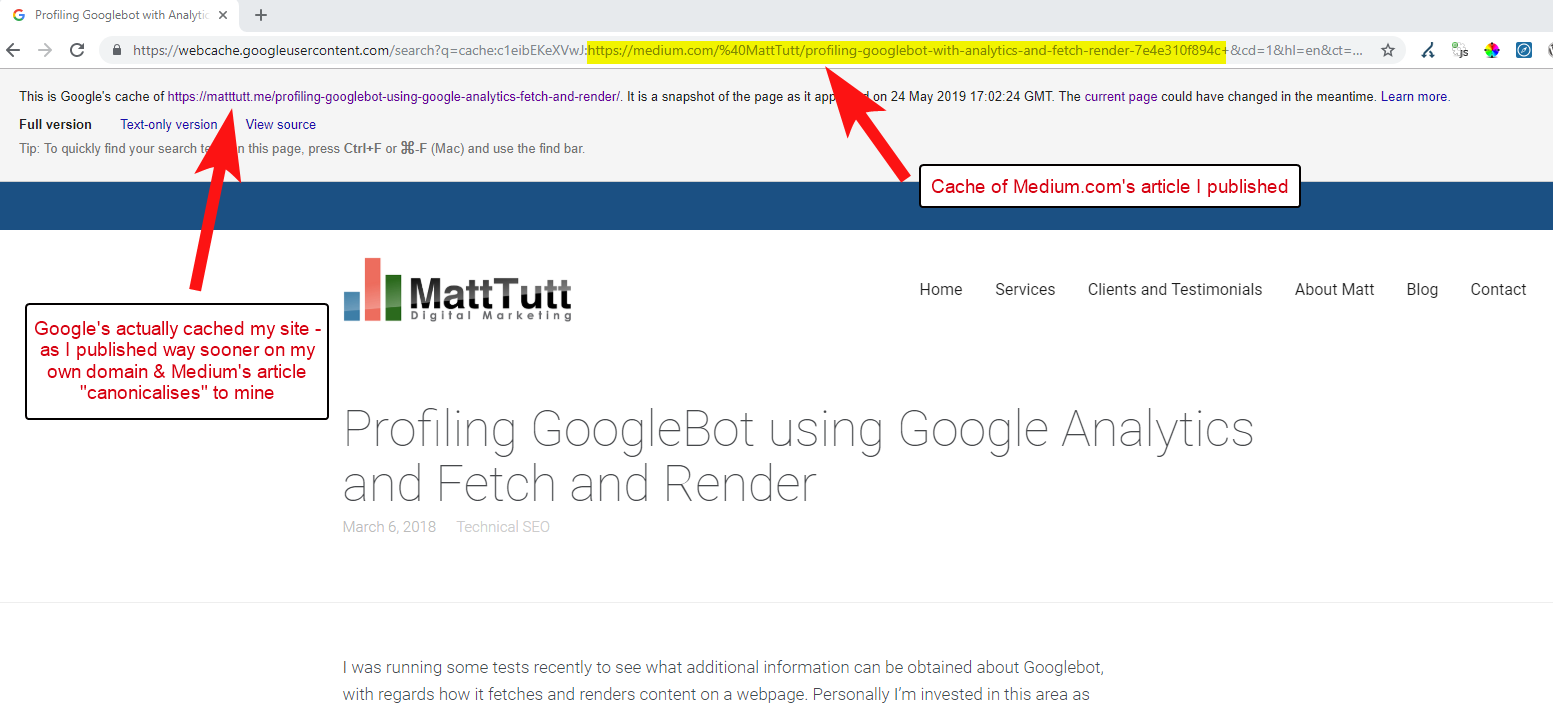
De algunos de mis análisis, aunque no siempre funciona así.
Creo que este es el caso porque cuando se publica un artículo en Medium sin permitir primero que Google rastree e indexe el artículo en su dominio, si el artículo cae bien en Medium (que es un poco impredecible) su contenido se vuelve indexado y asociado con el sitio de Medium a pesar de que apunta canónicamente al tuyo.
Una vez que el contenido se agrega a Medium (y particularmente si es popular), puede garantizar que la pieza se eliminará y se volverá a publicar en la web en otro lugar casi al instante, por lo que nuevamente su contenido se duplicará en otro lugar.
Mientras todo esto sucede, es probable que si su dominio es bastante pequeño en términos de autoridad, es posible que Google ni siquiera haya tenido la oportunidad de rastrear e indexar el contenido que publicó, e incluso podría darse el caso de que el elemento de representación del el rastreo/indexación aún no se ha completado, o hay mucho JavaScript que causa un gran retraso entre el rastreo, la representación y la indexación de ese contenido.
He visto situaciones en las que una gran empresa publica un gran artículo, pero al día siguiente lo publican como artículo de opinión en un blog masivo de noticias de la industria. Además de esto, su sitio tenía un problema en el que el contenido se duplicaba (e indexaba) en https://domain.com y https://www.domain.com.
Unos días después de la publicación, al buscar una frase exacta del artículo entre comillas dentro de Google, el sitio web de la empresa no se veía por ninguna parte. En cambio, el blog autorizado de la industria ocupaba el primer lugar y otros editores ocupaban las siguientes posiciones.
En ese caso, el contenido se ha asociado con el blog de la industria y, por lo tanto, cualquier enlace que gane la pieza beneficiará a ese sitio web, no al editor original.
Si va a reutilizar contenido en cualquier lugar de la web, es probable que se indexe, realmente debería esperar hasta que esté completamente seguro de que Google lo indexó en su propio dominio.
Probablemente trabaje duro para crear y elaborar su contenido, ¡no lo deseche por estar demasiado interesado en volver a publicarlo en otro lugar!
8 – Mala configuración de AMP (falta declaración de URL de AMP)
Solo un puñado de clientes a los que he asistido han optado por probar AMP, tal vez en base a algunos de los muchos estudios de casos financiados por Google sobre su uso.
A veces, ni siquiera sabía que un cliente tenía una versión AMP de su sitio; aparecía un tráfico extraño en los informes de referencia de Analytics, donde la versión AMP del sitio se vinculaba a la versión del sitio que no era AMP.
En ese caso, las versiones de la página AMP no se configuraron correctamente ya que no había ninguna referencia de URL desde el encabezado de las páginas que no son AMP.

Sin decirle a los motores de búsqueda que existe una página de AMP en una URL en particular, no tiene mucho sentido tener una configuración de AMP; el punto es que se indexa y se devuelve en SERPS para usuarios móviles.
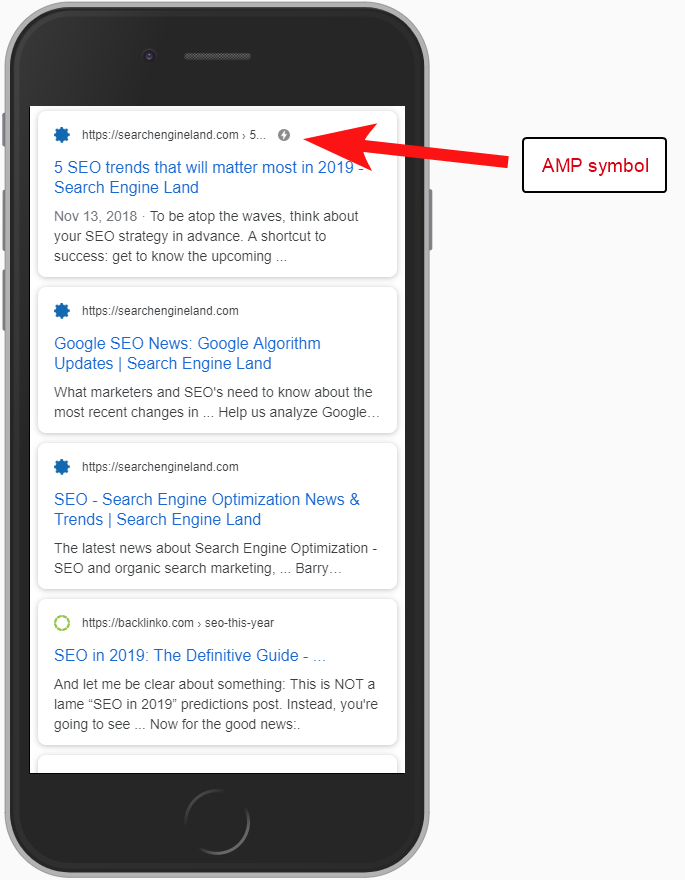
Agregar la referencia a su página que no es de AMP es una forma importante de informar a Google sobre la página de AMP, y es importante recordar que las etiquetas canónicas en las páginas de AMP no deben hacer referencia a sí mismas: se vinculan a la página que no es de AMP.
Y aunque no es realmente una consideración técnica de SEO, vale la pena señalar que aún debe incluir un código de seguimiento en las páginas de AMP si desea poder informar sobre cualquier información de tráfico y comportamiento del usuario.
Por lo general, como parte de mis auditorías de SEO, también me gusta realizar algunas comprobaciones básicas de la implementación de análisis; de lo contrario, es posible que los datos que le han proporcionado no sean tan útiles, especialmente si ha habido una configuración de análisis falsificada.
9 – Dominios heredados que redireccionan 302 o forman una cadena de redireccionamientos
Cuando se trabaja con una gran marca hotelera independiente en los EE. UU., que ha sufrido varios cambios de marca en los últimos años (bastante común en la industria hotelera), es importante controlar cómo se comportan las solicitudes de nombres de dominio anteriores.
Esto es fácil de olvidar, pero podría ser una simple verificación semirregular de tratar de rastrear su sitio anterior usando una herramienta como OnCrawl, o incluso un sitio de terceros que verifique los códigos de estado y los redireccionamientos.
La mayoría de las veces encontrará que el dominio 302 redirige al destino final (301 siempre es la mejor opción aquí) o 302 a una versión de la URL que no es WWW antes de saltar a través de varias redirecciones más antes de llegar a la URL final.
John Mueller de Google había declarado antes que solo siguen 5 redireccionamientos antes de darse por vencidos, mientras que también se sabe que por cada redireccionamiento pasado se pierde parte del valor del enlace. Por esas razones, prefiero ceñirme a las redirecciones 301 que son lo más limpias posible.
Redirect Path by Ayima es una excelente extensión del navegador Chrome que le mostrará los estados de redirección mientras navega por la web.
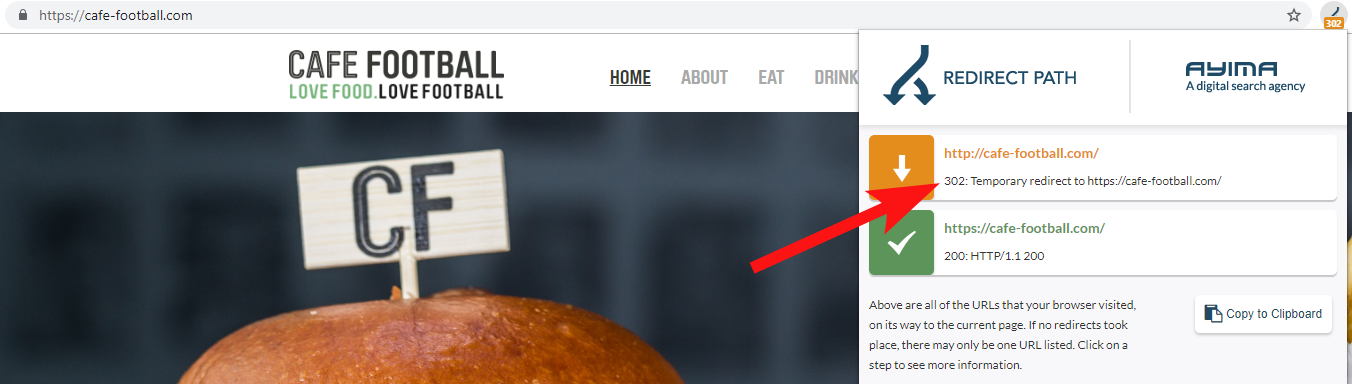
Otra forma en que detecté nombres de dominio antiguos que pertenecen a un cliente es buscando en Google su número de teléfono, usando comillas de coincidencia exacta o partes de su dirección.
Una empresa como un hotel no suele cambiar de dirección (al menos parte de ella de todos modos) y es posible que encuentre directorios/perfiles de empresas antiguos que se vinculen a un dominio antiguo.
El uso de una herramienta de vínculo de retroceso como Majestic o Ahrefs también puede mostrar algunos enlaces antiguos de dominios anteriores, por lo que este también es un buen puerto de escala, especialmente si no está en contacto directo con el cliente.
10 – Tratar mal el contenido de búsqueda interna
En realidad, este es un tema sobre el que he escrito antes aquí en OnCrawl, pero lo incluyo nuevamente porque todavía veo contenido interno problemático que sucede "en la naturaleza" con mucha frecuencia.
Comencé este artículo hablando sobre el problema de la directiva robots.txt de Pingdom que, desde mi exterior, parecía ser una solución para evitar que el contenido que estaban generando fuera rastreado e indexado.
Cualquier sitio que proporcione resultados de búsqueda interna a Google como contenido, o que genere una gran cantidad de contenido generado por el usuario, debe tener mucho cuidado con la forma en que lo hace.
Si un sitio ofrece resultados de búsqueda interna a Google de una manera muy directa, esto puede dar lugar a una sanción manual de algún tipo. Es probable que Google lo vea como una mala experiencia de usuario: buscan X, luego aterrizan en un sitio donde luego tienen que filtrar manualmente lo que quieren.
En algunos casos, creo que puede estar bien publicar contenido interno, solo depende del contexto y las circunstancias. Un sitio de trabajo, por ejemplo, puede querer mostrar los últimos resultados de trabajo que se actualizan casi a diario, por lo que casi tienen que lidiar con esto.
De hecho, es un ejemplo famoso de un sitio de trabajo que quizás lleva esto demasiado lejos, generando todo tipo de contenido basado en consultas de búsqueda populares (solo vea a continuación lo que puede suceder si usa esta táctica).
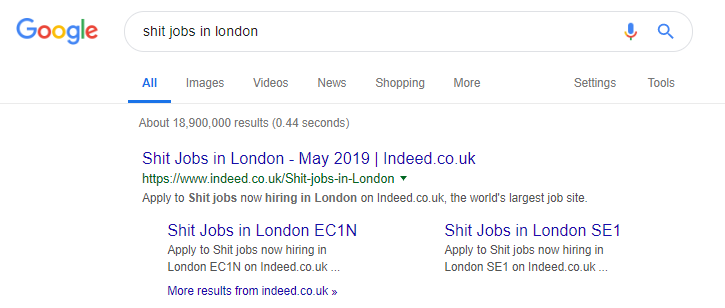
A pesar de esto, según los datos de SEMRush, su tráfico orgánico está funcionando muy bien, pero estas son líneas muy finas, y comportarse así lo pone en alto riesgo de una penalización de Google.
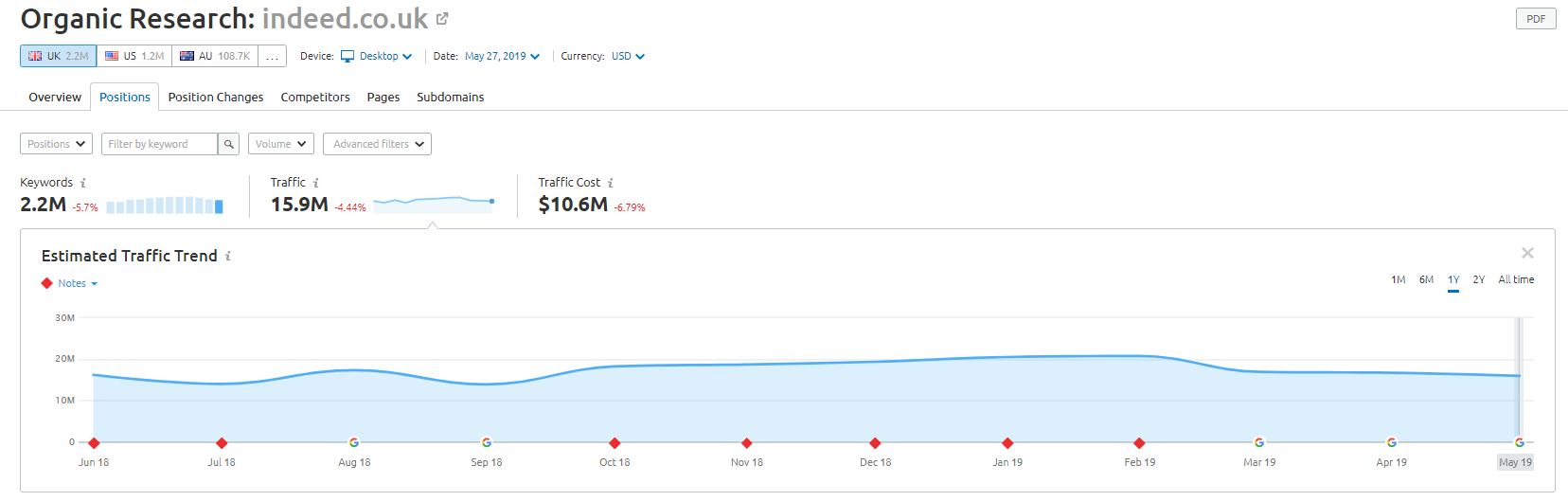
El minorista en línea Wayfair.com es otra marca a la que le gusta navegar cerca del viento. Con millones de URL indexadas (y muchas URL de palabras clave generadas automáticamente), les está yendo muy bien en términos de tráfico orgánico, pero corren un alto riesgo de ser penalizados por publicar contenido de esta manera en los motores de búsqueda.
Al implementar una estructura de sitio adecuada que implica la categorización de todo el contenido, la creación de diferentes jerarquías principal/secundario, incluso el uso de etiquetas u otras taxonomías personalizadas, podría ayudar a los clientes y a la navegación del rastreador de búsqueda.
El uso de trucos como los anteriores podría ganar a corto plazo, pero es poco probable que haga mucho por usted a largo plazo. Esto hace que sea clave tener la estructura del sitio correcta desde el principio, o al menos planificarla adecuadamente con anticipación.
Terminando
Los 10 errores discutidos en este artículo son algunos de los problemas técnicos más comunes que encuentro durante las auditorías del sitio.
Corregir estos errores en su sitio es un primer paso para asegurarse de que su sitio sea técnicamente saludable. Una vez que se corrigen estos problemas, las auditorías técnicas pueden concentrarse en problemas que son específicos de su sitio.