
Canalización de Business Intelligence basada en los servicios de AWS: estudio de caso
Publicado: 2019-05-16En los últimos años, hemos visto un mayor interés en el análisis de big data. Los ejecutivos, gerentes y otras partes interesadas del negocio utilizan Business Intelligence (BI) para tomar decisiones informadas. Les permite analizar información crítica de inmediato y tomar decisiones basadas no solo en su intuición sino en lo que pueden aprender del comportamiento real de sus clientes.
Cuando decide crear una solución de BI efectiva e informativa, uno de los primeros pasos que debe dar su equipo de desarrollo es planificar la arquitectura de canalización de datos. Hay varias herramientas basadas en la nube que se pueden aplicar para construir una canalización de este tipo, y no existe una solución que sea la mejor para todas las empresas. Antes de decidirse por una opción en particular, debe considerar su pila tecnológica actual, el precio de las herramientas y el conjunto de habilidades de sus desarrolladores. En este artículo, mostraré una arquitectura creada con herramientas de AWS que se implementó con éxito como parte de la aplicación Timesheets.
Descripción general de la arquitectura
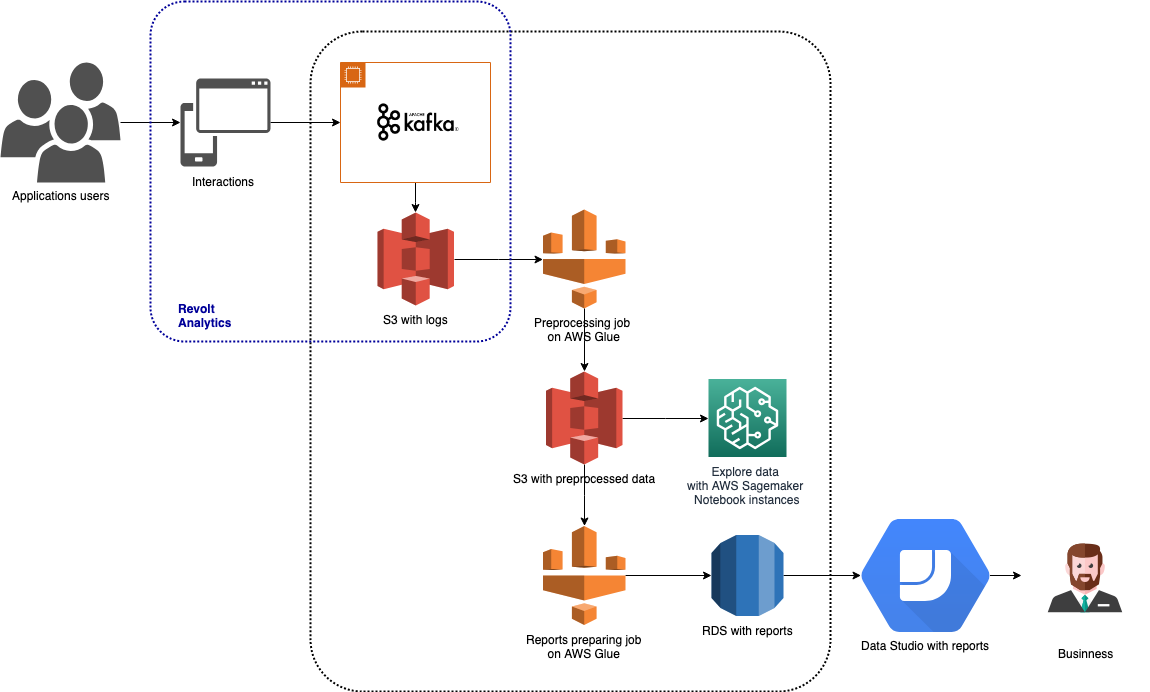
Timesheets es una herramienta para rastrear e informar el tiempo de los empleados. Se puede usar a través de la web, iOS, Android y aplicaciones de escritorio, chatbot integrado con Hangouts y Slack, y acción en el Asistente de Google. Dado que hay muchos tipos de aplicaciones disponibles, también hay muchos datos diversos para rastrear. Los datos se recopilan a través de Revolt Analytics, se almacenan en Amazon S3 y se procesan con AWS Glue y Amazon SageMaker. Los resultados del análisis se almacenan en Amazon RDS y se utilizan para crear informes visuales en Google Data Studio. Esta arquitectura se presenta en el gráfico anterior.
En los siguientes párrafos, describiré brevemente cada una de las herramientas de Big Data utilizadas en esta arquitectura.
Análisis de revuelta
Revolt Analytics es una herramienta desarrollada por Miquido para rastrear y analizar datos de aplicaciones de todo tipo. Para simplificar la implementación de Revolt en los sistemas cliente, se han creado los SDK de iOS, Android, JavaScript, Go, Python y Java. Una de las características clave de Revolt es su rendimiento: todos los eventos se ponen en cola, se almacenan y se envían en paquetes, lo que garantiza que se entreguen de manera rápida y eficiente. Revolt le brinda al propietario de la aplicación la capacidad de identificar a los usuarios y rastrear su comportamiento en la aplicación. Esto nos permite crear modelos de aprendizaje automático que aportan valor, como sistemas de recomendación completamente personalizados y modelos de predicción de abandono, y para perfiles de clientes basados en el comportamiento del usuario. Revolt también proporciona una función de sesionización. El conocimiento sobre las rutas y el comportamiento de los usuarios en las aplicaciones puede ayudarlo a comprender los objetivos y las necesidades de sus clientes.
Revolt se puede instalar en cualquier infraestructura que elijas. Este enfoque le brinda un control total sobre los costos y los eventos rastreados. En el caso de Timesheets presentado en este artículo, se creó en la infraestructura de AWS. Gracias al acceso total al almacenamiento de datos, los propietarios de productos pueden obtener fácilmente información sobre su aplicación y usar esos datos en otros sistemas.
Los SDK de Revolt se agregan a cada componente del sistema de Timesheets, que consta de:
- Aplicaciones de Android e iOS (creadas con Flutter)
- Aplicación de escritorio (construida con Electron)
- Aplicación web (escrita en React)
- Backend (escrito en Golang)
- Hangouts y chats en línea de Slack
- Acción en el Asistente de Google
Revolt proporciona a los administradores de Timesheets conocimientos sobre los dispositivos (p. ej., la marca y el modelo del dispositivo) y los sistemas (p. ej., la versión del sistema operativo, el idioma, la zona horaria) utilizados por los clientes de la aplicación. Además, envía varios eventos personalizados asociados con la actividad de los usuarios en las aplicaciones. En consecuencia, los administradores pueden analizar el comportamiento de los usuarios y comprender mejor sus objetivos y expectativas. También pueden verificar la facilidad de uso de las funciones implementadas y evaluar si estas funciones cumplen con las suposiciones del propietario del producto sobre cómo se usarían.

Pegamento AWS
AWS Glue es un servicio ETL (extracción, transformación y carga) que ayuda a preparar datos para tareas analíticas. Ejecuta trabajos ETL en un entorno sin servidor Apache Spark. Por lo general, consta de los siguientes tres elementos:
- Definición de rastreador : un rastreador se usa para escanear datos en todo tipo de repositorios y fuentes, clasificarlos, extraer información de esquema de ellos y almacenar los metadatos sobre ellos en el catálogo de datos. Puede, por ejemplo, escanear registros almacenados en archivos JSON en Amazon S3 y almacenar su información de esquema en el catálogo de datos.
- Script de trabajo : los trabajos de AWS Glue transforman los datos al formato deseado. AWS Glue puede generar automáticamente un script para cargar, limpiar y transformar sus datos. También puede proporcionar su propia secuencia de comandos de Apache Spark escrita en Python o Scala que ejecutaría las transformaciones deseadas. Podrían incluir tareas como el manejo de valores nulos, sesionización, agregaciones, etc.
- Desencadenadores : los rastreadores y los trabajos se pueden ejecutar bajo demanda o se pueden configurar para que se inicien cuando se produzca un desencadenante específico. Un disparador puede ser un programa basado en el tiempo o un evento (por ejemplo, una ejecución exitosa de un trabajo específico). Esta opción le brinda la capacidad de administrar sin esfuerzo la actualización de los datos en sus informes.
En nuestra arquitectura de Timesheets, esta parte de la canalización se presenta de la siguiente manera:
- Un disparador basado en el tiempo inicia un trabajo de preprocesamiento, que ejecuta la limpieza de datos, asigna registros de eventos apropiados para las sesiones y calcula las agregaciones iniciales. Los datos resultantes de este trabajo se almacenan en AWS S3.
- El segundo disparador está configurado para ejecutarse después de la ejecución completa y exitosa del trabajo de preprocesamiento. Este activador inicia un trabajo que prepara datos que se utilizan directamente en los informes analizados por los propietarios del producto.
- Los resultados del segundo trabajo se almacenan en una base de datos de AWS RDS. Esto los hace fácilmente accesibles y utilizables en herramientas de Business Intelligence como Google Data Studio, PowerBI o Tableau.
AWS SageMaker
Amazon SageMaker proporciona módulos para crear, entrenar e implementar modelos de aprendizaje automático.
Permite entrenar y ajustar modelos a cualquier escala y permite el uso de algoritmos de alto rendimiento proporcionados por AWS. No obstante, también puede usar algoritmos personalizados después de proporcionar una imagen acoplable adecuada. AWS SageMaker también simplifica el ajuste de hiperparámetros con trabajos configurables que comparan métricas para diferentes conjuntos de parámetros del modelo.
En las hojas de tiempo, las instancias de SageMaker Notebook nos ayudan a explorar los datos, probar scripts ETL y preparar prototipos de gráficos de visualización para usar en una herramienta de BI para la creación de informes. Esta solución admite y mejora la colaboración de los científicos de datos, ya que garantiza que trabajen en el mismo entorno de desarrollo. Además, esto ayuda a garantizar que no se almacenen datos confidenciales (que pueden ser parte de la salida de las celdas de los cuadernos) más allá de la infraestructura de AWS porque los cuadernos se almacenan solo en depósitos de AWS S3 y no se necesita un repositorio de Git para compartir el trabajo entre colegas. .
Envolver
Decidir qué herramientas de Big Data y Machine Learning usar es crucial en el diseño de una arquitectura de canalización para una solución de Business Intelligence. Esta elección puede tener un impacto sustancial en las capacidades del sistema, los costos y la facilidad para agregar nuevas funciones en el futuro. Sin duda vale la pena considerar las herramientas de AWS, pero debe seleccionar una tecnología que se adapte a su pila tecnológica actual y a las habilidades de su equipo de desarrollo.
¡Aproveche nuestra experiencia en la construcción de soluciones orientadas al futuro y contáctenos!