
Breadcrumb SEO, Python 3 y Oncrawl: ¡en camino a la automatización!
Publicado: 2021-04-14Aprendamos cómo crear automáticamente una segmentación basada en migas de pan con OnCrawl y Python 3.
¿Qué es la segmentación en Oncrawl?
Oncrawl utiliza segmentaciones para dividir un conjunto de páginas en grupos. Esto hace que sea muy fácil analizar datos de informes de rastreo, análisis de registros y otros informes de análisis cruzado que combinan datos de rastreo con Google Analytics, Google Search Console, AT Internet, Adobe Analytics o Majestic para backlinks.
¿Por qué es importante crear segmentaciones?
Una vez que se completa el rastreo, lo más importante es crear una segmentación personalizada. Esto le permite leer los análisis desde la perspectiva que mejor se adapte a su sitio y su estructura.
Hay muchas formas de segmentar las páginas de su sitio y no hay una forma correcta o incorrecta de hacerlo. Por ejemplo, es posible realizar un seguimiento de la estructura de su sitio en función de la estructura de la URL.
Por ejemplo, este tipo de URL " https://www.mydomain.com/news/canada/politics ", podría segmentarse fácilmente así:
- Un grupo para aislar la página de inicio
- Un grupo para todas las novedades
- Un subgrupo para el directorio de Canadá
- Un sub-subgrupo para el directorio Política
Como ves, es posible crear hasta 3 niveles de profundidad para tus segmentaciones. Esto le permite concentrarse en ciertos grupos o subgrupos en su análisis de SEO, sin tener que cambiar de segmentación.
¿Cómo creo una segmentación básica?
Debes saber que Oncrawl se encarga de crear la primera segmentación, todo él solo. Esto se basa en la "Primera ruta" o el primer directorio encontrado en las URL.
Esto le permite tener un análisis disponible tan pronto como se complete su rastreo.
Puede ser que esta segmentación no refleje la estructura de tu sitio, o que quieras analizar las cosas desde un ángulo diferente.
Así que va a crear una nueva segmentación utilizando lo que llamamos OQL, que significa Oncrawl Query Language. Es algo así como SQL, solo que mucho más simple e intuitivo: 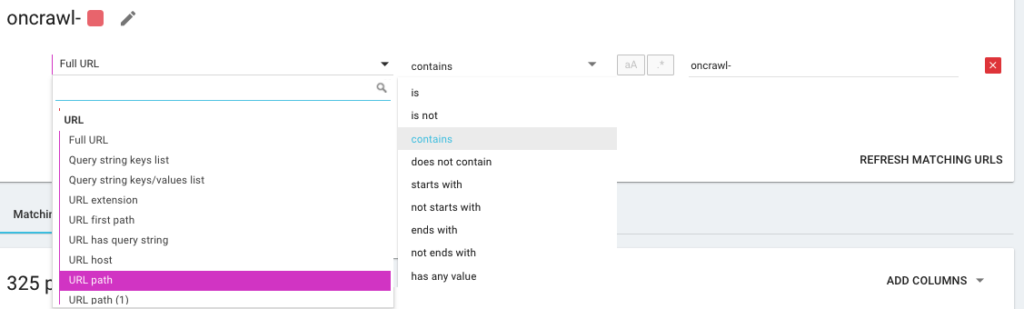
También es posible utilizar operadores de condición AND/OR para ser lo más preciso posible: 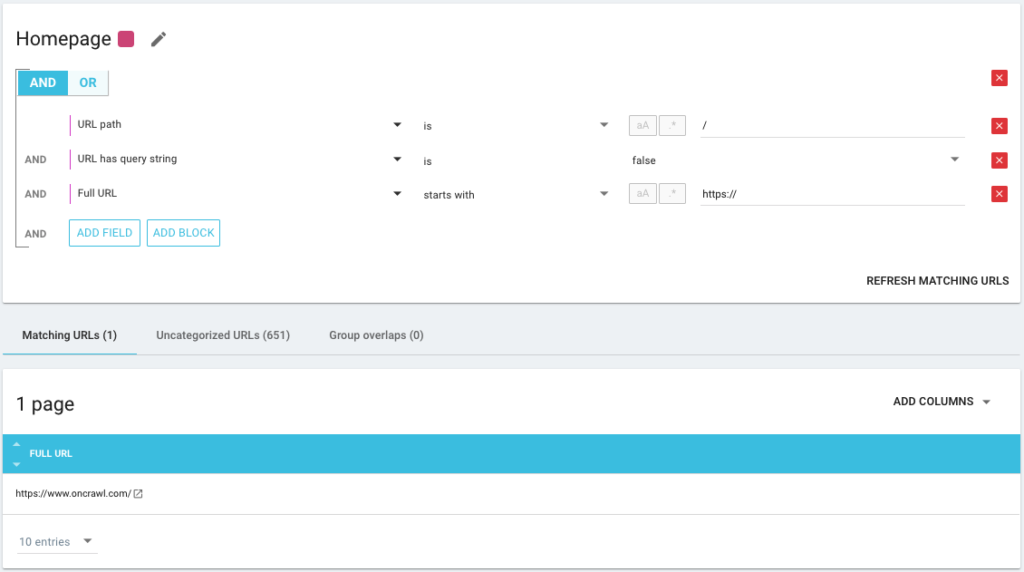
Segmentar mis páginas usando diferentes métodos
Uso de otros KPI
Las segmentaciones basadas en URLs están bien, pero sería perfecto si pudiéramos combinar también otros KPIs, como agrupar URLs que empiezan por /car-rental/ y cuyo H1 tiene la expresión “ Agencias de alquiler de coches ” y otro grupo donde sería el H1 “ Agencias de alquiler de servicios públicos ”, ¿es eso posible?
¡Si es posible! Durante la creación de tus segmentaciones, tienes a tu disposición todos los KPIs que utilizamos, y no solo los del crawler, sino también los de los conectores. ¡Esto hace que la creación de segmentaciones sea muy poderosa y le permite tener ángulos de análisis totalmente diferentes!
Por ejemplo, me encanta crear una segmentación utilizando la posición media de las URL gracias al conector de Google Search Console.
De esta forma, puedo identificar fácilmente las URL en lo profundo de mi estructura que aún funcionan, o las URL cercanas a mi página de inicio que están en la página 2 de Google.
Puedo ver si estas páginas tienen contenido duplicado, una etiqueta de título vacía, si reciben suficientes enlaces... También puedo ver cómo se comporta Googlebot en estas páginas. ¿La frecuencia de rastreo es buena o mala? En definitiva, me ayuda a priorizar y tomar decisiones que tendrán un impacto real en mi SEO y mi ROI.
Datos de seguimiento³
 Aprende más
Aprende másUso de ingesta de datos
Si no está familiarizado con nuestra función de ingesta de datos, lo invito a leer primero este artículo sobre el tema. Esta es otra herramienta muy poderosa que le permite agregar fuentes de datos externas a Oncrawl.
Por ejemplo, puedes añadir datos de SEMrush, Ahrefs, Babbar.tech… La ventaja es que puedes agrupar tus páginas según métricas extraídas de estas herramientas y realizar tu análisis en base a los datos que te interesan, aunque no lo sean. de forma nativa en Oncrawl.
Recientemente, trabajé con un grupo hotelero global. Utilizan un método de puntuación interno para saber si los registros del hotel se completaron correctamente, si tienen imágenes, videos, contenido, etc. Determinan un porcentaje de finalización, que usamos para analizar de forma cruzada los datos del archivo de registro y rastreo.
El resultado nos permite saber si Googlebot dedica más tiempo a las páginas que se rellenan correctamente, saber si algunas páginas con una puntuación superior al 90% son demasiado profundas, no reciben suficientes enlaces… Nos permite demostrar que cuanto mayor sea la score, cuantas más visitas reciben las páginas, más son exploradas por Google, y mejor su posición en el SERP de Google. ¡Un argumento imparable para animar a los hoteleros a rellenar su ficha de hotel!
Cree una segmentación basada en el rastro de migas de pan de SEO
Este es el tema de este artículo, así que vayamos al meollo del asunto. A veces es difícil segmentar las páginas de su sitio, si la estructura de las URL no adjunta las páginas a un directorio determinado. Este suele ser el caso de los sitios de comercio electrónico, donde las páginas de productos están todas en la raíz. Por lo tanto, es imposible saber a partir de la URL a qué grupo pertenece una página.
Para agrupar páginas, tenemos que encontrar una manera de identificar el grupo al que pertenecen. Por lo tanto, tuvimos la idea de recuperar el rastro del seo de la ruta de navegación de cada URL y categorizarlos en función de los valores en el seo de la ruta de navegación, utilizando la función Scraper que ofrece Oncrawl.
Raspado de migas de pan SEO con Oncrawl
Como vimos anteriormente, configuraremos una regla de raspado para recuperar el rastro de migas de pan. La mayoría de las veces es bastante simple porque podemos ir y recuperar la información en un div , luego los campos de cada nivel están en
Listas ul y li : 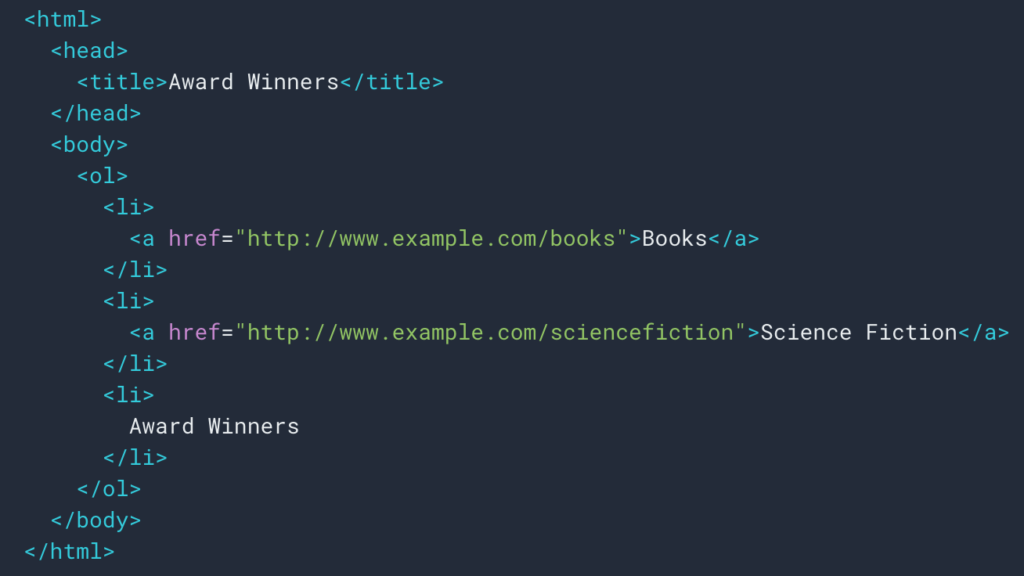
En ocasiones también podemos recuperar fácilmente la información gracias a datos estructurados del tipo Breadcrumb. Por lo tanto, será fácil recuperar el valor del campo "nombre" para cada posición. 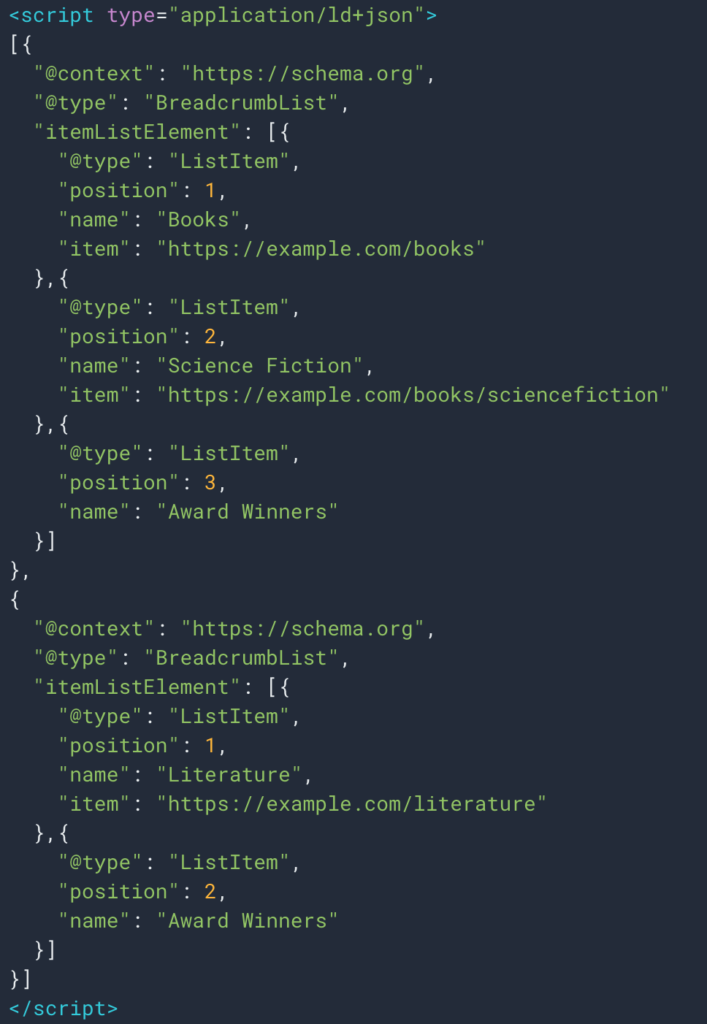
Aquí hay un ejemplo de una regla de raspado que uso: 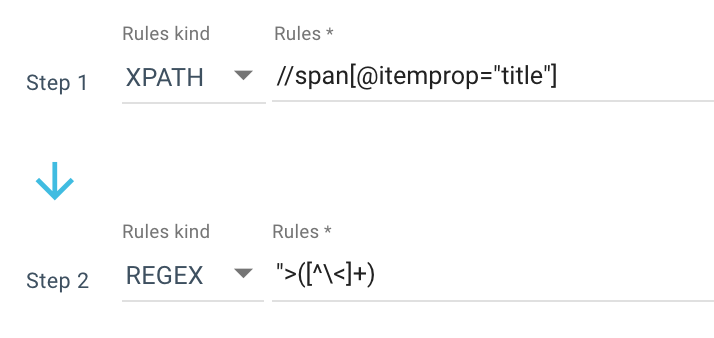
O esta regla: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()

Así que obtengo todo el span itemprop=”title” con Xpath, luego uso una expresión regular para extraer todo después de “> que no es un carácter > . Si desea saber más sobre Regex, le sugiero que lea este artículo sobre el tema y nuestra Hoja de trucos sobre Regex.
Obtengo varios valores como este como salida: 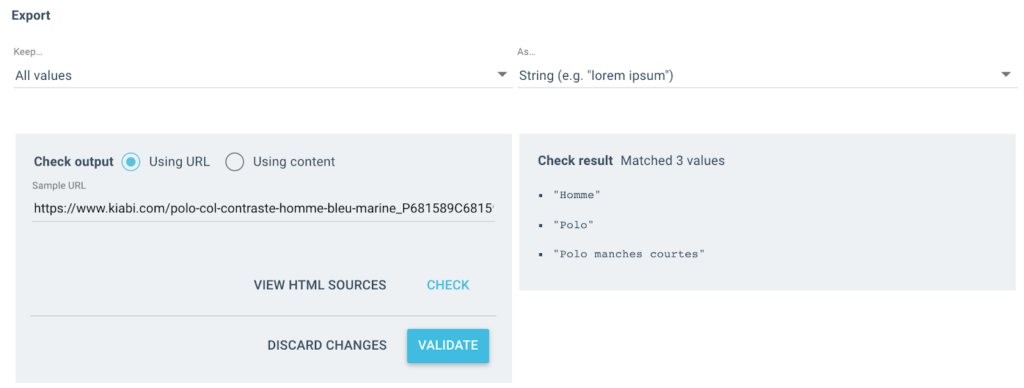
Para la URL probada, tendré un campo "Breadcrumb" con 3 valores:
- Hombre
- camisa polo
- polo de manga corta
importar json
importar al azar
solicitudes de importación
# auténtico
# Dos formas, con x-oncrawl-token de lo que puede obtener en los encabezados de solicitud desde el navegador
# o con token api aquí: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# Establezca la identificación de rastreo donde hay un campo personalizado de ruta de navegación
GATEAR_
# Actualice los elementos de migas de pan prohibidos que no desea obtener en la segmentación
FORBIDDEN_BREADCRUMB_ITEMS = ('Acceso',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
para v en FORBIDDEN_BREADCRUMB_ITEMS.split(',')
]
def random_color():
numero_aleatorio = random.randint(0, 16777215)
número_hex = str(hex(número_aleatorio))
número_hexadecimal = número_hexadecimal[2:].ljust(6, '0')
devuelve f'#{hex_number}'
def valor_a_grupo(valor):
devolver {
'color': color_aleatorio(),
'nombre': valor,
'oql': {'o': [{'field': ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(diccionario, nivel=0):
ret = {
"icono": "panel de control",
"transponible": Falso,
"name": "Breadcrumb"
}Ahora que la regla está definida, puedo iniciar mi rastreo y Oncrawl recuperará automáticamente los valores de ruta de navegación y los asociará con cada URL rastreada.
Automatice la creación de la segmentación multinivel con Python
Ahora que tengo todos los valores de migas de pan de SEO para cada URL, usaremos un script de Python de automatización de SEO en un Google Colab para crear automáticamente una segmentación compatible con Oncrawl.
Para el script en sí, usamos 3 bibliotecas que son:
- json (Para generar nuestra segmentación escrita en Json)
- CSV
- random (Para generar códigos de colores hexadecimales para cada grupo)
Una vez que se inicia el script, automáticamente se encarga de crear la segmentación en su proyecto. 
Vista previa de datos en los análisis
Ahora que nuestra segmentación está creada, es posible tener acceso a los diferentes análisis con una vista segmentada basada en mi ruta de navegación. 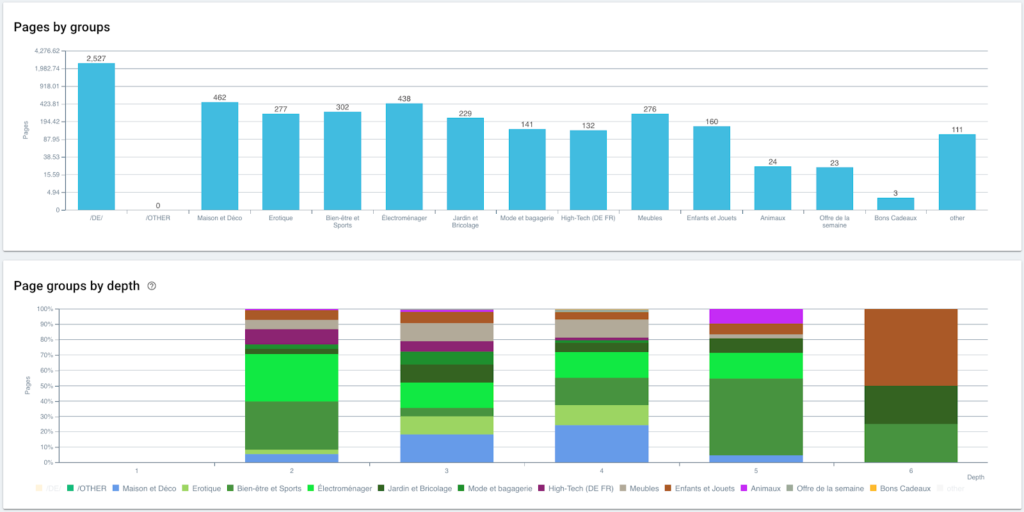
Distribución de páginas por grupo y por profundidad
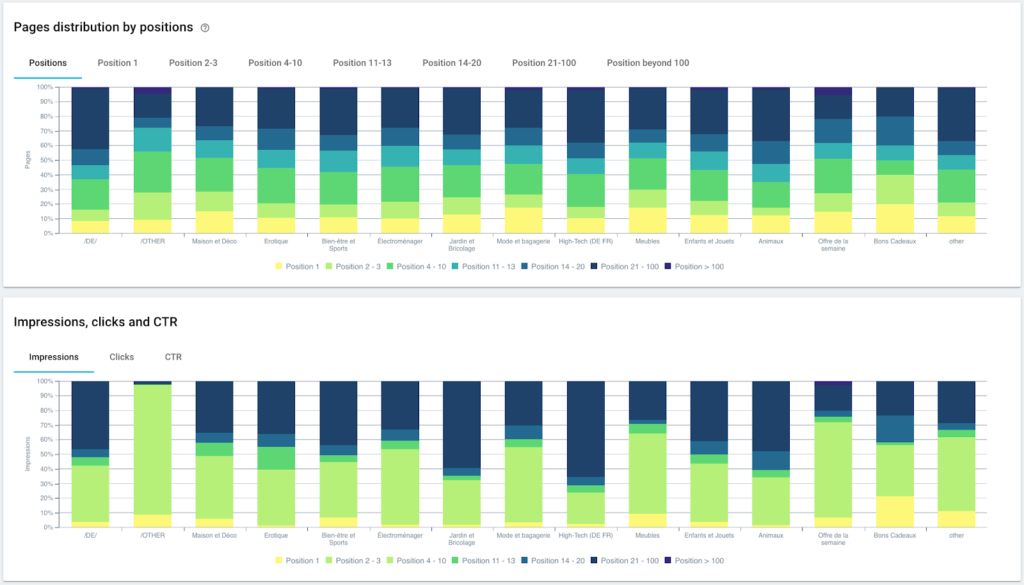
Rendimiento de clasificación (GSC)
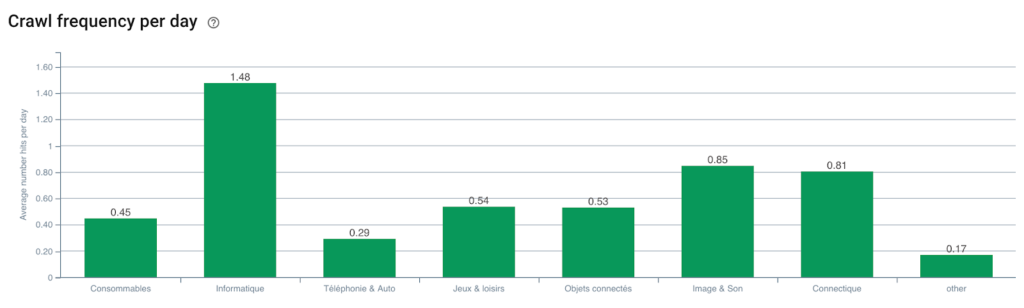
Frecuencia de rastreo del robot de Google
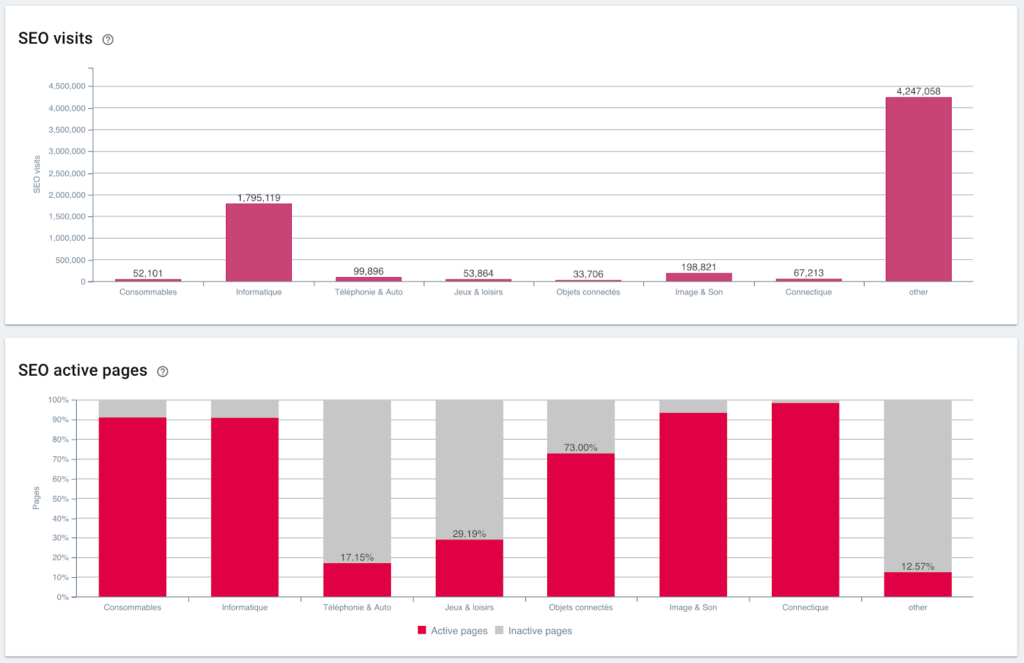
Ratio de visitas SEO y páginas activas
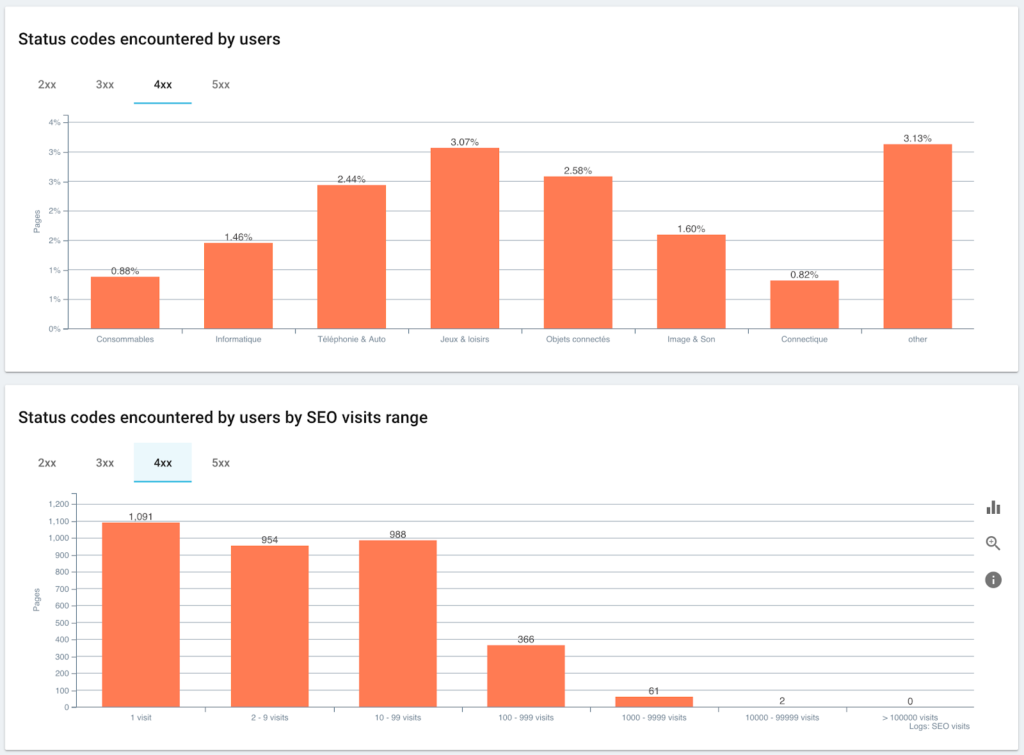
Códigos de estado encontrados por los usuarios frente a sesiones de SEO
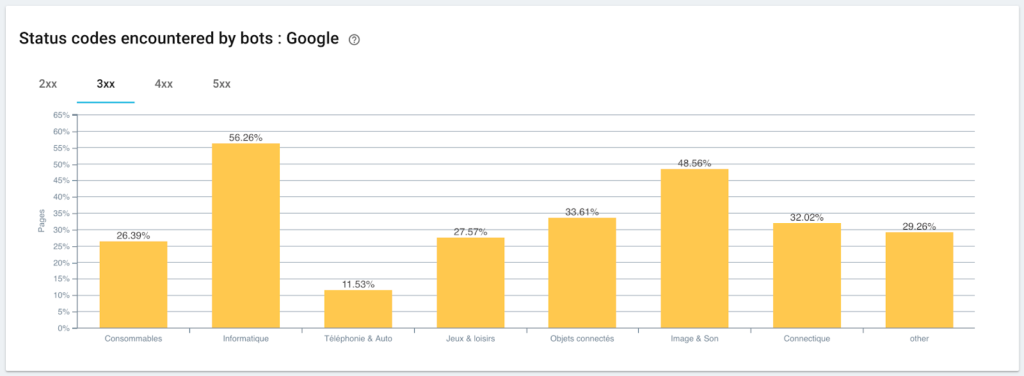
Supervisión de códigos de estado encontrados por Googlebot
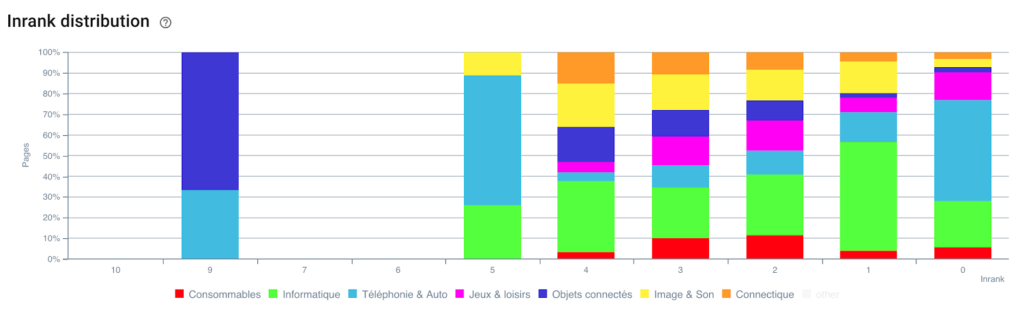
Distribución del Inrank
Y aquí estamos, acabamos de crear una segmentación automáticamente gracias a un script usando Python y OnCrawl. Todas las páginas ahora están agrupadas de acuerdo con el rastro de migas de pan y esto en 3 niveles de profundidad: 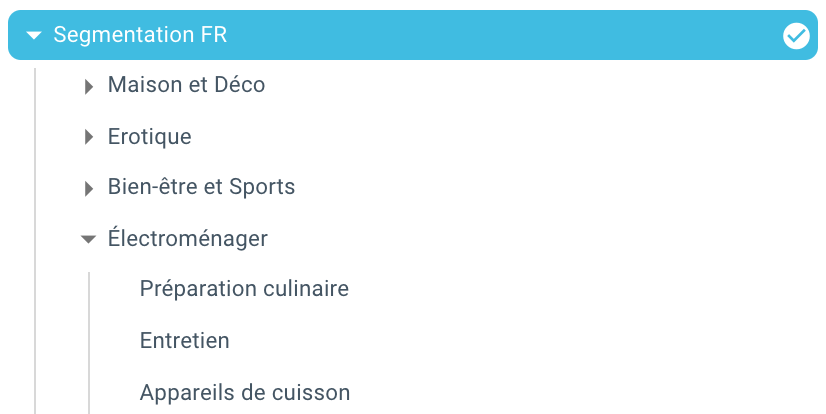
La ventaja es que ahora podemos monitorear los diferentes KPI (Crawl, profundidad, enlaces internos, presupuesto de rastreo, sesiones de SEO, visitas de SEO, rendimiento de clasificación, tiempo de carga) para cada grupo y subgrupo de páginas.
El futuro del SEO con Oncrawl
Probablemente esté pensando que es genial tener esta capacidad "lista para usar", pero no necesariamente tiene el tiempo para hacerlo todo. La buena noticia es que estamos trabajando para tener esta función integrada directamente en un futuro próximo.
Esto significa que pronto podrá crear automáticamente una segmentación en cualquier campo descartado o campo de Ingesta de datos con un simple clic. Y eso le ahorrará una tonelada de tiempo, al tiempo que le permitirá realizar un increíble análisis transversal de SEO.
Imagine poder extraer cualquier dato del código fuente de sus páginas o integrar cualquier KPI para cada URL. ¡El único límite es tu imaginación!
Por ejemplo, puede recuperar el precio de venta de los productos y ver la profundidad, el Inrank, los backlinks, el presupuesto de rastreo según el precio.
Pero también podemos recuperar los nombres de los autores de sus artículos de medios y ver quién se desempeña mejor y aplicar los métodos de escritura que funcionan mejor.
Podemos recuperar las reseñas y calificaciones de sus productos y ver si los mejores productos son accesibles con un mínimo de clics, reciben suficientes enlaces, tienen backlinks, Googlebot los rastrea bien, etc.
Podemos integrar los datos de su negocio, como la facturación, el margen, la tasa de conversión, sus gastos de Google Ads.
Ahora depende de usted imaginar cómo puede hacer una referencia cruzada de los datos para ampliar su análisis y tomar las decisiones de SEO correctas.
¿Quiere probar la segmentación automática en el rastro de migas de pan? Contáctenos a través del chatbox directamente desde Oncrawl.
¡Disfruta de tu gateo!